За останні кілька років великі мовні моделі (LLM) стали відомими як видатні інструменти, здатні розуміти, генерувати та маніпулювати текстом з безпрецедентною майстерністю. Їх потенційні застосування охоплюють від розмовних агентів до створення контенту та пошуку інформації, обіцяючи революцію в усіх галузях. Однак використання цього потенціалу, забезпечуючи відповідальне та ефективне використання цих моделей, залежить від критичного процесу оцінювання LLM. Оцінка – це завдання, яке використовується для вимірювання якості та відповідальності результату LLM або генеративної служби AI. Оцінка LLM мотивується не лише бажанням зрозуміти продуктивність моделі, але й необхідністю впровадження відповідального штучного інтелекту та необхідністю пом’якшити ризик надання дезінформації чи упередженого вмісту та мінімізувати створення шкідливого, небезпечного, зловмисного та неетичного вміст. Крім того, оцінка LLM також може допомогти зменшити ризики безпеки, особливо в контексті оперативного підроблення даних. Для додатків на базі LLM надзвичайно важливо визначити вразливі місця та впровадити засоби захисту від можливих порушень і несанкціонованих маніпуляцій з даними.
Надаючи основні інструменти для оцінки LLM із простою конфігурацією та підходом в один клік, Роз'яснити Amazon SageMaker Можливості оцінювання LLM надають клієнтам доступ до більшості вищезгаданих переваг. Маючи в руках ці інструменти, наступним завданням є інтеграція оцінювання LLM у життєвий цикл машинного навчання та експлуатації (MLOps) для досягнення автоматизації та масштабованості процесу. У цій публікації ми покажемо вам, як інтегрувати оцінювання Amazon SageMaker Clarify LLM із Amazon SageMaker Pipelines, щоб увімкнути масштабне оцінювання LLM. Крім того, ми надаємо приклад коду GitHub репозиторій, щоб дозволити користувачам проводити паралельну багатомодельну оцінку в масштабі, використовуючи такі приклади, як Llama2-7b-f, Falcon-7b і точно налаштовані моделі Llama2-7b.
Кому необхідно проводити оцінювання LLM?
Будь-хто, хто тренується, налаштовує або просто використовує попередньо підготовлений LLM, повинен точно оцінити його, щоб оцінити поведінку програми, що працює на цьому LLM. Виходячи з цього принципу, ми можемо класифікувати генеративних користувачів штучного інтелекту, яким потрібні можливості оцінювання LLM, на 3 групи, як показано на наступному малюнку: постачальники моделей, спеціалісти з тонкого налаштування та споживачі.

- Постачальники базової моделі (FM). моделі поїздів загального призначення. Ці моделі можна використовувати для багатьох подальших завдань, таких як вилучення функцій або створення вмісту. Кожна навчена модель потребує порівняння з багатьма завданнями не лише для оцінки її продуктивності, але й для порівняння з іншими існуючими моделями, для виявлення областей, які потребують вдосконалення, і, нарешті, для відстеження досягнень у галузі. Постачальники моделей також повинні перевірити наявність будь-яких упереджень, щоб переконатися в якості початкового набору даних і правильної поведінки своєї моделі. Збір оціночних даних життєво важливий для постачальників моделей. Крім того, ці дані та показники необхідно збирати, щоб відповідати майбутнім нормам. ISO 42001, Розпорядження адміністрації Байдена та Закон ЄС про ШІ розробити стандарти, інструменти та тести, щоб переконатися, що системи штучного інтелекту є безпечними, безпечними та надійними. Наприклад, Закон ЄС про штучний інтелект містить завдання надавати інформацію про те, які набори даних використовуються для навчання, яка обчислювальна потужність потрібна для запуску моделі, звітувати про результати моделі за загальнодоступними/галузевими стандартами та ділитися результатами внутрішнього та зовнішнього тестування.
- Model тонкі настройки хочуть розв’язувати конкретні завдання (наприклад, класифікацію настроїв, підсумовування, відповіді на запитання), а також попередньо підготовлені моделі для прийняття предметних завдань. Їм потрібні оціночні показники, створені постачальниками моделей, щоб вибрати правильну попередньо навчену модель як відправну точку.
Їм потрібно оцінити свої точно налаштовані моделі на відповідність бажаному сценарію використання з наборами даних для конкретного завдання або домену. Часто їм доводиться керувати та створювати свої приватні набори даних, оскільки загальнодоступні набори даних, навіть ті, що розроблені для конкретного завдання, можуть недостатньо відобразити нюанси, необхідні для їх конкретного випадку використання.
Тонка настройка є швидшою та дешевшою, ніж повне навчання, і вимагає швидшої оперативної ітерації для розгортання та тестування, оскільки зазвичай генерується багато моделей-кандидатів. Оцінка цих моделей дозволяє постійно вдосконалювати моделі, калібрувати та налагоджувати. Зауважте, що спеціалісти з тонкого налаштування можуть стати споживачами власних моделей, коли вони розробляють додатки реального світу. - Model споживачів або розгортачі моделей обслуговують і контролюють загальні або точно налаштовані моделі у виробництві, прагнучи покращити свої додатки чи послуги шляхом прийняття LLM. Перше завдання, яке вони мають, полягає в тому, щоб переконатися, що обраний LLM відповідає їхнім конкретним потребам, вартості та очікуванням продуктивності. Інтерпретація та розуміння результатів моделі є постійною проблемою, особливо коли йдеться про конфіденційність і безпеку даних (наприклад, для аудиту ризиків і відповідності в регульованих галузях, таких як фінансовий сектор). Безперервна оцінка моделі має вирішальне значення для запобігання поширенню упередженого чи шкідливого вмісту. Впроваджуючи надійну структуру моніторингу та оцінки, споживачі моделей можуть проактивно виявляти та усувати регресію в LLMs, гарантуючи, що ці моделі зберігають свою ефективність і надійність з часом.
Як провести оцінку LLM
Ефективна оцінка моделі включає три фундаментальні компоненти: одну або більше FM або точно налаштованих моделей для оцінки вхідних наборів даних (підказки, бесіди або регулярні вхідні дані) і логіку оцінювання.
Щоб вибрати моделі для оцінки, необхідно враховувати різні фактори, включаючи характеристики даних, складність проблеми, доступні обчислювальні ресурси та бажаний результат. Вхідне сховище даних надає дані, необхідні для навчання, тонкої настройки та тестування обраної моделі. Важливо, щоб це сховище даних було добре структурованим, репрезентативним і високоякісним, оскільки продуктивність моделі значною мірою залежить від даних, з яких вона навчається. Нарешті, логіка оцінювання визначає критерії та показники, які використовуються для оцінки ефективності моделі.
Разом ці три компоненти утворюють цілісну структуру, яка забезпечує ретельну та систематичну оцінку моделей машинного навчання, що зрештою призводить до обґрунтованих рішень і підвищення ефективності моделі.
Методи модельного оцінювання все ще активно досліджуються. Спільнота дослідників за останні кілька років створила багато загальнодоступних орієнтирів і платформ для вирішення широкого кола завдань і сценаріїв, таких як КЛЕЙ, Суперклей, КЛЕМ, MMLU та BIG-лавка. Ці тести мають таблиці лідерів, які можна використовувати для порівняння та порівняння оцінених моделей. Порівняльні показники, як-от HELM, також спрямовані на оцінку показників, окрім показників точності, як-от точність або оцінка F1. Еталонний тест HELM включає показники справедливості, упередженості та токсичності, які мають однакове важливе значення в загальній оцінці моделі.
Усі ці тести включають набір показників, які вимірюють, як модель виконує певне завдання. Найбільш відомі і найпоширеніші метрики ЧЕРВОНИЙ (Орієнтоване на пригадування дослідження для оцінки суті), СИНІЙ (BiLingual Evaluation Understudy), або METEOR (Метрика для оцінки перекладу з явним упорядкуванням). Ці показники служать корисним інструментом для автоматизованого оцінювання, надаючи кількісні показники лексичної подібності між створеним і довідковим текстом. Однак вони не охоплюють повної широти створення людської мови, яка включає семантичне розуміння, контекст або стилістичні нюанси. Наприклад, HELM не надає деталі оцінки, що стосуються конкретних випадків використання, рішень для тестування користувальницьких підказок і легко інтерпретованих результатів, які використовуються неекспертами, оскільки процес може бути дорогим, нелегким для масштабування та лише для конкретних завдань.
Крім того, досягнення генерації мови, схожої на людину, часто вимагає включення людини в цикл, щоб забезпечити якісні оцінки та людське судження, щоб доповнити автоматизовані показники точності. Людське оцінювання є цінним методом для оцінювання результатів LLM, але воно також може бути суб’єктивним і схильним до упередженості, оскільки різні оцінювачі можуть мати різні думки та тлумачення якості тексту. Крім того, людська оцінка може бути ресурсомісткою та дорогою, а також може потребувати значного часу та зусиль.
Давайте глибше зануримося в те, як Amazon SageMaker Clarify плавно поєднує крапки, допомагаючи клієнтам проводити ретельну оцінку та вибір моделі.
Оцінка LLM за допомогою Amazon SageMaker Clarify
Amazon SageMaker Clarify допомагає клієнтам автоматизувати показники, включаючи, але не обмежуючись, точність, надійність, токсичність, стереотипи та фактичні знання для автоматизації, а також стиль, узгодженість, релевантність для людського оцінювання та методи оцінювання, забезпечуючи структуру для оцінки LLMs і послуги на основі LLM, такі як Amazon Bedrock. Будучи повністю керованим сервісом, SageMaker Clarify спрощує використання фреймворків оцінки з відкритим кодом в Amazon SageMaker. Клієнти можуть вибрати відповідні набори даних і показники оцінки для своїх сценаріїв і розширити їх за допомогою власних наборів швидких даних і алгоритмів оцінки. SageMaker Clarify надає результати оцінювання в різних форматах для підтримки різних ролей у робочому процесі LLM. Науковці даних можуть аналізувати детальні результати за допомогою візуалізацій SageMaker Clarify у блокнотах, картках моделей SageMaker і звітах у форматі PDF. Водночас оперативні команди можуть використовувати Amazon SageMaker GroundTruth для перегляду та анотування елементів високого ризику, які ідентифікує SageMaker Clarify. Наприклад, через стереотипи, токсичність, уникнення ідентифікаційної інформації або низьку точність.
Анотації та навчання з підкріпленням згодом використовуються для зменшення потенційних ризиків. Зручні для людини пояснення виявлених ризиків прискорюють процес перевірки вручну, тим самим зменшуючи витрати. Зведені звіти пропонують зацікавленим сторонам порівняльні показники між різними моделями та версіями, сприяючи прийняттю обґрунтованих рішень.
На наступному малюнку показано структуру для оцінки LLM і послуг на основі LLM:

Оцінка LLM від Amazon SageMaker Clarify — це бібліотека Foundation Model Evaluation (FMEval) із відкритим кодом, розроблена AWS, щоб допомогти клієнтам легко оцінювати LLM. Усі функції також включено в Amazon SageMaker Studio, щоб користувачі могли оцінювати LLM. У наступних розділах ми представляємо інтеграцію можливостей оцінювання Amazon SageMaker Clarify LLM із SageMaker Pipelines, щоб уможливити масштабне оцінювання LLM за допомогою принципів MLOps.
Життєвий цикл Amazon SageMaker MLOps
Як пост "Основна дорожня карта MLOps для підприємств із Amazon SageMaker” описує, MLOps – це поєднання процесів, людей і технологій для ефективного створення випадків використання ML.
На наступному малюнку показано наскрізний життєвий цикл MLOps:

Типова подорож починається із того, що фахівець із обробки даних створює блокнот із підтвердженням концепції (PoC), щоб довести, що машинне навчання може вирішити бізнес-проблему. Під час розробки Proof of Concept (PoC) досліднику даних належить перетворити ключові показники ефективності бізнесу (KPI) у показники моделі машинного навчання, такі як точність або хибнопозитивний рівень, і використовувати обмежений набір тестових даних для їх оцінки. метрики. Науковці даних співпрацюють з інженерами ML для перенесення коду з ноутбуків у сховища, створюючи конвеєри ML за допомогою Amazon SageMaker Pipelines, які з’єднують різні етапи обробки та завдання, включаючи попередню обробку, навчання, оцінку та постобробку, і все це при постійному впровадженні нової продукції. даних. Розгортання Amazon SageMaker Pipelines залежить від взаємодії репозиторію та активації конвеєра CI/CD. Конвеєр ML зберігає найефективніші моделі, зображення контейнерів, результати оцінювання та інформацію про стан у реєстрі моделей, де зацікавлені сторони моделі оцінюють продуктивність і приймають рішення про перехід до виробництва на основі результатів продуктивності та контрольних показників, після чого активується інший конвеєр CI/CD для постановки та розгортання виробництва. Потрапивши у виробництво, споживачі ML використовують модель за допомогою висновків, ініційованих програмою, шляхом прямого виклику або викликів API, із циклами зворотного зв’язку з власниками моделі для поточної оцінки ефективності.
Інтеграція Amazon SageMaker Clarify та MLOps
Після життєвого циклу MLOps спеціалісти з тонкого налаштування або користувачі моделей із відкритим вихідним кодом створюють точно налаштовані моделі або FM за допомогою служб Amazon SageMaker Jumpstart і MLOps, як описано в розділі Впровадження практик MLOps за допомогою попередньо навчених моделей Amazon SageMaker JumpStart. Це призвело до створення нового домену для операцій базової моделі (FMOps) і LLM Operations (LLMOps). FMOps/LLMOps: реалізуйте генеративний ШІ та відмінності з MLOps.
На наступному малюнку показано наскрізний життєвий цикл LLMOps:
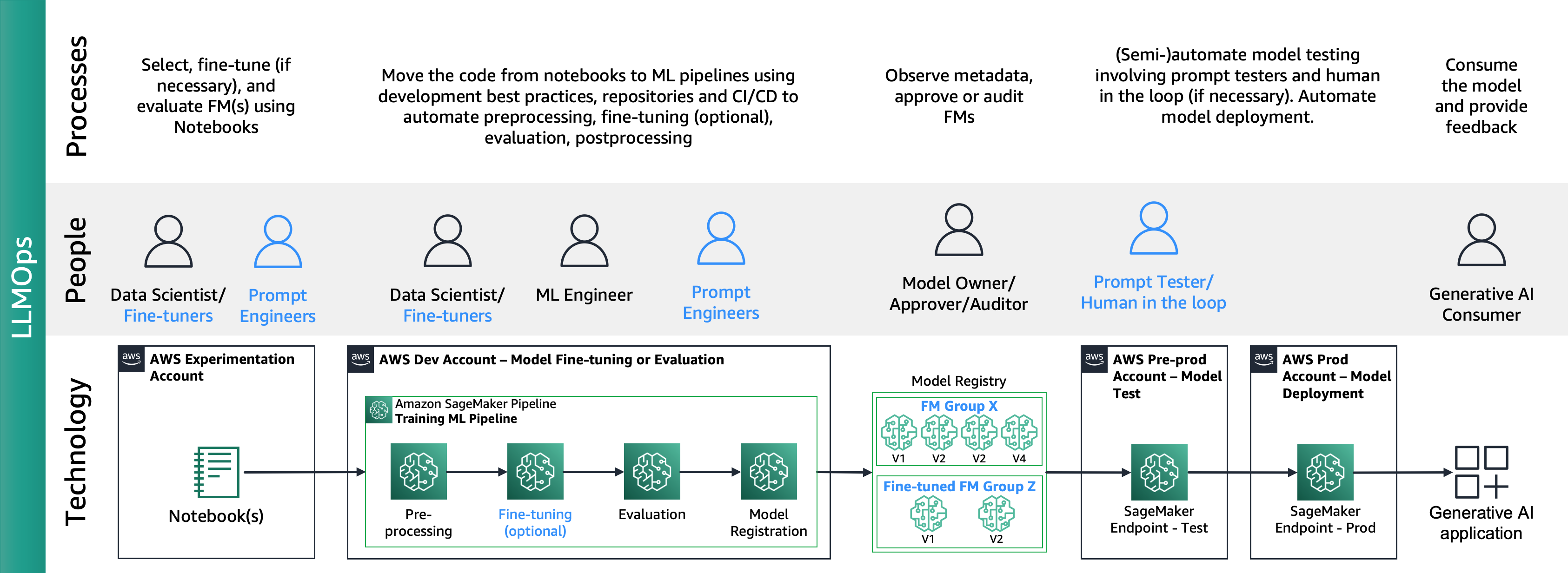
У LLMOps основні відмінності порівняно з MLOps полягають у виборі моделі та оцінці моделі, що включає різні процеси та показники. На початковому етапі експерименту дослідники даних (або спеціалісти з точного налаштування) вибирають FM, який використовуватиметься для конкретного випадку використання Generative AI.
Це часто призводить до тестування та точного налаштування кількох FM, деякі з яких можуть дати порівняльні результати. Після вибору моделі (моделей) інженери підказок несуть відповідальність за підготовку необхідних вхідних даних і очікуваних вихідних даних для оцінки (наприклад, вхідні підказки, що містять вхідні дані та запит) і визначають такі показники, як подібність і токсичність. На додаток до цих показників спеціалісти з обробки даних або спеціалісти з точного налаштування повинні перевірити результати та вибрати відповідний FM не лише за показниками точності, але й за іншими можливостями, такими як затримка та вартість. Потім вони можуть розгорнути модель на кінцевій точці SageMaker і перевірити її продуктивність у невеликому масштабі. Хоча етап експериментування може включати простий процес, перехід до виробництва вимагає від клієнтів автоматизації процесу та підвищення надійності рішення. Тому нам потрібно глибоко зануритися в те, як автоматизувати оцінювання, дозволяючи тестувальникам виконувати ефективне оцінювання в масштабі та реалізовуючи моніторинг вхідних і вихідних даних моделі в реальному часі.
Автоматизуйте оцінку FM
Amazon SageMaker Pipelines автоматизує всі етапи попередньої обробки, тонкого налаштування FM (опціонально) та оцінки в масштабі. Враховуючи моделі, вибрані під час експериментування, інженерам підказок потрібно охопити більший набір випадків, підготувавши багато підказок і зберігаючи їх у спеціальному сховищі, що називається каталогом підказок. Для отримання додаткової інформації див FMOps/LLMOps: реалізуйте генеративний ШІ та відмінності з MLOps. Тоді конвеєри Amazon SageMaker можна структурувати таким чином:
Сценарій 1 – Оцінка кількох FM: У цьому сценарії FM можуть охоплювати бізнес-випадок без тонкого налаштування. Конвеєр Amazon SageMaker складається з таких кроків: попередня обробка даних, паралельна оцінка кількох FM, порівняння моделей і вибір на основі точності та інших властивостей, таких як вартість або затримка, реєстрація вибраних артефактів моделі та метаданих.
Наступна схема ілюструє цю архітектуру.

Сценарій 2 – Точне налаштування та оцінка кількох FM: у цьому сценарії конвеєр Amazon SageMaker структурований подібно до сценарію 1, але виконується паралельно з етапами тонкого налаштування та оцінювання для кожного FM. Найкраще налаштована модель буде зареєстрована в Реєстрі моделей.
Наступна схема ілюструє цю архітектуру.

Сценарій 3 – Оцінка кількох FM та точно налаштованих FM: Цей сценарій є поєднанням оцінки FM загального призначення та точно налаштованих FM. У цьому випадку клієнти хочуть перевірити, чи може добре налаштована модель працювати краще, ніж FM загального призначення.
На наступному малюнку показано кінцеві кроки SageMaker Pipeline.

Зауважте, що реєстрація моделі відбувається за двома схемами: (а) зберігати модель із відкритим вихідним кодом і артефакти або (б) зберігати посилання на власний FM. Для отримання додаткової інформації див FMOps/LLMOps: реалізуйте генеративний ШІ та відмінності з MLOps.
Огляд рішення
Щоб прискорити ваш шлях до масштабної оцінки LLM, ми створили рішення, яке реалізує сценарії за допомогою Amazon SageMaker Clarify і нового Amazon SageMaker Pipelines SDK. Приклад коду, включаючи набори даних, вихідні блокноти та конвеєри SageMaker (кроки та конвеєр ML), доступний на GitHub. Для розробки цього прикладу рішення ми використали два FM: Llama2 і Falcon-7B. У цьому дописі наша основна увага зосереджена на ключових елементах рішення SageMaker Pipeline, які стосуються процесу оцінювання.
Конфігурація оцінювання: З метою стандартизації процедури оцінювання ми створили файл конфігурації YAML (evaluation_config.yaml), який містить необхідні деталі для процесу оцінювання, включаючи набір даних, модель (моделі) та алгоритми, які потрібно запускати під час етап оцінки конвеєра SageMaker. Наступний приклад ілюструє файл конфігурації:
pipeline: name: "llm-evaluation-multi-models-hybrid" dataset: dataset_name: "trivia_qa_sampled" input_data_location: "evaluation_dataset_trivia.jsonl" dataset_mime_type: "jsonlines" model_input_key: "question" target_output_key: "answer" models: - name: "llama2-7b-f" model_id: "meta-textgeneration-llama-2-7b-f" model_version: "*" endpoint_name: "llm-eval-meta-textgeneration-llama-2-7b-f" deployment_config: instance_type: "ml.g5.2xlarge" num_instances: 1 evaluation_config: output: '[0].generation.content' content_template: [[{"role":"user", "content": "PROMPT_PLACEHOLDER"}]] inference_parameters: max_new_tokens: 100 top_p: 0.9 temperature: 0.6 custom_attributes: accept_eula: True prompt_template: "$feature" cleanup_endpoint: True - name: "falcon-7b" ... - name: "llama2-7b-finetuned" ... finetuning: train_data_path: "train_dataset" validation_data_path: "val_dataset" parameters: instance_type: "ml.g5.12xlarge" num_instances: 1 epoch: 1 max_input_length: 100 instruction_tuned: True chat_dataset: False ... algorithms: - algorithm: "FactualKnowledge" module: "fmeval.eval_algorithms.factual_knowledge" config: "FactualKnowledgeConfig" target_output_delimiter: "<OR>"Етап оцінки: Новий SageMaker Pipeline SDK надає користувачам гнучкість визначення власних кроків у робочому процесі машинного навчання за допомогою декоратора Python «@step». Таким чином, користувачі повинні створити базовий сценарій Python, який виконує оцінку, як показано нижче:
def evaluation(data_s3_path, endpoint_name, data_config, model_config, algorithm_config, output_data_path,): from fmeval.data_loaders.data_config import DataConfig from fmeval.model_runners.sm_jumpstart_model_runner import JumpStartModelRunner from fmeval.reporting.eval_output_cells import EvalOutputCell from fmeval.constants import MIME_TYPE_JSONLINES s3 = boto3.client("s3") bucket, object_key = parse_s3_url(data_s3_path) s3.download_file(bucket, object_key, "dataset.jsonl") config = DataConfig( dataset_name=data_config["dataset_name"], dataset_uri="dataset.jsonl", dataset_mime_type=MIME_TYPE_JSONLINES, model_input_location=data_config["model_input_key"], target_output_location=data_config["target_output_key"], ) evaluation_config = model_config["evaluation_config"] content_dict = { "inputs": evaluation_config["content_template"], "parameters": evaluation_config["inference_parameters"], } serializer = JSONSerializer() serialized_data = serializer.serialize(content_dict) content_template = serialized_data.replace('"PROMPT_PLACEHOLDER"', "$prompt") print(content_template) js_model_runner = JumpStartModelRunner( endpoint_name=endpoint_name, model_id=model_config["model_id"], model_version=model_config["model_version"], output=evaluation_config["output"], content_template=content_template, custom_attributes="accept_eula=true", ) eval_output_all = [] s3 = boto3.resource("s3") output_bucket, output_index = parse_s3_url(output_data_path) for algorithm in algorithm_config: algorithm_name = algorithm["algorithm"] module = importlib.import_module(algorithm["module"]) algorithm_class = getattr(module, algorithm_name) algorithm_config_class = getattr(module, algorithm["config"]) eval_algo = algorithm_class(algorithm_config_class(target_output_delimiter=algorithm["target_output_delimiter"])) eval_output = eval_algo.evaluate(model=js_model_runner, dataset_config=config, prompt_template=evaluation_config["prompt_template"], save=True,) print(f"eval_output: {eval_output}") eval_output_all.append(eval_output) html = markdown.markdown(str(EvalOutputCell(eval_output[0]))) file_index = (output_index + "/" + model_config["name"] + "_" + eval_algo.eval_name + ".html") s3_object = s3.Object(bucket_name=output_bucket, key=file_index) s3_object.put(Body=html) eval_result = {"model_config": model_config, "eval_output": eval_output_all} print(f"eval_result: {eval_result}") return eval_resultКонвеєр SageMaker: Після створення необхідних кроків, таких як попередня обробка даних, розгортання моделі та оцінка моделі, користувачеві потрібно зв’язати кроки разом за допомогою SDK SageMaker Pipeline. Новий SDK автоматично генерує робочий процес, інтерпретуючи залежності між різними кроками під час виклику API створення конвеєра SageMaker, як показано в наступному прикладі:
import os
import argparse
from datetime import datetime import sagemaker
from sagemaker.workflow.pipeline import Pipeline
from sagemaker.workflow.function_step import step
from sagemaker.workflow.step_outputs import get_step # Import the necessary steps
from steps.preprocess import preprocess
from steps.evaluation import evaluation
from steps.cleanup import cleanup
from steps.deploy import deploy from lib.utils import ConfigParser
from lib.utils import find_model_by_name if __name__ == "__main__": os.environ["SAGEMAKER_USER_CONFIG_OVERRIDE"] = os.getcwd() sagemaker_session = sagemaker.session.Session() # Define data location either by providing it as an argument or by using the default bucket default_bucket = sagemaker.Session().default_bucket() parser = argparse.ArgumentParser() parser.add_argument("-input-data-path", "--input-data-path", dest="input_data_path", default=f"s3://{default_bucket}/llm-evaluation-at-scale-example", help="The S3 path of the input data",) parser.add_argument("-config", "--config", dest="config", default="", help="The path to .yaml config file",) args = parser.parse_args() # Initialize configuration for data, model, and algorithm if args.config: config = ConfigParser(args.config).get_config() else: config = ConfigParser("pipeline_config.yaml").get_config() evalaution_exec_id = datetime.now().strftime("%Y_%m_%d_%H_%M_%S") pipeline_name = config["pipeline"]["name"] dataset_config = config["dataset"] # Get dataset configuration input_data_path = args.input_data_path + "/" + dataset_config["input_data_location"] output_data_path = (args.input_data_path + "/output_" + pipeline_name + "_" + evalaution_exec_id) print("Data input location:", input_data_path) print("Data output location:", output_data_path) algorithms_config = config["algorithms"] # Get algorithms configuration model_config = find_model_by_name(config["models"], "llama2-7b") model_id = model_config["model_id"] model_version = model_config["model_version"] evaluation_config = model_config["evaluation_config"] endpoint_name = model_config["endpoint_name"] model_deploy_config = model_config["deployment_config"] deploy_instance_type = model_deploy_config["instance_type"] deploy_num_instances = model_deploy_config["num_instances"] # Construct the steps processed_data_path = step(preprocess, name="preprocess")(input_data_path, output_data_path) endpoint_name = step(deploy, name=f"deploy_{model_id}")(model_id, model_version, endpoint_name, deploy_instance_type, deploy_num_instances,) evaluation_results = step(evaluation, name=f"evaluation_{model_id}", keep_alive_period_in_seconds=1200)(processed_data_path, endpoint_name, dataset_config, model_config, algorithms_config, output_data_path,) last_pipeline_step = evaluation_results if model_config["cleanup_endpoint"]: cleanup = step(cleanup, name=f"cleanup_{model_id}")(model_id, endpoint_name) get_step(cleanup).add_depends_on([evaluation_results]) last_pipeline_step = cleanup # Define the SageMaker Pipeline pipeline = Pipeline( name=pipeline_name, steps=[last_pipeline_step], ) # Build and run the Sagemaker Pipeline pipeline.upsert(role_arn=sagemaker.get_execution_role()) # pipeline.upsert(role_arn="arn:aws:iam::<...>:role/service-role/AmazonSageMaker-ExecutionRole-<...>") pipeline.start()У прикладі реалізовано оцінку окремого FM шляхом попередньої обробки початкового набору даних, розгортання моделі та запуску оцінки. Згенерований конвеєрно-спрямований ациклічний граф (DAG) показаний на наступному малюнку.

Дотримуючись подібного підходу та використовуючи та адаптуючи приклад у Налаштуйте моделі LLaMA 2 на SageMaker JumpStart, ми створили конвеєр для оцінки точно налаштованої моделі, як показано на наступному малюнку.

Використовуючи попередні кроки SageMaker Pipeline як блоки «Lego», ми розробили рішення для сценарію 1 і сценарію 3, як показано на наступних малюнках. Зокрема, GitHub Репозиторій дозволяє користувачеві оцінювати кілька FM паралельно або виконувати більш складну оцінку, поєднуючи оцінку як основної, так і точно налаштованої моделей.


Додаткові функції, доступні в репозиторії, включають наступне:
- Генерація кроку динамічного оцінювання: Наше рішення динамічно генерує всі необхідні етапи оцінювання на основі файлу конфігурації, щоб користувачі могли оцінювати будь-яку кількість моделей. Ми розширили рішення для підтримки легкої інтеграції нових типів моделей, таких як Hugging Face або Amazon Bedrock.
- Запобігання перерозподілу кінцевої точки: якщо кінцева точка вже на місці, ми пропускаємо процес розгортання. Це дозволяє користувачеві повторно використовувати кінцеві точки з FM для оцінки, що призводить до економії коштів і скорочення часу розгортання.
- Очищення кінцевої точки: Після завершення оцінювання SageMaker Pipeline виводить із експлуатації розгорнуті кінцеві точки. Цю функціональність можна розширити, щоб зберегти найкращу кінцеву точку моделі.
- Етап вибору моделі: Ми додали заповнювач етапу вибору моделі, який вимагає бізнес-логіки остаточного вибору моделі, включаючи такі критерії, як вартість або затримка.
- Етап реєстрації моделі: найкращу модель можна зареєструвати в Amazon SageMaker Model Registry як нову версію певної групи моделей.
- Теплий басейн: Керовані теплі пули SageMaker дозволяють зберігати та повторно використовувати надану інфраструктуру після завершення завдання, щоб зменшити затримку для повторюваних робочих навантажень
На наступному малюнку показано ці можливості та приклад оцінки з кількома моделями, які користувачі можуть створити легко та динамічно, використовуючи наше рішення в цьому GitHub сховище

Ми навмисно виключили підготовку даних, оскільки вона буде детально описана в іншій публікації, включаючи оперативні дизайни каталогів, оперативні шаблони, оперативну оптимізацію. Для отримання додаткової інформації та відповідних визначень компонентів див FMOps/LLMOps: реалізуйте генеративний ШІ та відмінності з MLOps.
Висновок
У цій публікації ми зосередилися на тому, як автоматизувати та ввести в дію масштабне оцінювання LLM за допомогою можливостей оцінювання Amazon SageMaker Clarify LLM і Amazon SageMaker Pipelines. Окрім теоретичних проектів архітектури, у нас є приклади коду GitHub репозиторій (з Llama2 і Falcon-7B FM), щоб клієнти могли розробляти власні масштабовані механізми оцінки.
На наступній ілюстрації показано архітектуру оцінки моделі.

У цьому дописі ми зосередилися на операційній оцінці LLM у масштабі, як показано на лівій стороні ілюстрації. У майбутньому ми зосередимося на розробці прикладів виконання наскрізного життєвого циклу FM до виробництва, дотримуючись інструкцій, описаних у FMOps/LLMOps: реалізуйте генеративний ШІ та відмінності з MLOps. Це включає обслуговування LLM, моніторинг, зберігання рейтингу виходу, що в кінцевому підсумку запускатиме автоматичну повторну оцінку та тонке налаштування, і, нарешті, використання людей у циклі для роботи з позначеними даними або каталогом підказок.
Про авторів
 Доктор Сократіс Картакіс є головним архітектором рішень спеціаліста з машинного навчання та операцій для Amazon Web Services. Sokratis зосереджується на тому, щоб дозволити корпоративним клієнтам індустріалізувати свої рішення машинного навчання (ML) і генеративного штучного інтелекту, використовуючи сервіси AWS і формуючи свою операційну модель, тобто основи MLOps/FMOps/LLMOps, і дорожню карту трансформації, використовуючи найкращі практики розробки. Понад 15 років він присвятив винаходу, розробці, керівництву та впровадженню інноваційних наскрізних рішень ML та AI у сферах енергетики, роздрібної торгівлі, охорони здоров’я, фінансів, автоспорту тощо.
Доктор Сократіс Картакіс є головним архітектором рішень спеціаліста з машинного навчання та операцій для Amazon Web Services. Sokratis зосереджується на тому, щоб дозволити корпоративним клієнтам індустріалізувати свої рішення машинного навчання (ML) і генеративного штучного інтелекту, використовуючи сервіси AWS і формуючи свою операційну модель, тобто основи MLOps/FMOps/LLMOps, і дорожню карту трансформації, використовуючи найкращі практики розробки. Понад 15 років він присвятив винаходу, розробці, керівництву та впровадженню інноваційних наскрізних рішень ML та AI у сферах енергетики, роздрібної торгівлі, охорони здоров’я, фінансів, автоспорту тощо.
 Джагдіп Сінгх Соні є старшим партнером-архітектором рішень в AWS, розташованому в Нідерландах. Він використовує свою пристрасть до DevOps, GenAI та інструментів конструктора, щоб допомогти як системним інтеграторам, так і технологічним партнерам. Джагдіп використовує свій досвід розробки додатків і архітектури, щоб стимулювати інновації у своїй команді та просувати нові технології.
Джагдіп Сінгх Соні є старшим партнером-архітектором рішень в AWS, розташованому в Нідерландах. Він використовує свою пристрасть до DevOps, GenAI та інструментів конструктора, щоб допомогти як системним інтеграторам, так і технологічним партнерам. Джагдіп використовує свій досвід розробки додатків і архітектури, щоб стимулювати інновації у своїй команді та просувати нові технології.
 Доктор Ріккардо Гатті є старшим архітектором рішень для стартапів з Італії. Він є технічним консультантом для клієнтів, допомагаючи їм розвивати свій бізнес, вибираючи правильні інструменти та технології для впровадження інновацій, швидкого масштабування та виходу на глобальний рівень за лічені хвилини. Він завжди захоплювався машинним навчанням і генеративним штучним інтелектом, вивчаючи та застосовуючи ці технології в різних сферах протягом своєї кар’єри. Він є ведучим і редактором італійського подкасту AWS «Casa Startup», присвяченого історіям засновників стартапів і новим технологічним трендам.
Доктор Ріккардо Гатті є старшим архітектором рішень для стартапів з Італії. Він є технічним консультантом для клієнтів, допомагаючи їм розвивати свій бізнес, вибираючи правильні інструменти та технології для впровадження інновацій, швидкого масштабування та виходу на глобальний рівень за лічені хвилини. Він завжди захоплювався машинним навчанням і генеративним штучним інтелектом, вивчаючи та застосовуючи ці технології в різних сферах протягом своєї кар’єри. Він є ведучим і редактором італійського подкасту AWS «Casa Startup», присвяченого історіям засновників стартапів і новим технологічним трендам.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/operationalize-llm-evaluation-at-scale-using-amazon-sagemaker-clarify-and-mlops-services/

