La creazione di modelli di base (FM) richiede la creazione, la manutenzione e l'ottimizzazione di cluster di grandi dimensioni per addestrare modelli con decine o centinaia di miliardi di parametri su grandi quantità di dati. Creare un ambiente resiliente in grado di gestire guasti e cambiamenti ambientali senza perdere giorni o settimane di progresso nella formazione del modello è una sfida operativa che richiede l'implementazione della scalabilità dei cluster, del monitoraggio proattivo dello stato, del checkpoint del lavoro e delle capacità per riprendere automaticamente la formazione in caso di guasti o problemi. .
Siamo entusiasti di condividerlo Amazon SageMaker HyperPod è ora generalmente disponibile per abilitare modelli di base di formazione con migliaia di acceleratori fino al 40% più veloci fornendo un ambiente di formazione altamente resiliente ed eliminando al tempo stesso il lavoro pesante indifferenziato coinvolto nella gestione di cluster di formazione su larga scala. Con SageMaker HyperPod, i professionisti dell'apprendimento automatico (ML) possono formare i FM per settimane e mesi senza interruzioni e senza dover affrontare problemi di guasti hardware.
Clienti come Stability AI utilizzano SageMaker HyperPod per addestrare i loro modelli di base, incluso Stable Diffusion.
“In quanto azienda leader nel settore dell’intelligenza artificiale generativa open source, il nostro obiettivo è massimizzare l’accessibilità dell’intelligenza artificiale moderna. Stiamo costruendo modelli di base con decine di miliardi di parametri, che richiedono che l'infrastruttura riesca a scalare in modo ottimale le prestazioni della formazione. Con l'infrastruttura gestita e le librerie di ottimizzazione di SageMaker HyperPod, possiamo ridurre i tempi e i costi di formazione di oltre il 50%. Rende l’addestramento dei nostri modelli più resiliente e performante per costruire più velocemente modelli all’avanguardia”.
– Emad Mostaque, Fondatore e CEO di Stability AI.
Per rendere l'intero ciclo di sviluppo di FM resiliente ai guasti hardware, SageMaker HyperPod ti aiuta a creare cluster, monitorare l'integrità dei cluster, riparare e sostituire al volo i nodi difettosi, salvare checkpoint frequenti e riprendere automaticamente la formazione senza perdere i progressi. Inoltre, SageMaker HyperPod è preconfigurato con Amazon Sage Maker librerie di formazione distribuite, tra cui Libreria per il parallelismo dei dati SageMaker (SMDDP) ed Libreria di parallelismo dei modelli SageMaker (SMP), per migliorare le prestazioni di addestramento FM semplificando la suddivisione dei dati e dei modelli di addestramento in blocchi più piccoli ed elaborandoli in parallelo tra i nodi del cluster, utilizzando al tempo stesso l'infrastruttura di calcolo e di rete del cluster. SageMaker HyperPod integra Slurm Workload Manager per l'orchestrazione dei cluster e dei lavori di formazione.
Panoramica di Slurm Workload Manager
slurm, precedentemente noto come Simple Linux Utility for Resource Management, è un pianificatore di lavori per l'esecuzione di lavori su un cluster di elaborazione distribuito. Fornisce inoltre un framework per l'esecuzione di lavori paralleli utilizzando il file Libreria di comunicazione collettiva NVIDIA (NCCL) or Interfaccia per il passaggio dei messaggi (MPI) standard. Slurm è un popolare sistema di gestione delle risorse cluster open source ampiamente utilizzato dal calcolo ad alte prestazioni (HPC) e dai carichi di lavoro di formazione AI e FM generativi. SageMaker HyperPod fornisce un modo semplice per diventare subito operativi con un cluster Slurm in pochi minuti.
Quello che segue è un diagramma architettonico di alto livello di come gli utenti interagiscono con SageMaker HyperPod e di come i vari componenti del cluster interagiscono tra loro e con altri servizi AWS, come Amazon FSx per Lustre ed Servizio di archiviazione semplice Amazon (Amazon S3).

I lavori Slurm vengono inviati tramite comandi sulla riga di comando. I comandi per eseguire i lavori Slurm sono srun ed sbatch. srun il comando esegue il processo di training in modalità interattiva e di blocco e sbatch viene eseguito in modalità di elaborazione batch e non bloccante. srun viene utilizzato principalmente per eseguire lavori immediati, mentre sbatch può essere utilizzato per esecuzioni successive di lavori.
Per informazioni su ulteriori comandi e configurazioni Slurm, fare riferimento al file Documentazione di Slurm Workload Manager.
Funzionalità di ripristino automatico e di guarigione
Una delle nuove funzionalità di SageMaker HyperPod è la possibilità di riprendere automaticamente i tuoi lavori. In precedenza, quando un nodo di lavoro falliva durante l'esecuzione di un lavoro di training o di perfezionamento, spettava all'utente verificare lo stato del lavoro, riavviare il lavoro dall'ultimo checkpoint e continuare a monitorare il lavoro durante l'intera esecuzione. Con lavori di formazione o lavori di messa a punto che devono essere eseguiti per giorni, settimane o addirittura mesi alla volta, ciò diventa costoso a causa del sovraccarico amministrativo aggiuntivo dell'utente che deve spendere cicli per monitorare e mantenere il lavoro nel caso in cui un arresti anomali del nodo, nonché il costo dei tempi di inattività di costose istanze di calcolo accelerate.
SageMaker HyperPod affronta la resilienza del lavoro utilizzando controlli di integrità automatizzati, sostituzione dei nodi e ripristino dei lavori. I lavori Slurm in SageMaker HyperPod vengono monitorati utilizzando un plug-in Slurm personalizzato SageMaker utilizzando il file Quadro SPANK. Quando un processo di formazione fallisce, SageMaker HyperPod ispezionerà l'integrità del cluster attraverso una serie di controlli sanitari. Se nel cluster viene trovato un nodo difettoso, SageMaker HyperPod rimuoverà automaticamente il nodo dal cluster, lo sostituirà con un nodo integro e riavvierà il processo di training. Quando si utilizza il checkpoint nei lavori di training, qualsiasi lavoro interrotto o non riuscito può riprendere dall'ultimo checkpoint.
Panoramica della soluzione
Per distribuire il tuo SageMaker HyperPod, devi prima preparare il tuo ambiente configurando il tuo Cloud privato virtuale di Amazon (Amazon VPC) e gruppi di sicurezza, distribuendo servizi di supporto come FSx for Lustre nel tuo VPC e pubblicando gli script del ciclo di vita Slurm su un bucket S3. Quindi distribuisci e configuri il tuo SageMaker HyperPod e ti connetti al nodo principale per iniziare i tuoi lavori di formazione.
Prerequisiti
Prima di creare il tuo SageMaker HyperPod, devi prima configurare il tuo VPC, creare un file system FSx for Lustre e stabilire un bucket S3 con gli script del ciclo di vita del cluster desiderati. È inoltre necessaria l'ultima versione di Interfaccia della riga di comando di AWS (AWS CLI) e il plug-in CLI installato per Gestore sessioni AWS, una capacità di Gestore di sistemi AWS.
SageMaker HyperPod è completamente integrato con il tuo VPC. Per informazioni sulla creazione di un nuovo VPC, consulta Crea un VPC predefinito or Crea un VPC. Per consentire una connessione continua con le massime prestazioni tra le risorse, devi creare tutte le risorse nella stessa regione e zona di disponibilità, oltre a garantire che le regole del gruppo di sicurezza associato consentano la connessione tra le risorse del cluster.
Avanti, tu creare un file system FSx for Lustre. Questo servirà come file system ad alte prestazioni da utilizzare durante la nostra formazione sul modello. Assicurati che FSx for Lustre e i gruppi di sicurezza del cluster consentano la comunicazione in entrata e in uscita tra le risorse del cluster e il file system FSx for Lustre.
Per configurare gli script del ciclo di vita del cluster, che vengono eseguiti quando si verificano eventi come una nuova istanza del cluster, crea un bucket S3 e quindi copia e facoltativamente personalizza gli script del ciclo di vita predefiniti. Per questo esempio, memorizziamo tutti gli script del ciclo di vita in un prefisso bucket di lifecycle-scripts.
Innanzitutto, scarichi gli script del ciclo di vita di esempio dal file Repository GitHub. Dovresti personalizzarli per adattarli ai comportamenti del cluster desiderati.
Successivamente, crea un bucket S3 per archiviare gli script del ciclo di vita personalizzati.
Successivamente, copia gli script del ciclo di vita predefiniti dalla directory locale al bucket e al prefisso desiderati utilizzando aws s3 sync:
Infine, per configurare il client per la connessione semplificata al nodo head del cluster, dovresti installare o aggiornare l'AWS CLI e installare il Plug-in CLI di AWS Session Manager per consentire connessioni terminali interattive per amministrare il cluster ed eseguire lavori di formazione.
Puoi creare un cluster SageMaker HyperPod con le risorse disponibili su richiesta o richiedendo una prenotazione di capacità con SageMaker. Per creare una prenotazione di capacità, crea una richiesta di aumento della quota per prenotare specifici tipi di istanze di calcolo e allocazione di capacità nel dashboard Quote di servizio.
Configura il tuo cluster di formazione
Per creare il tuo cluster SageMaker HyperPod, completa i seguenti passaggi:
- Sulla console di SageMaker, scegli Gestione dei cluster per Cluster HyperPod nel pannello di navigazione.
- Scegli Crea un cluster.
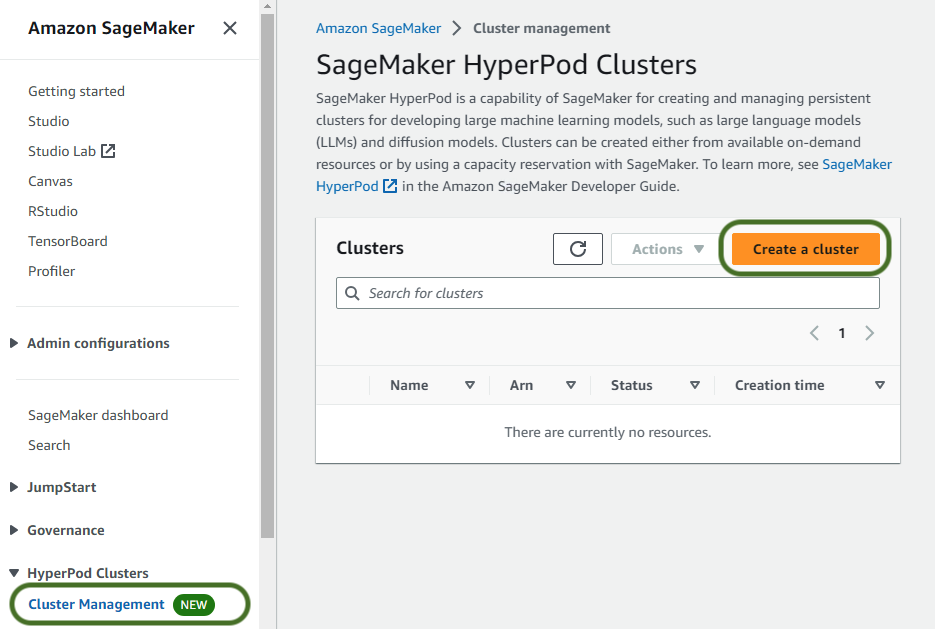
- Fornire un nome cluster e facoltativamente eventuali tag da applicare alle risorse cluster, quindi scegliere Avanti.
- Seleziona Crea gruppo di istanze e specifica il nome del gruppo di istanze, il tipo di istanza necessario, la quantità di istanze desiderate, il bucket S3 e il percorso del prefisso in cui hai copiato in precedenza gli script del ciclo di vita del cluster.
Si consiglia di avere gruppi di istanze diversi per i nodi controller utilizzati per amministrare il cluster e inviare lavori e i nodi di lavoro utilizzati per eseguire lavori di training utilizzando istanze di calcolo accelerate. Facoltativamente, puoi configurare un gruppo di istanze aggiuntivo per i nodi di accesso.
- Per prima cosa crei il gruppo di istanze del controller, che includerà il nodo head del cluster.
- Per questo gruppo di istanze Gestione dell'identità e dell'accesso di AWS (IAM) ruolo, scegli Crea un nuovo ruolo e specifica eventuali bucket S3 a cui desideri che le istanze del cluster nel gruppo di istanze abbiano accesso.
Per impostazione predefinita, al ruolo generato verrà concesso l'accesso di sola lettura ai bucket specificati.
- Scegli Crea ruolo.
- Immettere il nome dello script da eseguire alla creazione di ogni istanza nel prompt dello script al momento della creazione. In questo esempio viene richiamato lo script on-create
on_create.sh.
- Scegli Risparmi.
- Scegli Crea gruppo di istanze per creare il tuo gruppo di istanze di lavoro.
- Fornisci tutti i dettagli richiesti, incluso il tipo di istanza e la quantità desiderata.
Questo esempio utilizza quattro istanze accelerate ml.trn1.32xl per eseguire il nostro lavoro di formazione. Puoi utilizzare lo stesso ruolo IAM di prima o personalizzare il ruolo per le istanze di lavoro. Allo stesso modo, puoi utilizzare script del ciclo di vita in creazione diversi per questo gruppo di istanze di lavoro rispetto al gruppo di istanze precedente.
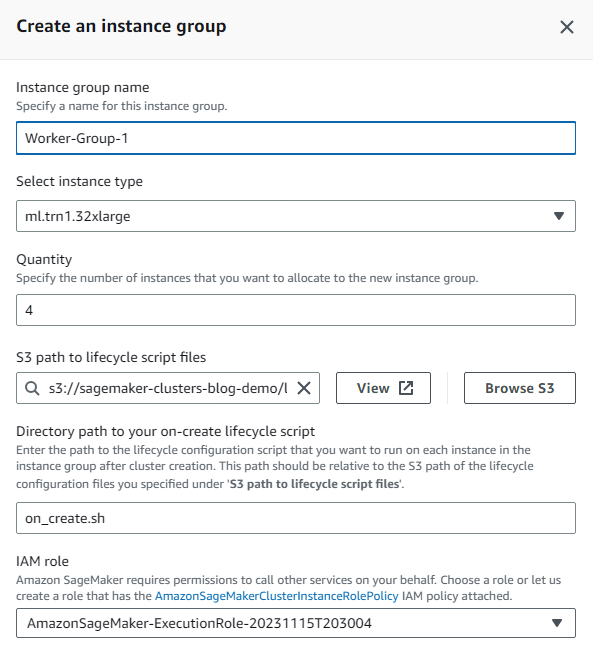
- Scegli Avanti procedere.
- Scegli il VPC, la sottorete e i gruppi di sicurezza desiderati per le tue istanze del cluster.
Ospitiamo le istanze del cluster in una singola zona di disponibilità e sottorete per garantire una bassa latenza.
Tieni presente che se accederai frequentemente ai dati S3, ti consigliamo di creare un endpoint VPC associato alla tabella di routing della sottorete privata per ridurre eventuali costi di trasferimento dei dati.
- Scegli Avanti.

- Esamina il riepilogo dei dettagli del cluster, quindi scegli Invio.
In alternativa, per creare il tuo SageMaker HyperPod utilizzando AWS CLI, personalizza prima i parametri JSON utilizzati per creare il cluster:
Quindi utilizzare il comando seguente per creare il cluster utilizzando gli input forniti:
Esegui il tuo primo lavoro di addestramento con Llama 2
Tieni presente che l'uso del modello Llama 2 è regolato dalla licenza Meta. Per scaricare i pesi del modello e il tokenizzatore, visitare il file sito web e accettare la licenza prima di richiedere l'accesso Il sito web di Hugging Face di Meta.
Dopo che il cluster è in esecuzione, accedi con Session Manager utilizzando l'ID del cluster, il nome del gruppo di istanze e l'ID dell'istanza. Utilizza il comando seguente per visualizzare i dettagli del cluster:
Prendi nota dell'ID del cluster incluso nell'ARN del cluster nella risposta.
Utilizza il comando seguente per recuperare il nome del gruppo di istanze e l'ID istanza necessari per accedere al cluster.
Prendi nota del file InstanceGroupName e la InstanceId nella risposta poiché questi verranno utilizzati per connettersi all'istanza con Session Manager.
Ora utilizzi Session Manager per accedere al nodo head o a uno dei nodi di accesso ed eseguire il processo di formazione:
Successivamente, prepareremo l'ambiente e scaricheremo Llama 2 e il set di dati RedPajama. Per il codice completo e una procedura dettagliata, seguire le istruzioni sul file Una certa formazione distribuita Repository GitHub.
Seguire i passaggi dettagliati nel 2.test_cases/8.neuronx-nemo-megatron/README.md file. Dopo aver seguito i passaggi per preparare l'ambiente, preparare il modello, scaricare e tokenizzare il set di dati e precompilare il modello, è necessario modificare il 6.pretrain-model.sh script e il sbatch comando di invio del lavoro per includere un parametro che ti consentirà di sfruttare la funzionalità di ripristino automatico di SageMaker HyperPod.
Modificare il sbatch linea per assomigliare alla seguente:
Dopo aver inviato il lavoro, riceverai un JobID che puoi utilizzare per verificare lo stato del lavoro utilizzando il seguente codice:
Inoltre, è possibile monitorare il lavoro seguendo il registro di output del lavoro utilizzando il seguente codice:
ripulire
Per eliminare il cluster SageMaker HyperPod, utilizza la console SageMaker o il seguente comando AWS CLI:
Conclusione
Questo post ti ha mostrato come preparare il tuo ambiente AWS, distribuire il tuo primo cluster SageMaker HyperPod e addestrare un modello Llama 7 da 2 miliardi di parametri. SageMaker HyperPod è oggi generalmente disponibile nelle regioni delle Americhe (Virginia settentrionale, Ohio e Oregon), dell'Asia Pacifico (Singapore, Sydney e Tokyo) e dell'Europa (Francoforte, Irlanda e Stoccolma). Possono essere distribuiti tramite la console SageMaker, AWS CLI e gli SDK AWS e supportano le famiglie di istanze p4d, p4de, p5, trn1, inf2, g5, c5, c5n, m5 e t3.
Per ulteriori informazioni su SageMaker HyperPod, visitare Amazon SageMaker HyperPod.
Circa gli autori
 Brad Doran è Senior Technical Account Manager presso Amazon Web Services, specializzato nell'intelligenza artificiale generativa. È responsabile della risoluzione delle sfide ingegneristiche per i clienti dell'intelligenza artificiale generativa nel segmento di mercato aziendale nativo digitale. Proviene da un background di sviluppo di infrastrutture e software e attualmente sta portando avanti studi di dottorato e ricerca nel campo dell'intelligenza artificiale e dell'apprendimento automatico.
Brad Doran è Senior Technical Account Manager presso Amazon Web Services, specializzato nell'intelligenza artificiale generativa. È responsabile della risoluzione delle sfide ingegneristiche per i clienti dell'intelligenza artificiale generativa nel segmento di mercato aziendale nativo digitale. Proviene da un background di sviluppo di infrastrutture e software e attualmente sta portando avanti studi di dottorato e ricerca nel campo dell'intelligenza artificiale e dell'apprendimento automatico.
 Keita Watanabe è Senior GenAI Specialist Solutions Architect presso Amazon Web Services, dove aiuta a sviluppare soluzioni di machine learning utilizzando progetti OSS come Slurm e Kubernetes. Il suo background è nella ricerca e nello sviluppo dell'apprendimento automatico. Prima di unirsi ad AWS, Keita ha lavorato nel settore dell'e-commerce come ricercatore sviluppando sistemi di recupero di immagini per la ricerca di prodotti. Keita ha conseguito un dottorato in scienze presso l'Università di Tokyo.
Keita Watanabe è Senior GenAI Specialist Solutions Architect presso Amazon Web Services, dove aiuta a sviluppare soluzioni di machine learning utilizzando progetti OSS come Slurm e Kubernetes. Il suo background è nella ricerca e nello sviluppo dell'apprendimento automatico. Prima di unirsi ad AWS, Keita ha lavorato nel settore dell'e-commerce come ricercatore sviluppando sistemi di recupero di immagini per la ricerca di prodotti. Keita ha conseguito un dottorato in scienze presso l'Università di Tokyo.
 Justin Pirtle è Principal Solutions Architect presso Amazon Web Services. Fornisce regolarmente consulenza ai clienti dell'intelligenza artificiale generativa nella progettazione, implementazione e ridimensionamento della loro infrastruttura. È un relatore regolare alle conferenze AWS, tra cui re:Invent, nonché ad altri eventi AWS. Justin ha conseguito una laurea in Management Information Systems presso l'Università del Texas ad Austin e un master in Ingegneria del software presso l'Università di Seattle.
Justin Pirtle è Principal Solutions Architect presso Amazon Web Services. Fornisce regolarmente consulenza ai clienti dell'intelligenza artificiale generativa nella progettazione, implementazione e ridimensionamento della loro infrastruttura. È un relatore regolare alle conferenze AWS, tra cui re:Invent, nonché ad altri eventi AWS. Justin ha conseguito una laurea in Management Information Systems presso l'Università del Texas ad Austin e un master in Ingegneria del software presso l'Università di Seattle.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/introducing-amazon-sagemaker-hyperpod-to-train-foundation-models-at-scale/

