This post was written in collaboration with Bhajandeep Singh and Ajay Vishwakarma from Wipro’s AWS AI/ML Practice.
Many organizations have been using a combination of on-premises and open source data science solutions to create and manage machine learning (ML) models.
Data science and DevOps teams may face challenges managing these isolated tool stacks and systems. Integrating multiple tool stacks to build a compact solution might involve building custom connectors or workflows. Managing different dependencies based on the current version of each stack and maintaining those dependencies with the release of new updates of each stack complicates the solution. This increases the cost of infrastructure maintenance and hampers productivity.
Artificial intelligence (AI) and machine learning (ML) offerings from Amazon Web Services (AWS), along with integrated monitoring and notification services, help organizations achieve the required level of automation, scalability, and model quality at optimal cost. AWS also helps data science and DevOps teams to collaborate and streamlines the overall model lifecycle process.
The AWS portfolio of ML services includes a robust set of services that you can use to accelerate the development, training, and deployment of machine learning applications. The suite of services can be used to support the complete model lifecycle including monitoring and retraining ML models.
In this post, we discuss model development and MLOps framework implementation for one of Wipro’s customers that uses Amazon SageMaker and other AWS services.
Wipro is an AWS Premier Tier Services Partner and Managed Service Provider (MSP). Its AI/ML solutions drive enhanced operational efficiency, productivity, and customer experience for many of their enterprise clients.
Current challenges
Let’s first understand a few of the challenges the customer’s data science and DevOps teams faced with their current setup. We can then examine how the integrated SageMaker AI/ML offerings helped solve those challenges.
- Collaboration – Data scientists each worked on their own local Jupyter notebooks to create and train ML models. They lacked an effective method for sharing and collaborating with other data scientists.
- Scalability – Training and re-training ML models was taking more and more time as models became more complex while the allocated infrastructure capacity remained static.
- MLOps – Model monitoring and ongoing governance wasn’t tightly integrated and automated with the ML models. There are dependencies and complexities with integrating third-party tools into the MLOps pipeline.
- Reusability – Without reusable MLOps frameworks, each model must be developed and governed separately, which adds to the overall effort and delays model operationalization.
This diagram summarizes the challenges and how Wipro’s implementation on SageMaker addressed them with built-in SageMaker services and offerings.
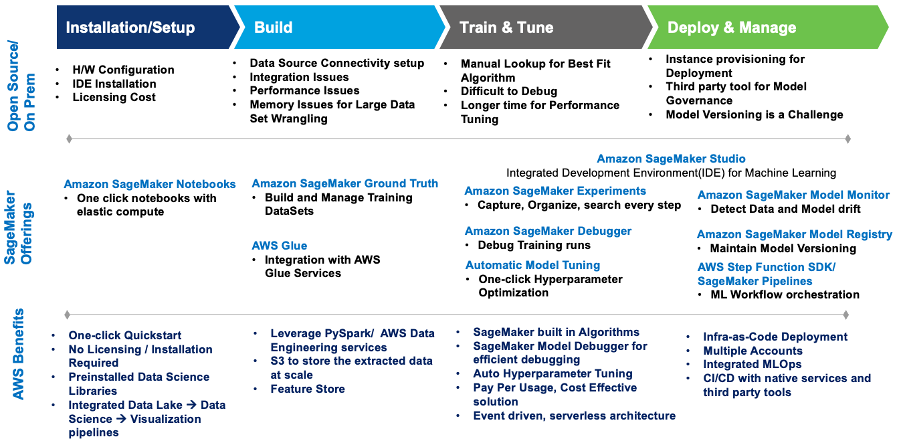
Figure 1 – SageMaker offerings for ML workload migration
Wipro defined an architecture that addresses the challenges in a cost-optimized and fully automated way.
The following is the use case and model used to build the solution:
- Use case: Price prediction based on the used car dataset
- Problem type: Regression
- Models used: XGBoost and Linear Learner (SageMaker built-in algorithms)
Solution architecture
Wipro consultants conducted a deep-dive discovery workshop with the customer’s data science, DevOps, and data engineering teams to understand the current environment as well as their requirements and expectations for a modern solution on AWS. By the end of the consulting engagement, the team had implemented the following architecture that effectively addressed the core requirements of the customer team, including:
Code Sharing – SageMaker notebooks enable data scientists to experiment and share code with other team members. Wipro further accelerated their ML model journey by implementing Wipro’s code accelerators and snippets to expedite feature engineering, model training, model deployment, and pipeline creation.
Continuous integration and continuous delivery (CI/CD) pipeline – Using the customer’s GitHub repository enabled code versioning and automated scripts to launch pipeline deployment whenever new versions of the code are committed.
MLOps – The architecture implements a SageMaker model monitoring pipeline for continuous model quality governance by validating data and model drift as required by the defined schedule. Whenever drift is detected, an event is launched to notify the respective teams to take action or initiate model retraining.
Event-driven architecture – The pipelines for model training, model deployment, and model monitoring are well integrated by use Amazon EventBridge, a serverless event bus. When defined events occur, EventBridge can invoke a pipeline to run in response. This provides a loosely-coupled set of pipelines that can run as needed in response to the environment.
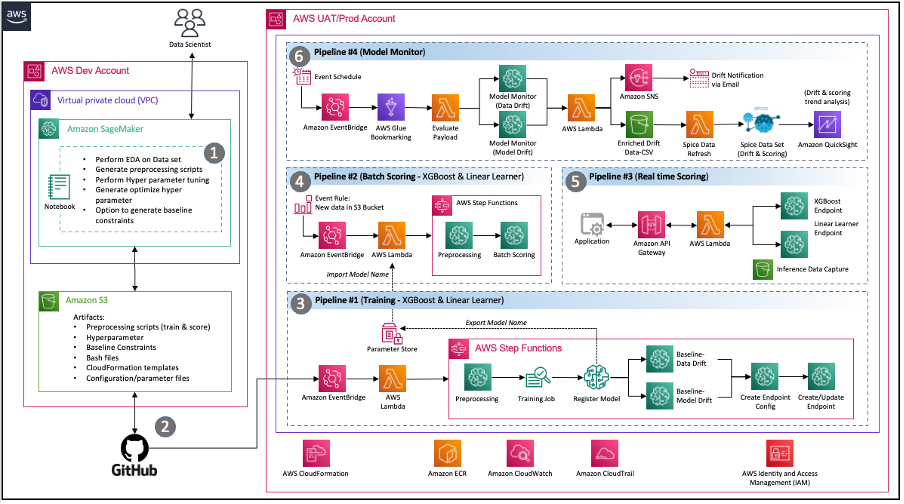
Figure 2 – Event Driven MLOps architecture with SageMaker
Solution components
This section describes the various solution components of the architecture.
Experiment notebooks
- Purpose: The customer’s data science team wanted to experiment with various datasets and multiple models to come up with the optimal features, using those as further inputs to the automated pipeline.
- Solution: Wipro created SageMaker experiment notebooks with code snippets for each reusable step, such as reading and writing data, model feature engineering, model training, and hyperparameter tuning. Feature engineering tasks can also be prepared in Data Wrangler, but the client specifically asked for SageMaker processing jobs and AWS Step Functions because they were more comfortable using those technologies. We used the AWS step function data science SDK to create a step function—for flow testing—directly from the notebook instance to enable well-defined inputs for the pipelines. This has helped the data scientist team to create and test pipelines at a much faster pace.
Automated training pipeline
- Purpose: To enable an automated training and re-training pipeline with configurable parameters such as instance type, hyperparameters, and an Amazon Simple Storage Service (Amazon S3) bucket location. The pipeline should also be launched by the data push event to S3.
- Solution: Wipro implemented a reusable training pipeline using the Step Functions SDK, SageMaker processing, training jobs, a SageMaker model monitor container for baseline generation, AWS Lambda, and EventBridge services.Using AWS event-driven architecture, the pipeline is configured to launch automatically based on a new data event being pushed to the mapped S3 bucket. Notifications are configured to be sent to the defined email addresses. At a high level, the training flow looks like the following diagram:
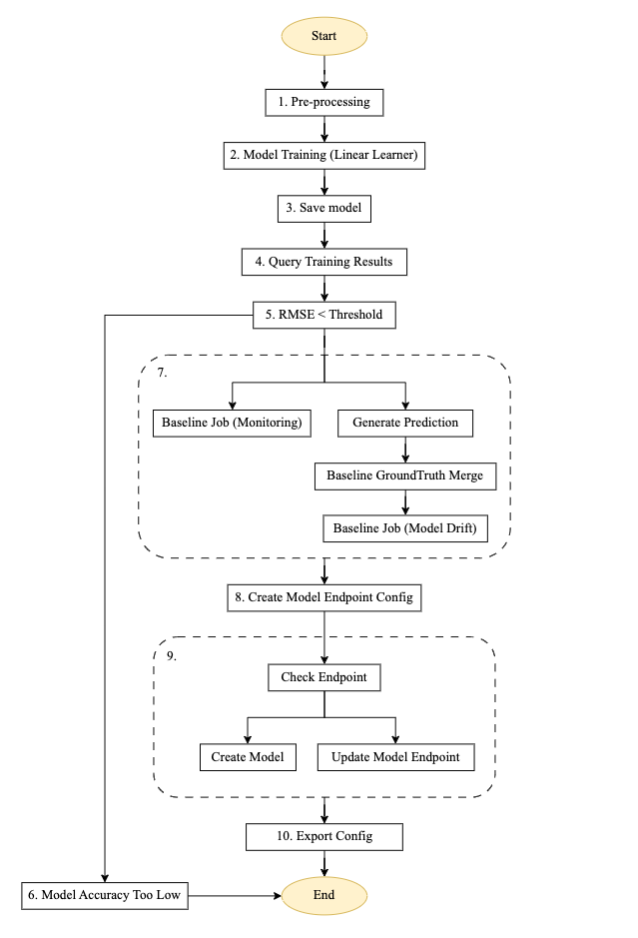
Figure 3 – Training pipeline step machine.
Flow description for the automated training pipeline
The above diagram is an automated training pipeline built using Step Functions, Lambda, and SageMaker. It’s a reusable pipeline for setting up automated model training, generating predictions, creating a baseline for model monitoring and data monitoring, and creating and updating an endpoint based on previous model threshold value.
- Pre-processing: This step takes data from an Amazon S3 location as input and uses the SageMaker SKLearn container to perform necessary feature engineering and data pre-processing tasks, such as the train, test, and validate split.
- Model training: Using the SageMaker SDK, this step runs training code with the respective model image and trains datasets from pre-processing scripts while generating the trained model artifacts.
- Save model: This step creates a model from the trained model artifacts. The model name is stored for reference in another pipeline using the AWS Systems Manager Parameter Store.
- Query training results: This step calls the Lambda function to fetch the metrics of the completed training job from the earlier model training step.
- RMSE threshold: This step verifies the trained model metric (RMSE) against a defined threshold to decide whether to proceed towards endpoint deployment or reject this model.
- Model accuracy too low: At this step the model accuracy is checked against the previous best model. If the model fails at metric validation, the notification is sent by a Lambda function to the target topic registered in Amazon Simple Notification Service (Amazon SNS). If this check fails, the flow exits because the new trained model didn’t meet the defined threshold.
- Baseline job data drift: If the trained model passes the validation steps, baseline stats are generated for this trained model version to enable monitoring and the parallel branch steps are run to generate the baseline for the model quality check.
- Create model endpoint configuration: This step creates endpoint configuration for the evaluated model in the previous step with an enable data capture configuration.
- Check endpoint: This step checks if the endpoint exists or needs to be created. Based on the output, the next step is to create or update the endpoint.
- Export configuration: This step exports the parameter’s model name, endpoint name, and endpoint configuration to the AWS Systems Manager Parameter Store.
Alerts and notifications are configured to be sent to the configured SNS topic email on the failure or success of state machine status change. The same pipeline configuration is reused for the XGBoost model.
Automated batch scoring pipeline
- Purpose: Launch batch scoring as soon as scoring input batch data is available in the respective Amazon S3 location. The batch scoring should use the latest registered model to do the scoring.
- Solution: Wipro implemented a reusable scoring pipeline using the Step Functions SDK, SageMaker batch transformation jobs, Lambda, and EventBridge. The pipeline is auto triggered based on the new scoring batch data availability to the respective S3 location.
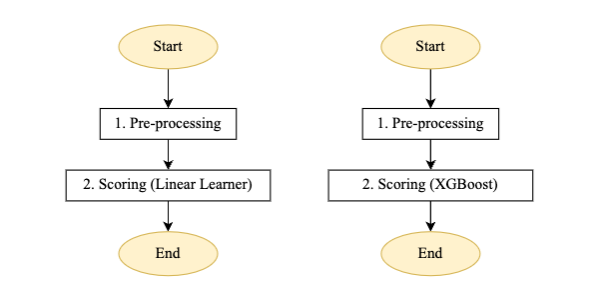
Figure 4 – Scoring pipeline step machine for linear learner and XGBoost model
Flow description for the automated batch scoring pipeline:
- Pre-processing: The input for this step is a data file from the respective S3 location, and does the required pre-processing before calling SageMaker batch transformation job.
- Scoring: This step runs the batch transformation job to generate inferences, calling the latest version of the registered model and storing the scoring output in an S3 bucket. Wipro has used the input filter and join functionality of SageMaker batch transformation API. It helped enrich the scoring data for better decision making.
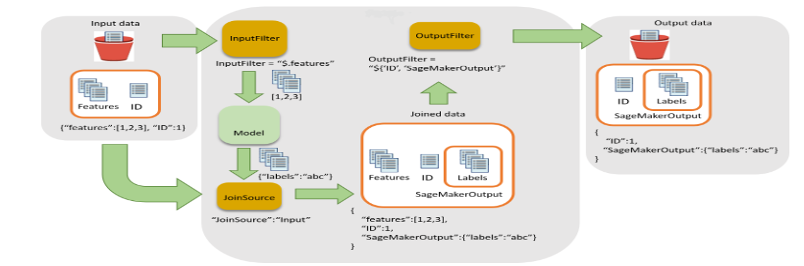
Figure 5 – Input filter and join flow for batch transformation
- In this step, the state machine pipeline is launched by a new data file in the S3 bucket.
The notification is configured to be sent to the configured SNS topic email on the failure/success of the state machine status change.
Real-time inference pipeline
- Purpose: To enable real-time inferences from both the models’ (Linear Learner and XGBoost) endpoints and get the maximum predicted value (or by using any other custom logic that can be written as a Lambda function) to be returned to the application.
- Solution: The Wipro team has implemented reusable architecture using Amazon API Gateway, Lambda, and SageMaker endpoint as shown in Figure 6:
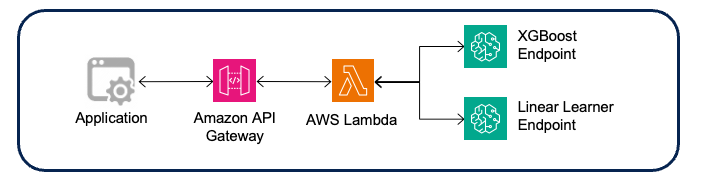
Figure 6 – Real-time inference pipeline
Flow description for the real-time inference pipeline shown in Figure 6:
- The payload is sent from the application to Amazon API Gateway, which routes it to the respective Lambda function.
- A Lambda function (with an integrated SageMaker custom layer) does the required pre-processing, JSON or CSV payload formatting, and invokes the respective endpoints.
- The response is returned to Lambda and sent back to the application through API Gateway.
The customer used this pipeline for small and medium scale models, which included using various types of open-source algorithms. One of the key benefits of SageMaker is that various types of algorithms can be brought into SageMaker and deployed using a bring your own container (BYOC) technique. BYOC involves containerizing the algorithm and registering the image in Amazon Elastic Container Registry (Amazon ECR), and then using the same image to create a container to do training and inference.
Scaling is one of the biggest issues in the machine learning cycle. SageMaker comes with the necessary tools for scaling a model during inference. In the preceding architecture, users need to enable auto-scaling of SageMaker, which eventually handles the workload. To enable auto-scaling, users must provide an auto-scaling policy that asks for the throughput per instance and maximum and minimum instances. Within the policy in place, SageMaker automatically handles the workload for real-time endpoints and switches between instances when needed.
Custom model monitor pipeline
- Purpose: The customer team wanted to have automated model monitoring to capture both data drift and model drift. The Wipro team used SageMaker model monitoring to enable both data drift and model drift with a reusable pipeline for real-time inferences and batch transformation.Note that during the development of this solution, the SageMaker model monitoring didn’t provide provision for detecting data or model drift for batch transformation. We have implemented customizations to use the model monitor container for the batch transformations payload.
- Solution: The Wipro team implemented a reusable model-monitoring pipeline for real-time and batch inference payloads using AWS Glue to capture the incremental payload and invoke the model monitoring job according to the defined schedule.
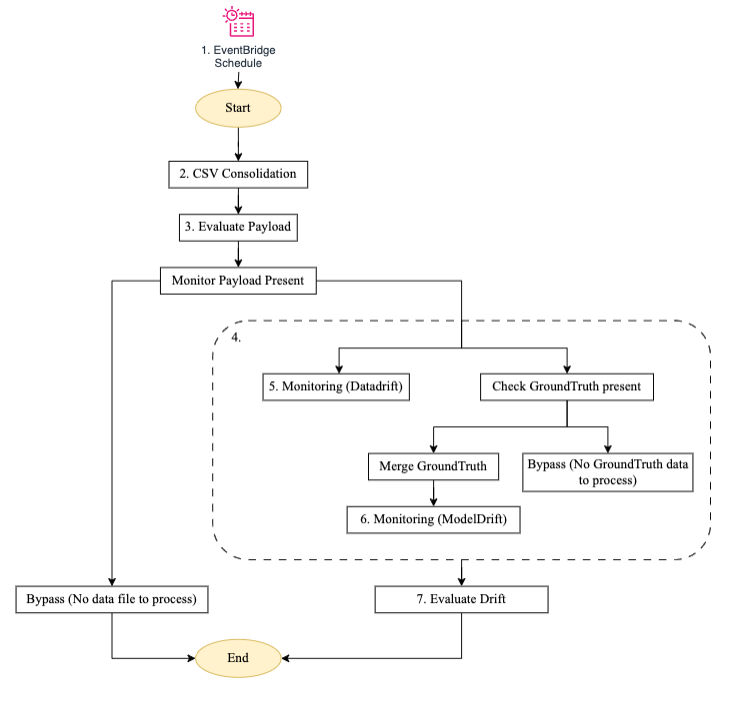
Figure 7 – Model monitor step machine
Flow description for the custom model monitor pipeline:
The pipeline runs according to the defined schedule configured through EventBridge.
- CSV consolidation – It uses the AWS Glue bookmark feature to detect the presence of incremental payload in the defined S3 bucket of real-time data capture and response and batch data response. It then aggregates that data for further processing.
- Evaluate payload – If there is incremental data or payload present for the current run, it invokes the monitoring branch. Otherwise, it bypasses without processing and exits the job.
- Post processing – The monitoring branch is designed to have two parallel sub branches—one for data drift and another for model drift.
- Monitoring (data drift) – The data drift branch runs whenever there is a payload present. It uses the latest trained model baseline constraints and statistics files generated through the training pipeline for the data features and runs the model monitoring job.
- Monitoring (model drift) – The model drift branch runs only when ground truth data is supplied, along with the inference payload. It uses trained model baseline constraints and statistics files generated through the training pipeline for the model quality features and runs the model monitoring job.
- Evaluate drift – The outcome of both data and model drift is a constraint violation file that’s evaluated by the evaluate drift Lambda function which sends notification to the respective Amazon SNS topics with details of the drift. Drift data is enriched further with the addition of attributes for reporting purposes. The drift notification emails will look similar to the examples in Figure 8.

Figure 8 – Data and model drift notification message

Figure 9 – Data and model drift notification message
Insights with Amazon QuickSight visualization:
- Purpose: The customer wanted to have insights about the data and model drift, relate the drift data to the respective model monitoring jobs, and find out the inference data trends to understand the nature of the interference data trends.
- Solution: The Wipro team enriched the drift data by connecting input data with the drift result, which enables triage from drift to monitoring and respective scoring data. Visualizations and dashboards were created using Amazon QuickSight with Amazon Athena as the data source (using the Amazon S3 CSV scoring and drift data).
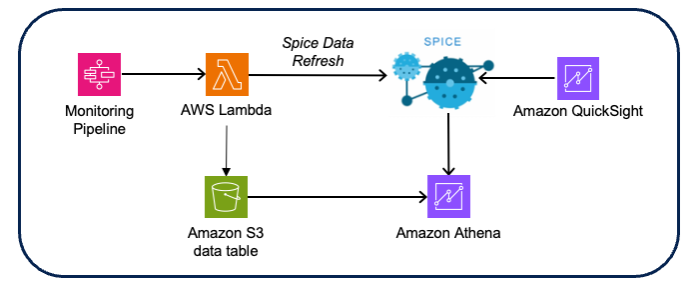
Figure 10 – Model monitoring visualization architecture
Design considerations:
- Use the QuickSight spice dataset for better in-memory performance.
- Use QuickSight refresh dataset APIs to automate the spice data refresh.
- Implement group-based security for dashboard and analysis access control.
- Across accounts, automate deployment using export and import dataset, data source, and analysis API calls provided by QuickSight.
Model monitoring dashboard:
To enable an effective outcome and meaningful insights of the model monitoring jobs, custom dashboards were created for the model monitoring data. The input data points are combined in parallel with inference request data, jobs data, and monitoring output to create a visualization of trends revealed by the model monitoring.
This has really helped the customer team to visualize the aspects of various data features along with the predicted outcome of each batch of inference requests.
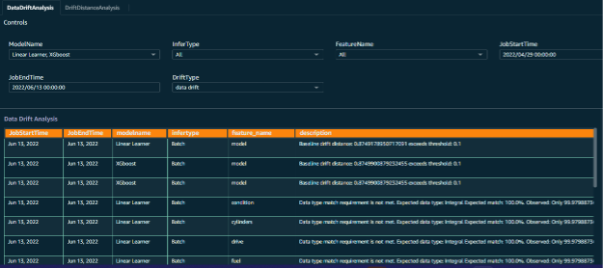
Figure 11 – Model monitor dashboard with selection prompts
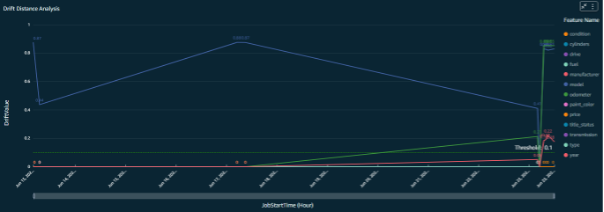
Figure 12 – Model monitor drift analysis
Conclusion
The implementation explained in this post enabled Wipro to effectively migrate their on-premises models to AWS and build a scalable, automated model development framework.
The use of reusable framework components empowers the data science team to effectively package their work as deployable AWS Step Functions JSON components. Simultaneously, the DevOps teams used and enhanced the automated CI/CD pipeline to facilitate the seamless promotion and retraining of models in higher environments.
Model monitoring component has enabled continuous monitoring of the model performance, and users receive alerts and notifications whenever data or model drift is detected.
The customer’s team is using this MLOps framework to migrate or develop more models and increase their SageMaker adoption.
By harnessing the comprehensive suite of SageMaker services in conjunction with our meticulously designed architecture, customers can seamlessly onboard multiple models, significantly reducing deployment time and mitigating complexities associated with code sharing. Moreover, our architecture simplifies code versioning maintenance, ensuring a streamlined development process.
This architecture handles the entire machine learning cycle, encompassing automated model training, real-time and batch inference, proactive model monitoring, and drift analysis. This end-to-end solution empowers customers to achieve optimal model performance while maintaining rigorous monitoring and analysis capabilities to ensure ongoing accuracy and reliability.
To create this architecture, begin by creating essential resources like Amazon Virtual Private Cloud (Amazon VPC), SageMaker notebooks, and Lambda functions. Make sure to set up appropriate AWS Identity and Access Management (IAM) policies for these resources.
Next, focus on building the components of the architecture—such as training and preprocessing scripts—within SageMaker Studio or Jupyter Notebook. This step involves developing the necessary code and configurations to enable the desired functionalities.
After the architecture’s components are defined, you can proceed with building the Lambda functions for generating inferences or performing post-processing steps on the data.
At the end, use Step Functions to connect the components and establish a smooth workflow that coordinates the running of each step.
About the Authors
 Stephen Randolph is a Senior Partner Solutions Architect at Amazon Web Services (AWS). He enables and supports Global Systems Integrator (GSI) partners on the latest AWS technology as they develop industry solutions to solve business challenges. Stephen is especially passionate about Security and Generative AI, and helping customers and partners architect secure, efficient, and innovative solutions on AWS.
Stephen Randolph is a Senior Partner Solutions Architect at Amazon Web Services (AWS). He enables and supports Global Systems Integrator (GSI) partners on the latest AWS technology as they develop industry solutions to solve business challenges. Stephen is especially passionate about Security and Generative AI, and helping customers and partners architect secure, efficient, and innovative solutions on AWS.
 Bhajandeep Singh has served as the AWS AI/ML Center of Excellence Head at Wipro Technologies, leading customer engagements to deliver data analytics and AI solutions. He holds the AWS AI/ML Specialty certification and authors technical blogs on AI/ML services and solutions. With experience of leading AWS AI/ML solutions across industries, Bhajandeep has enabled clients to maximize the value of AWS AI/ML services through his expertise and leadership.
Bhajandeep Singh has served as the AWS AI/ML Center of Excellence Head at Wipro Technologies, leading customer engagements to deliver data analytics and AI solutions. He holds the AWS AI/ML Specialty certification and authors technical blogs on AI/ML services and solutions. With experience of leading AWS AI/ML solutions across industries, Bhajandeep has enabled clients to maximize the value of AWS AI/ML services through his expertise and leadership.
 Ajay Vishwakarma is an ML engineer for the AWS wing of Wipro’s AI solution practice. He has good experience in building BYOM solution for custom algorithm in SageMaker, end to end ETL pipeline deployment, building chatbots using Lex, Cross account QuickSight resource sharing and building CloudFormation templates for deployments. He likes exploring AWS taking every customers problem as a challenge to explore more and provide solutions to them.
Ajay Vishwakarma is an ML engineer for the AWS wing of Wipro’s AI solution practice. He has good experience in building BYOM solution for custom algorithm in SageMaker, end to end ETL pipeline deployment, building chatbots using Lex, Cross account QuickSight resource sharing and building CloudFormation templates for deployments. He likes exploring AWS taking every customers problem as a challenge to explore more and provide solutions to them.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/modernizing-data-science-lifecycle-management-with-aws-and-wipro/

