Amazon Rekognition дозволяє легко додавати аналіз зображень і відео до ваших програм. Він заснований на тій самій перевіреній, високомасштабованій, глибокій технології навчання, розробленій вченими з комп’ютерного бачення Amazon для щоденного аналізу мільярдів зображень і відео. Для його використання не потрібні знання машинного навчання (ML), і ми постійно додаємо нові функції комп’ютерного зору до служби. Amazon Rekognition містить простий, легкий у використанні API, який може швидко аналізувати будь-яке зображення або відеофайл, що зберігається в Служба простого зберігання Amazon (Amazon S3).
Клієнти в таких галузях, як реклама та маркетингові технології, ігри, засоби масової інформації, роздрібна торгівля та електронна комерція, покладаються на зображення, завантажені їхніми кінцевими користувачами (контент, створений користувачами, або UGC), як на важливий компонент для стимулювання взаємодії на їхній платформі. Вони використовують Модерація вмісту Amazon Rekognition для виявлення невідповідного, небажаного та образливого вмісту, щоб захистити репутацію свого бренду та створити безпечні спільноти користувачів.
У цій публікації ми обговоримо наступне:
- Модель Content Moderation версія 7.0 і можливості
- Як працює Amazon Rekognition Bulk Analysis для модерації вмісту
- Як покращити передбачення модерації вмісту за допомогою групового аналізу та спеціальної модерації
Модель модерування вмісту версії 7.0 і можливості
Amazon Rekognition Content Moderation версії 7.0 додає 26 нових міток модерації та розширює таксономію міток модерації з дворівневої до трирівневої категорії міток. Ці нові мітки та розширена таксономія дозволяють клієнтам виявляти детальні поняття у вмісті, який вони хочуть модерувати. Крім того, оновлена модель представляє нову можливість ідентифікації двох нових типів вмісту, анімованого та ілюстрованого. Це дозволяє клієнтам створювати детальні правила для включення або виключення таких типів вмісту з робочого процесу модерації. Завдяки цим новим оновленням клієнти можуть модерувати вміст відповідно до своєї політики щодо вмісту з більшою точністю.
Давайте розглянемо приклад визначення мітки модерації для наступного зображення.

У наведеній нижче таблиці показано мітки модерації, тип вмісту та оцінки надійності, які повертаються у відповіді API.
| Мітки модерації | Рівень таксономії | Оцінки впевненості |
| Насильство | L1 | 92.6% |
| Графічне насильство | L2 | 92.6% |
| Вибухи та вибухи | L3 | 92.6% |
| Типи вмісту | Оцінки впевненості |
| Ілюстрований | 93.9% |
Щоб отримати повну таксономію для модерації вмісту версії 7.0, відвідайте наш керівництво для розробників.
Масовий аналіз для модерації вмісту
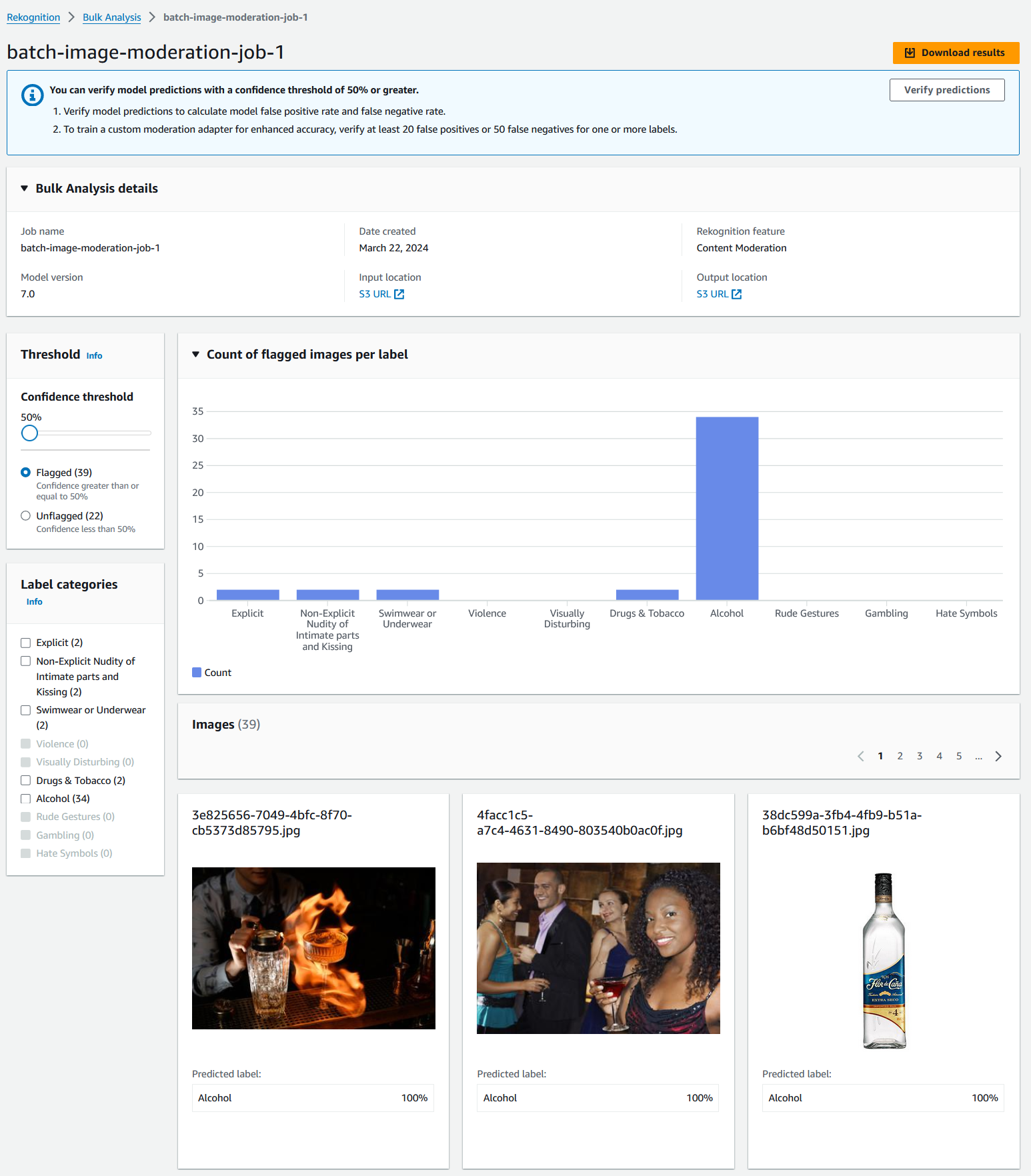
Amazon Rekognition Content Moderation також забезпечує групову модерацію зображень на додачу до модерації в реальному часі Масовий аналіз Amazon Rekognition. Це дає змогу асинхронно аналізувати великі колекції зображень, щоб виявляти неприйнятний вміст і отримати уявлення про категорії модерації, призначені зображенням. Це також усуває необхідність створювати пакетне рішення для модерації зображень для клієнтів.
Ви можете отримати доступ до функції масового аналізу через консоль Amazon Rekognition або викликаючи API безпосередньо за допомогою AWS CLI та AWS SDK. На консолі Amazon Rekognition ви можете завантажити зображення, які хочете проаналізувати, і отримати результати кількома клацаннями миші. Після завершення масового аналізу ви зможете визначити та переглянути передбачення міток модерації, як-от відверті, неявні зображення оголених інтимних частин тіла та поцілунки, насильство, наркотики та тютюн тощо. Ви також отримуєте оцінку надійності для кожної категорії міток.
Створіть завдання масового аналізу на консолі Amazon Rekognition
Виконайте наведені нижче дії, щоб спробувати масовий аналіз Amazon Rekognition:
- На консолі Amazon Rekognition виберіть Масовий аналіз у навігаційній панелі.
- Вибирати Розпочати груповий аналіз.
- Введіть назву завдання та вкажіть зображення, які потрібно проаналізувати, або ввівши розташування сегмента S3, або завантаживши зображення з комп’ютера.
- За бажанням ви можете вибрати адаптер для аналізу зображень за допомогою спеціального адаптера, який ви навчили за допомогою Custom Moderation.
- Вибирати Розпочати аналіз щоб запустити роботу.

Після завершення процесу ви зможете побачити результати на консолі Amazon Rekognition. Крім того, JSON-копія результатів аналізу буде збережена в вихідному місці Amazon S3.
Запит Amazon Rekognition Bulk Analysis API
У цьому розділі ми допоможемо вам створити завдання масового аналізу для модерації зображень за допомогою інтерфейсів програмування. Якщо ваші файли зображень ще не знаходяться в сегменті S3, завантажте їх, щоб забезпечити доступ через Amazon Rekognition. Подібно до створення завдання масового аналізу на консолі Amazon Rekognition під час виклику Запустіть MediaAnalysisJob API, потрібно надати такі параметри:
- OperationsConfig – Ось параметри конфігурації для завдання аналізу медіа, яке буде створено:
- MinConfidence – Мінімальний рівень достовірності з допустимим діапазоном 0–100 для повернення міток модерації. Amazon Rekognition не повертає жодних міток із рівнем достовірності, нижчим за вказане значення.
- вхід – Це включає наступне:
- S3Object – Інформація про об’єкт S3 для вхідного файлу маніфесту, включаючи сегмент і назву файлу. вхідний файл містить рядки JSON для кожного зображення, що зберігається у сегменті S3. наприклад:
{"source-ref": "s3://MY-INPUT-BUCKET/1.jpg"}
- S3Object – Інформація про об’єкт S3 для вхідного файлу маніфесту, включаючи сегмент і назву файлу. вхідний файл містить рядки JSON для кожного зображення, що зберігається у сегменті S3. наприклад:
- OutputConfig – Це включає наступне:
- S3Bucket – Назва сегмента S3 для вихідних файлів.
- S3KeyPrefix – Префікс ключа для вихідних файлів.
Дивіться наступний код:
Ви можете викликати той самий аналіз медіафайлів за допомогою такої команди AWS CLI:
Результати Amazon Rekognition Bulk Analysis API
Щоб отримати список завдань масового аналізу, ви можете використовувати ListMediaAnalysisJobs. Відповідь містить усі подробиці про вхідні та вихідні файли завдання аналізу та статус завдання:
Ви також можете викликати list-media-analysis-jobs через AWS CLI:
Amazon Rekognition Bulk Analysis генерує два вихідних файли у вихідному сегменті. Перший файл manifest-summary.json, який містить статистику завдань масового аналізу та список помилок:
Другий файл results.json, який містить один рядок JSON на кожне проаналізоване зображення в такому форматі. Кожен результат включає категорія вищого рівня (L1) виявленої мітки та категорія другого рівня мітки (L2), з оцінкою достовірності між 1–100. Деякі мітки таксономічного рівня 2 можуть мати мітки таксономічного рівня 3 (L3). Це дозволяє ієрархічно класифікувати вміст.

Ви можете використовувати Спеціальні адаптери модерації пізніше, щоб проаналізувати ваші зображення, просто вибравши настроюваний адаптер під час створення нового завдання масового аналізу або через API, передавши унікальний ідентифікатор адаптера настроюваного адаптера.
Підсумки
У цій публікації ми надали огляд модерації вмісту версії 7.0, груповий аналіз для модерації вмісту та те, як покращити прогнози модерації вмісту за допомогою масового аналізу та спеціальної модерації. Щоб спробувати нові мітки модерації та масовий аналіз, увійдіть у свій обліковий запис AWS і перегляньте консоль Amazon Rekognition для Модерація зображення та Масовий аналіз.
Про авторів
 Мехді Хагі є старшим архітектором рішень у команді AWS WWCS, який спеціалізується на штучному інтелекті та машинному обігу на AWS. Він працює з корпоративними клієнтами, допомагаючи їм мігрувати, модернізувати та оптимізувати робочі навантаження для хмари AWS. У вільний час він любить готувати перську їжу та займатися електронікою.
Мехді Хагі є старшим архітектором рішень у команді AWS WWCS, який спеціалізується на штучному інтелекті та машинному обігу на AWS. Він працює з корпоративними клієнтами, допомагаючи їм мігрувати, модернізувати та оптимізувати робочі навантаження для хмари AWS. У вільний час він любить готувати перську їжу та займатися електронікою.
 Шипра Канорія є головним менеджером із продуктів в AWS. Вона захоплено допомагає клієнтам вирішувати їхні найскладніші проблеми за допомогою можливостей машинного навчання та штучного інтелекту. Перш ніж приєднатися до AWS, Шипра пропрацювала понад 4 роки в Amazon Alexa, де вона запустила багато функцій, пов’язаних з продуктивністю, у голосовому помічнику Alexa.
Шипра Канорія є головним менеджером із продуктів в AWS. Вона захоплено допомагає клієнтам вирішувати їхні найскладніші проблеми за допомогою можливостей машинного навчання та штучного інтелекту. Перш ніж приєднатися до AWS, Шипра пропрацювала понад 4 роки в Amazon Alexa, де вона запустила багато функцій, пов’язаних з продуктивністю, у голосовому помічнику Alexa.
 Марія Хандоко є старшим менеджером із продуктів в AWS. Вона зосереджена на тому, щоб допомогти клієнтам вирішити їхні бізнес-завдання за допомогою машинного навчання та комп’ютерного зору. У вільний час вона любить піші прогулянки, слухає подкасти та вивчає різні кухні.
Марія Хандоко є старшим менеджером із продуктів в AWS. Вона зосереджена на тому, щоб допомогти клієнтам вирішити їхні бізнес-завдання за допомогою машинного навчання та комп’ютерного зору. У вільний час вона любить піші прогулянки, слухає подкасти та вивчає різні кухні.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/improving-content-moderation-with-amazon-rekognition-bulk-analysis-and-custom-moderation/

