Nykyaikaisille yrityksille, jotka käsittelevät valtavia määriä asiakirjoja, kuten sopimuksia, laskuja, ansioluetteloita ja raportteja, asianmukaisten tietojen tehokas käsittely ja haku on ratkaisevan tärkeää kilpailuedun säilyttämiseksi. Perinteiset menetelmät asiakirjojen tallentamiseen ja etsimiseen voivat kuitenkin olla aikaa vieviä ja johtavat usein suureen vaivaan tietyn asiakirjan löytämiseen, varsinkin kun niihin sisältyy käsinkirjoitusta. Entä jos olisi tapa käsitellä asiakirjoja älykkäästi ja tehdä niistä haettavissa suurella tarkkuudella?
Tämä on mahdollista Amazonin teksti, AWS:n älykäs asiakirjojen käsittelypalvelu yhdistettynä nopeisiin hakuominaisuuksiin opensearch. Tässä viestissä viemme sinut matkalle, jolla voit nopeasti rakentaa ja ottaa käyttöön dokumenttihaun indeksointiratkaisun, joka auttaa organisaatiotasi hyödyntämään asiakirjoja paremmin ja poimimaan niistä oivalluksia.
Olitpa henkilöstöosastolla, joka etsii tiettyjä lausekkeita työntekijäsopimuksista tai talousanalyytikko, joka seuloa laskuja maksutietojen poimimiseksi, tämä ratkaisu on räätälöity antamaan sinulle mahdollisuuden saada tarvitsemasi tiedot ennennäkemättömän nopeasti ja tarkasti.
Ehdotetun ratkaisun avulla asiakirjasi syötetään automaattisesti, niiden sisältö jäsennetään ja sen jälkeen indeksoidaan erittäin reagoivaksi ja skaalautuvaksi OpenSearch-hakemistoksi.
Kerromme, kuinka tekniikat, kuten Amazon Textract, AWS Lambda, Amazonin yksinkertainen tallennuspalvelu (Amazon S3) ja Amazon OpenSearch-palvelu voidaan integroida työnkulkuun, joka käsittelee asiakirjoja saumattomasti. Sitten sukeltamme näiden tietojen indeksoimiseen OpenSearchiin ja esittelemme hakuominaisuuksia, jotka ovat käytettävissäsi.
Olipa organisaatiosi ottamassa ensimmäisiä askelia digitaalisen muutoksen aikakauteen tai vakiintunut jättiläinen, joka pyrkii tehostamaan tiedonhakua, tämä opas on kompassi, jonka avulla voit navigoida AWS Intelligent Document Processingin ja OpenSearchin tarjoamissa mahdollisuuksissa.
- täytäntöönpano käytetty tässä viestissä käyttää Amazon Textract IDP CDK -konstruktit – AWS Cloud Development Kit (CDK) -komponentit Intelligent Document Processing (IDP) -työnkulkujen infrastruktuurin määrittämiseen – joiden avulla voit rakentaa käyttötapauskohtaisia mukautettavia IDP-työnkulkuja. IDP CDK -konstruktit ja näytteet ovat kokoelma komponentteja, jotka mahdollistavat IDP-prosessien määrittämisen AWS:ssä ja julkaistuja GitHub. Pääasialliset käytetyt käsitteet ovat AWS Cloud Development Kit (CDK) rakenteita, todellista CDK-pinot ja AWS-vaihetoiminnot. Työpaja Käytä koneoppimista asiakirjojen automatisointiin ja käsittelyyn mittakaavassa on hyvä lähtökohta oppia lisää työnkulkujen mukauttamisesta ja muiden mallityönkulkujen käyttämisestä oman perustasi.
Ratkaisun yleiskatsaus
Tässä ratkaisussa keskitymme asiakirjojen indeksointiin OpenSearch-hakemistoon tietojen ja asiakirjojen nopeaa hakua ja hakua varten. PDF-, TIFF-, JPEG- tai PNG-muodossa olevat asiakirjat laitetaan Amazon Simple Storage Service -palveluun (Amazon S3) segmenttiin ja indeksoidaan sitten OpenSearchiin käyttämällä tätä Step Functions -työnkulkua.

Kuva 1: Step Functions OpenSearch-työnkulku
- OpenSearchWorkflow-Decider tarkastelee asiakirjaa ja varmistaa, että asiakirja on yksi tuetuista mime-tyypeistä (PDF, TIFF, PNG tai JPEG). Se koostuu yhdestä AWS Lambda toiminto.
- Asiakirjanjakaja tuottaa enintään 2500 sivun osan asiakirjoista. Tämä tarkoittaa, että vaikka Amazon Textract tukee jopa 3000-sivuisia asiakirjoja, voit välittää asiakirjoja, joissa on paljon enemmän sivuja, ja prosessi toimii silti hyvin ja asettaa sivut OpenSearchiin ja luo oikeat sivunumerot. The Asiakirjanjakaja on toteutettu AWS Lambda -toimintona.
- Karttatila käsittelee jokaista palaa rinnakkain.
- TextractAsync tehtävä kutsuu Amazon Textractia käyttämällä asynkronista Sovellusohjelmointirajapinta (API) seuraavat parhaat käytännöt Amazon Simple Notification Service -palvelun avulla (Amazon SNS) ilmoitukset ja OutputConfig tallentaa Amazon Textract JSON -tulosteen asiakkaan Amazon S3 -ämpäriin. Se koostuu kahdesta Amazon Lambda -toiminnosta: toinen lähettää asiakirjan käsittelyyn ja toinen käynnistää Amazon SNS -ilmoituksen.
Koska TextractAsync-tehtävä voi tuottaa useita sivutettuja tulostustiedostoja TextractAsyncToJSON2 prosessi yhdistää ne yhdeksi JSON-tiedostoksi.
Step Functions -konteksti on rikastettu tiedolla, jonka pitäisi olla myös haettavissa OpenSearch-hakemistosta AsetaMetaData askel. Esimerkkitoteutus lisää ORIGIN_FILE_NAME, START_PAGE_NUMBERja ORIGIN_FILE_URI. Voit lisätä mitä tahansa tietoja rikastuttaaksesi hakukokemusta, kuten tietoja muista taustajärjestelmistä, tiettyjä tunnuksia tai luokitustietoja.
- GenerateOpenSearchBatch ottaa luodun Amazon Textract -tulosteen JSONin, yhdistää sen SetMetaDatan asettaman kontekstin tietoihin ja valmistelee tiedoston, joka on optimoitu erätuontiin OpenSearchiin.
In OpenSearchPushInvoke, tämä erätuontitiedosto lähetetään OpenSearch-hakemistoon ja on haettavissa. Tämä AWS Lambda -toiminto on yhdistetty aws-lambda-opensearch rakentaa alkaen AWS-ratkaisut kirjasto käyttäen m6g.large.search-esiintymiä, OpenSearch-versiota 2.7 ja määrittänyt Amazon Elastic Block Servicen (Amazon EBS). Voit muuttaa OpenSearch-asetuksia tarpeidesi mukaan.
Viimeinen TaskOpenSearchMapping vaihe tyhjentää kontekstin, joka muuten voisi ylittää Vaihetoimintojen kiintiö of Tehtävän, tilan tai suorituksen tulo- tai tulosten enimmäiskoko.
Edellytykset
Jotta voit ottaa näytteitä käyttöön, tarvitset AWS-tilin AWS Cloud Development Kit (AWS CDK), vaaditaan nykyinen Python-versio ja Docker. Tarvitset luvat ottaaksesi käyttöön AWS CloudFormation -malleja, siirry kohtaan Amazonin elastisten säiliörekisteri (Amazon ECR), luo Amazon Identity and Access Management (AWS IAM) -roolit, Amazon Lambda -toiminnot, Amazon S3 -ämpärit, Amazon Step Functions, Amazon OpenSearch -klusteri ja Amazon Cognito käyttäjäpooli. Varmista, että sinun AWS CLI -ympäristö on määritetty vastaavilla luvilla.
Voit myös pyörittää a AWS-pilvi9 ilmentymä, jossa on esiasennettu AWS CDK, Python ja Docker käyttöönoton aloittamiseksi.
Walkthrough
käyttöönoton
- Kun olet asettanut edellytykset, sinun on ensin kloonattava arkisto:
- Aseta sitten cd arkistokansioon ja asenna riippuvuudet:
- Ota OpenSearchWorkflow-pino käyttöön:
Käyttöönotto kestää noin 25 minuuttia GitHub-näytteistä saatujen oletusasetusten kanssa, ja se luo Step Functions -työnkulun, joka käynnistyy, kun asiakirja asetetaan Amazon S3 -säilöön/etuliitteelle ja jota käsitellään myöhemmin, kunnes dokumentin sisältö on indeksoitu. OpenSearch-klusterissa.
Seuraava on esimerkkituloste, joka sisältää hyödyllisiä linkkejä ja tietoja, jotka on luotucdk deploy OpenSearchWorkflowkomento:
Nämä tiedot ovat saatavilla myös AWS CloudFormation Consolessa.
Kun uusi asiakirja asetetaan alle OpenSearchWorkflow.DocumentUploadLocation, uusi Step Functions -työnkulku aloitetaan tälle asiakirjalle.
Voit tarkistaa tämän asiakirjan tilan valitsemalla OpenSearchWorkflow.StepFunctionFlowLink tarjoaa linkin StepFunction-suoritusten luetteloon AWS-hallintakonsolissa, joka näyttää kunkin Amazon S3:een ladatun asiakirjan asiakirjankäsittelyn tilan. Opetusohjelma Suoritusten katselu ja virheenkorjaus Step Functions -konsolissa tarjoaa yleiskatsauksen AWS-konsolin komponenteista ja näkymistä.
Testaus
- Ensimmäinen testi käyttämällä mallitiedostoa.
- Kun olet valinnut linkin StepFunction-työnkulkuun tai avannut AWS-hallintakonsolin ja siirtynyt Step Functions -palvelusivulle, voit tarkastella erilaisia työnkulkukutsuja.

Kuva 2: Vaihetoimintojen suoritusluettelo
- Katso parhaillaan käynnissä olevaa esimerkkiasiakirjan suoritusta, josta voit seurata yksittäisten työnkulun tehtävien suorittamista.
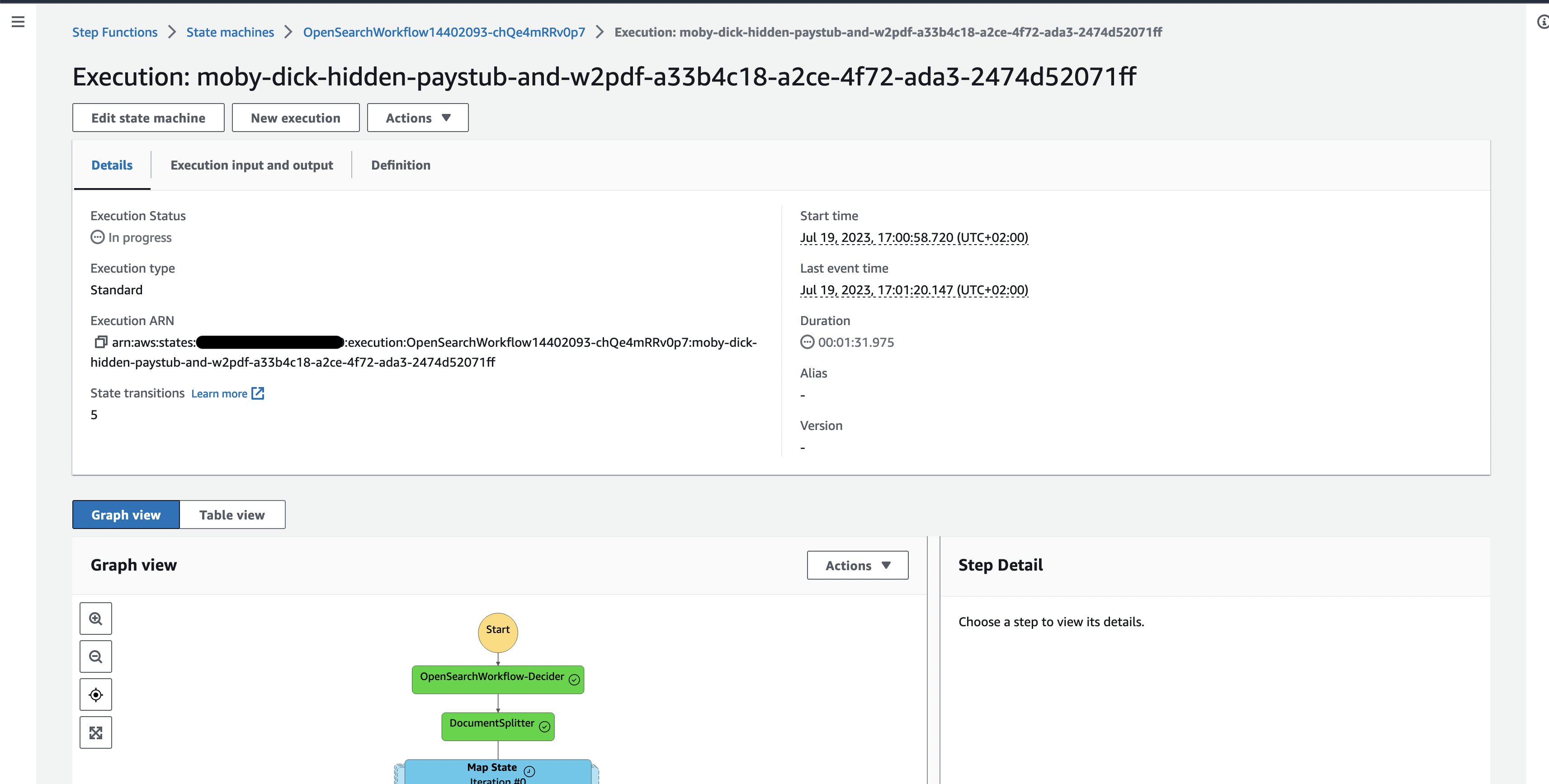
Kuva 3: Yhden asiakirjan Vaihetoimintojen työnkulun suoritus
Haku
Kun prosessi on valmis, voimme vahvistaa, että asiakirja on indeksoitu OpenSearch-hakemistoon.
- Tätä varten luomme ensin Amazon Cognito -käyttäjän. Amazon Cognitoa käytetään käyttäjien todentamiseen OpenSearch-indeksiä vastaan. Valitse linkki cdk-käyttöönoton tulosteessa (tai katso AWS-pilven muodostuminen lähtö AWS-hallintakonsolissa) nimetty OpenSearchWorkflow.CognitoUserPoolLink.

Kuva 4: Cogniton käyttäjäryhmä
- Valitse sitten Luo käyttäjä -painiketta, joka ohjaa sinut sivulle, jossa voit syöttää käyttäjänimen ja salasanan OpenSearch-hallintapaneeliin pääsyä varten.

Kuva 5: Cognito-käyttäjän luontivalintaikkuna
- Valinnan jälkeen Luo käyttäjä, voit jatkaa OpenSearch Dashboardiin napsauttamalla OpenSearchWorkflow.OpenSearchDashboard CDK:n käyttöönottotulosta. Kirjaudu sisään aiemmin luodulla käyttäjätunnuksella ja salasanalla. Kun kirjaudut sisään ensimmäisen kerran, sinun on vaihdettava salasana.
- Kun olet kirjautunut OpenSearch Dashboardiin, valitse Pinon hallinta osio, jota seuraa Indeksikuvios luodaksesi hakuhakemiston.

Kuva 6: OpenSearch Dashboards pinon hallinta

Kuva 7: OpenSearch-hakemistomallien yleiskatsaus
- Indeksin oletusnimi on paperit-indeksi ja indeksikuvion nimi paperit-indeksi* vastaa sitä.
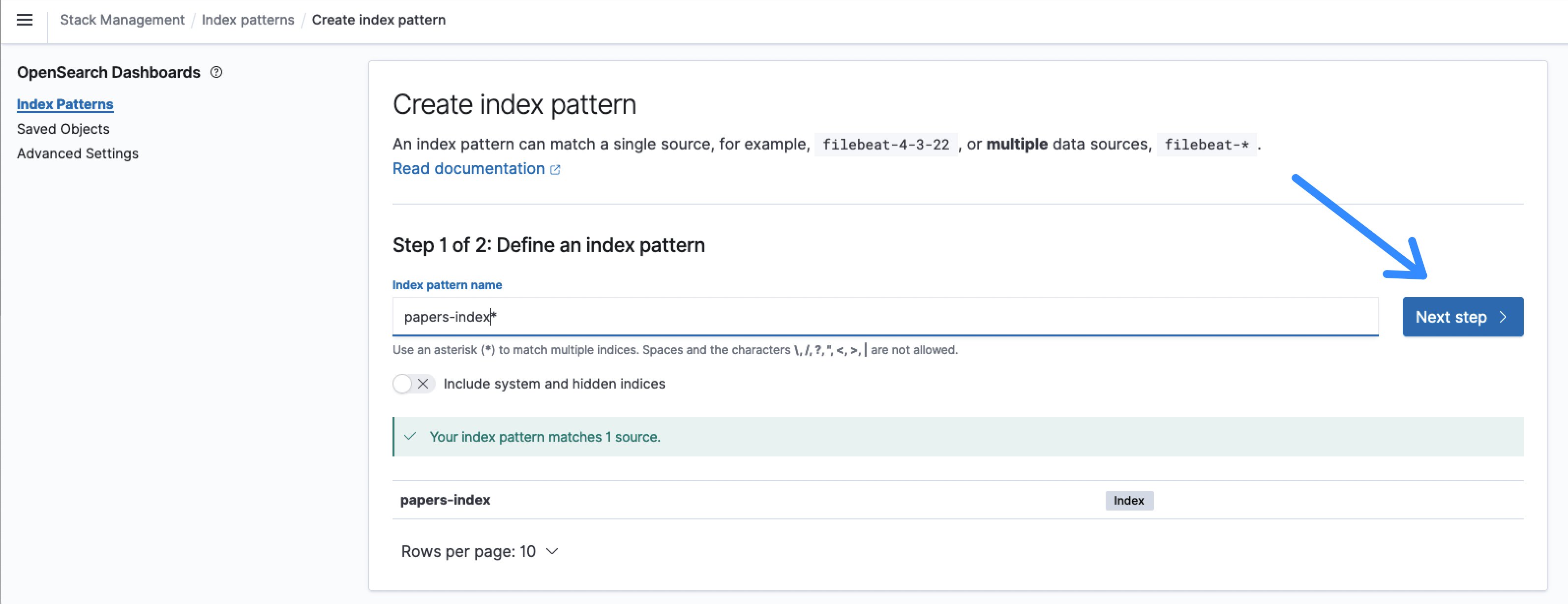
Kuva 8: Määritä OpenSearch-indeksikuvio
- Napsautuksen jälkeen Seuraava askelvalitse aikaleima kuten Aikakenttä ja Luo hakemistokuvio.

Kuva 9: OpenSearch-indeksikuvion aikakenttä
- Valitse nyt valikosta Tutustu.
Kuva 10: OpenSearch Discover
Useimmissa tapauksissa sinun on muutettava aikajaksoa viimeisimmän annoksesi mukaan. Oletusarvo on 15 minuuttia, ja usein ei ole ollut toimintaa viimeisen 15 minuutin aikana. Tässä esimerkissä se muuttui 15 päiväksi nielemisen visualisoimiseksi.

Kuva 11: OpenSearchin aikajänteen muutos
- Nyt voit aloittaa etsimisen. Romaani indeksoitiin, voit etsiä mitä tahansa termejä, kuten kutsu minua Ismaeliksi ja katso tulokset.

Kuva 12: OpenSearch-hakutermi
Tässä tapauksessa termi kutsu minua Ismaeliksi näkyy asiakirjan sivulla 6 annetulla Uniform Resource Identifier -tunnisteella (URI), joka osoittaa tiedoston Amazon S3 -sijaintiin. Tämä tekee asiakirjojen tunnistamisesta ja tiedon löytämisestä nopeampaa suuresta PDF-, TIFF- tai kuvatiedostokokonaisuudesta verrattuna niiden manuaaliseen ohittamiseen.
Juoksemassa mittakaavassa
Indeksointiprosessin mittakaavan ja keston arvioimiseksi toteutusta testattiin 93,997 1,583,197 dokumentilla ja yhteensä 16.84 3755 5.5 sivulla (keskimäärin 1 sivua/asiakirja ja suurimmassa tiedostossa XNUMX sivua), jotka kaikki indeksoitiin OpenSearchiin. Kaikkien tiedostojen käsittely ja indeksointi OpenSearchiin kesti XNUMX tuntia USA:n itäosassa (N. Virginia – us-east-XNUMX) oletusarvolla Amazon Textract -palvelukiintiöt. Alla olevassa kaaviossa näkyy ensimmäinen testi klo 18, jota seuraa pääannos klo 00 ja kaikki tehty klo 21 mennessä.

Kuva 13: OpenSearch-indeksoinnin yleiskatsaus
Käsittelyä varten tcdk.SFExecutionsStartThrottle asetettiin an executions_concurrency_threshold=550, mikä tarkoittaa, että samanaikaisten asiakirjojen käsittelyn työnkulkujen enimmäismäärä on 550 ja ylimääräiset pyynnöt asetetaan jonoon Amazonin SQS Fist-In-First-Out (FIFO) -jono, joka tyhjennetään, kun nykyiset työnkulut päättyvät. Kynnys 550 perustuu Textract Servicen 600 kiintiöön us-east-1 -alueella. Siksi vanhimman viestin jonon syvyys ja ikä ovat seurannan arvoisia mittareita.

Kuva 14: Amazon SQS -valvonta
Tässä testissä kaikki asiakirjat ladattiin Amazon S3:lle kerralla, joten Näkyvissä olevien viestien arvioitu määrä on jyrkkä nousu ja sitten hidas lasku, koska uusia asiakirjoja ei ole käsitelty. The Vanhimman viestin arvioitu ikä kasvaa, kunnes kaikki viestit on käsitelty. Amazon SQS MessageRetentionPeriod on asetettu 14 päivään. Jos kyseessä on erittäin pitkä ruuhkakäsittely, joka voi kestää yli 14 päivää, aloita pienemmällä osajoukolla edustavia asiakirjoja ja seuraa suorituksen kestoa arvioidaksesi, kuinka monta asiakirjaa voit siirtää ennen kuin 14 päivää ylittää. Amazon SQS CloudWatch -mittarit näyttävät samanlaisilta käyttötapauksessa, jossa käsitellään suuria asiakirjoja, jotka käsitellään kerralla ja käsitellään sitten kokonaan. Jos käyttötapasi on tasainen asiakirjojen virta, molemmat mittarit, Näkyvissä olevien viestien arvioitu määrä ja Vanhimman viestin arvioitu ikä tulee olemaan lineaarisempi. Voit myös käyttää kynnysparametria sekoittaaksesi tasaisen kuorman ruuhkan käsittelyyn ja allokoidaksesi kapasiteettia käsittelytarpeiden mukaan.
Toinen seurattava mittari on OpenSearch-klusterin kunto, joka sinun tulee määrittää Operatiiviset parhaat käytännöt Amazon OpenSearch Servicelle. Oletuskäyttöönotto käyttää m6g.large.search -esiintymiä.
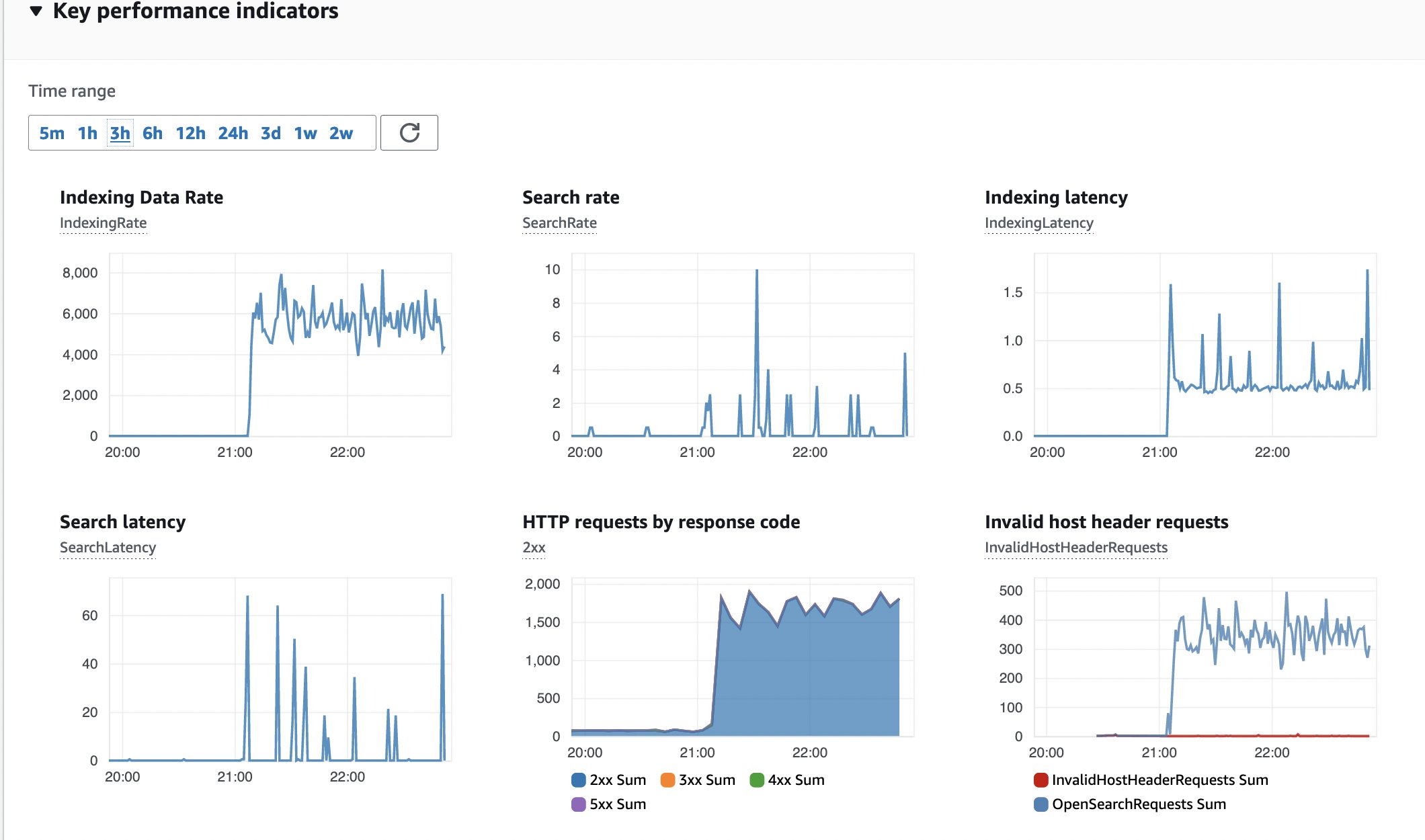
Kuva 15: OpenSearch-valvonta
Tässä on tilannekuva OpenSearch-klusterin tärkeimmistä suorituskykyindikaattoreista (KPI). Ei virheitä, jatkuva indeksoinnin datanopeus ja latenssi.
Step Functions -työnkulun suoritukset näyttävät kunkin yksittäisen asiakirjan käsittelyn tilan. Jos näet teloituksia Epäonnistui tila ja valitse sitten tiedot. Hyvä seurantamittari on AWS CloudWatch automaattinen hallintapaneeli Step Functionsille, joka paljastaa osan Vaihetoiminnot CloudWatch-mittarit.

Kuva 16: Step Functions -seurannan suoritukset onnistuivat
Tässä AWS CloudWatch Dashboard -kaaviossa näet onnistuneet Step Functions -suoritukset ajan mittaan.
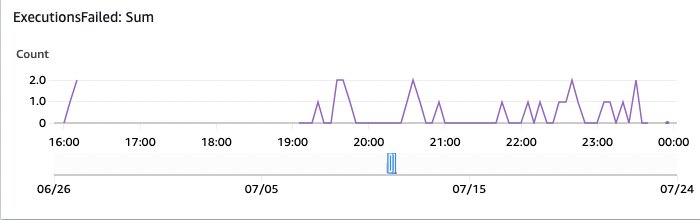
Kuva 17: OpenSearch-valvontasuoritukset epäonnistuivat
Ja tämä osoittaa epäonnistuneet teloitukset. Näitä kannattaa tutkia AWS-konsolin vaihetoimintojen yleiskatsauksen kautta.
Seuraavassa kuvakaappauksessa on esimerkki epäonnistuneesta suorituksesta, koska alkuperätiedoston koko on 0, mikä on järkevää, koska tiedostolla ei ole sisältöä eikä sitä voitu käsitellä. On tärkeää suodattaa epäonnistuneet prosessit ja visualisoida viat, jotta voit palata lähdeasiakirjaan ja vahvistaa perimmäisen syyn.
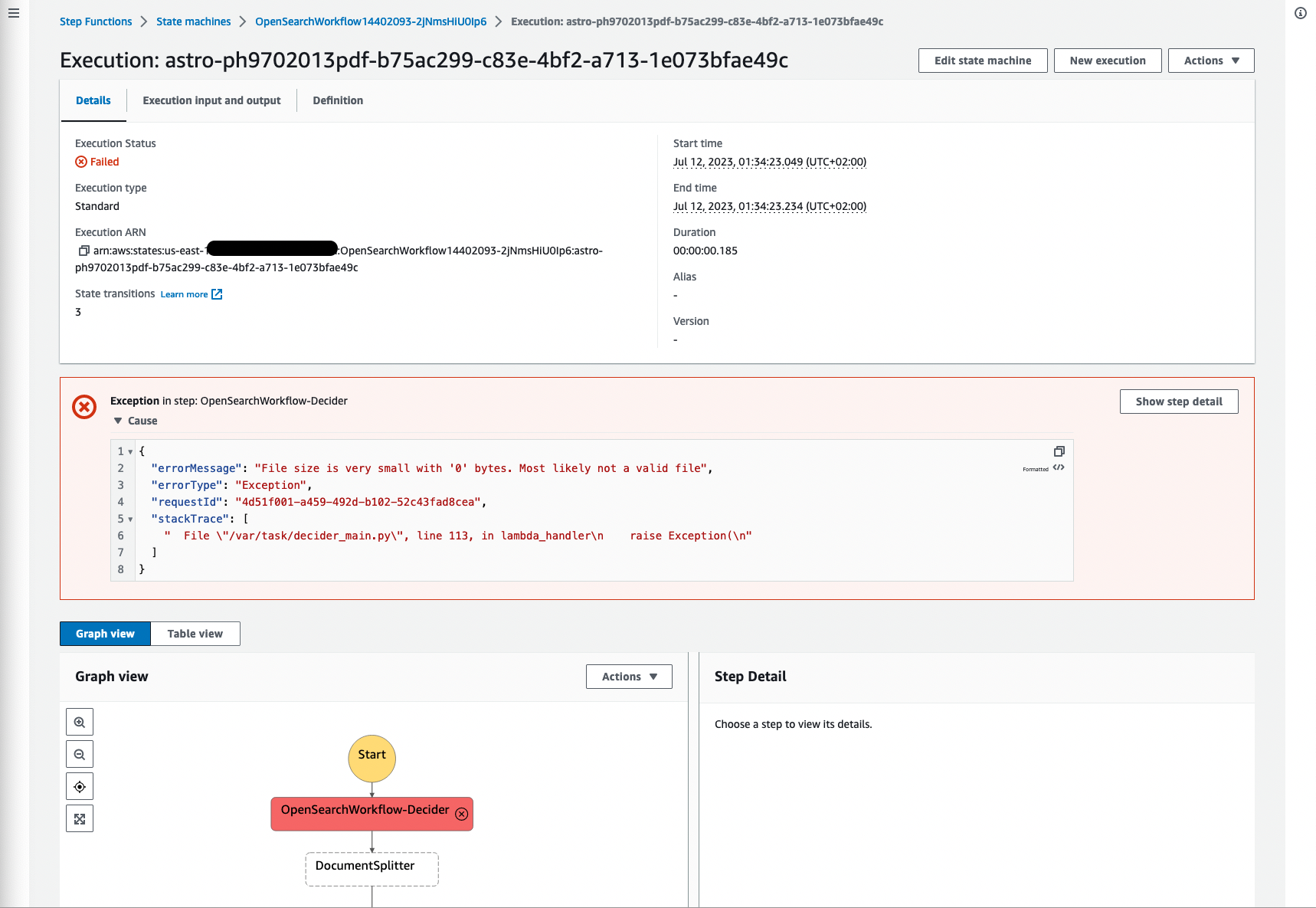
Kuva 18: Step Functions -työnkulku epäonnistui
Muita vikoja voivat olla dokumentit, jotka eivät ole MIME-tyyppisiä: application/pdf, image/png, image/jpeg tai image/tiff, koska Amazon Textract ei tue muita asiakirjatyyppejä.
Hinta
1,583,278 XNUMX XNUMX sivun käsittelyn kokonaiskustannukset jaettiin toteutuksessa käytettyjen AWS-palvelujen kesken. Seuraava luettelo on likimääräisiä lukuja, koska todelliset kustannukset ja käsittelyn kesto vaihtelevat asiakirjojen koon, asiakirjan sivumäärän, asiakirjojen tietojen tiheyden ja AWS-alueen mukaan. Amazon DynamoDB kulutti 0.55 dollaria, Amazon S3 3.33 dollaria, OpenSearch Service 14.71 dollaria, Step Functions 17.92 dollaria, AWS Lambda 28.95 dollaria ja Amazon Textract 1,849.97 XNUMX dollaria. Muista myös, että käyttöön otettu Amazon OpenSearch Service -klusteri laskutetaan tuntikohtaisesti ja siitä kertyy korkeampia kustannuksia, kun sitä käytetään tietyn ajanjakson aikana.
Muutokset
Todennäköisesti haluat muokata toteutusta ja mukauttaa käyttötapaustasi ja asiakirjojasi vastaavaksi. Työpaja Käytä koneoppimista asiakirjojen automatisointiin ja käsittelyyn mittakaavassa tarjoaa hyvän yleiskatsauksen todellisten työnkulkujen manipuloinnista, kulun muuttamisesta ja uusien komponenttien lisäämisestä. Jos haluat lisätä mukautettuja kenttiä OpenSearch-hakemistoon, katso AsetaMetaData tehtävä työnkulussa käyttämällä set-manifest-meta-data-opensearch AWS Lambda -toiminto lisää kontekstiin metatietoja, jotka lisätään kenttään OpenSearch-hakemistoon. Kaikista metatietotiedoista tulee osa hakemistoa.
Puhdistaa
Poista esimerkkiresurssit, jos et enää tarvitse niitä välttääksesi tulevia kustannuksia käyttämällä seuraavaa ind-komentoa:
samassa ympäristössä kuin cdk deploy komento. Varo, että tämä poistaa kaiken, mukaan lukien OpenSearch-klusterin ja kaikki asiakirjat sekä Amazon S3 -ämpäri. Jos haluat säilyttää nämä tiedot, varmuuskopioi Amazon S3 -ämpärisi ja Luo indeksivedos OpenSearch-klusteristasi. Jos olet käsitellyt useita tiedostoja, saatat joutua tyhjentämään Amazon S3 -säilöä ensin AWS-hallintakonsolin avulla (eli sen jälkeen, kun olet ottanut varmuuskopion tai synkronoinut ne toiseen säilöön, jos haluat säilyttää tiedot), koska puhdistustoiminto voi aikakatkaista ja sitten tuhota AWS CloudFormation -pinon.
Yhteenveto
Tässä viestissä näytimme sinulle, kuinka voit ottaa käyttöön täyden pinon ratkaisun suuren määrän asiakirjoja syöttämiseksi OpenSearch-hakemistoon, jotka ovat valmiita käytettäväksi haun käyttötapauksissa. Keskusteltiin toteutuksen yksittäisistä komponenteista sekä skaalausnäkökohdista, kustannuksista ja muutosvaihtoehdoista. Kaikki koodi on käytettävissä OpenSource-muodossa GitHubissa IDP CDK -näytteet ja kuten IDP CDK -konstruktit rakentaa omia ratkaisujasi tyhjästä. Seuraavana vaiheena voit alkaa muokata työnkulkua, lisätä tietoja hakuhakemiston asiakirjoihin ja tutkia IDP työpaja. Kommentoi alle kokemuksistasi ja ideoistasi nykyisen ratkaisun laajentamiseksi.
kirjailijasta
 Martin Schade on Senior ML Product SA Amazon Textract -tiimin kanssa. Hänellä on yli 20 vuoden kokemus Internetiin liittyvistä teknologioista, suunnittelusta ja arkkitehtiratkaisuista. Hän liittyi AWS:ään vuonna 2014 ja opasti ensin eräitä suurimmista AWS-asiakkaista AWS-palvelujen tehokkaimpaan ja skaalautuvimpaan käyttöön, ja myöhemmin keskittyi tekoälyyn/ML:ään keskittyen tietokonenäköön. Tällä hetkellä hän on pakkomielle tietojen poimimisesta asiakirjoista.
Martin Schade on Senior ML Product SA Amazon Textract -tiimin kanssa. Hänellä on yli 20 vuoden kokemus Internetiin liittyvistä teknologioista, suunnittelusta ja arkkitehtiratkaisuista. Hän liittyi AWS:ään vuonna 2014 ja opasti ensin eräitä suurimmista AWS-asiakkaista AWS-palvelujen tehokkaimpaan ja skaalautuvimpaan käyttöön, ja myöhemmin keskittyi tekoälyyn/ML:ään keskittyen tietokonenäköön. Tällä hetkellä hän on pakkomielle tietojen poimimisesta asiakirjoista.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. Autot / sähköautot, hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- ChartPrime. Nosta kaupankäyntipeliäsi ChartPrimen avulla. Pääsy tästä.
- BlockOffsets. Ympäristövastuun omistuksen nykyaikaistaminen. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/implement-smart-document-search-index-with-amazon-textract-and-amazon-opensearch/

