Машинне навчання (ML) революціонізує рішення в різних галузях і створює нові форми аналізу та аналізу даних. Багато алгоритмів ML тренуються на великих наборах даних, узагальнюючи шаблони, які вони знаходять у даних, і виводять результати з цих шаблонів, коли обробляються нові невидимі записи. Зазвичай, якщо набір даних або модель занадто великі для навчання на одному екземплярі, розподілене навчання дозволяє використовувати декілька екземплярів у кластері та розподіляти або дані, або розділи моделі між цими екземплярами під час процесу навчання. Рідна підтримка для розподіленого навчання пропонується через Amazon SageMaker SDK разом з приклади зошитів в популярних фреймворках.
Однак інколи через правила безпеки та конфіденційності всередині або між організаціями дані децентралізовано між кількома обліковими записами або в різних регіонах, і їх неможливо централізувати в одному обліковому записі чи в різних регіонах. У цьому випадку слід розглянути федеративне навчання (FL), щоб отримати узагальнену модель на всіх даних.
У цій публікації ми обговорюємо, як запровадити федеративне навчання на Amazon SageMaker для запуску машинного навчання з децентралізованими навчальними даними.
Що таке федеративне навчання?
Інтегроване навчання – це підхід машинного навчання, який дозволяє проводити декілька окремих навчальних сеансів, що проводяться паралельно, щоб проходити через великі межі, наприклад, географічно, і агрегувати результати для створення узагальненої моделі (глобальної моделі) у процесі. Точніше, кожен навчальний сеанс використовує власний набір даних і отримує власну локальну модель. Локальні моделі в різних тренувальних сесіях будуть об’єднані (наприклад, агрегація ваги моделі) в глобальну модель під час процесу навчання. Цей підхід відрізняється від централізованих методів машинного навчання, де набори даних об’єднуються для одного навчального сеансу.
Інтегроване навчання проти розподіленого навчання в хмарі
Коли ці два підходи працюють у хмарі, розподілене навчання відбувається в одному регіоні в одному обліковому записі, а навчальні дані починаються з централізованого навчального сеансу або завдання. Під час процесу розподіленого навчання набір даних розбивається на менші підмножини, і, залежно від стратегії (паралелізм даних або паралелізм моделі), підмножини надсилаються до різних навчальних вузлів або проходять через вузли в навчальному кластері, що означає, що окремі дані не обов’язково залишатися в одному вузлі кластера.
Навпаки, у випадку федеративного навчання навчання зазвичай відбувається в кількох окремих облікових записах або в різних регіонах. Кожен обліковий запис або регіон має власні екземпляри навчання. Навчальні дані децентралізовані між обліковими записами чи Регіонами від початку до кінця, а окремі дані зчитуються лише під час відповідного навчального сеансу чи завдання між різними обліковими записами чи Регіонами під час об’єднаного процесу навчання.
Flower об’єднана структура навчання
Кілька фреймворків з відкритим вихідним кодом доступні для федеративного навчання, наприклад СЛУЖБА, Квітка, PySyft, OpenFL, FedML, NVFlare та Tensorflow Federated. Вибираючи фреймворк FL, ми зазвичай розглядаємо його підтримку категорії моделі, фреймворку ML і пристрою чи операційної системи. Нам також потрібно враховувати розширюваність фреймворку FL і розмір пакета, щоб ефективно запускати його в хмарі. У цій публікації ми вибираємо легкорозширювану, настроювану та легку структуру Flower, щоб реалізувати FL за допомогою SageMaker.
Flower — це всеосяжний фреймворк FL, який відрізняється від існуючих фреймворків тим, що пропонує нові засоби для проведення широкомасштабних експериментів FL і забезпечує багато різнорідних сценаріїв пристроїв FL. FL вирішує проблеми, пов’язані з конфіденційністю даних і масштабованістю в сценаріях, коли обмін даними неможливий.
Принципи проектування та реалізації Flower FL
Flower FL за своєю конструкцією не залежить від мови та фреймворку ML, повністю розширюється та може включати нові алгоритми, стратегії навчання та протоколи зв’язку. Flower є відкритим кодом під ліцензією Apache 2.0.
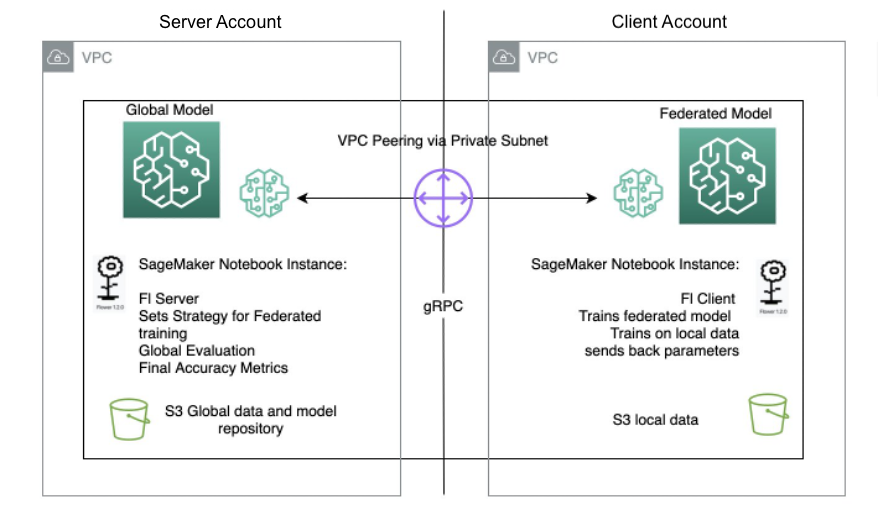
У статті описана концептуальна архітектура реалізації FL Квітка: дружня система федеративного навчання і виділено на наступному малюнку.

У цій архітектурі периферійні клієнти живуть на реальних периферійних пристроях і спілкуються із сервером через RPC. З іншого боку, віртуальні клієнти споживають майже нульові ресурси, коли вони неактивні, і завантажують модель і дані в пам’ять лише тоді, коли клієнт вибирається для навчання або оцінки.
Сервер Flower створює стратегію та конфігурації для надсилання клієнтам Flower. Він серіалізує ці словники конфігурації (або config dict коротко) до свого представлення ProtoBuf, переносить їх до клієнта за допомогою gRPC, а потім десеріалізує їх назад до словників Python.
Flower FL стратегії
Квітка дозволяє налаштувати процес навчання через абстракція стратегії. Стратегія визначає весь процес об’єднання, вказуючи ініціалізацію параметрів (незалежно від того, ініціалізовано це сервер чи клієнт), мінімальну кількість клієнтів, необхідних для ініціалізації запуску, вагу внесків клієнта, а також деталі навчання та оцінки.
Flower має широку реалізацію алгоритмів усереднення FL і надійний комунікаційний стек. Перелік реалізованих алгоритмів усереднення та відповідних наукових статей див. у наступній таблиці, з Квітка: дружня система федеративного навчання.

Інтегроване навчання за допомогою SageMaker: архітектура рішення
Архітектура об’єднаного навчання з використанням SageMaker із фреймворком Flower реалізована на основі двонаправлених потоків gRPC (основа). gRPC визначає типи повідомлень, якими обмінюються, і використовує компілятори для створення ефективної реалізації для Python, але він також може генерувати реалізацію для інших мов, таких як Java або C++.
Клієнти Flower отримують інструкції (повідомлення) у вигляді необроблених масивів байтів через мережу. Потім клієнти десеріалізують і виконують інструкцію (навчання на локальних даних). Потім результати (параметри та ваги моделі) серіалізуються та передаються на сервер.
Архітектура сервера/клієнта для Flower FL визначається в SageMaker за допомогою екземплярів блокнота в різних облікових записах у тому самому регіоні, що й сервер Flower і клієнт Flower. Стратегії навчання та оцінки визначаються на сервері, а також глобальні параметри, потім конфігурація серіалізується та надсилається клієнту через піринг VPC.
Клієнт екземпляра ноутбука запускає навчальне завдання SageMaker, яке запускає спеціальний сценарій, щоб ініціювати екземпляр клієнта Flower, який десеріалізує та зчитує конфігурацію сервера, запускає навчальне завдання та надсилає відповідь параметрів.
Останній крок відбувається на сервері, коли запускається оцінка щойно агрегованих параметрів після завершення кількості запусків і клієнтів, передбачених стратегією сервера. Оцінка виконується на тестовому наборі даних, який існує лише на сервері, і виробляються нові покращені показники точності.
Наступна діаграма ілюструє архітектуру налаштування FL на SageMaker із пакетом Flower.
Впроваджуйте федеративне навчання за допомогою SageMaker
SageMaker — це повністю керована служба машинного навчання. За допомогою SageMaker науковці та розробники даних можуть швидко створювати та навчати моделі ML, а потім розгортати їх у готовому до виробництва середовищі.
У цій публікації ми демонструємо, як використовувати керовану платформу машинного навчання, щоб забезпечити робоче середовище для ноутбуків і виконувати об’єднане навчання в облікових записах AWS, використовуючи навчальні завдання SageMaker. Необроблені навчальні дані ніколи не залишають обліковий запис, який володіє даними, і лише похідні ваги надсилаються через однорангове з’єднання.
У цій публікації ми виділяємо такі основні компоненти:
- мереж – SageMaker дозволяє швидко налаштувати конфігурацію мережі за замовчуванням, а також дозволяє повністю налаштувати мережу залежно від вимог вашої організації. Ми використовуємо a Конфігурація пірингу VPC у цьому прикладі в регіоні.
- Налаштування доступу між обліковими записами – Для того, щоб дозволити користувачеві в обліковому записі на сервері розпочати завдання навчання моделі в обліковому записі клієнта, ми делегувати доступ між обліковими записами використання Управління ідентифікацією та доступом AWS (IAM) ролі. Таким чином, користувачу облікового запису сервера не потрібно виходити з облікового запису та входити в обліковий запис клієнта, щоб виконувати дії на SageMaker. Цей параметр використовується лише для запуску навчальних завдань SageMaker і не має дозволу на доступ до даних між обліковими записами чи спільного використання.
- Впровадження клієнтського коду федеративного навчання в обліковому записі клієнта та коду сервера в обліковому записі сервера – Ми реалізуємо клієнтський код федеративного навчання в обліковому записі клієнта за допомогою пакета Flower і керованого навчання SageMaker. Тим часом ми реалізуємо код сервера в обліковому записі сервера за допомогою пакета Flower.
Налаштуйте піринг VPC
Однорангове з’єднання VPC — це мережеве з’єднання між двома VPC, яке дає змогу маршрутизувати трафік між ними за допомогою приватних адрес IPv4 або IPv6. Примірники в будь-якому VPC можуть спілкуватися між собою так, ніби вони знаходяться в одній мережі.
Щоб налаштувати однорангове з’єднання VPC, спочатку створіть запит на одноранговий зв’язок з іншим VPC. Ви можете надіслати запит на однорангове з’єднання VPC з іншим VPC у тому самому обліковому записі або, у нашому випадку використання, з’єднатися з VPC в іншому обліковому записі AWS. Щоб активувати запит, власник VPC повинен прийняти запит. Докладніше про піринг VPC див Створіть пірингове з’єднання VPC.
Запустіть екземпляри блокнотів SageMaker у VPC
Екземпляр блокнота SageMaker надає програму для блокнота Jupyter через повністю керований ML Обчислювальна хмара Amazon Elastic (Amazon EC2). Ноутбуки SageMaker Jupyter використовуються для розширеного дослідження даних, створення навчальних завдань, розгортання моделей на хостингу SageMaker, а також для тестування чи перевірки ваших моделей.
Екземпляр ноутбука має різноманітні доступні мережеві конфігурації. У цьому налаштуванні екземпляр ноутбука працює в приватній підмережі VPC і не має прямого доступу до Інтернету.

Налаштуйте параметри доступу між обліковими записами
Параметри доступу між обліковими записами включають два кроки для делегування доступу від облікового запису сервера до облікового запису клієнта за допомогою ролей IAM:
- Створіть роль IAM в обліковому записі клієнта.
- Надайте доступ до ролі в обліковому записі сервера.
Докладні кроки для налаштування подібного сценарію див Делегуйте доступ обліковим записам AWS за допомогою ролей IAM.
В обліковому записі клієнта ми створюємо роль IAM під назвою FL-kickoff-client-job з політикою FL-sagemaker-actions додається до ролі. The FL-sagemaker-actions політика має такий вміст JSON:
Потім ми змінюємо політику довіри в довірчих відносинах FL-kickoff-client-job роль:
В обліковому записі сервера дозволи додаються до наявного користувача (наприклад, developer), щоб дозволити перехід на FL-kickoff-client-job роль в обліковому записі клієнта. Для цього ми створюємо вбудовану політику під назвою FL-allow-kickoff-client-job і приєднати його до користувача. Нижче наведено вміст JSON політики:
Вибірковий набір даних і підготовка даних
У цій публікації ми використовуємо a підібраний набір даних для виявлення шахрайства в даних провайдерів Medicare, опублікованих Центри надання послуг Medicare & Medicaid (CMS). Дані розділені на набір даних для навчання та набір даних для тестування. Оскільки більшість даних не є шахрайськими, ми застосовуємо ПРИГРИТИ щоб збалансувати навчальний набір даних і далі розділити навчальний набір даних на навчальну та перевірочну частини. Дані навчання та перевірки завантажуються в Служба простого зберігання Amazon (Amazon S3) для навчання моделі в обліковому записі клієнта, а тестовий набір даних використовується в обліковому записі сервера лише з метою тестування. Подробиці коду підготовки даних наведено нижче ноутбук.
З SageMaker попередньо створені образи Docker для фреймворку scikit-learn і керований навчальний процес SageMaker, ми навчаємо модель логістичної регресії на цьому наборі даних за допомогою федеративного навчання.
Впровадьте клієнт інтегрованого навчання в обліковому записі клієнта
В екземплярі блокнота SageMaker облікового запису клієнта ми готуємо a client.py сценарій і a utils.py сценарій. The client.py файл містить код для клієнта та utils.py файл містить код для деяких службових функцій, які знадобляться для нашого навчання. Ми використовуємо пакет scikit-learn для створення моделі логістичної регресії.
In client.py, ми визначаємо клієнта Flower. Клієнт є похідним від класу fl.client.NumPyClient. Потрібно визначити такі три методи:
- get_parameters – Повертає поточні локальні параметри моделі. Функція корисності
get_model_parametersзробимо це. - відповідати – Він визначає кроки для навчання моделі на даних навчання в обліковому записі клієнта. Він також отримує глобальні параметри моделі та іншу конфігураційну інформацію від сервера. Ми оновлюємо параметри локальної моделі за допомогою отриманих глобальних параметрів і продовжуємо навчання на наборі даних в обліковому записі клієнта. Цей метод також надсилає на сервер параметри локальної моделі після навчання, розмір навчального набору та словник, що передає довільні значення.
- оцінювати – Він оцінює надані параметри, використовуючи дані перевірки в обліковому записі клієнта. Він повертає на сервер втрату разом з іншими деталями, такими як розмір набору перевірки та точність.
Нижче наведено фрагмент коду для визначення клієнта Flower:
Потім ми використовуємо SageMaker сценарій підготувати решту client.py файл. Це включає визначення параметрів, які будуть передані до навчання SageMaker, завантаження даних навчання та перевірки, ініціалізацію та навчання моделі на клієнті, налаштування клієнта Flower для зв’язку із сервером і, нарешті, збереження навченої моделі.
utils.py містить кілька допоміжних функцій, які викликаються client.py:
- get_model_parameters – Він повертає scikit-learn Логістична регресія параметри моделі.
- set_model_params – Він встановлює параметри моделі.
- set_initial_params – Він ініціалізує параметри моделі як нулі. Це потрібно, оскільки сервер запитує початкові параметри моделі від клієнта під час запуску. Однак у структурі scikit-learn,
LogisticRegressionпараметри моделі не ініціалізуються доmodel.fit()це називається. - load_data – Він завантажує дані навчання та тестування.
- зберегти_модель – Зберігає модель як a
.joblibфайлу.
Оскільки Flower не є пакетом, встановленим у SageMaker попередньо зібраний контейнер scikit-learn Docker, перераховуємо flwr==1.3.0 В requirements.txt файлу.
Ставимо всі три файли (client.py, utils.py та requirements.txt) у папці та заархівуйте її в tar. Файл .tar.gz (названий source.tar.gz у цій публікації) потім завантажується в сегмент S3 в обліковому записі клієнта.
Впровадьте сервер об’єднаного навчання в обліковому записі сервера
В обліковому записі сервера ми готуємо код на блокноті Jupyter. Це складається з двох частин: спочатку сервер бере на себе роль, щоб розпочати навчальну роботу в обліковому записі клієнта, а потім сервер об’єднує модель за допомогою Flower.
Візьміть на себе роль для виконання навчального завдання в обліковому записі клієнта
Ми використовуємо Boto3 Python SDK налаштувати Служба маркерів безпеки AWS (AWS STS) клієнт припускає FL-kickoff-client-job роль і налаштуйте клієнта SageMaker для запуску навчального завдання в обліковому записі клієнта за допомогою керованого процесу навчання SageMaker:
Використовуючи прийняту роль, ми створюємо навчальне завдання SageMaker в обліковому записі клієнта. Навчальна робота використовує вбудовану структуру scikit-learn SageMaker. Зауважте, що всі сегменти S3 і роль IAM SageMaker у наведеному нижче фрагменті коду пов’язані з обліковим записом клієнта:
Об’єднайте локальні моделі в глобальну модель за допомогою Flower
Ми готуємо код для об’єднання моделі на сервері. Це включає визначення стратегії об'єднання та її параметрів ініціалізації. Ми використовуємо функції корисності в utils.py сценарій, описаний раніше, для ініціалізації та встановлення параметрів моделі. Flower дозволяє вам визначати власні функції зворотного виклику, щоб налаштувати існуючу стратегію. Ми використовуємо FedAvg стратегія з користувальницькими зворотними викликами для оцінки та налаштування відповідності. Перегляньте наступний код:
Наступні дві функції згадуються в попередньому фрагменті коду:
- fit_round – Використовується для надсилання круглого числа клієнту. Ми передаємо цей зворотній виклик як
on_fit_config_fnпараметр стратегії. Ми робимо це просто для демонстрації використанняon_fit_config_fnпараметр. - get_evaluate_fn – Використовується для оцінки моделі на сервері.
У демонстраційних цілях ми використовуємо набір даних тестування, який ми відклали під час підготовки даних, щоб оцінити модель, об’єднану з облікового запису клієнта, і повідомити результат назад клієнту. Однак варто зазначити, що майже в усіх випадках реального використання дані, які використовуються в обліковому записі сервера, не відокремлюються від набору даних, який використовується в обліковому записі клієнта.
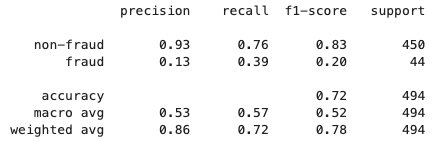
Після завершення процесу об’єднаного навчання a model.tar.gz файл зберігається SageMaker як артефакт моделі у сегменті S3 в обліковому записі клієнта. Тим часом а model.joblib файл зберігається в екземплярі блокнота SageMaker в обліковому записі сервера. Нарешті, ми використовуємо тестовий набір даних для тестування остаточної моделі (model.joblib) на сервері. Результат тестування кінцевої моделі такий:
Прибирати
Після завершення очистіть ресурси як в обліковому записі сервера, так і в обліковому записі клієнта, щоб уникнути додаткових витрат:
- Зупиніть екземпляри блокнота SageMaker.
- Видаліть пірингові з’єднання VPC і відповідні VPC.
- Очистіть і видаліть відро S3, яке ви створили для зберігання даних.
Висновок
У цій публікації ми розповіли, як реалізувати федеративне навчання на SageMaker за допомогою пакета Flower. Ми показали, як налаштувати піринг VPC, налаштувати доступ між обліковими записами та реалізувати клієнт і сервер FL. Ця публікація корисна для тих, кому потрібно навчати моделі ML на SageMaker, використовуючи децентралізовані дані в облікових записах із обмеженим обміном даними. Оскільки FL у цьому дописі реалізовано за допомогою SageMaker, варто зазначити, що в SageMaker можна додати набагато більше функцій.
Впровадження федеративного навчання на SageMaker може скористатися всіма розширеними функціями, які SageMaker надає через життєвий цикл ML. Існують інші способи досягнення або застосування федеративного навчання в хмарі AWS, як-от використання екземплярів EC2 або на межі. Докладніше про ці альтернативні підходи див Федеративне навчання на AWS з FedML та Застосування федеративного навчання для машинного навчання на межі.
Про авторів
 Шеррі Дін є старшим архітектором рішень спеціаліста зі штучного інтелекту/ML в Amazon Web Services (AWS). Вона має великий досвід машинного навчання зі ступенем доктора філософії з інформатики. В основному вона працює з клієнтами державного сектору над різними бізнес-завданнями, пов’язаними зі штучним інтелектом/ML, допомагаючи їм прискорити процес машинного навчання в AWS Cloud. Коли вона не допомагає клієнтам, вона любить активний відпочинок.
Шеррі Дін є старшим архітектором рішень спеціаліста зі штучного інтелекту/ML в Amazon Web Services (AWS). Вона має великий досвід машинного навчання зі ступенем доктора філософії з інформатики. В основному вона працює з клієнтами державного сектору над різними бізнес-завданнями, пов’язаними зі штучним інтелектом/ML, допомагаючи їм прискорити процес машинного навчання в AWS Cloud. Коли вона не допомагає клієнтам, вона любить активний відпочинок.
 Лореа Аррісабалага є архітектором рішень у державному секторі Великобританії, де вона допомагає клієнтам розробляти рішення ML за допомогою Amazon SageMaker. Вона також є частиною Technical Field Community, яка займається апаратним прискоренням, і допомагає тестувати та порівнювати робочі навантаження AWS Inferentia та AWS Trainium.
Лореа Аррісабалага є архітектором рішень у державному секторі Великобританії, де вона допомагає клієнтам розробляти рішення ML за допомогою Amazon SageMaker. Вона також є частиною Technical Field Community, яка займається апаратним прискоренням, і допомагає тестувати та порівнювати робочі навантаження AWS Inferentia та AWS Trainium.
 Бен Снівлі є старшим головним спеціалістом з розробки рішень AWS у державному секторі. Він працює з державними, некомерційними та освітніми організаціями над великими даними, аналітичними проектами та проектами AI/ML, допомагаючи їм створювати рішення за допомогою AWS.
Бен Снівлі є старшим головним спеціалістом з розробки рішень AWS у державному секторі. Він працює з державними, некомерційними та освітніми організаціями над великими даними, аналітичними проектами та проектами AI/ML, допомагаючи їм створювати рішення за допомогою AWS.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. Автомобільні / електромобілі, вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- ChartPrime. Розвивайте свою торгову гру за допомогою ChartPrime. Доступ тут.
- BlockOffsets. Модернізація екологічної компенсаційної власності. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/machine-learning-with-decentralized-training-data-using-federated-learning-on-amazon-sagemaker/

