جنوری 2024 میں، ایمیزون سیج میکر ایک نیا ورژن شروع کیا (0.26.0) بڑے ماڈل انفرنس (LMI) ڈیپ لرننگ کنٹینرز (DLCs) کا۔ یہ ورژن نئے ماڈلز (بشمول ماہرین کا مرکب)، کارکردگی اور افادیت میں بہتری کے لیے معاونت پیش کرتا ہے، نیز انفرنس بیک اینڈز میں کنٹرول اور پیشین گوئی کی وضاحت کے لیے نئی نسل کی تفصیلات (جیسے کہ جنریشن مکمل ہونے کی وجہ اور ٹوکن لیول لاگ امکانات)۔
LMI DLCs ایک کم کوڈ انٹرفیس پیش کرتے ہیں جو جدید ترین انفرنس آپٹیمائزیشن تکنیک اور ہارڈ ویئر کے استعمال کو آسان بناتا ہے۔ LMI آپ کو ٹینسر متوازی لاگو کرنے کی اجازت دیتا ہے۔ تازہ ترین موثر توجہ، بیچنگ، کوانٹائزیشن، اور میموری مینجمنٹ کی تکنیک؛ ٹوکن سٹریمنگ؛ اور بہت کچھ، صرف ماڈل ID اور اختیاری ماڈل پیرامیٹرز کی ضرورت کے ذریعے۔ SageMaker پر LMI DLCs کے ساتھ، آپ اپنے لیے وقت سے قدر کو تیز کر سکتے ہیں۔ تخلیقی مصنوعی ذہانت (AI) ایپلی کیشنز، آف لوڈ انفراسٹرکچر سے متعلق ہیوی لفٹنگ، اور اپنی پسند کے ہارڈ ویئر کے لیے بڑے لینگوئج ماڈلز (LLMs) کو بہتر بنائیں تاکہ قیمت کی بہترین کارکردگی حاصل کی جا سکے۔
اس پوسٹ میں، ہم اس ریلیز میں متعارف کرائی گئی تازہ ترین خصوصیات کو دریافت کرتے ہیں، کارکردگی کے بینچ مارکس کی جانچ کرتے ہیں، اور اعلی کارکردگی پر LMI DLC کے ساتھ نئے LLMs کی تعیناتی کے بارے میں ایک تفصیلی گائیڈ فراہم کرتے ہیں۔
LMI DLCs کے ساتھ نئی خصوصیات
اس سیکشن میں، ہم LMI بیک اینڈ پر نئی خصوصیات پر تبادلہ خیال کرتے ہیں، اور کچھ دیگر پر ڈرل ڈاؤن کرتے ہیں جو بیک اینڈ مخصوص ہیں۔ LMI فی الحال درج ذیل پس منظر کی حمایت کرتا ہے:
- LMI- تقسیم شدہ لائبریری - نتیجہ پر بہترین ممکنہ تاخیر اور درستگی حاصل کرنے کے لیے، OSS سے متاثر، LLMs کے ساتھ اندازہ لگانے کے لیے یہ AWS فریم ورک ہے۔
- ایل ایم آئی وی ایل ایل ایم - یہ میموری موثر کا AWS پسدید نفاذ ہے۔ vLLM انفرنس لائبریری
- LMI TensorRT-LLM ٹول کٹ - یہ AWS بیک اینڈ پر عمل درآمد ہے۔ NVIDIA TensorRT-LLM، جو مختلف GPUs پر کارکردگی کو بہتر بنانے کے لیے GPU مخصوص انجن بناتا ہے۔
- ایل ایم آئی ڈیپ اسپیڈ - یہ AWS کی موافقت ہے۔ ڈیپ اسپیڈ، جو حقیقی مسلسل بیچنگ، اسموتھ کوانٹ کوانٹائزیشن، اور قیاس کے دوران میموری کو متحرک طور پر ایڈجسٹ کرنے کی صلاحیت کا اضافہ کرتا ہے۔
- LMI نیورون ایکس - آپ اسے پر تعیناتی کے لیے استعمال کر سکتے ہیں۔ AWS Inferentia2 اور AWS ٹرینیم-کی بنیاد پر مثالیں، حقیقی مسلسل بیچنگ اور اسپیڈ اپ کی خاصیت AWS نیوران SDK
مندرجہ ذیل جدول نئی شامل کردہ خصوصیات کا خلاصہ کرتا ہے، دونوں عام اور بیک اینڈ مخصوص۔
|
بیک اینڈز میں عام |
|||
|
|||
|
پسدید مخصوص |
|||
|
LMI-تقسیم |
vLLM | TensorRT-LLM |
نیورون ایکس |
|
|
|
|
نئے ماڈلز کی حمایت کی گئی۔
نئے مشہور ماڈل بیک اینڈز میں سپورٹ ہوتے ہیں، جیسے Mistral-7B (تمام بیک اینڈز)، MoE پر مبنی Mixtral (Transformers-NeuronX کے علاوہ تمام بیک اینڈز)، اور Llama2-70B (Transformers-NeuronX)۔
سیاق و سباق کی ونڈو کی توسیع کی تکنیک
روٹری پوزیشنل ایمبیڈنگ (RoPE) پر مبنی سیاق و سباق کی پیمائش اب LMI-Dist، vLLM، اور TensorRT-LLM بیک اینڈز پر دستیاب ہے۔ RoPE اسکیلنگ ایک ماڈل کی ترتیب کی لمبائی میں کسی بھی سائز کے تخمینے کے دوران توسیع کے قابل بناتی ہے، بغیر ٹھیک ٹیوننگ کی ضرورت کے۔
RoPE استعمال کرتے وقت درج ذیل دو اہم تحفظات ہیں:
- ماڈل کی الجھن - جیسا کہ ترتیب کی لمبائی بڑھتی ہے، تو کر سکتے ہیں ماڈل کی اضطراب. اصل ٹریننگ میں استعمال ہونے والے ان پٹ سیکوینسز سے بڑے ان پٹ سیکونسز پر کم سے کم فائن ٹیوننگ کر کے اس اثر کو جزوی طور پر پورا کیا جا سکتا ہے۔ RoPE ماڈل کے معیار کو کس طرح متاثر کرتا ہے اس کی گہرائی سے تفہیم کے لیے رجوع کریں۔ RoPE کو بڑھانا.
- کارکردگی کا اندازہ - طویل ترتیب کی لمبائی زیادہ ایکسلریٹر کی ہائی بینڈوتھ میموری (HBM) استعمال کرے گی۔ یادداشت کا یہ بڑھتا ہوا استعمال آپ کے ایکسلریٹر کو سنبھالنے والی سمورتی درخواستوں کی تعداد کو بری طرح متاثر کر سکتا ہے۔
نسل کی تفصیلات شامل کی گئیں۔
اب آپ نسل کے نتائج کے بارے میں دو عمدہ تفصیلات حاصل کر سکتے ہیں:
- تکمیل_وجہ - یہ جنریشن کی تکمیل کی وجہ بتاتا ہے، جو کہ زیادہ سے زیادہ جنریشن کی لمبائی تک پہنچ سکتا ہے، جملے کے اختتام (EOS) ٹوکن کو پیدا کر سکتا ہے، یا صارف کی طرف سے طے شدہ سٹاپ ٹوکن بنا سکتا ہے۔ یہ آخری سٹریم شدہ ترتیب کے حصے کے ساتھ لوٹا جاتا ہے۔
- log_probs - یہ سٹریمڈ سیکوینس حصے میں ہر ٹوکن کے لیے ماڈل کے ذریعے تفویض کردہ لاگ امکان کو لوٹاتا ہے۔ آپ ان کا استعمال کر سکتے ہیں ماڈل اعتماد کے کسی اندازے کے طور پر کسی ترتیب کے مشترکہ امکان کا حساب لگا کر
log_probsانفرادی ٹوکنز کا، جو ماڈل آؤٹ پٹ کو اسکور کرنے اور درجہ بندی کرنے کے لیے مفید ہو سکتا ہے۔ یاد رکھیں کہ LLM ٹوکن کے امکانات عام طور پر انشانکن کے بغیر زیادہ پر اعتماد ہوتے ہیں۔
آپ LMI میں اپنے ان پٹ پے لوڈ میں تفصیلات=True شامل کر کے جنریشن کے نتائج کے آؤٹ پٹ کو فعال کر سکتے ہیں، باقی تمام پیرامیٹرز کو بغیر تبدیلی کے چھوڑ کر:
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}کنسولیڈیٹڈ کنفیگریشن پیرامیٹرز
آخر میں، LMI کنفیگریشن کے پیرامیٹرز کو بھی مضبوط کر دیا گیا ہے۔ تمام عام اور بیک اینڈ مخصوص تعیناتی کنفیگریشن پیرامیٹرز کے بارے میں مزید معلومات کے لیے، دیکھیں بڑے ماڈل انفرنس کنفیگریشنز.
LMI- تقسیم شدہ پسدید
AWS re:Invent 2023 میں، LMI-Dist نے GPUs کے درمیان مواصلت کو تیز کرنے کے لیے نئے، بہتر بنائے گئے اجتماعی آپریشنز کا اضافہ کیا، جس کے نتیجے میں ان ماڈلز کے لیے کم تاخیر اور زیادہ تھرو پٹ ہوتا ہے جو ایک GPU کے لیے بہت بڑے ہیں۔ یہ مجموعہ p4d مثالوں کے لیے خصوصی طور پر SageMaker کے لیے دستیاب ہیں۔
جب کہ پچھلی تکرار صرف تمام 8 GPUs میں شارڈنگ کی حمایت کرتی تھی، LMI 0.26.0 جزوی طور پر تمام پیٹرن میں 4 کے ٹینسر متوازی ڈگری کے لیے سپورٹ متعارف کراتا ہے۔ اس کے ساتھ مل کر کیا جا سکتا ہے سیج میکر انفرنس اجزاء، جس کے ساتھ آپ دانے دار طور پر ترتیب دے سکتے ہیں کہ اختتامی نقطہ کے پیچھے تعینات ہر ماڈل کے لیے کتنے ایکسلریٹر مختص کیے جائیں۔ ایک ساتھ، یہ خصوصیات بنیادی مثال کے وسائل کے استعمال پر بہتر کنٹرول فراہم کرتی ہیں، آپ کو ایک اختتامی نقطہ کے پیچھے مختلف ماڈلز کی میزبانی کرکے ماڈل ملٹی ٹینسی کو بڑھانے کے قابل بناتی ہیں، یا آپ کے ماڈل اور ٹریفک کی خصوصیات سے مماثل ہونے کے لیے آپ کی تعیناتی کے مجموعی تھروپپٹ کو بہتر بناتی ہیں۔
مندرجہ ذیل اعداد و شمار براہ راست سب سے سب کا جزوی سب سے سب کے ساتھ موازنہ کرتا ہے۔
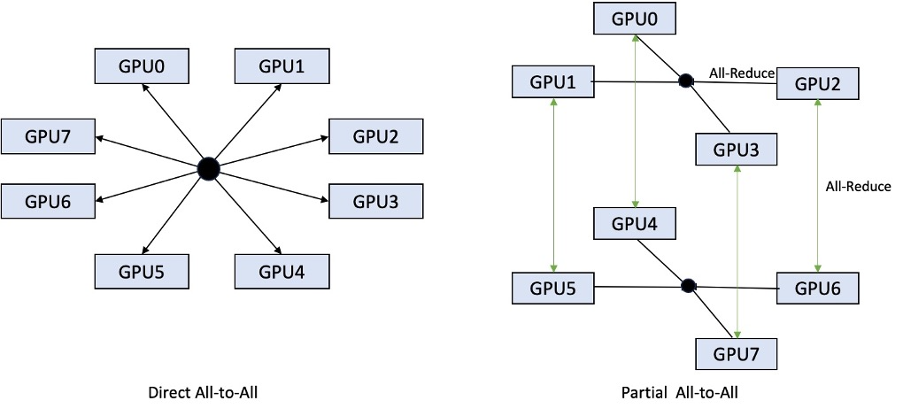
TensorRT-LLM پسدید
NVIDIA کے TensorRT-LLM کو پچھلی LMI DLC ریلیز (0.25.0) کے حصے کے طور پر متعارف کرایا گیا تھا، جو NVIDIA GPU استعمال کرتے وقت جدید ترین GPU کارکردگی اور اسموتھ کوانٹ، FP8، اور LLMs کے لیے مسلسل بیچنگ کو فعال کرتا ہے۔
TensorRT-LLM کو تعیناتی سے پہلے ماڈلز کو موثر انجنوں میں مرتب کرنے کی ضرورت ہے۔ LMI TensorRT-LLM DLC سرور کو شروع کرنے اور ریئل ٹائم انفرنس کے لیے ماڈل کو لوڈ کرنے سے پہلے، صرف وقت میں معاون ماڈلز کی فہرست مرتب کرنے کو خود بخود سنبھال سکتا ہے۔ DLC کا ورژن 0.26.0 JIT کی تالیف کے لیے معاون ماڈلز کی فہرست کو بڑھاتا ہے، جس میں Baichuan، ChatGLM، GPT2، GPT-J، InternLM، Mistral، Mixtral، Qwen، SantaCoder اور StarCoder ماڈلز متعارف کرائے جاتے ہیں۔
جے آئی ٹی کی تالیف اختتامی نقطہ کی فراہمی اور اسکیلنگ کے وقت میں کئی منٹ کے اوور ہیڈ کا اضافہ کرتی ہے، اس لیے یہ ہمیشہ تجویز کیا جاتا ہے کہ آپ اپنے ماڈل کو وقت سے پہلے مرتب کریں۔ ایسا کرنے کے طریقے کے بارے میں رہنمائی اور معاون ماڈلز کی فہرست کے لیے، دیکھیں TensorRT-LLM ماڈل ٹیوٹوریل کی وقت سے پہلے کی تالیف. اگر آپ کا منتخب کردہ ماڈل ابھی تک تعاون یافتہ نہیں ہے، تو رجوع کریں۔ TensorRT-LLM ماڈلز ٹیوٹوریل کی دستی تالیف کسی دوسرے ماڈل کو مرتب کرنے کے لیے جو TensorRT-LLM سے تعاون یافتہ ہو۔
مزید برآں، LMI اب مقامی TensorRT-LLM SmootQuant کوانٹائزیشن کو ظاہر کرتا ہے، ٹوکن یا چینل کے ذریعہ الفا اور اسکیلنگ فیکٹر کو کنٹرول کرنے کے پیرامیٹرز کے ساتھ۔ متعلقہ کنفیگریشنز کے بارے میں مزید معلومات کے لیے رجوع کریں۔ TensorRT-LLM.
vLLM پسدید
LMI DLC میں شامل vLLM کی تازہ ترین ریلیز میں 50% تک کی کارکردگی میں بہتری آئی ہے جو ایگر موڈ کے بجائے CUDA گراف موڈ کے ذریعے چلائی گئی ہے۔ CUDA گراف انفرادی طور پر شروع کرنے کے بجائے ایک ہی بار میں کئی GPU آپریشنز شروع کرکے GPU ورک بوجھ کو تیز کرتے ہیں، جس سے اوور ہیڈز کم ہوتے ہیں۔ یہ خاص طور پر چھوٹے ماڈلز کے لیے مؤثر ہے جب ٹینسر متوازی کا استعمال کرتے ہیں۔
اضافی کارکردگی اضافی GPU میموری کی کھپت کے ٹریڈ آف پر آتی ہے۔ CUDA گراف موڈ اب vLLM بیک اینڈ کے لیے پہلے سے طے شدہ ہے، لہذا اگر آپ GPU میموری کی دستیاب مقدار پر مجبور ہیں، تو آپ سیٹ کر سکتے ہیں۔ option.enforce_eager=True PyTorch کے شوقین موڈ کو مجبور کرنے کے لیے۔
ٹرانسفارمرز-نیورون ایکس بیک اینڈ
کی تازہ ترین ریلیز نیورون ایکس LMI NeuronX DLC میں شامل اب ان ماڈلز کو سپورٹ کرتا ہے جو گروپڈ سوال پر توجہ دینے کے طریقہ کار کو نمایاں کرتے ہیں، جیسے Mistral-7B اور LLama2-70B۔ گروپ شدہ سوال کی توجہ ڈیفالٹ ٹرانسفارمر توجہ کے طریقہ کار کی ایک اہم اصلاح ہے، جہاں ماڈل کو استفسار کے سروں کے مقابلے میں کم کلید اور ویلیو ہیڈز کے ساتھ تربیت دی جاتی ہے۔ اس سے GPU میموری پر KV کیشے کا سائز کم ہو جاتا ہے، جس سے زیادہ ہم آہنگی ہوتی ہے، اور قیمت کی کارکردگی میں بہتری آتی ہے۔
مندرجہ ذیل اعداد و شمار ملٹی ہیڈ، گروپڈ استفسار، اور کثیر استفسار پر توجہ دینے کے طریقوں کی وضاحت کرتا ہے (ذرائع).
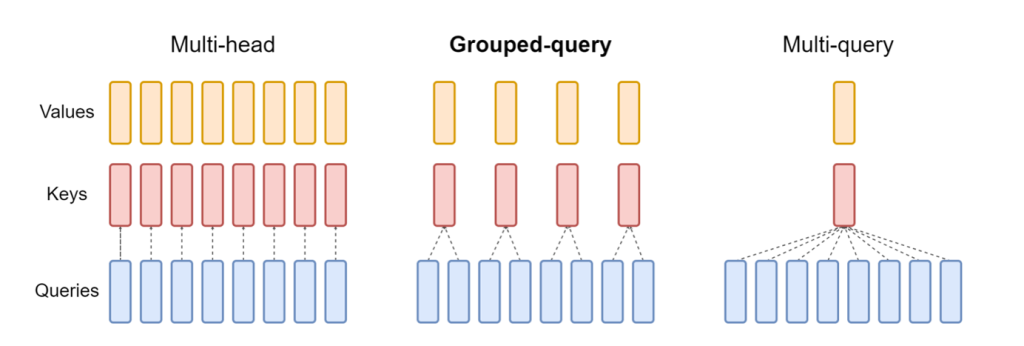
مختلف قسم کے کام کے بوجھ کو پورا کرنے کے لیے مختلف KV کیش شارڈنگ کی حکمت عملی دستیاب ہیں۔ شارڈنگ کی حکمت عملیوں کے بارے میں مزید معلومات کے لیے، دیکھیں گروپ شدہ سوال کی توجہ (GQA) سپورٹ. آپ اپنی مطلوبہ حکمت عملی کو فعال کر سکتے ہیں (shard-over-heads، مثال کے طور پر) درج ذیل کوڈ کے ساتھ:
مزید برآں، NeuronX DLC کا نیا نفاذ TransformerNeuronX کے لیے ایک کیش API متعارف کراتا ہے جو KV کیشے تک رسائی کے قابل بناتا ہے۔ یہ آپ کو نئی درخواستوں سے KV کیشے کی قطاریں داخل کرنے اور ہٹانے کی اجازت دیتا ہے جب آپ بیچڈ انفرنس دے رہے ہوں۔ اس API کو متعارف کرانے سے پہلے، KV کیشے کو کسی بھی نئی شامل کردہ درخواستوں کے لیے دوبارہ گنتی کی گئی تھی۔ LMI V7 (0.25.0) کے مقابلے میں، ہم نے ہم آہنگی کی درخواستوں کے ساتھ 33 فیصد سے زیادہ تاخیر کو بہتر کیا ہے، اور بہت زیادہ تھرو پٹ کو سپورٹ کیا ہے۔
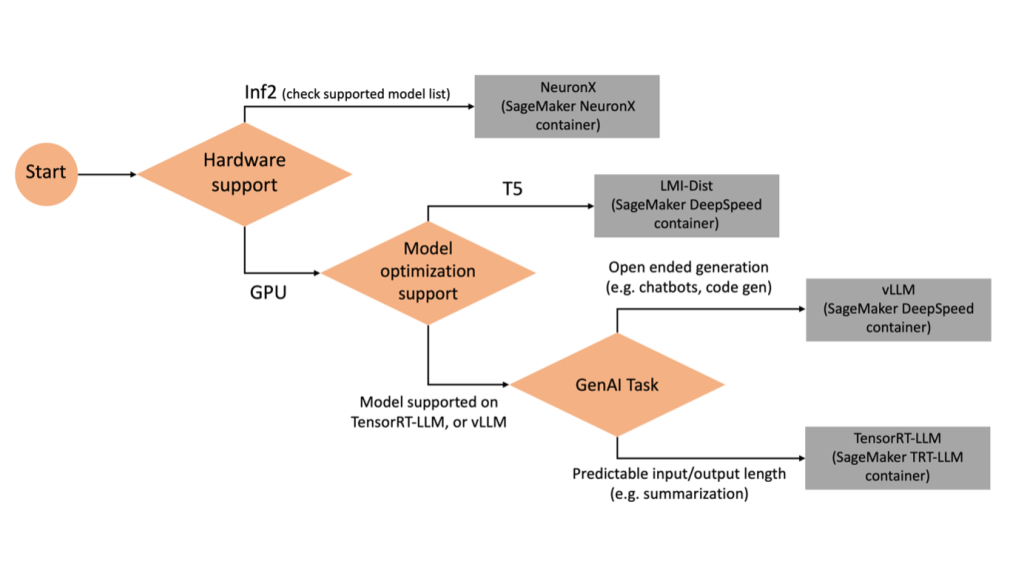
دائیں پسدید کو منتخب کرنا
منتخب ماڈل اور ٹاسک کی بنیاد پر یہ فیصلہ کرنے کے لیے کہ کون سا بیک اینڈ استعمال کرنا ہے، درج ذیل فلو چارٹ کا استعمال کریں۔ معاون ماڈلز کے ساتھ انفرادی بیک اینڈ یوزر گائیڈز کے لیے، دیکھیں LMI بیک اینڈ یوزر گائیڈز.
اضافی صفات کے ساتھ LMI DLC کے ساتھ Mixtral تعینات کریں۔
آئیے دیکھتے ہیں کہ آپ Mixtral-8x7B ماڈل کو LMI 0.26.0 کنٹینر کے ساتھ کیسے تعینات کر سکتے ہیں اور اضافی تفصیلات تیار کر سکتے ہیں جیسے log_prob اور finish_reason آؤٹ پٹ کے حصے کے طور پر۔ ہم اس بات پر بھی تبادلہ خیال کرتے ہیں کہ آپ مواد کی تخلیق کے استعمال کے کیس کے ذریعے ان اضافی صفات سے کیسے فائدہ اٹھا سکتے ہیں۔
تفصیلی ہدایات کے ساتھ مکمل نوٹ بک میں دستیاب ہے۔ GitHub repo.
ہم لائبریریوں کو درآمد کرکے اور سیشن کے ماحول کو ترتیب دے کر شروع کرتے ہیں:
آپ بغیر کسی اضافی انفرنس کوڈ کے ماڈلز کی میزبانی کے لیے SageMaker LMI کنٹینرز استعمال کر سکتے ہیں۔ آپ ماڈل سرور کو یا تو ماحولیاتی متغیرات یا a کے ذریعے ترتیب دے سکتے ہیں۔ serving.properties فائل اختیاری طور پر، آپ کو ایک ہو سکتا ہے model.py کسی بھی پری پروسیسنگ یا پوسٹ پروسیسنگ کے لیے فائل اور اے requirements.txt کسی بھی اضافی پیکجوں کے لیے فائل جو انسٹال کرنے کی ضرورت ہے۔
اس صورت میں، ہم استعمال کرتے ہیں serving.properties پیرامیٹرز کو ترتیب دینے اور LMI کنٹینر کے رویے کو حسب ضرورت بنانے کے لیے فائل۔ مزید تفصیلات کے لیے، سے رجوع کریں۔ GitHub repo. ریپو مختلف کنفیگریشن پیرامیٹرز کی تفصیلات بتاتا ہے جو آپ سیٹ کر سکتے ہیں۔ ہمیں درج ذیل کلیدی پیرامیٹرز کی ضرورت ہے:
- انجن - DJL کے استعمال کے لیے رن ٹائم انجن کی وضاحت کرتا ہے۔ یہ ماڈل کے لیے ایکسلریٹر میں شارڈنگ اور ماڈل لوڈ کرنے کی حکمت عملی کو چلاتا ہے۔
- option.model_id - کی وضاحت کرتا ہے۔ ایمیزون سادہ اسٹوریج سروس (Amazon S3) پہلے سے تربیت یافتہ ماڈل کا URI یا پہلے سے تربیت یافتہ ماڈل کی ماڈل ID گلے لگانے والا چہرہ. اس صورت میں، ہم Mixtral-8x7B ماڈل کے لیے ماڈل ID فراہم کرتے ہیں۔
- option.tensor_parallel_degree – GPU ڈیوائسز کی تعداد سیٹ کرتا ہے جس پر ایکسلریٹ کو ماڈل کو تقسیم کرنے کی ضرورت ہے۔ یہ پیرامیٹر فی ماڈل کارکنوں کی تعداد کو بھی کنٹرول کرتا ہے جو DJL سرونگ کے چلنے پر شروع کیے جائیں گے۔ ہم نے اس قدر کو مقرر کیا۔
max(موجودہ مشین پر زیادہ سے زیادہ GPU)۔ - option.rolling_batch - ایکسلریٹر کے استعمال اور مجموعی تھرو پٹ کو بہتر بنانے کے لیے مسلسل بیچنگ کو قابل بناتا ہے۔ TensorRT-LLM کنٹینر کے لیے، ہم استعمال کرتے ہیں۔
auto. - option.model_loading_timeout - اندازہ پیش کرنے کے لیے ماڈل کو ڈاؤن لوڈ اور لوڈ کرنے کے لیے ٹائم آؤٹ ویلیو سیٹ کرتا ہے۔
- option.max_rolling_batch - مسلسل بیچ کے زیادہ سے زیادہ سائز کو متعین کرتا ہے، اس بات کی وضاحت کرتا ہے کہ کسی بھی وقت متوازی طور پر کتنے سلسلے پر کارروائی کی جا سکتی ہے۔
ہم پیکج serving.properties tar.gz فارمیٹ میں کنفیگریشن فائل، تاکہ یہ SageMaker ہوسٹنگ کی ضروریات کو پورا کرے۔ ہم DJL LMI کنٹینر کو کنفیگر کرتے ہیں۔ tensorrtllm پسدید انجن کے طور پر. مزید برآں، ہم کنٹینر کا تازہ ترین ورژن (0.26.0) بتاتے ہیں۔
اگلا، ہم مقامی ٹربال اپ لوڈ کرتے ہیں (جس میں serving.properties کنفیگریشن فائل) ایک S3 سابقہ میں۔ SageMaker ماڈل آبجیکٹ بنانے کے لیے، ہم DJL کنٹینر اور Amazon S3 مقام کے لیے امیج URI کا استعمال کرتے ہیں جس پر نمونے پیش کرنے والے ماڈل کو ٹربال اپ لوڈ کیا گیا تھا۔
LMI 0.26.0 کے حصے کے طور پر، اب آپ پیدا شدہ آؤٹ پٹ کے بارے میں دو اضافی باریک تفصیلات استعمال کر سکتے ہیں:
- log_probs - یہ سٹریمڈ سیکوینس کے ہر ٹوکن کے لیے ماڈل کے ذریعے تفویض کردہ لاگ امکان ہے۔ آپ انفرادی ٹوکنز کے لاگ امکانات کے مجموعہ کے طور پر کسی ترتیب کے مشترکہ امکان کو شمار کر کے ماڈل کے اعتماد کے موٹے تخمینے کے طور پر استعمال کر سکتے ہیں، جو ماڈل آؤٹ پٹس کو اسکور کرنے اور درجہ بندی کرنے کے لیے مفید ہو سکتا ہے۔ یاد رکھیں کہ LLM ٹوکن کے امکانات عام طور پر انشانکن کے بغیر زیادہ پر اعتماد ہوتے ہیں۔
- تکمیل_وجہ – یہ جنریشن کی تکمیل کی وجہ ہے، جو زیادہ سے زیادہ جنریشن کی لمبائی تک پہنچ سکتی ہے، ایک EOS ٹوکن تیار کر رہی ہے، یا صارف کی طرف سے طے شدہ سٹاپ ٹوکن بنا سکتی ہے۔ یہ آخری سٹریم شدہ ترتیب کے حصے کے ساتھ لوٹا جاتا ہے۔
آپ گزر کر ان کو فعال کر سکتے ہیں۔ "details"=True ماڈل میں آپ کے ان پٹ کے حصے کے طور پر۔
آئیے دیکھتے ہیں کہ آپ یہ تفصیلات کیسے تیار کر سکتے ہیں۔ ہم ان کے اطلاق کو سمجھنے کے لیے مواد تیار کرنے کی مثال استعمال کرتے ہیں۔
ہم تعریف کرتے ہیں a LineIterator ہیلپر کلاس، جس کے فنکشنز سستی سے کسی رسپانس اسٹریم سے بائٹس حاصل کرنے، انہیں بفر کرنے، اور بفر کو لائنوں میں تقسیم کرنے کے لیے ہیں۔ خیال یہ ہے کہ بفر سے بائٹس پیش کریں جبکہ اسٹریم سے غیر مطابقت پذیری سے مزید بائٹس حاصل کریں۔
اضافی تفصیل کے طور پر ٹوکن امکان پیدا کریں اور استعمال کریں۔
استعمال کے معاملے پر غور کریں جہاں ہم مواد تیار کر رہے ہیں۔ خاص طور پر، ہمیں طرز زندگی پر مرکوز ویب سائٹ کے لیے باقاعدگی سے ورزش کرنے کے فوائد کے بارے میں ایک مختصر پیراگراف لکھنے کا کام سونپا گیا ہے۔ ہم مواد تیار کرنا چاہتے ہیں اور اس اعتماد کے کچھ اشارے سکور کو آؤٹ پٹ کرنا چاہتے ہیں جو ماڈل کے تیار کردہ مواد میں ہے۔
ہم اپنے پرامپٹ کے ساتھ ماڈل اینڈ پوائنٹ کو طلب کرتے ہیں اور پیدا کردہ جواب کو حاصل کرتے ہیں۔ ہم نے طے کیا "details": True ماڈل کے ان پٹ کے اندر رن ٹائم پیرامیٹر کے طور پر۔ چونکہ ہر آؤٹ پٹ ٹوکن کے لیے لاگ کا امکان پیدا ہوتا ہے، ہم انفرادی لاگ امکانات کو فہرست میں شامل کرتے ہیں۔ ہم جواب سے مکمل تیار کردہ متن کو بھی حاصل کرتے ہیں۔
اعتماد کے مجموعی اسکور کا حساب لگانے کے لیے، ہم تمام انفرادی ٹوکن امکانات کے اوسط کا حساب لگاتے ہیں اور اس کے بعد 0 اور 1 کے درمیان ایکسپونینشل ویلیو حاصل کرتے ہیں۔ یہ تیار کردہ ٹیکسٹ کے لیے ہمارا مجموعی اعتماد کا اسکور ہے، جو اس صورت میں فوائد کے بارے میں ایک پیراگراف ہے۔ باقاعدگی سے ورزش کرنے سے.

یہ اس کی ایک مثال تھی کہ آپ کس طرح تخلیق اور استعمال کرسکتے ہیں۔ log_prob، مواد تیار کرنے کے استعمال کے معاملے کے تناظر میں۔ اسی طرح، آپ استعمال کر سکتے ہیں log_prob درجہ بندی کے استعمال کے معاملات کے لیے اعتماد سکور کی پیمائش کے طور پر۔
متبادل طور پر، آپ اسے مجموعی آؤٹ پٹ ترتیب یا جملے کی سطح کے اسکورنگ کے لیے استعمال کر سکتے ہیں تاکہ پیرامیٹر کے اثرات جیسے کہ پیدا کردہ آؤٹ پٹ پر درجہ حرارت کا اندازہ لگایا جا سکے۔
اضافی تفصیل کے طور پر ختم ہونے کی وجہ پیدا کریں اور استعمال کریں۔
آئیے اسی استعمال کے معاملے کو بناتے ہیں، لیکن اس بار ہمیں ایک طویل مضمون لکھنے کا کام سونپا گیا ہے۔ مزید برآں، ہم اس بات کو یقینی بنانا چاہتے ہیں کہ جنریشن کی لمبائی کے مسائل (زیادہ سے زیادہ ٹوکن کی لمبائی) یا سٹاپ ٹوکنز کا سامنا کرنے کی وجہ سے آؤٹ پٹ کو چھوٹا نہیں کیا گیا ہے۔
اس کو پورا کرنے کے لیے، ہم استعمال کرتے ہیں۔ finish_reason آؤٹ پٹ میں پیدا ہونے والا انتساب، اس کی قدر کی نگرانی کریں، اور اس وقت تک پیدا کرنا جاری رکھیں جب تک کہ پورا آؤٹ پٹ تیار نہ ہوجائے۔
ہم ایک انفرنس فنکشن کی وضاحت کرتے ہیں جو پے لوڈ ان پٹ لیتا ہے اور SageMaker اینڈ پوائنٹ کو کال کرتا ہے، جواب کو واپس چلاتا ہے، اور تیار کردہ متن کو نکالنے کے لیے جواب پر کارروائی کرتا ہے۔ پے لوڈ میں پرامپٹ ٹیکسٹ ان پٹ اور پیرامیٹرز جیسے زیادہ سے زیادہ ٹوکن اور تفصیلات پر مشتمل ہوتا ہے۔ جواب کو ایک سٹریم میں پڑھا جاتا ہے اور تیار کردہ ٹیکسٹ ٹوکنز کو فہرست میں نکالنے کے لیے لائن بہ لائن پروسیس کیا جاتا ہے۔ ہم تفصیلات نکالتے ہیں جیسے finish_reason. ہم ہر بار مزید سیاق و سباق شامل کرتے ہوئے انفرنس فنکشن کو لوپ (زنجیروں والی درخواستوں) میں کال کرتے ہیں، اور ماڈل کے ختم ہونے تک تیار کردہ ٹوکنز اور بھیجی گئی درخواستوں کی تعداد کا پتہ لگاتے ہیں۔
جیسا کہ ہم دیکھ سکتے ہیں، اگرچہ max_new_token پیرامیٹر 256 پر سیٹ کیا گیا ہے، ہم اختتامی نقطہ پر متعدد درخواستوں کو سلسلہ کرنے کے لیے آؤٹ پٹ کے حصے کے طور پر finish_reason detail انتساب کا استعمال کرتے ہیں، جب تک کہ پورا آؤٹ پٹ تیار نہ ہوجائے۔
اسی طرح، آپ کے استعمال کے کیس کی بنیاد پر، آپ استعمال کر سکتے ہیں۔ stop_reason کسی دیے گئے کام کے لیے مخصوص آؤٹ پٹ تسلسل کی ناکافی لمبائی کا پتہ لگانے کے لیے یا انسانی سٹاپ کی ترتیب کی وجہ سے غیر ارادی تکمیل۔
نتیجہ
اس پوسٹ میں، ہم نے AWS LMI کنٹینر کے v0.26.0 ریلیز کا جائزہ لیا۔ ہم نے اہم کارکردگی میں بہتری، نئے ماڈل سپورٹ، اور نئی قابل استعمال خصوصیات کو اجاگر کیا۔ ان صلاحیتوں کے ساتھ، آپ اپنے اختتامی صارفین کو ایک بہتر تجربہ فراہم کرتے ہوئے لاگت اور کارکردگی کی خصوصیات میں بہتر توازن پیدا کر سکتے ہیں۔
LMI DLC صلاحیتوں کے بارے میں مزید جاننے کے لیے، رجوع کریں۔ ماڈل متوازی اور بڑے ماڈل کا اندازہ. ہم یہ دیکھ کر بہت پرجوش ہیں کہ آپ SageMaker سے ان نئی صلاحیتوں کو کس طرح استعمال کرتے ہیں۔
مصنفین کے بارے میں
 جواؤ مورا AWS میں ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ João AWS صارفین کی مدد کرتا ہے – چھوٹے سٹارٹ اپس سے لے کر بڑے اداروں تک – بڑے ماڈلز کو موثر طریقے سے تربیت اور تعینات کرتے ہیں، اور زیادہ وسیع پیمانے پر AWS پر ML پلیٹ فارم بنانے میں۔
جواؤ مورا AWS میں ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ João AWS صارفین کی مدد کرتا ہے – چھوٹے سٹارٹ اپس سے لے کر بڑے اداروں تک – بڑے ماڈلز کو موثر طریقے سے تربیت اور تعینات کرتے ہیں، اور زیادہ وسیع پیمانے پر AWS پر ML پلیٹ فارم بنانے میں۔
 راہول شرما AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے، جو AWS کے صارفین کو AI/ML سلوشنز ڈیزائن اور بنانے میں مدد کرتا ہے۔ AWS میں شامل ہونے سے پہلے، راہول نے کئی سال فنانس اور انشورنس کے شعبے میں گزارے ہیں، جس سے صارفین کو ڈیٹا اور تجزیاتی پلیٹ فارم بنانے میں مدد ملتی ہے۔
راہول شرما AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے، جو AWS کے صارفین کو AI/ML سلوشنز ڈیزائن اور بنانے میں مدد کرتا ہے۔ AWS میں شامل ہونے سے پہلے، راہول نے کئی سال فنانس اور انشورنس کے شعبے میں گزارے ہیں، جس سے صارفین کو ڈیٹا اور تجزیاتی پلیٹ فارم بنانے میں مدد ملتی ہے۔
 کنگ لین AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon میں کئی چیلنجنگ پروڈکٹس پر کام کر رہا ہے، بشمول ہائی پرفارمنس ایم ایل انفرنس سلوشنز اور ہائی پرفارمنس لاگنگ سسٹم۔ Qing کی ٹیم نے بہت کم تاخیر کے ساتھ Amazon Advertising میں پہلا بلین پیرامیٹر ماڈل کامیابی کے ساتھ لانچ کیا۔ کنگ کو بنیادی ڈھانچے کی اصلاح اور گہری سیکھنے کی سرعت کے بارے میں گہرائی سے علم ہے۔
کنگ لین AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ Amazon میں کئی چیلنجنگ پروڈکٹس پر کام کر رہا ہے، بشمول ہائی پرفارمنس ایم ایل انفرنس سلوشنز اور ہائی پرفارمنس لاگنگ سسٹم۔ Qing کی ٹیم نے بہت کم تاخیر کے ساتھ Amazon Advertising میں پہلا بلین پیرامیٹر ماڈل کامیابی کے ساتھ لانچ کیا۔ کنگ کو بنیادی ڈھانچے کی اصلاح اور گہری سیکھنے کی سرعت کے بارے میں گہرائی سے علم ہے۔
 جیان شینگ ایمیزون ویب سروسز میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے جس نے مشین لرننگ سسٹم کے کئی اہم پہلوؤں پر کام کیا ہے۔ وہ SageMaker Neo سروس میں کلیدی شراکت دار رہا ہے، جس نے گہری سیکھنے کی تالیف اور فریم ورک رن ٹائم آپٹیمائزیشن پر توجہ دی ہے۔ حال ہی میں، اس نے اپنی کوششوں کی ہدایت کی ہے اور بڑے ماڈل کی تشخیص کے لیے مشین لرننگ سسٹم کو بہتر بنانے میں تعاون کیا ہے۔
جیان شینگ ایمیزون ویب سروسز میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے جس نے مشین لرننگ سسٹم کے کئی اہم پہلوؤں پر کام کیا ہے۔ وہ SageMaker Neo سروس میں کلیدی شراکت دار رہا ہے، جس نے گہری سیکھنے کی تالیف اور فریم ورک رن ٹائم آپٹیمائزیشن پر توجہ دی ہے۔ حال ہی میں، اس نے اپنی کوششوں کی ہدایت کی ہے اور بڑے ماڈل کی تشخیص کے لیے مشین لرننگ سسٹم کو بہتر بنانے میں تعاون کیا ہے۔
 ٹائلر اوسٹربرگ AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ SageMaker کے اندر اعلیٰ کارکردگی والی مشین لرننگ انفرنس کے تجربات کو تیار کرنے میں مہارت رکھتا ہے۔ حال ہی میں، اس کی توجہ SageMaker پلیٹ فارم پر Inferentia Deep Learning Containers کی کارکردگی کو بہتر بنانے پر مرکوز ہے۔ ٹائلر بڑے لینگویج ماڈلز کے لیے پرفارمنٹ ہوسٹنگ سلوشنز کو نافذ کرنے اور جدید ٹیکنالوجی کا استعمال کرتے ہوئے صارف کے تجربات کو بڑھانے میں مہارت رکھتا ہے۔
ٹائلر اوسٹربرگ AWS میں سافٹ ویئر ڈویلپمنٹ انجینئر ہے۔ وہ SageMaker کے اندر اعلیٰ کارکردگی والی مشین لرننگ انفرنس کے تجربات کو تیار کرنے میں مہارت رکھتا ہے۔ حال ہی میں، اس کی توجہ SageMaker پلیٹ فارم پر Inferentia Deep Learning Containers کی کارکردگی کو بہتر بنانے پر مرکوز ہے۔ ٹائلر بڑے لینگویج ماڈلز کے لیے پرفارمنٹ ہوسٹنگ سلوشنز کو نافذ کرنے اور جدید ٹیکنالوجی کا استعمال کرتے ہوئے صارف کے تجربات کو بڑھانے میں مہارت رکھتا ہے۔
 روپندر گریوال AWS کے ساتھ ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ وہ فی الحال ایمیزون سیج میکر پر ماڈلز اور ایم ایل او پیز پیش کرنے پر توجہ مرکوز کرتا ہے۔ اس کردار سے پہلے، اس نے بطور مشین لرننگ انجینئر بلڈنگ اور ہوسٹنگ ماڈلز کے طور پر کام کیا۔ کام سے باہر، وہ ٹینس کھیلنا اور پہاڑی پگڈنڈیوں پر بائیک چلانا پسند کرتا ہے۔
روپندر گریوال AWS کے ساتھ ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ وہ فی الحال ایمیزون سیج میکر پر ماڈلز اور ایم ایل او پیز پیش کرنے پر توجہ مرکوز کرتا ہے۔ اس کردار سے پہلے، اس نے بطور مشین لرننگ انجینئر بلڈنگ اور ہوسٹنگ ماڈلز کے طور پر کام کیا۔ کام سے باہر، وہ ٹینس کھیلنا اور پہاڑی پگڈنڈیوں پر بائیک چلانا پسند کرتا ہے۔
 دھول پٹیل AWS میں پرنسپل مشین لرننگ آرکیٹیکٹ ہے۔ انہوں نے تقسیم شدہ کمپیوٹنگ اور مصنوعی ذہانت سے متعلق مسائل پر بڑے اداروں سے لے کر درمیانے درجے کے اسٹارٹ اپس تک کی تنظیموں کے ساتھ کام کیا ہے۔ وہ NLP اور کمپیوٹر ویژن ڈومینز سمیت گہری سیکھنے پر توجہ مرکوز کرتا ہے۔ وہ صارفین کو SageMaker پر اعلیٰ کارکردگی کے ماڈل کا اندازہ حاصل کرنے میں مدد کرتا ہے۔
دھول پٹیل AWS میں پرنسپل مشین لرننگ آرکیٹیکٹ ہے۔ انہوں نے تقسیم شدہ کمپیوٹنگ اور مصنوعی ذہانت سے متعلق مسائل پر بڑے اداروں سے لے کر درمیانے درجے کے اسٹارٹ اپس تک کی تنظیموں کے ساتھ کام کیا ہے۔ وہ NLP اور کمپیوٹر ویژن ڈومینز سمیت گہری سیکھنے پر توجہ مرکوز کرتا ہے۔ وہ صارفین کو SageMaker پر اعلیٰ کارکردگی کے ماڈل کا اندازہ حاصل کرنے میں مدد کرتا ہے۔
 راگھو رمیشا۔ ایمیزون سیج میکر سروس ٹیم کے ساتھ ایک سینئر ایم ایل سلوشنز آرکیٹیکٹ ہے۔ وہ صارفین کی ایم ایل پروڈکشن ورک بوجھ کو SageMaker پر پیمانے پر بنانے، تعینات کرنے اور منتقل کرنے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ وہ مشین لرننگ، AI، اور کمپیوٹر ویژن ڈومینز میں مہارت رکھتا ہے، اور UT Dallas سے کمپیوٹر سائنس میں ماسٹر ڈگری رکھتا ہے۔ اپنے فارغ وقت میں وہ سفر اور فوٹو گرافی سے لطف اندوز ہوتے ہیں۔
راگھو رمیشا۔ ایمیزون سیج میکر سروس ٹیم کے ساتھ ایک سینئر ایم ایل سلوشنز آرکیٹیکٹ ہے۔ وہ صارفین کی ایم ایل پروڈکشن ورک بوجھ کو SageMaker پر پیمانے پر بنانے، تعینات کرنے اور منتقل کرنے میں مدد کرنے پر توجہ مرکوز کرتا ہے۔ وہ مشین لرننگ، AI، اور کمپیوٹر ویژن ڈومینز میں مہارت رکھتا ہے، اور UT Dallas سے کمپیوٹر سائنس میں ماسٹر ڈگری رکھتا ہے۔ اپنے فارغ وقت میں وہ سفر اور فوٹو گرافی سے لطف اندوز ہوتے ہیں۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

