این یک پست مهمان است که با تیم PyTorch متا نوشته شده است و در ادامه قسمت 1 از این سری، جایی که ما عملکرد و سهولت اجرای PyTorch 2.0 در AWS را نشان می دهیم.
تحقیقات یادگیری ماشین (ML) ثابت کرده است که مدلهای زبان بزرگ (LLM) که با مجموعه دادههای بسیار بزرگ آموزش داده شدهاند، کیفیت مدل بهتری دارند. در چند سال اخیر، اندازه مدل های نسل فعلی به طور قابل توجهی افزایش یافته است و آنها نیازمند ابزارها و زیرساخت های مدرن برای آموزش کارآمد و در مقیاس هستند. PyTorch Distributed Data Parallelism (DDP) به پردازش داده ها در مقیاس به روشی ساده و قوی کمک می کند، اما نیاز دارد که مدل بر روی یک GPU قرار گیرد. کتابخانه PyTorch Fully Sharded Data Parallel (FSDP) با فعال کردن شاردینگ مدل برای آموزش مدلهای بزرگ در میان کارگران موازی داده، این مانع را میشکند.
آموزش مدل توزیعشده به مجموعهای از گرههای کارگری نیاز دارد که بتوانند مقیاس شوند. سرویس الاستیک کوبرنتز آمازون (Amazon EKS) یک سرویس محبوب سازگار با Kubernetes است که فرآیند اجرای بارهای کاری AI/ML را تا حد زیادی ساده می کند و آن را قابل مدیریت تر و زمان کمتری می کند.
در این پست وبلاگ، AWS با تیم PyTorch متا همکاری میکند تا درباره نحوه استفاده از کتابخانه PyTorch FSDP برای دستیابی به مقیاسبندی خطی مدلهای یادگیری عمیق در AWS به طور یکپارچه با استفاده از Amazon EKS و Amazon EKS صحبت کند. ظروف یادگیری عمیق AWS (DLC ها). ما این را از طریق اجرای گام به گام آموزش مدل های 7B، 13B و 70B Llama2 با استفاده از Amazon EKS با 16 نشان می دهیم. ابر محاسبه الاستیک آمازون (Amazon EC2) p4de.24xlarge نمونه (هر کدام با 8 پردازنده گرافیکی NVIDIA A100 Tensor Core و هر پردازنده گرافیکی با 80 گیگابایت حافظه HBM2e) یا 16 EC2 p5.48xlarge نمونههایی (هر کدام با 8 پردازنده گرافیکی NVIDIA H100 Tensor Core و هر پردازنده گرافیکی با 80 گیگابایت حافظه HBM3)، دستیابی به مقیاسبندی تقریباً خطی در توان عملیاتی و در نهایت امکان زمان آموزش سریعتر.
نمودار مقیاسبندی زیر نشان میدهد که نمونههای p5.48xlarge با تنظیم دقیق FSDP Llama87 در یک پیکربندی خوشهای 2 گره، 16% راندمان مقیاسبندی را ارائه میدهند.

چالش های آموزش LLM
کسبوکارها به طور فزایندهای از LLM برای طیف وسیعی از وظایف، از جمله دستیاران مجازی، ترجمه، ایجاد محتوا، و بینایی رایانهای استفاده میکنند تا کارایی و دقت را در برنامههای مختلف افزایش دهند.
با این حال، آموزش یا تنظیم دقیق این مدلهای بزرگ برای یک مورد استفاده سفارشی، به مقدار زیادی داده و توان محاسباتی نیاز دارد، که به پیچیدگی مهندسی کلی پشته ML میافزاید. این همچنین به دلیل حافظه محدود موجود در یک GPU است که اندازه مدل قابل آموزش را محدود می کند و همچنین اندازه دسته ای هر GPU را که در طول آموزش استفاده می شود محدود می کند.
برای مقابله با این چالش، تکنیک های موازی مدل های مختلف مانند DeepSpeed ZeRO و PyTorch FSDP برای غلبه بر این مانع حافظه محدود GPU ایجاد شده اند. این کار با استفاده از یک تکنیک موازی داده های خرد شده انجام می شود، که در آن هر شتاب دهنده فقط یک برش را نگه می دارد (یک تکه شکسته) یک ماکت مدل به جای کل ماکت مدل، که به طور چشمگیری ردپای حافظه کار آموزشی را کاهش می دهد.
این پست نشان می دهد که چگونه می توانید از PyTorch FSDP برای تنظیم دقیق مدل Llama2 با استفاده از Amazon EKS استفاده کنید. ما با کاهش ظرفیت محاسباتی و GPU برای رسیدگی به نیازهای مدل به این امر دست مییابیم.
نمای کلی FSDP
در آموزش PyTorch DDP، هر GPU (به عنوان یک کارگر در زمینه PyTorch) یک کپی کامل از مدل شامل وزن مدل، گرادیان و حالت های بهینه ساز را در خود نگه می دارد. هر کارگر دسته ای از داده ها را پردازش می کند و در پایان پاس به عقب، از یک استفاده می کند همه کم کردن عملیات برای همگام سازی گرادیان ها در بین کارگران مختلف.
وجود یک کپی از مدل در هر GPU، اندازه مدلی را که میتواند در یک گردش کار DDP قرار گیرد، محدود میکند. FSDP با به اشتراک گذاری پارامترهای مدل، حالت های بهینه ساز و گرادیان ها در میان کارگران موازی داده، در حالی که سادگی موازی سازی داده ها را حفظ می کند، به غلبه بر این محدودیت کمک می کند.
این در نمودار زیر نشان داده شده است، جایی که در مورد DDP، هر GPU یک نسخه کامل از حالت مدل، از جمله حالت بهینه ساز (OS)، گرادیان (G) و پارامترها (P) را در خود دارد: M(OS + G + P). در FSDP، هر پردازنده گرافیکی تنها بخشی از حالت مدل شامل حالت بهینه ساز (OS)، گرادیان (G) و پارامترها (P) را در خود جای می دهد: M. (OS + G + P). استفاده از FSDP منجر به ردپای حافظه GPU به طور قابل توجهی کمتری در مقایسه با DDP در همه کارگران می شود، که امکان آموزش مدل های بسیار بزرگ یا استفاده از اندازه های دسته ای بزرگتر برای کارهای آموزشی را فراهم می کند.
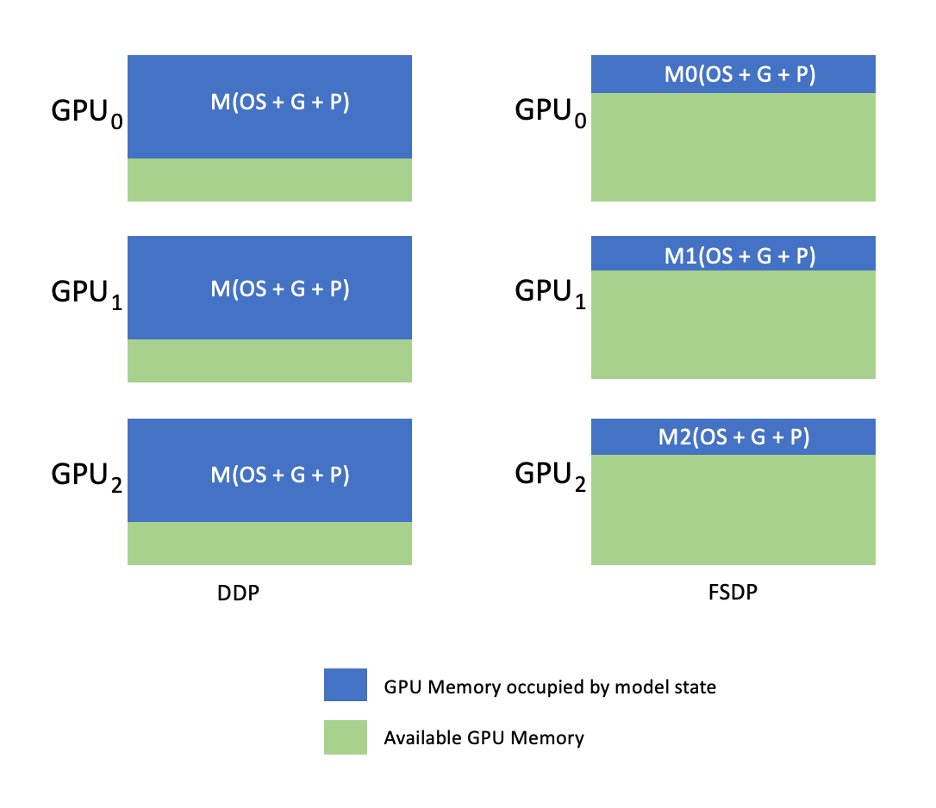
با این حال، این به قیمت افزایش هزینه های ارتباطی است که از طریق بهینه سازی FSDP مانند فرآیندهای ارتباطی و محاسباتی همپوشانی با ویژگی هایی مانند کاهش می یابد. پیش واکشی. برای اطلاعات دقیق تر مراجعه کنید شروع کار با داده های موازی کاملاً خرد شده (FSDP).
FSDP پارامترهای مختلفی را ارائه می دهد که به شما امکان می دهد عملکرد و کارایی مشاغل آموزشی خود را تنظیم کنید. برخی از ویژگی ها و قابلیت های کلیدی FSDP عبارتند از:
- سیاست بسته بندی ترانسفورماتور
- دقت مخلوط انعطاف پذیر
- ایست بازرسی فعال سازی
- استراتژی های اشتراک گذاری مختلف برای تطابق با سرعت های مختلف شبکه و توپولوژی های خوشه ای:
- FULL_SHARD - پارامترهای مدل شارد، گرادیان ها و حالت های بهینه ساز
- HYBRID_SHARD - قطعه کامل در یک گره DDP در سراسر گره ها. پشتیبانی از یک گروه تقسیم بندی انعطاف پذیر برای یک کپی کامل از مدل (HSDP)
- SHARD_GRAD_OP - فقط گرادیان ها و حالت های بهینه ساز شارد
- NO_SHARD - مشابه DDP
برای کسب اطلاعات بیشتر در مورد FSDP، مراجعه کنید آموزش کارآمد در مقیاس بزرگ با Pytorch FSDP و AWS.
شکل زیر نحوه عملکرد FSDP برای دو فرآیند موازی داده را نشان می دهد.

بررسی اجمالی راه حل
در این پست، ما یک خوشه محاسباتی را با استفاده از Amazon EKS راهاندازی کردیم که یک سرویس مدیریت شده برای اجرای Kubernetes در AWS Cloud و مراکز داده داخلی است. بسیاری از مشتریان آمازون EKS را برای اجرای بارهای کاری AI/ML مبتنی بر Kubernetes، با بهره گیری از عملکرد، مقیاس پذیری، قابلیت اطمینان و در دسترس بودن آن و همچنین ادغام آن با شبکه AWS، امنیت و سایر خدمات، پذیرفته اند.
برای مورد استفاده FSDP ما، از اپراتور آموزش Kubeflow در Amazon EKS، که یک پروژه بومی Kubernetes است که تنظیم دقیق و آموزش توزیعشده مقیاسپذیر را برای مدلهای ML تسهیل میکند. این فریمورک های مختلف ML، از جمله PyTorch را پشتیبانی می کند، که می توانید از آنها برای استقرار و مدیریت مشاغل آموزشی PyTorch در مقیاس استفاده کنید.
با استفاده از منبع سفارشی PyTorchJob از Kubeflow Training Operator، ما کارهای آموزشی را در Kubernetes با تعداد قابل تنظیمی از کپی های کارگر اجرا می کنیم که به ما امکان می دهد استفاده از منابع را بهینه کنیم.
موارد زیر چند جزء از اپراتور آموزشی است که در مورد استفاده از تنظیم دقیق Llama2 ما نقش دارند:
- یک کنترلر متمرکز Kubernetes که کارهای آموزشی توزیع شده را برای PyTorch هماهنگ می کند.
- PyTorchJob، یک منبع سفارشی Kubernetes برای PyTorch، ارائه شده توسط Kubeflow Training Operator، برای تعریف و استقرار مشاغل آموزشی Llama2 در Kubernetes.
- etcd که مربوط به پیاده سازی مکانیسم قرار ملاقات برای هماهنگی آموزش توزیع شده مدل های PyTorch می باشد. این
etcdسرور به عنوان بخشی از فرآیند قرار ملاقات، هماهنگی و همگام سازی کارگران شرکت کننده را در طول آموزش توزیع شده تسهیل می کند.
نمودار زیر معماری راه حل را نشان می دهد.

بیشتر جزئیات توسط اسکریپت های اتوماسیونی که برای اجرای مثال Llama2 استفاده می کنیم، خلاصه می شود.
ما از ارجاع کد زیر در این مورد استفاده می کنیم:
Llama2 چیست؟
Llama2 یک LLM از قبل آموزش دیده بر روی 2 تریلیون نشانه متن و کد است. این یکی از بزرگترین و قدرتمندترین LLM های موجود امروزی است. می توانید از Llama2 برای کارهای مختلفی از جمله پردازش زبان طبیعی (NLP)، تولید متن و ترجمه استفاده کنید. برای اطلاعات بیشتر مراجعه کنید شروع با Llama.
Llama2 در سه اندازه مدل مختلف موجود است:
- لاما2-70b – این بزرگترین مدل Llama2 با 70 میلیارد پارامتر است. این قوی ترین مدل Llama2 است و می تواند برای سخت ترین کارها استفاده شود.
- لاما2-13b – این مدل Llama2 با اندازه متوسط با 13 میلیارد پارامتر است. این تعادل خوبی بین عملکرد و کارایی است و می تواند برای کارهای مختلف استفاده شود.
- لاما2-7b – این کوچکترین مدل Llama2 با 7 میلیارد پارامتر است. این کارآمدترین مدل Llama2 است و می تواند برای کارهایی که به بالاترین سطح کارایی نیاز ندارند استفاده شود.
این پست شما را قادر می سازد تا تمام این مدل ها را در Amazon EKS تنظیم کنید. برای ارائه یک تجربه ساده و قابل تکرار از ایجاد یک خوشه EKS و اجرای کارهای FSDP روی آن، ما از aws-do-eks پروژه این مثال همچنین با یک خوشه EKS از قبل موجود کار می کند.
یک راهنما اسکریپت در دسترس است GitHub برای یک تجربه خارج از جعبه در بخشهای بعدی، فرآیند end-to-end را با جزئیات بیشتری توضیح میدهیم.
زیرساخت راه حل را فراهم کنید
برای آزمایشهایی که در این پست توضیح داده شد، از خوشههایی با گرههای p4de (GPU A100) و p5 (GPU H100) استفاده میکنیم.
خوشه با گره های p4de.24xlarge
برای خوشه خود با گرههای p4de، از موارد زیر استفاده میکنیم eks-gpu-p4de-odcr.yaml متن:
با استفاده از eksctl و مانیفست کلاستر قبلی، یک خوشه با گرههای p4de ایجاد میکنیم:
خوشه با گره های p5.48x بزرگ
یک الگوی terraform برای یک خوشه EKS با گرههای P5 در زیر قرار دارد GitHub repo.
شما می توانید خوشه را از طریق سفارشی سازی کنید متغیرها.tf فایل و سپس آن را از طریق Terraform CLI ایجاد کنید:
می توانید با اجرای یک دستور ساده kubectl در دسترس بودن خوشه را تأیید کنید:
خوشه سالم است اگر خروجی این دستور تعداد مورد انتظار گره ها را در وضعیت آماده نشان دهد.
پیش نیازها را مستقر کنید
برای اجرای FSDP در Amazon EKS، از PyTorchJob منبع سفارشی ایجاب می کند etcd و اپراتور آموزش Kubeflow به عنوان پیش نیاز
etcd را با کد زیر اجرا کنید:
اپراتور Kubeflow Training را با کد زیر مستقر کنید:
یک تصویر ظرف FSDP را بسازید و به Amazon ECR فشار دهید
از کد زیر برای ساخت یک تصویر کانتینر FSDP استفاده کنید و آن را فشار دهید رجیستری ظروف الاستیک آمازون (Amazon ECR):
مانیفست FSDP PyTorchJob را ایجاد کنید
خود را وارد کنید نشانه در آغوش گرفتن صورت در قطعه زیر قبل از اجرای آن:
PyTorchJob خود را با آن پیکربندی کنید .NS فایل یا مستقیماً در متغیرهای محیط خود به صورت زیر:
مانیفست PyTorchJob را با استفاده از قالب fsdp و تولید.ش اسکریپت یا مستقیماً با استفاده از اسکریپت زیر آن را ایجاد کنید:
PyTorchJob را اجرا کنید
PyTorchJob را با کد زیر اجرا کنید:
تعداد مشخص شده FDSP Worker Pod ایجاد شده را مشاهده می کنید و پس از کشیدن تصویر وارد حالت Running می شوند.
برای مشاهده وضعیت PyTorchJob از کد زیر استفاده کنید:
برای متوقف کردن PyTorchJob، از کد زیر استفاده کنید:
پس از تکمیل یک کار، قبل از شروع اجرای جدید باید آن را حذف کنید. ما همچنین مشاهده کرده ایم که حذفetcdپاد و اجازه راه اندازی مجدد آن قبل از راه اندازی یک کار جدید به جلوگیری از a RendezvousClosedError.
خوشه را مقیاس کنید
میتوانید مراحل قبلی ایجاد و اجرای مشاغل را تکرار کنید، در حالی که تعداد و نوع نمونه گرههای کارگر را در خوشه تغییر دهید. این به شما امکان می دهد نمودارهای مقیاس بندی مانند آنچه قبلا نشان داده شده است را تولید کنید. به طور کلی، زمانی که گره های بیشتری به خوشه اضافه می شوند، باید شاهد کاهش ردپای حافظه GPU، کاهش زمان دوره و افزایش توان عملیاتی باشید. نمودار قبلی با انجام چندین آزمایش با استفاده از یک گروه گره p5 با اندازه 1 تا 16 گره تولید شد.
حجم کار آموزشی FSDP را رعایت کنید
قابلیت مشاهده بارهای کاری هوش مصنوعی مولد برای امکان مشاهده مشاغل در حال اجرا و همچنین کمک به حداکثر استفاده از منابع محاسباتی شما مهم است. در این پست، از چند ابزار مشاهدهپذیری بومی و منبع باز Kubernetes برای این منظور استفاده میکنیم. این ابزارها شما را قادر می سازند تا خطاها، آمار و رفتار مدل را ردیابی کنید، و قابلیت مشاهده هوش مصنوعی را به بخش مهمی از هر مورد استفاده تجاری تبدیل می کند. در این بخش، رویکردهای مختلفی را برای مشاهده مشاغل آموزشی FSDP نشان می دهیم.
سیاهههای مربوط به غلاف کارگر
در ابتدایی ترین سطح، باید بتوانید سیاهه های مربوط به غلاف های آموزشی خود را ببینید. این را می توان به راحتی با استفاده از دستورات بومی Kubernetes انجام داد.
ابتدا فهرستی از غلاف ها را بازیابی کنید و نام موردی را که می خواهید گزارش های آن را ببینید پیدا کنید:
سپس گزارشهای مربوط به غلاف انتخابی را مشاهده کنید:
فقط یک کارگر (رهبر منتخب) گزارش غلاف آمار کلی شغل را فهرست می کند. نام غلاف رهبر انتخابی در ابتدای هر گزارش غلاف کارگر موجود است که با کلید مشخص می شود. master_addr=.
استفاده از پردازنده
بارهای آموزشی توزیع شده به منابع CPU و GPU نیاز دارند. برای بهینهسازی این حجمهای کاری، درک نحوه استفاده از این منابع مهم است. خوشبختانه، برخی از ابزارهای منبع باز عالی در دسترس هستند که به تجسم استفاده از CPU و GPU کمک می کنند. برای مشاهده استفاده از CPU، می توانید استفاده کنیدhtop. اگر غلافهای کارگر شما حاوی این ابزار هستند، میتوانید از دستور زیر برای باز کردن یک پوسته در یک pod استفاده کنید و سپس اجرا کنید.htop.
از طرف دیگر، می توانید یک htop را مستقر کنیدdaemonsetمانند آنچه در زیر ارائه شده است GitHub repo.
Ladaemonsetیک htop pod سبک وزن را روی هر گره اجرا می کند. می توانید در هر یک از این پادها اجرا کنید و آن را اجرا کنیدhtopفرمان:
تصویر زیر میزان استفاده از CPU را در یکی از گره های خوشه نشان می دهد. در این مورد، ما به یک نمونه P5.48xlarge نگاه می کنیم که دارای 192 vCPU است. هستههای پردازنده در حین بارگیری وزنهای مدل بیحرکت هستند و زمانی که وزنهای مدل در حافظه GPU بارگیری میشوند، شاهد افزایش استفاده هستیم.

استفاده از پردازنده گرافیکی
اگرnvtopابزار در پاد شما موجود است، می توانید با استفاده از زیر آن را اجرا کرده و سپس اجرا کنیدnvtop.
از طرف دیگر، می توانید یک nvtop را مستقر کنیدdaemonsetمانند آنچه در زیر ارائه شده است GitHub repo.
این اجرا خواهد شدnvtopغلاف روی هر گره شما می توانید در هر یک از آن پادها اجرا کنید و اجرا کنیدnvtop:
تصویر زیر استفاده از GPU را در یکی از گرههای کلاستر آموزشی نشان میدهد. در این مورد، ما به یک نمونه P5.48xlarge نگاه می کنیم که دارای 8 پردازنده گرافیکی NVIDIA H100 است. در حالی که وزنهای مدل بارگیری میشوند، پردازندههای گرافیکی بیکار هستند، سپس با بارگیری وزن مدل بر روی GPU، استفاده از حافظه GPU افزایش مییابد، و در حالی که تکرارهای آموزشی در حال انجام است، استفاده از GPU تا 100 درصد افزایش مییابد.

داشبورد گرافانا
اکنون که متوجه شدید که سیستم شما در سطح پاد و گره چگونه کار می کند، بررسی معیارها در سطح خوشه نیز مهم است. معیارهای استفاده انبوه را می توان توسط NVIDIA DCGM Exporter و Prometheus جمع آوری کرد و در Grafana تجسم کرد.
نمونه ای از استقرار Prometheus-Grafana در زیر موجود است GitHub repo.
نمونه ای از استقرار صادرکننده DCGM در زیر موجود است GitHub repo.
یک داشبورد ساده Grafana در تصویر زیر نشان داده شده است. با انتخاب معیارهای DCGM زیر ساخته شد: DCGM_FI_DEV_GPU_UTIL, DCGM_FI_MEM_COPY_UTIL, DCGM_FI_DEV_XID_ERRORS, DCGM_FI_DEV_SM_CLOCK, DCGM_FI_DEV_GPU_TEMPو DCGM_FI_DEV_POWER_USAGE. داشبورد را می توان به Prometheus وارد کرد GitHub.
داشبورد زیر یک دوره از یک کار آموزشی تک دوره ای Llama2 7b را نشان می دهد. نمودارها نشان میدهند که با افزایش ساعت چند پردازنده جریانی (SM)، مصرف انرژی و دمای پردازندههای گرافیکی نیز همراه با استفاده از GPU و حافظه افزایش مییابد. همچنین می توانید ببینید که هیچ خطای XID وجود نداشت و GPU ها در این اجرا سالم بودند.

از مارس 2024، قابلیت مشاهده GPU برای EKS به صورت بومی در آن پشتیبانی میشود CloudWatch Container Insights. برای فعال کردن این قابلیت کافی است افزونه CloudWatch Observability را در خوشه EKS خود مستقر کنید. سپس میتوانید معیارهای سطح غلاف، گره و کلاستر را از طریق داشبوردهای از پیش پیکربندیشده و قابل تنظیم در Container Insights مرور کنید.
پاک کردن
اگر خوشه خود را با استفاده از مثال های ارائه شده در این وبلاگ ایجاد کرده اید، می توانید کد زیر را برای حذف خوشه و هر منبع مرتبط با آن، از جمله VPC، اجرا کنید:
برای eksctl:
برای ترافورم:
ویژگی های آینده
انتظار می رود FSDP دارای ویژگی اشتراک گذاری در هر پارامتر باشد که هدف آن بهبود بیشتر فضای حافظه در هر GPU است. علاوه بر این، توسعه مداوم پشتیبانی از FP8 با هدف بهبود عملکرد FSDP در پردازندههای گرافیکی H100 است. در نهایت، زمانی که FSDP باtorch.compile، امیدواریم شاهد بهبود عملکرد بیشتر و فعال کردن ویژگی هایی مانند چک پوینت فعال سازی انتخابی باشیم.
نتیجه
در این پست، ما در مورد اینکه چگونه FSDP ردپای حافظه را در هر GPU کاهش میدهد، آموزش مدلهای بزرگتر را کارآمدتر و دستیابی به مقیاسبندی خطی تقریباً در توان پردازشی را مورد بحث قرار میدهد. ما این را از طریق اجرای گام به گام آموزش مدل Llama2 با استفاده از Amazon EKS در نمونههای P4de و P5 نشان دادیم و از ابزارهای مشاهدهپذیری مانند kubectl، htop، nvtop و dcgm برای نظارت بر گزارشها و همچنین استفاده از CPU و GPU استفاده کردیم.
ما شما را تشویق می کنیم که از PyTorch FSDP برای مشاغل آموزشی LLM خود استفاده کنید. شروع کنید در aws-do-fsdp.
درباره نویسنده
 کانوالجیت خرمی یک معمار اصلی راه حل های AI/ML در خدمات وب آمازون است. او با مشتریان AWS برای ارائه راهنمایی و کمک فنی کار می کند و به آنها کمک می کند ارزش راه حل های یادگیری ماشین خود را در AWS بهبود بخشند. Kanwaljit در کمک به مشتریان با برنامه های کاربردی محاسباتی کانتینری، توزیع شده و یادگیری عمیق تخصص دارد.
کانوالجیت خرمی یک معمار اصلی راه حل های AI/ML در خدمات وب آمازون است. او با مشتریان AWS برای ارائه راهنمایی و کمک فنی کار می کند و به آنها کمک می کند ارزش راه حل های یادگیری ماشین خود را در AWS بهبود بخشند. Kanwaljit در کمک به مشتریان با برنامه های کاربردی محاسباتی کانتینری، توزیع شده و یادگیری عمیق تخصص دارد.
 الکس ایانکولسکی یک معمار راه حل های اصلی، یادگیری ماشین خود مدیریت در AWS است. او یک مهندس نرم افزار و زیرساخت کامل است که دوست دارد کارهای عمیق و عملی انجام دهد. در نقش خود، او بر کمک به مشتریان با کانتینریسازی و هماهنگسازی بارهای کاری ML و AI در سرویسهای AWS با کانتینر تمرکز میکند. او همچنین نویسنده منبع باز است انجام چارچوب و یک کاپیتان Docker که عاشق استفاده از فناوریهای کانتینر برای تسریع سرعت نوآوری و در عین حال حل بزرگترین چالشهای جهان است.
الکس ایانکولسکی یک معمار راه حل های اصلی، یادگیری ماشین خود مدیریت در AWS است. او یک مهندس نرم افزار و زیرساخت کامل است که دوست دارد کارهای عمیق و عملی انجام دهد. در نقش خود، او بر کمک به مشتریان با کانتینریسازی و هماهنگسازی بارهای کاری ML و AI در سرویسهای AWS با کانتینر تمرکز میکند. او همچنین نویسنده منبع باز است انجام چارچوب و یک کاپیتان Docker که عاشق استفاده از فناوریهای کانتینر برای تسریع سرعت نوآوری و در عین حال حل بزرگترین چالشهای جهان است.
 آنا سیموز یک متخصص اصلی یادگیری ماشین، چارچوب ML در AWS است. او از مشتریانی پشتیبانی می کند که هوش مصنوعی، ML و هوش مصنوعی مولد را در مقیاس بزرگ در زیرساخت HPC در فضای ابری به کار می گیرند. آنا بر حمایت از مشتریان برای دستیابی به عملکرد قیمت برای بارهای کاری جدید و استفاده از موارد برای هوش مصنوعی و یادگیری ماشینی مولد تمرکز دارد.
آنا سیموز یک متخصص اصلی یادگیری ماشین، چارچوب ML در AWS است. او از مشتریانی پشتیبانی می کند که هوش مصنوعی، ML و هوش مصنوعی مولد را در مقیاس بزرگ در زیرساخت HPC در فضای ابری به کار می گیرند. آنا بر حمایت از مشتریان برای دستیابی به عملکرد قیمت برای بارهای کاری جدید و استفاده از موارد برای هوش مصنوعی و یادگیری ماشینی مولد تمرکز دارد.
 حمید شجاعی یک مهندس شریک در PyTorch است که روی منبع باز، بهینه سازی مدل با کارایی بالا، آموزش توزیع شده کار می کند (FSDP) و استنتاج. او همکار خالق است دستور غذای لاما و مشارکت کننده در TorchServe. علاقه اصلی او بهبود کارایی هزینه است و هوش مصنوعی را برای جامعه گسترده تر قابل دسترس تر می کند.
حمید شجاعی یک مهندس شریک در PyTorch است که روی منبع باز، بهینه سازی مدل با کارایی بالا، آموزش توزیع شده کار می کند (FSDP) و استنتاج. او همکار خالق است دستور غذای لاما و مشارکت کننده در TorchServe. علاقه اصلی او بهبود کارایی هزینه است و هوش مصنوعی را برای جامعه گسترده تر قابل دسترس تر می کند.
 رایت کمتر یک مهندس هوش مصنوعی / شریک در PyTorch است. او روی هسته های Triton/CUDA کار می کند (تسریع Dequant با تجزیه کار SplitK) بهینهسازهای صفحهدار، جریانی و کوانتیزهشده. و PyTorch توزیع شد (PyTorch FSDP).
رایت کمتر یک مهندس هوش مصنوعی / شریک در PyTorch است. او روی هسته های Triton/CUDA کار می کند (تسریع Dequant با تجزیه کار SplitK) بهینهسازهای صفحهدار، جریانی و کوانتیزهشده. و PyTorch توزیع شد (PyTorch FSDP).
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/scale-llms-with-pytorch-2-0-fsdp-on-amazon-eks-part-2/

