Це гостьовий допис у блозі, написаний Нітіном Кумаром, провідним спеціалістом із обробки даних у T and T Consulting Services, Inc.
У цій публікації ми обговорюємо цінність і потенційний вплив інтегрованого навчання в галузі охорони здоров’я. Цей підхід може допомогти пацієнтам із серцевим інсультом, лікарям і дослідникам у швидшій діагностиці, розширеному прийнятті рішень і більш інформованій, всеохоплюючій дослідницькій роботі щодо проблем здоров’я, пов’язаних з інсультом, використовуючи хмарний підхід із сервісами AWS для легкого підйому та простого впровадження .
Проблеми з діагностикою серцевих інсультів
Статистика з Центри з контролю і профілактиці захворювань (CDC) показують, що щороку в США більше 795,000 25 людей страждають від свого першого інсульту, і близько XNUMX% з них відчувають повторні напади. Це п'ята причина смерті згідно з Американська асоціація інсульту і головною причиною інвалідності в США. Тому вкрай важливо мати швидку діагностику та лікування, щоб зменшити пошкодження мозку та інші ускладнення у пацієнтів з гострим інсультом.
КТ та МРТ є золотим стандартом у технологіях візуалізації для класифікації різних підтипів інсульту та мають вирішальне значення під час попереднього обстеження пацієнтів, визначення першопричини та лікування. Однією з критичних проблем, особливо у випадку гострого інсульту, є час візуалізаційної діагностики, який у середньому коливається від 30 хвилин до години і може тривати набагато довше залежно від скупченості відділення невідкладної допомоги.
Лікарям та медичному персоналу потрібна швидка та точна діагностика за зображенням, щоб оцінити стан пацієнта та запропонувати варіанти лікування. За словами доктора Вернера Фогельса в AWS re:Invent 2023, «кожна секунда, коли в людини стався інсульт, має значення». Жертви інсульту можуть втрачати близько 1.9 мільярда нейронів кожну секунду, коли вони не лікуються.
Обмеження щодо медичних даних
Ви можете використовувати машинне навчання (ML), щоб допомогти лікарям і дослідникам у діагностичних завданнях, тим самим прискорюючи процес. Проте набори даних, необхідні для побудови моделей ML і отримання надійних результатів, зберігаються в різних системах охорони здоров’я та організаціях. Ці ізольовані застарілі дані можуть мати величезний вплив, якщо накопичувати їх. Тож чому його досі не використали?
Під час роботи з наборами даних у медичній сфері та створення рішень для машинного навчання виникає багато проблем, зокрема конфіденційність пацієнтів, безпека особистих даних, а також певні бюрократичні та політичні обмеження. Крім того, науково-дослідні установи посилили практику обміну даними. Ці перешкоди також заважають міжнародним дослідницьким групам працювати разом над різноманітними та багатими наборами даних, які, окрім інших переваг, можуть врятувати життя та запобігти інвалідності, спричиненій інсультом.
Політика та правила, як Положення про захист персональних даних Загальні (GDPR), Закон про переносимість та відповідальність за охорону здоров'я (HIPPA), і Каліфорнійський закон про конфіденційність споживачів (CCPA) обмежили обмін даними з медичної сфери, особливо даними пацієнтів. Крім того, набори даних в окремих інститутах, організаціях і лікарнях часто надто малі, незбалансовані або мають упереджений розподіл, що призводить до обмежень узагальнення моделі.
Інтегроване навчання: вступ
Федеративне навчання (FL) — це децентралізована форма машинного навчання — динамічний інженерний підхід. У цьому децентралізованому підході ML модель ML спільно використовується організаціями для навчання на підмножинах власних даних, на відміну від традиційного централізованого навчання ML, де модель зазвичай навчається на агрегованих наборах даних. Дані залишаються захищеними брандмауерам організації або VPC, тоді як модель із її метаданими надається спільно.
На етапі навчання глобальна модель FL поширюється та синхронізується між організаціями підрозділів для навчання на окремих наборах даних, а також повертається локальна навчена модель. Остаточна глобальна модель доступна для використання для прогнозування для всіх учасників, а також може бути використана як основа для подальшого навчання для створення локальних індивідуальних моделей для організацій-учасниць. Він може бути розширений для інших інститутів. Цей підхід може значно знизити вимоги до кібербезпеки для даних, що передаються, усуваючи необхідність у передачі даних за межі організації взагалі.
Наступна діаграма ілюструє приклад архітектури.
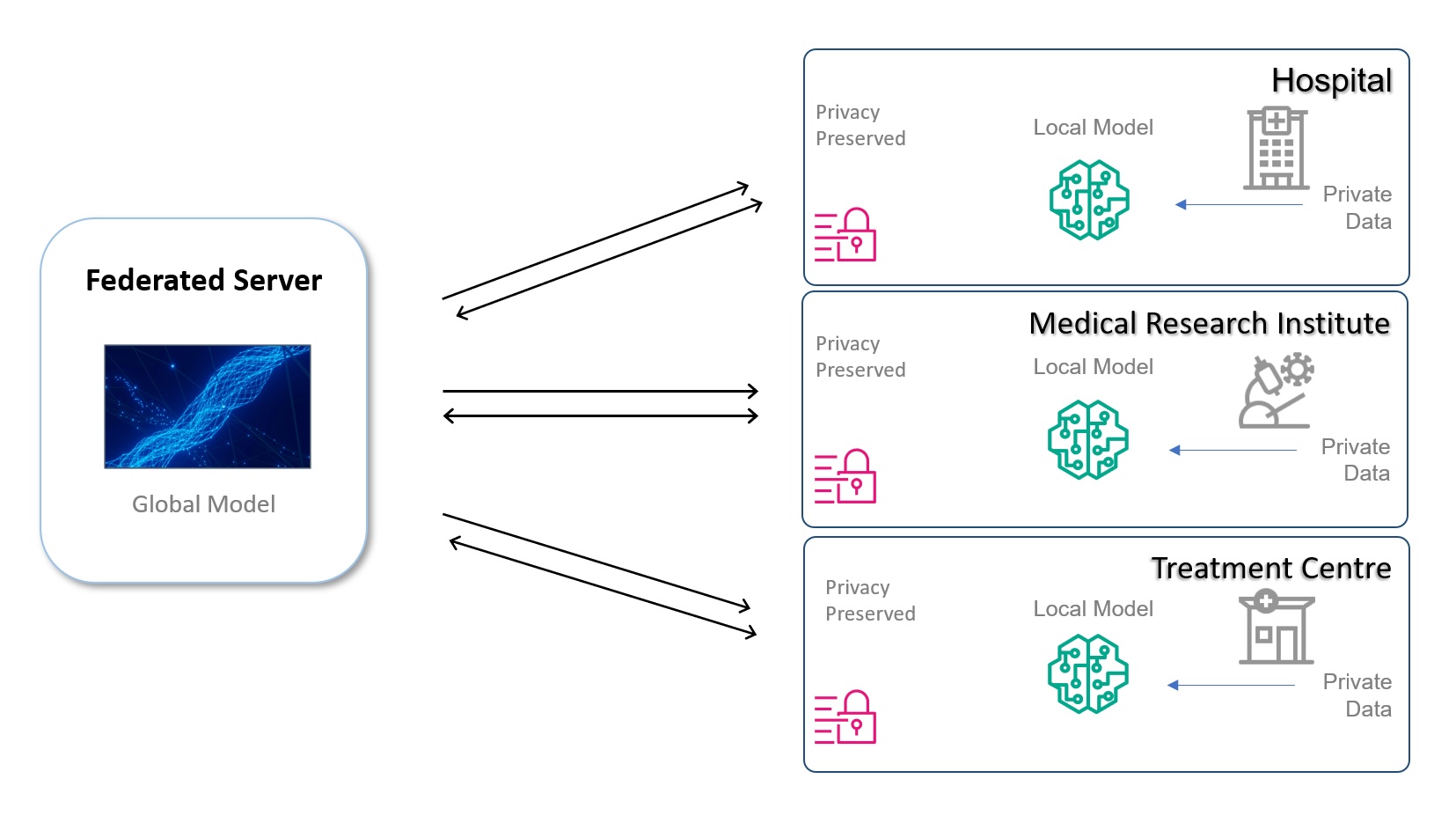
У наступних розділах ми обговорюємо, як інтегроване навчання може допомогти.
Федерація вчиться рятувати день (і рятувати життя)
Для якісного штучного інтелекту (ШІ) потрібні хороші дані.
Застарілі системи, які часто зустрічаються у федеральному домені, створюють значні проблеми з обробкою даних, перш ніж ви зможете отримати будь-які дані або об’єднати їх із новими наборами даних. Це є перешкодою для надання цінних розвідувальних даних лідерам. Це може призвести до неправильного прийняття рішень, оскільки частка застарілих даних іноді набагато цінніша порівняно з новим невеликим набором даних. Ви хочете вирішити це вузьке місце ефективно й без навантаження на консолідацію та інтеграцію вручну (включно з громіздкими процесами відображення) для застарілих і новіших наборів даних, які знаходяться в лікарнях та інститутах, що може зайняти багато місяців, якщо не років, у багатьох випадках. Застарілі дані є досить цінними, оскільки містять важливу контекстну інформацію, необхідну для прийняття точних рішень і обґрунтованого навчання моделі, що веде до надійного ШІ в реальному світі. Тривалість даних інформує про довгострокові варіації та закономірності в наборі даних, які в іншому випадку залишилися б непоміченими та призвели б до упереджених і погано обґрунтованих прогнозів.
Знищення цих бункерів даних для об’єднання невикористаного потенціалу розрізнених даних може врятувати та змінити багато життів. Це також може прискорити дослідження, пов’язані з вторинними проблемами зі здоров’ям, що виникають внаслідок серцевих інсультів. Це рішення може допомогти вам обмінюватися думками з даних, ізольованих між інститутами через політику та з інших причин, незалежно від того, чи є ви лікарнею, дослідницьким інститутом чи іншими організаціями, орієнтованими на дані про здоров’я. Це може дозволити приймати обґрунтовані рішення щодо напрямку дослідження та діагностики. Крім того, це створює централізоване сховище розвідувальних даних через безпечну, приватну та глобальну базу знань.

Інтегроване навчання має багато переваг загалом і особливо для параметрів медичних даних.
Функції безпеки та конфіденційності:
- Зберігає конфіденційні дані подалі від Інтернету та все одно використовує їх для ML, а також використовує свій інтелект із диференціальною конфіденційністю
- Дозволяє створювати, навчати та розгортати неупереджені та надійні моделі не лише на машинах, а й у мережах без будь-яких загроз безпеці даних
- Долає перешкоди з кількома постачальниками, які керують даними
- Усуває потребу в міжсайтовому обміні даними та глобальному управлінні
- Зберігає конфіденційність за допомогою диференційованої конфіденційності та пропонує безпечне багатостороннє обчислення з локальним навчанням
Покращення продуктивності:
- Вирішує проблему невеликого розміру вибірки в області медичних зображень і дорогих процесів маркування
- Збалансовує розподіл даних
- Дозволяє використовувати більшість традиційних методів машинного навчання та глибокого навчання (DL).
- Використовує об’єднані набори зображень, щоб допомогти покращити статистичну потужність, подолавши обмеження розміру вибірки окремих установ
Переваги стійкості:
- Якщо якась сторона вирішить піти, це не завадить навчанню
- Нова лікарня або інститут можуть приєднатися в будь-який час; він не залежить від будь-якого конкретного набору даних з будь-якою організацією вузла
- Немає потреби в розгалужених інженерних конвеєрах даних для застарілих даних, розкиданих по широко поширених географічних місцях
Ці функції можуть допомогти зруйнувати стіни між установами, які розміщують ізольовані набори даних у подібних доменах. Рішення може стати примножувачем сили, використовуючи уніфіковані можливості розподілених наборів даних і покращуючи ефективність шляхом радикальної трансформації аспекту масштабованості без важкої інфраструктури. Цей підхід допомагає ML повністю розкрити свій потенціал, стати досвідченим на клінічному рівні, а не лише на дослідницькому рівні.
Інтегроване навчання має порівнянну продуктивність зі звичайним машинним навчанням, як показано нижче експеримент від NVidia Clara (на Medical Modal ARchive (MMAR) з використанням набору даних BRATS2018). Тут FL досяг порівняльної продуктивності сегментації порівняно з навчанням із централізованими даними: понад 80% із приблизно 600 епохами під час навчання багатомодального завдання сегментації пухлини головного мозку з кількома класами.
Федеративне навчання нещодавно було протестовано в кількох підгалузях медицини для випадків використання, включаючи навчання схожості пацієнтів, навчання представлення пацієнтів, фенотипування та прогнозне моделювання.
План програми: інтегроване навчання робить це можливим і простим
Щоб розпочати роботу з FL, ви можете вибрати з багатьох високоякісних наборів даних. Наприклад, набори даних із зображеннями мозку включають ЗБИРАЙТЕСЬ (Ініціатива з обміну даними про аутизм, зображення мозку), ADNI (Ініціатива нейровізуалізації хвороби Альцгеймера), RSNA (Радіологічне товариство Північної Америки) КТ головного мозку, BraTS (Бенчмарк мультимодальної сегментації зображення пухлини головного мозку) регулярно оновлюється для завдання сегментації пухлини головного мозку під UPenn (Університет Пенсільванії), BioBank Великобританії (розглянуто в наступному NIH папір), А також XI. Подібно до зображень серця, ви можете вибрати один із кількох загальнодоступних варіантів, у тому числі ACDC (Automatic Cardiac Diagnosis Challenge), який є набором даних для оцінки МРТ серця з повною анотацією, згаданою Національною бібліотекою медицини в наступному. папір, і M&M (багатоцентровий, багатопровайдерський і багатозахворювальний) виклик сегментації серця, згаданий нижче IEEE папір.
Наступні зображення показують a імовірнісна карта перекриття уражень для первинних уражень із набору даних ATLAS R1.1. (Інсульти є однією з найпоширеніших причин уражень головного мозку згідно з Cleveland Clinic.)

Для даних електронних медичних записів (EHR) доступно кілька наборів даних, які слідують за Ресурси для швидкої взаємодії в галузі охорони здоров’я (FHIR) стандарт. Цей стандарт допомагає вам створювати прості пілотні проекти, усуваючи певні проблеми з різнорідними, ненормалізованими наборами даних, забезпечуючи плавний і безпечний обмін, спільний доступ та інтеграцію наборів даних. FHIR забезпечує максимальну сумісність. Приклади набору даних включають МІМІК-IV (Медичний інформаційний марш інтенсивної терапії). Інші високоякісні набори даних, які наразі не є FHIR, але можуть бути легко конвертовані, включають Центри Medicare та Medicaid Services (CMS) Файли загального користування (PUF) і База даних спільних досліджень eICU з MIT (Массачусетський технологічний інститут). Також стають доступними інші ресурси, які пропонують набори даних на основі FHIR.
Життєвий цикл реалізації FL може включати наступне кроки: ініціалізація завдання, вибір, конфігурація, навчання моделі, зв’язок клієнт/сервер, планування та оптимізація, версії, тестування, розгортання та припинення. Існує багато трудомістких етапів підготовки даних медичної візуалізації для традиційного МЛ, як описано нижче папір. У деяких сценаріях для попередньої обробки необроблених даних пацієнта може знадобитися знання домену, особливо через його конфіденційний і приватний характер. Їх можна консолідувати, а іноді й усунути для FL, заощаджуючи важливий час для навчання та забезпечуючи швидші результати.
Реалізація
Інструменти та бібліотеки FL зросли завдяки широкій підтримці, що спрощує використання FL без важкого підйому. Для початку є багато хороших ресурсів і варіантів фреймворків. Можна послатися на наступне великий перелік найпопулярніших фреймворків та інструментів у сфері FL, в т.ч PySyft, FedML, Квітка, OpenFL, СЛУЖБА, TensorFlow Federated та NVFlare. Він надає список проектів для початківців, які можна швидко розпочати та розвивати.
Ви можете реалізувати хмарний підхід за допомогою Amazon SageMaker який бездоганно працює з Піринг AWS VPC, зберігаючи навчання кожного вузла в приватній підмережі у відповідному VPC та забезпечуючи зв’язок через приватні адреси IPv4. Крім того, модельний хостинг на Amazon SageMaker JumpStart може допомогти, розкриваючи API кінцевої точки без спільного використання ваг моделі.
Це також усуває потенційні високорівневі обчислювальні проблеми з локальним обладнанням Обчислювальна хмара Amazon Elastic (Amazon EC2) ресурси. Ви можете реалізувати клієнт і сервери FL на AWS за допомогою Зошити SageMaker та Служба простого зберігання Amazon (Amazon S3), підтримувати регульований доступ до даних і моделі з Управління ідентифікацією та доступом AWS (IAM) ролі та використання Служба маркерів безпеки AWS (AWS STS) для безпеки на стороні клієнта. Ви також можете створити власну систему для FL за допомогою Amazon EC2.
Для детального огляду впровадження FL за допомогою Квітка фреймворк на SageMaker та обговорення його відмінностей від розподіленого навчання див Машинне навчання з децентралізованими навчальними даними за допомогою федеративного навчання на Amazon SageMaker.
Наступні малюнки ілюструють архітектуру трансферного навчання у Флориді.

Вирішення проблем з даними FL
Інтегроване навчання має свої проблеми з даними, зокрема конфіденційність і безпеку, але їх легко вирішити. По-перше, вам потрібно вирішити проблему неоднорідності даних із даними медичних зображень, які виникають із даних, які зберігаються на різних сайтах і в організаціях-учасниках, відомих як зсув домену проблема (також згадується як зміна клієнта у системі FL), як підкреслено Гуань і Лю в наступному папір. Це може призвести до різниці в конвергенції глобальної моделі.
Інші компоненти, які слід розглянути, включають забезпечення якості та одноманітності даних у джерелі, включення експертних знань у процес навчання, щоб викликати довіру до системи серед медичних працівників, і досягнення точності моделі. Щоб отримати додаткові відомості про деякі потенційні труднощі, з якими ви можете зіткнутися під час впровадження, див папір.
AWS допомагає вам вирішити ці проблеми за допомогою таких функцій, як гнучкі обчислення Amazon EC2 і готові Образи Docker у SageMaker для простого розгортання. Ви можете вирішити проблеми на стороні клієнта, наприклад незбалансовані дані та обчислювальні ресурси для кожної організації вузла. Ви можете вирішувати проблеми навчання на стороні сервера, наприклад атаки отруєння зловмисників за допомогою Віртуальна приватна хмара Amazon (Amazon VPC), групи безпекита інші стандарти безпеки, запобігаючи пошкодженню клієнта та впроваджуючи служби виявлення аномалій AWS.
AWS також допомагає вирішувати проблеми впровадження в реальному світі, які можуть включати проблеми інтеграції, проблеми сумісності з поточними або застарілими системами лікарень і перешкоди адаптації користувачів, пропонуючи гнучкі, прості у використанні та легкі ліфтові технологічні рішення.
За допомогою сервісів AWS ви можете забезпечити широкомасштабне дослідження на основі FL, клінічне впровадження та розгортання, яке може включати різні сайти по всьому світу.
Останні політики щодо сумісності підкреслюють потребу у федеративному навчанні
Багато законів, нещодавно ухвалених урядом, зосереджені на сумісності даних, підтримуючи потребу в міжорганізаційній сумісності даних для розвідки. Це можна зробити за допомогою FL, включаючи фреймворки, такі як TEFCA (Trusted Exchange Framework and Common Agreement) і розширений USCDI (Основні дані США для сумісності).
Запропонована ідея також сприяє ініціативі CDC щодо захоплення та розповсюдження CDC рухається вперед. Наступна цитата зі статті GovCIO Обмін даними та ШІ – головні пріоритети Федерального агентства охорони здоров’я у 2024 році також повторює подібну тему: «Ці можливості також можуть підтримувати громадськість у справедливий спосіб, зустрічаючи пацієнтів там, де вони є, і відкриваючи критично важливий доступ до цих послуг. Велика частина цієї роботи зводиться до даних».
Це може допомогти медичним інститутам і агенціям по всій країні (і по всьому світу) із накопичувачами даних. Вони можуть отримати вигоду від бездоганної та безпечної інтеграції та сумісності даних, що робить медичні дані придатними для ефективного прогнозування на основі машинного навчання та розпізнавання образів. Ви можете почати із зображень, але цей підхід також можна застосувати до всіх EHR. Мета полягає в тому, щоб знайти найкращий підхід для зацікавлених сторін даних із хмарним конвеєром для нормалізації та стандартизації даних або безпосереднього використання їх для FL.
Давайте розглянемо приклад використання. Дані зображень серцевого інсульту та сканування розкидані по всій країні та світі, сидять ізольовано в інститутах, університетах та лікарнях і розділені бюрократичними, географічними та політичними кордонами. Немає єдиного агрегованого джерела та простого способу для медичних працівників (не програмістів) отримати з нього інформацію. У той же час, неможливо навчити моделі ML і DL на цих даних, які могли б допомогти медичним працівникам приймати швидші та точніші рішення в критичні моменти, коли сканування серця може тривати години, а життя пацієнта може бути під загрозою. баланс.
Інші відомі випадки використання включають POTS (Система відстеження онлайн-покупок) на NIH (Національні інститути охорони здоров’я) та кібербезпека для розрізнених і багаторівневих розвідувальних рішень у місцях COMCOM/MAJCOM по всьому світу.
Висновок
Інтегроване навчання має великі перспективи для аналітики та аналізу застарілих даних охорони здоров’я. За допомогою служб AWS легко впровадити хмарне рішення, і FL особливо корисний для медичних організацій із застарілими даними та технічними проблемами. FL може потенційно вплинути на весь цикл лікування, а тепер ще більше, оскільки зосереджено увагу на сумісності даних великих федеральних організацій і урядових лідерів.
Це рішення може допомогти вам уникнути повторного винаходу велосипеда та використовувати новітні технології, щоб зробити стрибок від застарілих систем і бути в авангарді в цьому світі ШІ, що постійно розвивається. Ви також можете стати лідером у сфері найкращих практик і ефективного підходу до сумісності даних усередині та між установами та інститутами в галузі охорони здоров’я та за її межами. Якщо ви є інститутом або агенцією з базами даних, розкиданими по всій країні, ви можете скористатися перевагами цієї бездоганної та безпечної інтеграції.
Вміст і думки в цьому дописі належать сторонньому автору, і AWS не несе відповідальності за зміст або точність цього допису. Кожен клієнт несе відповідальність за визначення, чи підпадає на нього HIPAA, і якщо так, то як найкраще дотримуватися HIPAA та відповідних нормативних актів. Перш ніж використовувати AWS із захищеною інформацією про стан здоров’я, клієнти повинні ввести додаток AWS Business Associate Addendum (BAA) і дотримуватися вимог конфігурації.
Про автора

Нітін Кумар (МС, КМУ) є провідним спеціалістом із обробки даних у T and T Consulting Services, Inc. Він має великий досвід роботи з прототипуванням науково-дослідних розробок, медичною інформатикою, даними державного сектору та взаємодію даних. Він застосовує свої знання передових методів дослідження у федеральному секторі для надання інноваційних технічних документів, POC та MVP. Він працював з кількома федеральними агенціями, щоб просувати їхні цілі щодо даних та ШІ. Інші сфери діяльності Nitin включають обробку природної мови (NLP), конвеєри даних і генеративний штучний інтелект.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/enable-data-sharing-through-federated-learning-a-policy-approach-for-chief-digital-officers/

