Amazon SageMaker Studio teljes körűen felügyelt megoldást kínál az adattudósok számára a gépi tanulási (ML) modellek interaktív felépítéséhez, betanításához és üzembe helyezéséhez. Az ML feladataik elvégzése során az adattudósok általában azzal kezdik a munkafolyamatot, hogy felfedezik a releváns adatforrásokat, és csatlakoznak hozzájuk. Ezt követően az SQL-t használják a különböző forrásokból származó adatok feltárására, elemzésére, megjelenítésére és integrálására, mielőtt felhasználnák azokat az ML-tanításhoz és következtetésekhez. Korábban az adatkutatók gyakran több eszközzel zsonglőrködtek, hogy támogassák az SQL-t a munkafolyamatukban, ami hátráltatta a termelékenységet.
Örömmel jelentjük be, hogy a SageMaker Studio JupyterLab notebookjai már beépített SQL-támogatással rendelkeznek. Az adattudósok most:
- Csatlakozzon a népszerű adatszolgáltatásokhoz, beleértve Amazon Athéné, Amazon RedShift, Amazon DataZoneés a Hópehely közvetlenül a jegyzetfüzetekben
- Böngésszen és keressen adatbázisok, sémák, táblázatok és nézetek között, valamint megtekintheti az adatok előnézetét a notebook felületén
- Keverje össze az SQL-t és a Python-kódot ugyanabban a notebookban az adatok hatékony feltárásához és átalakításához ML-projektekben
- Használjon fejlesztői termelékenységi funkciókat, mint például az SQL-parancsok befejezése, a kód formázási támogatása és a szintaktikai kiemelés a kódfejlesztés felgyorsítása és a fejlesztők általános termelékenységének javítása érdekében.
Ezenkívül az adminisztrátorok biztonságosan kezelhetik az ezekhez az adatszolgáltatásokhoz fűződő kapcsolatokat, lehetővé téve az adatkutatók számára, hogy hozzáférjenek a felhatalmazott adatokhoz anélkül, hogy manuálisan kellene kezelniük a hitelesítési adatokat.
Ebben a bejegyzésben végigvezetjük Önt ennek a funkciónak a SageMaker Studio-ban történő beállításán, és bemutatjuk a funkció különféle lehetőségeit. Ezután bemutatjuk, hogyan javíthatja a notebookon belüli SQL-élményt a fejlett nagy nyelvi modellek (LLM) által biztosított Text-to-SQL képességekkel, hogy összetett SQL-lekérdezéseket írhasson természetes nyelvű szöveget bemenetként használva. Végül, annak érdekében, hogy a felhasználók szélesebb közönsége SQL-lekérdezéseket generálhasson a jegyzetfüzetükben lévő természetes nyelvi bevitelből, megmutatjuk, hogyan telepítheti ezeket a szövegből SQL-be modelleket Amazon SageMaker végpontok.
Megoldás áttekintése
A SageMaker Studio JupyterLab notebook SQL-integrációjával mostantól csatlakozhat olyan népszerű adatforrásokhoz, mint a Snowflake, az Athena, az Amazon Redshift és az Amazon DataZone. Ez az új funkció különféle funkciók végrehajtását teszi lehetővé.
Vizuálisan fedezheti fel például az adatforrásokat, például adatbázisokat, táblákat és sémákat közvetlenül a JupyterLab ökoszisztémából. Ha a notebook környezete a SageMaker Distribution 1.6 vagy újabb verzióját használja, keressen egy új widgetet a JupyterLab felület bal oldalán. Ez a kiegészítés javítja az adatok hozzáférhetőségét és kezelését a fejlesztői környezetben.
Ha jelenleg nem használja a javasolt SageMaker disztribúciót (1.5 vagy régebbi) vagy nem egyéni környezetben, további információkért tekintse meg a függeléket.

Miután beállította a kapcsolatokat (a következő szakaszban látható), listázhatja az adatkapcsolatokat, böngészhet az adatbázisokban és táblákban, és megvizsgálhatja a sémákat.

A SageMaker Studio JupyterLab beépített SQL-bővítménye azt is lehetővé teszi, hogy SQL-lekérdezéseket futtasson közvetlenül egy notebookból. A Jupyter notebookok különbséget tudnak tenni az SQL és a Python kód között a %%sm_sql magic parancs, amelyet minden SQL kódot tartalmazó cella tetejére kell helyezni. Ez a parancs jelzi a JupyterLab számára, hogy a következő utasítások SQL-parancsok, nem pedig Python-kódok. A lekérdezés kimenete közvetlenül a notebookon belül jeleníthető meg, megkönnyítve az SQL és Python munkafolyamatok zökkenőmentes integrációját az adatelemzésben.
A lekérdezés kimenete vizuálisan megjeleníthető HTML-táblázatok formájában, amint az a következő képernyőképen látható.

Ezek is írhatók a pandas DataFrame.

Előfeltételek
Győződjön meg arról, hogy teljesítette a következő előfeltételeket a SageMaker Studio notebook SQL-élmény használatához:
- SageMaker Studio V2 – Győződjön meg arról, hogy a legfrissebb verziót használja SageMaker Studio domain és felhasználói profilok. Ha jelenleg a SageMaker Studio Classic verzióját használja, tekintse meg a következőt: Migráció az Amazon SageMaker Studio Classic-ról.
- IAM szerepkör – A SageMakernek szüksége van egy AWS Identity and Access Management (IAM) szerepkört kell hozzárendelni egy SageMaker Studio tartományhoz vagy felhasználói profilhoz az engedélyek hatékony kezelése érdekében. A végrehajtási szerepkör frissítése szükséges lehet az adatböngészés és az SQL futtatási szolgáltatás elindításához. A következő példa házirend lehetővé teszi a felhasználók számára, hogy engedélyezzék, listázzák és futtassák AWS ragasztó, Athéné, Amazon egyszerű tárolási szolgáltatás (Amazon S3), AWS Secrets Managerés az Amazon Redshift erőforrásai:
- JupyterLab Space – Hozzá kell férnie a frissített SageMaker Stúdióhoz és a JupyterLab Space-hez SageMaker disztribúció v1.6 vagy újabb képverziók. Ha egyéni képeket használ a JupyterLab Spaceshez vagy a SageMaker Distribution régebbi verzióihoz (v1.5 vagy régebbi), tekintse meg a függeléket a szükséges csomagok és modulok telepítéséhez, amelyek lehetővé teszik ezt a funkciót a környezetekben. Ha többet szeretne megtudni a SageMaker Studio JupyterLab Spacesről, lásd: Növelje az Amazon SageMaker Studio termelékenységét: a JupyterLab Spaces és a generatív AI-eszközök bemutatása.
- Adatforrás hozzáférési hitelesítő adatok – A SageMaker Studio notebook funkciójához felhasználói név és jelszó hozzáférés szükséges az olyan adatforrásokhoz, mint a Snowflake és az Amazon Redshift. Hozzon létre felhasználónév- és jelszóalapú hozzáférést ezekhez az adatforrásokhoz, ha még nem rendelkezik ilyennel. A Snowflake OAuth-alapú hozzáférése jelen pillanatban nem támogatott.
- SQL varázslat betöltése – Mielőtt SQL-lekérdezéseket futtatna egy Jupyter jegyzetfüzet cellájából, feltétlenül töltse be az SQL magics kiterjesztést. Használja a parancsot
%load_ext amazon_sagemaker_sql_magichogy engedélyezze ezt a funkciót. Ezenkívül futtathatja a%sm_sql?parancsot, hogy megtekinthesse az SQL cellából történő lekérdezés támogatott opcióinak átfogó listáját. Ezek a lehetőségek többek között az alapértelmezett lekérdezési korlát 1,000-es beállítása, a teljes kibontás futtatása és a lekérdezési paraméterek beillesztése. Ez a beállítás lehetővé teszi az SQL adatok rugalmas és hatékony kezelését közvetlenül a notebook környezetében.
Hozzon létre adatbázis-kapcsolatokat
A SageMaker Studio beépített SQL-böngészési és végrehajtási képességeit az AWS Glue kapcsolatok továbbfejlesztik. Az AWS Glue kapcsolat egy AWS Glue Data Catalog objektum, amely alapvető adatokat, például bejelentkezési hitelesítő adatokat, URI-karakterláncokat és virtuális privát felhő (VPC) információkat tárol bizonyos adattárolókhoz. Ezeket a kapcsolatokat az AWS Glue bejárói, a feladatok és a fejlesztési végpontok használják különféle típusú adattárak eléréséhez. Ezeket a kapcsolatokat a forrás- és a céladatokhoz egyaránt használhatja, sőt ugyanazt a kapcsolatot több bejárón keresztül is felhasználhatja, vagy kibonthatja, átalakíthatja és betöltheti (ETL) feladatokat.
Az SQL adatforrások felfedezéséhez a SageMaker Studio bal oldali ablaktáblájában először létre kell hoznia az AWS Glue kapcsolati objektumokat. Ezek a kapcsolatok megkönnyítik a különböző adatforrásokhoz való hozzáférést, és lehetővé teszik azok sematikus adatelemeinek feltárását.
A következő szakaszokban az SQL-specifikus AWS Glue csatlakozók létrehozásának folyamatát mutatjuk be. Ez lehetővé teszi az adatkészletek elérését, megtekintését és felfedezését számos adattárban. Az AWS Glue csatlakozásokkal kapcsolatos részletesebb információkért lásd: Csatlakozás az adatokhoz.
Hozzon létre egy AWS Glue kapcsolatot
Az egyetlen módja annak, hogy adatforrásokat vigyünk be a SageMaker Studio-ba, az AWS Glue kapcsolatok. AWS Glue kapcsolatokat kell létrehoznia meghatározott kapcsolattípusokkal. Jelen pillanatban ezen kapcsolatok létrehozásának egyetlen támogatott mechanizmusa a AWS parancssori interfész (AWS CLI).
Kapcsolatdefiníciós JSON-fájl
Amikor különböző adatforrásokhoz csatlakozik az AWS Glue alkalmazásban, először létre kell hoznia egy JSON-fájlt, amely meghatározza a kapcsolat tulajdonságait – a továbbiakban: kapcsolatdefiníciós fájl. Ez a fájl kulcsfontosságú az AWS Glue kapcsolat létrehozásához, és részleteznie kell az adatforrás eléréséhez szükséges összes konfigurációt. A legjobb biztonsági gyakorlatok érdekében javasoljuk, hogy a Secrets Managert használja az érzékeny információk, például a jelszavak biztonságos tárolására. Eközben más kapcsolati tulajdonságok közvetlenül kezelhetők az AWS Glue kapcsolatokon keresztül. Ez a megközelítés biztosítja az érzékeny hitelesítő adatok védelmét, miközben továbbra is elérhetővé és kezelhetővé teszi a kapcsolat konfigurációját.
A következő példa egy kapcsolatdefiníciós JSON-ra:
Amikor AWS Glue kapcsolatokat állít be adatforrásaihoz, néhány fontos irányelvet be kell tartani a funkcionalitás és a biztonság biztosítása érdekében:
- Tulajdonságok stringizálása - Belül
PythonPropertiesgombot, győződjön meg arról, hogy minden tulajdonság megvan stringed kulcs-érték párok. Nagyon fontos, hogy a dupla idézőjeleket megfelelően elkerüljük a fordított perjel () karakter használatával, ahol szükséges. Ez segít fenntartani a helyes formátumot, és elkerülni a szintaktikai hibákat a JSON-ban. - Érzékeny információk kezelése – Bár lehetséges, hogy az összes kapcsolati tulajdonságot tartalmazza
PythonProperties, nem tanácsos ezekbe a tulajdonságokba közvetlenül beletenni érzékeny adatokat, például jelszavakat. Ehelyett használja a Secrets Managert az érzékeny információk kezelésére. Ez a megközelítés úgy védi az érzékeny adatokat, hogy ellenőrzött és titkosított környezetben, a fő konfigurációs fájloktól távol tárolja azokat.
Hozzon létre egy AWS Glue kapcsolatot az AWS CLI használatával
Miután az összes szükséges mezőt felvette a kapcsolatdefiníciós JSON-fájlba, készen áll az AWS Glue kapcsolat létrehozására az adatforráshoz az AWS CLI és a következő paranccsal:
Ez a parancs új AWS Glue-kapcsolatot kezdeményez a JSON-fájlban részletezett specifikációk alapján. Az alábbiakban a parancsösszetevők gyors lebontása látható:
- -vidék – Meghatározza azt az AWS régiót, ahol az AWS Glue kapcsolat létrejön. Kulcsfontosságú annak a régiónak a kiválasztása, ahol az adatforrások és egyéb szolgáltatások találhatók, hogy minimálisra csökkentsék a késleltetést és megfeleljenek az adatok tartózkodási helyére vonatkozó követelményeknek.
- –cli-input-json file:///path/to/file/connection/definition/file.json – Ez a paraméter arra irányítja az AWS parancssori felületet, hogy beolvassa a bemeneti konfigurációt egy helyi fájlból, amely a kapcsolatdefiníciót tartalmazza JSON formátumban.
A Studio JupyterLab termináljáról az előző AWS CLI paranccsal létre kell hoznia AWS Glue kapcsolatokat. A filé menüben válasszon Új és a terminál.

Ha a create-connection parancs sikeresen lefut, látnia kell az adatforrást az SQL böngésző ablaktáblájában. Ha nem látja az adatforrást a listában, válassza a lehetőséget felfrissít a gyorsítótár frissítéséhez.
Hozzon létre egy Snowflake kapcsolatot
Ebben a részben a Snowflake adatforrás és a SageMaker Studio integrálására összpontosítunk. A Snowflake-fiókok, adatbázisok és raktárak létrehozása nem tartozik ennek a bejegyzésnek a körébe. A Snowflake használatának megkezdéséhez tekintse meg a Snowflake használati útmutató. Ebben a bejegyzésben egy Snowflake definíciós JSON-fájl létrehozására és egy Snowflake adatforrás-kapcsolat létrehozására összpontosítunk az AWS ragasztó használatával.
Hozzon létre egy Secrets Manager titkot
A Snowflake fiókhoz felhasználói azonosító és jelszó vagy privát kulcsok használatával csatlakozhat. A felhasználói azonosítóval és jelszóval történő csatlakozáshoz biztonságosan tárolnia kell hitelesítő adatait a Titkokkezelőben. Amint azt korábban említettük, bár ezek az információk beágyazhatók a PythonProperties alá, nem ajánlott az érzékeny információkat egyszerű szöveges formátumban tárolni. Mindig győződjön meg arról, hogy az érzékeny adatokat biztonságosan kezeli a potenciális biztonsági kockázatok elkerülése érdekében.
Ha információkat szeretne tárolni a Secrets Managerben, tegye a következőket:
- A Secrets Manager konzolon válassza a lehetőséget Tárolj el egy új titkot.
- A Titkos típus, választ Más típusú titok.
- A kulcs-érték párhoz válassza a lehetőséget Egyszerű szöveg és írja be a következőket:
- Adja meg a titok nevét, például
sm-sql-snowflake-secret. - Hagyja a többi beállítást alapértelmezettként, vagy módosítsa, ha szükséges.
- Hozd létre a titkot.
Hozzon létre egy AWS Glue kapcsolatot a Snowflake számára
Amint azt korábban tárgyaltuk, az AWS Glue kapcsolatok elengedhetetlenek a SageMaker Studio bármely kapcsolatának eléréséhez. Megtalálhatja a listát a Snowflake összes támogatott csatlakozási tulajdonsága. Az alábbiakban egy minta kapcsolatdefiníció JSON a Snowflake számára. Cserélje le a helyőrző értékeket a megfelelő értékekkel, mielőtt lemezre menti:
A Snowflake adatforráshoz AWS Glue csatlakozási objektum létrehozásához használja a következő parancsot:
Ez a parancs új Snowflake adatforrás-kapcsolatot hoz létre az SQL böngésző ablaktáblájában, amely böngészhető, és SQL-lekérdezéseket futtathat ellene a JupyterLab jegyzetfüzet cellájából.

Hozzon létre egy Amazon Redshift kapcsolatot
Az Amazon Redshift egy teljesen felügyelt, petabyte méretű adattárház szolgáltatás, amely leegyszerűsíti és csökkenti az összes adat szabványos SQL használatával történő elemzésének költségeit. Az Amazon Redshift kapcsolat létrehozásának eljárása szorosan tükrözi a Snowflake kapcsolat eljárását.
Hozzon létre egy Secrets Manager titkot
A Snowflake beállításához hasonlóan, ha felhasználói azonosítóval és jelszóval szeretne csatlakozni az Amazon Redshifthez, biztonságosan kell tárolnia a titkos információkat a Secrets Managerben. Hajtsa végre a következő lépéseket:
- A Secrets Manager konzolon válassza a lehetőséget Tárolj el egy új titkot.
- A Titkos típus, választ Az Amazon Redshift-fürt hitelesítő adatai.
- Adja meg a bejelentkezéshez használt hitelesítő adatokat az Amazon Redshift adatforrásként való eléréséhez.
- Válassza ki a titkokhoz társított Vöröseltolódás-fürtöt.
- Adjon meg egy nevet a titoknak, például
sm-sql-redshift-secret. - Hagyja a többi beállítást alapértelmezettként, vagy módosítsa, ha szükséges.
- Hozd létre a titkot.
Az alábbi lépések követésével megbizonyosodhat arról, hogy kapcsolati hitelesítő adatait biztonságosan kezeli, és az AWS robusztus biztonsági funkcióit használja az érzékeny adatok hatékony kezelésére.
Hozzon létre egy AWS Glue kapcsolatot az Amazon Redshift számára
Ha egy JSON-definícióval szeretne kapcsolatot létrehozni az Amazon Redshifttel, töltse ki a szükséges mezőket, és mentse a következő JSON-konfigurációt lemezre:
A Redshift adatforráshoz AWS Glue csatlakozási objektum létrehozásához használja a következő AWS CLI parancsot:
Ez a parancs kapcsolatot hoz létre az AWS Glue-ban, amely a Redshift adatforráshoz kapcsolódik. Ha a parancs sikeresen lefut, láthatja a Redshift adatforrást a SageMaker Studio JupyterLab jegyzetfüzetében, amely készen áll az SQL-lekérdezések futtatására és az adatelemzés végrehajtására.

Hozzon létre egy Athena kapcsolatot
Az Athena egy teljesen felügyelt SQL lekérdezési szolgáltatás az AWS-től, amely lehetővé teszi az Amazon S3-ban tárolt adatok szabványos SQL használatával történő elemzését. Ha Athena-kapcsolatot szeretne beállítani adatforrásként a JupyterLab-jegyzetfüzet SQL-böngészőjében, létre kell hoznia egy Athena-minta kapcsolatdefiníciós JSON-t. A következő JSON-struktúra konfigurálja az Athena-hoz való csatlakozáshoz szükséges részleteket, megadva az adatkatalógust, az S3 állomáscímtárat és a régiót:
AWS Glue kapcsolati objektum létrehozásához az Athena adatforráshoz használja a következő AWS CLI parancsot:
Ha a parancs sikeres, akkor közvetlenül a SageMaker Studio JupyterLab notebook SQL böngészőjéből érheti el az Athena adatkatalógust és a táblázatokat.

Adatok lekérdezése több forrásból
Ha több adatforrás van integrálva a SageMaker Studio-ba a beépített SQL-böngészőn és a notebook SQL-szolgáltatásán keresztül, akkor gyorsan futtathat lekérdezéseket, és könnyedén válthat az adatforrás-háttérprogramok között a jegyzetfüzet következő celláiban. Ez a képesség zökkenőmentes átmenetet tesz lehetővé a különböző adatbázisok vagy adatforrások között az elemzési munkafolyamat során.
Lekérdezéseket futtathat az adatforrás-háttérrendszerek változatos gyűjteményében, és az eredményeket közvetlenül a Python-térbe viheti további elemzés vagy megjelenítés céljából. Ezt segíti elő a %%sm_sql magic parancs elérhető a SageMaker Studio notebookokban. Az SQL-lekérdezés eredményeinek egy pandas DataFrame-be történő kiadásához két lehetőség van:
- A notebook cella eszköztáráról válassza ki a kimenet típusát DataFrame és nevezze el a DataFrame változót
- Adja hozzá a következő paramétert az Önhöz
%%sm_sqlparancs:
A következő diagram szemlélteti ezt a munkafolyamatot, és bemutatja, hogyan futtathat könnyedén lekérdezéseket különböző forrásokból a következő jegyzetfüzet celláiban, valamint hogyan taníthat meg egy SageMaker-modellt betanítási feladatok segítségével vagy közvetlenül a notebookon belül helyi számítással. Ezenkívül a diagram rávilágít arra, hogy a SageMaker Studio beépített SQL-integrációja hogyan egyszerűsíti le a kinyerési és felépítési folyamatokat közvetlenül a JupyterLab notebook cellák ismerős környezetében.

Szöveg SQL-be: Természetes nyelv használata a lekérdezéskészítés javítására
Az SQL egy összetett nyelv, amely megköveteli az adatbázisok, táblák, szintaxisok és metaadatok megértését. Manapság a generatív mesterséges intelligencia (AI) lehetővé teszi, hogy összetett SQL-lekérdezéseket írjon anélkül, hogy mélyreható SQL-tapasztalatra lenne szüksége. Az LLM-ek fejlődése jelentősen befolyásolta a természetes nyelvi feldolgozáson (NLP) alapuló SQL-generálást, lehetővé téve precíz SQL-lekérdezések létrehozását természetes nyelvi leírásokból – ezt a technikát Text-to-SQL-nek nevezik. Elengedhetetlen azonban az emberi nyelv és az SQL közötti eredendő különbségek elismerése. Az emberi nyelv néha kétértelmű vagy pontatlan lehet, míg az SQL strukturált, explicit és egyértelmű. Ennek a szakadéknak az áthidalása és a természetes nyelv SQL-lekérdezésekké való pontos konvertálása óriási kihívást jelenthet. Ha megfelelő utasításokat kapnak, az LLM-ek segíthetnek áthidalni ezt a szakadékot azáltal, hogy megértik az emberi nyelv mögött meghúzódó szándékot, és ennek megfelelően pontos SQL-lekérdezéseket generálnak.
A SageMaker Studio notebook SQL-lekérdezési funkciójának kiadásával a SageMaker Studio egyszerűvé teszi az adatbázisok és sémák vizsgálatát, valamint az SQL-lekérdezések készítését, futtatását és hibakeresését anélkül, hogy elhagyná a Jupyter notebook IDE-t. Ez a rész azt vizsgálja, hogy a haladó LLM-ek Text-to-SQL képességei hogyan könnyíthetik meg az SQL-lekérdezések generálását természetes nyelven a Jupyter notebookokon belül. A legmodernebb Text-to-SQL modellt alkalmazzuk defog/sqlcoder-7b-2 a Jupyter AI-vel együtt, egy generatív AI-asszisztenssel, amelyet kifejezetten Jupyter notebookokhoz terveztek, hogy összetett SQL-lekérdezéseket hozzon létre természetes nyelvből. Ennek a fejlett modellnek a használatával könnyedén és hatékonyan hozhatunk létre összetett SQL-lekérdezéseket természetes nyelv használatával, ezáltal javítva az SQL-élményünket a notebookokon belül.
Notebook prototípus készítése a Hugging Face Hub segítségével
A prototípuskészítés megkezdéséhez a következőkre lesz szüksége:
- GitHub kód – Az ebben a részben bemutatott kód a következőkben érhető el GitHub repo és hivatkozva a példafüzet.
- JupyterLab Space – A GPU-alapú példányokkal támogatott SageMaker Studio JupyterLab Space elérése elengedhetetlen. A
defog/sqlcoder-7b-2modell esetén egy 7B paraméteres modell javasolt, egy ml.g5.2xlarge példány használatával. Alternatívák, mint pldefog/sqlcoder-70b-alpha vagydefog/sqlcoder-34b-alphatermészetes nyelvből SQL-be való konverzióhoz is életképesek, de a prototípusok készítéséhez nagyobb példánytípusokra lehet szükség. Győződjön meg arról, hogy rendelkezik a GPU által támogatott példány indításához szükséges kvótával. Ehhez navigáljon a Service Kvóták konzolra, keresse meg a SageMaker kifejezést, és keressen ráStudio JupyterLab Apps running on <instance type>.
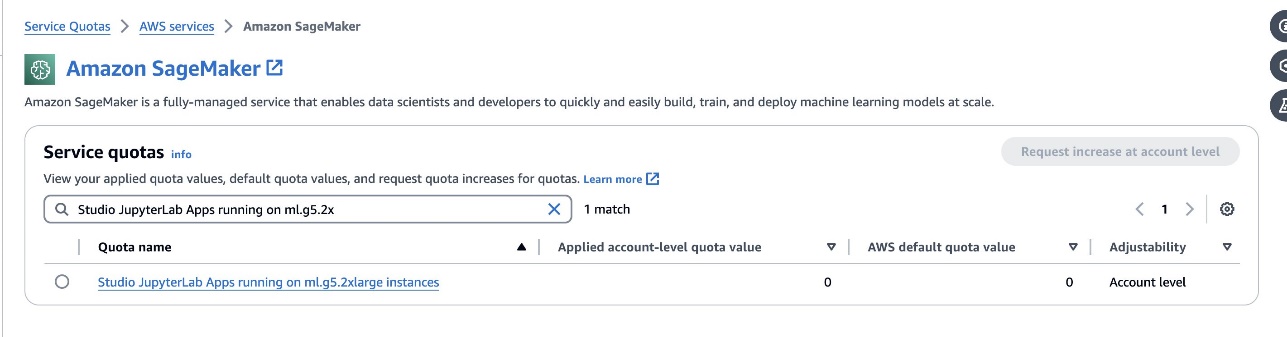
Indítson el egy új, GPU-val támogatott JupyterLab Space-t a SageMaker Studio-ból. Javasoljuk, hogy hozzon létre egy új JupyterLab Space-t legalább 75 GB tárhellyel Amazon Elastic Block Store (Amazon EBS) tároló 7B paraméteres modellhez.


- Átölelő Arc Hub – Ha a SageMaker Studio tartomány rendelkezik hozzáféréssel modellek letöltéséhez a Átölelő Arc Hub, használhatja a
AutoModelForCausalLMosztályból ölelőarc/transzformátorok a modellek automatikus letöltéséhez és a helyi GPU-hoz rögzítéséhez. A modellsúlyok a helyi gép gyorsítótárában lesznek tárolva. Lásd a következő kódot:
A modell teljes letöltése és memóriába való betöltése után meg kell figyelnie a GPU kihasználtságának növekedését a helyi gépen. Ez azt jelzi, hogy a modell aktívan használja a GPU-erőforrásokat számítási feladatokhoz. Ezt futtatással ellenőrizheti a saját JupyterLab-területén nvidia-smi (egyszeri megjelenítéshez) ill nvidia-smi —loop=1 (másodpercenként ismételni) a JupyterLab terminálról.

Szöveg-SQL modellek kiválóak a felhasználói kérés szándékának és kontextusának megértésében, még akkor is, ha a használt nyelv társalgási vagy kétértelmű. A folyamat magában foglalja a természetes nyelvi bemenetek lefordítását a megfelelő adatbázisséma elemekre, például táblanevekre, oszlopnevekre és feltételekre. Egy kész szöveg-SQL-modell azonban nem ismeri az adattárház szerkezetét, a konkrét adatbázissémákat, és nem tudja pontosan értelmezni egy tábla tartalmát pusztán oszlopnevek alapján. Ahhoz, hogy ezeket a modelleket hatékonyan használhassuk praktikus és hatékony SQL-lekérdezések természetes nyelvből történő előállításához, az SQL szöveggenerálási modellt hozzá kell igazítani az adott raktári adatbázissémához. Ezt az alkalmazkodást megkönnyíti a használata LLM kéri. A következő egy ajánlott prompt sablon a defog/sqlcoder-7b-2 Text-to-SQL modellhez, négy részre osztva:
- Feladat – Ebben a szakaszban meg kell határozni egy magas szintű feladatot, amelyet a modellnek el kell végeznie. Tartalmaznia kell az adatbázis-háttérrendszer típusát (például Amazon RDS, PostgreSQL vagy Amazon Redshift), hogy a modell tisztában legyen minden olyan árnyalt szintaktikai különbséggel, amely befolyásolhatja a végső SQL-lekérdezés generálását.
- Utasítás – Ennek a szakasznak meg kell határoznia a modell feladathatárait és tartománytudatát, és néhány példát is tartalmazhat, amelyek útmutatást nyújtanak a modellnek a finomhangolt SQL-lekérdezések generálásában.
- Adatbázis séma – Ennek a szakasznak részleteznie kell a raktári adatbázis-sémákat, felvázolva a táblák és oszlopok közötti kapcsolatokat, hogy segítse a modellt az adatbázis-struktúra megértésében.
- Válasz – Ez a szakasz annak a modellnek van fenntartva, amely az SQL lekérdezési választ a természetes nyelvi bemenetre adja ki.
Az ebben a részben használt adatbázissémára és promptra egy példa a következő helyen található: GitHub Repo.
Az azonnali tervezés nem csupán kérdések vagy kijelentések kialakítását jelenti; ez egy árnyalt művészet és tudomány, amely jelentősen befolyásolja az AI-modellel folytatott interakciók minőségét. A felszólítás elkészítésének módja mélyen befolyásolhatja az AI válaszának jellegét és hasznosságát. Ez a készség kulcsfontosságú a mesterséges intelligencia interakcióiban rejlő lehetőségek maximalizálásában, különösen olyan összetett feladatoknál, amelyek speciális megértést és részletes válaszokat igényelnek.
Fontos, hogy lehetőség legyen a modell válaszának gyors felépítésére és tesztelésére egy adott prompt esetén, valamint a válasz alapján a prompt optimalizálására. A JupyterLab notebookok lehetővé teszik, hogy azonnali modell-visszajelzést kapjanak egy helyi számításon futó modelltől, és optimalizálják a felszólítást, és tovább hangolják a modell válaszát, vagy teljesen módosítsák a modellt. Ebben a bejegyzésben az ml.g5.2xlarge NVIDIA A10G 24 GB-os GPU-jával támogatott SageMaker Studio JupyterLab notebookot használunk szöveg-SQL modellkövetkeztetés futtatásához a notebookon, és interaktív módon építjük fel a modellpromptunkat, amíg a modell válasza kellően hangolásra nem kerül, hogy biztosítsa. olyan válaszok, amelyek közvetlenül végrehajthatók a JupyterLab SQL celláiban. A modellkövetkeztetés futtatásához és a modellválaszok egyidejű streameléséhez a következők kombinációját használjuk model.generate és a TextIteratorStreamer a következő kódban meghatározottak szerint:
A modell kimenete SageMaker SQL varázslattal díszíthető %%sm_sql ..., amely lehetővé teszi a JupyterLab notebook számára, hogy a cellát SQL cellaként azonosítsa.
Szöveg-SQL-modelleket fogadjon SageMaker végpontként
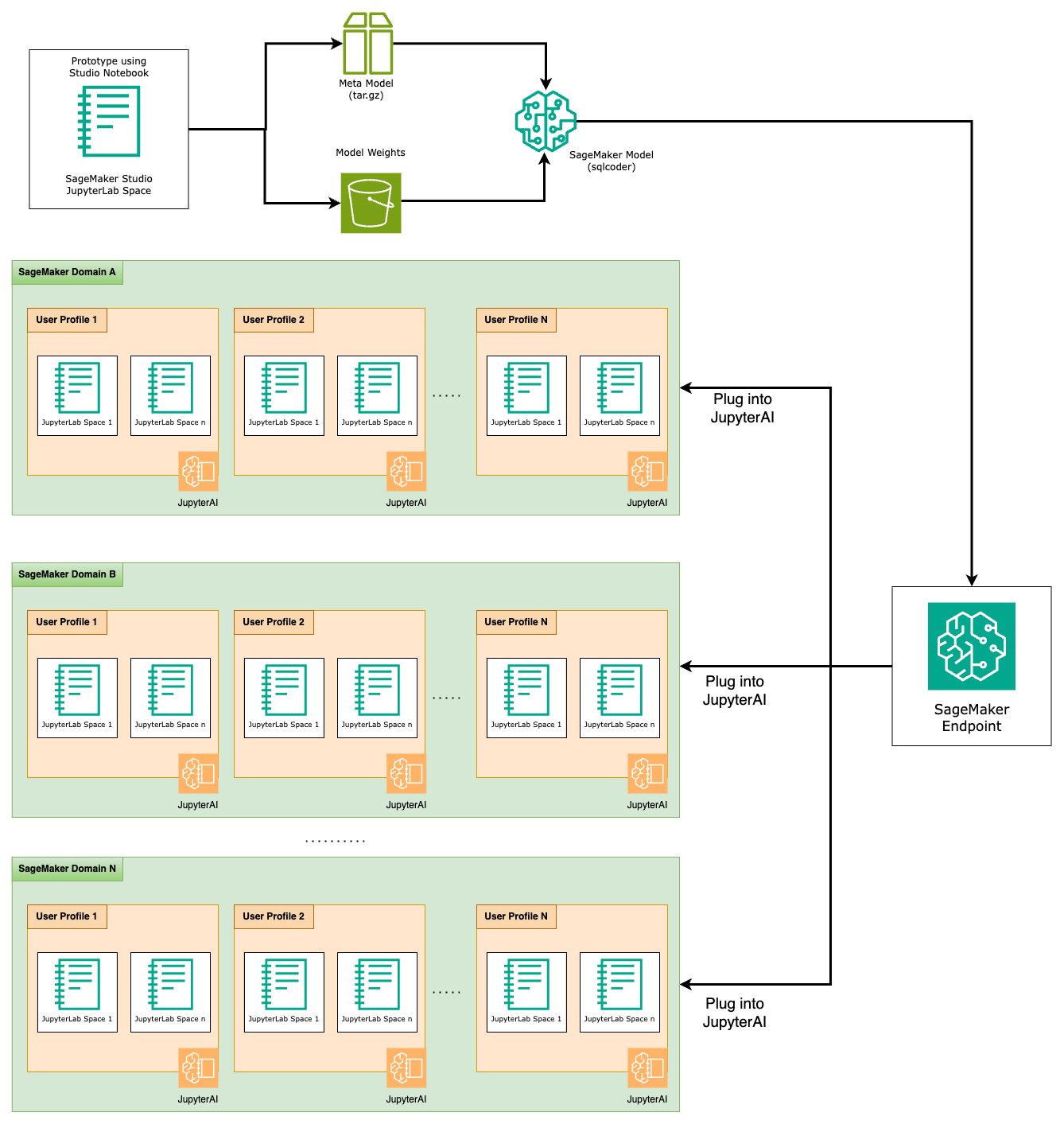
A prototípuskészítési szakasz végén kiválasztottuk az előnyben részesített Text-to-SQL LLM-ünket, egy hatékony prompt formátumot és egy megfelelő példánytípust a modell tárolására (egy GPU-s vagy több GPU-s). A SageMaker megkönnyíti az egyéni modellek méretezhető tárolását a SageMaker végpontok használatával. Ezek a végpontok meghatározott kritériumok szerint határozhatók meg, lehetővé téve az LLM-ek végpontként történő telepítését. Ez a képesség lehetővé teszi a megoldás szélesebb közönségre skálázását, lehetővé téve a felhasználók számára, hogy SQL-lekérdezéseket generáljanak természetes nyelvi bemenetekből egyéni hosztolt LLM-ek segítségével. A következő diagram ezt az architektúrát szemlélteti.
Ahhoz, hogy LLM-jét SageMaker-végpontként tárolja, több műterméket kell létrehoznia.
Az első műtermék a modellsúlyok. SageMaker Deep Java Library (DJL) szolgáltatás konténerek lehetővé teszik a konfigurációk beállítását egy meta segítségével kiszolgáló.tulajdonságok fájl, amely lehetővé teszi, hogy irányítsa a modellek beszerzési módját – akár közvetlenül a Hugging Face Hubról, akár a modelltermékek letöltésével az Amazon S3-ról. Ha megadod model_id=defog/sqlcoder-7b-2, a DJL Serving megpróbálja közvetlenül letölteni ezt a modellt a Hugging Face Hubról. Azonban a végpont minden egyes üzembe helyezésekor vagy rugalmas méretezésekor hálózati be-/kilépési díjak merülhetnek fel. A költségek elkerülése és a modellműtermékek letöltésének felgyorsítása érdekében javasoljuk, hogy hagyja ki a használatát model_id in serving.properties és mentse el a modellsúlyokat S3 műtermékként, és csak a következővel adja meg őket s3url=s3://path/to/model/bin.
A modell (a tokenizátorral együtt) lemezre mentése és az Amazon S3-ra való feltöltése néhány sornyi kóddal elvégezhető:
Használhat adatbázis-prompt fájlt is. Ebben a beállításban az adatbázis prompt a következőkből áll Task, Instructions, Database Schemaés Answer sections. A jelenlegi architektúra esetén minden adatbázissémához külön prompt fájlt rendelünk. Ez a beállítás azonban rugalmasan bővíthető úgy, hogy promptfájlonként több adatbázist is magában foglaljon, lehetővé téve a modell számára, hogy összetett összekapcsolásokat futtasson ugyanazon a kiszolgálón lévő adatbázisok között. A prototípuskészítési szakaszban az adatbázis promptot elmentjük egy szöveges fájlként <Database-Glue-Connection-Name>.prompt, Ahol Database-Glue-Connection-Name megfelel a JupyterLab környezetben látható kapcsolatnévnek. Például ez a bejegyzés egy Snowflake nevű kapcsolatra hivatkozik Airlines_Dataset, így az adatbázis prompt fájl neve Airlines_Dataset.prompt. Ezt a fájlt az Amazon S3 tárolja, majd a modellkiszolgáló logikánk beolvassa és gyorsítótárazza.
Ezenkívül ez az architektúra lehetővé teszi a végpont bármely jogosult felhasználója számára, hogy természetes nyelvet definiáljon, tároljon és generáljon SQL-lekérdezésekhez anélkül, hogy a modell többszöri újratelepítésére lenne szükség. A következőket használjuk példa egy adatbázis promptra a Text-to-SQL funkció bemutatására.
Ezután egyéni modellszolgáltatási logikát kell létrehozni. Ebben a részben egy elnevezésű egyéni következtetési logikát vázol fel modell.py. Ez a szkript a szöveg-SQL szolgáltatásaink teljesítményének és integrációjának optimalizálására szolgál:
- Határozza meg az adatbázis-prompt fájl gyorsítótárazási logikáját – A késleltetés minimalizálása érdekében egyéni logikát alkalmazunk az adatbázis-prompt fájlok letöltéséhez és gyorsítótárazásához. Ez a mechanizmus gondoskodik arról, hogy az értesítések könnyen elérhetőek legyenek, csökkentve a gyakori letöltésekkel járó többletköltséget.
- Egyéni modellkövetkeztetési logika meghatározása – A következtetési sebesség növelése érdekében a szöveg-SQL-modellünket float16 precíziós formátumban töltjük be, majd DeepSpeed modellré alakítjuk. Ez a lépés hatékonyabb számítást tesz lehetővé. Ezenkívül ezen a logikán belül megadhatja, hogy a felhasználók mely paramétereket állíthatják be a következtetési hívások során, hogy a funkcionalitást igényeiknek megfelelően szabják.
- Egyéni bemeneti és kimeneti logika meghatározása – Az egyértelmű és testreszabott bemeneti/kimeneti formátumok létrehozása elengedhetetlen a későbbi alkalmazásokkal való zökkenőmentes integrációhoz. Az egyik ilyen alkalmazás a JupyterAI, amelyet a következő részben tárgyalunk.
Ezen kívül tartalmazzuk a serving.properties fájl, amely globális konfigurációs fájlként működik a DJL-szolgáltatást használó modelleknél. További információkért lásd: Konfigurációk és beállítások.
Végül beillesztheti a requirements.txt fájlt a következtetéshez szükséges további modulok meghatározásához, és mindent egy tarballba csomagol a telepítéshez.
Lásd a következő kódot:
Integrálja végpontját a SageMaker Studio Jupyter AI-asszisztenssel
Jupyter AI egy nyílt forráskódú eszköz, amely a generatív mesterséges intelligenciát juttatja el a Jupyter notebookokhoz, robusztus és felhasználóbarát platformot kínálva a generatív AI modellek felfedezéséhez. Növeli a JupyterLab és a Jupyter notebookok termelékenységét azáltal, hogy olyan funkciókat biztosít, mint a %%ai varázslat generatív mesterséges intelligencia-játszótér létrehozásához a notebookok belsejében, a JupyterLab natív csevegőfelülete az AI-vel való interakcióhoz, mint beszélgetési asszisztens, valamint a LLM-ek széles skálájának támogatása a szolgáltatók kedvelik Amazon Titan, AI21, Anthropic, Cohere és Hugging Face vagy kezelt szolgáltatások, mint pl Amazon alapkőzet és a SageMaker végpontokat. Ebben a bejegyzésben a Jupyter AI beépített integrációját használjuk a SageMaker végpontokkal, hogy a Text-to-SQL képességet bevigyük a JupyterLab notebookokba. A Jupyter AI eszköz előre telepítve van az összes SageMaker Studio JupyterLab Space-ben, amelyet a SageMaker Distribution képek; a végfelhasználóknak nem kell további konfigurációkat elvégezniük ahhoz, hogy elkezdjék használni a Jupyter AI-bővítményt a SageMaker által üzemeltetett végponttal való integrációhoz. Ebben a részben az integrált Jupyter AI eszköz használatának két módját tárgyaljuk.
Jupyter AI egy notebook belsejében varázslatok segítségével
Jupyter AI %%ai A magic parancs lehetővé teszi, hogy SageMaker Studio JupyterLab notebookjait reprodukálható generatív AI környezetté alakítsa. Az AI varázslatok használatának megkezdéséhez győződjön meg arról, hogy a használathoz betöltötte a jupyter_ai_magics kiterjesztést %%ai varázslat, és emellett terhelés amazon_sagemaker_sql_magic használata %%sm_sql varázslat:
Hívás futtatásához a SageMaker végponthoz a notebookból a %%ai magic parancsot, adja meg a következő paramétereket, és a következőképpen strukturálja fel a parancsot:
- –régiónév – Adja meg a régiót, ahol a végpont telepítve van. Ez biztosítja, hogy a kérés a megfelelő földrajzi helyre kerüljön továbbításra.
- –kérés-séma – Tartalmazza a bemeneti adatok sémáját. Ez a séma felvázolja azoknak a bemeneti adatoknak a várható formátumát és típusait, amelyekre a modellnek szüksége van a kérés feldolgozásához.
- –válasz-útvonal – Határozza meg azt az útvonalat a válaszobjektumban, ahol a modell kimenete található. Ez az elérési út a releváns adatok kinyerésére szolgál a modell által visszaadott válaszból.
- -f (nem kötelező) - Ez egy kimeneti formázó zászló, amely jelzi a modell által visszaadott kimenet típusát. A Jupyter-jegyzetfüzet kontextusában, ha a kimenet kód, ezt a jelzőt ennek megfelelően kell beállítani, hogy a kimenetet végrehajtható kódként formázza a Jupyter-jegyzetfüzet cellájának tetején, majd egy szabad szövegbeviteli területet a felhasználói interakcióhoz.
Például a Jupyter jegyzetfüzet cellájában lévő parancs a következő kódhoz hasonlíthat:
Jupyter AI chat ablak
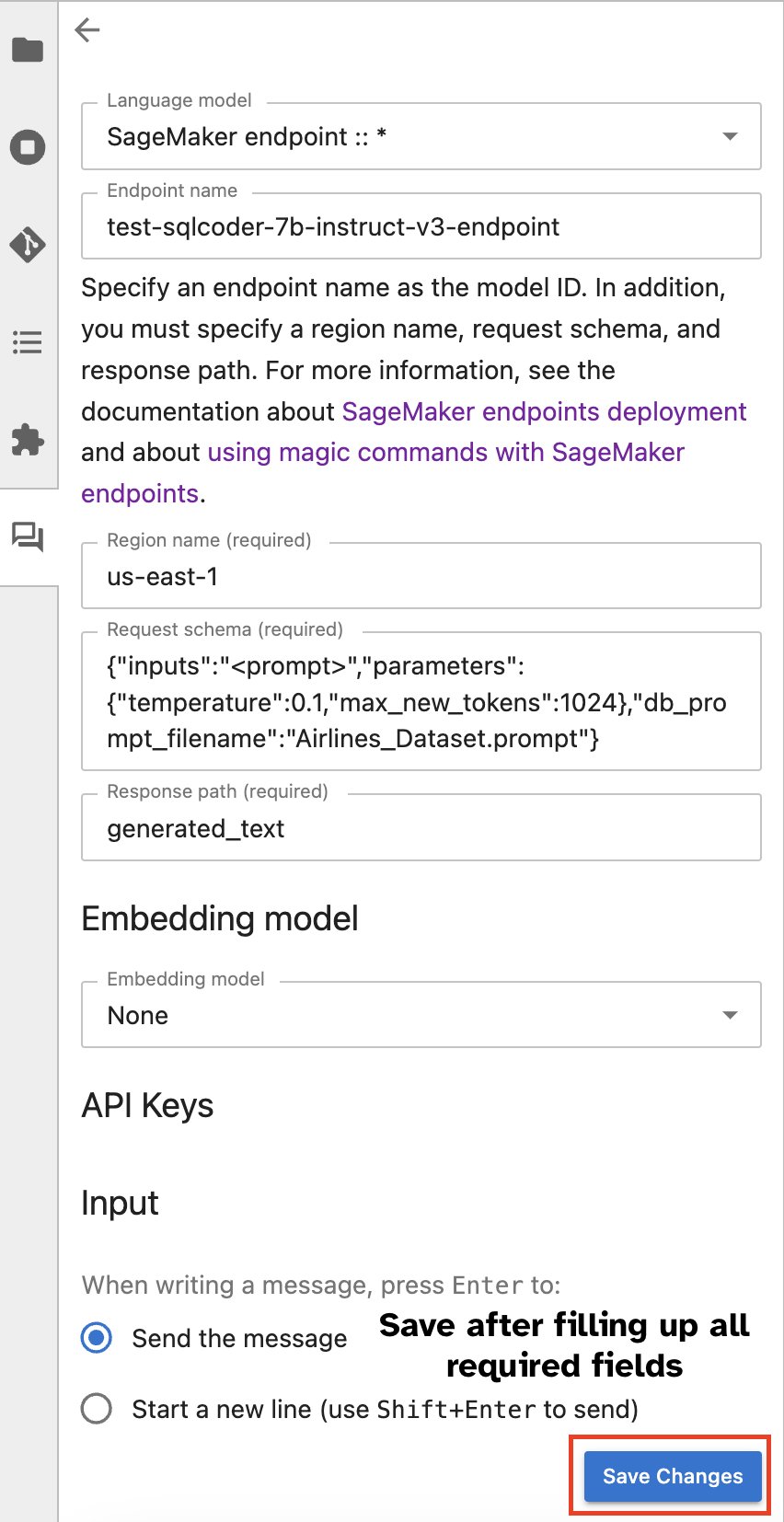
Alternatív megoldásként a SageMaker végpontjaival egy beépített felhasználói felületen keresztül kommunikálhat, leegyszerűsítve a lekérdezések generálását vagy a párbeszédet. Mielőtt elkezdené a csevegést a SageMaker-végponttal, konfigurálja a Jupyter AI-ben a SageMaker-végpont megfelelő beállításait, a következő képernyőképen látható módon.
 |
 |
Következtetés
A SageMaker Studio most leegyszerűsíti és leegyszerűsíti az adattudós munkafolyamatot az SQL támogatás JupyterLab notebookokba való integrálásával. Ez lehetővé teszi az adattudósok számára, hogy a feladataikra összpontosítsanak anélkül, hogy több eszközt kellene kezelniük. Ezenkívül a SageMaker Studio új beépített SQL-integrációja lehetővé teszi az adatszemélyek számára, hogy könnyedén generáljanak SQL-lekérdezéseket természetes nyelvű szöveg bemeneti használatával, ezáltal felgyorsítva munkafolyamatukat.
Javasoljuk, hogy fedezze fel ezeket a funkciókat a SageMaker Studio-ban. További információkért lásd: Adatok előkészítése SQL-lel a Studio alkalmazásban.
Függelék
Engedélyezze az SQL-böngészőt és a notebook SQL-cellát egyéni környezetekben
Ha nem SageMaker Distribution lemezképet vagy 1.5-ös vagy régebbi Distribution lemezképet használ, futtassa a következő parancsokat az SQL böngészési funkció engedélyezéséhez a JupyterLab környezetben:
Helyezze át az SQL böngésző widgetet
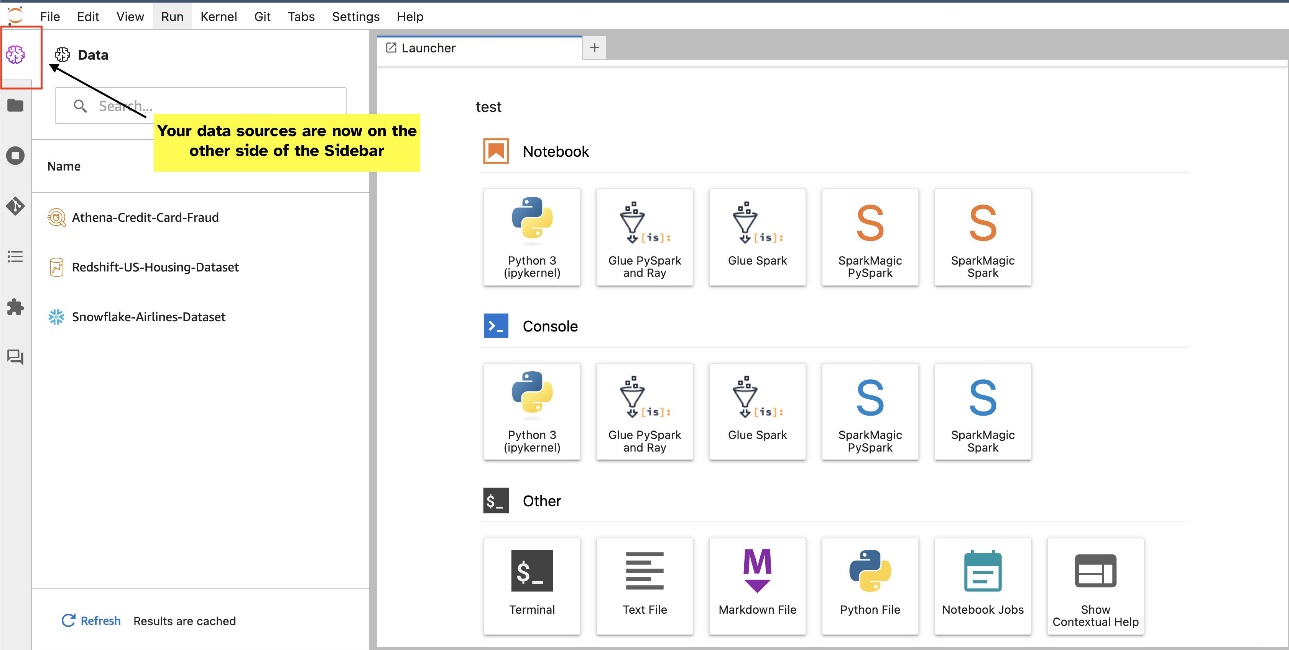
A JupyterLab widgetek lehetővé teszik az áthelyezést. A preferenciáktól függően a modulokat áthelyezheti a JupyterLab widgetek ablaktáblájának mindkét oldalára. Ha úgy tetszik, az SQL widget irányát az oldalsáv ellentétes oldalára (jobbról balra) mozgathatja. Ehhez egyszerűen kattintson a jobb gombbal a widget ikonjára, és válassza a Kapcsolja az oldalsáv oldalát.
 |
 |
A szerzőkről
 Pranav Murthy AI/ML Specialist Solutions Architect az AWS-nél. Arra összpontosít, hogy segítse az ügyfeleket a gépi tanulási (ML) munkaterhelések felépítésében, betanításában, üzembe helyezésében és a SageMakerre való migrálásában. Korábban a félvezetőiparban dolgozott nagy számítógépes látás (CV) és természetes nyelvi feldolgozási (NLP) modellek fejlesztésével a félvezető folyamatok fejlesztésére a legkorszerűbb ML technikák segítségével. Szabadidejében szívesen sakkozik és utazik. Pranav-ot megtalálod itt LinkedIn.
Pranav Murthy AI/ML Specialist Solutions Architect az AWS-nél. Arra összpontosít, hogy segítse az ügyfeleket a gépi tanulási (ML) munkaterhelések felépítésében, betanításában, üzembe helyezésében és a SageMakerre való migrálásában. Korábban a félvezetőiparban dolgozott nagy számítógépes látás (CV) és természetes nyelvi feldolgozási (NLP) modellek fejlesztésével a félvezető folyamatok fejlesztésére a legkorszerűbb ML technikák segítségével. Szabadidejében szívesen sakkozik és utazik. Pranav-ot megtalálod itt LinkedIn.
 Varun Shah szoftvermérnök, az Amazon SageMaker Studio-n dolgozik az Amazon Web Servicesnél. Olyan interaktív ML megoldások kidolgozására összpontosít , amelyek leegyszerűsítik az adatfeldolgozást és az adat - előkészítést . Szabadidejében Varun élvezi a szabadtéri tevékenységeket, beleértve a túrázást és a síelést, és mindig készen áll új, izgalmas helyek felfedezésére.
Varun Shah szoftvermérnök, az Amazon SageMaker Studio-n dolgozik az Amazon Web Servicesnél. Olyan interaktív ML megoldások kidolgozására összpontosít , amelyek leegyszerűsítik az adatfeldolgozást és az adat - előkészítést . Szabadidejében Varun élvezi a szabadtéri tevékenységeket, beleértve a túrázást és a síelést, és mindig készen áll új, izgalmas helyek felfedezésére.
 Sumedha Swamy az Amazon Web Services fő termékmenedzsere, ahol a SageMaker Studio csapatának vezetője az adattudomány és a gépi tanulás számára választott IDE fejlesztése. Az elmúlt 15 évben a Machine Learning alapú fogyasztói és vállalati termékek építésének szentelte.
Sumedha Swamy az Amazon Web Services fő termékmenedzsere, ahol a SageMaker Studio csapatának vezetője az adattudomány és a gépi tanulás számára választott IDE fejlesztése. Az elmúlt 15 évben a Machine Learning alapú fogyasztói és vállalati termékek építésének szentelte.
 Bosco Albuquerque az AWS Sr. Partner Solutions Architect, és több mint 20 éves tapasztalattal rendelkezik a vállalati adatbázis-szállítók és felhőszolgáltatók adatbázis- és elemzési termékeivel kapcsolatban. Segített technológiai cégeknek adatelemzési megoldások és termékek tervezésében és bevezetésében.
Bosco Albuquerque az AWS Sr. Partner Solutions Architect, és több mint 20 éves tapasztalattal rendelkezik a vállalati adatbázis-szállítók és felhőszolgáltatók adatbázis- és elemzési termékeivel kapcsolatban. Segített technológiai cégeknek adatelemzési megoldások és termékek tervezésében és bevezetésében.
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/explore-data-with-ease-using-sql-and-text-to-sql-in-amazon-sagemaker-studio-jupyterlab-notebooks/

