Сьогодні клієнти з усіх галузей — будь то фінансові послуги, охорона здоров’я та науки про життя, подорожі та готельний бізнес, засоби масової інформації та розваги, телекомунікації, програмне забезпечення як послуга (SaaS) і навіть постачальники запатентованих моделей — використовують великі мовні моделі (LLM), щоб створювати програми, такі як чат-боти із запитаннями та відповідями (QnA), пошукові системи та бази знань. Ці генеративний ШІ додатки використовуються не лише для автоматизації існуючих бізнес-процесів, але й мають можливість трансформувати досвід клієнтів, які використовують ці додатки. З прогресом, досягнутим у LLMs, як Мікстраль-8х7Б Інструкт, похідна від архітектур, таких як суміш експертів (МО), клієнти постійно шукають способи покращити продуктивність і точність генеративних додатків штучного інтелекту, дозволяючи їм ефективно використовувати більш широкий спектр закритих і відкритих моделей.
Для підвищення точності та продуктивності результатів LLM зазвичай використовується низка методів, наприклад, точне налаштування за допомогою ефективне тонке налаштування параметрів (PEFT), навчання з підкріпленням на основі зворотного зв’язку людини (RLHF), і виконуючи дистиляція знань. Однак, створюючи генеративні додатки ШІ, ви можете використовувати альтернативне рішення, яке дозволяє динамічно включати зовнішні знання та дозволяє вам контролювати інформацію, яка використовується для генерації, без необхідності тонкого налаштування вашої існуючої базової моделі. Ось де на допомогу приходить Retrieval Augmented Generation (RAG), спеціально для генеративних програм штучного інтелекту на відміну від більш дорогих і надійних альтернатив тонкого налаштування, які ми обговорювали. Якщо ви впроваджуєте складні програми RAG у свої щоденні завдання, ви можете зіткнутися з типовими проблемами своїх систем RAG, як-от неточне отримання, збільшення розміру та складності документів і переповнення контексту, що може значно вплинути на якість і надійність згенерованих відповідей. .
У цьому дописі обговорюються шаблони RAG для підвищення точності відповідей за допомогою LangChain і таких інструментів, як засіб отримання батьківського документа, а також такі методи, як контекстне стиснення, щоб розробники могли вдосконалювати існуючі генеративні програми ШІ.
Огляд рішення
У цій публікації ми демонструємо використання генерації тексту Mixtral-8x7B Instruct у поєднанні з моделлю вбудовування BGE Large En для ефективної побудови системи RAG QnA на ноутбуці Amazon SageMaker за допомогою інструменту отримання батьківського документа та техніки контекстного стиснення. Наведена нижче діаграма ілюструє архітектуру цього рішення.
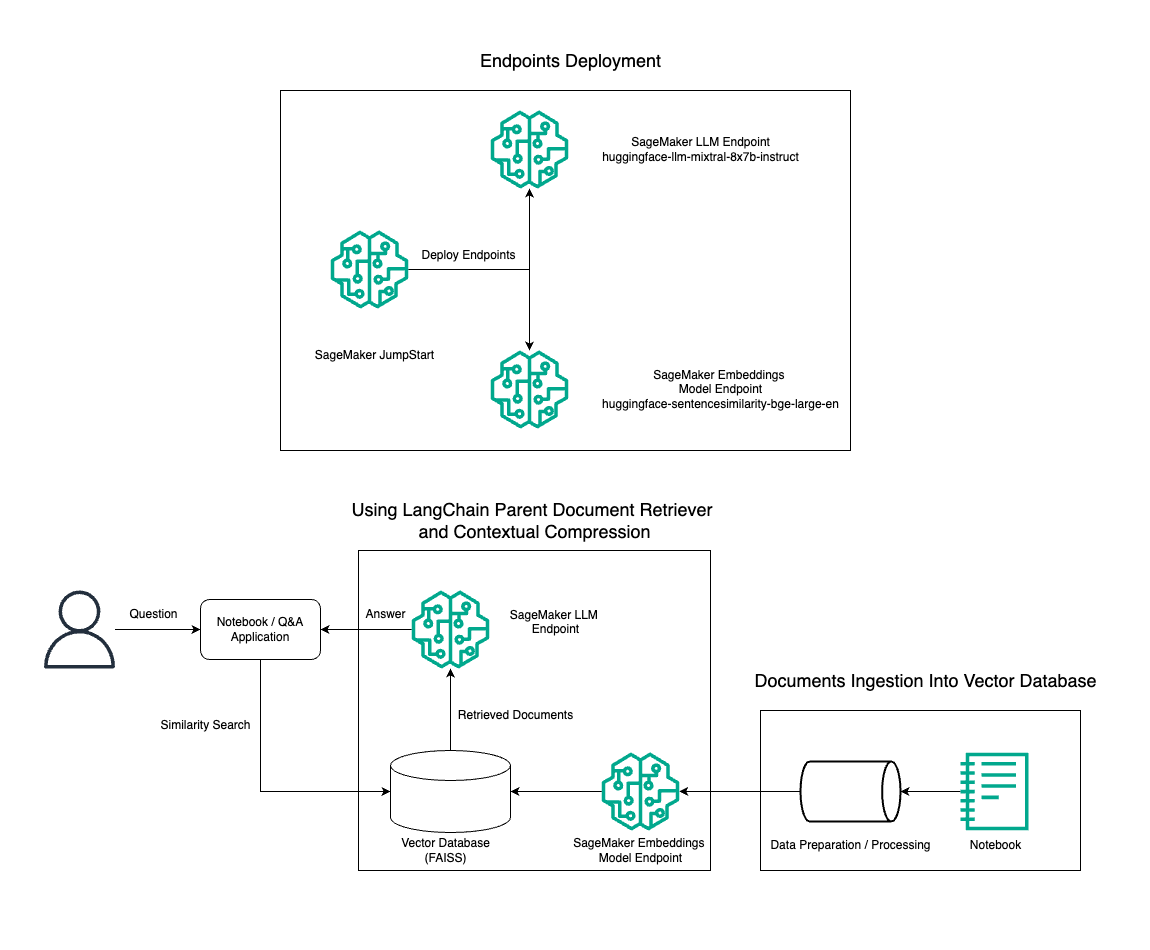
Ви можете розгорнути це рішення лише кількома клацаннями миші за допомогою Amazon SageMaker JumpStart, повністю керована платформа, яка пропонує найсучасніші основні моделі для різних випадків використання, таких як написання вмісту, генерація коду, відповіді на запитання, копірайтинг, узагальнення, класифікація та пошук інформації. Він надає колекцію попередньо навчених моделей, які можна швидко та легко розгортати, прискорюючи розробку та розгортання програм машинного навчання (ML). Одним із ключових компонентів SageMaker JumpStart є Model Hub, який пропонує великий каталог попередньо навчених моделей, таких як Mixtral-8x7B, для різноманітних завдань.
Mixtral-8x7B використовує архітектуру MoE. Ця архітектура дозволяє різним частинам нейронної мережі спеціалізуватися на різних завданнях, ефективно розподіляючи навантаження між кількома експертами. Цей підхід забезпечує ефективне навчання та розгортання більших моделей порівняно з традиційними архітектурами.
Однією з головних переваг архітектури MoE є її масштабованість. Розподіляючи робоче навантаження між кількома експертами, моделі MoE можна навчати на більших наборах даних і досягати кращої продуктивності, ніж традиційні моделі того самого розміру. Крім того, моделі MoE можуть бути більш ефективними під час висновків, оскільки для певного введення потрібно активувати лише підмножину експертів.
Для отримання додаткової інформації про Mixtral-8x7B Instruction on AWS див Mixtral-8x7B тепер доступний в Amazon SageMaker JumpStart. Модель Mixtral-8x7B доступна за дозвільною ліцензією Apache 2.0 для використання без обмежень.
У цій публікації ми обговорюємо, як ви можете використовувати LangChain для створення ефективних і ефективніших додатків RAG. LangChain — це бібліотека Python з відкритим вихідним кодом, призначена для створення додатків з LLM. Він забезпечує модульну та гнучку структуру для поєднання LLM з іншими компонентами, такими як бази знань, пошукові системи та інші інструменти штучного інтелекту, для створення потужних і настроюваних програм.
Ми розповімо про створення конвеєра RAG на SageMaker за допомогою Mixtral-8x7B. Ми використовуємо модель генерації тексту Mixtral-8x7B Instruct із вбудованою моделлю BGE Large En, щоб створити ефективну систему QnA за допомогою RAG на ноутбуці SageMaker. Ми використовуємо екземпляр ml.t3.medium, щоб продемонструвати розгортання LLM через SageMaker JumpStart, доступ до якого можна отримати через створену SageMaker кінцеву точку API. Це налаштування дозволяє досліджувати, експериментувати та оптимізувати передові методи RAG за допомогою LangChain. Ми також ілюструємо інтеграцію сховища FAISS Embedding у робочий процес RAG, підкреслюючи його роль у зберіганні та отриманні вбудовувань для підвищення продуктивності системи.
Ми виконуємо коротку інструкцію з блокнота SageMaker. Для отримання більш детальних і покрокових інструкцій зверніться до Розширені шаблони RAG з Mixtral на репо SageMaker Jumpstart GitHub.
Необхідність розширених шаблонів RAG
Удосконалені шаблони RAG необхідні для вдосконалення поточних можливостей LLM у обробці, розумінні та створенні тексту, схожого на людину. Зі збільшенням розміру та складності документів представлення кількох аспектів документа в одному вбудовуванні може призвести до втрати конкретності. Хоча дуже важливо охопити загальну суть документа, не менш важливо розпізнати та представити різноманітні підконтексти в ньому. Це проблема, з якою ви часто стикаєтеся під час роботи з великими документами. Інша проблема з RAG полягає в тому, що під час пошуку ви не знаєте про конкретні запити, які ваша система зберігання документів оброблятиме після прийому. Це може призвести до того, що інформація, найбільш релевантна запиту, буде прихована під текстом (переповнення контексту). Щоб пом’якшити помилки та покращити існуючу архітектуру RAG, ви можете використовувати розширені шаблони RAG (батьківський засіб пошуку документів і контекстне стиснення), щоб зменшити кількість помилок пошуку, підвищити якість відповідей і забезпечити обробку складних запитань.
За допомогою методів, розглянутих у цій публікації, ви можете вирішувати ключові проблеми, пов’язані із зовнішнім пошуком та інтеграцією знань, дозволяючи вашій програмі надавати більш точні відповіді з урахуванням контексту.
У наступних розділах ми досліджуємо, як це зробити засоби пошуку батьківських документів та контекстне стиснення може допомогти вам вирішити деякі проблеми, які ми обговорювали.
Батьківський засіб пошуку документів
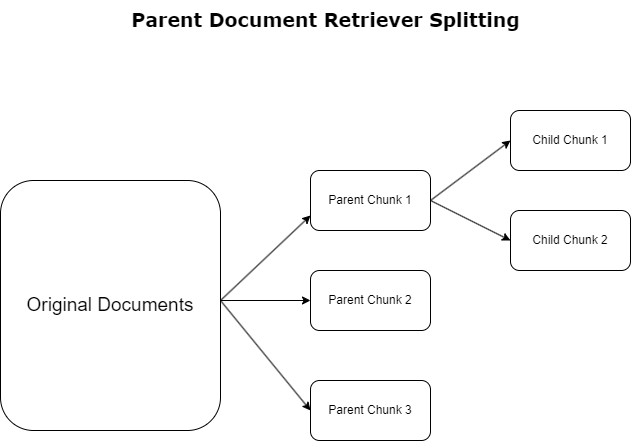
У попередньому розділі ми висвітлили проблеми, з якими стикаються програми RAG під час роботи з великими документами. Щоб вирішити ці проблеми, засоби пошуку батьківських документів класифікувати та позначати вхідні документи як батьківські документи. Ці документи визнаються своїм вичерпним характером, але не використовуються безпосередньо в оригінальній формі для вбудовування. Замість того, щоб стискати весь документ в одне вбудовування, засоби отримання батьківських документів розділяють ці батьківські документи на документи дитини. Кожен дочірній документ охоплює окремі аспекти або теми ширшого батьківського документа. Після ідентифікації цих дочірніх сегментів кожному призначаються окремі вкладення, що відображають їх конкретну тематичну сутність (див. наступну діаграму). Під час пошуку викликається батьківський документ. Ця техніка забезпечує цілеспрямовані, але широкі можливості пошуку, надаючи LLM ширшу перспективу. Засоби отримання батьківських документів надають LLM подвійну перевагу: специфіку вбудовування дочірніх документів для точного й релевантного пошуку інформації в поєднанні з викликом батьківських документів для генерації відповіді, що збагачує результати LLM багатошаровим і повним контекстом.
Контекстне стиснення
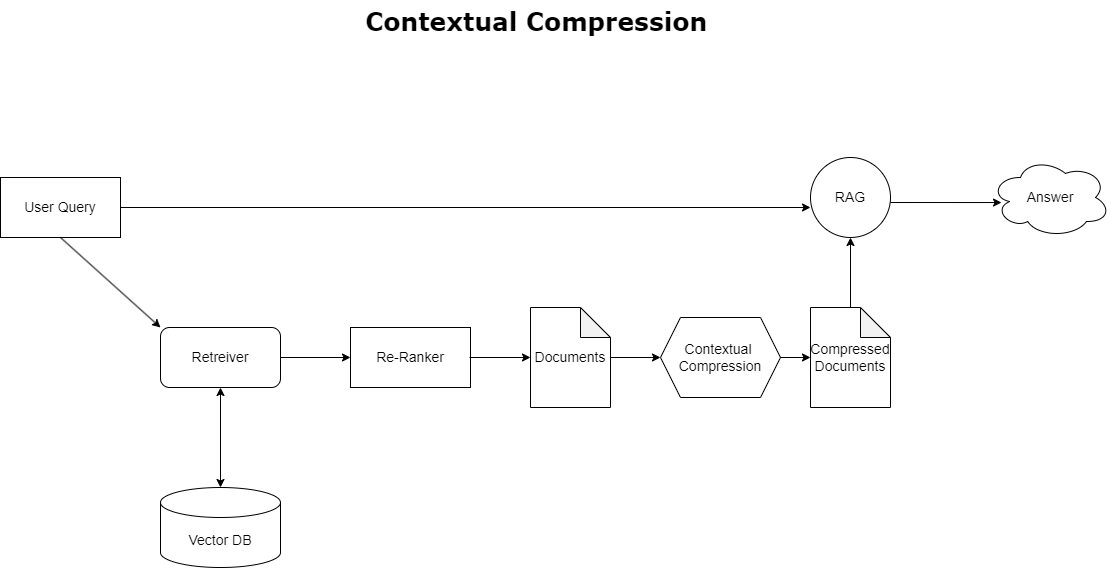
Щоб вирішити проблему переповнення контексту, яку обговорювали раніше, ви можете використовувати контекстне стиснення щоб стискати та фільтрувати отримані документи відповідно до контексту запиту, щоб зберігати та обробляти лише відповідну інформацію. Це досягається за допомогою поєднання базового засобу отримання для початкового отримання документів і компресора документів для вдосконалення цих документів шляхом скорочення їх вмісту або повного виключення на основі релевантності, як показано на наступній діаграмі. Цей спрощений підхід, який підтримується інструментом контекстного стиснення, значно підвищує ефективність застосування RAG, надаючи метод вилучення та використання лише необхідного з маси інформації. Він безпосередньо вирішує проблему перевантаження інформацією та обробки нерелевантних даних, що призводить до покращення якості відповідей, більш рентабельних операцій LLM та більш плавного загального процесу пошуку. По суті, це фільтр, який адаптує інформацію до поточного запиту, що робить його вкрай необхідним інструментом для розробників, які прагнуть оптимізувати свої програми RAG для кращої продуктивності та задоволення користувачів.
Передумови
Якщо ви новачок у SageMaker, зверніться до Посібник із розробки Amazon SageMaker.
Перш ніж почати роботу з рішенням, створити обліковий запис AWS. Коли ви створюєте обліковий запис AWS, ви отримуєте ідентифікатор єдиного входу (SSO), який має повний доступ до всіх служб і ресурсів AWS в обліковому записі. Цей ідентифікатор називається обліковим записом AWS root користувач.
Вхід у систему Консоль управління AWS використовуючи адресу електронної пошти та пароль, які ви використовували для створення облікового запису, ви отримаєте повний доступ до всіх ресурсів AWS у вашому обліковому записі. Ми настійно рекомендуємо вам не використовувати користувача root для повсякденних завдань, навіть адміністративних.
Натомість дотримуйтесь найкращі практики безпеки in Управління ідентифікацією та доступом AWS (IAM), і створити адміністратора користувача та групу. Потім надійно заблокуйте облікові дані користувача root і використовуйте їх для виконання лише кількох завдань керування обліковим записом і службами.
Для моделі Mixtral-8x7b потрібен екземпляр ml.g5.48xlarge. SageMaker JumpStart забезпечує спрощений спосіб доступу та розгортання понад 100 різних моделей основи з відкритим кодом і сторонніх виробників. Щоб запустити кінцеву точку для розміщення Mixtral-8x7B із SageMaker JumpStart, вам може знадобитися подати запит на збільшення квоти служби, щоб отримати доступ до примірника ml.g5.48xlarge для використання кінцевої точки. Ти можеш збільшення квоти обслуговування запитів через консоль, Інтерфейс командного рядка AWS (AWS CLI) або API, щоб дозволити доступ до цих додаткових ресурсів.
Налаштуйте екземпляр блокнота SageMaker і встановіть залежності
Для початку створіть екземпляр блокнота SageMaker і встановіть необхідні залежності. Зверніться до GitHub репо щоб забезпечити успішне налаштування. Після налаштування екземпляра ноутбука можна розгортати модель.
Ви також можете запустити ноутбук локально у бажаному інтегрованому середовищі розробки (IDE). Переконайтеся, що у вас встановлено Jupyter notebook lab.
Розгортання моделі
Розгорніть модель Mixtral-8X7B Instruct LLM на SageMaker JumpStart:
Розгорніть модель вбудовування BGE Large En на SageMaker JumpStart:
Налаштуйте LangChain
Після імпорту всіх необхідних бібліотек і розгортання моделі Mixtral-8x7B і моделі вбудовування BGE Large En тепер ви можете налаштувати LangChain. Щоб отримати покрокові інструкції, див GitHub репо.
Підготовка даних
У цій публікації ми використовуємо кілька років листів Amazon до акціонерів як текстового корпусу для проведення QnA. Щоб отримати докладнішу інформацію щодо підготовки даних, див GitHub репо.
Відповідь на запитання
Коли дані підготовлені, ви можете використовувати оболонку, надану LangChain, яка обертається навколо векторного сховища та приймає вхідні дані для LLM. Ця оболонка виконує такі кроки:
- Візьміть вхідне запитання.
- Створіть вбудовування запитання.
- Отримати відповідні документи.
- Включіть документи та запитання в підказку.
- Викличте модель із підказкою та згенеруйте відповідь у зрозумілій формі.
Тепер, коли векторний магазин готовий, ви можете почати задавати запитання:
Звичайний ретривер ланцюжок
У попередньому сценарії ми досліджували швидкий і простий спосіб отримати контекстно-залежну відповідь на ваше запитання. Тепер давайте розглянемо більш настроюваний параметр за допомогою RetrievalQA, де ви можете налаштувати спосіб додавання отриманих документів до підказки за допомогою параметра chain_type. Крім того, щоб контролювати, скільки відповідних документів потрібно отримати, ви можете змінити параметр k у наступному коді, щоб побачити різні виходи. У багатьох ситуаціях вам може знадобитися знати, які вихідні документи LLM використовував для створення відповіді. Ви можете отримати ці документи на виході за допомогою return_source_documents, який повертає документи, додані до контексту підказки LLM. RetrievalQA також дозволяє надати спеціальний шаблон підказки, який може бути специфічним для моделі.
Задамо питання:
Батьківський ланцюг отримання документів
Давайте розглянемо більш просунутий варіант RAG за допомогою ParentDocumentRetriever. Працюючи з пошуком документів, ви можете зіткнутися з компромісом між зберіганням невеликих фрагментів документа для точного вбудовування та більших документів для збереження більшого контексту. Засіб отримання батьківського документа досягає цього балансу, розділяючи та зберігаючи невеликі фрагменти даних.
Ми використовуємо a parent_splitter розділити оригінальні документи на більші частини, які називаються батьківськими документами та a child_splitter щоб створити менші дочірні документи з вихідних документів:
Потім дочірні документи індексуються у векторному сховищі за допомогою вбудовування. Це забезпечує ефективний пошук відповідних дочірніх документів на основі подібності. Щоб отримати релевантну інформацію, засіб отримання батьківського документа спочатку отримує дочірні документи з векторного сховища. Потім він шукає батьківські ідентифікатори для цих дочірніх документів і повертає відповідні більші батьківські документи.
Задамо питання:
Ланцюжок контекстного стиснення
Давайте розглянемо інший розширений параметр RAG під назвою контекстне стиснення. Однією з проблем із пошуком є те, що зазвичай ми не знаємо, з якими конкретними запитами зіткнеться ваша система зберігання документів, коли ви завантажуєте дані в систему. Це означає, що інформація, найбільш релевантна запиту, може бути прихована в документі з великою кількістю нерелевантного тексту. Передача цього повного документа через вашу заявку може призвести до дорожчих дзвінків LLM і погіршення відповідей.
Засіб контекстного стиснення вирішує проблему отримання відповідної інформації із системи зберігання документів, де відповідні дані можуть бути приховані в документах, що містять багато тексту. Завдяки стисненню та фільтруванню отриманих документів на основі даного контексту запиту повертається лише найбільш відповідна інформація.
Щоб використовувати засіб відновлення контекстного стиснення, вам знадобиться:
- Базовий ретривер – Це початковий засіб отримання, який отримує документи із системи зберігання на основі запиту
- Компресор документів – Цей компонент бере спочатку отримані документи та скорочує їх, зменшуючи вміст окремих документів або повністю видаляючи нерелевантні документи, використовуючи контекст запиту для визначення релевантності
Додавання контекстного стиснення за допомогою екстрактора ланцюга LLM
По-перше, загорніть ваш базовий ретривер в a ContextualCompressionRetriever. Ви додасте LLMChainExtractor, який виконуватиме ітерацію по спочатку повернутих документах і вилучатиме з кожного лише той вміст, який відповідає запиту.
Ініціалізуйте ланцюжок за допомогою ContextualCompressionRetriever з LLMChainExtractor і передайте підказку через chain_type_kwargs аргумент.
Задамо питання:
Фільтруйте документи за допомогою ланцюгового фільтра LLM
Команда LLMChainFilter є трохи простішим, але надійнішим компресором, який використовує ланцюжок LLM, щоб вирішити, які з початково отриманих документів відфільтрувати, а які повернути, без маніпулювання вмістом документа:
Ініціалізуйте ланцюжок за допомогою ContextualCompressionRetriever з LLMChainFilter і передайте підказку через chain_type_kwargs аргумент.
Задамо питання:
Порівняйте результати
У наведеній нижче таблиці порівнюються результати різних запитів на основі техніки.
| Техніка | Запит 1 | Запит 2 | порівняння |
| Як розвивався AWS? | Чому Amazon успішний? | ||
| Звичайний ланцюговий вихід Retriever | AWS (Amazon Web Services) перетворився з спочатку неприбуткової інвестиції в бізнес із річним прибутком у розмірі 85 мільярдів доларів США з високою рентабельністю, пропонуючи широкий спектр послуг і функцій і став значною частиною портфоліо Amazon. Незважаючи на скептицизм і короткострокові труднощі, AWS продовжувала впроваджувати інновації, залучати нових клієнтів і переміщувати активних клієнтів, пропонуючи такі переваги, як гнучкість, інновації, економічність і безпека. AWS також розширила свої довгострокові інвестиції, включаючи розробку чіпів, щоб надати нові можливості та змінити те, що можливо для своїх клієнтів. | Amazon досяг успіху завдяки постійним інноваціям і розширенню в нових сферах, таких як послуги технологічної інфраструктури, цифрові пристрої для читання, персональні помічники з голосовим керуванням і нові бізнес-моделі, такі як сторонній ринок. Його здатність швидко масштабувати операції, про що свідчить швидке розширення його транспортних мереж, також сприяє його успіху. Крім того, зосередження Amazon на оптимізації та підвищенні ефективності процесів призвело до підвищення продуктивності та скорочення витрат. Приклад Amazon Business підкреслює здатність компанії використовувати переваги електронної комерції та логістики в різних секторах. | Грунтуючись на відповідях звичайного ланцюжка ретриверів, ми помітили, що хоча він і надає довгі відповіді, він страждає від переповнення контексту та не згадує жодних важливих деталей із корпусу щодо відповіді на наданий запит. Звичайний ланцюжок пошуку не в змозі вловити нюанси з глибиною або контекстним розумінням, потенційно пропускаючи критичні аспекти документа. |
| Вихідний вихід батьківського документа | AWS (Amazon Web Services) розпочався з початкового запуску служби Elastic Compute Cloud (EC2) у 2006 році з низькими можливостями, забезпечуючи лише один розмір екземпляра, в одному центрі обробки даних, в одному регіоні світу, лише з екземплярами операційної системи Linux , і без багатьох ключових функцій, таких як моніторинг, балансування навантаження, автоматичне масштабування або постійне зберігання. Однак успіх AWS дозволив їм швидко ітерувати та додавати відсутні можливості, зрештою розширити, щоб запропонувати різні смаки, розміри та оптимізацію обчислень, зберігання та мереж, а також розробити власні мікросхеми (Graviton), щоб ще більше підвищити ціну та продуктивність. . Ітеративний інноваційний процес AWS вимагав значних інвестицій у фінансові та людські ресурси протягом 20 років, часто задовго до моменту виплати, щоб задовольнити потреби клієнтів і покращити довгостроковий досвід клієнтів, лояльність і прибутки для акціонерів. | Amazon досяг успіху завдяки своїй здатності постійно впроваджувати інновації, адаптуватися до мінливих умов ринку та задовольняти потреби клієнтів у різних сегментах ринку. Це очевидно в успіху Amazon Business, який виріс до приблизно 35 мільярдів доларів річного валового обсягу продажів завдяки забезпеченню вибору, цінності та зручності для бізнес-клієнтів. Інвестиції Amazon в електронну комерцію та логістичні можливості також дозволили створити такі сервіси, як Buy with Prime, який допомагає торговцям із веб-сайтами, орієнтованими безпосередньо на споживача, збільшувати кількість переглядів до покупок. | Батьківський засіб отримання документів глибше вивчає специфіку стратегії зростання AWS, включаючи ітеративний процес додавання нових функцій на основі відгуків клієнтів і детальний шлях від початкового запуску з бідними функціями до домінуючої позиції на ринку, водночас надаючи реакцію з багатим контекстом. . Відповіді охоплюють широкий спектр аспектів, від технічних інновацій і ринкової стратегії до організаційної ефективності та орієнтації на клієнта, надаючи цілісне уявлення про фактори, що сприяють успіху, разом із прикладами. Це можна пояснити цілеспрямованими, але широкими можливостями пошуку батьківського документа. |
| LLM Chain Extractor: вивід контекстного стиснення | AWS розвинувся, починаючи як невеликий проект всередині Amazon, що вимагав значних капіталовкладень і зіткнувся зі скептицизмом як з боку компанії, так і ззовні. Однак AWS мала перевагу перед потенційними конкурентами та вірила в користь, яку вона може принести клієнтам і Amazon. AWS узяла на себе довгострокове зобов’язання продовжувати інвестиції, в результаті чого у 3,300 році було запущено понад 2022 нових функцій і послуг. AWS змінила спосіб керування клієнтами своєю технологічною інфраструктурою та стала підприємством із річним доходом у розмірі 85 мільярдів доларів із високою прибутковістю. AWS також постійно вдосконалює свої пропозиції, наприклад, покращуючи EC2 додатковими функціями та послугами після його першого запуску. | Виходячи з наданого контексту, успіх Amazon можна пояснити його стратегічним розширенням із платформи продажу книг на глобальний ринок із жвавою екосистемою сторонніх продавців, ранніми інвестиціями в AWS, інноваціями у впровадженні Kindle і Alexa та значним зростанням у річному доході з 2019 по 2022 рік. Це зростання призвело до розширення площі центрів фулфілменту, створення транспортної мережі останньої милі та побудови нової мережі сортувальних центрів, які були оптимізовані для продуктивності та зниження витрат. | Екстрактор ланцюга LLM підтримує баланс між повним охопленням ключових моментів і уникненням непотрібної глибини. Він динамічно пристосовується до контексту запиту, тому результат є безпосередньо релевантним і вичерпним. |
| LLM Chain Filter: контекстне стиснення | AWS (Amazon Web Services) розвивався, спочатку запускаючи бідні функції, але швидко ітеруючи на основі відгуків клієнтів, щоб додати необхідні можливості. Цей підхід дозволив AWS запустити EC2 у 2006 році з обмеженими можливостями, а потім постійно додавати нові функції, такі як додаткові розміри екземплярів, центри обробки даних, регіони, параметри операційної системи, інструменти моніторингу, балансування навантаження, автоматичне масштабування та постійне зберігання. Згодом AWS перетворився з малофункціонального сервісу на багатомільярдний бізнес, зосередившись на потребах клієнтів, гнучкості, інноваціях, економічній ефективності та безпеці. Зараз AWS має річний дохід у розмірі 85 мільярдів доларів США та пропонує понад 3,300 нових функцій і послуг щороку, обслуговуючи широке коло клієнтів від стартапів до транснаціональних компаній і організацій державного сектору. | Amazon досяг успіху завдяки своїм інноваційним бізнес-моделям, постійному технологічному прогресу та стратегічним організаційним змінам. Компанія постійно підриває традиційні індустрії, представляючи нові ідеї, такі як платформа електронної комерції для різноманітних продуктів і послуг, сторонній ринок, сервіси хмарної інфраструктури (AWS), електронний рідер Kindle і голосовий персональний помічник Alexa. . Крім того, Amazon внесла структурні зміни, щоб підвищити свою ефективність, наприклад реорганізувала свою мережу доставки в США, щоб зменшити витрати та терміни доставки, що ще більше сприяло її успіху. | Подібно до екстрактора ланцюжків LLM, фільтр ланцюгів LLM гарантує, що незважаючи на охоплення ключових моментів, результат буде ефективним для клієнтів, які шукають стислі та контекстуальні відповіді. |
Порівнюючи ці різні техніки, ми бачимо, що в таких контекстах, як деталізація переходу AWS від простого сервісу до складної, багатомільярдної організації, або пояснення стратегічних успіхів Amazon, звичайному ланцюжку ретриверів бракує точності, яку пропонують більш складні методи, що призводить до менш цілеспрямованої інформації. Хоча між обговорюваними просунутими техніками помітно дуже мало відмінностей, вони набагато інформативніші, ніж звичайні ланцюги ретриверів.
Для клієнтів у таких галузях, як охорона здоров’я, телекомунікації та фінансові послуги, які прагнуть застосувати RAG у своїх програмах, обмеження звичайного ланцюжка отримання даних щодо забезпечення точності, уникнення надмірності та ефективного стиснення інформації роблять його менш придатним для задоволення цих потреб порівняно з до більш просунутих методів пошуку батьківських документів і контекстного стиснення. Ці методи здатні дистилювати величезні обсяги інформації в концентровану, вражаючу інформацію, яка вам потрібна, одночасно допомагаючи покращити співвідношення ціни та ефективності.
Прибирати
Коли ви закінчите працювати з блокнотом, видаліть створені вами ресурси, щоб уникнути нарахування плати за ресурси, що використовуються:
Висновок
У цьому дописі ми представили рішення, яке дозволяє реалізувати прийом батьківського документа та методи ланцюжка контекстного стиснення, щоб покращити здатність LLM обробляти та генерувати інформацію. Ми випробували ці передові методи RAG за допомогою моделей Mixtral-8x7B Instruct і BGE Large En, доступних із SageMaker JumpStart. Ми також досліджували використання постійного сховища для вбудовування та фрагментів документів та інтеграцію з корпоративними сховищами даних.
Техніки, які ми застосували, не лише вдосконалюють спосіб доступу моделей LLM до зовнішніх знань і врахування їх, а й значно покращують якість, релевантність та ефективність їхніх результатів. Поєднуючи пошук із великих текстових корпусів із можливостями генерації мови, ці передові методи RAG дозволяють LLM-ам створювати більш фактичні, узгоджені та відповідні контексту відповіді, підвищуючи їх продуктивність у різних завданнях обробки природної мови.
SageMaker JumpStart є центром цього рішення. Завдяки SageMaker JumpStart ви отримуєте доступ до широкого асортименту моделей із відкритим і закритим кодом, що спрощує процес початку роботи з машинним навчанням і забезпечує швидке експериментування та розгортання. Щоб розпочати розгортання цього рішення, перейдіть до блокнота в GitHub репо.
Про авторів
 Ніітхійн Віджеасваран є архітектором рішень в AWS. Його сфера уваги — генеративний ШІ та прискорювачі ШІ AWS. Має ступінь бакалавра комп’ютерних наук та біоінформатики. Niithiyn тісно співпрацює з командою Generative AI GTM, щоб допомогти клієнтам AWS працювати на багатьох фронтах і прискорити впровадження генеративного ШІ. Він затятий фанат Dallas Mavericks і любить колекціонувати кросівки.
Ніітхійн Віджеасваран є архітектором рішень в AWS. Його сфера уваги — генеративний ШІ та прискорювачі ШІ AWS. Має ступінь бакалавра комп’ютерних наук та біоінформатики. Niithiyn тісно співпрацює з командою Generative AI GTM, щоб допомогти клієнтам AWS працювати на багатьох фронтах і прискорити впровадження генеративного ШІ. Він затятий фанат Dallas Mavericks і любить колекціонувати кросівки.
 Себастьян Бустільо є архітектором рішень в AWS. Він зосереджується на технологіях AI/ML з глибокою пристрастю до генеративного AI та прискорювачів обчислень. В AWS він допомагає клієнтам розкрити цінність бізнесу за допомогою генеративного штучного інтелекту. Коли він не на роботі, він із задоволенням варить ідеальну чашку спеціальної кави та досліджує світ зі своєю дружиною.
Себастьян Бустільо є архітектором рішень в AWS. Він зосереджується на технологіях AI/ML з глибокою пристрастю до генеративного AI та прискорювачів обчислень. В AWS він допомагає клієнтам розкрити цінність бізнесу за допомогою генеративного штучного інтелекту. Коли він не на роботі, він із задоволенням варить ідеальну чашку спеціальної кави та досліджує світ зі своєю дружиною.
 Армандо Діаз є архітектором рішень в AWS. Він зосереджується на генеративному ШІ, ШІ/ML та аналізі даних. В AWS Армандо допомагає клієнтам інтегрувати передові генеративні можливості штучного інтелекту в їхні системи, сприяючи інноваціям і конкурентній перевагі. Коли він не на роботі, він із задоволенням проводить час із дружиною та родиною, ходить у походи та подорожує світом.
Армандо Діаз є архітектором рішень в AWS. Він зосереджується на генеративному ШІ, ШІ/ML та аналізі даних. В AWS Армандо допомагає клієнтам інтегрувати передові генеративні можливості штучного інтелекту в їхні системи, сприяючи інноваціям і конкурентній перевагі. Коли він не на роботі, він із задоволенням проводить час із дружиною та родиною, ходить у походи та подорожує світом.
 Доктор Фарук Сабір є старшим архітектором рішень зі штучного інтелекту та машинного навчання в AWS. Він має ступінь доктора філософії та магістра з електротехніки в Техаському університеті в Остіні та ступінь магістра з комп’ютерних наук у Технологічному інституті Джорджії. Він має понад 15 років досвіду роботи, а також любить навчати та наставляти студентів коледжу. В AWS він допомагає клієнтам формулювати та вирішувати їхні бізнес-проблеми в області обробки даних, машинного навчання, комп’ютерного зору, штучного інтелекту, чисельної оптимізації та пов’язаних областях. Живучи в Далласі, штат Техас, він і його сім’я люблять подорожувати та їздити в далекі подорожі.
Доктор Фарук Сабір є старшим архітектором рішень зі штучного інтелекту та машинного навчання в AWS. Він має ступінь доктора філософії та магістра з електротехніки в Техаському університеті в Остіні та ступінь магістра з комп’ютерних наук у Технологічному інституті Джорджії. Він має понад 15 років досвіду роботи, а також любить навчати та наставляти студентів коледжу. В AWS він допомагає клієнтам формулювати та вирішувати їхні бізнес-проблеми в області обробки даних, машинного навчання, комп’ютерного зору, штучного інтелекту, чисельної оптимізації та пов’язаних областях. Живучи в Далласі, штат Техас, він і його сім’я люблять подорожувати та їздити в далекі подорожі.
 Марко Пуніо є архітектором рішень, який зосереджується на генеративній стратегії ШІ, прикладних рішеннях ШІ та проводить дослідження, щоб допомогти клієнтам гіпермасштабувати AWS. Марко — консультант із цифрових хмарних технологій із досвідом роботи у сферах фінансових технологій, охорони здоров’я та біологічних наук, програмного забезпечення як послуги, а нещодавно — у галузях телекомунікацій. Він кваліфікований технолог із пристрастю до машинного навчання, штучного інтелекту та злиття та поглинання. Марко живе в Сіетлі, штат Вашингтон, і у вільний час любить писати, читати, займатися спортом і створювати програми.
Марко Пуніо є архітектором рішень, який зосереджується на генеративній стратегії ШІ, прикладних рішеннях ШІ та проводить дослідження, щоб допомогти клієнтам гіпермасштабувати AWS. Марко — консультант із цифрових хмарних технологій із досвідом роботи у сферах фінансових технологій, охорони здоров’я та біологічних наук, програмного забезпечення як послуги, а нещодавно — у галузях телекомунікацій. Він кваліфікований технолог із пристрастю до машинного навчання, штучного інтелекту та злиття та поглинання. Марко живе в Сіетлі, штат Вашингтон, і у вільний час любить писати, читати, займатися спортом і створювати програми.
 AJ Dhimine є архітектором рішень в AWS. Він спеціалізується на генеративному штучному інтелекті, безсерверних обчисленнях і аналітиці даних. Він є активним членом/наставником спільноти машинного навчання Technical Field Community і опублікував кілька наукових статей на різні теми AI/ML. Він працює з клієнтами, починаючи від стартапів і закінчуючи підприємствами, над розробкою генеративних рішень ШІ AWSome. Він особливо захоплений використанням великих мовних моделей для розширеної аналітики даних і дослідженням практичних застосувань, які вирішують проблеми реального світу. Поза роботою Ей Джей любить подорожувати, і зараз він у 53 країнах з метою відвідати всі країни світу.
AJ Dhimine є архітектором рішень в AWS. Він спеціалізується на генеративному штучному інтелекті, безсерверних обчисленнях і аналітиці даних. Він є активним членом/наставником спільноти машинного навчання Technical Field Community і опублікував кілька наукових статей на різні теми AI/ML. Він працює з клієнтами, починаючи від стартапів і закінчуючи підприємствами, над розробкою генеративних рішень ШІ AWSome. Він особливо захоплений використанням великих мовних моделей для розширеної аналітики даних і дослідженням практичних застосувань, які вирішують проблеми реального світу. Поза роботою Ей Джей любить подорожувати, і зараз він у 53 країнах з метою відвідати всі країни світу.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/advanced-rag-patterns-on-amazon-sagemaker/

