Digitaaliset julkaisijat etsivät jatkuvasti tapoja virtaviivaistaa ja automatisoida mediatyönkulkuaan luodakseen ja julkaistakseen uutta sisältöä mahdollisimman nopeasti.
Julkaisijalla voi olla arkistot, jotka sisältävät miljoonia kuvia, ja säästääkseen rahaa heidän on voitava käyttää näitä kuvia uudelleen eri artikkeleissa. Artikkelia parhaiten vastaavan kuvan löytäminen tämän mittakaavan arkistoista voi olla aikaa vievä, toistuva manuaalinen tehtävä, joka voidaan automatisoida. Se luottaa myös siihen, että arkiston kuvat on merkitty oikein, mikä voidaan myös automatisoida (asiakkaan menestystarina, katso Aller Media löytää menestystä KeyCoren ja AWS:n avulla).
Tässä viestissä esittelemme, miten sitä käytetään Amazonin tunnistus, Amazon SageMaker JumpStartja Amazon OpenSearch-palvelu ratkaisemaan tämän yritysongelman. Amazon Rekognitionin avulla on helppo lisätä kuva-analyysiominaisuutta sovelluksiisi ilman koneoppimisen (ML) asiantuntemusta, ja sen mukana tulee erilaisia sovellusliittymiä, jotka täyttävät käyttötapaukset, kuten kohteen havaitseminen, sisällön valvonta, kasvojen havaitseminen ja analysointi sekä tekstin ja julkkisten tunnistus. käytämme tässä esimerkissä. SageMaker JumpStart on alhaisen koodin palvelu, joka sisältää valmiita ratkaisuja, esimerkkimuistikirjoja ja monia huippuluokan, valmiiksi koulutettuja malleja julkisesti saatavilla olevista lähteistä, jotka on helppo ottaa käyttöön yhdellä napsautuksella AWS-tilillesi. . Nämä mallit on pakattu turvallisesti ja helposti otettavissa käyttöön Amazon Sage Maker API:t. Uuden SageMaker JumpStart Foundation Hubin avulla voit helposti ottaa käyttöön suuria kielimalleja (LLM) ja integroida ne sovelluksiisi. OpenSearch Service on täysin hallittu palvelu, jonka avulla on helppo ottaa käyttöön, skaalata ja käyttää OpenSearchia. OpenSearch-palvelun avulla voit tallentaa vektoreita ja muita tietotyyppejä hakemistoon, ja se tarjoaa monipuolisia toimintoja, joiden avulla voit etsiä dokumentteja vektorien avulla ja mittaamalla semanttista yhteyttä, jota käytämme tässä viestissä.
Tämän postauksen lopputavoite on näyttää, kuinka voimme tuoda esiin joukon kuvia, jotka ovat semanttisesti samanlaisia kuin jokin teksti, olipa kyseessä artikkeli tai tv-tiivistelmä.
Seuraavassa kuvakaappauksessa on esimerkki miniartikkelin käyttämisestä hakusyötteenä avainsanojen käyttämisen sijaan ja semanttisesti samankaltaisten kuvien näyttämisestä.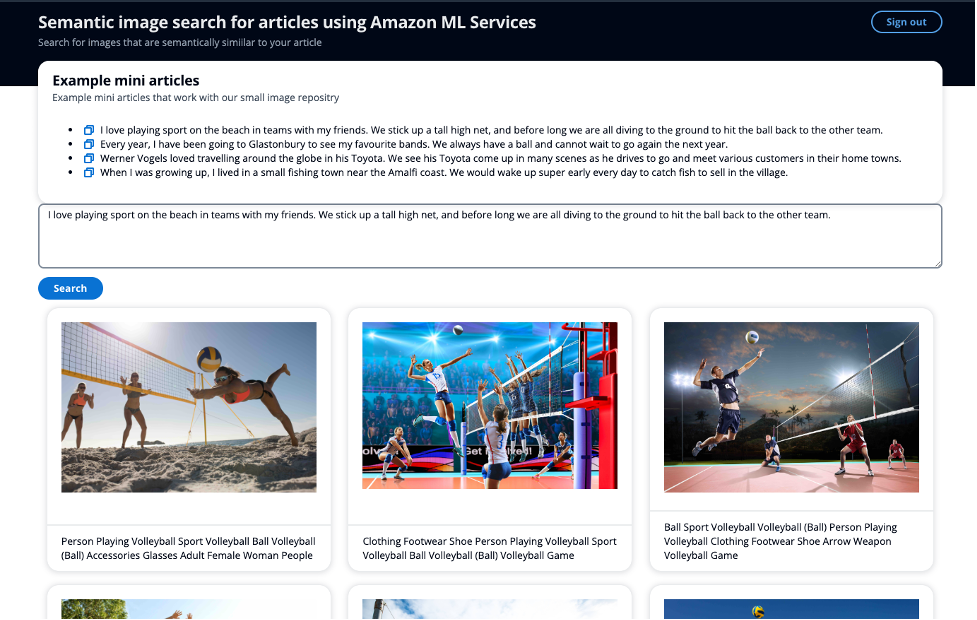
Katsaus ratkaisuun
Ratkaisu on jaettu kahteen pääosaan. Poimi ensin nimi- ja julkkismetatiedot kuvista Amazon Rekognitionin avulla. Luot sitten metatiedon upotuksen LLM:n avulla. Tallennat julkkisten nimet ja metatietojen upottamisen OpenSearch-palveluun. Toisessa pääosiossa sinulla on API, jolla voit hakea OpenSearch Service -hakemistostasi kuvia käyttämällä OpenSearchin älykkäitä hakuominaisuuksia löytääksesi kuvia, jotka ovat semanttisesti samanlaisia tekstisi kanssa.
Tämä ratkaisu käyttää tapahtumalähtöisiä palveluitamme Amazon EventBridge, AWS-vaihetoiminnotja AWS Lambda ohjata metatietojen poimimista kuvista Amazon Rekognitionin avulla. Amazon Rekognition suorittaa kaksi API-kutsua tarrojen ja tunnettujen julkkisten poimimiseksi kuvasta.
Amazon Rekognition julkkistunnistussovellusliittymä, palauttaa joukon elementtejä vastauksessa. Tässä viestissä käytät seuraavaa:
- Nimi, tunnus ja URL-osoitteet – Julkkiksen nimi, ainutlaatuinen Amazon Rekognition ID ja URL-osoitteiden luettelo, kuten julkkiksen IMDb- tai Wikipedia-linkki lisätietoja varten.
- MatchConfidence – Ottelun luotettavuuspisteet, joita voidaan käyttää API-käyttäytymisen ohjaamiseen. Suosittelemme käyttämään sopivaa kynnystä tälle pistemäärälle hakemuksessasi valitaksesi haluamasi toimintapisteen. Esimerkiksi asettamalla kynnysarvoksi 99 %, voit poistaa enemmän vääriä positiivisia tuloksia, mutta voit jättää huomiotta joitakin mahdollisia osumia.
Toisessa API-kutsussasi Amazon Rekognition -etiketin tunnistussovellusliittymä, palauttaa joukon elementtejä vastauksessa. Käytät seuraavaa:
Avainkäsite semanttisessa haussa on upotukset. Sanan upotus on sanan tai sanaryhmän numeerinen esitys vektorin muodossa. Kun vektoreita on useita, voit mitata niiden välisen etäisyyden, ja vektorit, jotka ovat lähellä etäisyyttä, ovat semanttisesti samanlaisia. Jos siis luot upotuksen kaikista kuviesi metatiedoista ja sitten upotuksen tekstistäsi, olipa kyseessä esimerkiksi artikkeli tai tv-tiivistelmä, käyttämällä samaa mallia, voit löytää kuvia, jotka ovat semanttisesti samanlaisia annettu teksti.
SageMaker JumpStartissa on monia malleja upotusten luomiseen. Tässä ratkaisussa käytät GPT-J 6B Embedding -sovellusta Halaaminen kasvot. Se tuottaa korkealaatuisia upotuksia ja sillä on yksi parhaista suorituskykymittareista Hugging Facen mukaan arvioinnin tulokset. Amazonin kallioperä on toinen vaihtoehto, vielä esikatselussa, jossa voit valita Amazon Titan Text Embeddings -mallin upotusten luomiseksi.
Käytät SageMaker JumpStartin esikoulutettua GPT-J-mallia luodaksesi upotuskuvan metatiedoista ja tallentaaksesi tämän k-NN vektori OpenSearch Service -hakemistossasi ja julkkiksen nimi toisessa kentässä.
Ratkaisun toinen osa on palauttaa käyttäjälle 10 parasta kuvaa, jotka ovat semanttisesti samankaltaisia kuin heidän tekstinsä, olipa tämä artikkeli tai tv-tiivistelmä, mukaan lukien mahdolliset julkkikset. Kun valitset kuvan artikkelin mukana, haluat kuvan resonoivan artikkelin asiaankuuluvien kohtien kanssa. SageMaker JumpStart isännöi monia yhteenvetomalleja, jotka voivat viedä pitkän tekstin ja tiivistää sen alkuperäisen tekstin pääkohtiin. Yhteenvetomallissa käytät AI21 Labs Yhteenveto mallista. Tämä malli tarjoaa laadukkaita uutisartikkeleiden yhteenvetoja ja lähdeteksti voi sisältää noin 10,000 XNUMX sanaa, jolloin käyttäjä voi tehdä yhteenvedon koko artikkelista yhdellä kertaa.
Voit havaita, sisältääkö teksti nimiä, mahdollisesti tunnettuja julkkiksia Amazonin käsitys joka voi poimia keskeiset kokonaisuudet tekstijonosta. Suodatat sitten Henkilö-olion mukaan, jota käytät syötehakuparametrina.
Sitten otat yhteenvedon artikkelista ja luot upotuksen käytettäväksi toisena syötehakuparametrina. On tärkeää huomata, että käytät samaa mallia, joka on otettu käyttöön samassa infrastruktuurissa artikkelin upotuksen luomiseen kuin kuvien luomiseen. Käytät sitten Tarkka k-NN pisteytyskäsikirjoituksella jotta voit etsiä kahdella kentällä: julkkisten nimillä ja vektorilla, joka taltioi artikkelin semanttiset tiedot. Viittaa tähän viestiin, Amazon OpenSearch Servicen vektoritietokantaominaisuudet selitetty, Score-komentosarjan skaalautumisesta ja siitä, kuinka tämä lähestymistapa suurille indekseille voi johtaa korkeisiin viiveisiin.
Walkthrough
Seuraava kaavio kuvaa ratkaisuarkkitehtuuria.

Numeroitujen tarrojen jälkeen:
- Lataat kuvan osoitteeseen Amazon S3 ämpäri
- Amazon EventBridge kuuntelee tätä tapahtumaa ja käynnistää sitten an AWS Step -toiminto teloitus
- Step Function ottaa kuvan syötteen, poimii etiketin ja julkkismetatiedot
- - AWS Lambda toiminto ottaa kuvan metatiedot ja luo upotuksen
- - Lambda toiminto lisää sitten julkkiksen nimen (jos olemassa) ja upotuksen k-NN-vektorina OpenSearch-palvelun hakemistoon
- Amazon S3 isännöi yksinkertaista staattista verkkosivustoa, jota palvelee an Amazon CloudFront jakelu. Käyttöliittymän (UI) avulla voit todentaa sovelluksen avulla Amazon Cognito kuvien etsimiseen
- Lähetät artikkelin tai tekstin käyttöliittymän kautta
- Toinen Lambda toimintokutsuja Amazonin käsitys tunnistaaksesi mahdolliset nimet tekstistä
- Funktio tekee sitten yhteenvedon tekstistä saadakseen artikkelin olennaiset kohdat
- Funktio luo tiivistetyn artikkelin upotuksen
- Sen jälkeen toiminto hakee OpenSearch-palvelu kuvaindeksi mille tahansa kuvalle, joka vastaa julkkiksen nimeä ja vektorin k-lähimpiä naapureita käyttäen kosinin samankaltaisuutta
- amazonin pilvikello ja AWS röntgen antaa sinulle havaittavuuden työnkulun loppuun asti, jotta voit varoittaa kaikista ongelmista.
Pura ja tallenna avainkuvan metatiedot
Amazon Rekognition DetectLabels- ja RecognizeCelebrities API -sovellusliittymät antavat sinulle kuvien metatiedot – tekstitunnisteet, joiden avulla voit muodostaa lauseen upotuksen luomiseen. Artikkeli antaa sinulle tekstisyötteen, jonka avulla voit luoda upotuksen.
Luo ja tallenna sanan upotuksia
Seuraava kuva havainnollistaa kuviemme vektorien piirtämistä 2-ulotteiseen tilaan, jossa visuaalisen avun vuoksi olemme luokitelleet upotukset ensisijaisen luokan mukaan.

Luot myös upotuksen tästä äskettäin kirjoitetusta artikkelista, jotta voit etsiä OpenSearch-palvelusta artikkelia lähimmät kuvat tässä vektoriavaruudessa. Käyttämällä k-lähimpien naapureiden (k-NN) -algoritmia voit määrittää, kuinka monta kuvaa tuloksissasi palautetaan.
Edelliseen kuvaan lähennettynä vektorit asetetaan paremmuusjärjestykseen niiden etäisyyden perusteella artikkelista ja palauttavat K-lähimmät kuvat, joissa K on tässä esimerkissä 10.

OpenSearch Service tarjoaa mahdollisuuden tallentaa suuria vektoreita hakemistoon ja tarjoaa myös toiminnon suorittaa kyselyitä indeksiä vastaan k-NN:n avulla, jolloin voit hakea vektorilla palauttaaksesi k-lähimmät asiakirjat, joissa on vektoreita lähietäisyydellä. käyttämällä erilaisia mittauksia. Tässä esimerkissä käytämme kosinin samankaltaisuus.
Tunnista nimet artikkelista
Käytät Amazon Comprehendia, tekoälyn luonnollisen kielen käsittelypalvelua (NLP) poimimaan tärkeimmät kokonaisuudet artikkelista. Tässä esimerkissä käytät Amazon Comprehendia kokonaisuuksien poimimiseen ja suodattamiseen Person-yksikön mukaan, joka palauttaa kaikki nimet, jotka Amazon Comprehend löytää toimittajan tarinasta, vain muutamalla koodirivillä:
Tässä esimerkissä lataat kuvan osoitteeseen Amazonin yksinkertainen tallennuspalvelu (Amazon S3), joka käynnistää työnkulun, jossa poimit kuvasta metatietoja, mukaan lukien tunnisteet ja julkisuuden henkilöt. Muunnat sitten puretut metatiedot upotukseksi ja tallennat kaikki nämä tiedot OpenSearch-palveluun.
Tee artikkelista yhteenveto ja luo upotus
Artikkelin yhteenvedon tekeminen on tärkeä askel sen varmistamisessa, että sana upotus vangitsee artikkelin olennaiset kohdat ja palauttaa siten artikkelin teeman kanssa resonoivia kuvia.
AI21 Labs Summarize -malli on erittäin helppokäyttöinen ilman kehotteita ja vain muutaman rivin koodia:
Käytä sitten GPT-J-mallia upotuksen luomiseen
Tämän jälkeen voit etsiä kuviasi OpenSearch-palvelusta
Seuraavassa on esimerkkikatkelma kyseisestä kyselystä:
Arkkitehtuuri sisältää yksinkertaisen verkkosovelluksen, joka edustaa sisällönhallintajärjestelmää (CMS).
Esimerkkiartikkelissa käytimme seuraavaa syötettä:
”Werner Vogels rakasti matkustaa ympäri maailmaa Toyotalla. Näemme hänen Toyotansa esiintyvän monissa kohtauksissa, kun hän ajaa tapaamaan erilaisia asiakkaita heidän kotikaupungeissaan.

Yhdessäkään kuvassa ei ole metadataa sanalle "Toyota", mutta sanan "Toyota" semantiikka on synonyymejä autoille ja ajamiselle. Siksi tällä esimerkillä voimme osoittaa, kuinka voimme ylittää avainsanahaun ja palauttaa kuvia, jotka ovat semanttisesti samankaltaisia. Yllä olevassa käyttöliittymän kuvakaappauksessa kuvan alla oleva kuvateksti näyttää Amazon Rekognitionin puretut metatiedot.
Voit sisällyttää tämän ratkaisun kohtaan a suurempi työnkulku jossa käytät kuvistasi jo poimimaasi metatietoa alkaaksesi käyttää vektorihakua yhdessä muiden avaintermien, kuten julkkisten nimien, kanssa saadaksesi hakukyselyäsi parhaiten resonoivat kuvat ja asiakirjat.
Yhteenveto
Tässä viestissä osoitimme, kuinka voit käyttää Amazon Rekognitionia, Amazon Comprehendia, SageMakeria ja OpenSearch Serviceä metatietojen poimimiseen kuvistasi ja sitten ML-tekniikoiden avulla löytääksesi ne automaattisesti julkkis- ja semanttisen haun avulla. Tämä on erityisen tärkeää julkaisuteollisuudessa, jossa nopeus on tärkeää, kun tuoretta sisältöä saadaan nopeasti ja useille alustoille.
Lisätietoja mediaresurssien käsittelystä on kohdassa Mediaäly on juuri älykkäämpi Media2Cloud 3.0:n avulla.
kirjailijasta
 Mark Watkins on Media and Entertainment -tiimin ratkaisuarkkitehti, joka auttaa asiakkaitaan ratkaisemaan monia data- ja ML-ongelmia. Poissa työelämästä hän rakastaa viettää aikaa perheensä kanssa ja katsella kahden pienen lapsensa kasvamista.
Mark Watkins on Media and Entertainment -tiimin ratkaisuarkkitehti, joka auttaa asiakkaitaan ratkaisemaan monia data- ja ML-ongelmia. Poissa työelämästä hän rakastaa viettää aikaa perheensä kanssa ja katsella kahden pienen lapsensa kasvamista.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- ChartPrime. Nosta kaupankäyntipeliäsi ChartPrimen avulla. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/semantic-image-search-for-articles-using-amazon-rekognition-amazon-sagemaker-foundation-models-and-amazon-opensearch-service/

