This post is cowritten by Shirsha Ray Chaudhuri, Harpreet Singh Baath, Rashmi B Pawar, and Palvika Bansal from Thomson Reuters.
Thomson Reuters (TR), a global content and technology-driven company, has been using artificial intelligence (AI) and machine learning (ML) in its professional information products for decades. Thomson Reuters Labs, the company’s dedicated innovation team, has been integral to its pioneering work in AI and natural language processing (NLP). A key milestone was the launch of Westlaw Is Natural (WIN) in 1992. This technology was one of the first of its kind, using NLP for more efficient and natural legal research. Fast forward to 2023, and Thomson Reuters continues to define the future of professionals through rapid innovation, creative solutions, and powerful technology.
The introduction of generative AI provides another opportunity for Thomson Reuters to work with customers and once again advance how they do their work, helping professionals draw insights and automate workflows, enabling them to focus their time where it matters most. While Thomson Reuters pushes the boundaries of what generative AI and other technologies could do for the modern professional, how is it using the power of this technology for its own teams?
Thomson Reuters is highly focused on driving awareness and understanding of AI among colleagues in every team and every business area. Starting from foundational principles of what is AI and how does ML work, it’s delivering a rolling program of company-wide AI awareness sessions, including webinars, training materials, and panel discussions. During these sessions, ideas on how AI could be used started to surface as colleagues considered how to use tools that helped them use AI for their day-to-day tasks as well as serve their customers.
In this post, we discuss how Thomson Reuters Labs created Open Arena, Thomson Reuters’s enterprise-wide large language model (LLM) playground that was developed in collaboration with AWS. The original concept came out of an AI/ML Hackathon supported by Simone Zucchet (AWS Solutions Architect) and Tim Precious (AWS Account Manager) and was developed into production using AWS services in under 6 weeks with support from AWS. AWS-managed services such as AWS Lambda, Amazon DynamoDB, and Amazon SageMaker, as well as the pre-built Hugging Face Deep Learning Containers (DLCs), contributed to the pace of innovation. Open Arena has helped unlock company-wide experimentation with generative AI in a safe and controlled environment.
Diving deeper, Open Arena is a web-based playground that allows users to experiment with a growing set of tools enabled with LLMs. This provides non-programmatic access for Thomson Reuters employees who don’t have a background in coding but want to explore the art of the possible with generative AI at TR. Open Arena has been developed to get quick answers from several sets of corpora, such as for customer support agents, solutions to get quick answers from websites, solutions to summarize and verify points in a document, and much more. The capabilities of Open Arena continue to grow as the experiences from employees across Thomson Reuters spur new ideas and as new trends emerge in the field of generative AI. This is all facilitated by the modular serverless AWS architecture that underpins the solution.
Envisioning the Open Arena
Thomson Reuters’s objective was clear: to build a safe, secure, user-friendly platform—an “open arena”—as an enterprise-wide playground. Here, internal teams could not only explore and test the various LLMs developed in-house and those from the open-source community such as with the AWS and Hugging Face partnership, but also discover unique use cases by merging the capabilities of LLMs with Thomson Reuters’s extensive company data. This kind of platform would enhance the ability of teams to generate innovative solutions, improving the products and services that Thomson Reuters could offer its clients.
The envisioned Open Arena platform would serve the diverse teams within Thomson Reuters globally, providing them with a playground to freely interact with LLMs. The ability to have this interaction in a controlled environment would allow teams to uncover new applications and methodologies that might not have been apparent in a less direct engagement with these complex models.
Building the Open Arena
Building the Open Arena was a multi-faceted process. We aimed to harness the capabilities of AWS’s serverless and ML services to craft a solution that would seamlessly enable Thomson Reuters employees to experiment with the latest LLMs. We saw the potential of these services not only to provide scalability and manageability but also to ensure cost-effectiveness.
Solution overview
From creating a robust environment for model deployment and fine-tuning to ensuring meticulous data management and providing a seamless user experience, TR needed each aspect to integrate with several AWS services. Open Arena’s architecture was designed to be comprehensive yet intuitive, balancing complexity with ease of use. The following diagram illustrates this architecture.
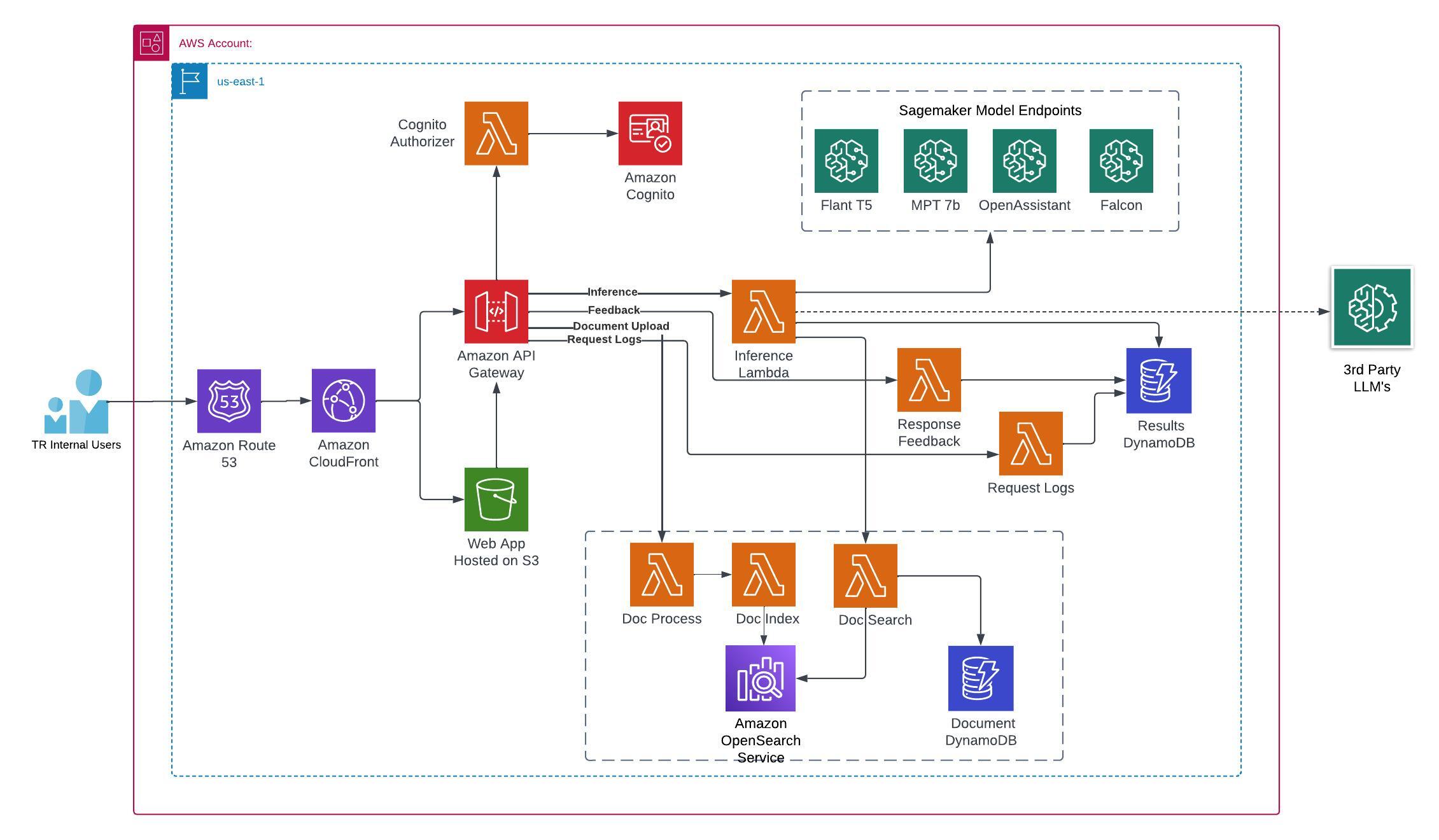
SageMaker served as the backbone, facilitating model deployment as SageMaker endpoints and providing a robust environment for fine-tuning the models. We capitalized on the Hugging Face on SageMaker DLC offered by AWS to enhance our deployment process. In addition, we used the SageMaker Hugging Face Inference Toolkit and the Accelerate library to accelerate the inference process and effectively handle the demands of running complex and resource-intensive models. These comprehensive tools were instrumental in ensuring the fast and seamless deployment of our LLMs. Lambda functions, triggered by Amazon API Gateway, managed the APIs, ensuring meticulous preprocessing and postprocessing of the data.
In our quest to deliver a seamless user experience, we adopted a secure API Gateway to connect the front end hosted in Amazon Simple Storage Service (Amazon S3) to the Lambda backend. We deployed the front end as a static site on an S3 bucket, ensuring user authentication with the help of Amazon CloudFront and our company’s single sign-on mechanism.
Open Arena has been designed to integrate seamlessly with multiple LLMs through REST APIs. This ensured that the platform was flexible enough to react and integrate quickly as new state-of-the art-models were developed and released in the fast-paced generative AI space. From its inception, Open Arena was architected to provide a safe and secure enterprise AI/ML playground, so Thomson Reuters employees can experiment with any state-of-the-art LLM as quickly as they are released. Using Hugging Face models on SageMaker allowed the team to fine-tune models in a secure environment because all data is encrypted and doesn’t leave the virtual private cloud (VPC), ensuring that data remains private and confidential.
DynamoDB, our chosen NoSQL database service, efficiently stored and managed a wide variety of data, including user queries, responses, response times, and user data. To streamline the development and deployment process, we employed AWS CodeBuild and AWS CodePipeline for continuous integration and continuous delivery (CI/CD). Monitoring the infrastructure and ensuring its optimal functioning was made possible with Amazon CloudWatch, which provided custom dashboards and comprehensive logging capabilities.
Model development and integration
The heart of Open Arena is its diverse assortment of LLMs, which comprise both open-source and in-house developed models. These models have been fine-tuned to provide responses following specific user prompts.
We have experimented with different LLMs for different use cases in Open Arena, including Flan-T5-XL, Open Assistant, MPT, Falcon, and fine-tuned Flan-T5-XL on available open-source datasets using the parameter efficient fine-tuning technique. We used bitsandbytes integration from Hugging Face to experiment with various quantization techniques. This allowed us to optimize our LLMs for enhanced performance and efficiency, paving the way for even greater innovation. While selecting a model as a backend behind these use cases, we considered different aspects, like what does the performance of these models look like on NLP tasks that are of relevance to Thomson Reuters. Furthermore, we needed to consider engineering aspects, such as the following:
- Increased efficiency when building applications with LLMs – Quickly integrating and deploying state-of-the-art LLMs into our applications and workloads that run on AWS, using familiar controls and integrations with the depth and breadth of AWS
- Secure customization – Ensuring that all data used to fine-tune LLMs remains encrypted and does not leave the VPC
- Flexibility – The ability to choose from a wide selection of AWS native and open-source LLMs to find the right model for our varied use cases
We’ve been asking questions like is the higher cost of larger models justified by significant performance gains? Can these models handle long documents?
The following diagram illustrates our model architecture.

We have been evaluating these models on the preceding aspects on open-source legal datasets and Thomson Reuters internal datasets to assess them for specific use cases.
For content-based use cases (experiences that call for answers from specific corpus), we have a retrieval augmented generation (RAG) pipeline in place, which will fetch the most relevant content against the query. In such pipelines, documents are split into chunks and then embeddings are created and stored in OpenSearch. To get the best match documents or chunks, we use the retrieval/re-ranker approach based on bi-encoder and cross-encoder models. The retrieved best match is then passed as an input to the LLM along with the query to generate the best response.
The integration of Thomson Reuters’s internal content with the LLM experience has been instrumental in enabling users to extract more relevant and insightful results from these models. More importantly, it led to sparking ideas amongst every team for possibilities of adopting AI-enabled solutions in their business workflows.
Open Arena tiles: Facilitating user interaction
Open Arena adopts a user-friendly interface, designed with pre-set enabling tiles for each experience, as shown in the following screenshot. These tiles serve as pre-set interactions that cater to the specific requirements of the users.

For instance, the Experiment with Open Source LLM tile opens a chat-like interaction channel with open-source LLMs.

The Ask your Document tile allows users to upload documents and ask specific questions related to the content from the LLMs. The Experiment with Summarization tile enables users to distil large volumes of text into concise summaries, as shown in the following screenshot.

These tiles simplify the user consumption of AI-enabled work solutions and the navigation process within the platform, igniting creativity and fostering the discovery of innovative use cases.
The impact of the Open Arena
The launch of the Open Arena marked a significant milestone in Thomson Reuters’s journey towards fostering a culture of innovation and collaboration. The platform’s success was undeniable, with its benefits becoming rapidly evident across the company.
The Open Arena’s intuitive, chat-based design required no significant technical knowledge, making it accessible to different teams and different job roles across the globe. This ease of use boosted engagement levels, encouraging more users to explore the platform and unveiling innovative use cases.
In under a month, the Open Arena catered to over 1,000 monthly internal users from TR’s global footprint, averaging an interaction time of 5 minutes per user. With a goal to foster internal TR LLM experimentation and crowdsource creation of LLM use cases, Open Arena’s launch led to an influx of new use cases, effectively harnessing the power of LLMs combined with Thomson Reuters’s vast data resources.
Here’s what some of our users had to say about the Open Arena:
“Open Arena gives employees from all parts of the company a chance to experiment with LLMs in a practical, hands-on way. It’s one thing to read about AI tools, and another to use them yourself. This platform turbo-charges our AI learning efforts across Thomson Reuters.”
– Abby Pinto, Talent Development Solutions Lead, People Function
“OA (Open Arena) has enabled me to experiment with tricky news translation problems for the German Language Service of Reuters that conventional translation software can’t handle, and to do so in a safe environment where I can use our actual stories without fear of data leaks. The team behind OA has been incredibly responsive to suggestions for new features, which is the sort of service you can only dream of with other software.”
– Scot W. Stevenson, Senior Breaking News Correspondent for the German Language Service, Berlin, Germany
“When I used Open Arena, I got the idea to build a similar interface for our teams of customer support agents. This playground helped us reimagine the possibilities with GenAI.”
– Marcel Batista, Gerente de Servicos, Operations Customer Service & Support
“Open Arena powered by AWS serverless services, Amazon SageMaker, and Hugging Face helped us to quickly expose cutting-edge LLMs and generative AI tooling to our colleagues, which helped drive enterprise-wide innovation.”
– Shirsha Ray Chaudhuri, Director, Research Engineering, Thomson Reuters Labs
On a broader scale, the introduction of the Open Arena had a profound impact on the company. It not only increased AI awareness among employees but also stimulated a spirit of innovation and collaboration. The platform brought teams together to explore, experiment, and generate ideas, fostering an environment where groundbreaking concepts could be turned into reality.
Furthermore, the Open Arena has had a positive influence on Thomson Reuters AI services and products. The platform has served as a sandbox for AI, allowing teams to identify and refine AI applications before incorporating them into our offerings. Consequently, this has accelerated the development and enhancement of Thomson Reuters AI services, providing customers with solutions that are ever evolving and at the forefront of technological advancement.
Conclusion
In the fast-paced world of AI, it is crucial to continue advancing, and Thomson Reuters is committed to doing just that. The team behind the Open Arena is constantly working to add more features and enhance the platform’s capabilities, using AWS services like Amazon Bedrock and Amazon SageMaker Jumpstart, ensuring that it remains a valuable resource for our teams. As we move forward, we aim to keep pace with the rapidly evolving landscape of generative AI and LLMs. AWS provides the services needed for TR to keep pace with the constantly evolving generative AI field.
In addition to the ongoing development of the Open Arena platform, we are actively working on productionizing the multitude of use cases generated by the platform. This will allow us to provide our customers with even more advanced and efficient AI solutions, tailored to their specific needs. Furthermore, we will continue to foster a culture of innovation and collaboration, enabling our teams to explore new ideas and applications for AI technology.
As we embark on this exciting journey, we are confident that the Open Arena will play a pivotal role in driving innovation and collaboration across Thomson Reuters. By staying at the forefront of AI advancements, we will ensure that our products and services continue to evolve and meet the ever-changing demands of our customers.
About the Authors
 Shirsha Ray Chaudhuri (Director, Research Engineering) heads the ML Engineering team in Bangalore for Thomson Reuters Labs, where she is leading the development and deployment of well-architected solutions in AWS and other cloud platforms for ML projects that drive efficiency and value for AI-driven features in Thomson Reuters products, platforms, and business systems. She works with communities on AI for good, societal impact projects and in the tech for D&I space. She loves to network with people who are using AI and modern tech for building a better world that is more inclusive, more digital, and together a better tomorrow.
Shirsha Ray Chaudhuri (Director, Research Engineering) heads the ML Engineering team in Bangalore for Thomson Reuters Labs, where she is leading the development and deployment of well-architected solutions in AWS and other cloud platforms for ML projects that drive efficiency and value for AI-driven features in Thomson Reuters products, platforms, and business systems. She works with communities on AI for good, societal impact projects and in the tech for D&I space. She loves to network with people who are using AI and modern tech for building a better world that is more inclusive, more digital, and together a better tomorrow.
 Harpreet Singh Baath is a Senior Cloud and DevOps Engineer at Thomson Reuters Labs, where he helps research engineers and scientists develop machine learning solutions on cloud platforms. With over 6 years of experience, Harpreet’s expertise spans across cloud architectures, automation, containerization, enabling DevOps practices, and cost optimization. He is passionate about efficiency and cost-effectiveness, ensuring that cloud resources are utilized optimally.
Harpreet Singh Baath is a Senior Cloud and DevOps Engineer at Thomson Reuters Labs, where he helps research engineers and scientists develop machine learning solutions on cloud platforms. With over 6 years of experience, Harpreet’s expertise spans across cloud architectures, automation, containerization, enabling DevOps practices, and cost optimization. He is passionate about efficiency and cost-effectiveness, ensuring that cloud resources are utilized optimally.
 Rashmi B Pawar is a Machine Learning Engineer at Thomson Reuters. She possesses considerable experience in productionizing models, establishing inference, and creating training pipelines tailored for various machine learning applications. Furthermore, she has significant expertise in incorporating machine learning workflows into existing systems and products.
Rashmi B Pawar is a Machine Learning Engineer at Thomson Reuters. She possesses considerable experience in productionizing models, establishing inference, and creating training pipelines tailored for various machine learning applications. Furthermore, she has significant expertise in incorporating machine learning workflows into existing systems and products.
 Palvika Bansal is an Associate Applied Research Scientist at Thomson Reuters. She has worked on projects across diverse sectors to solve business problems for customers using AI/ML. She is highly passionate about her work and enthusiastic about taking on new challenges. Outside of work, she enjoys traveling, cooking, and reading.
Palvika Bansal is an Associate Applied Research Scientist at Thomson Reuters. She has worked on projects across diverse sectors to solve business problems for customers using AI/ML. She is highly passionate about her work and enthusiastic about taking on new challenges. Outside of work, she enjoys traveling, cooking, and reading.
 Simone Zucchet is a Senior Solutions Architect at AWS. With close to a decade’s experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
Simone Zucchet is a Senior Solutions Architect at AWS. With close to a decade’s experience as a Cloud Architect, Simone enjoys working on innovative projects that help transform the way organizations approach business problems. He helps support large enterprise customers at AWS and is part of the Machine Learning TFC. Outside of his professional life, he enjoys working on cars and photography.
 Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing, large language models, and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
Heiko Hotz is a Senior Solutions Architect for AI & Machine Learning with a special focus on natural language processing, large language models, and generative AI. Prior to this role, he was the Head of Data Science for Amazon’s EU Customer Service. Heiko helps our customers be successful in their AI/ML journey on AWS and has worked with organizations in many industries, including insurance, financial services, media and entertainment, healthcare, utilities, and manufacturing. In his spare time, Heiko travels as much as possible.
 João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
João Moura is an AI/ML Specialist Solutions Architect at AWS, based in Spain. He helps customers with deep learning model training and inference optimization, and more broadly building large-scale ML platforms on AWS. He is also an active proponent of ML-specialized hardware and low-code ML solutions.
 Georgios Schinas is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in London and works closely with customers in the UK and Ireland. Georgios helps customers design and deploy machine learning applications in production on AWS, with a particular interest in MLOps practices and enabling customers to perform machine learning at scale. In his spare time, he enjoys traveling, cooking, and spending time with friends and family.
Georgios Schinas is a Specialist Solutions Architect for AI/ML in the EMEA region. He is based in London and works closely with customers in the UK and Ireland. Georgios helps customers design and deploy machine learning applications in production on AWS, with a particular interest in MLOps practices and enabling customers to perform machine learning at scale. In his spare time, he enjoys traveling, cooking, and spending time with friends and family.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- ChartPrime. Elevate your Trading Game with ChartPrime. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/how-thomson-reuters-developed-open-arena-an-enterprise-grade-large-language-model-playground-in-under-6-weeks/

