Останні розробки в машинному навчанні (ML) призвели до все більших моделей, деякі з яких потребують сотень мільярдів параметрів. Незважаючи на те, що вони потужніші, навчання та висновки на цих моделях потребують значних обчислювальних ресурсів. Незважаючи на доступність розширених розподілених навчальних бібліотек, зазвичай для завдань навчання та логічного висновку потрібні сотні прискорювачів (графічні процесори або спеціальні чіпи ML, як-от AWS Trainium та AWS Inferentia), а отже, десятки чи сотні випадків.
У таких розподілених середовищах спостережуваність як екземплярів, так і мікросхем машинного навчання стає ключовою для точного налаштування продуктивності моделі та оптимізації витрат. Метрики дозволяють командам зрозуміти поведінку робочого навантаження та оптимізувати розподіл і використання ресурсів, діагностувати аномалії та підвищити загальну ефективність інфраструктури. Для дослідників даних використання та насичення чіпів ML також актуальні для планування потужності.
Ця публікація проведе вас через Шаблон спостережуваності з відкритим кодом для AWS Inferentia, який показує вам, як контролювати продуктивність мікросхем ML, що використовуються в Послуга Amazon Elastic Kubernetes (Amazon EKS) кластер з вузлами площини даних на основі Обчислювальна хмара Amazon Elastic (Amazon EC2) екземпляри типу Інф1 та Інф2.
Візерунок є частиною AWS CDK Observability Accelerator, набір впевнених модулів, які допоможуть вам налаштувати спостережуваність для кластерів Amazon EKS. AWS CDK Observability Accelerator організовано навколо шаблонів, які є повторно використовуваними одиницями для розгортання кількох ресурсів. Набір інструментів спостережуваності з відкритим кодом шаблонів Grafana під керуванням Amazon приладові дошки, ан Дистрибутив AWS для OpenTelemetry збирач для збору метрик і Керована служба Amazon для Prometheus зберігати їх.
Огляд рішення
Наступна діаграма ілюструє архітектуру рішення.

Це рішення розгортає кластер Amazon EKS із групою вузлів, яка включає екземпляри Inf1.
Тип AMI групи вузлів: AL2_x86_64_GPU, який використовує Amazon EKS оптимізував прискорений Amazon Linux AMI. На додаток до стандартної конфігурації AMI, оптимізованої для Amazon EKS, прискорений AMI включає Середа виконання NeuronX.
Щоб отримати доступ до чіпів ML із Kubernetes, шаблон розгортає AWS нейрон плагін пристрою.
Метрики надаються Amazon Managed Service for Prometheus neuron-monitor DaemonSet, який розгортає мінімальний контейнер із Нейронні інструменти встановлено. Зокрема, neuron-monitor DaemonSet запускає neuron-monitor команда передана в neuron-monitor-prometheus.py супровідний сценарій (обидві команди є частиною контейнера):
Команда використовує такі компоненти:
neuron-monitorзбирає показники та статистику з додатків Neuron, запущених у системі, і передає зібрані дані на stdout у Формат JSONneuron-monitor-prometheus.pyкартографує та виставляє телеметричні дані з формату JSON у формат, сумісний з Prometheus
Дані візуалізуються в Amazon Managed Grafana за допомогою відповідної інформаційної панелі.
Решта налаштувань для збору та візуалізації метрик за допомогою Amazon Managed Service for Prometheus і Amazon Managed Grafana подібні до тих, що використовуються в інших шаблонах на основі відкритого коду, які включені в AWS Observability Accelerator for CDK Репозиторій GitHub.
Передумови
Щоб виконати кроки, описані в цій публікації, потрібно:
Налаштуйте середовище
Щоб налаштувати середовище, виконайте наведені нижче дії.
- Відкрийте вікно терміналу та виконайте такі команди:
- Отримайте ідентифікатори будь-якої існуючої робочої області Grafana, керованої Amazon:
Нижче наведено наш зразок вихідних даних:
- Призначте значення
idтаendpointдо таких змінних середовища:
COA_AMG_ENDPOINT_URL потрібно включити https://.
- Створіть ключ API Grafana з робочої області Grafana, керованої Amazon:
- Створіть секрет у Менеджер систем AWS:
Доступ до секрету матиме надбудова External Secrets, і він стане доступним як рідний секрет Kubernetes у кластері EKS.
Завантажте середовище AWS CDK
Першим кроком до будь-якого розгортання AWS CDK є завантаження середовища. Ви використовуєте cdk bootstrap команду в CLI AWS CDK, щоб підготувати середовище (поєднання облікового запису AWS і регіону AWS) із ресурсами, потрібними AWS CDK для виконання розгортань у цьому середовищі. Завантаження AWS CDK потрібне для кожної комбінації облікового запису та регіону, тому, якщо ви вже завантажили AWS CDK у регіоні, вам не потрібно повторювати процес завантаження.
Розгорніть рішення
Щоб розгорнути рішення, виконайте наведені нижче дії.
- Клонуйте cdk-aws-observability-accelerator репозиторій і встановіть пакети залежностей. Це сховище містить код AWS CDK v2, написаний на TypeScript.
Очікується, що фактичні параметри для файлів JSON панелі інструментів Grafana будуть указані в контексті AWS CDK. Вам потрібно оновити context в cdk.json файл, розташований у поточному каталозі. Розташування приладової панелі вказується fluxRepository.values.GRAFANA_NEURON_DASH_URL параметр і neuronNodeGroup використовується для встановлення типу екземпляра, номера та Магазин еластичних блоків Amazon (Amazon EBS), який використовується для вузлів.
- Введіть наступний фрагмент коду
cdk.json, замінившиcontext:
Ви можете замінити тип екземпляра Inf1 на Inf2 і за потреби змінити розмір. Щоб перевірити наявність у вибраному регіоні, виконайте таку команду (змінити Values як вважаєте за потрібне):
- Встановіть залежності проекту:
- Виконайте такі команди, щоб розгорнути шаблон спостереження з відкритим кодом:
Перевірте рішення
Виконайте наступні кроки, щоб перевірити рішення:
- Запустіть
update-kubeconfigкоманда. Ви повинні мати змогу отримати команду з вихідного повідомлення попередньої команди:
- Перевірте створені вами ресурси:
На наступному знімку екрана показано наш зразок результату.

- Переконайтеся в тому,
neuron-device-plugin-daemonsetDaemonSet працює:
Наш очікуваний результат:
- Підтвердьте, що
neuron-monitorDaemonSet працює:
Наш очікуваний результат:
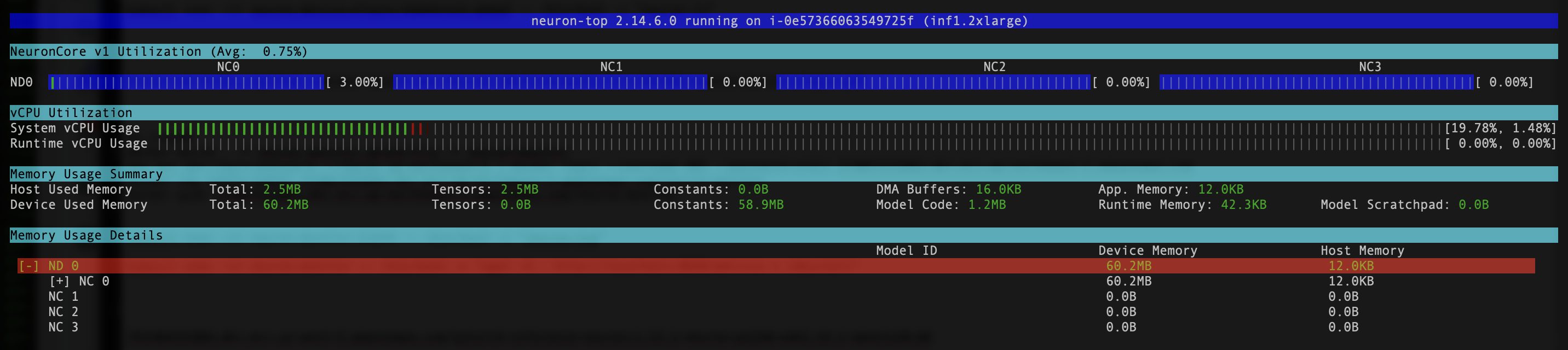
- Щоб переконатися, що пристрої та ядра Neuron видимі, запустіть
neuron-lsтаneuron-topкоманди, наприклад, з модуля монітора нейронів (ви можете отримати ім’я модуля з виводуkubectl get pods -A):
На наступному знімку екрана показано очікуваний результат.

На наступному знімку екрана показано очікуваний результат.
Візуалізуйте дані за допомогою інформаційної панелі Grafana Neuron
Увійдіть у свій робочий простір Grafana, керований Amazon, і перейдіть до Панелі панель. Ви повинні побачити інформаційну панель з назвою Нейрон / Монітор.
Щоб побачити деякі цікаві показники на інформаційній панелі Grafana, ми застосовуємо такий маніфест:
Це зразок робочого навантаження, який компілює модель torchvision ResNet50 і запускає повторювані висновки в циклі для генерації телеметричних даних.
Щоб переконатися, що модуль успішно розгорнуто, запустіть такий код:
Ви повинні побачити пакет з назвою pytorch-inference-resnet50.
Через кілька хвилин, заглянувши в Нейрон / Монітор інформаційної панелі, ви повинні побачити зібрані показники, подібні до наведених нижче знімків екрана.




Grafana Operator і Flux завжди працюють разом, щоб синхронізувати ваші інформаційні панелі з Git. Якщо ви випадково видалите свої інформаційні панелі, їх буде повторно налаштовано автоматично.
Прибирати
Ви можете видалити весь стек AWS CDK за допомогою такої команди:
Висновок
У цій публікації ми показали вам, як запровадити спостережливість за допомогою інструментів з відкритим вихідним кодом у кластер EKS, що містить площину даних, на якій працюють екземпляри EC2 Inf1. Ми почали з вибору оптимізованого для Amazon EKS прискореного AMI для вузлів площини даних, який включає середовище виконання контейнера Neuron, що забезпечує доступ до пристроїв AWS Inferentia та Trainium Neuron. Потім, щоб представити ядра та пристрої Neuron Kubernetes, ми розгорнули плагін пристрою Neuron. Фактичний збір і відображення телеметричних даних у форматі, сумісному з Prometheus, було досягнуто за допомогою neuron-monitor та neuron-monitor-prometheus.py. Метрики були отримані з Amazon Managed Service для Prometheus і відображалися на інформаційній панелі Neuron у Amazon Managed Grafana.
Ми рекомендуємо вам вивчити додаткові моделі спостережуваності в AWS Observability Accelerator для CDK Репо GitHub. Щоб дізнатися більше про Neuron, зверніться до Документація AWS Neuron.
Про автора
 Ріккардо Фрешкі є старшим архітектором рішень в AWS, який займається модернізацією додатків. Він тісно співпрацює з партнерами та клієнтами, щоб допомогти їм трансформувати свої ІТ-ландшафти на шляху до хмари AWS шляхом рефакторингу існуючих програм і створення нових.
Ріккардо Фрешкі є старшим архітектором рішень в AWS, який займається модернізацією додатків. Він тісно співпрацює з партнерами та клієнтами, щоб допомогти їм трансформувати свої ІТ-ландшафти на шляху до хмари AWS шляхом рефакторингу існуючих програм і створення нових.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

