ออโต้เอ็มแอล ช่วยให้คุณได้รับข้อมูลเชิงลึกทั่วไปอย่างรวดเร็วจากข้อมูลของคุณตั้งแต่เริ่มต้นวงจรชีวิตของโปรเจ็กต์แมชชีนเลิร์นนิง (ML) การทำความเข้าใจล่วงหน้าว่าเทคนิคการประมวลผลล่วงหน้าและประเภทอัลกอริทึมใดที่ให้ผลลัพธ์ที่ดีที่สุดจะช่วยลดเวลาในการพัฒนา ฝึกฝน และปรับใช้โมเดลที่เหมาะสม โดยมีบทบาทสำคัญในกระบวนการพัฒนาโมเดลทุกรุ่น และช่วยให้นักวิทยาศาสตร์ข้อมูลมุ่งเน้นไปที่เทคนิค ML ที่มีแนวโน้มดีที่สุดได้ นอกจากนี้ AutoML ยังมอบประสิทธิภาพของโมเดลพื้นฐานที่สามารถใช้เป็นจุดอ้างอิงสำหรับทีมวิทยาศาสตร์ข้อมูลได้
เครื่องมือ AutoML ใช้การผสมผสานระหว่างอัลกอริธึมและเทคนิคการประมวลผลล่วงหน้าต่างๆ กับข้อมูลของคุณ ตัวอย่างเช่น สามารถปรับขนาดข้อมูล ดำเนินการเลือกคุณสมบัติที่ไม่แปรเปลี่ยน ดำเนินการ PCA ที่ระดับขีดจำกัดความแปรปรวนที่แตกต่างกัน และใช้การจัดกลุ่ม เทคนิคการประมวลผลล่วงหน้าดังกล่าวสามารถนำไปใช้เป็นรายบุคคลหรือรวมกันในไปป์ไลน์ได้ ต่อจากนั้น เครื่องมือ AutoML จะฝึกโมเดลประเภทต่างๆ เช่น Linear Regression, Elastic-Net หรือ Random Forest บนเวอร์ชันต่างๆ ของชุดข้อมูลที่ประมวลผลล่วงหน้าของคุณ และดำเนินการเพิ่มประสิทธิภาพไฮเปอร์พารามิเตอร์ (HPO) ระบบนำร่องอัตโนมัติของ Amazon SageMaker ช่วยลดภาระหนักของการสร้างโมเดล ML หลังจากจัดเตรียมชุดข้อมูลแล้ว SageMaker Autopilot จะสำรวจโซลูชันต่างๆ โดยอัตโนมัติเพื่อค้นหาโมเดลที่ดีที่สุด แต่ถ้าคุณต้องการปรับใช้เวิร์กโฟลว์ AutoML เวอร์ชันที่ปรับแต่งโดยเฉพาะล่ะ
โพสต์นี้จะแสดงวิธีสร้างเวิร์กโฟลว์ AutoML แบบกำหนดเอง อเมซอน SageMaker การใช้ การปรับโมเดลอัตโนมัติของ Amazon SageMaker พร้อมโค้ดตัวอย่างที่มีอยู่ใน ที่เก็บ GitHub
ภาพรวมโซลูชัน
สำหรับกรณีการใช้งานนี้ สมมติว่าคุณเป็นส่วนหนึ่งของทีมวิทยาศาสตร์ข้อมูลที่พัฒนาแบบจำลองในโดเมนเฉพาะ คุณได้พัฒนาชุดเทคนิคการประมวลผลล่วงหน้าแบบกำหนดเอง และเลือกอัลกอริทึมจำนวนหนึ่งที่คุณมักคาดหวังว่าจะทำงานได้ดีกับปัญหา ML ของคุณ เมื่อทำงานกับกรณีการใช้งาน ML ใหม่ คุณต้องดำเนินการเรียกใช้ AutoML ก่อนโดยใช้เทคนิคและอัลกอริธึมการประมวลผลล่วงหน้าเพื่อจำกัดขอบเขตของโซลูชันที่เป็นไปได้ให้แคบลง
สำหรับตัวอย่างนี้ คุณไม่ได้ใช้ชุดข้อมูลพิเศษ แต่คุณทำงานกับชุดข้อมูล California Housing ที่คุณจะนำเข้าแทน บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน S3). จุดมุ่งเน้นคือการสาธิตการใช้งานทางเทคนิคของโซลูชันโดยใช้ SageMaker HPO ซึ่งสามารถนำไปใช้กับชุดข้อมูลและโดเมนใดๆ ในภายหลัง
ไดอะแกรมต่อไปนี้นำเสนอเวิร์กโฟลว์โซลูชันโดยรวม

เบื้องต้น
ต่อไปนี้เป็นข้อกำหนดเบื้องต้นสำหรับการฝึกปฏิบัติให้เสร็จสิ้นในโพสต์นี้:
ดำเนินการแก้ปัญหา
รหัสเต็มมีอยู่ใน repo GitHub.
ขั้นตอนในการใช้โซลูชัน (ตามที่ระบุไว้ในแผนภาพเวิร์กโฟลว์) มีดังนี้:
- สร้างอินสแตนซ์สมุดบันทึก และระบุสิ่งต่อไปนี้:
- สำหรับ ประเภทอินสแตนซ์ของโน้ตบุ๊กเลือก มล.t3.ปานกลาง.
- สำหรับ การอนุมานแบบยืดหยุ่นเลือก ไม่มี.
- สำหรับ ตัวระบุแพลตฟอร์มเลือก อเมซอน ลินุกซ์ 2, จูปิเตอร์ แล็บ 3.
- สำหรับ บทบาท IAMให้เลือกค่าเริ่มต้น
AmazonSageMaker-ExecutionRole. หากไม่มีอยู่ ให้สร้างใหม่ AWS Identity และการจัดการการเข้าถึง (IAM) และแนบไฟล์ นโยบาย AmazonSageMakerFullAccess IAM.
โปรดทราบว่าคุณควรสร้างบทบาทและนโยบายการดำเนินการที่มีขอบเขตน้อยที่สุดในการผลิต
- เปิดอินเทอร์เฟซ JupyterLab สำหรับอินสแตนซ์โน้ตบุ๊กของคุณและโคลน repo GitHub
คุณสามารถทำได้โดยเริ่มเซสชันเทอร์มินัลใหม่และเรียกใช้ git clone <REPO> คำสั่งหรือโดยใช้ฟังก์ชัน UI ดังที่แสดงในภาพหน้าจอต่อไปนี้

- เปิด
automl.ipynbไฟล์สมุดบันทึก ให้เลือกไฟล์conda_python3เคอร์เนล และปฏิบัติตามคำแนะนำเพื่อทริกเกอร์ ชุดงาน HPO.
หากต้องการเรียกใช้โค้ดโดยไม่มีการเปลี่ยนแปลงใดๆ คุณจะต้องเพิ่มโควต้าบริการ ml.m5.large สำหรับฝึกการใช้งาน และ จำนวนอินสแตนซ์ในงานฝึกอบรมทั้งหมด. AWS อนุญาตตามค่าเริ่มต้นงานการฝึกอบรม SageMaker แบบขนานเพียง 20 งานสำหรับโควต้าทั้งสอง คุณต้องขอเพิ่มโควต้าเป็น 30 สำหรับทั้งคู่ โดยทั่วไปการเปลี่ยนแปลงโควต้าทั้งสองควรได้รับการอนุมัติภายในไม่กี่นาที อ้างถึง ขอเพิ่มโควต้า สำหรับข้อมูลเพิ่มเติม

หากคุณไม่ต้องการเปลี่ยนโควต้า คุณสามารถแก้ไขค่าของ MAX_PARALLEL_JOBS ตัวแปรในสคริปต์ (เช่น ถึง 5)
- งาน HPO แต่ละงานจะเสร็จสิ้นชุดของ ฝึกงาน ทดลองและระบุโมเดลด้วยไฮเปอร์พารามิเตอร์ที่เหมาะสมที่สุด
- วิเคราะห์ผลลัพธ์และ ปรับใช้โมเดลที่มีประสิทธิภาพดีที่สุด.
โซลูชันนี้จะมีค่าใช้จ่ายในบัญชี AWS ของคุณ ต้นทุนของโซลูชันนี้จะขึ้นอยู่กับจำนวนและระยะเวลาของงานการฝึกอบรม HPO เมื่อสิ่งเหล่านี้เพิ่มขึ้น ต้นทุนก็จะเพิ่มมากขึ้นเช่นกัน คุณสามารถลดต้นทุนได้โดยการจำกัดเวลาการฝึกอบรมและการกำหนดค่า TuningJobCompletionCriteriaConfig ตามคำแนะนำที่จะกล่าวถึงในภายหลังในโพสต์นี้ สำหรับข้อมูลราคา โปรดดูที่ ราคา Amazon SageMaker.
ในส่วนต่อไปนี้ เราจะหารือเกี่ยวกับสมุดบันทึกโดยละเอียดยิ่งขึ้นพร้อมตัวอย่างโค้ดและขั้นตอนในการวิเคราะห์ผลลัพธ์และเลือกรุ่นที่ดีที่สุด
ตั้งค่าเริ่มต้น
มาเริ่มกันที่การรัน การนำเข้าและการตั้งค่า ส่วนใน custom-automl.ipynb สมุดบันทึก. โดยจะติดตั้งและนำเข้าการขึ้นต่อกันที่จำเป็นทั้งหมด สร้างอินสแตนซ์เซสชันและไคลเอนต์ SageMaker และตั้งค่าภูมิภาคเริ่มต้นและบัคเก็ต S3 สำหรับการจัดเก็บข้อมูล
การเตรียมข้อมูล
ดาวน์โหลดชุดข้อมูล California Housing และจัดเตรียมโดยเรียกใช้ ดาวน์โหลดข้อมูล ส่วนของสมุดบันทึก ชุดข้อมูลจะแบ่งออกเป็นเฟรมข้อมูลการฝึกอบรมและการทดสอบ และอัปโหลดไปยังบัคเก็ต S3 เริ่มต้นของเซสชัน SageMaker
ชุดข้อมูลทั้งหมดมี 20,640 บันทึก และทั้งหมด 9 คอลัมน์ รวมเป้าหมายด้วย เป้าหมายคือการทำนายค่ามัธยฐานของบ้าน (medianHouseValue คอลัมน์). ภาพหน้าจอต่อไปนี้แสดงแถวบนสุดของชุดข้อมูล

เทมเพลตสคริปต์การฝึกอบรม
เวิร์กโฟลว์ AutoML ในโพสต์นี้อิงตาม scikit เรียนรู้ การประมวลผลไปป์ไลน์และอัลกอริธึมล่วงหน้า จุดมุ่งหมายคือการสร้างการผสมผสานระหว่างไปป์ไลน์และอัลกอริธึมการประมวลผลล่วงหน้าที่แตกต่างกันจำนวนมาก เพื่อค้นหาการตั้งค่าที่มีประสิทธิภาพดีที่สุด เริ่มต้นด้วยการสร้างสคริปต์การฝึกอบรมทั่วไป ซึ่งจะคงอยู่ในอินสแตนซ์โน้ตบุ๊ก ในสคริปต์นี้ มีบล็อกความคิดเห็นว่างสองบล็อก: บล็อกหนึ่งสำหรับการฉีดไฮเปอร์พารามิเตอร์ และอีกบล็อกสำหรับอ็อบเจ็กต์ไปป์ไลน์โมเดลการประมวลผลล่วงหน้า พวกเขาจะถูกฉีดแบบไดนามิกสำหรับตัวเลือกโมเดลก่อนการประมวลผลแต่ละตัว วัตถุประสงค์ของการมีสคริปต์ทั่วไปหนึ่งสคริปต์คือเพื่อให้การใช้งานเป็นแบบแห้ง (อย่าทำซ้ำตัวเอง)
สร้างการผสมผสานระหว่างการประมวลผลล่วงหน้าและโมเดล
พื้นที่ preprocessors พจนานุกรมประกอบด้วยข้อกำหนดของเทคนิคการประมวลผลล่วงหน้าที่ใช้กับคุณสมบัติอินพุตทั้งหมดของโมเดล แต่ละสูตรถูกกำหนดโดยใช้ Pipeline หรือ FeatureUnion object จาก scikit-learn ซึ่งเชื่อมโยงการแปลงข้อมูลแต่ละรายการเข้าด้วยกันและซ้อนกัน ตัวอย่างเช่น, mean-imp-scale เป็นสูตรง่ายๆ ที่ช่วยให้แน่ใจว่าค่าที่หายไปจะถูกใส่โดยใช้ค่าเฉลี่ยของคอลัมน์ที่เกี่ยวข้อง และคุณลักษณะทั้งหมดจะถูกปรับขนาดโดยใช้ เครื่องชั่งน้ำหนักมาตราฐาน. ในทางตรงกันข้ามไฟล์ mean-imp-scale-pca เชื่อมโยงสูตรอาหารเข้าด้วยกันอีกสองสามอย่าง:
- แทนค่าที่หายไปในคอลัมน์ด้วยค่าเฉลี่ย
- ใช้การปรับขนาดคุณลักษณะโดยใช้ค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน
- คำนวณ PCA ที่ด้านบนของข้อมูลอินพุตที่ค่าเกณฑ์ความแปรปรวนที่ระบุ และผสานเข้ากับคุณสมบัติอินพุตที่ใส่เข้าไปและปรับขนาด
ในโพสต์นี้ คุณลักษณะอินพุตทั้งหมดเป็นตัวเลข หากคุณมีประเภทข้อมูลมากกว่าในชุดข้อมูลอินพุต คุณควรระบุไปป์ไลน์ที่ซับซ้อนมากขึ้น โดยที่สาขาการประมวลผลล่วงหน้าที่แตกต่างกันจะถูกนำไปใช้กับชุดประเภทคุณสมบัติที่แตกต่างกัน
พื้นที่ models พจนานุกรมมีข้อกำหนดของอัลกอริธึมต่างๆ ที่เหมาะกับชุดข้อมูล ทุกรุ่นจะมีข้อกำหนดเฉพาะต่อไปนี้ในพจนานุกรม:
- script_output – ชี้ไปยังตำแหน่งของสคริปต์การฝึกอบรมที่ผู้ประมาณใช้ ฟิลด์นี้จะถูกเติมแบบไดนามิกเมื่อ
modelsพจนานุกรมจะรวมกับpreprocessorsพจนานุกรม. - แทรก – กำหนดรหัสที่จะแทรกลงใน
script_draft.pyและบันทึกไว้ในลำดับต่อมาscript_output. ที่สำคัญ“preprocessor”ถูกปล่อยว่างไว้โดยเจตนาเนื่องจากตำแหน่งนี้เต็มไปด้วยหนึ่งในตัวประมวลผลล่วงหน้าเพื่อสร้างชุดค่าผสมระหว่างโมเดลและตัวประมวลผลล่วงหน้าหลายตัว - ไฮเปอร์พารามิเตอร์ – ชุดของไฮเปอร์พารามิเตอร์ที่ได้รับการปรับให้เหมาะสมโดยงาน HPO
- รวม_cls_metadata – รายละเอียดการกำหนดค่าเพิ่มเติมที่ SageMaker ต้องการ
Tunerชั้นเรียน
ตัวอย่างแบบเต็มของ models พจนานุกรมมีอยู่ในที่เก็บ GitHub
ต่อไป เรามาวนซ้ำผ่าน preprocessors และ models พจนานุกรมและสร้างชุดค่าผสมที่เป็นไปได้ทั้งหมด ตัวอย่างเช่นหากคุณ preprocessors พจนานุกรมมี 10 สูตรและคุณมี 5 คำจำกัดความของแบบจำลองใน models พจนานุกรม พจนานุกรมไปป์ไลน์ที่สร้างขึ้นใหม่ประกอบด้วยไปป์ไลน์โมเดลพรีโปรเซสเซอร์ 50 รายการที่ได้รับการประเมินระหว่าง HPO โปรดทราบว่าขณะนี้ยังไม่ได้สร้างสคริปต์ไปป์ไลน์แต่ละรายการ บล็อกโค้ดถัดไป (เซลล์ 9) ของสมุดบันทึก Jupyter จะวนซ้ำผ่านออบเจ็กต์โมเดลตัวประมวลผลล่วงหน้าทั้งหมดใน pipelines พจนานุกรม แทรกส่วนโค้ดที่เกี่ยวข้องทั้งหมด และยังคงมีสคริปต์เวอร์ชันเฉพาะไปป์ไลน์อยู่ในเครื่องโน้ตบุ๊ก สคริปต์เหล่านั้นจะใช้ในขั้นตอนถัดไปเมื่อสร้างตัวประมาณค่าแต่ละตัวที่คุณเสียบเข้ากับงาน HPO
กำหนดตัวประมาณค่า
ตอนนี้คุณสามารถกำหนด SageMaker Estimators ที่งาน HPO ใช้หลังจากสคริปต์พร้อมแล้ว เริ่มต้นด้วยการสร้างคลาส wrapper ที่กำหนดคุณสมบัติทั่วไปบางอย่างสำหรับตัวประมาณค่าทั้งหมด มันสืบทอดมาจาก SKLearn และระบุบทบาท จำนวนอินสแตนซ์ และประเภท รวมถึงคอลัมน์ที่สคริปต์ใช้เป็นคุณลักษณะและเป้าหมาย
มาสร้างกันเถอะ estimators พจนานุกรมโดยการวนซ้ำสคริปต์ทั้งหมดที่สร้างขึ้นก่อนและอยู่ใน scripts ไดเรกทอรี คุณสร้างตัวอย่างตัวประมาณค่าใหม่โดยใช้ SKLearnBase คลาสที่มีชื่อตัวประมาณค่าเฉพาะ และหนึ่งในสคริปต์ โปรดทราบว่า estimators พจนานุกรมมีสองระดับ: ระดับบนสุดกำหนดก pipeline_family. นี่คือการจัดกลุ่มแบบลอจิคัลตามประเภทของแบบจำลองที่จะประเมินและเท่ากับความยาวของ models พจนานุกรม. ระดับที่สองประกอบด้วยประเภทตัวประมวลผลล่วงหน้าแต่ละประเภทรวมกับประเภทที่กำหนด pipeline_family. การจัดกลุ่มแบบลอจิคัลนี้จำเป็นเมื่อสร้างงาน HPO
กำหนดอาร์กิวเมนต์จูนเนอร์ HPO
เพื่อเพิ่มประสิทธิภาพการส่งผ่านข้อโต้แย้งไปยัง HPO Tuner คลาส, HyperparameterTunerArgs คลาสข้อมูลเริ่มต้นได้ด้วยอาร์กิวเมนต์ที่คลาส HPO ต้องการ มาพร้อมกับชุดฟังก์ชันที่ช่วยให้มั่นใจว่าอาร์กิวเมนต์ HPO จะถูกส่งกลับในรูปแบบที่คาดหวังเมื่อปรับใช้คำจำกัดความของโมเดลหลายรายการพร้อมกัน
บล็อกโค้ดถัดไปใช้โค้ดที่แนะนำก่อนหน้านี้ HyperparameterTunerArgs คลาสข้อมูล คุณสร้างพจนานุกรมอื่นที่เรียกว่า hp_args และสร้างชุดพารามิเตอร์อินพุตเฉพาะสำหรับแต่ละรายการ estimator_family จาก estimators พจนานุกรม. อาร์กิวเมนต์เหล่านี้จะใช้ในขั้นตอนถัดไปเมื่อเริ่มต้นงาน HPO สำหรับแต่ละตระกูลโมเดล
สร้างออบเจ็กต์จูนเนอร์ HPO
ในขั้นตอนนี้ คุณจะสร้างจูนเนอร์แต่ละตัวสำหรับแต่ละอัน estimator_family. เหตุใดคุณจึงสร้างงาน HPO สามงานแยกกัน แทนที่จะเปิดตัวเพียงงานเดียวจากเครื่องมือประมาณการทั้งหมด ที่ HyperparameterTuner คลาสถูกจำกัดไว้ที่ 10 คำจำกัดความของโมเดลที่แนบมาด้วย ดังนั้น HPO แต่ละตัวมีหน้าที่รับผิดชอบในการค้นหาพรีโปรเซสเซอร์ที่มีประสิทธิภาพดีที่สุดสำหรับตระกูลโมเดลที่กำหนด และปรับแต่งไฮเปอร์พารามิเตอร์ของตระกูลโมเดลนั้น
ต่อไปนี้เป็นประเด็นเพิ่มเติมบางประการเกี่ยวกับการตั้งค่า:
- กลยุทธ์การปรับให้เหมาะสมคือ Bayesian ซึ่งหมายความว่า HPO ติดตามประสิทธิภาพของการทดลองทั้งหมดอย่างแข็งขัน และนำทางการปรับให้เหมาะสมไปสู่ชุดค่าผสมไฮเปอร์พารามิเตอร์ที่มีแนวโน้มมากขึ้น ควรตั้งค่าการหยุดก่อนเวลาเป็น Off or รถยนต์ เมื่อทำงานกับกลยุทธ์แบบเบย์ซึ่งจัดการกับตรรกะนั้นเอง
- งาน HPO แต่ละงานจะรันได้สูงสุด 100 งานและรัน 10 งานแบบขนาน หากคุณกำลังจัดการกับชุดข้อมูลขนาดใหญ่ คุณอาจต้องการเพิ่มจำนวนงานทั้งหมด
- นอกจากนี้ คุณอาจต้องการใช้การตั้งค่าที่ควบคุมระยะเวลาที่งานจะรันและจำนวนงานที่ HPO ของคุณเรียกใช้ วิธีหนึ่งในการทำเช่นนั้นคือตั้งค่ารันไทม์สูงสุดเป็นวินาที (สำหรับโพสต์นี้ เราตั้งค่าไว้ที่ 1 ชั่วโมง) อีกประการหนึ่งคือการใช้ที่เพิ่งเปิดตัว
TuningJobCompletionCriteriaConfig. มีชุดการตั้งค่าที่ติดตามความคืบหน้าของงานของคุณและตัดสินใจว่ามีแนวโน้มว่างานจำนวนมากขึ้นจะปรับปรุงผลลัพธ์หรือไม่ ในโพสต์นี้ เราได้กำหนดจำนวนงานการฝึกอบรมสูงสุดที่ไม่ปรับปรุงเป็น 20 ด้วยวิธีนี้ หากคะแนนไม่ดีขึ้น (เช่น จากการทดลองครั้งที่สี่สิบ) คุณจะไม่ต้องจ่ายเงินสำหรับการทดลองที่เหลือจนกว่าmax_jobsถึง.
ตอนนี้ขอย้ำผ่าน tuners และ hp_args พจนานุกรมและทริกเกอร์งาน HPO ทั้งหมดใน SageMaker สังเกตการใช้อาร์กิวเมนต์ wait ที่ตั้งค่าเป็น Falseซึ่งหมายความว่าเคอร์เนลจะไม่รอจนกว่าผลลัพธ์จะเสร็จสมบูรณ์ และคุณสามารถทริกเกอร์งานทั้งหมดในครั้งเดียวได้
มีแนวโน้มว่างานฝึกอบรมบางงานจะไม่เสร็จสมบูรณ์ และงาน HPO บางงานอาจถูกหยุดไว้ เหตุผลก็คือ TuningJobCompletionCriteriaConfig—การปรับให้เหมาะสมจะเสร็จสิ้นหากตรงตามเกณฑ์ใดๆ ที่ระบุ ในกรณีนี้ เมื่อเกณฑ์การปรับให้เหมาะสมไม่ปรับปรุงสำหรับงาน 20 งานติดต่อกัน
วิเคราะห์ผล
เซลล์ 15 ของสมุดบันทึกจะตรวจสอบว่างาน HPO ทั้งหมดเสร็จสมบูรณ์หรือไม่ และรวมผลลัพธ์ทั้งหมดไว้ในรูปแบบของกรอบข้อมูลแพนด้าเพื่อการวิเคราะห์เพิ่มเติม ก่อนที่จะวิเคราะห์ผลลัพธ์โดยละเอียด เรามาดูคอนโซล SageMaker ในระดับสูงกันก่อน
ที่ด้านบนของ งานปรับแต่งไฮเปอร์พารามิเตอร์ คุณจะเห็นงาน HPO ที่เปิดตัวแล้วสามงานของคุณ พวกเขาทั้งหมดเสร็จสิ้นเร็วและไม่ได้ฝึกฝนทั้งหมด 100 งาน ในภาพหน้าจอต่อไปนี้ คุณจะเห็นว่ากลุ่มโมเดล Elastic-Net เสร็จสิ้นการทดลองจำนวนสูงสุดแล้ว ในขณะที่กลุ่มอื่นๆ ไม่ต้องการงานการฝึกอบรมมากมายเพื่อให้ได้ผลลัพธ์ที่ดีที่สุด

คุณสามารถเปิดงาน HPO เพื่อเข้าถึงรายละเอียดเพิ่มเติม เช่น งานการฝึกอบรมส่วนบุคคล การกำหนดค่างาน และข้อมูลและประสิทธิภาพของงานการฝึกอบรมที่ดีที่สุด

มาสร้างการแสดงภาพตามผลลัพธ์เพื่อรับข้อมูลเชิงลึกเพิ่มเติมเกี่ยวกับประสิทธิภาพเวิร์กโฟลว์ AutoML ในตระกูลโมเดลทั้งหมด
จากกราฟต่อไปนี้สรุปได้ว่า Elastic-Net ประสิทธิภาพของโมเดลแกว่งไปมาระหว่าง 70,000 ถึง 80,000 RMSE และหยุดลงในที่สุด เนื่องจากอัลกอริทึมไม่สามารถปรับปรุงประสิทธิภาพได้แม้จะลองใช้เทคนิคการประมวลผลล่วงหน้าและค่าไฮเปอร์พารามิเตอร์ต่างๆ ก็ตาม ดูเหมือนว่าเช่นกัน RandomForest ประสิทธิภาพแตกต่างกันมากขึ้นอยู่กับไฮเปอร์พารามิเตอร์ที่ HPO ตั้งค่าไว้ แต่แม้จะมีการทดลองหลายครั้ง แต่ก็ไม่สามารถต่ำกว่าข้อผิดพลาด 50,000 RMSE ได้ GradientBoosting บรรลุประสิทธิภาพที่ดีที่สุดตั้งแต่เริ่มต้นที่ต่ำกว่า 50,000 RMSE HPO พยายามปรับปรุงผลลัพธ์นั้นเพิ่มเติมแต่ไม่สามารถบรรลุประสิทธิภาพที่ดีขึ้นเมื่อเทียบกับชุดค่าผสมไฮเปอร์พารามิเตอร์อื่นๆ ข้อสรุปทั่วไปสำหรับงาน HPO ทั้งหมดคือไม่จำเป็นต้องมีงานมากนักเพื่อค้นหาชุดไฮเปอร์พารามิเตอร์ที่มีประสิทธิภาพดีที่สุดสำหรับแต่ละอัลกอริทึม เพื่อปรับปรุงผลลัพธ์ให้ดียิ่งขึ้น คุณจะต้องทดลองสร้างฟีเจอร์เพิ่มเติมและดำเนินการวิศวกรรมฟีเจอร์เพิ่มเติม

คุณยังสามารถตรวจสอบมุมมองที่ละเอียดมากขึ้นของการรวมกันของโมเดล-พรีโปรเซสเซอร์ เพื่อสรุปข้อสรุปเกี่ยวกับการผสมผสานที่มีแนวโน้มมากที่สุด

เลือกโมเดลที่ดีที่สุดและปรับใช้
ข้อมูลโค้ดต่อไปนี้จะเลือกโมเดลที่ดีที่สุดโดยพิจารณาจากมูลค่าวัตถุประสงค์ที่บรรลุผลต่ำสุด จากนั้นคุณสามารถปรับใช้โมเดลเป็นจุดสิ้นสุด SageMaker ได้
ทำความสะอาด
เพื่อป้องกันการเรียกเก็บเงินที่ไม่ต้องการไปยังบัญชี AWS ของคุณ เราขอแนะนำให้ลบทรัพยากร AWS ที่คุณใช้ในโพสต์นี้:
- บนคอนโซล Amazon S3 ให้ล้างข้อมูลจากบัคเก็ต S3 ที่เก็บข้อมูลการฝึกไว้

- บนคอนโซล SageMaker ให้หยุดอินสแตนซ์สมุดบันทึก
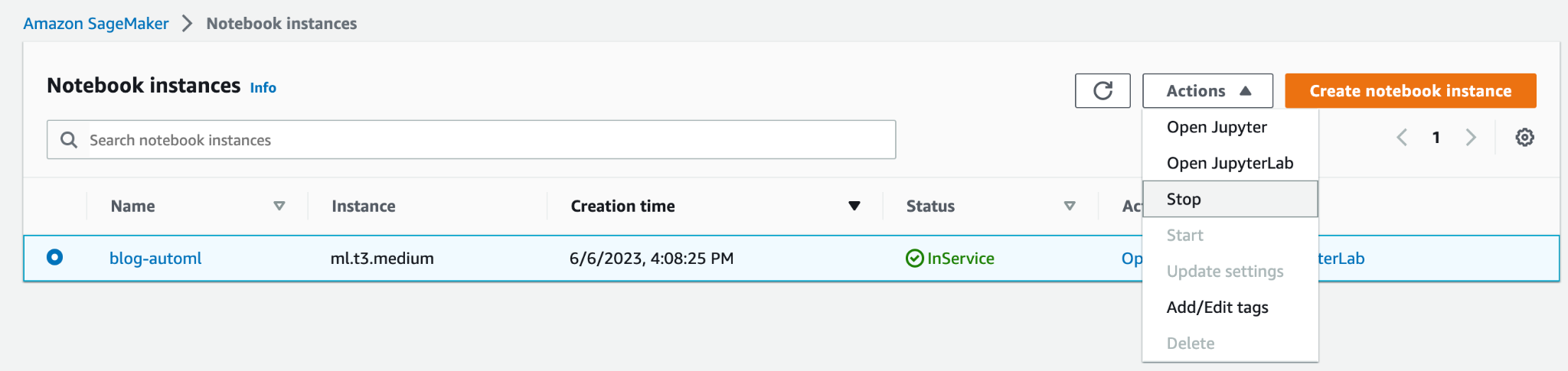
- ลบตำแหน่งข้อมูลโมเดลหากคุณปรับใช้ ควรลบตำแหน่งข้อมูลเมื่อไม่ได้ใช้งานอีกต่อไป เนื่องจากมีการเรียกเก็บเงินตามเวลาที่ใช้งาน
สรุป
ในโพสต์นี้ เราได้แสดงวิธีสร้างงาน HPO แบบกำหนดเองใน SageMaker โดยใช้การเลือกอัลกอริธึมและเทคนิคการประมวลผลล่วงหน้าแบบกำหนดเอง โดยเฉพาะอย่างยิ่ง ตัวอย่างนี้สาธิตวิธีทำให้กระบวนการสร้างสคริปต์การฝึกอบรมจำนวนมากเป็นแบบอัตโนมัติ และวิธีการใช้โครงสร้างการเขียนโปรแกรม Python เพื่อการปรับใช้งานการปรับให้เหมาะสมแบบขนานหลายงานอย่างมีประสิทธิภาพ เราหวังว่าโซลูชันนี้จะสร้างรากฐานให้กับงานการปรับแต่งโมเดลแบบกำหนดเองใดๆ ที่คุณจะปรับใช้โดยใช้ SageMaker เพื่อให้ได้รับประสิทธิภาพที่สูงขึ้นและเร่งความเร็วเวิร์กโฟลว์ ML ของคุณ
ตรวจสอบแหล่งข้อมูลต่อไปนี้เพื่อเพิ่มพูนความรู้ของคุณเกี่ยวกับวิธีใช้ SageMaker HPO ให้ลึกซึ้งยิ่งขึ้น:
เกี่ยวกับผู้เขียน
 คอนราด เซ็มช เป็นสถาปนิกอาวุโสด้านโซลูชัน ML ของทีม Amazon Web Services Data Lab เขาช่วยให้ลูกค้าใช้การเรียนรู้ของเครื่องเพื่อแก้ปัญหาความท้าทายทางธุรกิจด้วย AWS เขาสนุกกับการประดิษฐ์และลดความซับซ้อนเพื่อให้ลูกค้าได้รับโซลูชันที่เรียบง่ายและใช้งานได้จริงสำหรับโครงการ AI/ML ของพวกเขา เขามีความหลงใหลเกี่ยวกับ MlOps และวิทยาศาสตร์ข้อมูลแบบดั้งเดิมมากที่สุด นอกเหนือจากงาน เขาเป็นแฟนตัวยงของวินด์เซิร์ฟและไคท์เซิร์ฟ
คอนราด เซ็มช เป็นสถาปนิกอาวุโสด้านโซลูชัน ML ของทีม Amazon Web Services Data Lab เขาช่วยให้ลูกค้าใช้การเรียนรู้ของเครื่องเพื่อแก้ปัญหาความท้าทายทางธุรกิจด้วย AWS เขาสนุกกับการประดิษฐ์และลดความซับซ้อนเพื่อให้ลูกค้าได้รับโซลูชันที่เรียบง่ายและใช้งานได้จริงสำหรับโครงการ AI/ML ของพวกเขา เขามีความหลงใหลเกี่ยวกับ MlOps และวิทยาศาสตร์ข้อมูลแบบดั้งเดิมมากที่สุด นอกเหนือจากงาน เขาเป็นแฟนตัวยงของวินด์เซิร์ฟและไคท์เซิร์ฟ
 ทูน่าเออร์ซอย เป็นสถาปนิกโซลูชันอาวุโสที่ AWS เป้าหมายหลักของเธอคือการช่วยให้ลูกค้าภาครัฐนำเทคโนโลยีคลาวด์มาใช้กับปริมาณงานของพวกเขา เธอมีพื้นฐานด้านการพัฒนาแอปพลิเคชัน สถาปัตยกรรมองค์กร และเทคโนโลยีศูนย์ติดต่อ ความสนใจของเธอรวมถึงสถาปัตยกรรมแบบไร้เซิร์ฟเวอร์และ AI/ML
ทูน่าเออร์ซอย เป็นสถาปนิกโซลูชันอาวุโสที่ AWS เป้าหมายหลักของเธอคือการช่วยให้ลูกค้าภาครัฐนำเทคโนโลยีคลาวด์มาใช้กับปริมาณงานของพวกเขา เธอมีพื้นฐานด้านการพัฒนาแอปพลิเคชัน สถาปัตยกรรมองค์กร และเทคโนโลยีศูนย์ติดต่อ ความสนใจของเธอรวมถึงสถาปัตยกรรมแบบไร้เซิร์ฟเวอร์และ AI/ML
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/implement-a-custom-automl-job-using-pre-selected-algorithms-in-amazon-sagemaker-automatic-model-tuning/

