อเมซอน SageMaker อุปกรณ์ปลายทางหลายรุ่น (MME) เป็นความสามารถที่มีการจัดการเต็มรูปแบบของการอนุมานของ SageMaker ซึ่งช่วยให้คุณสามารถปรับใช้โมเดลหลายพันรายการบนตำแหน่งข้อมูลเดียว ก่อนหน้านี้ MME จะจัดสรรพลังการประมวลผล CPU ไว้ล่วงหน้าให้กับโมเดลแบบคงที่ โดยไม่คำนึงถึงปริมาณการรับส่งข้อมูลของโมเดล โดยใช้ เซิร์ฟเวอร์หลายรุ่น (MMS) เป็นเซิร์ฟเวอร์รุ่นของมัน ในโพสต์นี้ เราจะพูดถึงโซลูชันที่ MME สามารถปรับกำลังประมวลผลที่กำหนดให้กับแต่ละรุ่นได้แบบไดนามิกตามรูปแบบการรับส่งข้อมูลของโมเดล โซลูชันนี้ช่วยให้คุณใช้การประมวลผลพื้นฐานของ MME ได้อย่างมีประสิทธิภาพมากขึ้นและประหยัดค่าใช้จ่าย
MME จะโหลดและยกเลิกการโหลดโมเดลแบบไดนามิกโดยอิงตามการรับส่งข้อมูลขาเข้าไปยังปลายทาง เมื่อใช้ MMS เป็นเซิร์ฟเวอร์โมเดล MME จะจัดสรรจำนวนคนงานโมเดลที่แน่นอนสำหรับแต่ละรุ่น สำหรับข้อมูลเพิ่มเติม โปรดดูที่ รูปแบบการโฮสต์โมเดลใน Amazon SageMaker ตอนที่ 3: เรียกใช้และเพิ่มประสิทธิภาพการอนุมานแบบหลายโมเดลด้วยตำแหน่งข้อมูลแบบหลายโมเดลของ Amazon SageMaker.
อย่างไรก็ตาม สิ่งนี้อาจนำไปสู่ปัญหาบางประการเมื่อรูปแบบการเข้าชมของคุณไม่แน่นอน สมมติว่าคุณมีโมเดลเดียวหรือสองสามโมเดลที่ได้รับการเข้าชมจำนวนมาก คุณสามารถกำหนดค่า MMS เพื่อจัดสรรคนทำงานจำนวนมากสำหรับโมเดลเหล่านี้ได้ แต่สิ่งนี้จะได้รับการกำหนดให้กับโมเดลทั้งหมดที่อยู่เบื้องหลัง MME เนื่องจากเป็นการกำหนดค่าแบบคงที่ ส่งผลให้มีพนักงานจำนวนมากที่ใช้การประมวลผลด้วยฮาร์ดแวร์ แม้แต่รุ่นที่ไม่ได้ใช้งานก็ตาม ปัญหาตรงกันข้ามอาจเกิดขึ้นได้หากคุณตั้งค่าจำนวนคนงานเพียงเล็กน้อย โมเดลยอดนิยมจะมีคนทำงานไม่เพียงพอในระดับเซิร์ฟเวอร์โมเดลเพื่อจัดสรรฮาร์ดแวร์ที่เพียงพอหลังจุดสิ้นสุดสำหรับโมเดลเหล่านี้อย่างเหมาะสม ปัญหาหลักคือ เป็นเรื่องยากที่จะรักษารูปแบบการรับส่งข้อมูลให้คงอยู่ หากคุณไม่สามารถปรับขนาดผู้ปฏิบัติงานในระดับเซิร์ฟเวอร์แบบจำลองแบบไดนามิกเพื่อจัดสรรปริมาณการประมวลผลที่จำเป็นได้
วิธีแก้ปัญหาที่เราพูดถึงในโพสต์นี้ใช้ DJLเสิร์ฟ เป็นเซิร์ฟเวอร์โมเดล ซึ่งสามารถช่วยบรรเทาปัญหาบางอย่างที่เราได้พูดคุยกัน และเปิดใช้งานการปรับขนาดต่อโมเดล และทำให้ MME ไม่เชื่อเรื่องรูปแบบการรับส่งข้อมูล
สถาปัตยกรรมเอ็มเอ็มอี
SageMaker MME ช่วยให้คุณสามารถปรับใช้หลายโมเดลหลังจุดสิ้นสุดการอนุมานจุดเดียวที่อาจมีอย่างน้อยหนึ่งอินสแตนซ์ แต่ละอินสแตนซ์ได้รับการออกแบบมาเพื่อโหลดและให้บริการหลายรุ่น โดยขึ้นอยู่กับหน่วยความจำและความจุ CPU/GPU ด้วยสถาปัตยกรรมนี้ ธุรกิจซอฟต์แวร์ในรูปแบบบริการ (SaaS) สามารถลดต้นทุนที่เพิ่มขึ้นเชิงเส้นของการโฮสต์โมเดลหลายรุ่น และบรรลุการนำโครงสร้างพื้นฐานกลับมาใช้ใหม่ได้ โดยสอดคล้องกับโมเดลการเช่าหลายรายที่ใช้ในส่วนอื่นในกลุ่มแอปพลิเคชัน แผนภาพต่อไปนี้แสดงให้เห็นถึงสถาปัตยกรรมนี้

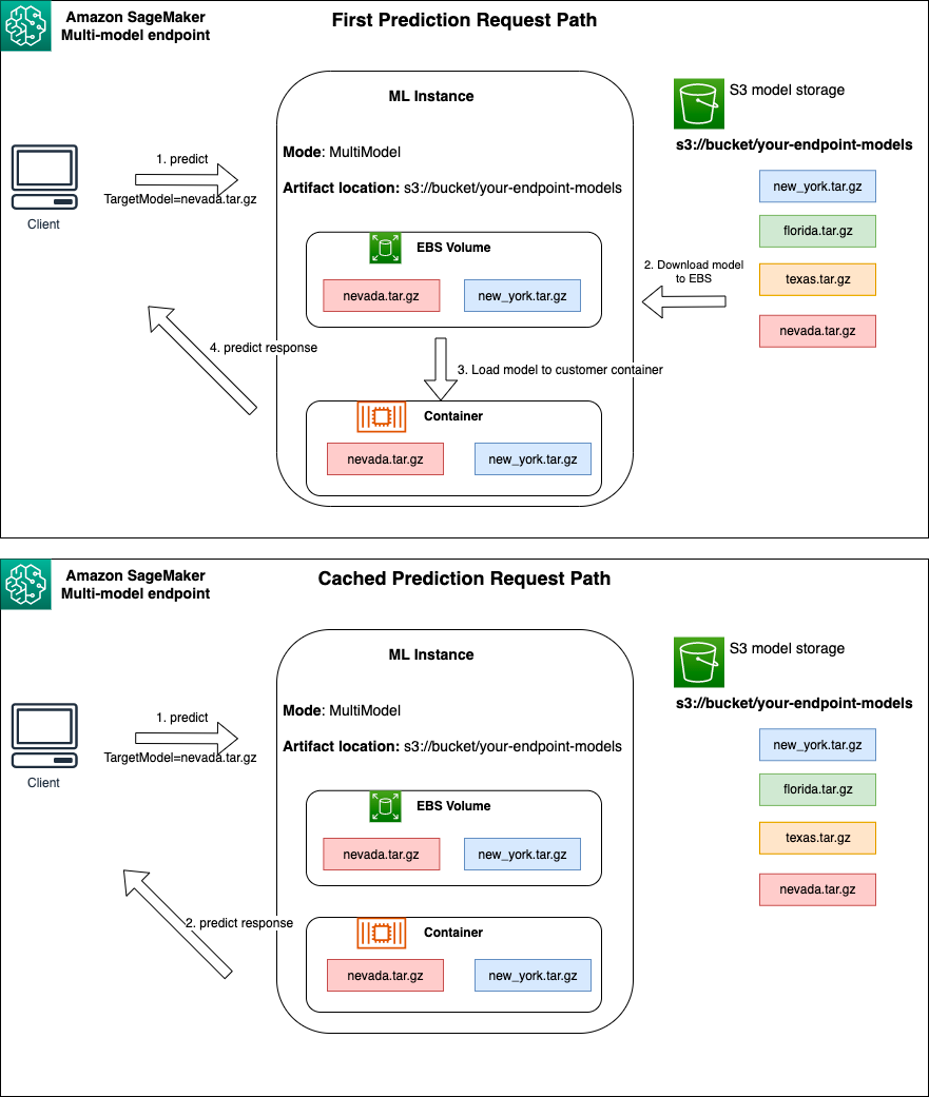
SageMaker MME จะโหลดโมเดลแบบไดนามิก บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) เมื่อเรียกใช้ แทนที่จะดาวน์โหลดโมเดลทั้งหมดเมื่อสร้างตำแหน่งข้อมูลครั้งแรก ด้วยเหตุนี้ การเรียกใช้โมเดลครั้งแรกอาจเห็นเวลาแฝงในการอนุมานที่สูงกว่าการอนุมานครั้งต่อๆ ไป ซึ่งเสร็จสมบูรณ์ด้วยเวลาแฝงต่ำ หากโมเดลถูกโหลดบนคอนเทนเนอร์แล้วเมื่อเรียกใช้ ขั้นตอนการดาวน์โหลดจะถูกข้ามไป และโมเดลจะส่งกลับการอนุมานที่มีเวลาแฝงต่ำ ตัวอย่างเช่น สมมติว่าคุณมีโมเดลที่ใช้งานเพียงไม่กี่ครั้งต่อวัน ระบบจะโหลดโดยอัตโนมัติตามความต้องการ ในขณะที่โมเดลที่มีการเข้าถึงบ่อยจะยังคงอยู่ในหน่วยความจำและเรียกใช้โดยมีเวลาแฝงต่ำอย่างสม่ำเสมอ
เบื้องหลัง MME แต่ละรายการคืออินสแตนซ์การโฮสต์โมเดล ดังแสดงในแผนภาพต่อไปนี้ อินสแตนซ์เหล่านี้โหลดและขับไล่โมเดลหลายตัวเข้าและออกจากหน่วยความจำตามรูปแบบการรับส่งข้อมูลไปยังโมเดล

SageMaker ยังคงกำหนดเส้นทางคำขอการอนุมานสำหรับโมเดลไปยังอินสแตนซ์ที่โมเดลถูกโหลดไว้แล้ว เพื่อให้คำขอได้รับการตอบสนองจากสำเนาโมเดลที่แคชไว้ (ดูแผนภาพต่อไปนี้ ซึ่งแสดงเส้นทางคำขอสำหรับคำขอการคาดการณ์แรกเทียบกับการคาดการณ์ที่แคชไว้ ขอเส้นทาง) อย่างไรก็ตาม หากโมเดลได้รับการร้องขอการเรียกใช้จำนวนมาก และมีอินสแตนซ์เพิ่มเติมสำหรับ MME SageMaker จะกำหนดเส้นทางคำขอบางส่วนไปยังอินสแตนซ์อื่นเพื่อรองรับการเพิ่มขึ้น หากต้องการใช้ประโยชน์จากการปรับขนาดโมเดลอัตโนมัติใน SageMaker ตรวจสอบให้แน่ใจว่าคุณมี ตั้งค่าการปรับขนาดอัตโนมัติของอินสแตนซ์ เพื่อจัดเตรียมความจุอินสแตนซ์เพิ่มเติม ตั้งค่านโยบายการปรับสเกลระดับปลายทางของคุณด้วยพารามิเตอร์ที่กำหนดเองหรือการเรียกใช้ต่อนาที (แนะนำ) เพื่อเพิ่มอินสแตนซ์ให้กับฟลีตปลายทาง
ภาพรวมเซิร์ฟเวอร์โมเดล
เซิร์ฟเวอร์โมเดลคือส่วนประกอบซอฟต์แวร์ที่จัดเตรียมสภาพแวดล้อมรันไทม์สำหรับการปรับใช้และให้บริการโมเดลการเรียนรู้ของเครื่อง (ML) โดยทำหน้าที่เป็นอินเทอร์เฟซระหว่างโมเดลที่ได้รับการฝึกและแอปพลิเคชันไคลเอนต์ที่ต้องการคาดการณ์โดยใช้โมเดลเหล่านั้น
วัตถุประสงค์หลักของเซิร์ฟเวอร์โมเดลคือเพื่อให้สามารถบูรณาการได้อย่างง่ายดายและปรับใช้โมเดล ML ในระบบที่ใช้งานจริงได้อย่างมีประสิทธิภาพ แทนที่จะฝังโมเดลลงในแอปพลิเคชันหรือเฟรมเวิร์กเฉพาะโดยตรง เซิร์ฟเวอร์โมเดลจะมีแพลตฟอร์มแบบรวมศูนย์ที่สามารถนำโมเดลต่างๆ ไปใช้ จัดการ และให้บริการได้
โดยทั่วไปเซิร์ฟเวอร์จำลองจะมีฟังก์ชันการทำงานดังต่อไปนี้:
- กำลังโหลดโมเดล – เซิร์ฟเวอร์โหลดโมเดล ML ที่ผ่านการฝึกอบรมแล้วลงในหน่วยความจำ ทำให้พร้อมสำหรับการให้บริการการคาดการณ์
- API การอนุมาน – เซิร์ฟเวอร์เปิดเผย API ที่อนุญาตให้แอปพลิเคชันไคลเอนต์ส่งข้อมูลอินพุตและรับการคาดการณ์จากโมเดลที่ปรับใช้
- ขูดหินปูน – เซิร์ฟเวอร์จำลองได้รับการออกแบบมาเพื่อจัดการคำขอพร้อมกันจากไคลเอนต์หลายเครื่อง โดยจัดเตรียมกลไกสำหรับการประมวลผลแบบขนานและการจัดการทรัพยากรอย่างมีประสิทธิภาพเพื่อให้แน่ใจว่ามีปริมาณงานสูงและมีเวลาแฝงต่ำ
- บูรณาการกับเครื่องยนต์แบ็กเอนด์ – เซิร์ฟเวอร์โมเดลมีการผสานรวมกับเฟรมเวิร์กแบ็กเอนด์ เช่น DeepSpeed และ FasterTransformer เพื่อแบ่งพาร์ติชันโมเดลขนาดใหญ่และเรียกใช้การอนุมานที่ได้รับการปรับปรุงให้เหมาะสมที่สุด
สถาปัตยกรรมดีเจแอล
ดีเจแอล เสิร์ฟ เป็นเซิร์ฟเวอร์รุ่นสากลโอเพ่นซอร์ส ประสิทธิภาพสูง DJL Serving ถูกสร้างขึ้นบน DJLซึ่งเป็นไลบรารีการเรียนรู้เชิงลึกที่เขียนด้วยภาษาการเขียนโปรแกรม Java โดยอาจใช้โมเดลการเรียนรู้เชิงลึก หลายโมเดล หรือเวิร์กโฟลว์และทำให้พร้อมใช้งานผ่านตำแหน่งข้อมูล HTTP DJL Serving รองรับการปรับใช้โมเดลจากหลายเฟรมเวิร์ก เช่น PyTorch, TensorFlow, Apache MXNet, ONNX, TensorRT, Hugging Face Transformers, DeepSpeed, FasterTransformer และอื่นๆ
DJL Serving นำเสนอคุณสมบัติมากมายที่ช่วยให้คุณสามารถปรับใช้โมเดลของคุณด้วยประสิทธิภาพสูง:
- ความง่ายดายในการใช้งาน – DJL Serving สามารถให้บริการโมเดลส่วนใหญ่ได้ทันทีที่แกะกล่อง เพียงนำสิ่งประดิษฐ์แบบจำลองมา แล้ว DJL Serving ก็สามารถเป็นเจ้าภาพได้
- รองรับอุปกรณ์หลายตัวและตัวเร่งความเร็ว – DJL Serving รองรับการปรับใช้โมเดลบน CPU, GPU และ การอนุมาน AWS.
- ประสิทธิภาพ – DJL Serving รันการอนุมานแบบมัลติเธรดใน JVM เดียวเพื่อเพิ่มปริมาณงาน
- การแบ่งกลุ่มแบบไดนามิก – DJL Serving รองรับการแบทช์แบบไดนามิกเพื่อเพิ่มปริมาณงาน
- ปรับขนาดอัตโนมัติ – DJL Serving จะปรับขนาดพนักงานขึ้นและลงโดยอัตโนมัติตามปริมาณการรับส่งข้อมูล
- รองรับหลายเครื่องยนต์ – DJL Serving สามารถโฮสต์โมเดลได้พร้อมกันโดยใช้เฟรมเวิร์กที่แตกต่างกัน (เช่น PyTorch และ TensorFlow)
- แบบจำลองทั้งมวลและเวิร์กโฟลว์ – DJL Serving รองรับการปรับใช้เวิร์กโฟลว์ที่ซับซ้อนซึ่งประกอบด้วยหลายรุ่น และรันบางส่วนของเวิร์กโฟลว์บน CPU และส่วนต่างๆ บน GPU โมเดลภายในเวิร์กโฟลว์สามารถใช้เฟรมเวิร์กที่แตกต่างกันได้
โดยเฉพาะอย่างยิ่ง คุณสมบัติการปรับขนาดอัตโนมัติของ DJL Serving ช่วยให้มั่นใจได้ว่าโมเดลได้รับการปรับขนาดอย่างเหมาะสมสำหรับการรับส่งข้อมูลขาเข้า ตามค่าเริ่มต้น DJL Serving จะกำหนดจำนวนคนทำงานสูงสุดสำหรับรุ่นที่สามารถรองรับได้ตามฮาร์ดแวร์ที่มีอยู่ (แกน CPU, อุปกรณ์ GPU) คุณสามารถตั้งค่าขอบเขตล่างและบนสำหรับแต่ละรุ่นเพื่อให้แน่ใจว่าระดับการรับส่งข้อมูลขั้นต่ำสามารถให้บริการได้เสมอ และโมเดลเดียวไม่ได้ใช้ทรัพยากรที่มีอยู่ทั้งหมด
DJL Serving ใช้ไฟล์ Netty ส่วนหน้าอยู่ด้านบนของพูลเธรดของผู้ปฏิบัติงานส่วนหลัง ส่วนหน้าใช้การตั้งค่า Netty เดียวกับหลายรายการ HttpRequestHandlers. ตัวจัดการคำขอที่แตกต่างกันจะให้การสนับสนุนสำหรับ API การอนุมาน, API การจัดการหรือ API อื่นๆ ที่มีให้ใช้งานจากปลั๊กอินต่างๆ
แบ็กเอนด์จะขึ้นอยู่กับ ตัวจัดการภาระงาน โมดูล (WLM) WLM ดูแลเธรดผู้ปฏิบัติงานหลายเธรดสำหรับแต่ละรุ่น พร้อมกับการแบทช์และการร้องขอการกำหนดเส้นทางไปยังเธรดเหล่านั้น เมื่อให้บริการหลายโมเดล WLM จะตรวจสอบขนาดคิวคำขอการอนุมานของแต่ละโมเดลก่อน หากขนาดคิวมากกว่าสองเท่าของขนาดแบตช์ของโมเดล WLM จะเพิ่มจำนวนผู้ปฏิบัติงานที่กำหนดให้กับโมเดลนั้น
ภาพรวมโซลูชัน
การใช้งาน DJL ด้วย MME แตกต่างจากการตั้งค่า MMS เริ่มต้น สำหรับการให้บริการ DJL ด้วย MME เราจะบีบอัดไฟล์ต่อไปนี้ในรูปแบบ model.tar.gz ที่ SageMaker Inference คาดหวัง:
- model.joblib – สำหรับการใช้งานนี้ เราจะพุชข้อมูลเมตาของโมเดลลงใน tarball โดยตรง ในกรณีนี้ เรากำลังทำงานร่วมกับก
.joblibดังนั้นเราจึงจัดเตรียมไฟล์นั้นไว้ใน tarball เพื่อให้สคริปต์การอนุมานของเราอ่านได้ หากอาร์ติแฟกต์มีขนาดใหญ่เกินไป คุณยังสามารถพุชไปยัง Amazon S3 และชี้ไปที่การกำหนดค่าการให้บริการที่คุณกำหนดสำหรับ DJL ได้ - ให้บริการคุณสมบัติ – ที่นี่คุณสามารถกำหนดค่าโมเดลที่เกี่ยวข้องกับเซิร์ฟเวอร์ได้ ตัวแปรสภาพแวดล้อม. พลังของ DJL ที่นี่คือคุณสามารถกำหนดค่าได้
minWorkersและmaxWorkersสำหรับทาร์บอลแต่ละรุ่น ซึ่งช่วยให้แต่ละโมเดลสามารถขยายขนาดขึ้นและลงที่ระดับเซิร์ฟเวอร์โมเดลได้ ตัวอย่างเช่น หากโมเดลเอกพจน์ได้รับปริมาณข้อมูลส่วนใหญ่สำหรับ MME เซิร์ฟเวอร์โมเดลจะขยายขนาดผู้ปฏิบัติงานแบบไดนามิก ในตัวอย่างนี้ เราไม่ได้กำหนดค่าตัวแปรเหล่านี้และให้ DJL กำหนดจำนวนคนทำงานที่จำเป็นโดยขึ้นอยู่กับรูปแบบการรับส่งข้อมูลของเรา - model.py – นี่คือสคริปต์การอนุมานสำหรับการประมวลผลล่วงหน้าหรือการประมวลผลภายหลังแบบกำหนดเองใดๆ ที่คุณต้องการนำไปใช้ model.py คาดว่าตรรกะของคุณจะถูกห่อหุ้มด้วยวิธีการจัดการตามค่าเริ่มต้น
- Requirement.txt (ไม่บังคับ) – ตามค่าเริ่มต้น DJL จะติดตั้งมาพร้อมกับ PyTorch แต่การขึ้นต่อกันเพิ่มเติมใดๆ ที่คุณต้องการสามารถพุชได้ที่นี่
สำหรับตัวอย่างนี้ เราแสดงพลังของ DJL ด้วย MME โดยใช้โมเดล SKLearn ตัวอย่าง เราดำเนินการฝึกอบรมกับโมเดลนี้ จากนั้นสร้างสำเนาของอาร์ติแฟกต์ของโมเดลนี้จำนวน 1,000 สำเนาเพื่อสนับสนุน MME ของเรา จากนั้นเราจะแสดงให้เห็นว่า DJL สามารถปรับขนาดแบบไดนามิกเพื่อรองรับรูปแบบการรับส่งข้อมูลประเภทใดก็ตามที่ MME ของคุณอาจได้รับได้อย่างไร ซึ่งอาจรวมถึงการกระจายการรับส่งข้อมูลอย่างสม่ำเสมอในทุกรุ่น หรือแม้แต่รุ่นยอดนิยมบางรุ่นที่ได้รับการเข้าชมส่วนใหญ่ คุณสามารถค้นหารหัสทั้งหมดได้ดังต่อไปนี้ repo GitHub.
เบื้องต้น
สำหรับตัวอย่างนี้ เราใช้อินสแตนซ์โน้ตบุ๊ก SageMaker ที่มีเคอร์เนล conda_python3 และอินสแตนซ์ ml.c5.xlarge หากต้องการดำเนินการทดสอบโหลด คุณสามารถใช้ อเมซอน อีลาสติก คอมพิวท์ คลาวด์ (Amazon EC2) หรืออินสแตนซ์โน้ตบุ๊ก SageMaker ที่ใหญ่กว่า ในตัวอย่างนี้ เราปรับขนาดเป็นธุรกรรมมากกว่าหนึ่งพันรายการต่อวินาที (TPS) ดังนั้นเราจึงขอแนะนำให้ทดสอบบนอินสแตนซ์ EC2 ที่หนักกว่า เช่น ml.c5.18xlarge เพื่อให้คุณมีการประมวลผลที่มากขึ้นในการทำงาน
สร้างสิ่งประดิษฐ์แบบจำลอง
ก่อนอื่นเราต้องสร้างสิ่งประดิษฐ์แบบจำลองและข้อมูลที่เราใช้ในตัวอย่างนี้ก่อน ในกรณีนี้ เราสร้างข้อมูลปลอมด้วย NumPy และฝึกโดยใช้แบบจำลองการถดถอยเชิงเส้นของ SKLearn ด้วยข้อมูลโค้ดต่อไปนี้:
หลังจากที่คุณเรียกใช้โค้ดก่อนหน้า คุณควรมี model.joblib ไฟล์ที่สร้างขึ้นในสภาพแวดล้อมท้องถิ่นของคุณ
ดึงอิมเมจ DJL Docker
Docker image djl-inference:0.23.0-cpu-full-v1.0 คือคอนเทนเนอร์ที่ให้บริการ DJL ที่ใช้ในตัวอย่างนี้ คุณสามารถปรับ URL ต่อไปนี้ได้ขึ้นอยู่กับภูมิภาคของคุณ:
inference_image_uri = "474422712127.dkr.ecr.us-east-1.amazonaws.com/djl-serving-cpu:latest"
หรือคุณสามารถใช้รูปภาพนี้เป็นรูปภาพพื้นฐานและขยายเพื่อสร้างอิมเมจ Docker ของคุณเองได้ การลงทะเบียน Amazon Elastic Container (Amazon ECR) พร้อมด้วยการอ้างอิงอื่นๆ ที่คุณต้องการ
สร้างไฟล์โมเดล
ขั้นแรก เราสร้างไฟล์ชื่อ serving.properties. สิ่งนี้จะสั่งให้ DJLServing ใช้เอ็นจิ้น Python เรายังกำหนด max_idle_time ของคนงานเป็น 600 วินาที เพื่อให้แน่ใจว่าเราจะใช้เวลานานขึ้นในการลดจำนวนพนักงานที่เรามีต่อโมเดล เราไม่ปรับ. minWorkers และ maxWorkers ที่เราสามารถกำหนดได้ และเราปล่อยให้ DJL คำนวณจำนวนพนักงานที่ต้องการแบบไดนามิก ขึ้นอยู่กับปริมาณการรับส่งข้อมูลที่แต่ละรุ่นได้รับ serving.propertiesแสดงไว้ดังนี้ หากต้องการดูรายการตัวเลือกการกำหนดค่าทั้งหมด โปรดดูที่ การกำหนดค่าเครื่องยนต์.
ต่อไป เราจะสร้างไฟล์ model.py ซึ่งกำหนดการโหลดโมเดลและตรรกะการอนุมาน สำหรับ MME แต่ละไฟล์ model.py จะเป็นข้อมูลเฉพาะสำหรับโมเดลหนึ่งๆ โมเดลจะถูกจัดเก็บไว้ในเส้นทางของตนเองภายใต้ที่เก็บโมเดล (โดยปกติคือ /opt/ml/model/). เมื่อโหลดโมเดล โมเดลเหล่านั้นจะถูกโหลดภายใต้พาธที่เก็บโมเดลในไดเร็กทอรีของตนเอง ตัวอย่าง model.py แบบเต็มในการสาธิตนี้สามารถดูได้ใน repo GitHub.
เราสร้างไฟล์ model.tar.gz ไฟล์ที่มีโมเดลของเรา (model.joblib), model.pyและ serving.properties:
เพื่อวัตถุประสงค์ในการสาธิต เราทำสำเนาแบบเดียวกันนี้จำนวน 1,000 ชุด model.tar.gz ไฟล์เพื่อแสดงโมเดลจำนวนมากที่จะโฮสต์ ในการผลิตคุณต้องสร้าง model.tar.gz ไฟล์สำหรับแต่ละรุ่นของคุณ
สุดท้ายนี้ เราอัปโหลดโมเดลเหล่านี้ไปยัง Amazon S3
สร้างโมเดล SageMaker
ตอนนี้เราสร้าง รุ่น SageMaker. เราใช้อิมเมจ ECR ที่กำหนดไว้ก่อนหน้านี้และสิ่งประดิษฐ์ของโมเดลจากขั้นตอนก่อนหน้าเพื่อสร้างโมเดล SageMaker ในการตั้งค่าโมเดล เรากำหนดค่าโหมดเป็น MultiModel สิ่งนี้เป็นการแจ้ง DJLServing ว่าเรากำลังสร้าง MME
สร้างจุดสิ้นสุด SageMaker
ในการสาธิตนี้ เราใช้อินสแตนซ์ 20 ml.c5d.18xlarge เพื่อปรับขนาดเป็น TPS ในช่วงหลักพัน ตรวจสอบให้แน่ใจว่าได้รับการเพิ่มขีดจำกัดสำหรับประเภทอินสแตนซ์ของคุณ หากจำเป็น เพื่อให้บรรลุ TPS ที่คุณกำหนดเป้าหมาย
โหลดการทดสอบ
ในขณะที่เขียน เครื่องมือทดสอบโหลดภายใน SageMaker ผู้แนะนำการอนุมานของ Amazon SageMaker ไม่รองรับการทดสอบ MME โดยกำเนิด ดังนั้นเราจึงใช้เครื่องมือโอเพ่นซอร์ส Python ปาทังกา. Locust ตั้งค่าได้ง่ายและสามารถติดตามตัวชี้วัด เช่น TPS และเวลาแฝงจากต้นทางถึงปลายทางได้ หากต้องการทำความเข้าใจวิธีตั้งค่าด้วย SageMaker อย่างครบถ้วน โปรดดู แนวทางปฏิบัติที่ดีที่สุดสำหรับการทดสอบการโหลดจุดสิ้นสุดการอนุมานแบบเรียลไทม์ของ Amazon SageMaker.
ในกรณีการใช้งานนี้ เรามีรูปแบบการรับส่งข้อมูลที่แตกต่างกันสามรูปแบบที่เราต้องการจำลองด้วย MME ดังนั้นเราจึงมีสคริปต์ Python สามสคริปต์ต่อไปนี้ซึ่งสอดคล้องกับแต่ละรูปแบบ เป้าหมายของเราในที่นี้คือการพิสูจน์ว่า ไม่ว่ารูปแบบการรับส่งข้อมูลของเราจะเป็นอย่างไร เราสามารถบรรลุ TPS เป้าหมายเดียวกันและปรับขนาดได้อย่างเหมาะสม
เราสามารถระบุน้ำหนักในสคริปต์ Locust เพื่อกำหนดปริมาณการรับส่งข้อมูลในส่วนต่างๆ ของโมเดลของเรา ตัวอย่างเช่น ด้วยโมเดลฮอตโมเดลเดี่ยวของเรา เราจะใช้สองวิธีดังต่อไปนี้:
จากนั้น เราสามารถกำหนดน้ำหนักที่แน่นอนให้กับแต่ละวิธีได้ ซึ่งก็คือเมื่อวิธีการหนึ่งได้รับเปอร์เซ็นต์การเข้าชมที่เฉพาะเจาะจง:
สำหรับอินสแตนซ์ 20 ml.c5d.18xlarge เราจะเห็นตัววัดคำขอต่อไปนี้ใน อเมซอน คลาวด์วอตช์ คอนโซล ค่าเหล่านี้ยังคงค่อนข้างสอดคล้องกันในรูปแบบการเข้าชมทั้งสามรูปแบบ หากต้องการทำความเข้าใจตัววัด CloudWatch สำหรับการอนุมานแบบเรียลไทม์ของ SageMaker และ MME ให้ดียิ่งขึ้น โปรดดูที่ เมตริกการเรียกใช้ปลายทางของ SageMaker.

คุณสามารถค้นหาสคริปต์ Locust ที่เหลือได้ใน ไดเรกทอรี locust-utils ในพื้นที่เก็บข้อมูล GitHub
สรุป
ในโพสต์นี้ เราได้พูดคุยถึงวิธีที่ MME สามารถปรับกำลังประมวลผลแบบไดนามิกที่กำหนดให้กับแต่ละรุ่นตามรูปแบบการรับส่งข้อมูลของโมเดล คุณสมบัติที่เพิ่งเปิดตัวนี้มีให้บริการในทุกภูมิภาค AWS ที่ SageMaker ใช้งานได้ โปรดทราบว่าในขณะที่ประกาศ รองรับเฉพาะอินสแตนซ์ CPU เท่านั้น หากต้องการเรียนรู้เพิ่มเติม โปรดดูที่ อัลกอริทึม เฟรมเวิร์ก และอินสแตนซ์ที่รองรับ.
เกี่ยวกับผู้เขียน
 ราม เวจิราจุ เป็นสถาปนิก ML กับทีมบริการ SageMaker เขามุ่งเน้นที่การช่วยลูกค้าสร้างและเพิ่มประสิทธิภาพโซลูชัน AI/ML ของตนบน Amazon SageMaker ในเวลาว่าง เขาชอบท่องเที่ยวและเขียนหนังสือ
ราม เวจิราจุ เป็นสถาปนิก ML กับทีมบริการ SageMaker เขามุ่งเน้นที่การช่วยลูกค้าสร้างและเพิ่มประสิทธิภาพโซลูชัน AI/ML ของตนบน Amazon SageMaker ในเวลาว่าง เขาชอบท่องเที่ยวและเขียนหนังสือ
 ชิงเหว่ย ลี่ เป็นผู้เชี่ยวชาญด้าน Machine Learning ที่ Amazon Web Services เขาได้รับปริญญาเอกของเขา ใน Operations Research หลังจากที่เขาทำลายบัญชีทุนวิจัยของที่ปรึกษาและล้มเหลวในการมอบรางวัลโนเบลที่เขาสัญญาไว้ ปัจจุบันเขาช่วยลูกค้าในอุตสาหกรรมบริการทางการเงินและประกันภัยสร้างโซลูชันแมชชีนเลิร์นนิงบน AWS เวลาว่างชอบอ่านหนังสือและสอน
ชิงเหว่ย ลี่ เป็นผู้เชี่ยวชาญด้าน Machine Learning ที่ Amazon Web Services เขาได้รับปริญญาเอกของเขา ใน Operations Research หลังจากที่เขาทำลายบัญชีทุนวิจัยของที่ปรึกษาและล้มเหลวในการมอบรางวัลโนเบลที่เขาสัญญาไว้ ปัจจุบันเขาช่วยลูกค้าในอุตสาหกรรมบริการทางการเงินและประกันภัยสร้างโซลูชันแมชชีนเลิร์นนิงบน AWS เวลาว่างชอบอ่านหนังสือและสอน
 เจมส์ หวู่ เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้าน AI/ML อาวุโสที่ AWS ช่วยลูกค้าออกแบบและสร้างโซลูชัน AI/ML งานของ James ครอบคลุมกรณีการใช้งาน ML ที่หลากหลาย โดยมีความสนใจหลักในด้านการมองเห็นคอมพิวเตอร์ การเรียนรู้เชิงลึก และการปรับขนาด ML ทั่วทั้งองค์กร ก่อนที่จะร่วมงานกับ AWS เจมส์เคยเป็นสถาปนิก นักพัฒนา และผู้นำด้านเทคโนโลยีมานานกว่า 10 ปี รวมถึง 6 ปีในด้านวิศวกรรมและ 4 ปีในอุตสาหกรรมการตลาดและการโฆษณา
เจมส์ หวู่ เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญด้าน AI/ML อาวุโสที่ AWS ช่วยลูกค้าออกแบบและสร้างโซลูชัน AI/ML งานของ James ครอบคลุมกรณีการใช้งาน ML ที่หลากหลาย โดยมีความสนใจหลักในด้านการมองเห็นคอมพิวเตอร์ การเรียนรู้เชิงลึก และการปรับขนาด ML ทั่วทั้งองค์กร ก่อนที่จะร่วมงานกับ AWS เจมส์เคยเป็นสถาปนิก นักพัฒนา และผู้นำด้านเทคโนโลยีมานานกว่า 10 ปี รวมถึง 6 ปีในด้านวิศวกรรมและ 4 ปีในอุตสาหกรรมการตลาดและการโฆษณา
 ซอราภ ตรีกันเด เป็นผู้จัดการผลิตภัณฑ์อาวุโสสำหรับการอนุมานของ Amazon SageMaker เขาหลงใหลในการทำงานกับลูกค้าและมีแรงจูงใจโดยเป้าหมายของการทำให้แมชชีนเลิร์นนิงเป็นประชาธิปไตย เขามุ่งเน้นไปที่ความท้าทายหลักที่เกี่ยวข้องกับการปรับใช้งานแอปพลิเคชัน ML ที่ซับซ้อน โมเดล ML แบบหลายผู้เช่า การเพิ่มประสิทธิภาพต้นทุน และทำให้การปรับใช้โมเดลการเรียนรู้เชิงลึกสามารถเข้าถึงได้มากขึ้น ในเวลาว่าง Saurabh สนุกกับการเดินป่า เรียนรู้เกี่ยวกับเทคโนโลยีที่เป็นนวัตกรรม ติดตาม TechCrunch และใช้เวลากับครอบครัวของเขา
ซอราภ ตรีกันเด เป็นผู้จัดการผลิตภัณฑ์อาวุโสสำหรับการอนุมานของ Amazon SageMaker เขาหลงใหลในการทำงานกับลูกค้าและมีแรงจูงใจโดยเป้าหมายของการทำให้แมชชีนเลิร์นนิงเป็นประชาธิปไตย เขามุ่งเน้นไปที่ความท้าทายหลักที่เกี่ยวข้องกับการปรับใช้งานแอปพลิเคชัน ML ที่ซับซ้อน โมเดล ML แบบหลายผู้เช่า การเพิ่มประสิทธิภาพต้นทุน และทำให้การปรับใช้โมเดลการเรียนรู้เชิงลึกสามารถเข้าถึงได้มากขึ้น ในเวลาว่าง Saurabh สนุกกับการเดินป่า เรียนรู้เกี่ยวกับเทคโนโลยีที่เป็นนวัตกรรม ติดตาม TechCrunch และใช้เวลากับครอบครัวของเขา
 ซูเติ้ง เป็นผู้จัดการวิศวกรซอฟต์แวร์ในทีม SageMaker เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการสร้างและเพิ่มประสิทธิภาพประสบการณ์การอนุมาน AI/ML บน Amazon SageMaker ในเวลาว่าง เขาชอบการเดินทางและการเล่นสโนว์บอร์ด
ซูเติ้ง เป็นผู้จัดการวิศวกรซอฟต์แวร์ในทีม SageMaker เขามุ่งเน้นที่การช่วยเหลือลูกค้าในการสร้างและเพิ่มประสิทธิภาพประสบการณ์การอนุมาน AI/ML บน Amazon SageMaker ในเวลาว่าง เขาชอบการเดินทางและการเล่นสโนว์บอร์ด
 สิทธัตถะ เวนกาเตสัน เป็นวิศวกรซอฟต์แวร์ใน AWS Deep Learning ปัจจุบันเขามุ่งเน้นไปที่การสร้างโซลูชันสำหรับการอนุมานแบบจำลองขนาดใหญ่ ก่อนหน้าที่ AWS เขาทำงานในองค์กร Amazon Grocery ในการสร้างคุณสมบัติการชำระเงินใหม่สำหรับลูกค้าทั่วโลก นอกงาน เขาชอบเล่นสกี กลางแจ้ง และดูกีฬา
สิทธัตถะ เวนกาเตสัน เป็นวิศวกรซอฟต์แวร์ใน AWS Deep Learning ปัจจุบันเขามุ่งเน้นไปที่การสร้างโซลูชันสำหรับการอนุมานแบบจำลองขนาดใหญ่ ก่อนหน้าที่ AWS เขาทำงานในองค์กร Amazon Grocery ในการสร้างคุณสมบัติการชำระเงินใหม่สำหรับลูกค้าทั่วโลก นอกงาน เขาชอบเล่นสกี กลางแจ้ง และดูกีฬา
 โรหิต นัลลามัดดี เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS เขาทำงานเพื่อเพิ่มประสิทธิภาพเวิร์กโหลดการเรียนรู้เชิงลึกบน GPU สร้างการอนุมาน ML ประสิทธิภาพสูงและโซลูชันการให้บริการ ก่อนหน้านี้ เขาทำงานเกี่ยวกับการสร้างไมโครเซอร์วิสโดยใช้ AWS สำหรับธุรกิจ Amazon F3 นอกเวลางานเขาชอบเล่นและดูกีฬา
โรหิต นัลลามัดดี เป็นวิศวกรพัฒนาซอฟต์แวร์ที่ AWS เขาทำงานเพื่อเพิ่มประสิทธิภาพเวิร์กโหลดการเรียนรู้เชิงลึกบน GPU สร้างการอนุมาน ML ประสิทธิภาพสูงและโซลูชันการให้บริการ ก่อนหน้านี้ เขาทำงานเกี่ยวกับการสร้างไมโครเซอร์วิสโดยใช้ AWS สำหรับธุรกิจ Amazon F3 นอกเวลางานเขาชอบเล่นและดูกีฬา
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/run-ml-inference-on-unplanned-and-spiky-traffic-using-amazon-sagemaker-multi-model-endpoints/

