Suuret kielimallit (LLM) opetetaan yleensä suurilla julkisesti saatavilla olevilla tietojoukoilla, jotka ovat toimialueen agnostikkoja. Esimerkiksi, Metan laama malleja koulutetaan tietojoukkojen, kuten CommonCrawl, C4, Wikipedia ja ArXiv. Nämä tietojoukot kattavat laajan valikoiman aiheita ja verkkotunnuksia. Vaikka tuloksena saadut mallit tuottavat hämmästyttävän hyviä tuloksia yleisiin tehtäviin, kuten tekstin luomiseen ja entiteetin tunnistamiseen, on näyttöä siitä, että verkkoaluekohtaisilla tietojoukoilla koulutetut mallit voivat parantaa LLM:n suorituskykyä entisestään. Esimerkiksi käytettävät harjoitustiedot BloombergGPT on 51 % verkkotunnuskohtaisista asiakirjoista, mukaan lukien talousuutiset, ilmoitukset ja muu talousmateriaali. Tuloksena oleva LLM on parempi kuin LLM:t, jotka on koulutettu ei-verkkoaluekohtaisiin tietojoukoihin, kun niitä testataan talouskohtaisissa tehtävissä. Tekijät BloombergGPT totesi, että heidän mallinsa suoriutuu paremmin kuin kaikki muut mallit, jotka testattiin neljässä viidestä taloustehtävästä. Malli tarjosi vielä paremman suorituskyvyn, kun sitä testattiin Bloombergin sisäisissä taloustehtävissä laajalla marginaalilla – jopa 60 pistettä parempi (100:sta). Vaikka voit oppia lisää kattavasta arvioinnin tuloksista paperi, seuraava näyte otettu kohteesta BloombergGPT Paperi voi antaa sinulle välähdyksen eduista, joita saadaan, kun LLM:itä koulutetaan käyttämällä talousaluekohtaisia tietoja. Kuten esimerkissä näkyy, BloombergGPT-malli antoi oikeat vastaukset, kun taas muut ei-verkkotunnuskohtaiset mallit vaikeuksissa:
Tämä viesti tarjoaa oppaan LLM:ien kouluttamiseen erityisesti rahoitusalalla. Katamme seuraavat avainalueet:
- Tiedonkeruu ja valmistelu – Ohjeita asiaankuuluvien taloustietojen hankintaan ja kuratointiin tehokkaan mallikoulutuksen varmistamiseksi
- Jatkuva esikoulutus vs. hienosäätö – Milloin käyttää kutakin tekniikkaa LLM:n suorituskyvyn optimoimiseksi
- Tehokas jatkuva esikoulutus – Strategiat jatkuvan esikoulutusprosessin virtaviivaistamiseksi, mikä säästää aikaa ja resursseja
Tämä viesti kokoaa yhteen Amazon Finance Technologyn soveltavan tieteen tutkimusryhmän ja AWS:n maailmanlaajuisen rahoitusalan asiantuntijaryhmän asiantuntemuksen. Osa sisällöstä perustuu paperiin Tehokas jatkuva esikoulutus verkkotunnuskohtaisten suurten kielimallien luomiseen.
Taloustietojen kerääminen ja valmistelu
Verkkotunnuksen jatkuva esikoulutus vaatii laajan, laadukkaan, toimialuekohtaisen tietojoukon. Seuraavat ovat verkkotunnuksen tietojoukon kuraation päävaiheet:
- Tunnista tietolähteet – Verkkotunnuskorpuksen mahdollisia tietolähteitä ovat avoin verkko, Wikipedia, kirjat, sosiaalinen media ja sisäiset asiakirjat.
- Verkkotunnuksen tietosuodattimet – Koska perimmäisenä tavoitteena on kuratoida verkkotunnuskorpusta, saatat joutua suorittamaan lisävaiheita suodattaaksesi pois näytteet, jotka eivät ole merkityksellisiä kohdeverkkotunnuksen kannalta. Tämä vähentää hyödytöntä aineistoa jatkuvalle esikoulutukselle ja alentaa koulutuskustannuksia.
- esikäsittely – Voit harkita sarjan esikäsittelyvaiheita tietojen laadun ja koulutuksen tehokkuuden parantamiseksi. Esimerkiksi tietyt tietolähteet voivat sisältää melkoisen määrän meluisia tokeneita; duplikointia pidetään hyödyllisenä askeleena tiedon laadun parantamiseksi ja koulutuskustannusten vähentämiseksi.
Taloudellisten LLM-yritysten kehittämiseen voit käyttää kahta tärkeää tietolähdettä: News CommonCrawl- ja SEC-tiedostot. SEC-hakemus on rahoitusselvitys tai muu virallinen asiakirja, joka toimitetaan Yhdysvaltain arvopaperi- ja pörssiviranomaiselle (SEC). Pörssiyhtiöiden on toimitettava säännöllisesti erilaisia asiakirjoja. Tämä luo vuosien varrella suuren määrän asiakirjoja. News CommonCrawl on CommonCrawlin vuonna 2016 julkaisema tietojoukko. Se sisältää uutisartikkeleita uutissivustoilta ympäri maailmaa.
News CommonCrawl on saatavilla osoitteessa Amazonin yksinkertainen tallennuspalvelu (Amazon S3) sisällä commoncrawl ämpäri klo crawl-data/CC-NEWS/. Voit saada tiedostoluettelot käyttämällä AWS-komentoriviliitäntä (AWS CLI) ja seuraava komento:
In Tehokas jatkuva esikoulutus verkkotunnuskohtaisten suurten kielimallien luomiseen, kirjoittajat käyttävät URL- ja avainsanapohjaista lähestymistapaa talousuutisten suodattamiseen yleisistä uutisista. Erityisesti kirjoittajat ylläpitävät luetteloa tärkeistä talousuutisten toimipisteistä ja joukko talousuutisiin liittyviä avainsanoja. Tunnistamme artikkelin talousuutiseksi, jos se tulee talousuutisista tai jos URL-osoitteessa näkyy avainsanoja. Tämän yksinkertaisen mutta tehokkaan lähestymistavan avulla voit tunnistaa talousuutisia paitsi talousuutisten lisäksi myös yleisten uutispisteiden rahoitusosastoista.
SEC-ilmoitukset ovat saatavilla verkossa SEC:n EDGAR (Electronic Data Gathering, Analysis, and Retrieval) -tietokannan kautta, joka tarjoaa avoimen pääsyn tietoihin. Voit kaapata tiedot suoraan EDGARista tai käyttää sovellusliittymiä Amazon Sage Maker muutamalla rivillä koodia, mille tahansa ajanjaksolle ja suurelle määrälle tickertejä (eli SEC:lle määritetty tunniste). Lisätietoja saat osoitteesta SEC-tiedostojen haku.
Seuraavassa taulukossa on yhteenveto molempien tietolähteiden tärkeimmistä yksityiskohdista.
| . | Uutiset CommonCrawl | SEC-arkistointi |
| Kattavuus | 2016-2022 | 1993-2022 |
| Koko | 25.8 miljardia sanaa | 5.1 miljardia sanaa |
Kirjoittajat käyvät läpi muutaman ylimääräisen esikäsittelyvaiheen ennen kuin tiedot syötetään opetusalgoritmiin. Ensinnäkin havaitsemme, että SEC-tiedostot sisältävät kohinaa tekstiä taulukoiden ja kuvien poistamisen vuoksi, joten kirjoittajat poistavat lyhyet lauseet, joita pidetään taulukko- tai kuviomerkintöinä. Toiseksi käytämme paikkaherkkää hajautusalgoritmia uusien artikkelien ja tiedostojen kaksoiskappaleiden poistamiseen. SEC-arkistointien osalta poistamme kaksoiskappaleet osatasolla asiakirjatason sijaan. Lopuksi ketjutamme asiakirjat pitkäksi merkkijonoksi, tokenisoimme sen ja lohkomme tunnuksen osiin, joiden enimmäispituus on opetettavan mallin tukema. Tämä parantaa jatkuvan esikoulutuksen suorituskykyä ja vähentää koulutuskustannuksia.
Jatkuva esikoulutus vs. hienosäätö
Useimmat saatavilla olevat LLM:t ovat yleiskäyttöisiä, ja niiltä puuttuu toimialuekohtaisia kykyjä. Domain LLM:t ovat osoittaneet huomattavaa suorituskykyä lääketieteen, rahoituksen tai tieteen aloilla. LLM:llä on neljä tapaa hankkia verkkoaluekohtaista tietoa: koulutus alusta alkaen, jatkuva esikoulutus, ohjeiden hienosäätö verkkotunnuksen tehtävissä ja Retrieval Augmented Generation (RAG).
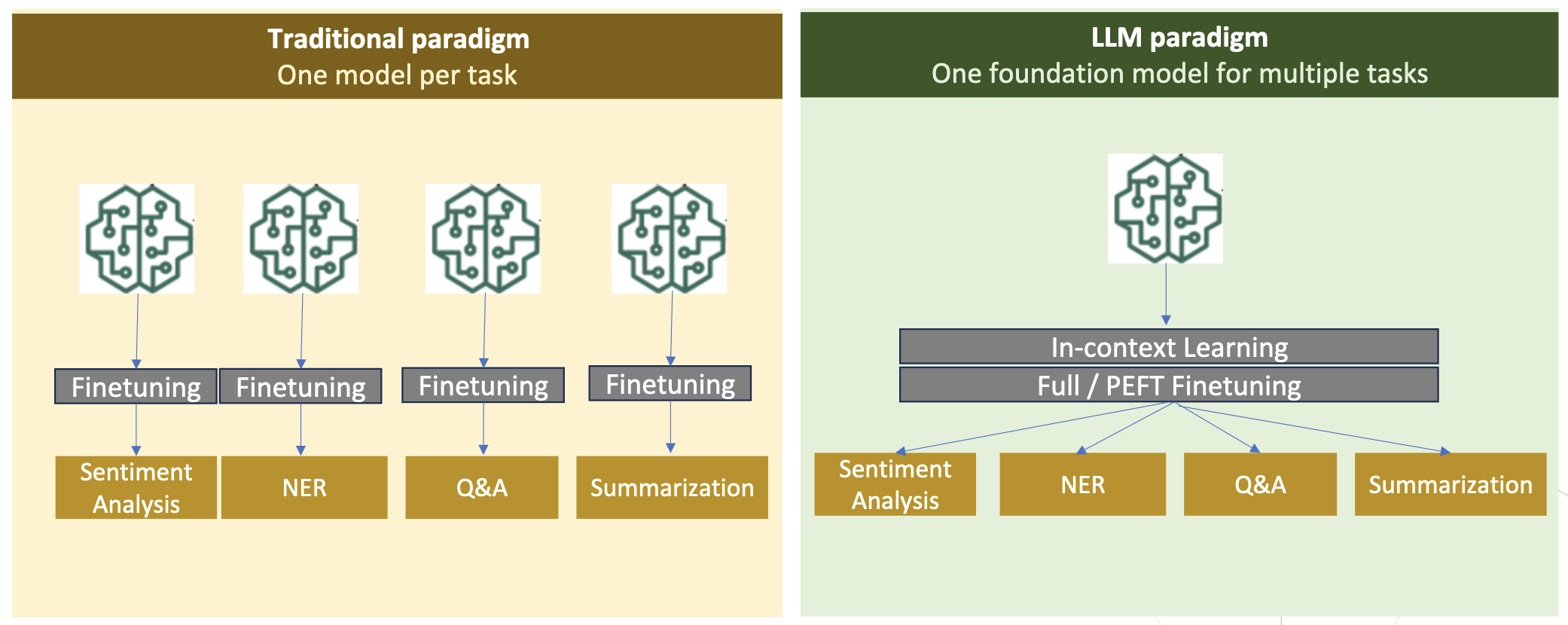
Perinteisissä malleissa hienosäätöä käytetään yleensä tehtäväkohtaisten mallien luomiseen toimialueelle. Tämä tarkoittaa useiden mallien ylläpitoa useisiin tehtäviin, kuten entiteetin poimimiseen, tarkoitusten luokitteluun, tunteiden analysointiin tai kysymyksiin vastaamiseen. LLM:ien myötä tarve ylläpitää erillisiä malleja on vanhentunut käyttämällä tekniikoita, kuten kontekstin sisäistä oppimista tai kehottamista. Tämä säästää vaivaa, joka tarvitaan mallipinon ylläpitoon toisiinsa liittyville mutta erillisille tehtäville.
Intuitiivisesti voit kouluttaa LLM:itä alusta alkaen verkkotunnuskohtaisilla tiedoilla. Vaikka suurin osa toimialueen LLM:ien luomisesta on keskittynyt koulutukseen tyhjästä, se on kohtuuttoman kallista. Esimerkiksi GPT-4-malli maksaa yli $ 100 miljoonaa junaan. Nämä mallit on koulutettu avoimen verkkotunnuksen datan ja verkkotunnuksen datan yhdistelmään. Jatkuva esikoulutus voi auttaa malleja hankkimaan toimialuekohtaista tietoa ilman, että esikoulutuksesta aiheutuu kustannuksia tyhjästä, koska esikoulutat olemassa olevan avoimen verkkotunnuksen LLM:n vain verkkotunnuksen tiedoilla.
Kun tehtävän käskyjen hienosäätö on käytössä, mallia ei voi saada verkkoaluetietoa hankkimaan, koska LLM hankkii vain ohjeiden hienosäätötietojoukon sisältämät toimialuetiedot. Ellei käskyjen hienosäätöön käytetä erittäin suurta tietojoukkoa, se ei riitä toimialuetiedon hankkimiseen. Laadukkaiden ohjeaineistojen hankinta on yleensä haastavaa, ja se on syy käyttää LLM:itä ensisijaisesti. Myös yhden tehtävän ohjeiden hienosäätö voi vaikuttaa muiden tehtävien suorituskykyyn (kuten näkyy kohdasta Tässä asiakirjassa). Opetuksen hienosäätö on kuitenkin kustannustehokkaampaa kuin kumpikaan esikoulutusvaihtoehto.
Seuraavassa kuvassa verrataan perinteistä tehtäväkohtaista hienosäätöä. Vs. konteksti-oppimisen paradigma LLM:ien kanssa.
 RAG on tehokkain tapa ohjata LLM:ää luomaan toimialueeseen perustuvia vastauksia. Vaikka se voi ohjata mallia luomaan vastauksia antamalla tietoja toimialueelta aputietoina, se ei hanki verkkoaluekohtaista kieltä, koska LLM luottaa edelleen ei-domain-kielityyliin vastausten luomisessa.
RAG on tehokkain tapa ohjata LLM:ää luomaan toimialueeseen perustuvia vastauksia. Vaikka se voi ohjata mallia luomaan vastauksia antamalla tietoja toimialueelta aputietoina, se ei hanki verkkoaluekohtaista kieltä, koska LLM luottaa edelleen ei-domain-kielityyliin vastausten luomisessa.
Jatkuva esikoulutus on keskitie esikoulutuksen ja opetuksen hienosäädön välillä kustannusten kannalta samalla kun se on vahva vaihtoehto aluekohtaisen tiedon ja tyylin hankkimiselle. Se voi tarjota yleisen mallin, jonka avulla voidaan suorittaa lisäohjeiden hienosäätöä rajoitetulle käskydatalle. Jatkuva esikoulutus voi olla kustannustehokas strategia erikoistuneille aloille, joilla loppupään tehtävien joukko on suuri tai tuntematon ja merkitty ohjeen viritystieto on rajallinen. Muissa skenaarioissa ohjeiden hienosäätö tai RAG voisi olla sopivampi.
Lisätietoja hienosäädöstä, RAG:sta ja mallikoulutuksesta on osoitteessa Hienosäädä pohjamalli, Retrieval Augmented Generation (RAG)ja Kouluta malli Amazon SageMakerilla, vastaavasti. Tässä postauksessa keskitymme tehokkaaseen jatkuvaan esikoulutukseen.
Tehokkaan jatkuvan esikoulutuksen menetelmät
Jatkuva esikoulutus koostuu seuraavista menetelmistä:
- Domain-Adaptive Continual Pre-Training (DACP) – Lehdessä Tehokas jatkuva esikoulutus verkkotunnuskohtaisten suurten kielimallien luomiseen, kirjoittajat harjoittelevat jatkuvasti Pythia-kielimallisarjaa rahoituskorpuksella mukauttaakseen sen rahoitusalalle. Tavoitteena on luoda taloudellisia LLM:itä syöttämällä tietoa koko talousalueelta avoimen lähdekoodin malliin. Koska koulutuskorpus sisältää kaikki toimialueen kuratoidut aineistot, tuloksena syntyvän mallin tulisi hankkia talouskohtaista tietoa, jolloin siitä tulee monipuolinen malli erilaisiin taloustehtäviin. Tämä johtaa FinPythia-malleihin.
- Task-Adaptive Continual Pre-training (TACP) – Kirjoittajat esikouluttavat malleja edelleen merkittyjen ja merkitsemättömien tehtävätietojen perusteella räätälöidäkseen ne tiettyjä tehtäviä varten. Tietyissä olosuhteissa kehittäjät voivat suosia malleja, jotka tarjoavat paremman suorituskyvyn verkkotunnuksen sisäisten tehtävien ryhmässä verkkotunnuksen yleisen mallin sijaan. TACP on suunniteltu jatkuvaksi esikoulutukseksi, jonka tavoitteena on parantaa suorituskykyä kohdistetuissa tehtävissä ilman vaatimuksia merkittyjä tietoja varten. Erityisesti kirjoittajat kouluttavat jatkuvasti avoimen lähdekoodin malleja tehtävätunnisteilla (ilman tunnisteita). TACP:n ensisijainen rajoitus on tehtäväkohtaisten LLM:ien rakentaminen perus-LLM:iden sijasta, koska koulutuksessa käytetään ainoastaan merkitsemättömiä tehtävätietoja. Vaikka DACP käyttää paljon suurempaa aineistoa, se on kohtuuttoman kallis. Näiden rajoitusten tasapainottamiseksi kirjoittajat ehdottavat kahta lähestymistapaa, joilla pyritään rakentamaan toimialuekohtaisia perustamispohjaisia LLM:itä säilyttäen samalla ylivoimainen suorituskyky kohdetehtävissä:
- Tehokas Task-Similar DACP (ETS-DACP) – Kirjoittajat ehdottavat, että valitaan rahoituskorpuksen osajoukko, joka on hyvin samankaltainen tehtävädatan kanssa, käyttämällä sulautettua samankaltaisuutta. Tätä osajoukkoa käytetään jatkuvaan esikoulutukseen sen tehostamiseksi. Tarkemmin sanottuna kirjoittajat jatkuvasti esikouluttavat avoimen lähdekoodin LLM:tä pienessä rahoituskorpuksesta poimitussa aineistossa, joka on lähellä jakelun kohdetehtäviä. Tämä voi auttaa parantamaan tehtävien suorituskykyä, koska otamme mallin tehtävätunnisteiden jakeluun, vaikka merkittyjä tietoja ei vaadita.
- Tehokas Task-Agnosttic DACP (ETA-DACP) – Kirjoittajat ehdottavat sellaisten mittareiden käyttöä, kuten hämmennys ja merkkityyppien entropia, jotka eivät vaadi tehtävätietoja otosten valitsemiseksi talouskorpuksesta tehokkaan jatkuvan esikoulutuksen varmistamiseksi. Tämä lähestymistapa on suunniteltu käsittelemään skenaarioita, joissa tehtävätietoja ei ole saatavilla tai laajemman toimialueen monipuolisempia toimialuemalleja suositellaan. Kirjoittajat ottavat käyttöön kaksi ulottuvuutta valitakseen tietonäytteet, jotka ovat tärkeitä verkkotunnustietojen saamiseksi koulutusta edeltävien verkkotunnustietojen osajoukosta: uutuus ja monimuotoisuus. Uutuus, mitattuna kohdemallin tallentamalla hämmennyksellä, viittaa tietoon, jota LLM ei aiemmin nähnyt. Erittäin uutuustiedot osoittavat uutta tietoa LLM:lle, ja tällaisen tiedon katsotaan olevan vaikeampi oppia. Tämä päivittää yleiset LLM:t intensiivisellä verkkotunnuksen tuntemuksella jatkuvan esikoulutuksen aikana. Monimuotoisuus puolestaan kaappaa token-tyyppien jakautumien monimuotoisuuden toimialuekorpuksessa, mikä on dokumentoitu hyödylliseksi piirteeksi kielimallinnuksen opetussuunnitelmaoppimisen tutkimuksessa.
Seuraavassa kuvassa vertaillaan esimerkkiä ETS-DACP:stä (vasemmalla) ja ETA-DACP:stä (oikealla).
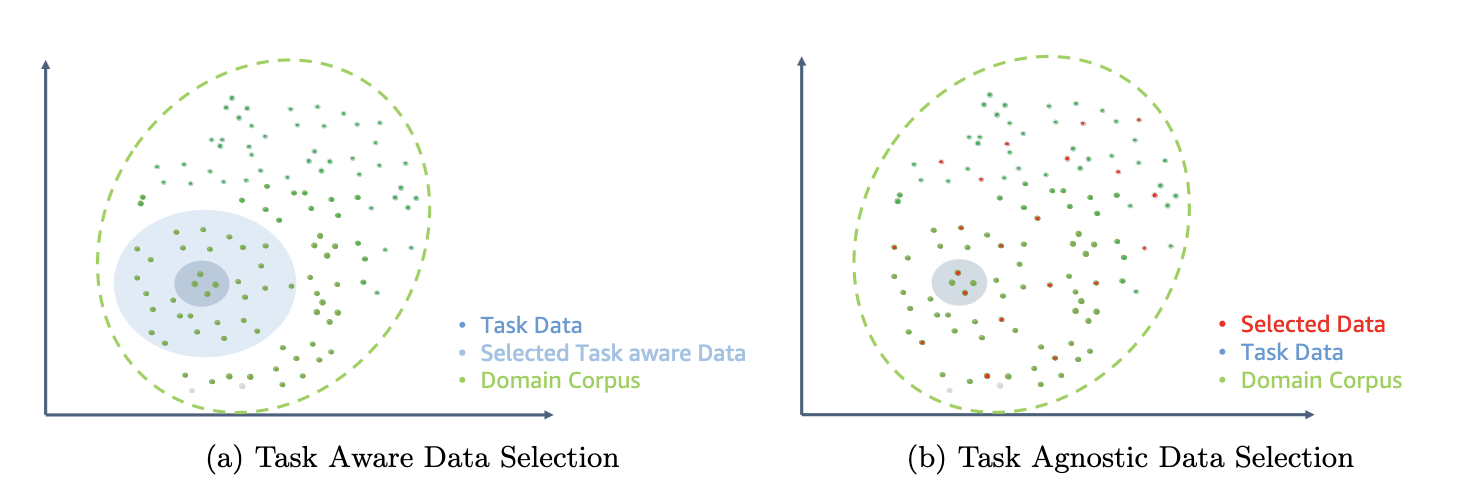
Käytämme kahta otantajärjestelmää valitaksemme aktiivisesti datapisteitä kuratoidusta talouskorpuksesta: kova otanta ja pehmeä otanta. Edellinen tehdään järjestämällä ensin talouskorpus vastaavilla mittareilla ja valitsemalla sitten top-k -otos, jossa k on ennalta määrätty koulutusbudjetin mukaan. Jälkimmäiselle kirjoittajat määrittävät näytteenottopainot jokaiselle datapisteelle metriarvojen mukaisesti ja ottavat sitten satunnaisesti k tietopistettä harjoitusbudjetin täyttämiseksi.
Tulos ja analyysi
Kirjoittajat arvioivat tuloksena olevia taloudellisia LLM:itä useissa taloudellisissa tehtävissä tutkiakseen jatkuvan esikoulutuksen tehokkuutta:
- Talouslausepankki – Talousuutisten tunteiden luokittelutehtävä.
- FiQA SA – Talousuutisiin ja otsikoihin perustuva näkökohtapohjainen tunteiden luokittelutehtävä.
- Otsikko – Binäärinen luokitustehtävä siitä, sisältääkö rahoitusyksikön otsikko tiettyjä tietoja.
- NER – SEC-raporttien luottoriskin arviointiosaan perustuva taloudellinen nimetty kokonaisuus. Tämän tehtävän sanoihin on merkitty PER, LOC, ORG ja MISC.
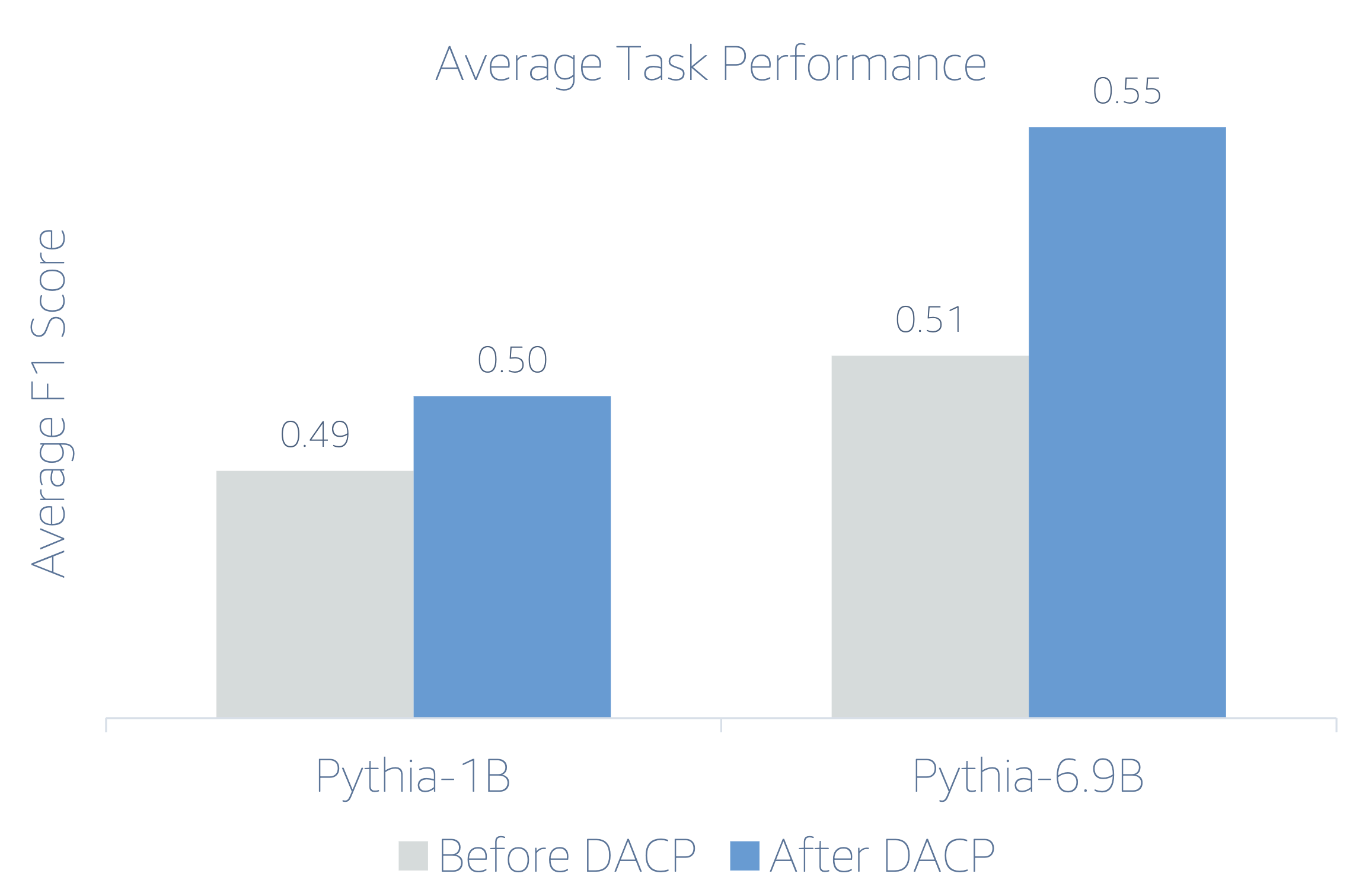
Koska taloushallinnon LLM:t ovat ohjeistettuja, kirjoittajat arvioivat malleja 5 laukauksen asetuksella kullekin tehtävälle kestävyyden vuoksi. Keskimäärin FinPythia 6.9B ylittää Pythia 6.9B:n 10 % neljässä tehtävässä, mikä osoittaa verkkoaluekohtaisen jatkuvan esikoulutuksen tehokkuuden. 1B-mallissa parannus ei ole yhtä syvällistä, mutta suorituskyky paranee silti keskimäärin 2 %.
Seuraava kuva havainnollistaa suorituskyvyn eroa ennen ja jälkeen DACP:n molemmissa malleissa.
Seuraavassa kuvassa on kaksi laadullista esimerkkiä, jotka on luotu Pythia 6.9B:llä ja FinPythia 6.9B:llä. Kahteen sijoittajapäällikköä ja taloustermiä koskevaan talouteen liittyvään kysymykseen Pythia 6.9B ei ymmärrä termiä tai tunnista nimeä, kun taas FinPythia 6.9B tuottaa yksityiskohtaiset vastaukset oikein. Laadulliset esimerkit osoittavat, että jatkuva esikoulutus antaa LLM:ille mahdollisuuden hankkia alan tietoa prosessin aikana.

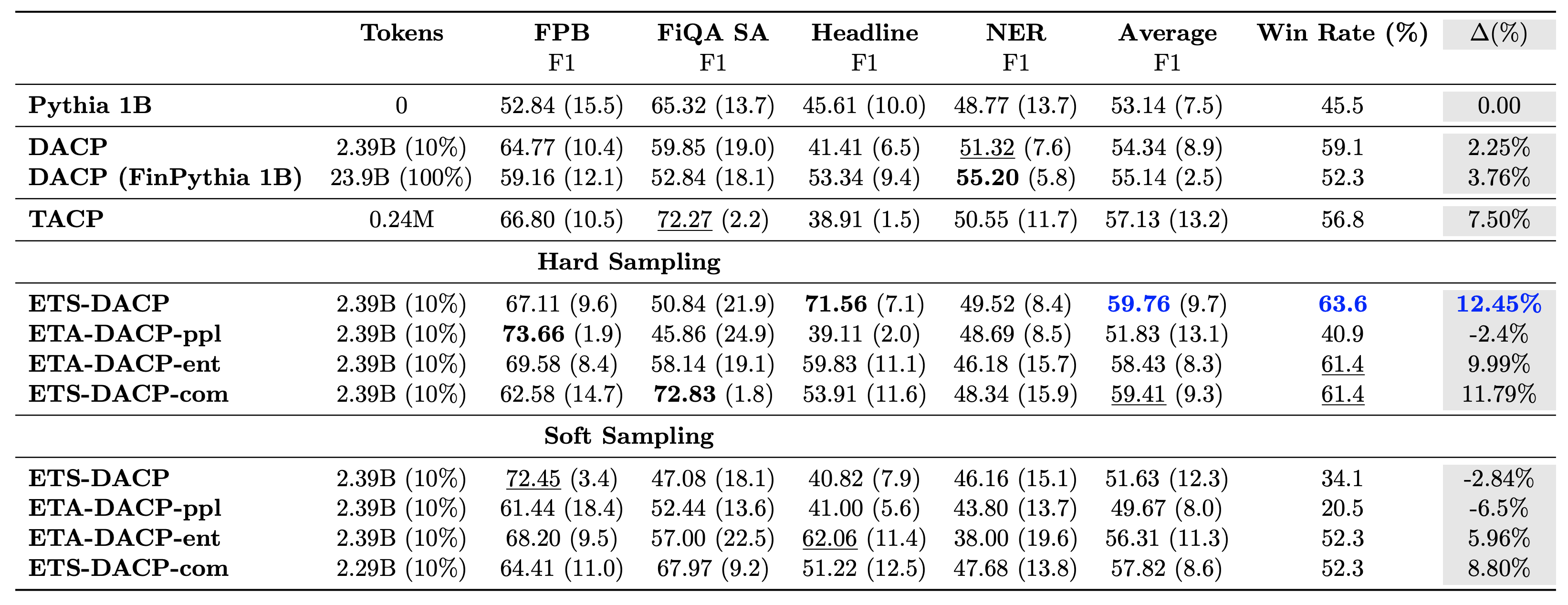
Seuraavassa taulukossa verrataan erilaisia tehokkaita jatkuvan esikoulutuksen lähestymistapoja. ETA-DACP-ppl on ETA-DACP, joka perustuu hämmennykseen (uutuus), ja ETA-DACP-ent perustuu entropiaan (diversiteetti). ETS-DACP-com on samanlainen kuin DACP, jossa tiedot valitaan laskemalla kaikkien kolmen mittarin keskiarvo. Seuraavassa muutamia poimintoja tuloksista:
- Tiedonvalintamenetelmät ovat tehokkaita – Ne ylittävät tavallisen jatkuvan esiharjoittelun vain 10 %:lla harjoitustiedoista. Tehokas jatkuva esikoulutus, mukaan lukien Task-Similar DACP (ETS-DACP), Task-Agnostic DACP, joka perustuu entropiaan (ESA-DACP-ent) ja Task-Similar DACP, joka perustuu kaikkiin kolmeen mittariin (ETS-DACP-com), ylittää tavallisen DACP:n keskimäärin huolimatta siitä, että he ovat koulutettuja vain 10 prosentissa rahoituskorpuksesta.
- Tehtävätietoinen tiedonvalinta toimii parhaiten pienten kielimallien tutkimuksen mukaisesti – ETS-DACP tallentaa parhaan keskimääräisen suorituskyvyn kaikista menetelmistä ja tallentaa kaikkien kolmen mittarin perusteella toiseksi parhaan tehtävän suorituskyvyn. Tämä viittaa siihen, että merkitsemättömien tehtävätietojen käyttö on edelleen tehokas tapa parantaa tehtävien suorituskykyä LLM:iden tapauksessa.
- Tehtäväagnostisten tietojen valinta on lähellä toista – ESA-DACP-ent noudattaa tehtävätietoisen tiedonvalintamenetelmän suorituskykyä, mikä tarkoittaa, että voisimme silti tehostaa tehtävien suorituskykyä valitsemalla aktiivisesti korkealaatuisia näytteitä, jotka eivät ole sidottu tiettyihin tehtäviin. Tämä tasoittaa tietä rakentaa taloudellisia LLM:itä koko toimialueelle ja samalla saavuttaa ylivoimainen tehtävien suoritus.
Yksi jatkuvaa esikoulutusta koskeva kriittinen kysymys on, vaikuttaako se negatiivisesti toimialueeseen kuulumattomien tehtävien suorituskykyyn. Kirjoittajat arvioivat myös jatkuvasti esikoulutettua mallia neljässä yleisesti käytetyssä yleistehtävässä: ARC, MMLU, TruthQA ja HellaSwag, jotka mittaavat kysymyksiin vastaamisen, päättelyn ja loppuunsaattamisen kykyä. Kirjoittajat havaitsevat, että jatkuva esikoulutus ei vaikuta haitallisesti muun kuin verkkotunnuksen suorituskykyyn. Katso lisätietoja osoitteesta Tehokas jatkuva esikoulutus verkkotunnuskohtaisten suurten kielimallien luomiseen.
Yhteenveto
Tämä viesti tarjosi näkemyksiä tiedonkeruusta ja jatkuvasta esikoulutusstrategioista LLM:ien kouluttamiseksi rahoitusalalla. Voit alkaa kouluttaa omia LLM:iäsi taloudellisiin tehtäviin käyttämällä Amazon SageMaker -koulutus or Amazonin kallioperä tänään.
Tietoja Tekijät
 Yong Xie on soveltava tutkija Amazon FinTechissä. Hän keskittyy suurten kielimallien ja generatiivisten AI-sovellusten kehittämiseen rahoitukseen.
Yong Xie on soveltava tutkija Amazon FinTechissä. Hän keskittyy suurten kielimallien ja generatiivisten AI-sovellusten kehittämiseen rahoitukseen.
 Karan Aggarwal on vanhempi sovellettu tutkija Amazon FinTechin palveluksessa ja keskittyy luovaan tekoälyyn rahoituksen käyttötapauksissa. Karanilla on laaja kokemus aikasarja-analyysistä ja NLP:stä, ja hän on erityisen kiinnostunut oppimaan rajoitetuista merkityistä tiedoista
Karan Aggarwal on vanhempi sovellettu tutkija Amazon FinTechin palveluksessa ja keskittyy luovaan tekoälyyn rahoituksen käyttötapauksissa. Karanilla on laaja kokemus aikasarja-analyysistä ja NLP:stä, ja hän on erityisen kiinnostunut oppimaan rajoitetuista merkityistä tiedoista
 Aitzaz Ahmad on sovelletun tieteen johtaja Amazonissa, jossa hän johtaa tutkijaryhmää, joka rakentaa erilaisia koneoppimisen ja luovan tekoälyn sovelluksia rahoituksessa. Hänen tutkimuskohteitaan ovat NLP, Generatiivinen tekoäly ja LLM Agents. Hän valmistui sähkötekniikan tohtoriksi Texas A&M -yliopistosta.
Aitzaz Ahmad on sovelletun tieteen johtaja Amazonissa, jossa hän johtaa tutkijaryhmää, joka rakentaa erilaisia koneoppimisen ja luovan tekoälyn sovelluksia rahoituksessa. Hänen tutkimuskohteitaan ovat NLP, Generatiivinen tekoäly ja LLM Agents. Hän valmistui sähkötekniikan tohtoriksi Texas A&M -yliopistosta.
 Qingwei Li on koneoppimisen asiantuntija Amazon Web Servicesissä. Hän sai Ph.D. Operations Researchissa sen jälkeen, kun hän rikkoi neuvonantajansa tutkimusapurahatilin ja epäonnistui toimittamaan lupaamansa Nobel-palkintoa. Tällä hetkellä hän auttaa talouspalvelualan asiakkaita rakentamaan koneoppimisratkaisuja AWS:lle.
Qingwei Li on koneoppimisen asiantuntija Amazon Web Servicesissä. Hän sai Ph.D. Operations Researchissa sen jälkeen, kun hän rikkoi neuvonantajansa tutkimusapurahatilin ja epäonnistui toimittamaan lupaamansa Nobel-palkintoa. Tällä hetkellä hän auttaa talouspalvelualan asiakkaita rakentamaan koneoppimisratkaisuja AWS:lle.
 Raghvender Arni johtaa Customer Acceleration Team (CAT) -tiimiä AWS Industriesissa. CAT on maailmanlaajuinen poikkitoiminnallinen tiimi, joka koostuu asiakkaita palvelevista pilviarkkitehdeistä, ohjelmistoinsinööreistä, datatieteilijöistä sekä AI/ML-asiantuntijoista ja suunnittelijoista, joka ajaa innovaatioita edistyneen prototyyppien avulla ja ajaa pilvitoimintojen erinomaisuutta erikoistuneen teknisen asiantuntemuksen avulla.
Raghvender Arni johtaa Customer Acceleration Team (CAT) -tiimiä AWS Industriesissa. CAT on maailmanlaajuinen poikkitoiminnallinen tiimi, joka koostuu asiakkaita palvelevista pilviarkkitehdeistä, ohjelmistoinsinööreistä, datatieteilijöistä sekä AI/ML-asiantuntijoista ja suunnittelijoista, joka ajaa innovaatioita edistyneen prototyyppien avulla ja ajaa pilvitoimintojen erinomaisuutta erikoistuneen teknisen asiantuntemuksen avulla.
- SEO-pohjainen sisällön ja PR-jakelu. Vahvista jo tänään.
- PlatoData.Network Vertical Generatiivinen Ai. Vahvista itseäsi. Pääsy tästä.
- PlatoAiStream. Web3 Intelligence. Tietoa laajennettu. Pääsy tästä.
- PlatoESG. hiili, CleanTech, energia, ympäristö, Aurinko, Jätehuolto. Pääsy tästä.
- PlatonHealth. Biotekniikan ja kliinisten kokeiden älykkyys. Pääsy tästä.
- Lähde: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

