AI generativa le applicazioni guidate da modelli fondamentali (FM) stanno consentendo alle organizzazioni di ottenere un valore aziendale significativo in termini di esperienza del cliente, produttività, ottimizzazione dei processi e innovazioni. Tuttavia, l’adozione di questi FM implica affrontare alcune sfide chiave, tra cui risultati di qualità, privacy dei dati, sicurezza, integrazione con i dati dell’organizzazione, costi e competenze da fornire.
In questo post esploriamo i diversi approcci che puoi adottare quando crei applicazioni che utilizzano l'intelligenza artificiale generativa. Con il rapido progresso dei FM, è un momento entusiasmante per sfruttare il loro potere, ma è anche fondamentale capire come utilizzarli correttamente per ottenere risultati aziendali. Forniamo una panoramica dei principali approcci all'intelligenza artificiale generativa, tra cui il prompt engineering, il Retrieval Augmented Generation (RAG) e la personalizzazione del modello. Quando applichiamo questi approcci, discutiamo considerazioni chiave su potenziali allucinazioni, integrazione con dati aziendali, qualità dell'output e costi. Alla fine, avrai solide linee guida e un utile diagramma di flusso per determinare il metodo migliore per sviluppare le tue applicazioni basate su FM, basate su esempi di vita reale. Che si tratti di creare un chatbot o uno strumento di riepilogo, puoi modellare potenti FM in base alle tue esigenze.
IA generativa con AWS
L’emergere dei FM sta creando sia opportunità che sfide per le organizzazioni che desiderano utilizzare queste tecnologie. Una sfida chiave è garantire risultati coerenti e di alta qualità che siano in linea con le esigenze aziendali, piuttosto che allucinazioni o false informazioni. Le organizzazioni devono inoltre gestire attentamente la privacy dei dati e i rischi per la sicurezza derivanti dal trattamento dei dati proprietari con i FM. Le competenze necessarie per integrare, personalizzare e convalidare adeguatamente i FM all’interno dei sistemi e dei dati esistenti scarseggiano. La creazione di modelli linguistici di grandi dimensioni (LLM) da zero o la personalizzazione di modelli preaddestrati richiede notevoli risorse di calcolo, data scientist esperti e mesi di lavoro di ingegneria. Il solo costo computazionale può facilmente raggiungere i milioni di dollari per addestrare modelli con centinaia di miliardi di parametri su enormi set di dati utilizzando migliaia di GPU o TPU. Oltre all'hardware, la pulizia e l'elaborazione dei dati, la progettazione dell'architettura del modello, l'ottimizzazione degli iperparametri e lo sviluppo della pipeline di formazione richiedono competenze specializzate in machine learning (ML). Il processo end-to-end è complesso, dispendioso in termini di tempo e proibitivamente costoso per la maggior parte delle organizzazioni senza le infrastrutture necessarie e gli investimenti in talenti. Le organizzazioni che non riescono ad affrontare adeguatamente questi rischi possono affrontare impatti negativi sulla reputazione del marchio, sulla fiducia dei clienti, sulle operazioni e sui ricavi.
Roccia Amazzonica è un servizio completamente gestito che offre una scelta di Foundation Model (FM) ad alte prestazioni di aziende leader nel settore dell'intelligenza artificiale come AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI e Amazon tramite un'unica API. Con l'esperienza serverless di Amazon Bedrock, puoi iniziare rapidamente, personalizzare privatamente i FM con i tuoi dati e integrarli e distribuirli nelle tue applicazioni utilizzando gli strumenti AWS senza dover gestire alcuna infrastruttura. Amazon Bedrock è idoneo HIPAA e puoi utilizzare Amazon Bedrock in conformità con il GDPR. Con Amazon Bedrock, i tuoi contenuti non vengono utilizzati per migliorare i modelli di base e non vengono condivisi con fornitori di modelli di terze parti. I tuoi dati in Amazon Bedrock sono sempre crittografati in transito e inattivi e, facoltativamente, puoi crittografare le risorse utilizzando le tue chiavi. Puoi usare Collegamento privato AWS con Amazon Bedrock per stabilire una connettività privata tra i tuoi FM e il tuo VPC senza esporre il tuo traffico a Internet. Con Basi di conoscenza per Amazon Bedrock, puoi fornire a FM e agenti informazioni contestuali dalle origini dati private della tua azienda affinché RAG fornisca risposte più pertinenti, accurate e personalizzate. Puoi personalizzare privatamente gli FM con i tuoi dati attraverso un'interfaccia visiva senza scrivere alcun codice. Essendo un servizio completamente gestito, Amazon Bedrock offre agli sviluppatori un'esperienza semplice per lavorare con un'ampia gamma di FM ad alte prestazioni.
Lanciato nel 2017, Amazon Sage Maker è un servizio completamente gestito che semplifica la creazione, il training e la distribuzione di modelli ML. Sempre più clienti stanno creando i propri FM utilizzando SageMaker, tra cui Stability AI, AI21 Labs, Hugging Face, Perplexity AI, Hippocratic AI, LG AI Research e Technology Innovation Institute. Per aiutarti a iniziare rapidamente, JumpStart di Amazon SageMaker offre un hub ML in cui è possibile esplorare, addestrare e distribuire un'ampia selezione di FM pubblici, come modelli Mistral, modelli LightOn, RedPajama, Mosiac MPT-7B, FLAN-T5/UL2, GPT-J-6B/Neox-20B e Bloom/BloomZ, utilizzando strumenti SageMaker appositamente creati come esperimenti e pipeline.
Approcci comuni all’intelligenza artificiale generativa
In questa sezione, discutiamo approcci comuni per implementare soluzioni efficaci di intelligenza artificiale generativa. Esploriamo le popolari tecniche di prompt engineering che ti consentono di realizzare attività più complesse e interessanti con i FM. Discuteremo anche di come tecniche come RAG e personalizzazione del modello possano migliorare ulteriormente le capacità dei FM e superare sfide come dati limitati e vincoli computazionali. Con la tecnica giusta, puoi creare soluzioni di intelligenza artificiale generativa potenti e di grande impatto.
Ingegneria rapida
Il prompt engineering è la pratica di progettare attentamente i prompt per sfruttare in modo efficiente le capacità dei FM. Implica l'uso di prompt, ovvero brevi porzioni di testo che guidano il modello a generare risposte più accurate e pertinenti. Con una progettazione tempestiva è possibile migliorare le prestazioni degli FM e renderli più efficaci per una varietà di applicazioni. In questa sezione, esploriamo tecniche come il suggerimento zero-shot e il suggerimento a pochi colpi, che adatta rapidamente i FM a nuovi compiti con solo pochi esempi, e il suggerimento della catena di pensiero, che scompone il ragionamento complesso in passaggi intermedi. Questi metodi dimostrano come l'ingegneria tempestiva possa rendere i FM più efficaci su compiti complessi senza richiedere la riqualificazione del modello.
Suggerimento per lo scatto zero
Una tecnica di prompt zero-shot richiede che i FM generino una risposta senza fornire alcun esempio esplicito del comportamento desiderato, basandosi esclusivamente sulla sua pre-formazione. Lo screenshot seguente mostra un esempio di un prompt zero-shot con il modello Anthropic Claude 2.1 sulla console Amazon Bedrock.
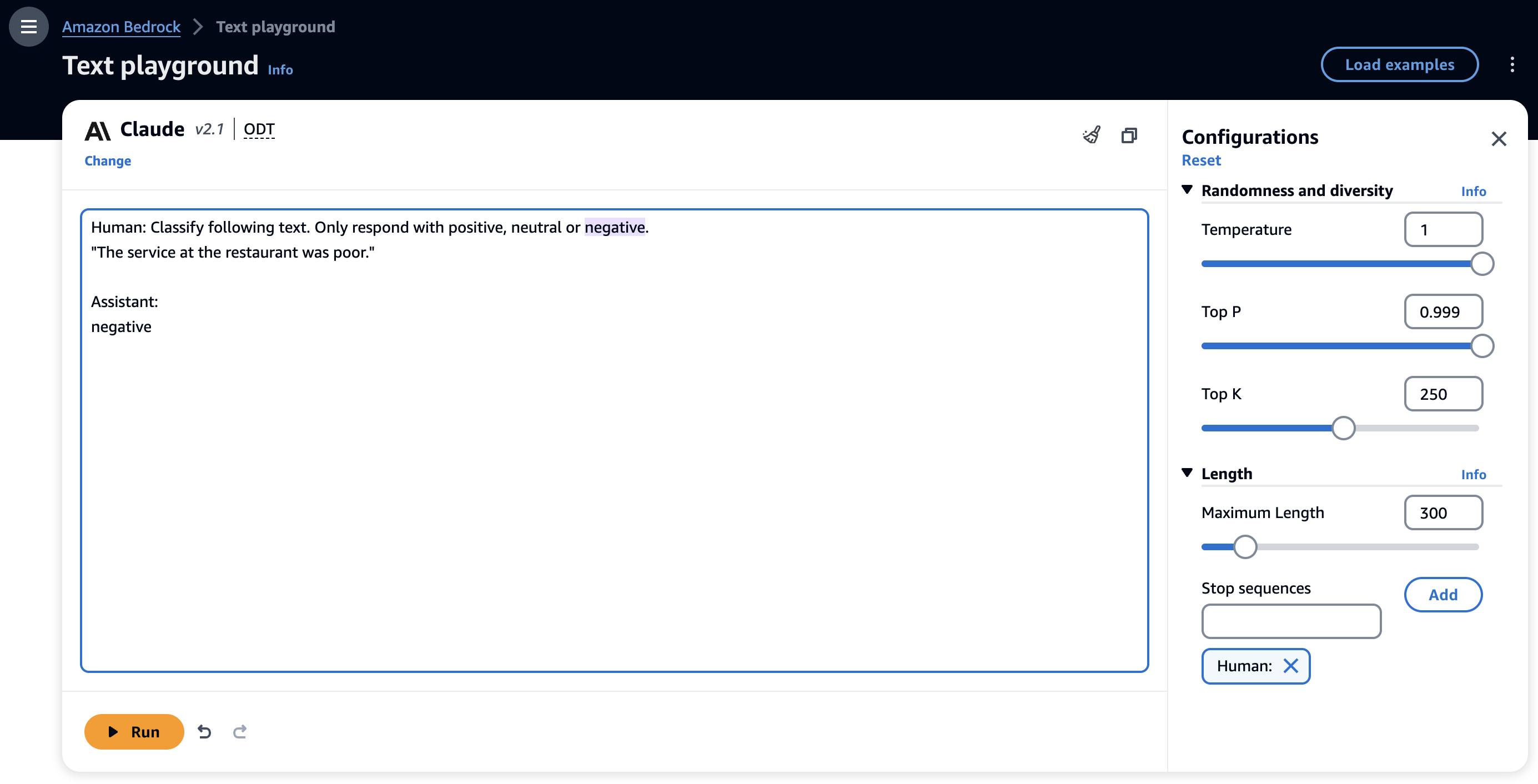
In queste istruzioni non abbiamo fornito alcun esempio. Tuttavia, il modello può comprendere l'attività e generare output appropriato. I prompt zero-shot sono la tecnica di prompt più semplice con cui iniziare quando si valuta un FM per il proprio caso d'uso. Tuttavia, sebbene i FM siano notevoli con i suggerimenti zero-shot, potrebbero non sempre fornire risultati accurati o desiderati per attività più complesse. Quando i suggerimenti zero-shot non sono sufficienti, si consiglia di fornire alcuni esempi nel prompt (prompt pochi-shot).
Suggerimento per pochi colpi
La tecnica dei prompt a pochi colpi consente ai FM di apprendere in contesto dagli esempi nei prompt ed eseguire l'attività in modo più accurato. Con solo pochi esempi è possibile adattare rapidamente i FM a nuovi compiti senza grandi set di formazione e guidarli verso il comportamento desiderato. Di seguito è riportato un esempio di un prompt di pochi scatti con il modello Cohere Command sulla console Amazon Bedrock.
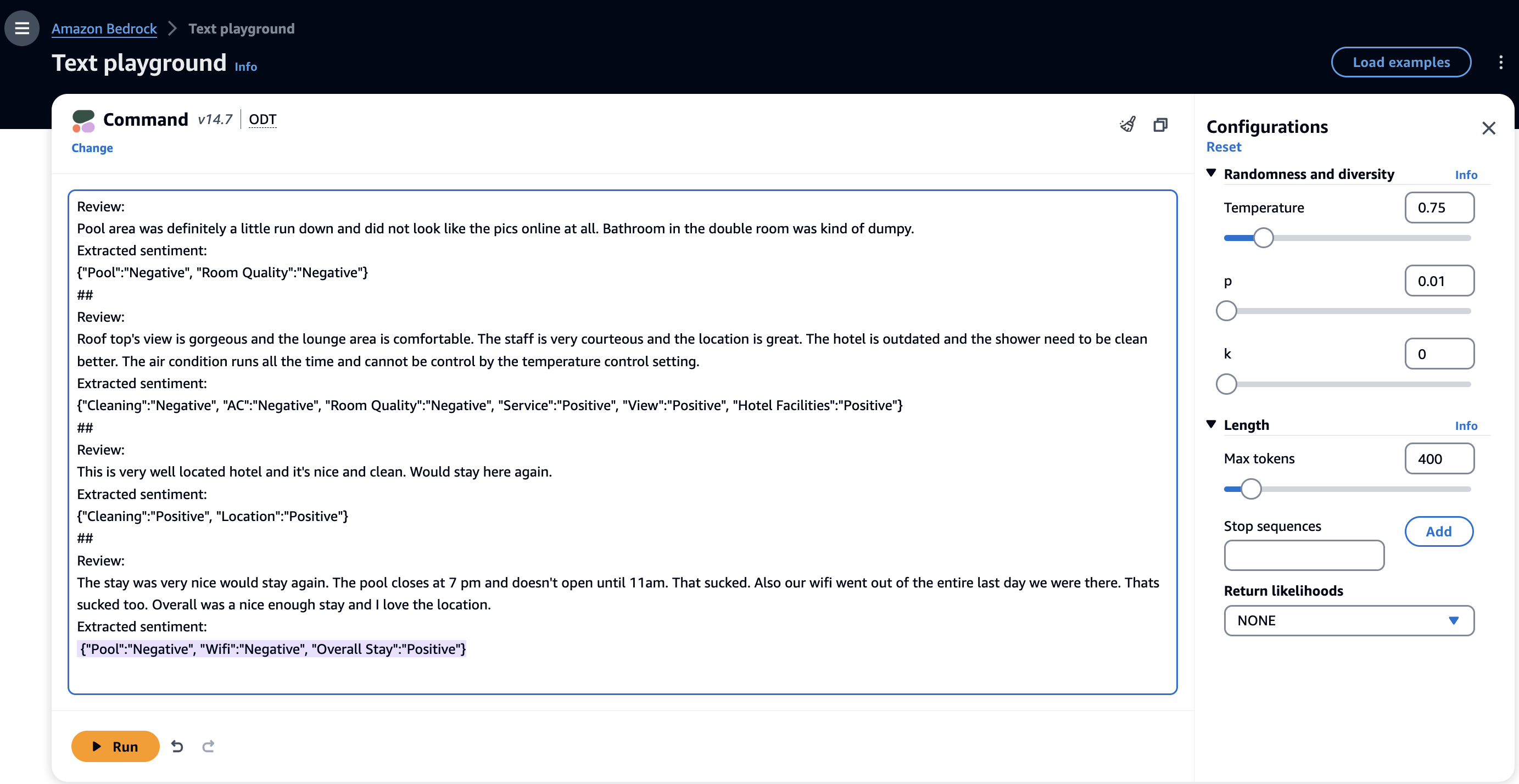
Nell'esempio precedente, il FM è stato in grado di identificare le entità dal testo di input (recensioni) ed estrarre i sentimenti associati. I suggerimenti di pochi scatti rappresentano un modo efficace per affrontare compiti complessi fornendo alcuni esempi di coppie input-output. Per attività semplici, puoi fornire un esempio (1 scatto), mentre per compiti più difficili dovresti fornire da tre (3 scatti) a cinque (5 scatti). Min et al. (2022) hanno pubblicato risultati sull'apprendimento in contesto che possono migliorare le prestazioni della tecnica di suggerimento a pochi colpi. È possibile utilizzare la richiesta rapida per una serie di attività, ad esempio l'analisi del sentiment, il riconoscimento delle entità, la risposta alle domande, la traduzione e la generazione di codice.
Stimolazione della catena di pensieri
Nonostante il suo potenziale, il suggerimento a pochi colpi presenta dei limiti, soprattutto quando si affrontano compiti di ragionamento complessi (come compiti aritmetici o logici). Queste attività richiedono la suddivisione del problema in passaggi e la successiva risoluzione. Wei et al. (2022) ha introdotto la tecnica di suggerimento della catena di pensiero (CoT) per risolvere problemi di ragionamento complessi attraverso passaggi di ragionamento intermedi. Puoi combinare CoT con la richiesta di pochi colpi per migliorare i risultati su attività complesse. Di seguito è riportato un esempio di attività di ragionamento che utilizza la richiesta CoT con pochi scatti con il modello Anthropic Claude 2 sulla console Amazon Bedrock.

Kojima et al. (2022) ha introdotto l'idea di CoT zero-shot utilizzando le capacità zero-shot non sfruttate dei FM. La loro ricerca indica che il CoT zero-shot, utilizzando lo stesso modello a prompt singolo, supera significativamente le prestazioni FM zero-shot su diversi compiti di ragionamento benchmark. È possibile utilizzare il suggerimento CoT zero-shot per semplici attività di ragionamento aggiungendo "Pensiamo passo dopo passo" al suggerimento originale.
Reagire
I suggerimenti CoT possono migliorare le capacità di ragionamento dei FM, ma dipendono comunque dalla conoscenza interna del modello e non considerano alcuna base di conoscenza o ambiente esterno per raccogliere più informazioni, il che può portare a problemi come allucinazioni. L'approccio ReAct (ragionamento e azione) affronta questa lacuna estendendo CoT e consentendo il ragionamento dinamico utilizzando un ambiente esterno (come Wikipedia).
integrazione
I FM hanno la capacità di comprendere domande e fornire risposte utilizzando le loro conoscenze pre-addestrate. Tuttavia, non hanno la capacità di rispondere a domande che richiedono l'accesso ai dati privati di un'organizzazione o la capacità di svolgere compiti in modo autonomo. RAG e agenti sono metodi per connettere queste applicazioni generative basate sull'intelligenza artificiale a set di dati aziendali, consentendo loro di fornire risposte che tengano conto delle informazioni organizzative e consentano l'esecuzione di azioni basate sulle richieste.
Recupero generazione aumentata
Retrieval Augmented Generation (RAG) consente di personalizzare le risposte di un modello quando si desidera che il modello consideri nuove conoscenze o informazioni aggiornate. Quando i dati cambiano frequentemente, come l'inventario o i prezzi, non è pratico mettere a punto e aggiornare il modello mentre risponde alle query degli utenti. Per dotare il FM di informazioni proprietarie aggiornate, le organizzazioni si rivolgono a RAG, una tecnica che prevede il recupero di dati da fonti di dati aziendali e l'arricchimento del prompt con tali dati per fornire risposte più pertinenti e accurate.
Esistono diversi casi d'uso in cui RAG può aiutare a migliorare le prestazioni FM:
- Risposta alla domanda – I modelli RAG aiutano le applicazioni di risposta alle domande a individuare e integrare informazioni da documenti o fonti di conoscenza per generare risposte di alta qualità. Ad esempio, un'applicazione di risposta alle domande potrebbe recuperare passaggi su un argomento prima di generare una risposta riassuntiva.
- Chatbot e agenti conversazionali – I RAG consentono ai chatbot di accedere a informazioni rilevanti da grandi fonti di conoscenza esterne. Ciò rende le risposte del chatbot più competenti e naturali.
- Assistenza alla scrittura – RAG può suggerire contenuti, fatti e punti di discussione pertinenti per aiutarti a scrivere documenti come articoli, rapporti ed e-mail in modo più efficiente. Le informazioni recuperate forniscono contesto e idee utili.
- Riassunto – RAG può trovare documenti di origine, passaggi o fatti rilevanti per aumentare la comprensione di un argomento da parte di un modello di riepilogo, consentendogli di generare riepiloghi migliori.
- Scrittura creativa e narrazione – RAG può estrarre idee per la trama, personaggi, ambientazioni ed elementi creativi da storie esistenti per ispirare modelli di generazione di storie AI. Ciò rende l'output più interessante e radicato.
- Traduzione – RAG può trovare esempi di come determinate frasi vengono tradotte tra le lingue. Ciò fornisce il contesto al modello di traduzione, migliorando la traduzione di frasi ambigue.
- Personalizzazione – Nei chatbot e nelle applicazioni di raccomandazione, RAG può estrarre contesto personale come conversazioni passate, informazioni sul profilo e preferenze per rendere le risposte più personalizzate e pertinenti.
Ci sono diversi vantaggi nell’usare un framework RAG:
- Allucinazioni ridotte – Il recupero di informazioni rilevanti aiuta a radicare il testo generato nei fatti e nella conoscenza del mondo reale, piuttosto che in un testo allucinante. Ciò promuove risposte più accurate, basate sui fatti e affidabili.
- Copertura – Il recupero consente a un FM di coprire una gamma più ampia di argomenti e scenari oltre i dati di addestramento inserendo informazioni esterne. Ciò aiuta a risolvere i problemi di copertura limitata.
- EFFICIENZA – Il recupero consente al modello di concentrare la sua generazione sulle informazioni più rilevanti, anziché generare tutto da zero. Ciò migliora l'efficienza e consente l'utilizzo di contesti più ampi.
- Sicurezza – Il recupero delle informazioni dalle origini dati richieste e consentite può migliorare la governance e il controllo sulla generazione di contenuti dannosi e imprecisi. Ciò supporta un’adozione più sicura.
- Scalabilità – L’indicizzazione e il recupero da corpora di grandi dimensioni consentono all’approccio di adattarsi meglio rispetto all’utilizzo dell’intero corpus durante la generazione. Ciò consente di adottare FM in ambienti con risorse più limitate.
RAG produce risultati di qualità, grazie all'aumento del contesto specifico del caso d'uso direttamente dagli archivi dati vettorizzati. Rispetto all'ingegneria rapida, produce risultati notevolmente migliorati con probabilità estremamente basse di allucinazioni. Puoi creare applicazioni basate su RAG sui dati aziendali utilizzando Amazon Kendra. RAG ha una complessità maggiore rispetto al prompt engineering perché è necessario possedere competenze di codifica e architettura per implementare questa soluzione. Tuttavia, Knowledge Base per Amazon Bedrock fornisce un'esperienza RAG completamente gestita e il modo più semplice per iniziare a utilizzare RAG in Amazon Bedrock. Knowledge Base per Amazon Bedrock automatizza il flusso di lavoro RAG end-to-end, inclusi acquisizione, recupero e implementazione tempestiva, eliminando la necessità di scrivere codice personalizzato per integrare origini dati e gestire query. La gestione del contesto della sessione è integrata in modo che la tua app possa supportare conversazioni a più turni. Le risposte della Knowledge Base vengono fornite con citazioni della fonte per migliorare la trasparenza e ridurre al minimo le allucinazioni. Il modo più semplice per creare un assistente basato sull'intelligenza artificiale generativa è utilizzare Amazon Q, che ha un sistema RAG integrato.
RAG ha il massimo grado di flessibilità quando si tratta di modifiche all'architettura. Puoi modificare il modello di incorporamento, l'archivio vettoriale e FM in modo indipendente con un impatto minimo o moderato sugli altri componenti. Per saperne di più sull'approccio RAG con Servizio Amazon OpenSearch e Amazon Bedrock, fare riferimento a Crea flussi di lavoro RAG scalabili e serverless con un motore vettoriale per i modelli Amazon OpenSearch Serverless e Amazon Bedrock Claude. Per informazioni su come implementare RAG con Amazon Kendra, fare riferimento a Sfruttare la potenza dei dati aziendali con l'intelligenza artificiale generativa: approfondimenti da Amazon Kendra, LangChain e modelli linguistici di grandi dimensioni.
Agenti
I FM possono comprendere e rispondere alle domande in base alla loro conoscenza pre-addestrata. Tuttavia, non sono in grado di completare alcuna attività reale, come prenotare un volo o elaborare un ordine di acquisto, da soli. Questo perché tali attività richiedono dati e flussi di lavoro specifici dell'organizzazione che in genere necessitano di una programmazione personalizzata. Quadri come LangChain e alcuni FM come i modelli Claude forniscono funzionalità di chiamata di funzioni per interagire con API e strumenti. Tuttavia, Agenti per Amazon Bedrock, una funzionalità IA nuova e completamente gestita di AWS, mira a rendere più semplice per gli sviluppatori creare applicazioni utilizzando FM di prossima generazione. Con pochi clic, può suddividere automaticamente le attività e generare la logica di orchestrazione richiesta, senza bisogno di codifica manuale. Gli agenti possono connettersi in modo sicuro ai database aziendali tramite API, acquisire e strutturare i dati per il consumo della macchina e integrarli con dettagli contestuali per produrre risposte più accurate e soddisfare le richieste. Poiché gestisce l'integrazione e l'infrastruttura, Agents for Amazon Bedrock ti consente di sfruttare appieno l'intelligenza artificiale generativa per i casi d'uso aziendali. Gli sviluppatori possono ora concentrarsi sulle loro applicazioni principali anziché sulle operazioni idrauliche di routine. L'elaborazione automatizzata dei dati e le chiamate API consentono inoltre a FM di fornire risposte aggiornate e personalizzate ed eseguire attività effettive utilizzando conoscenze proprietarie.
Personalizzazione del modello
I modelli Foundation sono estremamente capaci e consentono alcune ottime applicazioni, ma ciò che ti aiuterà a guidare la tua attività è l'intelligenza artificiale generativa che sa cosa è importante per i tuoi clienti, i tuoi prodotti e la tua azienda. E questo è possibile solo potenziando i modelli con i tuoi dati. I dati sono la chiave per passare da applicazioni generiche ad applicazioni di intelligenza artificiale generativa personalizzate che creano valore reale per i tuoi clienti e la tua azienda.
In questa sezione, discutiamo le diverse tecniche e i vantaggi della personalizzazione dei tuoi FM. Parleremo di come la personalizzazione del modello implica un ulteriore addestramento e la modifica dei pesi del modello per migliorarne le prestazioni.
Ritocchi
La messa a punto è il processo che prende un FM pre-addestrato, come Llama 2, e lo addestra ulteriormente su un'attività a valle con un set di dati specifico per quell'attività. Il modello pre-addestrato fornisce conoscenze linguistiche generali e la messa a punto gli consente di specializzarsi e migliorare le prestazioni su un compito particolare come la classificazione del testo, la risposta a domande o la generazione di testo. Con la messa a punto, fornisci set di dati etichettati, annotati con contesto aggiuntivo, per addestrare il modello su attività specifiche. È quindi possibile adattare i parametri del modello per l'attività specifica in base al contesto aziendale.
È possibile implementare la regolazione fine sugli FM con JumpStart di Amazon SageMaker e il substrato roccioso dell'Amazzonia. Per ulteriori dettagli, fare riferimento a Distribuisci e ottimizza i modelli di base in Amazon SageMaker JumpStart con due righe di codice ed Personalizza i modelli in Amazon Bedrock con i tuoi dati utilizzando la messa a punto e la formazione preliminare continua.
Pre-allenamento continuo
La formazione preliminare continua in Amazon Bedrock ti consente di insegnare a un modello precedentemente addestrato su dati aggiuntivi simili ai dati originali. Consente al modello di acquisire una conoscenza linguistica più generale piuttosto che concentrarsi su una singola applicazione. Con una formazione preliminare continua, puoi utilizzare i tuoi set di dati senza etichetta, o dati grezzi, per migliorare la precisione del modello di base per il tuo dominio modificando i parametri del modello. Ad esempio, un'azienda sanitaria può continuare a pre-addestrare il proprio modello utilizzando riviste mediche, articoli e documenti di ricerca per renderlo più informato sulla terminologia del settore. Per ulteriori dettagli, fare riferimento a Esperienza dello sviluppatore Amazon Bedrock.
Vantaggi della personalizzazione del modello
La personalizzazione del modello presenta numerosi vantaggi e può aiutare le organizzazioni con quanto segue:
- Adattamento specifico del dominio – È possibile utilizzare un FM per scopi generici e quindi addestrarlo ulteriormente sui dati provenienti da un dominio specifico (ad esempio biomedico, legale o finanziario). Ciò adatta il modello al vocabolario, allo stile e così via di quel dominio.
- Messa a punto specifica dell'attività – Puoi prendere un FM pre-addestrato e ottimizzarlo sui dati per un'attività specifica (come l'analisi del sentiment o la risposta alle domande). Ciò specializza il modello per quel particolare compito.
- Personalizzazione – Puoi personalizzare un FM sui dati di un individuo (e-mail, testi, documenti che ha scritto) per adattare il modello al suo stile unico. Ciò può consentire applicazioni più personalizzate.
- Ottimizzazione della lingua con risorse limitate – Puoi riqualificare solo gli strati superiori di un FM multilingue su una lingua con poche risorse per adattarlo meglio a quella lingua.
- Correzione dei difetti – Se in un modello vengono rilevati determinati comportamenti non desiderati, la personalizzazione su dati appropriati può aiutare ad aggiornare il modello per ridurre tali difetti.
La personalizzazione del modello aiuta a superare le seguenti sfide relative all'adozione di FM:
- Adattamento a nuovi ambiti e compiti – I FM pre-addestrati su corpora di testo generali spesso necessitano di essere messi a punto su dati specifici per attività per funzionare bene per le applicazioni a valle. La messa a punto adatta il modello a nuovi domini o attività su cui non era stato originariamente addestrato.
- Superare i pregiudizi – Gli FM possono presentare distorsioni rispetto ai dati di addestramento originali. La personalizzazione di un modello su nuovi dati può ridurre i pregiudizi indesiderati negli output del modello.
- Miglioramento dell'efficienza computazionale – I FM pre-addestrati sono spesso molto grandi e computazionalmente costosi. La personalizzazione del modello può consentire di ridimensionarlo eliminando parametri non importanti, rendendo la distribuzione più fattibile.
- Gestire dati target limitati – In alcuni casi, i dati reali disponibili per l’attività target sono limitati. La personalizzazione del modello utilizza i pesi pre-addestrati appresi su set di dati più grandi per superare questa scarsità di dati.
- Migliorare le prestazioni delle attività – La regolazione fine migliora quasi sempre le prestazioni sui compiti target rispetto all’utilizzo dei pesi pre-addestrati originali. Questa ottimizzazione del modello per l'uso previsto consente di implementare con successo gli FM in applicazioni reali.
La personalizzazione del modello presenta una complessità maggiore rispetto al prompt engineering e al RAG perché il peso e i parametri del modello vengono modificati tramite script di ottimizzazione, che richiedono competenze in scienza dei dati e ML. Tuttavia, Amazon Bedrock semplifica il compito fornendo un'esperienza gestita con cui personalizzare i modelli ritocchi or ha continuato la pre-formazione. La personalizzazione del modello fornisce risultati estremamente accurati con risultati di qualità comparabili rispetto a RAG. Poiché stai aggiornando i pesi del modello su dati specifici del dominio, il modello produce più risposte contestuali. Rispetto al RAG, la qualità potrebbe essere leggermente migliore a seconda del caso d'uso. Pertanto, è importante condurre un'analisi del compromesso tra le due tecniche. È potenzialmente possibile implementare RAG con un modello personalizzato.
Riqualificazione o formazione da zero
Costruire il proprio modello di intelligenza artificiale di base anziché utilizzare esclusivamente modelli pubblici preaddestrati consente un maggiore controllo, prestazioni migliorate e personalizzazione in base ai casi d'uso e ai dati specifici della tua organizzazione. Investire nella creazione di un FM su misura può fornire migliore adattabilità, aggiornamenti e controllo sulle capacità. L'addestramento distribuito consente la scalabilità necessaria per addestrare FM molto grandi su set di dati di grandi dimensioni su molte macchine. Questa parallelizzazione rende fattibili modelli con centinaia di miliardi di parametri addestrati su trilioni di token. I modelli più grandi hanno una maggiore capacità di apprendere e generalizzare.
L'addestramento da zero può produrre risultati di alta qualità perché il modello si sta addestrando da zero su dati specifici del caso d'uso, le possibilità di allucinazioni sono rare e la precisione dell'output può essere tra le più alte. Tuttavia, se il tuo set di dati è in continua evoluzione, potresti comunque riscontrare problemi di allucinazioni. La formazione da zero presenta la complessità e i costi di implementazione più elevati. Richiede il massimo sforzo perché richiede la raccolta di una grande quantità di dati, la loro cura ed elaborazione e la formazione di un FM abbastanza grande, che richiede una profonda scienza dei dati e competenze ML. Questo approccio richiede molto tempo (in genere possono essere necessarie settimane o mesi).
Dovresti prendere in considerazione la formazione di un FM da zero quando nessuno degli altri approcci funziona per te e hai la capacità di creare un FM con una grande quantità di dati tokenizzati ben curati, un budget sofisticato e un team di esperti di ML altamente qualificati . AWS fornisce l'infrastruttura cloud più avanzata per addestrare ed eseguire LLM e altri FM basati su GPU e chip di formazione ML appositamente realizzati. AWSTrainiume acceleratore di inferenza ML, AWS Inferenza. Per ulteriori dettagli sulla formazione dei LLM su SageMaker, fare riferimento a Formazione di modelli linguistici di grandi dimensioni su Amazon SageMaker: best practice ed SageMaker HyperPod.
Selezionare l'approccio giusto per lo sviluppo di applicazioni di intelligenza artificiale generativa
Quando si sviluppano applicazioni di intelligenza artificiale generativa, le organizzazioni devono considerare attentamente diversi fattori chiave prima di selezionare il modello più adatto a soddisfare le proprie esigenze. È necessario considerare una serie di aspetti, tra cui i costi (per garantire che il modello selezionato sia in linea con i vincoli di budget), la qualità (per fornire risultati coerenti e accurati nei fatti), la perfetta integrazione con le piattaforme e i flussi di lavoro aziendali attuali e la riduzione delle allucinazioni o la generazione di informazioni false. . Con molte opzioni disponibili, prendersi il tempo necessario per valutare attentamente questi aspetti aiuterà le organizzazioni a scegliere il modello di intelligenza artificiale generativa che meglio soddisfa le loro esigenze e priorità specifiche. Dovresti esaminare attentamente i seguenti fattori:
- Integrazione con i sistemi aziendali – Affinché i FM siano veramente utili in un contesto aziendale, devono integrarsi e interagire con i sistemi e i flussi di lavoro aziendali esistenti. Ciò potrebbe comportare l’accesso ai dati da database, pianificazione delle risorse aziendali (ERP) e gestione delle relazioni con i clienti (CRM), nonché l’attivazione di azioni e flussi di lavoro. Senza un’adeguata integrazione, la FM rischia di essere uno strumento isolato. I sistemi aziendali come l'ERP contengono dati aziendali chiave (clienti, prodotti, ordini). Il FM deve essere connesso a questi sistemi per utilizzare i dati aziendali piuttosto che elaborare il proprio grafico della conoscenza, che potrebbe essere impreciso o obsoleto. Ciò garantisce accuratezza e un'unica fonte di verità.
- Allucinazioni – Le allucinazioni si verificano quando un’applicazione di intelligenza artificiale genera false informazioni che sembrano reali. Questi problemi devono essere affrontati attentamente prima che i FM siano ampiamente adottati. Ad esempio, un chatbot medico progettato per fornire suggerimenti diagnostici potrebbe allucinare dettagli sui sintomi o sulla storia medica di un paziente, portandolo a proporre una diagnosi imprecisa. Prevenire allucinazioni dannose come queste attraverso soluzioni tecniche e la cura dei set di dati sarà fondamentale per garantire che questi FM possano essere considerati affidabili per applicazioni sensibili come l’assistenza sanitaria, la finanza e il diritto. Test approfonditi e trasparenza sui dati di addestramento di un FM e sui difetti rimanenti dovranno accompagnare le implementazioni.
- Competenze e risorse – Il successo dell’adozione dei FM dipenderà in larga misura dal possesso delle competenze e delle risorse adeguate per utilizzare la tecnologia in modo efficace. Le organizzazioni hanno bisogno di dipendenti con forti competenze tecniche per implementare, personalizzare e mantenere correttamente i FM in base alle loro esigenze specifiche. Richiedono inoltre ampie risorse computazionali come hardware avanzato e capacità di cloud computing per eseguire FM complessi. Ad esempio, un team di marketing che desidera utilizzare un FM per generare testi pubblicitari e post sui social media ha bisogno di ingegneri qualificati per integrare il sistema, creativi per fornire suggerimenti e valutare la qualità dell'output e una potenza di cloud computing sufficiente per implementare il modello in modo economicamente vantaggioso. Investire nello sviluppo di competenze e infrastrutture tecniche consentirà alle organizzazioni di ottenere un reale valore commerciale dall’applicazione dei FM.
- Qualità di uscita – La qualità dell’output prodotto dai FM sarà fondamentale nel determinare la loro adozione e utilizzo, in particolare nelle applicazioni rivolte ai consumatori come i chatbot. Se i chatbot basati su FM forniscono risposte imprecise, prive di senso o inappropriate, gli utenti si sentiranno rapidamente frustrati e smetteranno di interagire con loro. Pertanto, le aziende che desiderano implementare chatbot devono testare rigorosamente i FM che li guidano per garantire che generino costantemente risposte di alta qualità che siano utili, pertinenti e appropriate per fornire una buona esperienza utente. La qualità dell'output comprende fattori come pertinenza, accuratezza, coerenza e adeguatezza, che contribuiscono tutti alla soddisfazione complessiva dell'utente e determineranno o distruggeranno l'adozione di FM come quelli utilizzati per i chatbot.
- Costo – L’elevata potenza computazionale richiesta per addestrare ed eseguire modelli di intelligenza artificiale di grandi dimensioni come i FM può comportare costi sostanziali. Molte organizzazioni potrebbero non avere le risorse finanziarie o l’infrastruttura cloud necessarie per utilizzare modelli così massicci. Inoltre, l'integrazione e la personalizzazione dei FM per casi d'uso specifici comporta un aumento dei costi di progettazione. Le considerevoli spese richieste per l’utilizzo dei FM potrebbero scoraggiare un’adozione diffusa, soprattutto tra le aziende più piccole e le startup con budget limitati. Valutare il potenziale ritorno sull'investimento e valutare i costi rispetto ai benefici dei FM è fondamentale per le organizzazioni che ne considerano l'applicazione e l'utilità. L’efficienza in termini di costi sarà probabilmente un fattore decisivo nel determinare se e come questi modelli potenti ma ad alta intensità di risorse possano essere implementati in modo fattibile.
Decisione di progettazione
Come abbiamo spiegato in questo post, sono attualmente disponibili molte tecniche di intelligenza artificiale diverse, come il prompt engineering, il RAG e la personalizzazione del modello. Questa ampia gamma di scelte rende difficile per le aziende determinare l’approccio ottimale per il loro particolare caso d’uso. La scelta del giusto insieme di tecniche dipende da vari fattori, tra cui l'accesso a origini dati esterne, feed di dati in tempo reale e la specificità del dominio dell'applicazione prevista. Per facilitare l'identificazione della tecnica più adatta in base al caso d'uso e alle considerazioni coinvolte, esaminiamo il seguente diagramma di flusso, che delinea raccomandazioni per soddisfare esigenze e vincoli specifici con metodi appropriati.

Per ottenere una comprensione chiara, esaminiamo il diagramma di flusso delle decisioni di progettazione utilizzando alcuni esempi illustrativi:
- Ricerca aziendale – Un dipendente sta cercando di richiedere un congedo alla propria organizzazione. Per fornire una risposta in linea con le politiche HR dell'organizzazione, il FM ha bisogno di più contesto oltre le proprie conoscenze e capacità. Nello specifico, il FM richiede l'accesso a fonti di dati esterne che forniscono linee guida e politiche pertinenti in materia di risorse umane. Considerato questo scenario di richiesta di un dipendente che richiede il riferimento a dati esterni specifici del dominio, l'approccio consigliato secondo il diagramma di flusso è il prompt engineering con RAG. RAG aiuterà a fornire i dati rilevanti provenienti da fonti di dati esterne come contesto per FM.
- Ricerca aziendale con output specifico dell'organizzazione – Supponiamo di avere disegni tecnici e di voler estrarre da essi la distinta base, formattando l'output secondo gli standard di settore. Per fare ciò, è possibile utilizzare una tecnica che combina il prompt engineering con RAG e un modello linguistico ottimizzato. Il modello ottimizzato verrebbe addestrato a produrre distinte materiali quando vengono forniti come input i disegni tecnici. RAG aiuta a trovare i disegni tecnici più rilevanti dalle origini dati dell'organizzazione da inserire nel contesto dell'FM. Nel complesso, questo approccio estrae distinte materiali dai disegni tecnici e struttura l'output in modo appropriato per il dominio ingegneristico.
- Ricerca generale – Immagina di voler trovare l’identità del 30° Presidente degli Stati Uniti. Potresti utilizzare il prompt engineering per ottenere la risposta da un FM. Poiché questi modelli vengono addestrati su molte origini dati, spesso possono fornire risposte accurate a domande concrete come questa.
- Ricerca generale con eventi recenti – Se desideri determinare il prezzo attuale delle azioni di Amazon, puoi utilizzare l’approccio di pronta ingegneria con un agente. L'agente fornirà al FM il prezzo delle azioni più recente in modo che possa generare la risposta fattuale.
Conclusione
L’intelligenza artificiale generativa offre alle organizzazioni un enorme potenziale per promuovere l’innovazione e aumentare la produttività in una varietà di applicazioni. Tuttavia, per adottare con successo queste tecnologie emergenti di intelligenza artificiale è necessario affrontare considerazioni chiave su integrazione, qualità dell’output, competenze, costi e rischi potenziali come allucinazioni dannose o vulnerabilità della sicurezza. Le organizzazioni devono adottare un approccio sistematico per valutare i requisiti e i vincoli dei casi d’uso per determinare le tecniche più appropriate per adattare e applicare i FM. Come evidenziato in questo post, il prompt engineering, il RAG e i metodi efficienti di personalizzazione del modello hanno ciascuno i propri punti di forza e di debolezza che si adattano a diversi scenari. Mappando le esigenze aziendali con le capacità dell’intelligenza artificiale utilizzando un quadro strutturato, le organizzazioni possono superare gli ostacoli all’implementazione e iniziare a ottenere vantaggi dai FM, costruendo al tempo stesso barriere per gestire i rischi. Con una pianificazione attenta basata su esempi reali, le aziende di ogni settore potranno sbloccare un immenso valore da questa nuova ondata di intelligenza artificiale generativa. Impara al riguardo IA generativa su AWS.
Informazioni sugli autori
 Jay Rao è Principal Solutions Architect presso AWS. Si concentra sulle tecnologie AI/ML con un vivo interesse per l'intelligenza artificiale generativa e la visione artificiale. In AWS, gli piace fornire consulenza tecnica e strategica ai clienti e aiutarli a progettare e implementare soluzioni che portino risultati aziendali. È autore di libri (Computer Vision su AWS), pubblica regolarmente blog ed esempi di codice e ha tenuto conferenze in conferenze tecnologiche come AWS re:Invent.
Jay Rao è Principal Solutions Architect presso AWS. Si concentra sulle tecnologie AI/ML con un vivo interesse per l'intelligenza artificiale generativa e la visione artificiale. In AWS, gli piace fornire consulenza tecnica e strategica ai clienti e aiutarli a progettare e implementare soluzioni che portino risultati aziendali. È autore di libri (Computer Vision su AWS), pubblica regolarmente blog ed esempi di codice e ha tenuto conferenze in conferenze tecnologiche come AWS re:Invent.
 Babu Kariyaden Parambath è uno specialista senior di IA/ML presso AWS. In AWS, gli piace lavorare con i clienti aiutandoli a identificare il giusto caso d'uso aziendale con valore aziendale e risolverlo utilizzando soluzioni e servizi AWS AI/ML. Prima di entrare in AWS, Babu era un sostenitore dell'intelligenza artificiale con 20 anni di esperienza in diversi settori offrendo valore aziendale basato sull'intelligenza artificiale per i clienti.
Babu Kariyaden Parambath è uno specialista senior di IA/ML presso AWS. In AWS, gli piace lavorare con i clienti aiutandoli a identificare il giusto caso d'uso aziendale con valore aziendale e risolverlo utilizzando soluzioni e servizi AWS AI/ML. Prima di entrare in AWS, Babu era un sostenitore dell'intelligenza artificiale con 20 anni di esperienza in diversi settori offrendo valore aziendale basato sull'intelligenza artificiale per i clienti.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/best-practices-to-build-generative-ai-applications-on-aws/

