Organisaatiot investoivat jatkuvasti aikaa ja vaivaa älykkäiden suositusratkaisujen kehittämiseen tarjotakseen räätälöityä ja osuvaa sisältöä käyttäjilleen. Tavoitteita voi olla monia: muuttaa käyttökokemusta, luoda mielekästä vuorovaikutusta ja lisätä sisällön kulutusta. Jotkut näistä ratkaisuista käyttävät yleisiä koneoppimismalleja (ML), jotka on rakennettu historiallisiin vuorovaikutusmalleihin, käyttäjien demografisiin ominaisuuksiin, tuotteiden yhtäläisyyksiin ja ryhmän käyttäytymiseen. Näiden ominaisuuksien lisäksi konteksti (kuten sää, sijainti ja niin edelleen) vuorovaikutuksen aikana voi vaikuttaa käyttäjien päätöksiin, kun he navigoivat sisältöä.
Tässä viestissä näytämme, kuinka voit käyttää käyttäjän nykyistä laitetyyppiä kontekstina parantaaksesi laitteen tehokkuutta Amazon Muokkaa-pohjaisia suosituksia. Lisäksi näytämme, kuinka tällaista kontekstia voidaan käyttää suositusten dynaamiseen suodattamiseen. Vaikka tämä viesti näyttää, kuinka Amazon Personalizea voidaan käyttää video on demand (VOD) -käyttötapauksessa, on syytä huomata, että Amazon Personalizea voidaan käyttää useilla toimialoilla.
Mikä on Amazon Personalize?
Amazon Personalize antaa kehittäjille mahdollisuuden rakentaa sovelluksia, jotka käyttävät samantyyppistä ML-tekniikkaa, jota Amazon.com käyttää reaaliaikaisten henkilökohtaisten suositusten saamiseksi. Amazon Personalize pystyy tarjoamaan laajan valikoiman personointikokemuksia, mukaan lukien erityiset tuotesuositukset, henkilökohtainen tuotteiden uudelleensijoitus ja räätälöity suoramarkkinointi. Lisäksi täysin hallitun tekoälypalveluna Amazon Personalize nopeuttaa asiakkaiden digitaalisia muutoksia ML:n avulla, mikä helpottaa henkilökohtaisten suositusten integrointia olemassa oleviin verkkosivustoihin, sovelluksiin, sähköpostimarkkinointijärjestelmiin ja muihin.
Miksi konteksti on tärkeä?
Käyttäjän kontekstuaalisen metatietojen, kuten sijainnin, vuorokaudenajan, laitetyypin ja sään, käyttö tarjoaa henkilökohtaisia kokemuksia olemassa oleville käyttäjille ja auttaa parantamaan kylmäkäynnistysvaihetta uusille tai tuntemattomille käyttäjille. The kylmäkäynnistysvaihe viittaa ajanjaksoon, jolloin suositusmoottorisi tarjoaa henkilökohtaisia suosituksia, koska kyseisestä käyttäjästä puuttuu historiallisia tietoja. Tilanteissa, joissa kohteiden suodattamiseen ja mainostamiseen on muita vaatimuksia (esimerkiksi uutisissa ja säässä), käyttäjän nykyisen kontekstin (sesonki tai kellonaika) lisääminen parantaa tarkkuutta sisällyttämällä ja jättämällä pois suosituksia.
Otetaan esimerkki VOD-alustasta, joka suosittelee ohjelmia, dokumentteja ja elokuvia käyttäjälle. Käyttäytymisanalyysin perusteella tiedämme, että VOD-käyttäjillä on taipumus kuluttaa lyhyempää sisältöä, kuten tilannekommentteja, mobiililaitteissa ja pitempimuotoista sisältöä, kuten elokuvia televisiossaan tai työpöydällään.
Ratkaisun yleiskatsaus
Laajennamme esimerkkiä käyttäjän laitetyypin tarkastelusta, ja näytämme, kuinka nämä tiedot voidaan antaa kontekstina, jotta Amazon Personalize voi automaattisesti oppia käyttäjän laitteen vaikutuksen heidän haluamaansa sisältötyyppiin.
Seuraamme seuraavassa kaaviossa esitettyä arkkitehtuurimallia havainnollistaaksemme, kuinka konteksti voidaan siirtää automaattisesti Amazon Personalizelle. Kontekstin automaattinen johtaminen saavutetaan Amazon CloudFront otsikot, jotka sisältyvät pyyntöihin, kuten REST API in Amazon API -yhdyskäytävä joka kutsuu an AWS Lambda toiminto suositusten hakemiseen. Katso täydellinen koodiesimerkki, joka on saatavilla osoitteessamme GitHub-arkisto. Tarjoamme a AWS-pilven muodostuminen mallia tarvittavien resurssien luomiseksi.
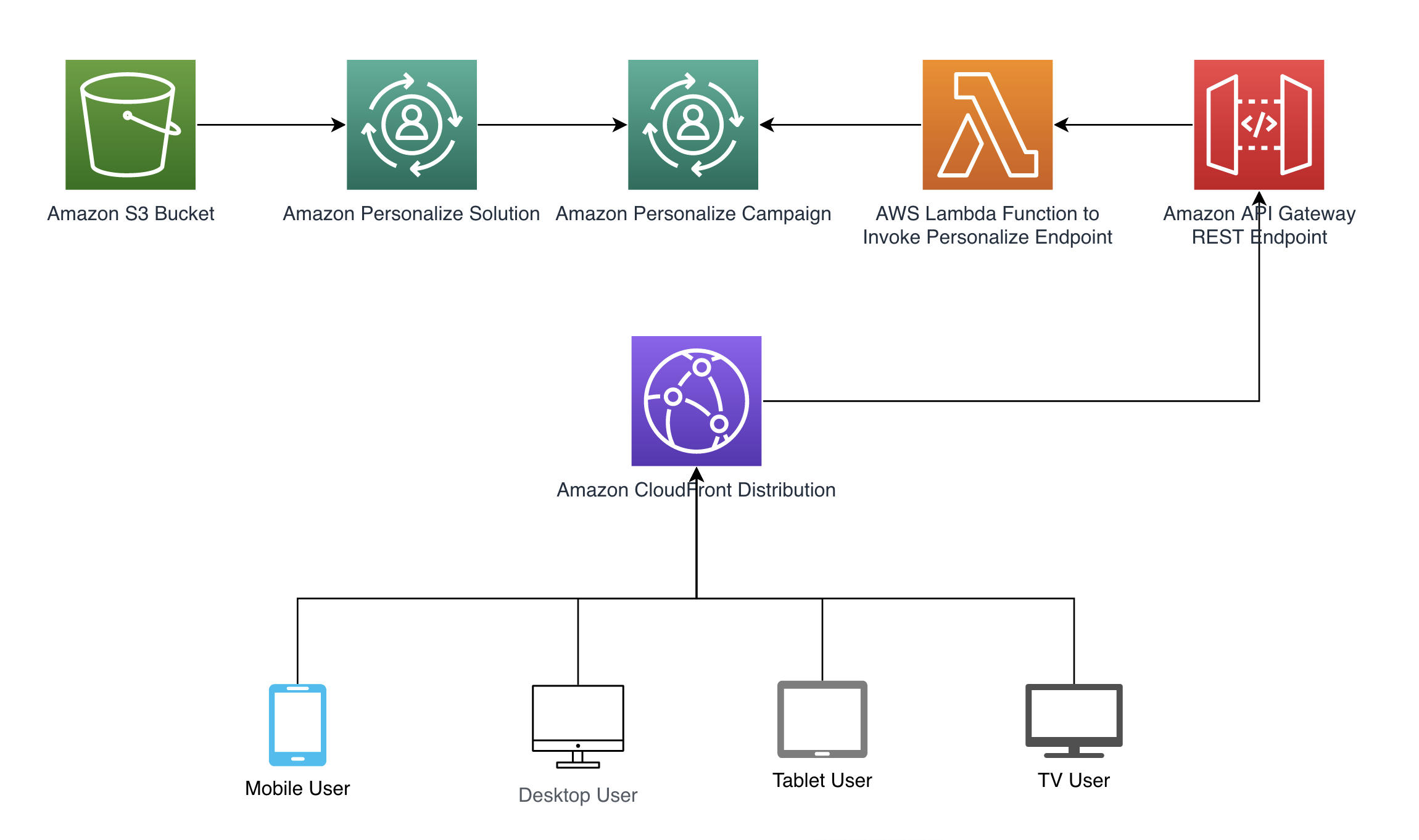
Seuraavissa osissa käymme läpi, kuinka malliarkkitehtuurimallin jokainen vaihe määritetään.
Valitse resepti
Reseptit ovat Amazon Personalize -algoritmeja, jotka on valmistettu tiettyjä käyttötapauksia varten. Amazon Personalize tarjoaa yleisiin käyttötapauksiin perustuvia reseptejä harjoitusmalleille. Käyttötapauksemme varten rakennamme yksinkertaisen Amazon Personalize -suosittajan käyttämällä User-Personalization -reseptiä. Se ennustaa kohteet, joiden kanssa käyttäjä on vuorovaikutuksessa vuorovaikutustietojoukon perusteella. Lisäksi tämä resepti käyttää myös kohteita ja käyttäjien tietojoukkoja vaikuttamaan suosituksiin, jos niitä tarjotaan. Jos haluat lisätietoja tämän reseptin toiminnasta, katso Käyttäjän mukauttamisresepti.
Luo ja tuo tietojoukko
Kontekstin hyödyntäminen edellyttää kontekstiarvojen määrittämistä vuorovaikutuksilla, jotta suosittelejat voivat käyttää kontekstia ominaisuuksina malleja harjoittaessaan. Meidän on myös annettava käyttäjän nykyinen konteksti päättelyhetkellä. Vuorovaikutusskeema (katso seuraava koodi) määrittelee historiallisten ja reaaliaikaisten käyttäjien ja kohteiden välisen vuorovaikutusdatan rakenteen. The USER_ID, ITEM_IDja TIMESTAMP Amazon Personalize vaatii kentät tälle tietojoukolle. DEVICE_TYPE on mukautettu kategorinen kenttä, jonka lisäämme tähän esimerkkiin siepataksemme käyttäjän nykyisen kontekstin ja sisällyttääksemme sen mallikoulutukseen. Amazon Personalize käyttää tätä vuorovaikutustietojoukkoa mallien kouluttamiseen ja suosituskampanjoiden luomiseen.
Vastaavasti nimikeskeema (katso seuraava koodi) määrittelee tuote- ja videoluettelotietojen rakenteen. The ITEM_ID Amazon Personalize vaatii tälle tietojoukolle. CREATION_TIMESTAMP on varatun sarakkeen nimi, mutta se ei ole pakollinen. GENRE ja ALLOWED_COUNTRIES ovat mukautettuja kenttiä, jotka lisäämme tähän esimerkkiin, jotta voimme kaapata videon genren ja maat, joissa videoita saa toistaa. Amazon Personalize käyttää tätä tietoaineistoa mallien kouluttamiseen ja suosituskampanjoiden luomiseen.
Meidän kontekstissamme historiallisia tietoja viittaa loppukäyttäjien vuorovaikutushistoriaan videoiden ja kohteiden kanssa VOD-alustalla. Nämä tiedot yleensä kerätään ja tallennetaan sovelluksen tietokantaan.
Esittelytarkoituksiin käytämme Pythonin Faker-kirjastoa luomaan testitietoja, jotka pilkkaavat vuorovaikutustietojoukon eri kohteiden, käyttäjien ja laitetyyppien kanssa 3 kuukauden aikana. Kun skeema ja syöttövuorovaikutustiedoston sijainti on määritetty, seuraavien vaiheiden avulla luodaan tietojoukkoryhmä, sisällytetään vuorovaikutustietojoukko tietojoukkoryhmään ja lopuksi tuodaan harjoitustiedot tietojoukkoon seuraavien koodinpätkien mukaisesti:
Kerää historiallisia tietoja ja harjoittele mallia
Tässä vaiheessa määritämme valitun reseptin ja luomme ratkaisun ja ratkaisuversion viitaten aiemmin määritettyyn tietojoukkoryhmään. Kun luot mukautetun ratkaisun, määrität reseptin ja määrität harjoitusparametrit. Kun luot ratkaisulle ratkaisuversion, Amazon Personalize kouluttaa mallin, joka tukee ratkaisuversiota reseptin ja koulutuskokoonpanon perusteella. Katso seuraava koodi:
Luo kampanjan päätepiste
Kun olet kouluttanut mallisi, otat sen käyttöön a kampanja. Kampanja luo ja hallitsee automaattisesti skaalautuvan päätepisteen koulutetulle mallillesi, jonka avulla voit saada henkilökohtaisia suosituksia GetRecommendations API. Myöhemmässä vaiheessa käytämme tätä kampanjan päätepistettä siirtämään laitetyypin automaattisesti kontekstina parametrina ja saamaan henkilökohtaisia suosituksia. Katso seuraava koodi:
Luo dynaaminen suodatin
Kun saat suosituksia luodusta kampanjasta, voit suodattaa tuloksia mukautettujen kriteerien perusteella. Luomme esimerkiksi suodattimen, joka täyttää vaatimuksen suositella videoita, joiden toistaminen on sallittua vain käyttäjän nykyisestä maasta. Maatiedot välitetään dynaamisesti CloudFront HTTP-otsikosta.
Luo Lambda-toiminto
Seuraava vaihe arkkitehtuurissamme on luoda Lambda-toiminto, joka käsittelee CloudFront-jakelusta tulevat API-pyynnöt ja vastaa Amazon Personalize -kampanjan päätepisteeseen. Tässä Lambda-funktiossa määritämme logiikan analysoimaan seuraavan CloudFront-pyynnön HTTP-otsikoita ja kyselymerkkijonoparametreja määrittääksemme käyttäjän laitetyypin ja käyttäjätunnuksen:
CloudFront-Is-Desktop-ViewerCloudFront-Is-Mobile-ViewerCloudFront-Is-SmartTV-ViewerCloudFront-Is-Tablet-ViewerCloudFront-Viewer-Country
Tämän toiminnon luomiseen tarvittava koodi otetaan käyttöön CloudFormation-mallin kautta.
Luo REST API
Jotta Lambda-toiminto ja Amazon Personalize -kampanjan päätepiste ovat käytettävissä CloudFront-jakelussa, luomme REST API -päätepisteen, joka on määritetty Lambda-välityspalvelimeksi. API Gateway tarjoaa työkaluja sovellusliittymien luomiseen ja dokumentointiin, jotka reitittävät HTTP-pyynnöt Lambda-toimintoihin. Lambda-välityspalvelimen integrointiominaisuuden avulla CloudFront voi kutsua yksittäisen Lambda-funktion abstraktipyynnöt Amazon Personalize -kampanjan päätepisteeseen. Tämän toiminnon luomiseen tarvittava koodi otetaan käyttöön CloudFormation-mallin kautta.
Luo CloudFront-jakelu
Kun luot CloudFront-jakelun, koska tämä on esittelyasennus, poistamme välimuistin käytöstä mukautetun välimuistikäytännön avulla ja varmistamme, että pyyntö menee alkuperään joka kerta. Lisäksi käytämme alkuperäpyyntökäytäntöä, joka määrittää vaaditut HTTP-otsikot ja kyselymerkkijonoparametrit, jotka sisältyvät alkuperäpyyntöön. Tämän toiminnon luomiseen tarvittava koodi otetaan käyttöön CloudFormation-mallin kautta.
Testin suositukset
Kun CloudFront-jakelun URL-osoitetta käytetään eri laitteilla (työpöytä, tabletti, puhelin ja niin edelleen), voimme nähdä henkilökohtaisia videosuosituksia, jotka ovat olennaisimpia heidän laitteensa kannalta. Lisäksi, jos kylmä käyttäjä esitetään, esitetään käyttäjän laitteelle räätälöidyt suositukset. Seuraavissa näytetuloksissa videoiden nimiä käytetään vain niiden genren ja suoritusajan esittämiseen, jotta ne ovat suhteellisia.
Seuraavassa koodissa tunnetulle käyttäjälle, joka rakastaa aikaisempaan vuorovaikutukseen perustuvaa komediaa ja joka käyttää puhelimella, esitetään lyhyempiä sitcomeja:
Seuraavalle tunnetulle käyttäjälle esitetään elokuvia, kun hän käyttää älytelevisiolaitetta aiempien vuorovaikutusten perusteella:
Kylmälle (tuntemattomalle) käyttäjälle, joka käyttää puhelimella, esitetään lyhyempiä, mutta suosittuja esityksiä:
Recommendations for user: 666 ITEM_ID GENRE ALLOWED_COUNTRIES 940 Satire US|FI|CN|ES|HK|AE 760 Satire US|FI|CN|ES|HK|AE 160 Sitcom US|FI|CN|ES|HK|AE 880 Comedy US|FI|CN|ES|HK|AE 360 Satire US|PK|NI|JM|IN|DK 840 Satire US|PK|NI|JM|IN|DK 420 Satire US|PK|NI|JM|IN|DK
Kylmälle (tuntemattomalle) käyttäjälle, joka käyttää työpöytää, esitellään huippuscifi-elokuvia ja dokumentteja:
Seuraava tunnettu käyttäjä, joka käyttää puhelimella, palauttaa suodatettuja suosituksia sijaintiin (Yhdysvallat):
Yhteenveto
Tässä viestissä kuvailimme, kuinka voit käyttää käyttäjän laitetyyppiä kontekstuaalisena datana, jotta suosituksistasi tulee osuvampia. Kontekstikohtaisten metatietojen käyttäminen Amazon Personalize -mallien kouluttamiseen auttaa sinua suosittelemaan tuotteita, jotka ovat olennaisia sekä uusille että olemassa oleville käyttäjille, ei vain profiilitiedoista vaan myös selauslaitteen alustasta. Paitsi, että konteksti, kuten sijainti (maa, kaupunki, alue, postinumero) ja aika (viikonpäivä, viikonloppu, arkipäivä, vuodenaika) avaa mahdollisuuden antaa käyttäjälle kohdistettavia suosituksia. Voit suorittaa täydellisen koodiesimerkin käyttämällä CloudFormation-mallia, joka on toimitettavissamme GitHub-arkisto ja kloonaa muistikirjat Amazon SageMaker Studio.
Tietoja Tekijät
 Gilles-Kuessan Satchivi on AWS Enterprise Solutions -arkkitehti, jolla on tausta verkko-, infrastruktuuri-, turvallisuus- ja IT-toiminnoista. Hän on intohimoinen auttamaan asiakkaita rakentamaan hyvin suunniteltuja järjestelmiä AWS:lle. Ennen AWS:lle tuloaan hän työskenteli verkkokaupan parissa 17 vuotta. Työn ulkopuolella hän viettää mielellään aikaa perheensä kanssa ja kannustaa lastensa jalkapallojoukkueeseen.
Gilles-Kuessan Satchivi on AWS Enterprise Solutions -arkkitehti, jolla on tausta verkko-, infrastruktuuri-, turvallisuus- ja IT-toiminnoista. Hän on intohimoinen auttamaan asiakkaita rakentamaan hyvin suunniteltuja järjestelmiä AWS:lle. Ennen AWS:lle tuloaan hän työskenteli verkkokaupan parissa 17 vuotta. Työn ulkopuolella hän viettää mielellään aikaa perheensä kanssa ja kannustaa lastensa jalkapallojoukkueeseen.
 Aditya Pendyala on vanhempi ratkaisuarkkitehti AWS:ssä New Yorkista. Hänellä on laaja kokemus pilvipohjaisten sovellusten suunnittelusta. Hän työskentelee parhaillaan suurten yritysten kanssa auttaakseen niitä luomaan erittäin skaalautuvia, joustavia ja joustavia pilviarkkitehtuureja ja opastaa heitä kaikessa pilvessä. Hän on suorittanut tietojenkäsittelytieteen maisterin tutkinnon Shippensburgin yliopistosta ja uskoo lainaukseen "Kun lakkaat oppimasta, lakkaat kasvamasta."
Aditya Pendyala on vanhempi ratkaisuarkkitehti AWS:ssä New Yorkista. Hänellä on laaja kokemus pilvipohjaisten sovellusten suunnittelusta. Hän työskentelee parhaillaan suurten yritysten kanssa auttaakseen niitä luomaan erittäin skaalautuvia, joustavia ja joustavia pilviarkkitehtuureja ja opastaa heitä kaikessa pilvessä. Hän on suorittanut tietojenkäsittelytieteen maisterin tutkinnon Shippensburgin yliopistosta ja uskoo lainaukseen "Kun lakkaat oppimasta, lakkaat kasvamasta."
 Prabhakar Chandrasekaran on vanhempi tekninen asiakaspäällikkö, jolla on AWS-yritystuki. Prabhakar haluaa auttaa asiakkaita rakentamaan huippuluokan AI/ML-ratkaisuja pilveen. Hän työskentelee myös yritysasiakkaiden kanssa tarjoten ennakoivaa ohjausta ja operatiivista apua, mikä auttaa heitä parantamaan ratkaisujensa arvoa AWS:n käytössä. Prabhakarilla on kuusi AWS-todistusta ja kuusi muuta ammattisertifikaattia. Yli 20 vuoden ammatillisella kokemuksella Prabhakar oli tietoinsinööri ja ohjelmajohtaja rahoituspalvelualalla ennen liittymistään AWS:ään.
Prabhakar Chandrasekaran on vanhempi tekninen asiakaspäällikkö, jolla on AWS-yritystuki. Prabhakar haluaa auttaa asiakkaita rakentamaan huippuluokan AI/ML-ratkaisuja pilveen. Hän työskentelee myös yritysasiakkaiden kanssa tarjoten ennakoivaa ohjausta ja operatiivista apua, mikä auttaa heitä parantamaan ratkaisujensa arvoa AWS:n käytössä. Prabhakarilla on kuusi AWS-todistusta ja kuusi muuta ammattisertifikaattia. Yli 20 vuoden ammatillisella kokemuksella Prabhakar oli tietoinsinööri ja ohjelmajohtaja rahoituspalvelualalla ennen liittymistään AWS:ään.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/recommend-and-dynamically-filter-items-based-on-user-context-in-amazon-personalize/

