Ez egy vendégbejegyzés, amelyet Meta PyTorch csapatával közösen írtunk, és a folytatása rész 1 sorozatból, ahol bemutatjuk a PyTorch 2.0 AWS-en való futtatásának teljesítményét és egyszerűségét.
A gépi tanulási (ML) kutatások bebizonyították, hogy a jelentősen nagy adatkészletekkel betanított nagy nyelvi modellek (LLM-ek) jobb modellminőséget eredményeznek. Az elmúlt néhány évben a jelenlegi generációs modellek mérete jelentősen megnőtt, és a hatékony és méretarányos betanításhoz modern eszközök és infrastruktúra szükséges. A PyTorch Distributed Data Parallelism (DDP) segíti az adatok egyszerű és robusztus méretű feldolgozását, de ehhez a modellnek egy GPU-ra kell illeszkednie. A PyTorch Fully Sharded Data Parallel (FSDP) könyvtár áttöri ezt a korlátot azáltal, hogy lehetővé teszi a modellfelosztást, hogy nagy modelleket tanítson az adatokkal párhuzamos dolgozók között.
Az elosztott modellképzéshez olyan dolgozói csomópontok fürtje szükséges, amelyek méretezhetők. Amazon Elastic Kubernetes szolgáltatás (Amazon EKS) egy népszerű Kubernetes-konform szolgáltatás, amely nagymértékben leegyszerűsíti az AI/ML-munkaterhelések futtatásának folyamatát, így könnyebben kezelhető és kevésbé időigényes.
Ebben a blogbejegyzésben az AWS együttműködik a Meta PyTorch csapatával, hogy megvitassák, hogyan lehet a PyTorch FSDP könyvtárat használni a mélytanulási modellek lineáris skálázásához az AWS-en az Amazon EKS és az Amazon EKS segítségével. AWS Deep Learning Containers (DLC-k). Ezt a 7B, 13B és 70B Llama2 modellek betanításával mutatjuk be lépésről lépésre az Amazon EKS 16 használatával Amazon rugalmas számítási felhő (Amazon EC2) p4de.24xlarge példányok (mindegyik 8 NVIDIA A100 Tensor Core GPU-val és minden GPU 80 GB HBM2e memóriával) vagy 16 EC2 p5.48xnagy példányok (mindegyik 8 NVIDIA H100 Tensor Core GPU-val és mindegyik GPU 80 GB HBM3 memóriával), közel lineáris skálázást ér el az átviteli sebességben, és végső soron gyorsabb edzési időt tesz lehetővé.
A következő skálázási diagram azt mutatja, hogy a p5.48xlarge példányok 87%-os skálázási hatékonyságot kínálnak az FSDP Llama2 finomhangolásával egy 16 csomópontos fürtkonfigurációban.

Az LLM-ek képzésének kihívásai
A vállalkozások egyre gyakrabban alkalmazzák az LLM-eket számos feladathoz, ideértve a virtuális asszisztenseket, a fordítást, a tartalomkészítést és a számítógépes megjelenítést, hogy növeljék a hatékonyságot és a pontosságot a különféle alkalmazásokban.
Azonban ezeknek a nagy modelleknek az egyedi felhasználási esetekhez való betanítása vagy finomhangolása nagy mennyiségű adatot és számítási teljesítményt igényel, ami növeli az ML-verem általános mérnöki összetettségét. Ennek oka az egyetlen GPU-n elérhető korlátozott memória is, ami korlátozza a betanítható modell méretét, és korlátozza a betanítás során használt GPU-nkénti kötegméretet is.
Ennek a kihívásnak a megoldására különféle modellpárhuzamossági technikák, mint pl DeepSpeed ZeRO és a PyTorch FSDP azért jöttek létre, hogy lehetővé tegyék a korlátozott GPU-memória ezen akadályának leküzdését. Ez egy szilánkos adatok párhuzamos technikájával történik, ahol minden gyorsító csak egy szeletet tartalmaz (a szilánk).
Ez a bejegyzés bemutatja, hogyan használhatja a PyTorch FSDP-t a Llama2 modell finomhangolására az Amazon EKS használatával. Ezt úgy érjük el, hogy a számítási és GPU-kapacitást a modellkövetelményekhez igazítjuk.
Az FSDP áttekintése
A PyTorch DDP képzésben minden GPU (a továbbiakban: a munkás a PyTorch kontextusában) a modell teljes másolatát tartalmazza, beleértve a modell súlyait, színátmeneteit és optimalizáló állapotait. Minden dolgozó egy köteg adatot dolgoz fel, és a visszafelé haladás végén egy mindent csökkenteni művelet a gradiensek szinkronizálására a különböző dolgozók között.
A modell replikája minden GPU-n korlátozza a DDP-munkafolyamatba beilleszthető modell méretét. Az FSDP segít leküzdeni ezt a korlátot a modellparaméterek, az optimalizáló állapotok és a gradiensek felosztásával az adatok párhuzamos feldolgozói között, miközben megőrzi az adatok párhuzamosságának egyszerűségét.
Ezt a következő diagram szemlélteti, ahol DDP esetén minden GPU rendelkezik a modellállapot teljes másolatával, beleértve az optimalizáló állapotát (OS), a gradienseket (G) és a paramétereket (P): M(OS + G) + P). Az FSDP-ben minden GPU csak a modell állapotának egy szeletét tartalmazza, beleértve az optimalizáló állapotát (OS), a gradienseket (G) és a paramétereket (P): M (OS + G + P). Az FSDP használata lényegesen kisebb GPU-memóriaterületet eredményez a DDP-hez képest az összes dolgozó esetében, lehetővé téve a nagyon nagy modellek betanítását, vagy nagyobb kötegméretek használatát a betanítási munkákhoz.
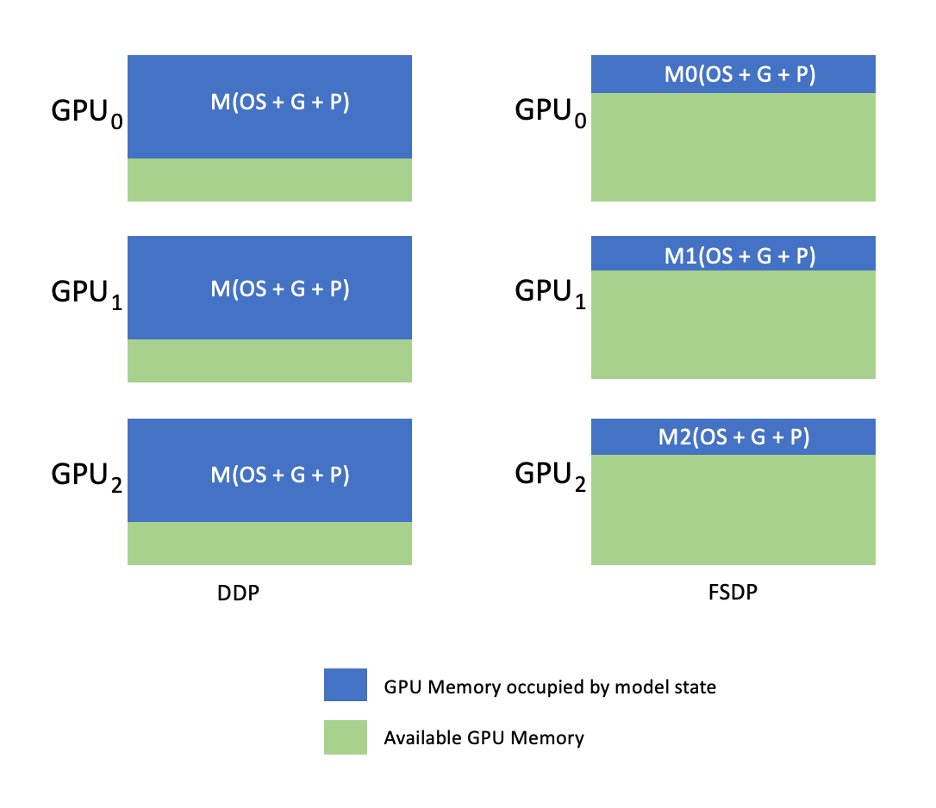
Ennek azonban megnövekedett kommunikációs többletterhelése az ára, amelyet az FSDP-optimalizálások mérsékelnek, mint például a kommunikációs és számítási folyamatok átfedése olyan funkciókkal, mint pl. előletöltés. Részletesebb információkért lásd Kezdő lépések a teljesen megosztott adatokkal párhuzamosan (FSDP).
Az FSDP különféle paramétereket kínál, amelyek lehetővé teszik a képzési feladatok teljesítményének és hatékonyságának beállítását. Az FSDP néhány kulcsfontosságú jellemzője és képessége:
- Transzformátor csomagolási politika
- Rugalmas vegyes precizitás
- Aktiválási ellenőrzőpont
- Különféle felosztási stratégiák a különböző hálózati sebességekhez és fürttopológiákhoz:
- FULL_SHARD – A szilánkos modell paraméterei, színátmenetei és optimalizáló állapotai
- HYBRID_SHARD – Teljes szilánk egy csomóponton belüli DDP csomópontokon keresztül; támogatja a rugalmas felosztási csoportot a modell teljes másolatához (HSDP)
- SHARD_GRAD_OP – Csak a színátmenetek és az optimalizáló állapotok felosztása
- NO_SHARD – Hasonló a DDP-hez
Az FSDP-vel kapcsolatos további információkért lásd: Hatékony nagyszabású képzés Pytorch FSDP és AWS segítségével.
Az alábbi ábra bemutatja, hogyan működik az FSDP két párhuzamos adatfolyamat esetén.

Megoldás áttekintése
Ebben a bejegyzésben egy számítási fürtöt állítottunk be az Amazon EKS használatával, amely egy felügyelt szolgáltatás a Kubernetes futtatásához az AWS felhőben és a helyszíni adatközpontokban. Sok ügyfél használja az Amazon EKS-t a Kubernetes-alapú AI/ML munkaterhelések futtatásához, kihasználva annak teljesítményét, méretezhetőségét, megbízhatóságát és rendelkezésre állását, valamint az AWS-hálózati, biztonsági és egyéb szolgáltatásokkal való integrációját.
Az FSDP használati esetünkben a Kubeflow képzési operátor az Amazon EKS-en, amely egy Kubernetes-natív projekt, amely megkönnyíti az ML modellek finomhangolását és méretezhető elosztott képzését. Támogatja a különféle ML-keretrendszereket, beleértve a PyTorch-ot is, amellyel a PyTorch-oktatási feladatokat nagy méretben telepítheti és kezelheti.
A Kubeflow Training Operator PyTorchJob egyéni erőforrását felhasználva képzési feladatokat futtatunk Kubernetesen konfigurálható számú dolgozói replikával, amely lehetővé teszi számunkra az erőforrás-kihasználás optimalizálását.
Az alábbiakban felsoroljuk a kiképző kezelő néhány összetevőjét, amelyek szerepet játszanak a Llama2 finomhangolási használati esetünkben:
- Központi Kubernetes-vezérlő, amely a PyTorch elosztott képzési munkáit irányítja.
- PyTorchJob, a Kubernetes egyéni PyTorch-erőforrás, amelyet a Kubeflow Training Operator biztosít a Llama2 képzési feladatok Kubernetesen történő meghatározásához és telepítéséhez.
- etcd, amely a PyTorch modellek elosztott képzését koordináló randevúzási mechanizmus megvalósításához kapcsolódik. Ez
etcdszerver a randevúzási folyamat részeként elősegíti a résztvevő dolgozók koordinációját és szinkronizálását az elosztott képzés során.
A következő ábra a megoldás architektúráját mutatja be.

A legtöbb részletet az automatizálási szkriptek absztrahálják, amelyeket a Llama2 példa futtatásához használunk.
Ebben a használati esetben a következő kódhivatkozásokat használjuk:
Mi az a Llama2?
A Llama2 egy LLM, amely 2 billió token szövegre és kódra van előképzett. Ez az egyik legnagyobb és legerősebb ma elérhető LLM. A Llama2-t számos feladathoz használhatja, beleértve a természetes nyelvi feldolgozást (NLP), a szöveggenerálást és a fordítást. További információkért lásd: Kezdő lépések Llamával.
A Llama2 három különböző modellméretben kapható:
- Llama2-70b – Ez a legnagyobb Llama2 modell, 70 milliárd paraméterrel. Ez a legerősebb Llama2 modell, és a legigényesebb feladatokhoz is használható.
- Llama2-13b – Ez egy közepes méretű Llama2 modell, 13 milliárd paraméterrel. Jó egyensúlyt teremt a teljesítmény és a hatékonyság között, és különféle feladatokhoz használható.
- Llama2-7b – Ez a legkisebb Llama2 modell, 7 milliárd paraméterrel. Ez a leghatékonyabb Llama2 modell, és olyan feladatokhoz használható, amelyek nem igényelnek a legmagasabb szintű teljesítményt.
Ez a bejegyzés lehetővé teszi az összes modell finomhangolását az Amazon EKS-en. Az EKS-fürt létrehozásának és az FSDP-feladatok futtatásának egyszerű és reprodukálható élménye érdekében a aws-do-eks projekt. A példa egy már meglévő EKS-fürttel is működik.
A forgatókönyvvel ellátott végigjátszás elérhető a következő helyen GitHub az azonnali élményért. A következő szakaszokban részletesebben elmagyarázzuk a teljes folyamatot.
Biztosítsa a megoldás infrastruktúráját
Az ebben a bejegyzésben leírt kísérletekhez p4de (A100 GPU) és p5 (H100 GPU) csomópontokkal rendelkező klasztereket használunk.
Klaszter p4de.24xlarge csomópontokkal
A p4de csomópontokkal rendelkező fürtünkhöz a következőket használjuk eks-gpu-p4de-odcr.yaml forgatókönyv:
<p></p> exctl és az előző fürt jegyzéke, létrehozunk egy klasztert p4de csomópontokkal:
Fürt p5.48xnagy csomópontokkal
A P5 csomópontokkal rendelkező EKS-fürt terraformsablonja az alábbiakban található GitHub repo.
A fürt testreszabható a változók.tf fájlt, majd hozza létre a Terraform CLI-n keresztül:
A fürt elérhetőségét egy egyszerű kubectl parancs futtatásával ellenőrizheti:
A fürt egészséges, ha ennek a parancsnak a kimenete a csomópontok várható számát mutatja Ready állapotban.
Telepítse az előfeltételeket
Az FSDP Amazon EKS rendszeren történő futtatásához a PyTorchJob egyéni erőforrás. Szükséges hozzá stb és a Kubeflow képzési operátor előfeltételként.
Telepítse az etcd-t a következő kóddal:
Telepítse a Kubeflow Training Operatort a következő kóddal:
Hozzon létre és küldjön FSDP-tárolóképet az Amazon ECR-nek
Használja a következő kódot egy FSDP-tárolókép létrehozásához, és küldje el Amazon Elastic Container Registry (Amazon ECR):
Hozza létre az FSDP PyTorchJob jegyzéket
Helyezze be Ölelő Arc token a következő részletben a futtatás előtt:
Konfigurálja a PyTorchJob-ot a következővel .NS fájlban vagy közvetlenül a környezeti változókban az alábbiak szerint:
A PyTorchJob jegyzék létrehozása a fsdp sablon és a gener.sh szkriptet, vagy hozza létre közvetlenül az alábbi szkript segítségével:
Futtassa a PyTorchJob-ot
Futtassa a PyTorchJob-ot a következő kóddal:
Látni fogja a megadott számú FDSP worker pod létrehozását, és a kép kihúzása után Futó állapotba kerülnek.
A PyTorchJob állapotának megtekintéséhez használja a következő kódot:
A PyTorchJob leállításához használja a következő kódot:
Egy feladat befejezése után törölni kell, mielőtt új futást kezdeményezne. Azt is megfigyeltük, hogy aetcdpod és hagyja újraindulni egy új feladat indítása előtt segít elkerülni a RendezvousClosedError.
Méretezze a klasztert
Megismételheti a jobok létrehozásának és futtatásának előző lépéseit, miközben változtatja a fürtben lévő worker csomópontok számát és példánytípusát. Ez lehetővé teszi a korábban bemutatotthoz hasonló méretezési diagramok készítését. Általánosságban elmondható, hogy a GPU-memória helyigényének csökkenését, az időszaki idő csökkenését és az átviteli sebesség növekedését kell tapasztalnia, ha több csomópontot adnak a fürthöz. Az előző diagramot több kísérlet elvégzésével állítottuk elő egy 5-1 csomópont méretű p16 csomópont csoporttal.
Vegye figyelembe az FSDP képzési munkaterhelését
A generatív mesterséges intelligencia munkaterheléseinek megfigyelése fontos ahhoz, hogy láthatóvá váljanak a futó munkái, valamint segítse a számítási erőforrások maximális kihasználását. Ebben a bejegyzésben néhány Kubernetes-natív és nyílt forráskódú megfigyelési eszközt használunk erre a célra. Ezekkel az eszközökkel nyomon követheti a hibákat, a statisztikákat és a modell viselkedését, így a mesterséges intelligencia megfigyelése minden üzleti felhasználás döntő részévé válik. Ebben a részben különböző megközelítéseket mutatunk be az FSDP képzési munkáinak megfigyelésére.
Munkás pod naplók
A legalapvetőbb szinten látnia kell az edzésdobozok naplóit. Ez könnyen megtehető a Kubernetes-natív parancsok használatával.
Először is kérje le a tömbök listáját, és keresse meg annak nevét, amelynek naplóit szeretné látni:
Ezután tekintse meg a kiválasztott pod naplóit:
Csak egy dolgozó (megválasztott vezető) naplója tartalmazza a teljes munkastatisztikát. A megválasztott vezetőcsoport neve minden dolgozói csoportnapló elején megtalálható, a kulccsal azonosítva master_addr=.
CPU kihasználtság
Az elosztott képzési munkaterhelések CPU- és GPU-erőforrásokat is igényelnek. A munkaterhelések optimalizálásához fontos megérteni, hogyan használják fel ezeket az erőforrásokat. Szerencsére néhány nagyszerű nyílt forráskódú segédprogram is elérhető, amelyek segítik a CPU és a GPU kihasználtságát. A CPU kihasználtságának megtekintéséhez használhatjahtop. Ha a worker pod-ok tartalmazzák ezt a segédprogramot, az alábbi paranccsal megnyithat egy parancsértelmezőt egy podba, majd futtathatjahtop.
Alternatív megoldásként telepíthet egy htop-otdaemonsetmint a következőkben közölt GitHub repo.
Adaemonsetminden csomóponton egy könnyű htop pod fog futni. Bármelyik podba végrehajthatja, és futtathatja ahtopparancs:
A következő képernyőkép a CPU kihasználtságát mutatja a fürt egyik csomópontján. Ebben az esetben egy P5.48xlarge példányt nézünk, amely 192 vCPU-val rendelkezik. A processzormagok tétlenek a modellsúlyok letöltése közben, és növekvő kihasználtságot tapasztalunk, miközben a modellsúlyok betöltődnek a GPU memóriájába.

GPU kihasználtság
Ha anvtopsegédprogram elérhető a podban, végrehajthatja az alábbi használatával, majd futtassanvtop.
Alternatív megoldásként telepíthet egy nvtopotdaemonsetmint a következőkben közölt GitHub repo.
Ez futni fog anvtoppod minden csomóponton. Bármelyikbe léphet, és futhatnvtop:
A következő képernyőkép a GPU kihasználtságát mutatja a betanítási fürt egyik csomópontján. Ebben az esetben egy P5.48xlarge példányt nézünk, amely 8 NVIDIA H100 GPU-val rendelkezik. A GPU-k tétlenek a modellsúlyok letöltése közben, majd a GPU-memória kihasználtsága növekszik, ahogy a modellsúlyok betöltődnek a GPU-ra, és a GPU-kihasználás 100%-ra emelkedik, miközben a betanítási iterációk folyamatban vannak.

Grafana műszerfal
Most, hogy megértette, hogyan működik a rendszer a pod és a csomópont szintjén, fontos a fürtszintű mutatók vizsgálata is. Az összesített felhasználási mutatók az NVIDIA DCGM Exporter és a Prometheus segítségével gyűjthetők, és a Grafana programban jeleníthetők meg.
Egy példa a Prometheus-Grafana telepítésére az alábbiakban található GitHub repo.
Egy példa a DCGM exportőr telepítésére a következőkben található GitHub repo.
A következő képernyőképen egy egyszerű Grafana műszerfal látható. A következő DCGM-mérőszámok kiválasztásával készült: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPés DCGM_FI_DEV_POWER_USAGE. A műszerfal importálható a Prometheusba innen GitHub.
A következő műszerfal egy Llama2 7b egykorszakos képzési feladat egy futtatását mutatja. A grafikonok azt mutatják, hogy a streaming multiprocessor (SM) órajelének növekedésével a GPU-k teljesítményfelvétele és hőmérséklete is nő, valamint a GPU és a memória kihasználtsága. Azt is láthatja, hogy nem volt XID hiba, és a GPU-k egészségesek voltak a futtatás során.

2024 márciusa óta az EKS GPU megfigyelhetősége natív módon támogatott CloudWatch Container Insights. A funkció engedélyezéséhez csak telepítse a CloudWatch megfigyelési bővítményt az EKS-fürtbe. Ezután a Container Insights előre konfigurált és testreszabható irányítópultjain keresztül böngészhet a pod-, csomópont- és fürtszintű mutatók között.
Tisztítsuk meg
Ha a fürtöt az ebben a blogban található példák alapján hozta létre, a következő kód futtatásával törölheti a fürtöt és a hozzá kapcsolódó erőforrásokat, beleértve a VPC-t is:
Exctl esetén:
Terraformhoz:
Közelgő funkciók
Az FSDP várhatóan tartalmazni fog egy paraméterenkénti felosztási funkciót, amelynek célja a GPU-nkénti memóriaterület további javítása. Ezenkívül az FP8 támogatásának folyamatban lévő fejlesztése az FSDP teljesítményének javítását célozza a H100 GPU-kon. Végül, amikor az FSDP integrálva vantorch.compile, reméljük, hogy további teljesítményjavításokat és olyan funkciókat teszünk lehetővé, mint a szelektív aktiválás-ellenőrzőpont.
Következtetés
Ebben a bejegyzésben megvitattuk, hogy az FSDP hogyan csökkenti az egyes GPU-k memóriaterületét, lehetővé téve a nagyobb modellek hatékonyabb betanítását, és közel lineáris skálázást az átviteli sebességben. Ezt egy Llama2 modell betanításának lépésről lépésre történő megvalósításával mutattuk be az Amazon EKS használatával P4de és P5 példányokon, és megfigyelési eszközöket, például kubectl, htop, nvtop és dcgm használtunk a naplók, valamint a CPU és a GPU kihasználtságának figyelésére.
Javasoljuk, hogy használja ki a PyTorch FSDP előnyeit saját LLM-képzési munkáihoz. Kezdje a címen aws-do-fsdp.
A szerzőkről
 Kanwaljit Khurmi az Amazon Web Services fő AI/ML megoldások építésze. Együttműködik az AWS-ügyfelekkel, hogy útmutatást és technikai segítséget nyújtson, segítve őket gépi tanulási megoldásaik értékének növelésében az AWS-ben. A Kanwaljit arra specializálódott, hogy segítse az ügyfeleket konténeres, elosztott számítástechnikai és mély tanulási alkalmazásokban.
Kanwaljit Khurmi az Amazon Web Services fő AI/ML megoldások építésze. Együttműködik az AWS-ügyfelekkel, hogy útmutatást és technikai segítséget nyújtson, segítve őket gépi tanulási megoldásaik értékének növelésében az AWS-ben. A Kanwaljit arra specializálódott, hogy segítse az ügyfeleket konténeres, elosztott számítástechnikai és mély tanulási alkalmazásokban.
 Alex Iankoulski az AWS saját menedzselt gépi tanulási részlegének vezető megoldástervezője. Ő egy full-stack szoftver- és infrastruktúramérnök, aki szeret mélyreható, gyakorlatias munkát végezni. Munkájában arra összpontosít, hogy segítse az ügyfeleket az ML és AI munkaterhelések konténerezésében és összehangolásában a konténeralapú AWS szolgáltatásokon. Ő a nyílt forráskód szerzője is keretet készíteni és egy Docker kapitány, aki szereti a konténertechnológiák alkalmazását az innováció ütemének felgyorsítására, miközben megoldja a világ legnagyobb kihívásait.
Alex Iankoulski az AWS saját menedzselt gépi tanulási részlegének vezető megoldástervezője. Ő egy full-stack szoftver- és infrastruktúramérnök, aki szeret mélyreható, gyakorlatias munkát végezni. Munkájában arra összpontosít, hogy segítse az ügyfeleket az ML és AI munkaterhelések konténerezésében és összehangolásában a konténeralapú AWS szolgáltatásokon. Ő a nyílt forráskód szerzője is keretet készíteni és egy Docker kapitány, aki szereti a konténertechnológiák alkalmazását az innováció ütemének felgyorsítására, miközben megoldja a világ legnagyobb kihívásait.
 Ana Simoes az AWS ML Frameworks fő gépi tanulási szakértője. Támogatja az AI-t, az ML-t és a generatív AI-t nagy léptékben telepítő ügyfeleket a felhőben található HPC-infrastruktúrán. Az Ana arra összpontosít, hogy támogassa az ügyfeleket abban, hogy ár-teljesítményt érjenek el az új munkaterhelésekhez, valamint a generatív mesterséges intelligencia és a gépi tanulás használatához.
Ana Simoes az AWS ML Frameworks fő gépi tanulási szakértője. Támogatja az AI-t, az ML-t és a generatív AI-t nagy léptékben telepítő ügyfeleket a felhőben található HPC-infrastruktúrán. Az Ana arra összpontosít, hogy támogassa az ügyfeleket abban, hogy ár-teljesítményt érjenek el az új munkaterhelésekhez, valamint a generatív mesterséges intelligencia és a gépi tanulás használatához.
 Hamid Shojanazeri a PyTorch partnermérnöke, aki nyílt forráskódú, nagy teljesítményű modelloptimalizáláson, elosztott képzéseken dolgozik (FSDP), és következtetés. Ő a társteremtője láma-recept és közreműködője TorchServe. Fő érdeke a költséghatékonyság javítása, hogy a mesterséges intelligencia elérhetőbbé váljon a szélesebb közösség számára.
Hamid Shojanazeri a PyTorch partnermérnöke, aki nyílt forráskódú, nagy teljesítményű modelloptimalizáláson, elosztott képzéseken dolgozik (FSDP), és következtetés. Ő a társteremtője láma-recept és közreműködője TorchServe. Fő érdeke a költséghatékonyság javítása, hogy a mesterséges intelligencia elérhetőbbé váljon a szélesebb közösség számára.
 Kevesebb Wright AI/partnermérnök a PyTorch-ban. Triton/CUDA kerneleken dolgozik (Dequant gyorsítása SplitK munkabontással); lapozott, streaming és kvantált optimalizálók; és PyTorch Distributed (PyTorch FSDP).
Kevesebb Wright AI/partnermérnök a PyTorch-ban. Triton/CUDA kerneleken dolgozik (Dequant gyorsítása SplitK munkabontással); lapozott, streaming és kvantált optimalizálók; és PyTorch Distributed (PyTorch FSDP).
- SEO által támogatott tartalom és PR terjesztés. Erősödjön még ma.
- PlatoData.Network Vertical Generative Ai. Erősítse meg magát. Hozzáférés itt.
- PlatoAiStream. Web3 Intelligence. Felerősített tudás. Hozzáférés itt.
- PlatoESG. Carbon, CleanTech, Energia, Környezet, Nap, Hulladékgazdálkodás. Hozzáférés itt.
- PlatoHealth. Biotechnológiai és klinikai vizsgálatok intelligencia. Hozzáférés itt.
- Forrás: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

