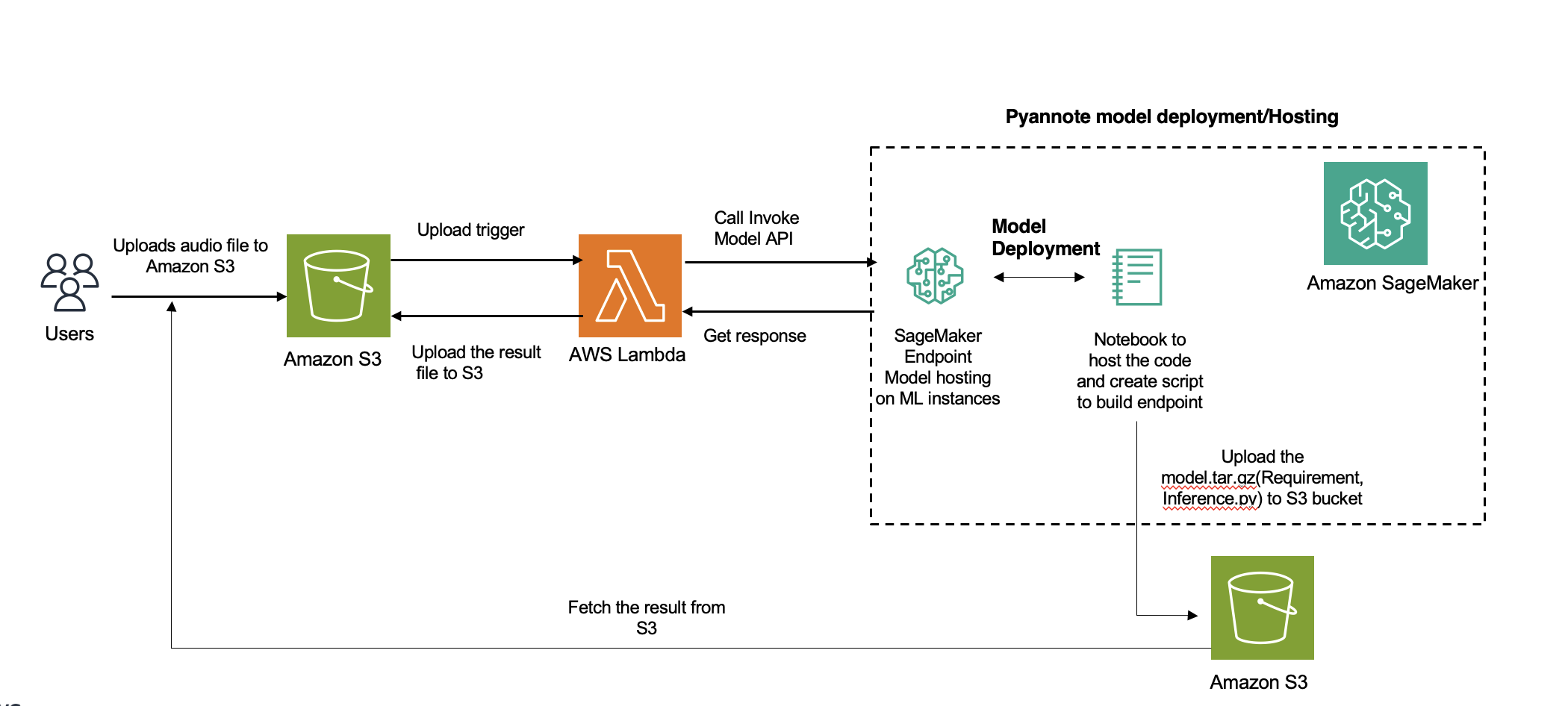
การแยกเสียงของผู้พูดเป็นกระบวนการสำคัญในการวิเคราะห์เสียง โดยจะแบ่งไฟล์เสียงตามเอกลักษณ์ของผู้พูด โพสต์นี้เจาะลึกเกี่ยวกับการบูรณาการ PyAnnote ของ Hugging Face เพื่อการแยกแยะผู้พูดด้วย อเมซอน SageMaker จุดสิ้นสุดแบบอะซิงโครนัส
เรามีคำแนะนำที่ครอบคลุมเกี่ยวกับวิธีการปรับใช้โซลูชันการแบ่งส่วนผู้พูดและการจัดกลุ่มโดยใช้ SageMaker บน AWS Cloud คุณสามารถใช้โซลูชันนี้สำหรับแอปพลิเคชันที่เกี่ยวข้องกับการบันทึกเสียงที่มีลำโพงหลายตัว (มากกว่า 100 ตัว)
ภาพรวมโซลูชัน
ถอดความจากอเมซอน เป็นบริการแบบ go-to สำหรับการแยกแยะผู้พูดใน AWS อย่างไรก็ตาม สำหรับภาษาที่ไม่รองรับ คุณสามารถใช้โมเดลอื่นๆ (ในกรณีของเราคือ PyAnnote) ที่จะนำไปใช้ใน SageMaker เพื่อการอนุมาน สำหรับไฟล์เสียงสั้นที่การอนุมานใช้เวลาถึง 60 วินาที คุณสามารถใช้ได้ การอนุมานตามเวลาจริง - เป็นเวลานานกว่า 60 วินาที ไม่ตรงกัน ควรใช้การอนุมาน ประโยชน์เพิ่มเติมของการอนุมานแบบอะซิงโครนัสคือการประหยัดต้นทุนโดยปรับขนาดอินสแตนซ์นับให้เป็นศูนย์โดยอัตโนมัติเมื่อไม่มีคำขอให้ดำเนินการ
กอดหน้า เป็นฮับโอเพ่นซอร์สยอดนิยมสำหรับโมเดลการเรียนรู้ของเครื่อง (ML) AWS และ Hugging Face มี ห้างหุ้นส่วน ที่ช่วยให้สามารถผสานรวมได้อย่างราบรื่นผ่าน SageMaker กับชุด AWS Deep Learning Containers (DLC) สำหรับการฝึกอบรมและการอนุมานใน PyTorch หรือ TensorFlow และตัวประมาณค่า Hugging Face และตัวทำนายสำหรับ SageMaker Python SDK คุณสมบัติและความสามารถของ SageMaker ช่วยให้นักพัฒนาและนักวิทยาศาสตร์ข้อมูลเริ่มต้นการประมวลผลภาษาธรรมชาติ (NLP) บน AWS ได้อย่างง่ายดาย
การบูรณาการสำหรับโซลูชันนี้เกี่ยวข้องกับการใช้โมเดลการแยกเสียงของผู้พูดที่ได้รับการฝึกอบรมล่วงหน้าของ Hugging Face โดยใช้ ไลบรารี PyAnnote - PyAnnote เป็นชุดเครื่องมือโอเพ่นซอร์สที่เขียนด้วยภาษา Python สำหรับการแยกเสียงของผู้พูด แบบจำลองนี้ได้รับการฝึกอบรมเกี่ยวกับชุดข้อมูลเสียงตัวอย่าง ช่วยให้สามารถแบ่งพาร์ติชันลำโพงในไฟล์เสียงได้อย่างมีประสิทธิภาพ โมเดลนี้ใช้งานบน SageMaker ในรูปแบบการตั้งค่าตำแหน่งข้อมูลแบบอะซิงโครนัส ซึ่งให้การประมวลผลงานไดอะไรซ์ที่มีประสิทธิภาพและปรับขนาดได้
ไดอะแกรมต่อไปนี้แสดงสถาปัตยกรรมโซลูชัน
สำหรับโพสต์นี้ เราใช้ไฟล์เสียงต่อไปนี้
ไฟล์เสียงสเตอริโอหรือหลายช่องสัญญาณจะถูกดาวน์มิกซ์เป็นโมโนโดยอัตโนมัติโดยการหาค่าเฉลี่ยของช่องสัญญาณ ไฟล์เสียงที่สุ่มตัวอย่างในอัตราอื่นจะถูกสุ่มใหม่เป็น 16kHz โดยอัตโนมัติเมื่อโหลด
เบื้องต้น
กรอกข้อกำหนดเบื้องต้นต่อไปนี้:
สร้างโดเมน SageMaker .ตรวจสอบให้แน่ใจของคุณ AWS Identity และการจัดการการเข้าถึง ผู้ใช้ (IAM) มีสิทธิ์การเข้าถึงที่จำเป็นสำหรับการสร้าง บทบาทของ SageMaker .
ตรวจสอบให้แน่ใจว่าบัญชี AWS มีโควต้าบริการสำหรับการโฮสต์ตำแหน่งข้อมูล SageMaker สำหรับอินสแตนซ์ ml.g5.2xlarge
สร้างฟังก์ชันแบบจำลองสำหรับการเข้าถึงการแยกเสียงของผู้พูด PyAnnote จาก Hugging Face
คุณสามารถใช้ Hugging Face Hub เพื่อเข้าถึงการฝึกล่วงหน้าที่ต้องการได้ โมเดลการแยกเสียงลำโพง PyAnnote - คุณใช้สคริปต์เดียวกันในการดาวน์โหลดไฟล์โมเดลเมื่อสร้างตำแหน่งข้อมูล SageMaker
ดูรหัสต่อไปนี้:
from PyAnnote.audio import Pipeline
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="Replace-with-the-Hugging-face-auth-token")
return model
บรรจุรหัสรุ่น
เตรียมไฟล์สำคัญ เช่น inference.py ซึ่งมีโค้ดการอนุมาน:
%%writefile model/code/inference.py
from PyAnnote.audio import Pipeline
import subprocess
import boto3
from urllib.parse import urlparse
import pandas as pd
from io import StringIO
import os
import torch
def model_fn(model_dir):
# Load the model from the specified model directory
model = Pipeline.from_pretrained(
"PyAnnote/speaker-diarization-3.1",
use_auth_token="hf_oBxxxxxxxxxxxx)
return model
def diarization_from_s3(model, s3_file, language=None):
s3 = boto3.client("s3")
o = urlparse(s3_file, allow_fragments=False)
bucket = o.netloc
key = o.path.lstrip("/")
s3.download_file(bucket, key, "tmp.wav")
result = model("tmp.wav")
data = {}
for turn, _, speaker in result.itertracks(yield_label=True):
data[turn] = (turn.start, turn.end, speaker)
data_df = pd.DataFrame(data.values(), columns=["start", "end", "speaker"])
print(data_df.shape)
result = data_df.to_json(orient="split")
return result
def predict_fn(data, model):
s3_file = data.pop("s3_file")
language = data.pop("language", None)
result = diarization_from_s3(model, s3_file, language)
return {
"diarization_from_s3": result
}
เตรียมไฟล์ requirements.txt ซึ่งมีไลบรารี Python ที่จำเป็นซึ่งจำเป็นต่อการเรียกใช้การอนุมาน:
with open("model/code/requirements.txt", "w") as f:
f.write("transformers==4.25.1n")
f.write("boto3n")
f.write("PyAnnote.audion")
f.write("soundfilen")
f.write("librosan")
f.write("onnxruntimen")
f.write("wgetn")
f.write("pandas")
สุดท้ายให้บีบอัดไฟล์ inference.py และไฟล์require.txtแล้วบันทึกเป็น model.tar.gz:
กำหนดค่าโมเดล SageMaker
กำหนดทรัพยากรโมเดล SageMaker โดยการระบุ URI รูปภาพ ตำแหน่งข้อมูลโมเดล บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (S3) และบทบาท SageMaker:
import sagemaker
import boto3
sess = sagemaker.Session()
sagemaker_session_bucket = None
if sagemaker_session_bucket is None and sess is not None:
sagemaker_session_bucket = sess.default_bucket()
try:
role = sagemaker.get_execution_role()
except ValueError:
iam = boto3.client("iam")
role = iam.get_role(RoleName="sagemaker_execution_role")["Role"]["Arn"]
sess = sagemaker.Session(default_bucket=sagemaker_session_bucket)
print(f"sagemaker role arn: {role}")
print(f"sagemaker bucket: {sess.default_bucket()}")
print(f"sagemaker session region: {sess.boto_region_name}")
อัปโหลดโมเดลไปยัง Amazon S3
อัปโหลดไฟล์โมเดล PyAnnote Hugging Face ที่ถูกซิปไปยังบัคเก็ต S3:
s3_location = f"s3://{sagemaker_session_bucket}/whisper/model/model.tar.gz"
!aws s3 cp model.tar.gz $s3_location
สร้างจุดสิ้นสุดแบบอะซิงโครนัสของ SageMaker
กำหนดค่าตำแหน่งข้อมูลแบบอะซิงโครนัสสำหรับการปรับใช้โมเดลบน SageMaker โดยใช้การกำหนดค่าการอนุมานแบบอะซิงโครนัสที่ให้มา:
from sagemaker.huggingface.model import HuggingFaceModel
from sagemaker.async_inference.async_inference_config import AsyncInferenceConfig
from sagemaker.s3 import s3_path_join
from sagemaker.utils import name_from_base
async_endpoint_name = name_from_base("custom-asyc")
# create Hugging Face Model Class
huggingface_model = HuggingFaceModel(
model_data=s3_location, # path to your model and script
role=role, # iam role with permissions to create an Endpoint
transformers_version="4.17", # transformers version used
pytorch_version="1.10", # pytorch version used
py_version="py38", # python version used
)
# create async endpoint configuration
async_config = AsyncInferenceConfig(
output_path=s3_path_join(
"s3://", sagemaker_session_bucket, "async_inference/output"
), # Where our results will be stored
# Add nofitication SNS if needed
notification_config={
# "SuccessTopic": "PUT YOUR SUCCESS SNS TOPIC ARN",
# "ErrorTopic": "PUT YOUR ERROR SNS TOPIC ARN",
}, # Notification configuration
)
env = {"MODEL_SERVER_WORKERS": "2"}
# deploy the endpoint endpoint
async_predictor = huggingface_model.deploy(
initial_instance_count=1,
instance_type="ml.xx",
async_inference_config=async_config,
endpoint_name=async_endpoint_name,
env=env,
)
ทดสอบจุดสิ้นสุด
ประเมินฟังก์ชันการทำงานของตำแหน่งข้อมูลโดยการส่งไฟล์เสียงเพื่อทำไดอะไรเซชัน และเรียกข้อมูลเอาต์พุต JSON ที่จัดเก็บไว้ในเส้นทางเอาต์พุต S3 ที่ระบุ:
# Replace with a path to audio object in S3
from sagemaker.async_inference import WaiterConfig
res = async_predictor.predict_async(data=data)
print(f"Response output path: {res.output_path}")
print("Start Polling to get response:")
config = WaiterConfig(
max_attempts=10, # number of attempts
delay=10# time in seconds to wait between attempts
)
res.get_result(config)
#import waiterconfig
หากต้องการปรับใช้โซลูชันนี้ในวงกว้าง เราขอแนะนำให้ใช้ AWS แลมบ์ดา , บริการแจ้งเตือนแบบง่ายของ Amazon (อเมซอน SNS) หรือ บริการ Amazon Simple Queue (อเมซอน SQS) บริการเหล่านี้ได้รับการออกแบบมาเพื่อความสามารถในการปรับขนาด สถาปัตยกรรมที่ขับเคลื่อนด้วยเหตุการณ์ และการใช้ทรัพยากรอย่างมีประสิทธิภาพ สามารถช่วยแยกกระบวนการอนุมานแบบอะซิงโครนัสออกจากการประมวลผลผลลัพธ์ได้ ช่วยให้คุณสามารถปรับขนาดแต่ละองค์ประกอบได้อย่างอิสระและจัดการคำขออนุมานต่อเนื่องได้อย่างมีประสิทธิภาพมากขึ้น
ผลสอบ
โมเดลเอาท์พุตจะถูกเก็บไว้ที่ s3://sagemaker-xxxx /async_inference/output/. ผลลัพธ์แสดงว่าการบันทึกเสียงถูกแบ่งออกเป็นสามคอลัมน์:
เริ่มต้น (เวลาเริ่มต้นเป็นวินาที)
สิ้นสุด (เวลาสิ้นสุดเป็นวินาที)
ลำโพง (ป้ายลำโพง)
รหัสต่อไปนี้แสดงตัวอย่างผลลัพธ์ของเรา:
[0.9762308998, 8.9049235993, "SPEAKER_01"]
[9.533106961, 12.1646859083, "SPEAKER_01"]
[13.1324278438, 13.9303904924, "SPEAKER_00"]
[14.3548387097, 26.1884550085, "SPEAKER_00"]
[27.2410865874, 28.2258064516, "SPEAKER_01"]
[28.3446519525, 31.298811545, "SPEAKER_01"]
ทำความสะอาด
คุณสามารถตั้งค่านโยบายการปรับขนาดให้เป็นศูนย์ได้โดยตั้งค่า MinCapacity เป็น 0 การอนุมานแบบอะซิงโครนัส ช่วยให้คุณปรับขนาดเป็นศูนย์อัตโนมัติโดยไม่ต้องร้องขอ คุณไม่จำเป็นต้องลบปลายทางมัน ตาชั่ง จากศูนย์เมื่อจำเป็นอีกครั้ง ลดต้นทุนเมื่อไม่ได้ใช้งาน ดูรหัสต่อไปนี้:
# Common class representing application autoscaling for SageMaker
client = boto3.client('application-autoscaling')
# This is the format in which application autoscaling references the endpoint
resource_id='endpoint/' + <endpoint_name> + '/variant/' + <'variant1'>
# Define and register your endpoint variant
response = client.register_scalable_target(
ServiceNamespace='sagemaker',
ResourceId=resource_id,
ScalableDimension='sagemaker:variant:DesiredInstanceCount', # The number of EC2 instances for your Amazon SageMaker model endpoint variant.
MinCapacity=0,
MaxCapacity=5
)
หากคุณต้องการลบปลายทาง ให้ใช้รหัสต่อไปนี้:
async_predictor.delete_endpoint(async_endpoint_name)
ประโยชน์ของการปรับใช้ตำแหน่งข้อมูลแบบอะซิงโครนัส
โซลูชันนี้ให้ประโยชน์ดังต่อไปนี้:
โซลูชันนี้สามารถจัดการไฟล์เสียงหลายไฟล์หรือขนาดใหญ่ได้อย่างมีประสิทธิภาพ
ตัวอย่างนี้ใช้อินสแตนซ์เดียวสำหรับการสาธิต หากคุณต้องการใช้โซลูชันนี้กับวิดีโอนับร้อยหรือหลายพันรายการ และใช้ตำแหน่งข้อมูลแบบอะซิงโครนัสเพื่อประมวลผลข้ามอินสแตนซ์หลายรายการ คุณสามารถใช้ นโยบายการปรับขนาดอัตโนมัติ ซึ่งออกแบบมาสำหรับเอกสารต้นฉบับจำนวนมาก การปรับขนาดอัตโนมัติจะปรับจำนวนอินสแตนซ์ที่จัดเตรียมไว้สำหรับโมเดลแบบไดนามิกเพื่อตอบสนองต่อการเปลี่ยนแปลงในปริมาณงานของคุณ
โซลูชันนี้ปรับทรัพยากรให้เหมาะสมและลดภาระของระบบโดยแยกงานที่ใช้เวลานานออกจากการอนุมานแบบเรียลไทม์
สรุป
ในโพสต์นี้ เราได้จัดเตรียมแนวทางที่ตรงไปตรงมาในการปรับใช้โมเดลการแยกเสียงของผู้พูดของ Hugging Face บน SageMaker โดยใช้สคริปต์ Python การใช้จุดสิ้นสุดแบบอะซิงโครนัสเป็นวิธีที่มีประสิทธิภาพและปรับขนาดได้เพื่อส่งมอบการคาดการณ์ไดอะไรซ์เป็นบริการ เพื่อรองรับคำขอที่เกิดขึ้นพร้อมกันได้อย่างราบรื่น
เริ่มต้นวันนี้ด้วยการแยกเสียงลำโพงแบบอะซิงโครนัสสำหรับโปรเจ็กต์เสียงของคุณ ติดต่อเราในความคิดเห็นหากคุณมีคำถามใดๆ เกี่ยวกับการเริ่มต้นและใช้งานจุดสิ้นสุดไดอะไรเซชันแบบอะซิงโครนัสของคุณเอง
เกี่ยวกับผู้เขียน
สัญชัย ทิวารี เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AI/ML ซึ่งใช้เวลาทำงานร่วมกับลูกค้าเชิงกลยุทธ์เพื่อกำหนดความต้องการทางธุรกิจ จัดเตรียมเซสชัน L300 ตามกรณีการใช้งานเฉพาะ และออกแบบแอปพลิเคชันและบริการ AI/ML ที่สามารถปรับขนาดได้ เชื่อถือได้ และมีประสิทธิภาพ เขาได้ช่วยเปิดตัวและปรับขนาดบริการ Amazon SageMaker ที่ขับเคลื่อนด้วย AI/ML และได้นำการพิสูจน์แนวคิดหลายประการไปใช้โดยใช้บริการของ Amazon AI นอกจากนี้ เขายังพัฒนาแพลตฟอร์มการวิเคราะห์ขั้นสูง ซึ่งเป็นส่วนหนึ่งของการเดินทางสู่การเปลี่ยนแปลงทางดิจิทัล
กีราน ชลปัลลี เป็นผู้พัฒนาธุรกิจเทคโนโลยีล้ำลึกกับภาครัฐของ AWS เขามีประสบการณ์มากกว่า 8 ปีในด้าน AI/ML และประสบการณ์การพัฒนาซอฟต์แวร์และการขายโดยรวม 23 ปี Kiran ช่วยให้ธุรกิจภาครัฐทั่วอินเดียสำรวจและร่วมสร้างโซลูชันบนคลาวด์ที่ใช้ AI, ML และ AI เชิงสร้างสรรค์ รวมถึงเทคโนโลยีโมเดลภาษาขนาดใหญ่
 สัญชัย ทิวารี เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AI/ML ซึ่งใช้เวลาทำงานร่วมกับลูกค้าเชิงกลยุทธ์เพื่อกำหนดความต้องการทางธุรกิจ จัดเตรียมเซสชัน L300 ตามกรณีการใช้งานเฉพาะ และออกแบบแอปพลิเคชันและบริการ AI/ML ที่สามารถปรับขนาดได้ เชื่อถือได้ และมีประสิทธิภาพ เขาได้ช่วยเปิดตัวและปรับขนาดบริการ Amazon SageMaker ที่ขับเคลื่อนด้วย AI/ML และได้นำการพิสูจน์แนวคิดหลายประการไปใช้โดยใช้บริการของ Amazon AI นอกจากนี้ เขายังพัฒนาแพลตฟอร์มการวิเคราะห์ขั้นสูง ซึ่งเป็นส่วนหนึ่งของการเดินทางสู่การเปลี่ยนแปลงทางดิจิทัล
สัญชัย ทิวารี เป็นสถาปนิกโซลูชันผู้เชี่ยวชาญ AI/ML ซึ่งใช้เวลาทำงานร่วมกับลูกค้าเชิงกลยุทธ์เพื่อกำหนดความต้องการทางธุรกิจ จัดเตรียมเซสชัน L300 ตามกรณีการใช้งานเฉพาะ และออกแบบแอปพลิเคชันและบริการ AI/ML ที่สามารถปรับขนาดได้ เชื่อถือได้ และมีประสิทธิภาพ เขาได้ช่วยเปิดตัวและปรับขนาดบริการ Amazon SageMaker ที่ขับเคลื่อนด้วย AI/ML และได้นำการพิสูจน์แนวคิดหลายประการไปใช้โดยใช้บริการของ Amazon AI นอกจากนี้ เขายังพัฒนาแพลตฟอร์มการวิเคราะห์ขั้นสูง ซึ่งเป็นส่วนหนึ่งของการเดินทางสู่การเปลี่ยนแปลงทางดิจิทัล กีราน ชลปัลลี เป็นผู้พัฒนาธุรกิจเทคโนโลยีล้ำลึกกับภาครัฐของ AWS เขามีประสบการณ์มากกว่า 8 ปีในด้าน AI/ML และประสบการณ์การพัฒนาซอฟต์แวร์และการขายโดยรวม 23 ปี Kiran ช่วยให้ธุรกิจภาครัฐทั่วอินเดียสำรวจและร่วมสร้างโซลูชันบนคลาวด์ที่ใช้ AI, ML และ AI เชิงสร้างสรรค์ รวมถึงเทคโนโลยีโมเดลภาษาขนาดใหญ่
กีราน ชลปัลลี เป็นผู้พัฒนาธุรกิจเทคโนโลยีล้ำลึกกับภาครัฐของ AWS เขามีประสบการณ์มากกว่า 8 ปีในด้าน AI/ML และประสบการณ์การพัฒนาซอฟต์แวร์และการขายโดยรวม 23 ปี Kiran ช่วยให้ธุรกิจภาครัฐทั่วอินเดียสำรวจและร่วมสร้างโซลูชันบนคลาวด์ที่ใช้ AI, ML และ AI เชิงสร้างสรรค์ รวมถึงเทคโนโลยีโมเดลภาษาขนาดใหญ่
