In asset management, portfolio managers need to closely monitor companies in their investment universe to identify risks and opportunities, and guide investment decisions. Tracking direct events like earnings reports or credit downgrades is straightforward—you can set up alerts to notify managers of news containing company names. However, detecting second and third-order impacts arising from events at suppliers, customers, partners, or other entities in a company’s ecosystem is challenging.
For example, a supply chain disruption at a key vendor would likely negatively impact downstream manufacturers. Or the loss of a top customer for a major client poses a demand risk for the supplier. Very often, such events fail to make headlines featuring the impacted company directly, but are still important to pay attention to. In this post, we demonstrate an automated solution combining knowledge graphs and generative artificial intelligence (AI) to surface such risks by cross-referencing relationship maps with real-time news.
Broadly, this entails two steps: First, building the intricate relationships between companies (customers, suppliers, directors) into a knowledge graph. Second, using this graph database along with generative AI to detect second and third-order impacts from news events. For instance, this solution can highlight that delays at a parts supplier may disrupt production for downstream auto manufacturers in a portfolio though none are directly referenced.
With AWS, you can deploy this solution in a serverless, scalable, and fully event-driven architecture. This post demonstrates a proof of concept built on two key AWS services well suited for graph knowledge representation and natural language processing: Amazon Neptune and Amazon Bedrock. Neptune is a fast, reliable, fully managed graph database service that makes it straightforward to build and run applications that work with highly connected datasets. Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon through a single API, along with a broad set of capabilities to build generative AI applications with security, privacy, and responsible AI.
Overall, this prototype demonstrates the art of possible with knowledge graphs and generative AI—deriving signals by connecting disparate dots. The takeaway for investment professionals is the ability to stay on top of developments closer to the signal while avoiding noise.
Build the knowledge graph

The first step in this solution is building a knowledge graph, and a valuable yet often overlooked data source for knowledge graphs is company annual reports. Because official corporate publications undergo scrutiny before release, the information they contain is likely to be accurate and reliable. However, annual reports are written in an unstructured format meant for human reading rather than machine consumption. To unlock their potential, you need a way to systematically extract and structure the wealth of facts and relationships they contain.
With generative AI services like Amazon Bedrock, you now have the capability to automate this process. You can take an annual report and trigger a processing pipeline to ingest the report, break it down into smaller chunks, and apply natural language understanding to pull out salient entities and relationships.
For example, a sentence stating that “[Company A] expanded its European electric delivery fleet with an order for 1,800 electric vans from [Company B]” would allow Amazon Bedrock to identify the following:
- [Company A] as a customer
- [Company B] as a supplier
- A supplier relationship between [Company A] and [Company B]
- Relationship details of “supplier of electric delivery vans”
Extracting such structured data from unstructured documents requires providing carefully crafted prompts to large language models (LLMs) so they can analyze text to pull out entities like companies and people, as well as relationships such as customers, suppliers, and more. The prompts contain clear instructions on what to look out for and the structure to return the data in. By repeating this process across the entire annual report, you can extract the relevant entities and relationships to construct a rich knowledge graph.
However, before committing the extracted information to the knowledge graph, you need to first disambiguate the entities. For instance, there may already be another ‘[Company A]’ entity in the knowledge graph, but it could represent a different organization with the same name. Amazon Bedrock can reason and compare the attributes such as business focus area, industry, and revenue-generating industries and relationships to other entities to determine if the two entities are actually distinct. This prevents inaccurately merging unrelated companies into a single entity.
After disambiguation is complete, you can reliably add new entities and relationships into your Neptune knowledge graph, enriching it with the facts extracted from annual reports. Over time, the ingestion of reliable data and integration of more reliable data sources will help build a comprehensive knowledge graph that can support revealing insights through graph queries and analytics.
This automation enabled by generative AI makes it feasible to process thousands of annual reports and unlocks an invaluable asset for knowledge graph curation that would otherwise go untapped due to the prohibitively high manual effort needed.
The following screenshot shows an example of the visual exploration that’s possible in a Neptune graph database using the Graph Explorer tool.

Process news articles

The next step of the solution is automatically enriching portfolio managers’ news feeds and highlighting articles relevant to their interests and investments. For the news feed, portfolio managers can subscribe to any third-party news provider through AWS Data Exchange or another news API of their choice.
When a news article enters the system, an ingestion pipeline is invoked to process the content. Using techniques similar to the processing of annual reports, Amazon Bedrock is used to extract entities, attributes, and relationships from the news article, which are then used to disambiguate against the knowledge graph to identify the corresponding entity in the knowledge graph.
The knowledge graph contains connections between companies and people, and by linking article entities to existing nodes, you can identify if any subjects are within two hops of the companies that the portfolio manager has invested in or is interested in. Finding such a connection indicates the article may be relevant to the portfolio manager, and because the underlying data is represented in a knowledge graph, it can be visualized to help the portfolio manager understand why and how this context is relevant. In addition to identifying connections to the portfolio, you can also use Amazon Bedrock to perform sentiment analysis on the entities referenced.
The final output is an enriched news feed surfacing articles likely to impact the portfolio manager’s areas of interest and investments.
Solution overview
The overall architecture of the solution looks like the following diagram.
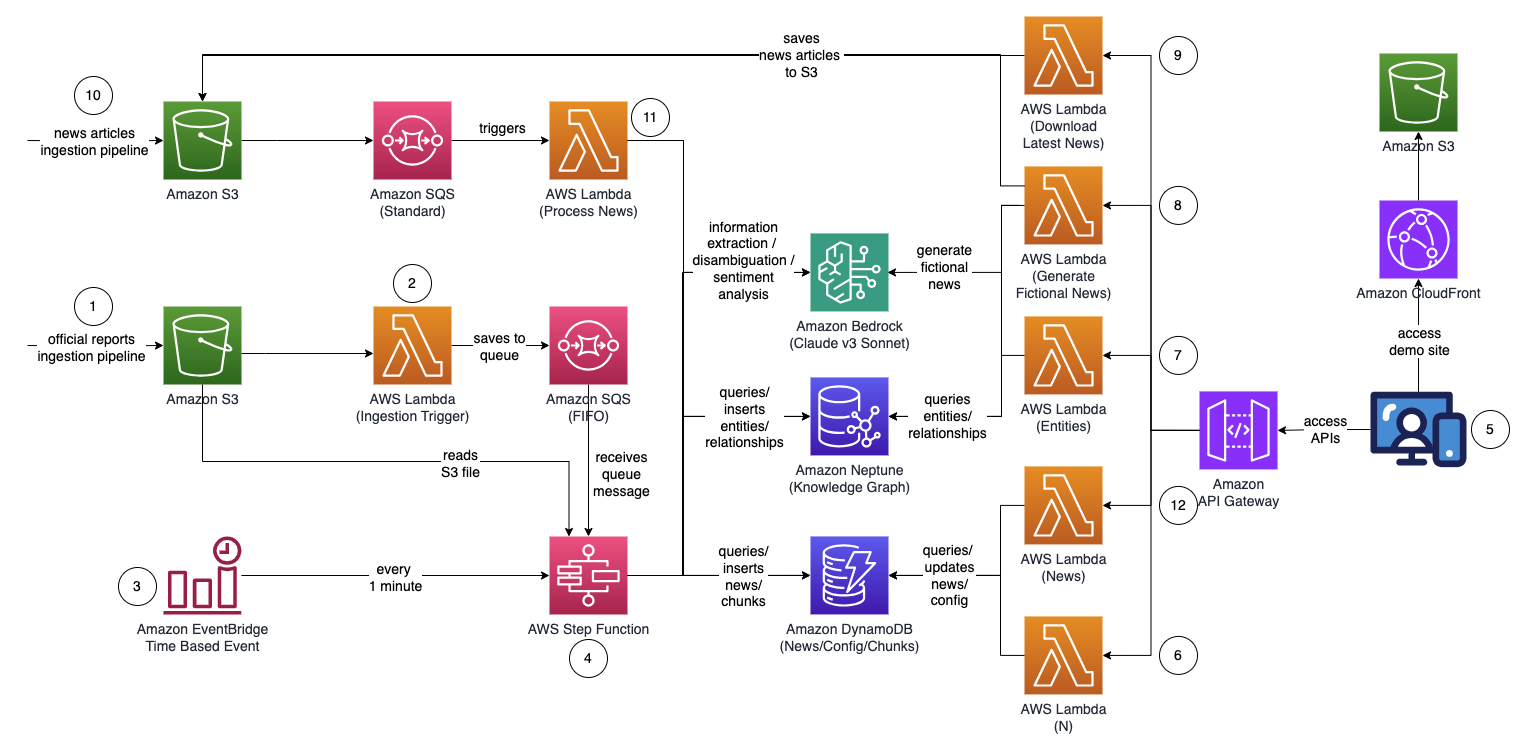
The workflow consists of the following steps:
- A user uploads official reports (in PDF format) to an Amazon Simple Storage Service (Amazon S3) bucket. The reports should be officially published reports to minimize the inclusion of inaccurate data into your knowledge graph (as opposed to news and tabloids).
- The S3 event notification invokes an AWS Lambda function, which sends the S3 bucket and file name to an Amazon Simple Queue Service (Amazon SQS) queue. The First-In-First-Out (FIFO) queue makes sure that the report ingestion process is performed sequentially to reduce the likelihood of introducing duplicate data into your knowledge graph.
- An Amazon EventBridge time-based event runs every minute to start the run of an AWS Step Functions state machine asynchronously.
- The Step Functions state machine runs through a series of tasks to process the uploaded document by extracting key information and inserting it into your knowledge graph:
- Receive the queue message from Amazon SQS.
- Download the PDF report file from Amazon S3, split it into multiple smaller text chunks (approximately 1,000 words) for processing, and store the text chunks in Amazon DynamoDB.
- Use Anthropic’s Claude v3 Sonnet on Amazon Bedrock to process the first few text chunks to determine the main entity that the report is referring to, together with relevant attributes (such as industry).
- Retrieve the text chunks from DynamoDB and for each text chunk, invoke a Lambda function to extract out entities (such as company or person), and its relationship (customer, supplier, partner, competitor, or director) to the main entity using Amazon Bedrock.
- Consolidate all extracted information.
- Filter out noise and irrelevant entities (for example, generic terms such as “consumers”) using Amazon Bedrock.
- Use Amazon Bedrock to perform disambiguation by reasoning using the extracted information against the list of similar entities from the knowledge graph. If the entity does not exist, insert it. Otherwise, use the entity that already exists in the knowledge graph. Insert all relationships extracted.
- Clean up by deleting the SQS queue message and the S3 file.
- A user accesses a React-based web application to view the news articles that are supplemented with the entity, sentiment, and connection path information.
- Using the web application, the user specifies the number of hops (default N=2) on the connection path to monitor.
- Using the web application, the user specifies the list of entities to track.
- To generate fictional news, the user chooses Generate Sample News to generate 10 sample financial news articles with random content to be fed into the news ingestion process. Content is generated using Amazon Bedrock and is purely fictional.
- To download actual news, the user chooses Download Latest News to download the top news happening today (powered by NewsAPI.org).
- The news file (TXT format) is uploaded to an S3 bucket. Steps 8 and 9 upload news to the S3 bucket automatically, but you can also build integrations to your preferred news provider such as AWS Data Exchange or any third-party news provider to drop news articles as files into the S3 bucket. News data file content should be formatted as
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - The S3 event notification sends the S3 bucket or file name to Amazon SQS (standard), which invokes multiple Lambda functions to process the news data in parallel:
- Use Amazon Bedrock to extract entities mentioned in the news together with any related information, relationships, and sentiment of the mentioned entity.
- Check against the knowledge graph and use Amazon Bedrock to perform disambiguation by reasoning using the available information from the news and from within the knowledge graph to identify the corresponding entity.
- After the entity has been located, search for and return any connection paths connecting to entities marked with
INTERESTED=YESin the knowledge graph that are within N=2 hops away.
- The web application auto refreshes every 1 second to pull out the latest set of processed news to display on the web application.
Deploy the prototype
You can deploy the prototype solution and start experimenting yourself. The prototype is available from GitHub and includes details on the following:
- Deployment prerequisites
- Deployment steps
- Cleanup steps
Summary
This post demonstrated a proof of concept solution to help portfolio managers detect second- and third-order risks from news events, without direct references to companies they track. By combining a knowledge graph of intricate company relationships with real-time news analysis using generative AI, downstream impacts can be highlighted, such as production delays from supplier hiccups.
Although it’s only a prototype, this solution shows the promise of knowledge graphs and language models to connect dots and derive signals from noise. These technologies can aid investment professionals by revealing risks faster through relationship mappings and reasoning. Overall, this is a promising application of graph databases and AI that warrants exploration to augment investment analysis and decision-making.
If this example of generative AI in financial services is of interest to your business, or you have a similar idea, reach out to your AWS account manager, and we will be delighted to explore further with you.
About the Author
 Xan Huang is a Senior Solutions Architect with AWS and is based in Singapore. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Xan spends most of his free time with his family and getting bossed around by his 3-year-old daughter. You can find Xan on LinkedIn.
Xan Huang is a Senior Solutions Architect with AWS and is based in Singapore. He works with major financial institutions to design and build secure, scalable, and highly available solutions in the cloud. Outside of work, Xan spends most of his free time with his family and getting bossed around by his 3-year-old daughter. You can find Xan on LinkedIn.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

