I recenti sviluppi nell’apprendimento automatico (ML) hanno portato a modelli sempre più grandi, alcuni dei quali richiedono centinaia di miliardi di parametri. Sebbene siano più potenti, l’addestramento e l’inferenza su tali modelli richiedono risorse computazionali significative. Nonostante la disponibilità di librerie di formazione distribuite avanzate, è normale che i lavori di formazione e inferenza necessitino di centinaia di acceleratori (GPU o chip ML appositamente realizzati come AWSTrainium ed AWS Inferenza), e quindi decine o centinaia di casi.
In tali ambienti distribuiti, l'osservabilità di entrambe le istanze e dei chip ML diventa fondamentale per la messa a punto delle prestazioni del modello e l'ottimizzazione dei costi. Le metriche consentono ai team di comprendere il comportamento del carico di lavoro e ottimizzare l'allocazione e l'utilizzo delle risorse, diagnosticare anomalie e aumentare l'efficienza complessiva dell'infrastruttura. Per i data scientist, l’utilizzo e la saturazione dei chip ML sono rilevanti anche per la pianificazione della capacità.
Questo post ti guida attraverso Modello di osservabilità open source per AWS Inferentia, che mostra come monitorare le prestazioni dei chip ML, utilizzati in un Servizio Amazon Elastic Kubernetes (Amazon EKS), con nodi del piano dati basati su Cloud di calcolo elastico di Amazon (Amazon EC2) istanze di tipo INF1 ed INF2.
Il modello fa parte del Acceleratore di osservabilità di AWS CDK, una serie di moduli basati su opinioni che ti aiutano a impostare l'osservabilità per i cluster Amazon EKS. AWS CDK Observability Accelerator è organizzato attorno a modelli, che sono unità riutilizzabili per la distribuzione di più risorse. L'insieme di modelli di osservabilità open source con cui è possibile osservare gli strumenti Grafana gestita da Amazon cruscotti, un Distribuzione AWS per OpenTelemetry collector per raccogliere metriche e Servizio gestito da Amazon per Prometheus per conservarli.
Panoramica della soluzione
Il diagramma seguente illustra l'architettura della soluzione.

Questa soluzione distribuisce un cluster Amazon EKS con un gruppo di nodi che include istanze Inf1.
Il tipo AMI del gruppo di nodi è AL2_x86_64_GPU, che utilizza il AMI Amazon Linux accelerata ottimizzata per Amazon EKS. Oltre alla configurazione AMI standard ottimizzata per Amazon EKS, l'AMI accelerata include Tempo di esecuzione di NeuronX.
Per accedere ai chip ML da Kubernetes, il modello distribuisce il file Neurone AWS plug-in del dispositivo.
I parametri vengono esposti ad Amazon Managed Service per Prometheus da neuron-monitor DaemonSet, che distribuisce un contenitore minimo, con il file Strumenti neuronali installato. Nello specifico, il neuron-monitor DaemonSet esegue il file neuron-monitor comando convogliato nel file neuron-monitor-prometheus.py script complementare (entrambi i comandi fanno parte del contenitore):
Il comando utilizza i seguenti componenti:
neuron-monitorraccoglie parametri e statistiche dalle applicazioni Neuron in esecuzione sul sistema e trasmette i dati raccolti a stdout in Formato JSONneuron-monitor-prometheus.pymappa ed espone i dati di telemetria dal formato JSON al formato compatibile con Prometheus
I dati vengono visualizzati in Amazon Managed Grafana tramite la dashboard corrispondente.
Il resto della configurazione per raccogliere e visualizzare i parametri con Amazon Managed Service for Prometheus e Amazon Managed Grafana è simile a quello utilizzato in altri modelli basati su open source, inclusi nel AWS Observability Accelerator for CDK Archivio GitHub.
Prerequisiti
Per completare i passaggi descritti in questo post è necessario quanto segue:
Crea l'ambiente
Completa i seguenti passaggi per configurare il tuo ambiente:
- Apri una finestra di terminale ed esegui i seguenti comandi:
- Recupera gli ID dello spazio di lavoro di qualsiasi spazio di lavoro Amazon Managed Grafana esistente:
Quello che segue è il nostro output di esempio:
- Assegnare i valori di
idedendpointalle seguenti variabili d'ambiente:
COA_AMG_ENDPOINT_URL deve includere https://.
- Crea una chiave API Grafana dall'area di lavoro Amazon Managed Grafana:
- Imposta un segreto in Gestore di sistemi AWS:
Al segreto si accederà dal componente aggiuntivo External Secrets e verrà reso disponibile come segreto Kubernetes nativo nel cluster EKS.
Avvia l'ambiente AWS CDK
Il primo passaggio per qualsiasi distribuzione AWS CDK è il bootstrap dell'ambiente. Usi il cdk bootstrap comando nell'AWS CDK CLI per preparare l'ambiente (una combinazione di account AWS e regione AWS) con le risorse richieste da AWS CDK per eseguire distribuzioni in tale ambiente. Il bootstrap di AWS CDK è necessario per ogni combinazione di account e regione, quindi se hai già avviato AWS CDK in una regione, non è necessario ripetere il processo di bootstrap.
Distribuisci la soluzione
Completare i seguenti passaggi per distribuire la soluzione:
- Clona il file cdk-aws-osservabilità-acceleratore repository e installare i pacchetti delle dipendenze. Questo repository contiene codice AWS CDK v2 scritto in TypeScript.
Si prevede che le impostazioni effettive per i file JSON del dashboard Grafana siano specificate nel contesto AWS CDK. È necessario aggiornare context nel cdk.json file, situato nella directory corrente. La posizione del dashboard è specificata da fluxRepository.values.GRAFANA_NEURON_DASH_URL parametro, e neuronNodeGroup viene utilizzato per impostare il tipo di istanza, il numero e Negozio di blocchi elastici di Amazon (Amazon EBS) utilizzata per i nodi.
- Inserisci il seguente snippet in
cdk.json, sostituendocontext:
Puoi sostituire il tipo di istanza Inf1 con Inf2 e modificare le dimensioni secondo necessità. Per verificare la disponibilità nella regione selezionata, esegui il comando seguente (amend Values come meglio credi):
- Installa le dipendenze del progetto:
- Esegui i seguenti comandi per distribuire il modello di osservabilità open source:
Convalida la soluzione
Completare i seguenti passaggi per convalidare la soluzione:
- Corri il
update-kubeconfigcomando. Dovresti essere in grado di ottenere il comando dal messaggio di output del comando precedente:
- Verifica le risorse che hai creato:
Lo screenshot seguente mostra il nostro output di esempio.

- Assicurarsi che la
neuron-device-plugin-daemonsetDaemonSet è in esecuzione:
Quello che segue è il nostro output atteso:
- Conferma che il
neuron-monitorDaemonSet è in esecuzione:
Quello che segue è il nostro output atteso:
- Per verificare che i dispositivi e i core Neuron siano visibili, eseguire il file
neuron-lsedneuron-topcomandi provenienti, ad esempio, dal pod del monitor neuronale (puoi ottenere il nome del pod dall'output dikubectl get pods -A):
Lo screenshot seguente mostra l'output previsto.

Lo screenshot seguente mostra l'output previsto.
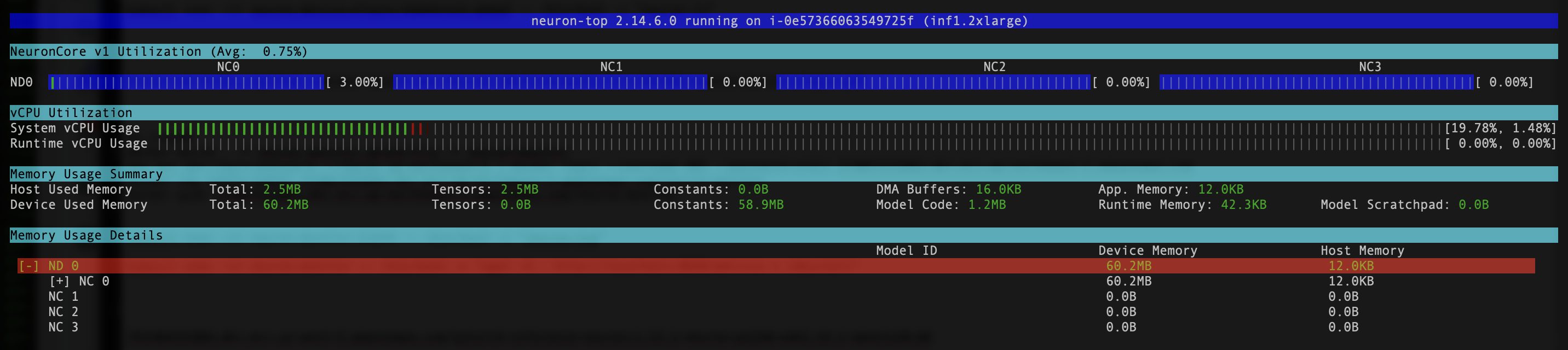
Visualizza i dati utilizzando la dashboard di Grafana Neuron
Accedi al tuo spazio di lavoro Amazon Managed Grafana e vai al file Cruscotti pannello. Dovresti vedere una dashboard denominata Neurone/Monitor.
Per vedere alcune metriche interessanti sulla dashboard di Grafana, applichiamo il seguente manifest:
Questo è un carico di lavoro di esempio che compila il file modello torchvision ResNet50 ed esegue l'inferenza ripetitiva in un ciclo per generare dati di telemetria.
Per verificare che il pod sia stato distribuito correttamente, esegui il codice seguente:
Dovresti vedere un pod con nome pytorch-inference-resnet50.
Dopo alcuni minuti, esaminando il Neurone/Monitor dashboard, dovresti vedere i parametri raccolti simili ai seguenti screenshot.




Grafana Operator e Flux lavorano sempre insieme per sincronizzare le tue dashboard con Git. Se elimini le tue dashboard per sbaglio, verrà effettuato nuovamente il provisioning automaticamente.
ripulire
Puoi eliminare l'intero stack AWS CDK con il comando seguente:
Conclusione
In questo post, ti abbiamo mostrato come introdurre l'osservabilità, con strumenti open source, in un cluster EKS dotato di un piano dati che esegue istanze EC2 Inf1. Abbiamo iniziato selezionando l'AMI accelerata ottimizzata per Amazon EKS per i nodi del piano dati, che include il runtime del container Neuron, fornendo l'accesso ai dispositivi AWS Inferentia e Trainium Neuron. Quindi, per esporre i core e i dispositivi Neuron a Kubernetes, abbiamo distribuito il plug-in del dispositivo Neuron. L'effettiva raccolta e mappatura dei dati di telemetria in un formato compatibile con Prometheus è stata ottenuta tramite neuron-monitor ed neuron-monitor-prometheus.py. I parametri sono stati ottenuti da Amazon Managed Service per Prometheus e visualizzati nel dashboard Neuron di Amazon Managed Grafana.
Ti consigliamo di esplorare ulteriori modelli di osservabilità nel file AWS Observability Accelerator per CDK Deposito GitHub. Per saperne di più su Neuron, fare riferimento a Documentazione di AWS Neuron.
L'autore
 Riccardo Freschi è Sr. Solutions Architect presso AWS, specializzato nella modernizzazione delle applicazioni. Lavora a stretto contatto con partner e clienti per aiutarli a trasformare i loro ambienti IT nel loro percorso verso il cloud AWS effettuando il refactoring delle applicazioni esistenti e creandone di nuove.
Riccardo Freschi è Sr. Solutions Architect presso AWS, specializzato nella modernizzazione delle applicazioni. Lavora a stretto contatto con partner e clienti per aiutarli a trasformare i loro ambienti IT nel loro percorso verso il cloud AWS effettuando il refactoring delle applicazioni esistenti e creandone di nuove.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/open-source-observability-for-aws-inferentia-nodes-within-amazon-eks-clusters/

