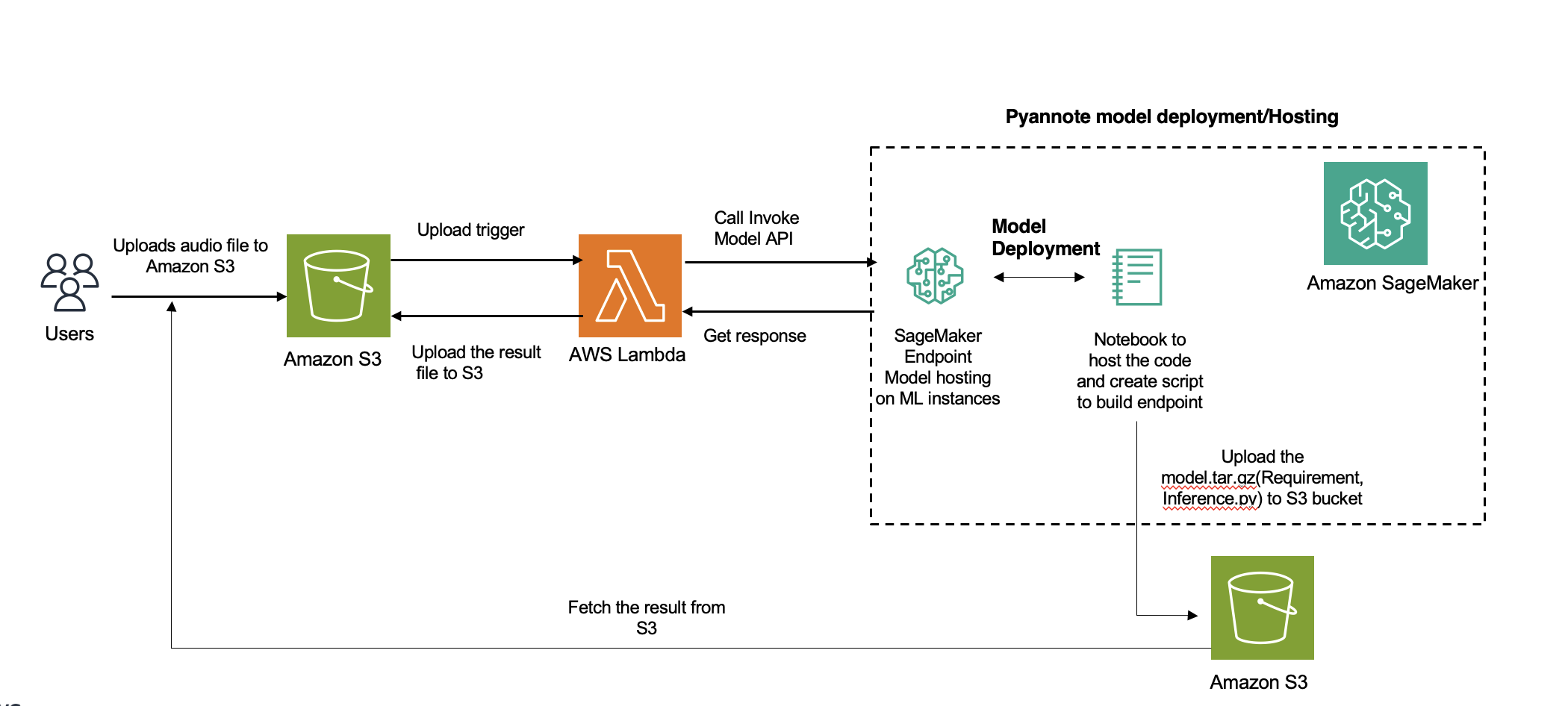
您可以使用 Hugging Face Hub 来访问所需的预训练 PyAnnote 说话人二值化模型。创建 SageMaker 终端节点时,您可以使用相同的脚本下载模型文件。
请参见以下代码:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
封装模型代码
准备必要的文件,例如 inference.py,其中包含推理代码:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
准备一个 requirements.txt 文件,其中包含运行推理所需的 Python 库:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
测试端点
通过发送音频文件进行分类并检索存储在指定 S3 输出路径中的 JSON 输出来评估端点功能:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
 桑杰·蒂瓦里 是一名专家 AI/ML 解决方案架构师,他花时间与战略客户合作来定义业务需求,围绕特定用例提供 L300 会话,并设计可扩展、可靠且高性能的 AI/ML 应用程序和服务。他帮助启动和扩展了由 AI/ML 驱动的 Amazon SageMaker 服务,并使用 Amazon AI 服务实施了多项概念验证。他还开发了高级分析平台,作为数字化转型之旅的一部分。
桑杰·蒂瓦里 是一名专家 AI/ML 解决方案架构师,他花时间与战略客户合作来定义业务需求,围绕特定用例提供 L300 会话,并设计可扩展、可靠且高性能的 AI/ML 应用程序和服务。他帮助启动和扩展了由 AI/ML 驱动的 Amazon SageMaker 服务,并使用 Amazon AI 服务实施了多项概念验证。他还开发了高级分析平台,作为数字化转型之旅的一部分。 基兰·查拉帕利 是 AWS 公共部门的深度技术业务开发人员。他在 AI/ML 领域拥有超过 8 年的经验,以及 23 年的整体软件开发和销售经验。 Kiran 帮助印度各地的公共部门企业探索和共同创建基于云的解决方案,这些解决方案使用人工智能、机器学习和生成人工智能(包括大型语言模型)技术。
基兰·查拉帕利 是 AWS 公共部门的深度技术业务开发人员。他在 AI/ML 领域拥有超过 8 年的经验,以及 23 年的整体软件开发和销售经验。 Kiran 帮助印度各地的公共部门企业探索和共同创建基于云的解决方案,这些解决方案使用人工智能、机器学习和生成人工智能(包括大型语言模型)技术。
