A fejlődő gyártási környezetben az AI és a gépi tanulás (ML) átalakító ereje nyilvánvaló, és olyan digitális forradalmat indít el, amely egyszerűsíti a műveleteket és növeli a termelékenységet. Ez a haladás azonban egyedi kihívások elé állítja az adatvezérelt megoldásokban navigáló vállalkozásokat. Az ipari létesítmények hatalmas mennyiségű strukturálatlan adattal küzdenek, amelyek érzékelőkből, telemetriai rendszerekből és gyártósorokon szétszórt berendezésekből származnak. A valós idejű adatok létfontosságúak az olyan alkalmazásokhoz, mint a prediktív karbantartás és az anomália-észlelés, de az ilyen idősoros adatokkal minden ipari felhasználási esetre egyedi ML-modellek kidolgozása jelentős időt és erőforrást igényel az adatkutatóktól, ami akadályozza a széles körű alkalmazást.
Generatív AI nagy előre betanított alapozó modellek (FM) használatával, mint pl Claude Gyorsan képes különféle tartalmat generálni a társalgási szövegtől a számítógépes kódig egyszerű szöveges felszólítások alapján, az úgynevezett nulla lövés felszólítás. Ez kiküszöböli annak szükségességét, hogy az adattudósok manuálisan specifikus ML-modelleket fejlesszenek ki minden egyes felhasználási esethez, és ezáltal demokratizálja az AI-hozzáférést, ami még a kis gyártók számára is előnyös. A dolgozók a mesterséges intelligencia által generált betekintések révén termelékenységet érnek el, a mérnökök proaktívan észlelhetik az anomáliákat, az ellátási lánc vezetői optimalizálják a készleteket, az üzem vezetése pedig tájékozott, adatvezérelt döntéseket hoz.
Mindazonáltal az önálló FM-ek korlátokkal szembesülnek az összetett ipari adatok kezelésében, a kontextus méretének korlátaival (általában kevesebb mint 200,000 XNUMX token), ami kihívásokat jelent. Ennek megoldására használhatja az FM azon képességét, hogy kódot generáljon válaszul a természetes nyelvi lekérdezésekre (NLQ). Ügynökök, mint PandasAI Ez a kód nagy felbontású idősoros adatokon fut, és FM-ek használatával kezeli a hibákat. A PandasAI egy Python-könyvtár, amely generatív mesterséges intelligencia képességeket ad a pandákhoz, a népszerű adatelemző és -manipulációs eszközhöz.
Az összetett NLQ-k azonban, mint például az idősoros adatfeldolgozás, a többszintű összesítés és a pivot vagy a közös táblaműveletek, inkonzisztens Python-szkript pontosságot eredményezhetnek nulla-lövés esetén.
A kódgenerálás pontosságának növelése érdekében dinamikus felépítést javasolunk több lövést tartalmazó promptok az NLQ-k számára. A többképes felszólítás további kontextust biztosít az FM-nek azáltal, hogy számos példát mutat be a kívánt kimenetekre hasonló promptokhoz, növelve a pontosságot és a konzisztenciát. Ebben a bejegyzésben a többszörös felvételes promptokat egy hasonló adattípuson futtatott sikeres Python-kódot tartalmazó beágyazásból kérik le (például nagy felbontású idősor-adatok a dolgok Internete eszközökről). A dinamikusan felépített többképes prompt biztosítja az FM legrelevánsabb kontextusát, és növeli az FM fejlett matematikai számítási, idősoros adatfeldolgozási és adatmozaikszó-megértési képességeit. Ez a továbbfejlesztett válasz megkönnyíti a vállalati dolgozókat és az operatív csapatokat az adatok kezelésében, és betekintést nyernek anélkül, hogy kiterjedt adattudományi ismeretekre lenne szükségük.
Az idősoros adatelemzésen túl az FM-ek értékesnek bizonyulnak különféle ipari alkalmazásokban. A karbantartó csapatok felmérik az eszközök állapotát, és képeket készítenek Amazon felismerés-alapú funkcionalitás összefoglalók és az anomáliák kiváltó okainak elemzése intelligens keresések segítségével Visszakeresés kiterjesztett generáció (RONGY). A munkafolyamatok egyszerűsítése érdekében az AWS bevezette Amazon alapkőzet, amely lehetővé teszi generatív mesterséges intelligencia alkalmazások létrehozását és méretezését a legkorszerűbb, előre betanított FM-ekkel, mint pl. Claude v2. A Tudásbázisok az Amazon Bedrock számára, leegyszerűsítheti a RAG fejlesztési folyamatát, hogy pontosabb anomáliák kiváltó ok-elemzést biztosítson az üzem dolgozói számára. Bejegyzésünk egy intelligens asszisztenst mutat be ipari felhasználási esetekhez, az Amazon Bedrock által meghajtott, NLQ-kihívásokkal foglalkozik, képekből részösszegzéseket készít, és a RAG-megközelítésen keresztül javítja az FM-válaszokat a berendezések diagnosztizálásához.
Megoldás áttekintése
A következő ábra a megoldás architektúráját mutatja be.
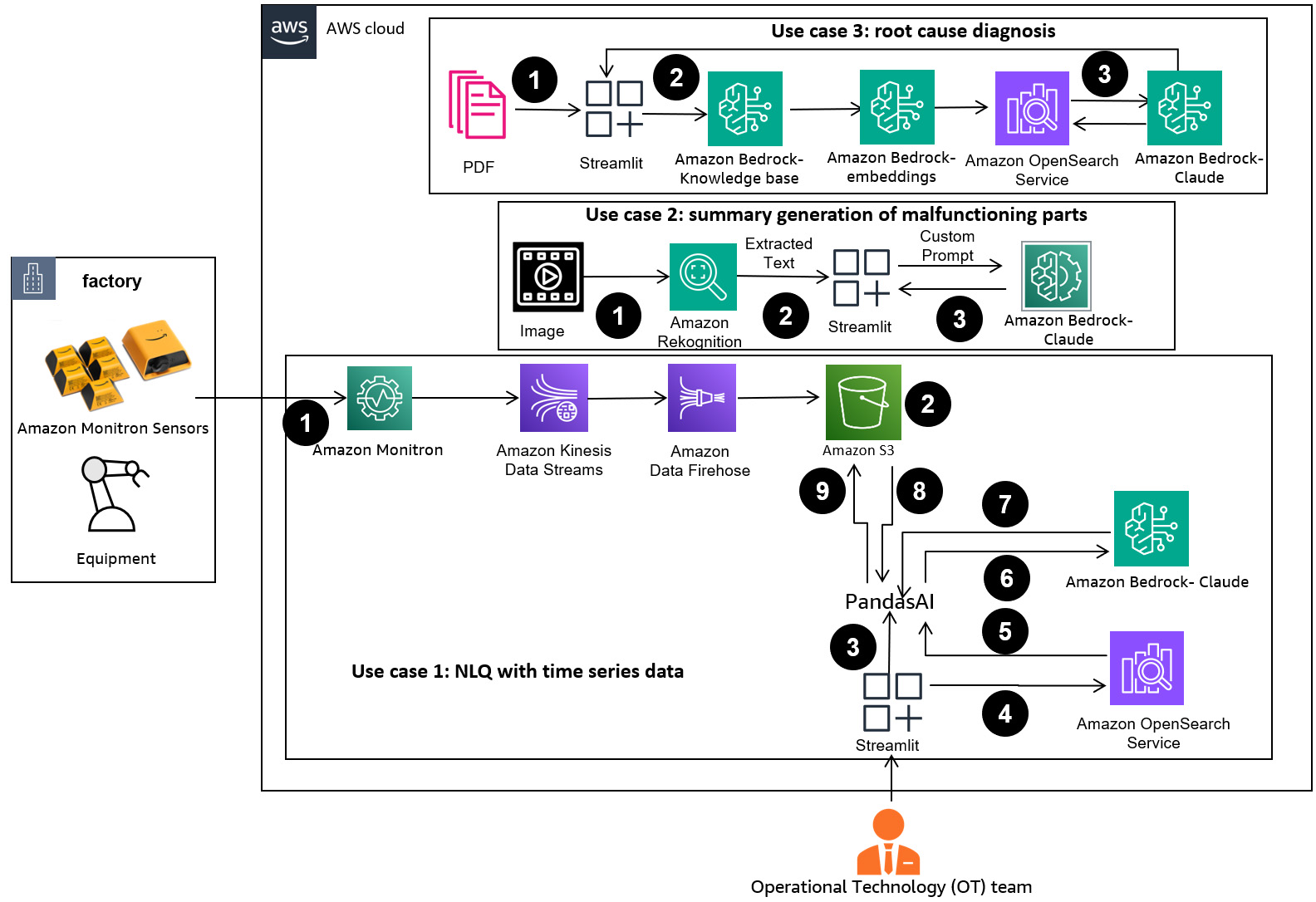
A munkafolyamat három különböző használati esetet tartalmaz:
1. használati eset: NLQ idősoros adatokkal
Az idősoros adatokkal rendelkező NLQ munkafolyamata a következő lépésekből áll:
- Az anomáliák észlelésére ML képességekkel rendelkező állapotfigyelő rendszert használunk, mint pl Amazon Monitron, az ipari berendezések állapotának ellenőrzésére. Az Amazon Monitron a berendezés rezgés- és hőmérsékletmérései alapján képes észlelni a lehetséges berendezéshibákat.
- Az idősoros adatokat feldolgozással gyűjtjük Amazon Monitron adatokon keresztül Amazon Kinesis adatfolyamok és a Amazon Data Firehose, átalakítja táblázatos CSV formátumba és elmenti egy Amazon egyszerű tárolási szolgáltatás (Amazon S3) vödör.
- A végfelhasználó elkezdhet csevegni idősoraival az Amazon S3-ban, ha természetes nyelvű lekérdezést küld a Streamlit alkalmazásnak.
- A Streamlit alkalmazás továbbítja a felhasználói lekérdezéseket a Amazon Bedrock Titan szövegbeágyazó modell a lekérdezés beágyazásához, és hasonlósági keresést hajt végre egy Amazon OpenSearch szolgáltatás index, amely korábbi NLQ-kat és példakódokat tartalmaz.
- A hasonlósági keresés után a legjobb hasonló példák, beleértve az NLQ-kérdéseket, az adatsémát és a Python-kódokat, beszúrásra kerülnek egy egyéni promptba.
- A PandasAI ezt az egyéni promptot küldi az Amazon Bedrock Claude v2 modellnek.
- Az alkalmazás a PandasAI ügynököt használja az Amazon Bedrock Claude v2 modellel való interakcióhoz, Python kódot generálva az Amazon Monitron adatelemzéséhez és az NLQ válaszokhoz.
- Miután az Amazon Bedrock Claude v2 modell visszaadja a Python-kódot, a PandasAI lefuttatja a Python-lekérdezést az alkalmazásból feltöltött Amazon Monitron-adatokon, összegyűjti a kódkimeneteket, és megkeresi a sikertelen futtatásokhoz szükséges újrapróbálkozásokat.
- A Streamlit alkalmazás a PandasAI-n keresztül gyűjti a választ, és a kimenetet biztosítja a felhasználóknak. Ha a kimenet kielégítő, a felhasználó megjelölheti hasznosnak, és elmentheti az NLQ és a Claude által generált Python kódot az OpenSearch szolgáltatásba.
2. használati eset: A hibás alkatrészek összefoglalása
Összefoglaló generációs használati esetünk a következő lépésekből áll:
- Miután a felhasználó tudja, hogy melyik ipari eszköz mutat rendellenes viselkedést, képeket tölthet fel a hibásan működő részről, hogy megállapítsa, van-e valami fizikai probléma ezzel az alkatrészrel a műszaki specifikáció és a működési állapot szerint.
- A felhasználó használhatja a Amazon Recognition DetectText API szöveges adatok kinyerésére ezekből a képekből.
- A kivont szöveges adatok szerepelnek az Amazon Bedrock Claude v2 modell promptjában, lehetővé téve a modell számára, hogy 200 szavas összefoglalót készítsen a hibás részről. A felhasználó ezt az információt felhasználhatja az alkatrész további ellenőrzésére.
3. használati eset: A kiváltó ok diagnózisa
A kiváltó okok diagnózisának használati esete a következő lépésekből áll:
- A felhasználó különféle dokumentum formátumokban (PDF, TXT stb.) szerzi be a meghibásodott eszközökhöz kapcsolódó vállalati adatokat, és feltölti azokat egy S3 tárolóba.
- Ezeknek a fájloknak a tudásbázisa az Amazon Bedrockban jön létre a Titan szövegbeágyazási modellel és egy alapértelmezett OpenSearch Service vektortárolóval.
- A felhasználó kérdéseket tesz fel a hibás berendezés kiváltó okának diagnosztizálásával kapcsolatban. A válaszok az Amazon Bedrock tudásbázison keresztül generálódnak RAG megközelítéssel.
Előfeltételek
A bejegyzés követéséhez teljesítenie kell a következő előfeltételeket:
Telepítse a megoldás infrastruktúráját
A megoldási erőforrások beállításához hajtsa végre a következő lépéseket:
- Telepítse a AWS felhőképződés sablon opensearchsagemaker.yml, amely létrehoz egy OpenSearch Service gyűjteményt és indexet, Amazon SageMaker notebook példány és S3 vödör. Ezt az AWS CloudFormation-vermet a következőképpen nevezheti el:
genai-sagemaker. - Nyissa meg a SageMaker jegyzetfüzet példányát a JupyterLab alkalmazásban. A következőket találja GitHub repo már letöltve ezen a példányon: a generatív-ai-in-ipari-műveletek-potenciál felszabadítása.
- Futtassa a jegyzetfüzetet a lerakat következő könyvtárából: a generative-ai-in-industrial-operations/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. Ez a jegyzetfüzet betölti az OpenSearch Service indexet a SageMaker jegyzetfüzet segítségével, hogy a kulcs-érték párokat tárolja a meglévő 23 NLQ példa.
- Dokumentumok feltöltése az adatmappából assetpartdoc a GitHub-tárolóban a CloudFormation veremkimeneteiben felsorolt S3 tárolóba.

Ezután létrehozza az Amazon S3 dokumentumok tudásbázisát.
- Az Amazon Bedrock konzolon válassza a lehetőséget Blog a navigációs ablaktáblában.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Tudásbázis létrehozása.
- A Tudásbázis neve, írjon be egy nevet.
- A Futóidejű szerepkörválassza Hozzon létre és használjon új szolgáltatási szerepet.

- A Adatforrás neve, írja be az adatforrás nevét.
- A S3 URI, adja meg annak a csoportnak az S3 elérési útját, ahová a kiváltó okok dokumentumait feltöltötte.
- A pop-art design, négy időzóna kijelzése egyszerre és méretének arányai azok az érvek, amelyek a NeXtime Time Zones-t kiváló választássá teszik. Válassza a Következő.
 A Titan beágyazott modell automatikusan kiválasztásra kerül.
A Titan beágyazott modell automatikusan kiválasztásra kerül. - választ Hozzon létre gyorsan egy új vektortárat.

- Tekintse át beállításait, és válassza ki a tudásbázist Tudásbázis létrehozása.
- A tudásbázis sikeres létrehozása után válassza a lehetőséget Szinkronizálás hogy szinkronizálja az S3 tárolót a tudásbázissal.

- Miután felállította a tudásbázist, tesztelheti a RAG-megközelítést a kiváltó okok diagnosztizálására oly módon, hogy olyan kérdéseket tesz fel, mint például: „Az aktuátorom lassan mozog, mi lehet a probléma?”

A következő lépés az alkalmazás telepítése a szükséges könyvtárcsomagokkal a számítógépen vagy egy EC2 példányon (Ubuntu Server 22.04 LTS).
- Állítsa be az AWS hitelesítő adatait az AWS CLI-vel a helyi számítógépen. Az egyszerűség kedvéért ugyanazt a rendszergazdai szerepkört használhatja, amelyet a CloudFormation-verem üzembe helyezéséhez használt. Ha Amazon EC2-t használ, megfelelő IAM-szerepet csatoljon a példányhoz.
- Clone GitHub repo:
- Módosítsa a könyvtárat erre:
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcés futtassa asetup.shscript ebben a mappában a szükséges csomagok, köztük a LangChain és a PandasAI telepítéséhez:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - Futtassa a Streamlit alkalmazást a következő paranccsal:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
Adja meg az OpenSearch szolgáltatás ARN gyűjteményét, amelyet az Amazon Bedrockban az előző lépésben hozott létre.
Csevegés az eszköz-egészségügyi asszisztenssel
A végpontok közötti üzembe helyezés befejezése után az alkalmazást a 8501-es porton lévő localhost segítségével érheti el, amely megnyit egy böngészőablakot a webes felülettel. Ha az alkalmazást EC2-példányon telepítette, engedélyezze a 8501-es port elérését a biztonsági csoport bejövő szabályán keresztül. Különféle használati esetekhez navigálhat a különböző lapokra.
Fedezze fel az 1. használati esetet
Az első használati eset felfedezéséhez válassza a lehetőséget Data Insight és diagram. Kezdje az idősor adatainak feltöltésével. Ha nem rendelkezik használható idősoros adatfájllal, feltöltheti a következőket minta CSV fájl névtelen Amazon Monitron projektadatokkal. Ha már van Amazon Monitron projektje, tekintse meg a Az Amazon Monitron és az Amazon Kinesis segítségével megvalósítható betekintést nyerhet a prediktív karbantartáskezeléshez az Amazon Monitron adatainak streameléséhez az Amazon S3-ra, és adatainak ezzel az alkalmazással való felhasználásához.
Amikor a feltöltés befejeződött, írjon be egy lekérdezést, hogy beszélgetést kezdeményezzen adataival. A bal oldalsáv számos példakérdést kínál az Ön kényelme érdekében. A következő képernyőképek szemléltetik az FM által generált választ és Python-kódot, amikor olyan kérdéseket ír be, mint például: „Mondja meg az érzékelők egyedi számát az egyes helyszíneken, amelyek figyelmeztetésként vagy riasztásként jelennek meg?” (nehéz szintű kérdés) vagy „Azoknál az érzékelőknél, amelyek hőmérsékleti jele NEM egészséges, ki tudja számítani az időtartamot napokban minden egyes érzékelőnél, amely rendellenes rezgésjelet mutat?” (egy kihívás szintű kérdés). Az alkalmazás válaszol a kérdésére, és megjeleníti az adatelemzés Python-szkriptjét is, amelyet az ilyen eredmények generálásához végzett.
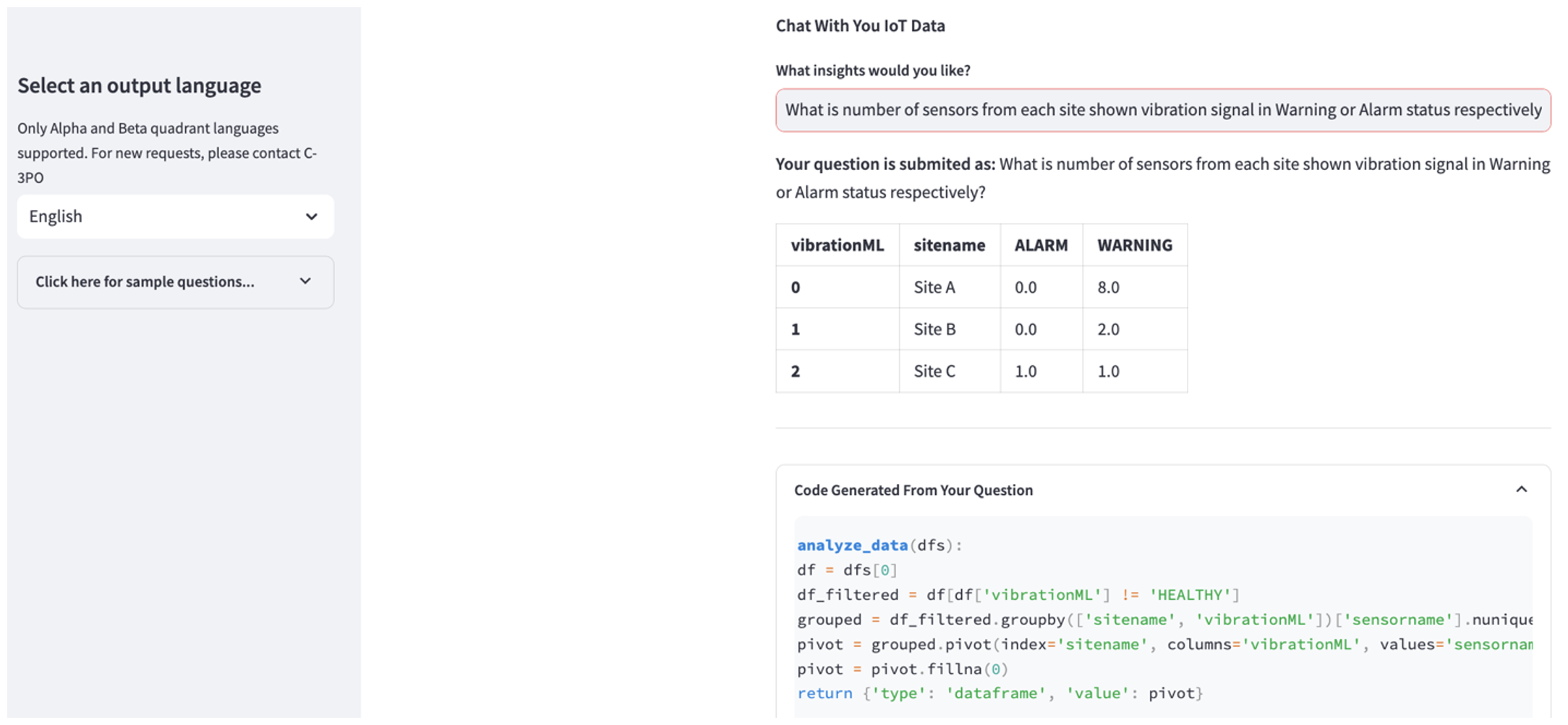

Ha elégedett a válasszal, megjelölheti, mint Hasznos, az NLQ és a Claude által generált Python kód mentése egy OpenSearch Service indexbe.

Fedezze fel az 2. használati esetet
A második használati eset felfedezéséhez válassza a lehetőséget A rögzített kép összefoglalója lapon a Streamlit alkalmazásban. Képet tölthet fel ipari eszközéről, és az alkalmazás a képinformációk alapján 200 szavas összefoglalót generál annak műszaki jellemzőiről és működési állapotáról. A következő képernyőképen egy szíjmotoros hajtás képéből készült összefoglaló látható. A funkció teszteléséhez, ha nincs megfelelő kép, használhatja a következőket példa kép.

Hidraulikus felvonómotor címke” szerzője: Clarence Risher licence alá tartozik CC BY-SA 2.0.

Fedezze fel az 3. használati esetet
A harmadik használati eset felfedezéséhez válassza a A kiváltó ok diagnózisa lapon. Írjon be egy lekérdezést az elromlott ipari eszközéhez, például: „Az állítómű lassan mozog, mi lehet a probléma?” Amint az a következő képernyőképen látható, az alkalmazás a válasz generálásához használt forrásdokumentum-kivonattal válaszol.

1. használati eset: Tervezési részletek
Ebben a részben az alkalmazás munkafolyamatának tervezési részleteit tárgyaljuk az első használati esetre.
Egyedi azonnali építés
A felhasználó természetes nyelvű lekérdezésének különböző nehézségi szintjei vannak: könnyű, nehéz és kihívás.
Az egyszerű kérdések a következő kéréseket tartalmazhatják:
- Válasszon egyedi értékeket
- Számolja meg az összes számot
- Értékek rendezése
Ezekre a kérdésekre a PandasAI közvetlenül kapcsolatba léphet az FM-mel, hogy Python-szkripteket állítson elő a feldolgozáshoz.
A nehéz kérdések alapvető összesítési műveletet vagy idősorelemzést igényelnek, például a következők:
- Először válassza ki az értéket, és csoportosítsa az eredményeket hierarchikusan
- Statisztikák végrehajtása a kezdeti rekordválasztás után
- Időbélyegek száma (például min és max)
Nehéz kérdések esetén a részletes, lépésenkénti utasításokat tartalmazó gyorssablon segíti az FM-eket a pontos válaszadásban.
A kihívás szintű kérdések fejlett matematikai számításokat és idősor-feldolgozást igényelnek, mint például a következők:
- Számítsa ki az anomália időtartamát minden egyes érzékelőhöz
- Számítsa ki az anomália-érzékelőket a helyszínre havonta
- Hasonlítsa össze az érzékelők leolvasásait normál működés és rendellenes körülmények között
Ezekre a kérdésekre több felvételt is használhat egyéni promptban a válasz pontosságának növelése érdekében. Az ilyen többszörös felvételek példákat mutatnak be a fejlett idősor-feldolgozásra és a matematikai számításokra, és kontextust biztosítanak az FM számára, hogy releváns következtetéseket hajtson végre hasonló elemzésekre. Az NLQ kérdésbank legrelevánsabb példáinak dinamikus beszúrása a promptba kihívást jelenthet. Az egyik megoldás az, hogy a meglévő NLQ-kérdésmintákból beágyazásokat hoz létre, és ezeket a beágyazásokat elmenti egy vektortárolóba, például az OpenSearch szolgáltatásba. Amikor egy kérdést elküldenek a Streamlit alkalmazásba, a kérdés vektorizálásra kerül AlapkőzetBeágyazások. Az adott kérdéshez tartozó N legfontosabb beágyazás a következő használatával kerül lekérésre opensearch_vector_search.similarity_search és beillesztjük a prompt sablonba többlövéses promptként.
A következő diagram ezt a munkafolyamatot mutatja be.
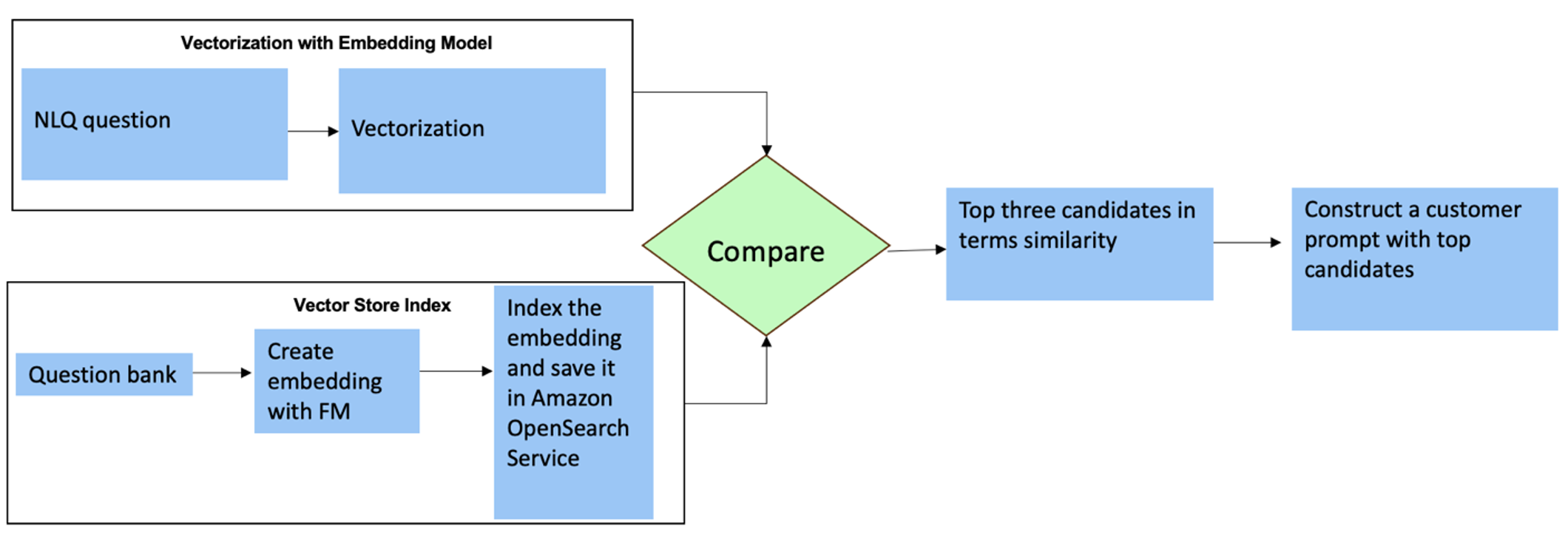
A beágyazási réteg három kulcsfontosságú eszközzel készül:
- Beágyazási modell – Az Amazon Bedrock-on keresztül elérhető Amazon Titan beágyazásokat használjuk (amazon.titan-embed-text-v1) szöveges dokumentumok numerikus megjelenítéséhez.
- Vektor bolt – A vektortárunkhoz az OpenSearch szolgáltatást használjuk a LangChain keretrendszeren keresztül, ezzel egyszerűsítve az NLQ-példákból generált beágyazások tárolását ebben a notebookban.
- index – Az OpenSearch Service index kulcsfontosságú szerepet játszik a bemeneti beágyazások és a dokumentumbeágyazások összehasonlításában, és megkönnyíti a releváns dokumentumok visszakeresését. Mivel a Python példakódokat JSON-fájlként mentették, az OpenSearch Service-ben vektorokként indexelték őket egy OpenSearchVevtorSearch.fromtexts API hívás.
Ember által auditált példák folyamatos gyűjtése a Streamliten keresztül
Az alkalmazásfejlesztés kezdetén mindössze 23 mentett példával kezdtük az OpenSearch Service indexét beágyazásként. Ahogy az alkalmazás élesben működik a terepen, a felhasználók elkezdik beírni NLQ-jaikat az alkalmazáson keresztül. A sablonban rendelkezésre álló példák korlátozott száma miatt azonban előfordulhat, hogy egyes NLQ-k nem találnak hasonló promptokat. A beágyazások folyamatos gazdagításához és relevánsabb felhasználói utasítások megjelenítéséhez használhatja a Streamlit alkalmazást az ember által ellenőrzött példák összegyűjtésére.
Az alkalmazáson belül a következő funkció szolgálja ezt a célt. Amikor a végfelhasználók hasznosnak találják a kimenetet, és kiválasztják Hasznos, az alkalmazás a következő lépéseket követi:
- Használja a PandasAI visszahívási módszerét a Python-szkript összegyűjtéséhez.
- Formázza újra a Python-szkriptet, írja be a kérdést és a CSV-metaadatokat egy karakterláncba.
- Ellenőrizze, hogy ez az NLQ-példa létezik-e már az OpenSearch Service aktuális indexében opensearch_vector_search.similarity_search_with_score.
- Ha nincs hasonló példa, akkor ezt az NLQ-t a rendszer hozzáadja az OpenSearch Service indexéhez opensearch_vector_search.add_texts.
Abban az esetben, ha a felhasználó kiválasztja Nem segítőkész, nem történik intézkedés. Ez az iteratív folyamat biztosítja, hogy a rendszer folyamatosan fejlődjön a felhasználók által hozzáadott példák beépítésével.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
Az emberi auditálás beépítésével az OpenSearch szolgáltatásban az azonnali beágyazáshoz rendelkezésre álló példák száma növekszik, ahogy az alkalmazás egyre nagyobb mértékben használható. Ez a kibővített beágyazott adatkészlet idővel nagyobb keresési pontosságot eredményez. Pontosabban, a kihívást jelentő NLQ-k esetében az FM válaszpontossága eléri a körülbelül 90%-ot, ha dinamikusan beszúrnak hasonló példákat, hogy egyéni promptokat készítsenek minden egyes NLQ-kérdéshez. Ez figyelemre méltó, 28%-os növekedést jelent a többszörös felhívás nélküli forgatókönyvekhez képest.
2. használati eset: Tervezési részletek
A Streamlit alkalmazásban A rögzített kép összefoglalója lapon közvetlenül feltölthet egy képfájlt. Ez elindítja az Amazon Rekognition API-t (észlel_szöveg API), a gép specifikációit részletező szöveg kinyerése a képcímkéből. Ezt követően a kivont szöveges adatokat az Amazon Bedrock Claude-modellhez küldik egy prompt kontextusaként, ami egy 200 szavas összefoglalást eredményez.
A felhasználói élmény szempontjából a streaming funkcionalitás engedélyezése a szöveges összegzési feladatokhoz kiemelkedően fontos, lehetővé téve a felhasználók számára, hogy az FM által generált összefoglalót kisebb darabokban olvassák el, ahelyett, hogy a teljes kimenetre várnának. Az Amazon Bedrock API-ján keresztül megkönnyíti a streamelést (bedrock_runtime.invoke_model_with_response_stream).
3. használati eset: Tervezési részletek
Ebben a forgatókönyvben kifejlesztettünk egy chatbot alkalmazást, amely az okok elemzésére összpontosít, és a RAG megközelítést alkalmazza. Ez a chatbot több, a csapágyberendezéssel kapcsolatos dokumentumból merít, hogy megkönnyítse a kiváltó okok elemzését. Ez a RAG-alapú kiváltó ok-elemző chatbot tudásbázisokat használ a vektoros szövegreprezentációk vagy beágyazások generálására. A Knowledge Bases for Amazon Bedrock egy teljesen felügyelt képesség, amely segít a teljes RAG-munkafolyamat megvalósításában, a feldolgozástól a visszakeresésig és az azonnali kiegészítésig anélkül, hogy egyéni integrációkat kellene létrehoznia az adatforrásokhoz, illetve kezelnie kellene az adatfolyamokat és a RAG megvalósítási részleteit.
Ha elégedett az Amazon Bedrock tudásbázis-válaszával, integrálhatja a kiváltó okokra adott választ a tudásbázisból a Streamlit alkalmazásba.
Tisztítsuk meg
A költségek megtakarítása érdekében törölje az ebben a bejegyzésben létrehozott erőforrásokat:
- Törölje a tudásbázist az Amazon Bedrockból.
- Törölje az OpenSearch szolgáltatás indexét.
- Törölje a genai-sagemaker CloudFormation veremét.
- Állítsa le az EC2 példányt, ha EC2 példányt használt a Streamlit alkalmazás futtatásához.
Következtetés
A generatív AI-alkalmazások már számos üzleti folyamatot átalakítottak, javítva a dolgozók termelékenységét és készségeit. Azonban az FM-ek korlátai az idősoros adatelemzés kezelésében akadályozták azok teljes körű hasznosítását az ipari ügyfelek számára. Ez a megszorítás akadályozta a generatív mesterséges intelligencia alkalmazását az uralkodó, naponta feldolgozott adattípusokra.
Ebben a bejegyzésben bemutattunk egy generatív mesterséges intelligencia-alkalmazási megoldást, amelyet az ipari felhasználók ezen kihívásának enyhítésére terveztek. Ez az alkalmazás egy nyílt forráskódú ügynököt, a PandasAI-t használja az FM idősorelemzési képességének megerősítésére. Ahelyett, hogy az idősoradatokat közvetlenül FM-ekre küldené, az alkalmazás a PandasAI segítségével Python-kódot állít elő a strukturálatlan idősor-adatok elemzéséhez. A Python kódgenerálás pontosságának növelése érdekében egyéni prompt-generálási munkafolyamatot valósítottak meg emberi ellenőrzéssel.
Az eszközeik állapotába való betekintéssel az ipari dolgozók teljes mértékben kiaknázhatják a generatív AI-ban rejlő lehetőségeket különféle felhasználási esetekben, beleértve a kiváltó okok diagnosztizálását és az alkatrészcsere tervezését. Az Amazon Bedrock tudásbázisaival a RAG megoldást a fejlesztők egyszerűen elkészíthetik és kezelhetik.
A vállalati adatkezelés és -műveletek pályája összetéveszthetetlenül a generatív mesterséges intelligencia mélyebb integrációja felé halad, hogy átfogó betekintést nyerhessen a működési állapotba. Ezt az Amazon Bedrock által vezetett váltást jelentősen felerősíti az olyan LLM-ek növekvő robusztussága és potenciálja, mint pl. Amazon Bedrock Claude 3 hogy tovább emeljék a megoldásokat. További információért keresse fel a Amazon Bedrock dokumentáció, és ismerkedjen meg a Amazon Bedrock műhely.
A szerzőkről
 Julia Hu Sr. AI/ML Solutions Architect az Amazon Web Servicesnél. Szakterülete a generatív AI, az alkalmazott adattudomány és az IoT architektúra. Jelenleg az Amazon Q csapatának tagja, és a Machine Learning Technical Field Community aktív tagja/mentora. Az induló vállalkozásoktól a vállalkozásokig ügyfelekkel dolgozik az AWSome generatív AI-megoldások fejlesztésén. Különösen szenvedélyes a nagy nyelvi modellek kihasználása a fejlett adatelemzés érdekében, és olyan gyakorlati alkalmazások felfedezése, amelyek a valós világ kihívásait kezelik.
Julia Hu Sr. AI/ML Solutions Architect az Amazon Web Servicesnél. Szakterülete a generatív AI, az alkalmazott adattudomány és az IoT architektúra. Jelenleg az Amazon Q csapatának tagja, és a Machine Learning Technical Field Community aktív tagja/mentora. Az induló vállalkozásoktól a vállalkozásokig ügyfelekkel dolgozik az AWSome generatív AI-megoldások fejlesztésén. Különösen szenvedélyes a nagy nyelvi modellek kihasználása a fejlett adatelemzés érdekében, és olyan gyakorlati alkalmazások felfedezése, amelyek a valós világ kihívásait kezelik.
 Sudeesh Sasidharan az AWS vezető megoldási építésze, az Energy csapaton belül. Sudeesh szeret új technológiákkal kísérletezni és innovatív megoldásokat készíteni, amelyek összetett üzleti kihívásokat oldanak meg. Amikor éppen nem megoldásokat tervez, vagy a legújabb technológiákkal bütyköl, akkor a teniszpályán találkozhat a fonákján.
Sudeesh Sasidharan az AWS vezető megoldási építésze, az Energy csapaton belül. Sudeesh szeret új technológiákkal kísérletezni és innovatív megoldásokat készíteni, amelyek összetett üzleti kihívásokat oldanak meg. Amikor éppen nem megoldásokat tervez, vagy a legújabb technológiákkal bütyköl, akkor a teniszpályán találkozhat a fonákján.
 Neil Desai egy technológiai vezető, aki több mint 20 éves tapasztalattal rendelkezik a mesterséges intelligencia (AI), az adattudomány, a szoftverfejlesztés és a vállalati architektúra területén. Az AWS-nél világméretű mesterségesintelligencia-szolgáltatásokra szakosodott megoldások tervezőiből álló csapatot vezet, akik segítenek az ügyfeleknek innovatív, generatív mesterségesintelligencia-alapú megoldások kidolgozásában, a bevált gyakorlatok megosztásában az ügyfelekkel, és a termék ütemtervének kialakításában. A Vestasnál, a Honeywellnél és a Quest Diagnosticsnál betöltött korábbi szerepeiben Neil vezető szerepet töltött be olyan innovatív termékek és szolgáltatások fejlesztésében és bevezetésében, amelyek segítették a vállalatokat működésük javításában, a költségek csökkentésében és a bevételek növelésében. Szenvedélyesen használja a technológiát a valós problémák megoldására, és stratégiai gondolkodó, aki bizonyítottan sikeres.
Neil Desai egy technológiai vezető, aki több mint 20 éves tapasztalattal rendelkezik a mesterséges intelligencia (AI), az adattudomány, a szoftverfejlesztés és a vállalati architektúra területén. Az AWS-nél világméretű mesterségesintelligencia-szolgáltatásokra szakosodott megoldások tervezőiből álló csapatot vezet, akik segítenek az ügyfeleknek innovatív, generatív mesterségesintelligencia-alapú megoldások kidolgozásában, a bevált gyakorlatok megosztásában az ügyfelekkel, és a termék ütemtervének kialakításában. A Vestasnál, a Honeywellnél és a Quest Diagnosticsnál betöltött korábbi szerepeiben Neil vezető szerepet töltött be olyan innovatív termékek és szolgáltatások fejlesztésében és bevezetésében, amelyek segítették a vállalatokat működésük javításában, a költségek csökkentésében és a bevételek növelésében. Szenvedélyesen használja a technológiát a valós problémák megoldására, és stratégiai gondolkodó, aki bizonyítottan sikeres.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

