机器学习 (ML) 的最新发展导致模型越来越大,其中一些需要数千亿个参数。尽管它们更强大,但这些模型的训练和推理需要大量的计算资源。尽管可以使用高级分布式训练库,但训练和推理作业通常需要数百个加速器(GPU 或专用机器学习芯片,例如 AWS 培训 和 AWS 推理),因此有数十或数百个实例。
在这种分布式环境中,实例和机器学习芯片的可观测性成为模型性能微调和成本优化的关键。指标使团队能够了解工作负载行为、优化资源分配和利用、诊断异常并提高整体基础设施效率。对于数据科学家来说,机器学习芯片的利用率和饱和度也与容量规划相关。
这篇文章将带您了解 AWS Inferentia 的开源可观测性模式,它向您展示了如何监控机器学习芯片的性能,该芯片用于 Amazon Elastic Kubernetes服务 (Amazon EKS) 集群,数据平面节点基于 亚马逊弹性计算云 (Amazon EC2) 类型的实例 信息1 和 信息2.
该图案是 AWS CDK 可观测性加速器,一组固执己见的模块,可帮助您设置 Amazon EKS 集群的可观察性。 AWS CDK Observability Accelerator 围绕模式进行组织,这些模式是用于部署多个资源的可重用单元。开源可观测性模式集可观测性工具 亚马逊托管 Grafana 仪表板,一个 用于 OpenTelemetry 的 AWS 发行版 收集器收集指标,以及 亚马逊普罗米修斯托管服务 存储它们。
解决方案概述
下图说明了解决方案体系结构。

此解决方案部署一个 Amazon EKS 集群,其节点组包含 Inf1 实例。
节点组的 AMI 类型为 AL2_x86_64_GPU,使用 Amazon EKS 优化加速 Amazon Linux AMI。除了经过 Amazon EKS 优化的标准 AMI 配置外,加速 AMI 还包括 NeuronX 运行时.
为了从 Kubernetes 访问 ML 芯片,该模式部署了 AWS 神经元 设备插件。
指标由 Amazon Managed Service for Prometheus 公开 neuron-monitor DaemonSet,部署一个最小的容器, 神经元工具 安装。具体来说, neuron-monitor DaemonSet 运行 neuron-monitor 命令通过管道传输到 neuron-monitor-prometheus.py 配套脚本(两个命令都是容器的一部分):
neuron-monitor | neuron-monitor-prometheus.py --port <port>
该命令使用以下组件:
neuron-monitor 从系统上运行的 Neuron 应用程序收集指标和统计数据,并将收集到的数据流式传输到标准输出 JSON格式neuron-monitor-prometheus.py 将遥测数据从 JSON 格式映射并公开为 Prometheus 兼容格式
数据在 Amazon Managed Grafana 中通过相应的仪表板进行可视化。
使用 Amazon Managed Service for Prometheus 和 Amazon Managed Grafana 收集和可视化指标的其余设置与其他基于开源的模式中使用的设置类似,这些设置包含在 AWS Observability Accelerator for CDK GitHub 存储库。
先决条件
您需要以下内容才能完成本文中的步骤:
搭建环境
完成以下步骤来设置您的环境:
- 打开终端窗口并运行以下命令:
export AWS_REGION=<YOUR AWS REGION>
export ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' --output text)
- 检索任何现有 Amazon Managed Grafana 工作区的工作区 ID:
aws grafana list-workspaces
以下是我们的示例输出:
{
"workspaces": [
{
"authentication": {
"providers": [
"AWS_SSO"
]
},
"created": "2023-06-07T12:23:56.625000-04:00",
"description": "accelerator-workspace",
"endpoint": "g-XYZ.grafana-workspace.us-east-2.amazonaws.com",
"grafanaVersion": "9.4",
"id": "g-XYZ",
"modified": "2023-06-07T12:30:09.892000-04:00",
"name": "accelerator-workspace",
"notificationDestinations": [
"SNS"
],
"status": "ACTIVE",
"tags": {}
}
]
}
- 指定以下值:
id 和 endpoint 到以下环境变量:
export COA_AMG_WORKSPACE_ID="<<YOUR-WORKSPACE-ID, similar to the above g-XYZ, without quotation marks>>"
export COA_AMG_ENDPOINT_URL="<<https://YOUR-WORKSPACE-URL, including protocol (i.e. https://), without quotation marks, similar to the above https://g-XYZ.grafana-workspace.us-east-2.amazonaws.com>>"
COA_AMG_ENDPOINT_URL 需要包括 https://.
- 从 Amazon Managed Grafana 工作区创建 Grafana API 密钥:
export AMG_API_KEY=$(aws grafana create-workspace-api-key
--key-name "grafana-operator-key"
--key-role "ADMIN"
--seconds-to-live 432000
--workspace-id $COA_AMG_WORKSPACE_ID
--query key
--output text)
- 设定一个秘密 AWS系统经理:
aws ssm put-parameter --name "/cdk-accelerator/grafana-api-key"
--type "SecureString"
--value $AMG_API_KEY
--region $AWS_REGION
该密钥将由外部密钥附加组件访问,并作为 EKS 集群中的本机 Kubernetes 密钥提供。
引导 AWS CDK 环境
任何 AWS CDK 部署的第一步是引导环境。您使用 cdk bootstrap AWS CDK CLI 中的命令来准备环境(AWS 账户和 AWS 区域的组合)以及 AWS CDK 在该环境中执行部署所需的资源。每个账户和区域组合都需要 AWS CDK 引导,因此,如果您已在某个区域中引导 AWS CDK,则无需重复引导过程。
cdk bootstrap aws://$ACCOUNT_ID/$AWS_REGION
部署解决方案
完成以下步骤来部署解决方案:
- 克隆 cdk-aws-可观测性加速器 存储库并安装依赖包。此存储库包含用 TypeScript 编写的 AWS CDK v2 代码。
git clone https://github.com/aws-observability/cdk-aws-observability-accelerator.git
cd cdk-aws-observability-accelerator
Grafana 仪表板 JSON 文件的实际设置预计在 AWS CDK 上下文中指定。你需要更新 context ,在 cdk.json 文件,位于当前目录。仪表板的位置由 fluxRepository.values.GRAFANA_NEURON_DASH_URL 参数,以及 neuronNodeGroup 用于设置实例类型、数量等 Amazon Elastic Block商店 (Amazon EBS) 用于节点的大小。
- 将以下代码片段输入到
cdk.json,替换 context:
"context": {
"fluxRepository": {
"name": "grafana-dashboards",
"namespace": "grafana-operator",
"repository": {
"repoUrl": "https://github.com/aws-observability/aws-observability-accelerator",
"name": "grafana-dashboards",
"targetRevision": "main",
"path": "./artifacts/grafana-operator-manifests/eks/infrastructure"
},
"values": {
"GRAFANA_CLUSTER_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/cluster.json",
"GRAFANA_KUBELET_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/kubelet.json",
"GRAFANA_NSWRKLDS_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/namespace-workloads.json",
"GRAFANA_NODEEXP_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/nodeexporter-nodes.json",
"GRAFANA_NODES_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/nodes.json",
"GRAFANA_WORKLOADS_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/infrastructure/workloads.json",
"GRAFANA_NEURON_DASH_URL" : "https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/grafana-dashboards/eks/neuron/neuron-monitor.json"
},
"kustomizations": [
{
"kustomizationPath": "./artifacts/grafana-operator-manifests/eks/infrastructure"
},
{
"kustomizationPath": "./artifacts/grafana-operator-manifests/eks/neuron"
}
]
},
"neuronNodeGroup": {
"instanceClass": "inf1",
"instanceSize": "2xlarge",
"desiredSize": 1,
"minSize": 1,
"maxSize": 3,
"ebsSize": 512
}
}
您可以将 Inf1 实例类型替换为 Inf2,并根据需要更改大小。要检查所选区域的可用性,请运行以下命令(修改 Values 如您认为合适):
aws ec2 describe-instance-type-offerings
--filters Name=instance-type,Values="inf1*"
--query "InstanceTypeOfferings[].InstanceType"
--region $AWS_REGION
- 安装项目依赖项:
- 运行以下命令来部署开源可观察性模式:
make build
make pattern single-new-eks-inferentia-opensource-observability deploy
验证解决方案
完成以下步骤来验证解决方案:
- 运行
update-kubeconfig 命令。您应该能够从上一个命令的输出消息中获取该命令:
aws eks update-kubeconfig --name single-new-eks-inferentia-opensource... --region <your region> --role-arn arn:aws:iam::xxxxxxxxx:role/single-new-eks-....
- 验证您创建的资源:
以下屏幕截图显示了我们的示例输出。

- 确保
neuron-device-plugin-daemonset DaemonSet 正在运行:
kubectl get ds neuron-device-plugin-daemonset --namespace kube-system
以下是我们的预期输出:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
neuron-device-plugin-daemonset 1 1 1 1 1 <none> 2h
- 确认
neuron-monitor DaemonSet 正在运行:
kubectl get ds neuron-monitor --namespace kube-system
以下是我们的预期输出:
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE
neuron-monitor 1 1 1 1 1 <none> 2h
- 要验证 Neuron 设备和内核是否可见,请运行
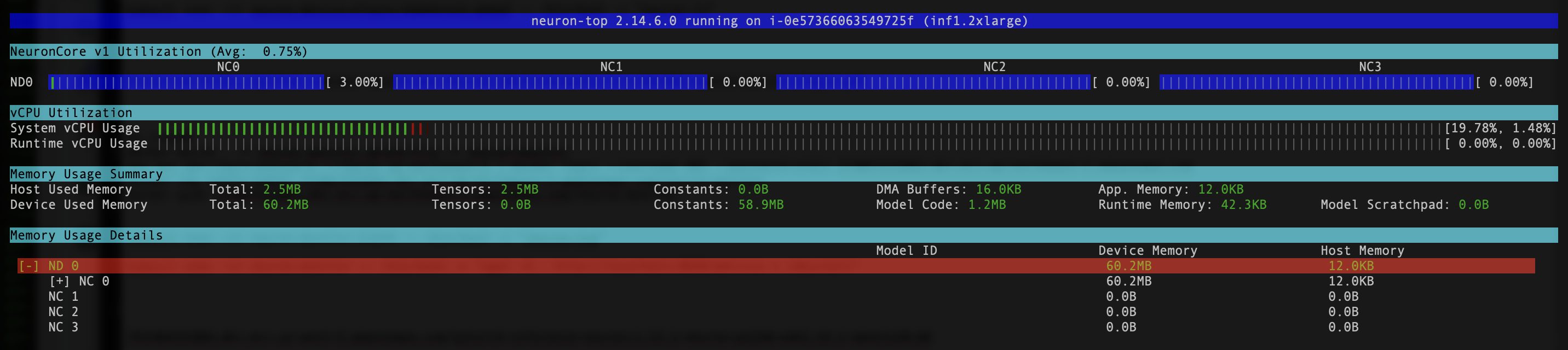
neuron-ls 和 neuron-top 例如,来自神经元监视器 pod 的命令(您可以从以下命令的输出中获取 pod 的名称) kubectl get pods -A):
kubectl exec -it {your neuron-monitor pod} -n kube-system -- /bin/bash -c "neuron-ls"
以下屏幕截图显示了我们的预期输出。

kubectl exec -it {your neuron-monitor pod} -n kube-system -- /bin/bash -c "neuron-top"
以下屏幕截图显示了我们的预期输出。
使用 Grafana Neuron 仪表板可视化数据
登录到您的 Amazon Managed Grafana 工作区并导航到 仪表板 控制板。您应该看到一个名为的仪表板 神经元/监视器.
要在 Grafana 仪表板上查看一些有趣的指标,我们应用以下清单:
curl https://raw.githubusercontent.com/aws-observability/aws-observability-accelerator/main/artifacts/k8s-deployment-manifest-templates/neuron/pytorch-inference-resnet50.yml | kubectl apply -f -
这是一个示例工作负载,用于编译 torchvision ResNet50 模型 并在循环中运行重复推理以生成遥测数据。
要验证 Pod 是否已成功部署,请运行以下代码:
您应该会看到一个名为 pytorch-inference-resnet50.
几分钟后,查看 神经元/监视器 在仪表板中,您应该会看到类似于以下屏幕截图的收集指标。




Grafana Operator 和 Flux 始终协同工作,将您的仪表板与 Git 同步。如果您意外删除仪表板,它们将自动重新配置。
清理
您可以使用以下命令删除整个 AWS CDK 堆栈:
make pattern single-new-eks-inferentia-opensource-observability destroy
结论
在这篇文章中,我们向您展示了如何使用开源工具将可观察性引入具有运行 EC2 Inf1 实例的数据平面的 EKS 集群。我们首先为数据平面节点选择 Amazon EKS 优化的加速 AMI,其中包括 Neuron 容器运行时,提供对 AWS Inferentia 和 Trainium Neuron 设备的访问。然后,为了向 Kubernetes 公开 Neuron 核心和设备,我们部署了 Neuron 设备插件。遥测数据的实际收集和映射为 Prometheus 兼容格式是通过以下方式实现的 neuron-monitor 和 neuron-monitor-prometheus.py。指标源自 Prometheus 的 Amazon Managed Service,并显示在 Amazon Managed Grafana 的 Neuron 仪表板上。
我们建议您探索其他可观察性模式 适用于 CDK 的 AWS 可观测性加速器 GitHub 存储库。要了解有关 Neuron 的更多信息,请参阅 AWS Neuron文档.
关于作者
 里卡多·弗雷斯基 是 AWS 的高级解决方案架构师,专注于应用程序现代化。他与合作伙伴和客户密切合作,通过重构现有应用程序和构建新应用程序,帮助他们在转向 AWS 云的过程中转变 IT 环境。
里卡多·弗雷斯基 是 AWS 的高级解决方案架构师,专注于应用程序现代化。他与合作伙伴和客户密切合作,通过重构现有应用程序和构建新应用程序,帮助他们在转向 AWS 云的过程中转变 IT 环境。

