این یک پست مشترک توسط NXP SEMICONDUCTORS NV & AWS Machine Learning Solutions Lab (MLSL) است.
یادگیری ماشینی (ML) در طیف وسیعی از صنایع برای استخراج بینش عملی از دادهها برای سادهسازی فرآیندها و بهبود تولید درآمد استفاده میشود. در این پست، ما نشان میدهیم که چگونه NXP، پیشرو صنعت در بخش نیمههادی، با آزمایشگاه راه حل های یادگیری ماشین AWS (MLSL) برای استفاده از تکنیک های ML برای بهینه سازی تخصیص NXP بودجه تحقیق و توسعه (R&D) برای به حداکثر رساندن بازده سرمایه گذاری بلندمدت (ROI).
NXP تلاش های تحقیق و توسعه خود را عمدتاً به سمت توسعه راه حل های نیمه هادی جدید هدایت می کند که در آن فرصت های قابل توجهی برای رشد مشاهده می شود. برای پیشی گرفتن از رشد بازار، NXP در تحقیق و توسعه سرمایه گذاری می کند تا موقعیت های پیشرو در بازار را گسترش دهد یا ایجاد کند، با تاکید بر بخش های بازار با رشد سریع و قابل توجه. برای این تعامل، آنها به دنبال ایجاد پیشبینی فروش ماهانه برای محصولات جدید و موجود در گروههای مواد مختلف و خطوط تجاری بودند. در این پست، نحوه استفاده از MLSL و NXP را نشان میدهیم پیش بینی آمازون و سایر مدل های سفارشی برای پیش بینی های فروش بلند مدت برای محصولات مختلف NXP.
ما با تیمی از دانشمندان و کارشناسان در آزمایشگاه راهحلهای یادگیری ماشین آمازون همکاری کردیم تا راهحلی برای پیشبینی فروش محصولات جدید بسازیم و بفهمیم که آیا و کدام ویژگیهای اضافی میتواند به اطلاعرسانی در فرآیند تصمیمگیری برای بهینهسازی هزینههای تحقیق و توسعه کمک کند یا خیر. تنها در عرض چند هفته، تیم راهحلها و تحلیلهای متعددی را در برخی از خطوط تجاری، گروههای مواد و در سطح [یک] محصول فردی ارائه کرد. MLSL یک مدل پیشبینی فروش ارائه کرد که مکمل روش فعلی پیشبینی دستی ما است و به ما کمک کرد تا چرخه عمر محصول را با رویکردهای یادگیری ماشینی جدید با استفاده از Amazon Forecast و Amazon SageMaker مدلسازی کنیم. در حالی که یک جریان کاری مشترک با تیم خود را حفظ می کنیم، MLSL به ما در ارتقای مهارت متخصصان خود در زمینه برتری علمی و بهترین شیوه ها در توسعه ML با استفاده از زیرساخت AWS کمک کرد.
- بارت زیمن، استراتژیست و تحلیلگر در دفتر CTO در NXP Semiconductors.
اهداف و مورد استفاده
هدف از تعامل بین NXP و تیم MLSL پیش بینی فروش کلی NXP در بازارهای نهایی مختلف است. به طور کلی، تیم NXP به فروش در سطح کلان علاقه مند است که شامل فروش خطوط تجاری مختلف (BLs) است که شامل چندین گروه مواد (MAG) است. علاوه بر این، تیم NXP همچنین علاقه مند به پیش بینی چرخه عمر محصول محصولات تازه معرفی شده است. چرخه عمر یک محصول به چهار مرحله مختلف (مقدمه، رشد، بلوغ و زوال) تقسیم می شود. پیشبینی چرخه عمر محصول، تیم NXP را قادر میسازد تا درآمد تولید شده توسط هر محصول را شناسایی کند تا بودجه تحقیق و توسعه را به محصولاتی که بالاترین میزان فروش را ایجاد میکنند یا محصولاتی با بالاترین پتانسیل برای به حداکثر رساندن بازگشت سرمایه برای فعالیت تحقیق و توسعه اختصاص دهند. علاوه بر این، آنها می توانند فروش بلندمدت را در سطح خرد پیش بینی کنند، که به آنها نگاهی از پایین به بالا در مورد چگونگی تغییر درآمدشان در طول زمان می دهد.
در بخشهای بعدی، چالشهای کلیدی مرتبط با توسعه مدلهای قوی و کارآمد برای پیشبینیهای بلندمدت فروش را ارائه میکنیم. ما بیشتر شهود پشت تکنیکهای مدلسازی مختلف را که برای دستیابی به دقت مطلوب مورد استفاده قرار میگیرد، توصیف میکنیم. سپس ارزیابی مدلهای نهایی خود را ارائه میکنیم، جایی که عملکرد مدلهای پیشنهادی را از نظر پیشبینی فروش با کارشناسان بازار در NXP مقایسه میکنیم. ما همچنین عملکرد پیشرفتهترین الگوریتم پیشبینی چرخه عمر محصول مبتنی بر ابر را نشان میدهیم.
چالش ها
یکی از چالشهایی که هنگام استفاده از مدلسازی ریز دانه یا در سطح خرد مانند مدلهای سطح محصول برای پیشبینی فروش با آن مواجه بودیم، دادههای فروش از دست رفته بود. داده های از دست رفته نتیجه عدم فروش در هر ماه است. به طور مشابه، برای پیشبینی فروش در سطح کلان، طول دادههای فروش تاریخی محدود بود. هم دادههای فروش گمشده و هم طول محدود دادههای فروش تاریخی، چالشهای مهمی را از نظر دقت مدل برای پیشبینی فروش بلندمدت در سال 2026 ایجاد میکنند. سطح محصول) تا فروش در سطح کلان (سطح BL)، مقادیر از دست رفته کمتر معنی دار می شوند. با این حال، حداکثر طول دادههای فروش تاریخی (حداکثر طول 140 ماه) همچنان چالشهای مهمی را از نظر دقت مدل ایجاد میکند.
تکنیک های مدل سازی
پس از EDA، ما بر پیشبینی در سطوح BL و MAG و در سطح محصول برای یکی از بزرگترین بازارهای نهایی (بازار نهایی خودرو) برای NXP تمرکز کردیم. با این حال، راهحلهایی که ما توسعه دادهایم را میتوان به سایر بازارهای نهایی گسترش داد. مدل سازی در سطح BL، MAG یا محصول، مزایا و معایب خاص خود را از نظر عملکرد مدل و در دسترس بودن داده ها دارد. جدول زیر این مزایا و معایب را برای هر سطح خلاصه می کند. برای پیشبینی فروش در سطح کلان، ما از پیشبینی خودکار پیشبینی آمازون برای راهحل نهایی خود استفاده کردیم. به طور مشابه، برای پیشبینی فروش در سطح خرد، یک رویکرد جدید مبتنی بر ابر نقطه ایجاد کردیم.

پیش بینی فروش کلان (از بالا به پایین)
برای پیشبینی ارزشهای فروش بلندمدت (2026) در سطح کلان، روشهای مختلفی از جمله Amazon Forecast، GluonTS و N-BEATS (اجرا شده در GluonTS و PyTorch) را آزمایش کردیم. به طور کلی، Forecast برای پیشبینی فروش در سطح کلان، از همه روشهای دیگر مبتنی بر رویکرد بکآزمایی (که در بخش معیارهای ارزیابی بعداً در این پست توضیح داده شد) بهتر عمل کرد. ما همچنین دقت AutoPredictor را با پیشبینیهای انسانی مقایسه کردیم.
ما همچنین استفاده از N-BEATS را به دلیل خواص تفسیری آن پیشنهاد کردیم. N-BEATS بر اساس یک معماری بسیار ساده اما قدرتمند است که از مجموعه ای از شبکه های پیشخور استفاده می کند که از اتصالات باقیمانده با بلوک های باقی مانده انباشته برای پیش بینی استفاده می کند. این معماری بیشتر سوگیری استقرایی را در معماری خود رمزگذاری می کند تا مدل سری زمانی را قادر به استخراج روند و فصلی کند (شکل زیر را ببینید). این تفاسیر با استفاده از PyTorch Forecasting ایجاد شد.
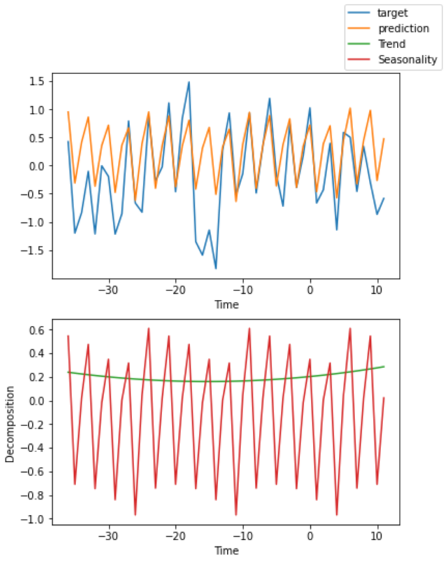
پیش بینی فروش خرد (از پایین به بالا)
در این بخش، روش جدیدی را مورد بحث قرار میدهیم که برای پیشبینی چرخه عمر محصول نشان داده شده در شکل زیر در حالی که محصول شروع سرد را در نظر میگیریم، بحث میکنیم. ما این روش را با استفاده از PyTorch در پیاده سازی کردیم Amazon SageMaker Studio. ابتدا یک روش مبتنی بر ابر نقطه ای را معرفی کردیم. این روش ابتدا داده های فروش را به یک نقطه ابری تبدیل می کند، جایی که هر نقطه نشان دهنده داده های فروش در سن خاصی از محصول است. مدل شبکه عصبی مبتنی بر ابر نقطه ای با استفاده از این داده ها برای یادگیری پارامترهای منحنی چرخه عمر محصول آموزش داده می شود (شکل زیر را ببینید). در این رویکرد، ما همچنین ویژگیهای اضافی، از جمله توصیف محصول را به عنوان مجموعهای از کلمات برای مقابله با مشکل شروع سرد برای پیشبینی منحنی چرخه عمر محصول، گنجاندهایم.

سری های زمانی به عنوان پیش بینی چرخه عمر محصول مبتنی بر ابر نقطه
ما یک رویکرد مبتنی بر ابر نقطه جدید برای پیشبینی چرخه عمر محصول و پیشبینیهای فروش در سطح خرد ایجاد کردیم. ما همچنین ویژگیهای اضافی را برای بهبود بیشتر دقت مدل برای پیشبینیهای چرخه عمر محصول شروع سرد گنجاندهایم. این ویژگیها شامل تکنیکهای ساخت محصول و سایر اطلاعات طبقهبندی مرتبط با محصولات است. چنین داده های اضافی می تواند به مدل کمک کند تا فروش یک محصول جدید را حتی قبل از عرضه در بازار (شروع سرد) پیش بینی کند. شکل زیر رویکرد مبتنی بر ابر نقطه ای را نشان می دهد. این مدل، فروش نرمال شده و سن محصول (تعداد ماههایی که از زمان عرضه محصول میگذرد) را به عنوان ورودی در نظر میگیرد. بر اساس این ورودی ها، مدل در طول آموزش با استفاده از گرادیان نزول، پارامترها را یاد می گیرد. در مرحله پیشبینی، پارامترها به همراه ویژگیهای محصول شروع سرد برای پیشبینی چرخه عمر استفاده میشوند. تعداد زیاد مقادیر از دست رفته در داده ها در سطح محصول تقریباً بر تمام مدل های سری زمانی موجود تأثیر منفی می گذارد. این راهحل جدید مبتنی بر ایدههای مدلسازی چرخه حیات و رفتار با دادههای سری زمانی به عنوان ابرهای نقطهای برای کاهش مقادیر از دست رفته است.

شکل زیر نشان می دهد که چگونه روش چرخه حیات مبتنی بر ابر نقطه ما به مقادیر داده های از دست رفته پرداخته و قادر به پیش بینی چرخه عمر محصول با نمونه های آموزشی بسیار کمی است. محور X نشان دهنده سن در زمان است و محور Y نشان دهنده فروش یک محصول است. نقاط نارنجی نشان دهنده نمونه های آموزشی، نقاط سبز نشان دهنده نمونه های آزمایشی، و خط آبی نشان دهنده چرخه عمر پیش بینی شده یک محصول توسط مدل است.

روش شناسی
برای پیشبینی فروش در سطح کلان، ما از Amazon Forecast در میان تکنیکهای دیگر استفاده کردیم. به طور مشابه، برای فروش خرد، ما یک مدل سفارشی مبتنی بر ابر نقطه ای پیشرفته را توسعه دادیم. پیشبینی از نظر عملکرد مدل بهتر از سایر روشها بود. ما از نمونه های نوت بوک Amazon SageMaker برای ایجاد خط لوله پردازش داده استفاده کردیم که نمونه های آموزشی را از سرویس ذخیره سازی ساده آمازون (Amazon S3) استخراج می کرد. داده های آموزشی بیشتر به عنوان ورودی برای Forecast برای آموزش یک مدل و پیش بینی فروش بلند مدت استفاده شد.
آموزش مدل سری زمانی با استفاده از آمازون پیش بینی شامل سه مرحله اصلی است. در مرحله اول، داده های تاریخی را به آمازون S3 وارد کردیم. دوم، یک پیش بینی با استفاده از داده های تاریخی آموزش داده شد. در نهایت، ما پیش بینی آموزش دیده را برای ایجاد پیش بینی مستقر کردیم. در این قسمت توضیحات مفصلی به همراه کدهای هر مرحله ارائه می دهیم.
ما با استخراج آخرین داده های فروش شروع کردیم. این مرحله شامل آپلود مجموعه داده در آمازون S3 در قالب صحیح بود. آمازون Forecast سه ستون را به عنوان ورودی می گیرد: timestamp، item_id، و target_value (داده های فروش). ستون مهر زمان حاوی زمان فروش است که می تواند به صورت ساعتی، روزانه و غیره قالب بندی شود. ستون item_id حاوی نام اقلام فروخته شده و ستون target_value حاوی مقادیر فروش است. در مرحله بعد، از مسیر دادههای آموزشی واقع در آمازون S3 استفاده کردیم، فرکانس مجموعههای زمانی سری (H, D, W, M, Y) را تعریف کردیم، یک نام مجموعه را تعریف کردیم و ویژگیهای مجموعه داده را شناسایی کردیم (نقشهبرداری از ستونهای مربوطه در مجموعه داده و انواع داده های آنها). سپس، تابع create_dataset را از API Boto3 فراخوانی کردیم تا مجموعه داده ای با ویژگی هایی مانند Domain، DatasetType، DatasetName، DatasetFrequency و Schema ایجاد کنیم. این تابع یک شی JSON را برگرداند که حاوی نام منبع آمازون (ARN) بود. این ARN متعاقباً در مراحل زیر مورد استفاده قرار گرفت. کد زیر را ببینید:
dataset_path = "PATH_OF_DATASET_IN_S3"
DATASET_FREQUENCY = "M" # Frequency of dataset (H, D, W, M, Y) TS_DATASET_NAME = "NAME_OF_THE_DATASET"
TS_SCHEMA = { "Attributes":[ { "AttributeName":"item_id", "AttributeType":"string" }, { "AttributeName":"timestamp", "AttributeType":"timestamp" }, { "AttributeName":"target_value", "AttributeType":"float" } ]
} create_dataset_response = forecast.create_dataset(Domain="CUSTOM", DatasetType='TARGET_TIME_SERIES', DatasetName=TS_DATASET_NAME, DataFrequency=DATASET_FREQUENCY, Schema=TS_SCHEMA) ts_dataset_arn = create_dataset_response['DatasetArn']پس از ایجاد مجموعه داده، با استفاده از Boto3 به Amazon Forecast وارد شد create_dataset_import_job تابع. create_dataset_import_job تابع نام شغل (مقدار رشته)، ARN مجموعه داده از مرحله قبل، مکان داده های آموزشی در آمازون S3 از مرحله قبل، و قالب مهر زمان را به عنوان آرگومان می گیرد. یک شی JSON حاوی کار واردات ARN را برمی گرداند. کد زیر را ببینید:
TIMESTAMP_FORMAT = "yyyy-MM-dd"
TS_IMPORT_JOB_NAME = "SALES_DATA_IMPORT_JOB_NAME" ts_dataset_import_job_response = forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME, DatasetArn=ts_dataset_arn, DataSource= { "S3Config" : { "Path": ts_s3_path, "RoleArn": role_arn } }, TimestampFormat=TIMESTAMP_FORMAT, TimeZone = TIMEZONE) ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']سپس از مجموعه داده وارد شده برای ایجاد یک گروه داده با استفاده از تابع create_dataset_group استفاده شد. این تابع دامنه (مقادیر رشته ای که دامنه پیش بینی را تعریف می کند)، نام گروه مجموعه داده و مجموعه داده ARN را به عنوان ورودی می گیرد:
DATASET_GROUP_NAME = "SALES_DATA_GROUP_NAME"
DATASET_ARNS = [ts_dataset_arn] create_dataset_group_response = forecast.create_dataset_group(Domain="CUSTOM", DatasetGroupName=DATASET_GROUP_NAME, DatasetArns=DATASET_ARNS) dataset_group_arn = create_dataset_group_response['DatasetGroupArn']
در مرحله بعد، ما از گروه داده برای آموزش مدلهای پیشبینی استفاده کردیم. آمازون پیش بینی مدل های مختلف پیشرفته ای را ارائه می دهد. هر یک از این مدل ها را می توان برای آموزش استفاده کرد. ما از AutoPredictor به عنوان مدل پیش فرض خود استفاده کردیم. مزیت اصلی استفاده از AutoPredictor این است که به طور خودکار پیش بینی سطح آیتم را با استفاده از مدل بهینه از مجموعه ای از شش مدل پیشرفته بر اساس مجموعه داده ورودی تولید می کند. Boto3 API فراهم می کند create_auto_predictor عملکرد برای آموزش یک مدل پیش بینی خودکار. پارامترهای ورودی این تابع هستند PredictorName, ForecastHorizonو فرکانس پیش بینی. کاربران همچنین مسئولیت انتخاب افق و فرکانس پیش بینی را بر عهده دارند. افق پیش بینی اندازه پنجره پیش بینی آینده را نشان می دهد که می تواند ساعت ها، روزها، هفته ها، ماه ها و غیره را قالب بندی کند. به طور مشابه، فرکانس پیشبینی نشاندهنده دانهبندی مقادیر پیشبینیشده، مانند ساعتی، روزانه، هفتگی، ماهانه یا سالانه است. ما عمدتاً بر پیش بینی فروش ماهانه NXP در BL های مختلف متمرکز شده ایم. کد زیر را ببینید:
PREDICTOR_NAME = "SALES_PREDICTOR"
FORECAST_HORIZON = 24
FORECAST_FREQUENCY = "M" create_auto_predictor_response = forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME, ForecastHorizon = FORECAST_HORIZON, ForecastFrequency = FORECAST_FREQUENCY, DataConfig = { 'DatasetGroupArn': dataset_group_arn }) predictor_arn = create_auto_predictor_response['PredictorArn']سپس از پیش بینی آموزش دیده برای تولید مقادیر پیش بینی استفاده شد. پیش بینی ها با استفاده از ایجاد_پیش بینی عملکرد از پیش بینی آموزش دیده قبلی. این تابع نام پیش بینی و ARN پیش بینی کننده را به عنوان ورودی می گیرد و مقادیر پیش بینی افق و فرکانس تعریف شده در پیش بینی را تولید می کند:
FORECAST_NAME = "SALES_FORECAST" create_forecast_response = forecast.create_forecast(ForecastName=FORECAST_NAME, PredictorArn=predictor_arn)Amazon Forecast یک سرویس کاملاً مدیریت شده است که به طور خودکار مجموعه داده های آموزشی و آزمایشی را تولید می کند و معیارهای دقت مختلفی را برای ارزیابی قابلیت اطمینان پیش بینی تولید شده توسط مدل ارائه می دهد. با این حال، برای ایجاد توافق بر روی دادههای پیشبینیشده و مقایسه مقادیر پیشبینیشده با پیشبینیهای انسانی، دادههای تاریخی خود را به دادههای آموزشی و دادههای اعتبارسنجی به صورت دستی تقسیم کردیم. ما مدل را با استفاده از داده های آموزشی بدون قرار دادن مدل در معرض داده های اعتبار سنجی آموزش دادیم و پیش بینی طول داده های اعتبار سنجی را ایجاد کردیم. داده های اعتبارسنجی با مقادیر پیش بینی شده برای ارزیابی عملکرد مدل مقایسه شد. معیارهای اعتبارسنجی ممکن است شامل میانگین درصد خطای مطلق (MAPE) و خطای درصد مطلق وزنی (WAPE) باشد. همانطور که در بخش بعدی بحث شد، ما از WAPE به عنوان متریک دقت خود استفاده کردیم.
معیارهای ارزیابی
ما ابتدا عملکرد مدل را با استفاده از آزمون پسزمینه تأیید کردیم تا پیشبینی مدل پیشبینی خود را برای پیشبینی بلندمدت فروش (فروش 2026) تأیید کنیم. ما عملکرد مدل را با استفاده از WAPE ارزیابی کردیم. هرچه مقدار WAPE کمتر باشد، مدل بهتر است. مزیت کلیدی استفاده از WAPE نسبت به سایر معیارهای خطا مانند MAPE این است که WAPE تأثیر فردی فروش هر کالا را می سنجد. بنابراین، در هنگام محاسبه خطای کلی، سهم هر محصول در کل فروش را محاسبه می کند. به عنوان مثال، اگر در محصولی که 2 میلیون دلار تولید می کند، 30 درصد خطا و در محصولی که 10 دلار تولید می کند، خطای 50,000 درصدی داشته باشید، MAPE شما کل داستان را بازگو نمی کند. خطای 2% در واقع گرانتر از خطای 10% است، چیزی که با استفاده از MAPE نمی توانید آن را تشخیص دهید. به طور نسبی، WAPE این تفاوت ها را محاسبه می کند. ما همچنین مقادیر مختلف صدک را برای فروش پیشبینی کردیم تا مرزهای بالا و پایین پیشبینی مدل را نشان دهیم.
اعتبارسنجی مدل پیشبینی فروش در سطح کلان
در مرحله بعد، عملکرد مدل را از نظر مقادیر WAPE تأیید کردیم. ما مقدار WAPE یک مدل را با تقسیم دادهها به مجموعههای تست و اعتبارسنجی محاسبه کردیم. به عنوان مثال، در ارزش WAPE 2019، ما مدل خود را با استفاده از دادههای فروش بین سالهای 2011-2018 آموزش دادیم و ارزشهای فروش را برای 12 ماه آینده (فروش 2019) پیشبینی کردیم. سپس مقدار WAPE را با استفاده از فرمول زیر محاسبه کردیم:

ما همین رویه را برای محاسبه مقدار WAPE برای سالهای 2020 و 2021 تکرار کردیم. ما WAPE را برای همه BL ها در بازار پایان خودرو برای سالهای 2019، 2020 و 2021 ارزیابی کردیم. به طور کلی، مشاهده کردیم که پیشبینی آمازون میتواند به مقدار WAPE 0.33 حتی برای سال 2020 (در طول همه گیری COVID-19). در سالهای 2019 و 2020، مدل ما کمتر از 0.1 مقادیر WAPE را به دست آورد که دقت بالایی را نشان میدهد.
مقایسه پایه پیشبینی فروش در سطح کلان
ما عملکرد مدلهای پیشبینی فروش کلان توسعهیافته با استفاده از پیشبینی آمازون را با سه مدل پایه از نظر ارزش WAPE برای سالهای 2019، 2020 و 2021 مقایسه کردیم (شکل زیر را ببینید). پیش بینی آمازون یا به طور قابل توجهی بهتر از سایر مدل های پایه عمل کرد یا در تمام 3 سال عملکردی مشابه داشت. این نتایج بیشتر اثربخشی پیشبینیهای مدل نهایی ما را تأیید میکند.

مدل پیشبینی فروش در سطح کلان در مقابل پیشبینیهای انسانی
برای تایید بیشتر اطمینان مدل سطح کلان خود، در مرحله بعد عملکرد مدل خود را با ارزش های فروش پیش بینی شده توسط انسان مقایسه کردیم. در ابتدای سه ماهه چهارم هر سال، کارشناسان بازار در NXP ارزش فروش هر BL را با در نظر گرفتن روندهای بازار جهانی و همچنین سایر شاخص های جهانی که به طور بالقوه می توانند بر فروش محصولات NXP تأثیر بگذارند، پیش بینی می کنند. ما درصد خطای پیشبینی مدل را در مقابل پیشبینی انسان با ارزشهای فروش واقعی در سالهای 2019، 2020 و 2021 مقایسه میکنیم. ما سه مدل را با استفاده از دادههای 2011-2018 آموزش دادیم و ارزشهای فروش را تا سال 2021 پیشبینی کردیم. سپس MAPE را برای آن محاسبه کردیم. ارزش های واقعی فروش سپس از مقادیر پیشبینیشده توسط انسان تا پایان سال 2018 استفاده کردیم (پیشبینی مدل را از 1 سال قبل تا پیشبینی 3 سال آینده آزمایش کنید). ما این فرآیند را برای پیشبینی مقادیر در سال 2019 (پیشبینی 1 سال آینده تا پیشبینی 2 سال آینده) و 2020 (برای پیشبینی 1 سال آینده) تکرار کردیم. به طور کلی، این مدل با پیشبینیکنندههای انسانی یا در برخی موارد بهتر عمل کرد. این نتایج اثربخشی و قابلیت اطمینان مدل ما را نشان می دهد.
پیش بینی فروش در سطح خرد و چرخه عمر محصول
شکل زیر نحوه رفتار مدل را با استفاده از داده های محصول نشان می دهد در حالی که به مشاهدات بسیار کمی برای هر محصول دسترسی دارد (یعنی یک یا دو مشاهده در ورودی برای پیش بینی چرخه عمر محصول). نقاط نارنجی نشان دهنده داده های آموزشی، نقاط سبز نشان دهنده داده های تست و خط آبی نشان دهنده چرخه عمر محصول پیش بینی شده مدل است.

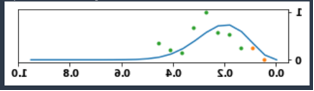

این مدل می تواند مشاهدات بیشتری را برای زمینه بدون نیاز به آموزش مجدد با در دسترس قرار گرفتن داده های فروش جدید تغذیه کند. شکل زیر نشان میدهد که اگر مدل بیشتری به آن زمینه داده شود، چگونه رفتار میکند. در نهایت، زمینه بیشتر منجر به کاهش مقادیر WAPE می شود.
علاوه بر این، ما موفق شدیم ویژگیهای اضافی را برای هر محصول، از جمله تکنیکهای ساخت و سایر اطلاعات طبقهبندی، ترکیب کنیم. در این راستا، ویژگی های خارجی به کاهش مقدار WAPE در رژیم کم زمینه کمک کردند (شکل زیر را ببینید). دو توضیح برای این رفتار وجود دارد. اول، ما باید اجازه دهیم که داده ها برای خود در رژیم های با زمینه بالا صحبت کنند. ویژگیهای اضافی میتوانند در این فرآیند اختلال ایجاد کنند. دوم، ما به ویژگی های بهتری نیاز داریم. ما از 1,000 ویژگی رمزگذاری شده یک بعدی (کیسه کلمات) استفاده کردیم. حدس این است که تکنیک های مهندسی ویژگی بهتر می تواند به کاهش WAPE حتی بیشتر کمک کند.
چنین داده های اضافی می تواند به مدل کمک کند تا فروش محصولات جدید را حتی قبل از عرضه در بازار پیش بینی کند. به عنوان مثال، در شکل زیر نشان میدهیم که فقط از ویژگیهای خارجی چقدر مسافت پیموده شده است.

نتیجه
در این پست، ما نشان دادیم که چگونه تیمهای MLSL و NXP با یکدیگر برای پیشبینی فروش بلندمدت در سطح کلان و خرد برای NXP کار کردند. تیم NXP اکنون میآموزد که چگونه از این پیشبینیهای فروش در فرآیندهای خود استفاده کند - به عنوان مثال، استفاده از آن به عنوان ورودی برای تصمیمگیریهای بودجه تحقیق و توسعه و افزایش بازگشت سرمایه. ما از پیشبینی آمازون برای پیشبینی فروش برای خطوط کسبوکار (فروش کلان) استفاده کردیم که از آن به عنوان رویکرد بالا به پایین یاد کردیم. ما همچنین یک رویکرد جدید با استفاده از سری های زمانی به عنوان یک ابر نقطه برای مقابله با چالش های مقادیر از دست رفته و شروع سرد در سطح محصول (سطح خرد) پیشنهاد کردیم. ما به این رویکرد به عنوان پایین به بالا اشاره کردیم، جایی که ما فروش ماهانه هر محصول را پیش بینی کردیم. ما بیشتر ویژگی های خارجی هر محصول را برای بهبود عملکرد مدل برای شروع سرد گنجانده ایم.
به طور کلی، مدلهای توسعهیافته در طول این تعامل در مقایسه با پیشبینی انسان عملکردی مشابه داشتند. در برخی موارد، مدلها در بلندمدت بهتر از پیشبینیهای انسانی عمل کردند. این نتایج اثربخشی و قابلیت اطمینان مدل های ما را نشان می دهد.
این راه حل می تواند برای هر مشکل پیش بینی استفاده شود. برای کمک بیشتر در زمینه طراحی و توسعه راه حل های ML، لطفاً رایگان با ما تماس بگیرید MLSL تیم.
درباره نویسندگان
 سواد بوتان یک دانشمند داده در NXP-CTO است، جایی که در حال تبدیل داده های مختلف به بینش های معنادار برای حمایت از تصمیم گیری تجاری با استفاده از ابزارها و تکنیک های پیشرفته است.
سواد بوتان یک دانشمند داده در NXP-CTO است، جایی که در حال تبدیل داده های مختلف به بینش های معنادار برای حمایت از تصمیم گیری تجاری با استفاده از ابزارها و تکنیک های پیشرفته است.
 بن فریدولین یک دانشمند داده در NXP-CTO است، جایی که او در زمینه تسریع هوش مصنوعی و پذیرش ابر هماهنگ می کند. او بر یادگیری ماشینی، یادگیری عمیق و راهحلهای ML سرتاسر تمرکز دارد.
بن فریدولین یک دانشمند داده در NXP-CTO است، جایی که او در زمینه تسریع هوش مصنوعی و پذیرش ابر هماهنگ می کند. او بر یادگیری ماشینی، یادگیری عمیق و راهحلهای ML سرتاسر تمرکز دارد.
 کورنی گینن یک پروژه پیشرو در پورتفولیو داده NXP است که از سازمان در تحول دیجیتالی آن به سمت داده محور شدن پشتیبانی می کند.
کورنی گینن یک پروژه پیشرو در پورتفولیو داده NXP است که از سازمان در تحول دیجیتالی آن به سمت داده محور شدن پشتیبانی می کند.
 بارت زیمن یک استراتژیست با اشتیاق به داده ها و تجزیه و تحلیل در NXP-CTO است که در آن برای تصمیم گیری های داده محور بهتر برای رشد و نوآوری بیشتر رانندگی می کند.
بارت زیمن یک استراتژیست با اشتیاق به داده ها و تجزیه و تحلیل در NXP-CTO است که در آن برای تصمیم گیری های داده محور بهتر برای رشد و نوآوری بیشتر رانندگی می کند.
 احسان علی یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که با مشتریانی از حوزه های مختلف کار می کند تا مشکلات فوری و گران قیمت آنها را با استفاده از تکنیک های پیشرفته AI/ML حل کند.
احسان علی یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که با مشتریانی از حوزه های مختلف کار می کند تا مشکلات فوری و گران قیمت آنها را با استفاده از تکنیک های پیشرفته AI/ML حل کند.
 ییفو هو یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به طراحی راه حل های خلاقانه ML برای رسیدگی به مشکلات تجاری مشتریان در صنایع مختلف کمک می کند.
ییفو هو یک دانشمند کاربردی در آزمایشگاه راه حل های یادگیری ماشین آمازون است، جایی که به طراحی راه حل های خلاقانه ML برای رسیدگی به مشکلات تجاری مشتریان در صنایع مختلف کمک می کند.
 مهدی نوری مدیر علوم کاربردی در آمازون ML Solutions Lab است، جایی که به توسعه راه حلهای ML برای سازمانهای بزرگ در صنایع مختلف کمک میکند و بخش انرژی را رهبری میکند. او علاقه زیادی به استفاده از AI/ML برای کمک به مشتریان در دستیابی به اهداف پایداری خود دارد.
مهدی نوری مدیر علوم کاربردی در آمازون ML Solutions Lab است، جایی که به توسعه راه حلهای ML برای سازمانهای بزرگ در صنایع مختلف کمک میکند و بخش انرژی را رهبری میکند. او علاقه زیادی به استفاده از AI/ML برای کمک به مشتریان در دستیابی به اهداف پایداری خود دارد.
 حذیفه رنگوالا مدیر ارشد علوم کاربردی در AIRE، AWS است. او تیمی از دانشمندان و مهندسان را رهبری میکند تا امکان کشف داراییهای داده مبتنی بر یادگیری ماشین را فراهم کنند. علایق تحقیقاتی او در هوش مصنوعی مسئول، یادگیری فدرال و کاربردهای ML در مراقبت های بهداشتی و علوم زندگی است.
حذیفه رنگوالا مدیر ارشد علوم کاربردی در AIRE، AWS است. او تیمی از دانشمندان و مهندسان را رهبری میکند تا امکان کشف داراییهای داده مبتنی بر یادگیری ماشین را فراهم کنند. علایق تحقیقاتی او در هوش مصنوعی مسئول، یادگیری فدرال و کاربردهای ML در مراقبت های بهداشتی و علوم زندگی است.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/predicting-new-and-existing-product-sales-in-semiconductors-using-amazon-forecast/

