مدلهای زبان بزرگ (LLM) عموماً بر روی مجموعه دادههای بزرگ در دسترس عموم که دارای آگنوستیک دامنه هستند آموزش داده میشوند. مثلا، لاما متا مدل ها بر روی مجموعه داده هایی مانند CommonCrawl, C4، ویکی پدیا و ArXiv. این مجموعه داده ها طیف وسیعی از موضوعات و حوزه ها را در بر می گیرد. اگرچه مدلهای بهدستآمده نتایج فوقالعاده خوبی برای کارهای عمومی، مانند تولید متن و شناسایی موجودیت، به دست میدهند، شواهدی وجود دارد که مدلهای آموزشدیده شده با مجموعه دادههای خاص دامنه میتوانند عملکرد LLM را بیشتر بهبود بخشند. به عنوان مثال، داده های آموزشی مورد استفاده برای بلومبرگ GPT 51٪ اسناد مربوط به دامنه، از جمله اخبار مالی، پرونده ها و سایر مطالب مالی است. LLM حاصل از LLMهایی که در مجموعه داده های غیر دامنه خاص آموزش داده شده اند، هنگام آزمایش بر روی وظایف خاص مالی، بهتر عمل می کند. نویسندگان از بلومبرگ GPT به این نتیجه رسیدند که مدل آنها از تمام مدل های دیگر آزمایش شده برای چهار مورد از پنج وظیفه مالی بهتر عمل می کند. این مدل زمانی که برای وظایف مالی داخلی بلومبرگ با اختلاف زیادی مورد آزمایش قرار گرفت، حتی 60 امتیاز بهتر (از 100) عملکرد بهتری داشت. اگر چه می توانید در مورد نتایج ارزیابی جامع اطلاعات بیشتری کسب کنید مقاله، نمونه زیر گرفته شده از بلومبرگ GPT مقاله می تواند نگاهی اجمالی به مزایای آموزش LLM با استفاده از داده های خاص حوزه مالی به شما بدهد. همانطور که در مثال نشان داده شده است، مدل BloombergGPT پاسخ های درستی ارائه می دهد در حالی که سایر مدل های غیر اختصاصی دامنه با مشکل مواجه هستند:
این پست راهنمایی برای آموزش LLM به طور خاص برای حوزه مالی ارائه می دهد. ما حوزه های کلیدی زیر را پوشش می دهیم:
- جمع آوری و آماده سازی داده ها - راهنمایی در مورد منبع یابی و مدیریت داده های مالی مرتبط برای آموزش مدل موثر
- پیش تمرین مداوم در مقابل تنظیم دقیق - چه زمانی از هر تکنیک برای بهینه سازی عملکرد LLM خود استفاده کنید
- پیش تمرین مستمر کارآمد - استراتژیهایی برای سادهسازی فرآیند پیشآموزشی مستمر، صرفهجویی در زمان و منابع
این پست تخصص تیم تحقیقات علمی کاربردی در فناوری مالی آمازون و تیم متخصص جهانی AWS برای صنعت مالی جهانی را گرد هم می آورد. برخی از مطالب بر اساس مقاله است پیشآموزش مستمر کارآمد برای ساخت مدلهای زبان بزرگ خاص دامنه.
جمع آوری و تهیه داده های مالی
پیشآموزش مستمر دامنه نیازمند مجموعه دادهای در مقیاس بزرگ، با کیفیت بالا و مختص دامنه است. مراحل اصلی برای تنظیم مجموعه داده دامنه به شرح زیر است:
- منابع داده را شناسایی کنید – منابع داده بالقوه برای مجموعه دامنه شامل وب باز، ویکی پدیا، کتاب ها، رسانه های اجتماعی و اسناد داخلی است.
- فیلترهای داده دامنه - از آنجایی که هدف نهایی مدیریت مجموعه دامنه است، ممکن است لازم باشد مراحل بیشتری را برای فیلتر کردن نمونههایی که به دامنه هدف نامرتبط هستند، اعمال کنید. این امر بدنه بی فایده را برای پیش تمرین مستمر کاهش می دهد و هزینه آموزش را کاهش می دهد.
- پیش پردازش - ممکن است یک سری مراحل پیش پردازش را برای بهبود کیفیت داده ها و کارایی آموزش در نظر بگیرید. به عنوان مثال، برخی منابع داده میتوانند حاوی تعداد مناسبی از نشانههای پر سر و صدا باشند. حذف مجدد یک گام مفید برای بهبود کیفیت داده ها و کاهش هزینه آموزش در نظر گرفته می شود.
برای توسعه LLM های مالی، می توانید از دو منبع داده مهم استفاده کنید: پرونده های News CommonCrawl و SEC. پرونده SEC یک صورت مالی یا سایر اسناد رسمی است که به کمیسیون بورس و اوراق بهادار ایالات متحده (SEC) ارسال می شود. شرکت های پذیرفته شده در بورس عمومی موظفند اسناد مختلف را به طور منظم ثبت کنند. این باعث ایجاد تعداد زیادی اسناد در طول سال ها می شود. News CommonCrawl مجموعه داده ای است که توسط CommonCrawl در سال 2016 منتشر شد. حاوی مقالات خبری از سایت های خبری در سراسر جهان است.
اخبار CommonCrawl در دسترس است سرویس ذخیره سازی ساده آمازون (Amazon S3) در commoncrawl سطل در crawl-data/CC-NEWS/. شما می توانید لیست فایل ها را با استفاده از رابط خط فرمان AWS (AWS CLI) و دستور زیر:
In پیشآموزش مستمر کارآمد برای ساخت مدلهای زبان بزرگ خاص دامنه، نویسندگان از یک URL و رویکرد مبتنی بر کلمه کلیدی برای فیلتر کردن مقالات اخبار مالی از اخبار عمومی استفاده می کنند. به طور خاص، نویسندگان فهرستی از رسانه های مهم اخبار مالی و مجموعه ای از کلمات کلیدی مرتبط با اخبار مالی را حفظ می کنند. اگر مقاله ای از رسانه های خبری مالی آمده باشد یا هر کلمه کلیدی در URL نشان داده شود، ما آن را به عنوان اخبار مالی شناسایی می کنیم. این رویکرد ساده و در عین حال موثر به شما امکان میدهد تا اخبار مالی را نه تنها از رسانههای خبری مالی، بلکه بخشهای مالی از رسانههای خبری عمومی را نیز شناسایی کنید.
پرونده های SEC به صورت آنلاین از طریق پایگاه داده EDGAR (جمع آوری، تجزیه و تحلیل و بازیابی اطلاعات الکترونیکی) SEC که دسترسی به داده های باز را فراهم می کند، در دسترس است. میتوانید فایلها را مستقیماً از EDGAR خراش دهید یا از API در آن استفاده کنید آمازون SageMaker با چند خط کد، برای هر دوره زمانی و برای تعداد زیادی علامت (به عنوان مثال، SEC شناسه اختصاص داده شده). برای کسب اطلاعات بیشتر به ادامه مطلب مراجعه نمایید بازیابی پرونده SEC.
جدول زیر جزئیات کلیدی هر دو منبع داده را خلاصه می کند.
| . | اخبار CommonCrawl | تشکیل پرونده SEC |
| پوشش | 2016-2022 | 1993-2022 |
| اندازه | 25.8 میلیارد کلمه | 5.1 میلیارد کلمه |
نویسندگان قبل از اینکه داده ها به یک الگوریتم آموزشی وارد شوند، چند مرحله پیش پردازش اضافی را طی می کنند. اول، مشاهده میکنیم که فایلهای SEC به دلیل حذف جداول و شکلها حاوی متن پر سر و صدایی هستند، بنابراین نویسندگان جملات کوتاهی را که برچسبهای جدول یا شکل تلقی میشوند حذف میکنند. ثانیا، ما یک الگوریتم هش حساس به محلی را برای حذف مجدد مقالات و پرونده های جدید اعمال می کنیم. برای پرونده های SEC، به جای سطح سند، در سطح بخش کپی می کنیم. در نهایت، ما اسناد را در یک رشته طولانی به هم متصل میکنیم، آن را توکن میکنیم و توکنسازی را به قطعات حداکثر طول ورودی که توسط مدلی که باید آموزش داده شود، پشتیبانی میکنیم. این کار باعث بهبود عملکرد پیشآموزش مستمر و کاهش هزینه آموزش میشود.
پیش تمرین مداوم در مقابل تنظیم دقیق
اکثر LLM های موجود، همه منظوره هستند و فاقد توانایی های خاص دامنه هستند. دامنه های LLM عملکرد قابل توجهی در حوزه های پزشکی، مالی یا علمی نشان داده اند. برای یک LLM برای کسب دانش خاص دامنه، چهار روش وجود دارد: آموزش از ابتدا، پیش آموزش مداوم، تنظیم دقیق دستورالعمل در وظایف دامنه، و بازیابی نسل افزوده (RAG).
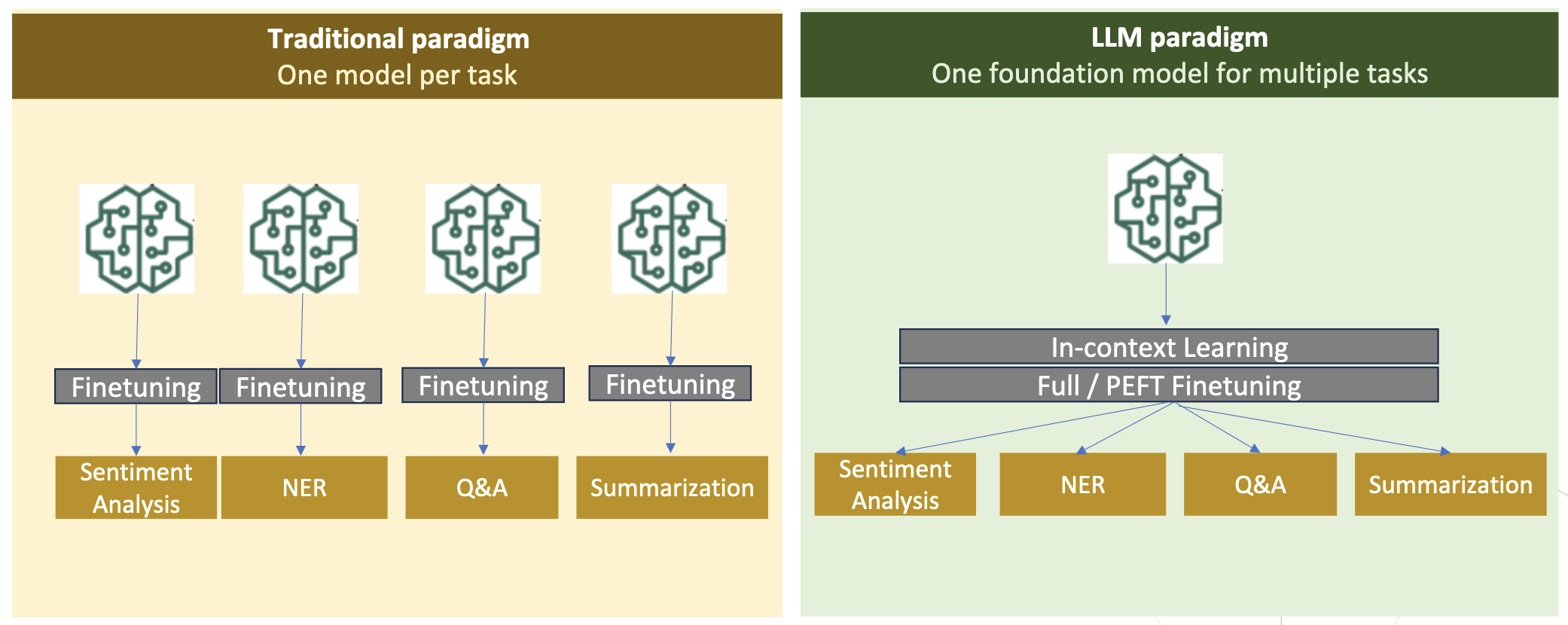
در مدلهای سنتی، تنظیم دقیق معمولاً برای ایجاد مدلهای خاص کار برای یک دامنه استفاده میشود. این به معنای حفظ مدل های متعدد برای چندین کار مانند استخراج موجودیت، طبقه بندی قصد، تجزیه و تحلیل احساسات یا پاسخ به سؤال است. با ظهور LLM ها، نیاز به حفظ مدل های جداگانه با استفاده از تکنیک هایی مانند یادگیری درون متنی یا درخواست منسوخ شده است. این باعث صرفه جویی در تلاش لازم برای حفظ مجموعه ای از مدل ها برای کارهای مرتبط اما متمایز می شود.
به طور مستقیم، می توانید LLM ها را از ابتدا با داده های دامنه خاص آموزش دهید. اگرچه بیشتر کار برای ایجاد دامنه LLM روی آموزش از ابتدا متمرکز شده است، اما بسیار گران است. به عنوان مثال، مدل GPT-4 هزینه دارد بیش از $ 100 میلیون برای آموزش این مدل ها بر روی ترکیبی از داده های دامنه باز و داده های دامنه آموزش داده شده اند. پیشآموزش مستمر میتواند به مدلها کمک کند تا دانش خاص دامنه را بدون متحمل شدن هزینههای پیشآموزشی از ابتدا به دست آورند، زیرا شما یک LLM دامنه باز موجود را فقط بر روی دادههای دامنه از قبل آموزش میدهید.
با تنظیم دقیق دستورالعمل روی یک کار، نمیتوانید مدل را وادار کنید دانش دامنه را به دست آورد زیرا LLM فقط اطلاعات دامنه موجود در مجموعه داده تنظیم دقیق دستورالعمل را به دست میآورد. مگر اینکه یک مجموعه داده بسیار بزرگ برای تنظیم دقیق دستورالعمل استفاده شود، برای کسب دانش دامنه کافی نیست. منبع یابی مجموعه داده های دستورالعمل با کیفیت بالا معمولاً چالش برانگیز است و دلیل استفاده از LLM در وهله اول است. همچنین، تنظیم دقیق دستورالعمل در یک کار می تواند بر عملکرد سایر وظایف تأثیر بگذارد (همانطور که در زیر مشاهده می شود این مقاله). با این حال، تنظیم دقیق دستورالعمل مقرون به صرفه تر از هر یک از جایگزین های قبل از آموزش است.
شکل زیر تنظیم دقیق کار خاص را با هم مقایسه می کند. در مقابل پارادایم یادگیری درون متنی با LLM.
 RAG موثرترین راه برای هدایت یک LLM برای تولید پاسخ های مبتنی بر یک دامنه است. اگرچه میتواند با ارائه حقایق از دامنه بهعنوان اطلاعات کمکی، مدلی را برای تولید پاسخها راهنمایی کند، اما زبان خاص دامنه را به دست نمیآورد زیرا LLM هنوز برای تولید پاسخها به سبک زبان غیر دامنه متکی است.
RAG موثرترین راه برای هدایت یک LLM برای تولید پاسخ های مبتنی بر یک دامنه است. اگرچه میتواند با ارائه حقایق از دامنه بهعنوان اطلاعات کمکی، مدلی را برای تولید پاسخها راهنمایی کند، اما زبان خاص دامنه را به دست نمیآورد زیرا LLM هنوز برای تولید پاسخها به سبک زبان غیر دامنه متکی است.
پیشآموزش مستمر، از نظر هزینه، راه حلی میانی بین پیشآموزش و تنظیم دقیق دستورالعمل است، در حالی که جایگزینی قوی برای کسب دانش و سبک خاص دامنه است. میتواند یک مدل کلی ارائه کند که بر اساس آن، تنظیم دقیق دستورالعملها در دادههای دستورالعمل محدود میتواند انجام شود. پیشآموزش مستمر میتواند یک استراتژی مقرونبهصرفه برای حوزههای تخصصی باشد که در آن مجموعه وظایف پاییندستی بزرگ یا ناشناخته است و دادههای تنظیم دستورالعمل برچسبگذاری شده محدود است. در سناریوهای دیگر، تنظیم دقیق دستورالعمل یا RAG ممکن است مناسب تر باشد.
برای کسب اطلاعات بیشتر در مورد آموزش تنظیم دقیق، RAG و مدل به ادامه مطلب مراجعه کنید یک مدل فونداسیون را دقیق تنظیم کنید, بازیابی نسل افزوده (RAG)و آموزش یک مدل با آمازون SageMaker، به ترتیب. برای این پست، ما بر روی پیشآموزش مستمر کارآمد تمرکز میکنیم.
روش شناسی کارآمد پیش آموزش مستمر
پیشآموزش مستمر شامل روششناسی زیر است:
- پیش آموزش مستمر تطبیقی با دامنه (DACP) - در کاغذ پیشآموزش مستمر کارآمد برای ساخت مدلهای زبان بزرگ خاص دامنه، نویسندگان به طور مداوم مجموعه مدل زبان Pythia را در مجموعه مالی پیش آموزش می دهند تا آن را با حوزه مالی تطبیق دهند. هدف ایجاد LLM های مالی با تغذیه داده ها از کل حوزه مالی به یک مدل منبع باز است. از آنجایی که مجموعه آموزشی شامل تمام مجموعه داده های مدیریت شده در حوزه است، مدل حاصل باید دانش مالی خاص را به دست آورد، در نتیجه تبدیل به یک مدل همه کاره برای وظایف مختلف مالی می شود. این منجر به مدل های FinPythia می شود.
- پیشآموزش مستمر تطبیقی با وظایف (TACP) - نویسندگان مدلها را از قبل بر روی دادههای وظایف برچسبدار و بدون برچسب بیشتر آموزش میدهند تا آنها را برای وظایف خاص تطبیق دهند. در شرایط خاص، توسعهدهندگان ممکن است مدلهایی را ترجیح دهند که عملکرد بهتری را در گروهی از وظایف درون دامنه ارائه میدهند تا مدلهای عمومی دامنه. TACP بهعنوان پیشآموزشی مستمر با هدف افزایش عملکرد در وظایف هدفگذاری شده، بدون نیاز به دادههای برچسبگذاری شده طراحی شده است. به طور خاص، نویسندگان به طور مداوم مدلهای منبع باز را روی نشانههای وظیفه (بدون برچسب) از قبل آموزش میدهند. محدودیت اولیه TACP در ساختن LLMهای خاص وظیفه به جای LLMهای بنیادی نهفته است که به دلیل استفاده انحصاری از داده های وظیفه بدون برچسب برای آموزش است. اگرچه DACP از مجموعه بسیار بزرگتری استفاده می کند، اما بسیار گران است. برای متعادل کردن این محدودیتها، نویسندگان دو رویکرد را پیشنهاد میکنند که با هدف ایجاد LLMهای بنیادی خاص دامنه و در عین حال حفظ عملکرد برتر در وظایف هدف:
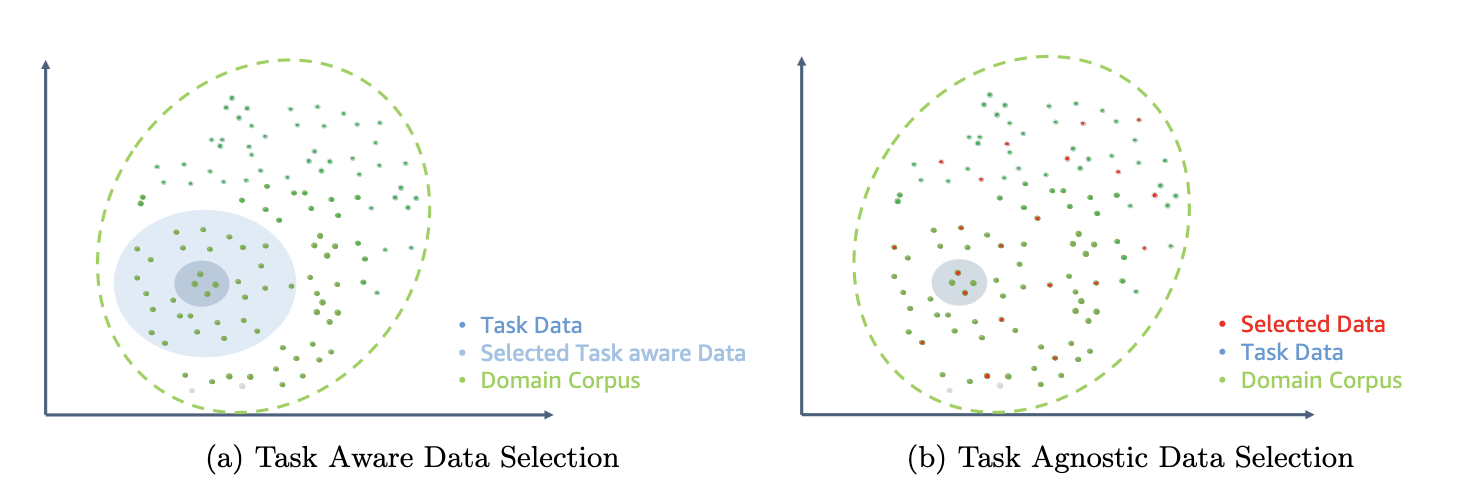
- DACP کارآمد مشابه (ETS-DACP) - نویسندگان انتخاب زیر مجموعه ای از پیکره مالی را پیشنهاد می کنند که با استفاده از تشابه جاسازی بسیار شبیه به داده های کار باشد. این زیرمجموعه برای پیش تمرین مداوم استفاده می شود تا کارآمدتر شود. به طور خاص، نویسندگان به طور مداوم LLM منبع باز را روی یک مجموعه کوچک استخراج شده از مجموعه مالی که نزدیک به وظایف هدف در توزیع است، از قبل آموزش می دهند. این میتواند به بهبود عملکرد کار کمک کند، زیرا ما این مدل را برای توزیع نشانههای وظیفه با وجود عدم نیاز به دادههای برچسبگذاری شده اتخاذ میکنیم.
- DACP کارآمد کارآمد (ETA-DACP) - نویسندگان استفاده از معیارهایی مانند گیجی و آنتروپی نوع رمز را پیشنهاد میکنند که برای انتخاب نمونهها از مجموعه مالی برای پیشآموزش کارآمد مستمر، به دادههای وظیفه نیازی ندارد. این رویکرد برای مقابله با سناریوهایی طراحی شده است که در آن داده های وظیفه در دسترس نیست یا مدل های دامنه همه کاره تر برای دامنه وسیع تر ترجیح داده می شوند. نویسندگان برای انتخاب نمونه های داده ای که برای به دست آوردن اطلاعات دامنه از زیرمجموعه ای از داده های حوزه پیش از آموزش مهم هستند، دو بعد را انتخاب می کنند: تازگی و تنوع. تازگی، که با گیجی ثبت شده توسط مدل هدف اندازه گیری می شود، به اطلاعاتی اشاره دارد که قبلا توسط LLM دیده نشده بود. داده های با تازگی بالا نشان دهنده دانش جدید برای LLM است و یادگیری چنین داده هایی دشوارتر است. این LLM های عمومی را با دانش گسترده دامنه در طول پیش آموزش مداوم به روز می کند. از سوی دیگر، تنوع، تنوع توزیع انواع نشانهها را در مجموعه دامنه به تصویر میکشد که به عنوان یک ویژگی مفید در تحقیق یادگیری برنامه درسی در مورد مدلسازی زبان مستند شده است.
شکل زیر نمونه ای از ETS-DACP (چپ) را در مقابل ETA-DACP (راست) مقایسه می کند.
ما دو طرح نمونهگیری را برای انتخاب فعال نقاط داده از مجموعه مالی انتخاب شده اتخاذ میکنیم: نمونهگیری سخت و نمونهگیری نرم. اولی با رتبهبندی مجموعه مالی با معیارهای مربوطه و سپس انتخاب نمونههای top-k انجام میشود، جایی که k با توجه به بودجه آموزشی از پیش تعیین میشود. برای دومی، نویسندگان وزنهای نمونهگیری را برای هر نقطه داده با توجه به مقادیر متریک اختصاص میدهند و سپس بهطور تصادفی از k نقطه داده نمونهبرداری میکنند تا بودجه آموزشی را برآورده کنند.
نتیجه و تحلیل
نویسندگان LLM های مالی حاصل را در مجموعه ای از وظایف مالی برای بررسی اثربخشی پیش آموزش مستمر ارزیابی می کنند:
- بانک عبارات مالی - وظیفه طبقه بندی احساسات در اخبار مالی.
- FiQA SA - یک کار طبقه بندی احساسات مبتنی بر جنبه بر اساس اخبار و سرفصل های مالی.
- عنوان - یک کار طبقه بندی دودویی در مورد اینکه آیا عنوان یک واحد مالی حاوی اطلاعات خاصی است یا خیر.
- NER - یک وظیفه استخراج نهاد با نام مالی بر اساس بخش ارزیابی ریسک اعتباری گزارش های SEC. کلمات در این کار با PER، LOC، ORG و MISC حاشیه نویسی می شوند.
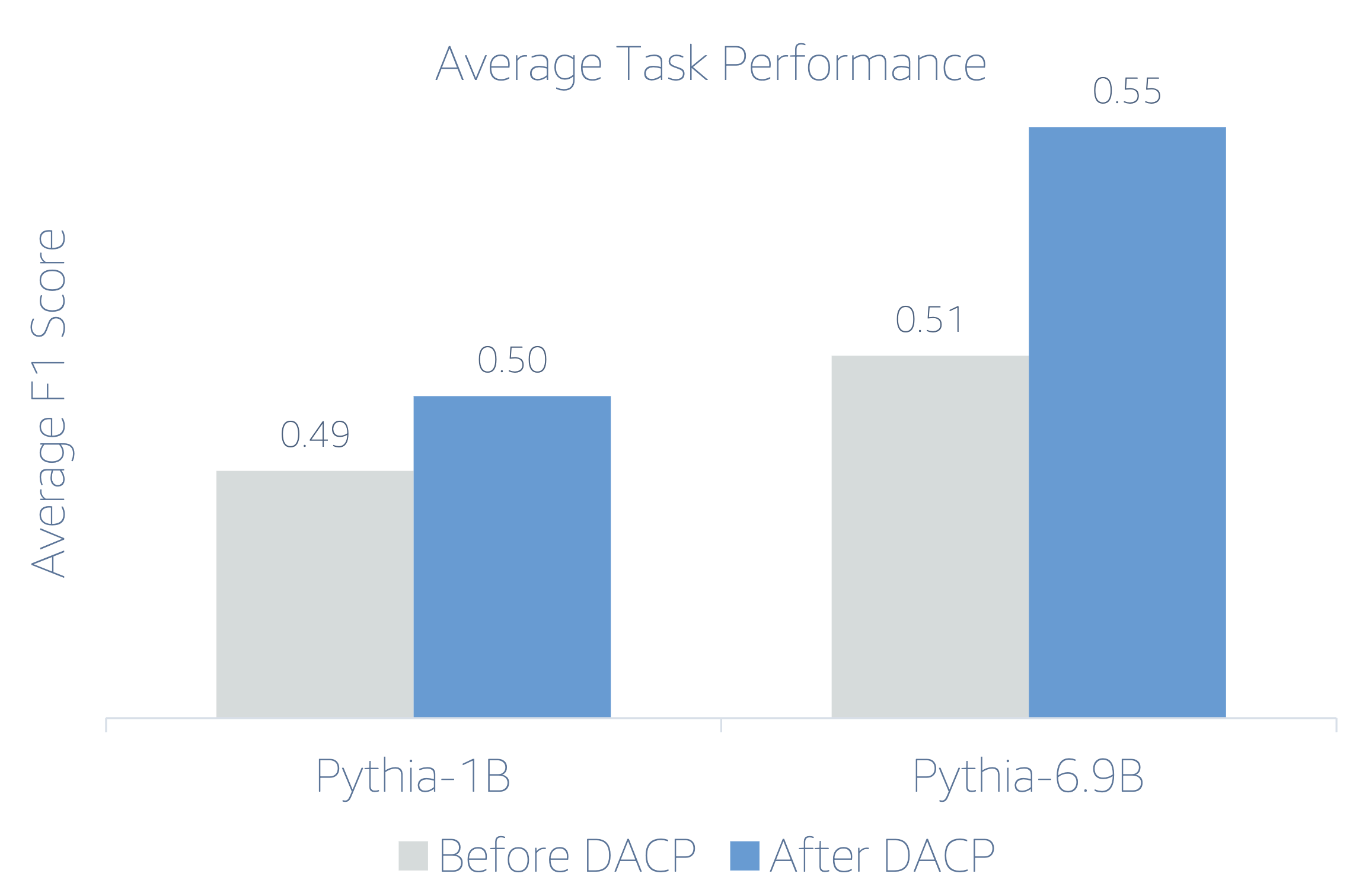
از آنجایی که LLM های مالی دستورالعمل ها را دقیق تنظیم می کنند، نویسندگان مدل ها را در یک تنظیم 5 شات برای هر کار به خاطر استحکام ارزیابی می کنند. به طور متوسط، FinPythia 6.9B در چهار کار، 6.9% بهتر از Pythia 10B عمل می کند، که نشان دهنده کارآمدی پیش آموزش مداوم برای دامنه خاص است. برای مدل 1B، بهبود کمتر عمیق است، اما عملکرد هنوز به طور متوسط 2٪ بهبود می یابد.
شکل زیر تفاوت عملکرد قبل و بعد از DACP را در هر دو مدل نشان می دهد.
شکل زیر دو نمونه کیفی تولید شده توسط Pythia 6.9B و FinPythia 6.9B را نشان می دهد. برای دو سوال مرتبط با امور مالی در مورد مدیر سرمایه گذار و یک اصطلاح مالی، Pythia 6.9B این اصطلاح را نمیفهمد یا نام آن را نمیشناسد، در حالی که FinPythia 6.9B پاسخهای دقیق را به درستی ایجاد میکند. مثالهای کیفی نشان میدهند که پیشآموزش مستمر LLM را قادر میسازد تا دانش دامنه را در طول فرآیند به دست آورند.

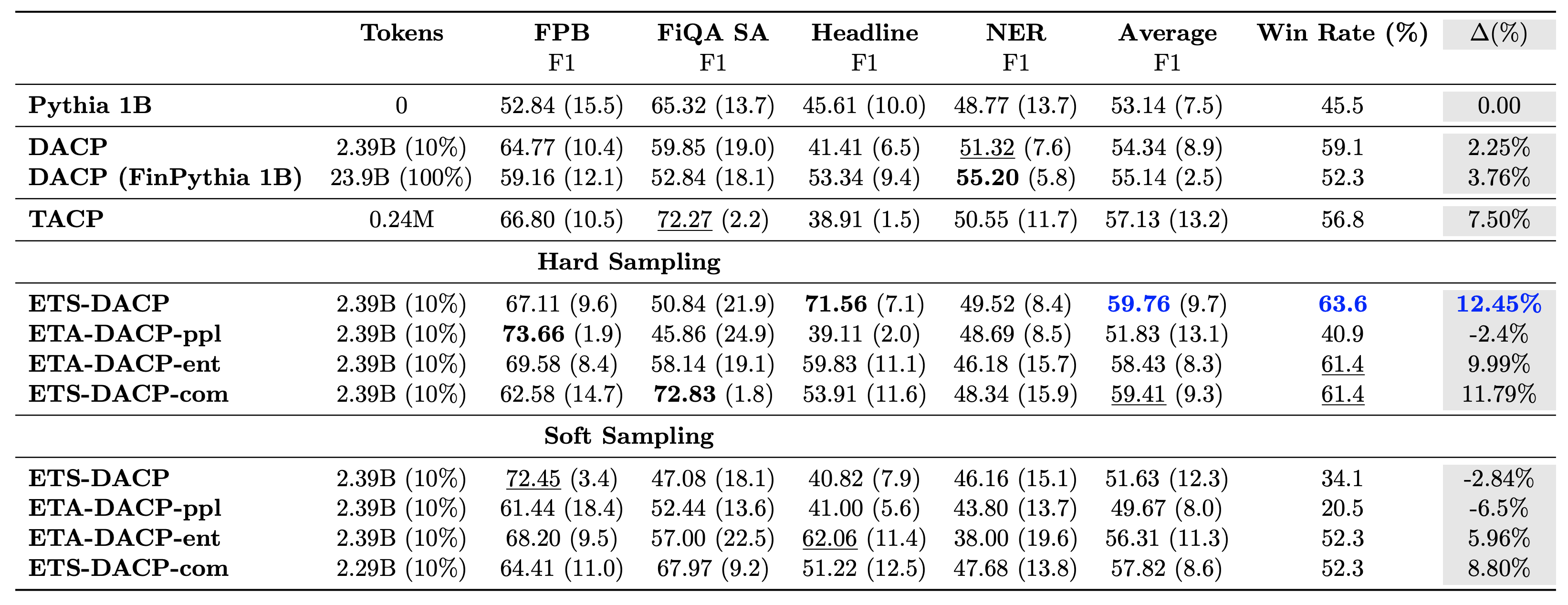
جدول زیر روش های مختلف کارآمد پیش تمرینی را با هم مقایسه می کند. ETA-DACP-ppl بر اساس سرگشتگی (تازه) ETA-DACP است و ETA-DACP-ent بر اساس آنتروپی (تنوع) است. ETS-DACP-com مشابه DACP با انتخاب داده با میانگین هر سه معیار است. در زیر چند برداشت از نتایج آورده شده است:
- روش های انتخاب داده کارآمد هستند - آنها فقط با 10٪ داده های آموزشی از پیش تمرین مداوم استاندارد پیشی می گیرند. پیشآموزش مستمر کارآمد شامل DACP Task-Similar (ETS-DACP)، Task-Agnostic DACP مبتنی بر آنتروپی (ESA-DACP-ent) و DACP-Similar بر اساس هر سه معیار (ETS-DACP-com) از DACP استاندارد بهتر عمل میکند. به طور متوسط علیرغم این واقعیت که آنها فقط در 10٪ از مجموعه مالی آموزش دیده اند.
- انتخاب دادههای آگاه از وظیفه بهترین عملکرد را در راستای تحقیقات مدلهای زبان کوچک دارد – ETS-DACP بهترین میانگین عملکرد را در بین تمام روشها ثبت میکند و بر اساس هر سه معیار، دومین عملکرد برتر کار را ثبت میکند. این نشان میدهد که استفاده از دادههای وظیفه بدون برچسب هنوز یک رویکرد مؤثر برای افزایش عملکرد کار در مورد LLM است.
- انتخاب داده های Task-Agnostic در رده دوم قرار دارد - ESA-DACP-ent از عملکرد رویکرد انتخاب داده آگاهانه از وظیفه پیروی می کند، به این معنی که ما همچنان می توانیم با انتخاب فعال نمونه های با کیفیت بالا که به وظایف خاصی مرتبط نیستند، عملکرد کار را افزایش دهیم. این راه را برای ایجاد LLMهای مالی برای کل دامنه و در عین حال دستیابی به عملکرد برتر هموار می کند.
یک سوال مهم در مورد پیشآموزش مستمر این است که آیا تاثیر منفی بر عملکرد در کارهای غیر دامنه دارد یا خیر. نویسندگان همچنین مدل از پیش آموزشدیدهشده را بر روی چهار کار عمومی پرکاربرد ارزیابی میکنند: ARC، MMLU، TruthQA، و HellaSwag، که توانایی پاسخگویی به سؤال، استدلال، و تکمیل را اندازهگیری میکنند. نویسندگان دریافتهاند که پیشآموزش مستمر تأثیر منفی بر عملکرد غیر دامنهای ندارد. برای جزئیات بیشتر مراجعه کنید پیشآموزش مستمر کارآمد برای ساخت مدلهای زبان بزرگ خاص دامنه.
نتیجه
این پست بینشهایی را در مورد جمعآوری دادهها و استراتژیهای پیشآموزشی مستمر برای آموزش LLM برای حوزه مالی ارائه میدهد. می توانید با استفاده از آموزش LLM های خود را برای کارهای مالی شروع کنید آموزش آمازون SageMaker or بستر آمازون امروز.
درباره نویسنده
 یونگ زی یک دانشمند کاربردی در آمازون فین تک است. او بر توسعه مدلهای زبان بزرگ و برنامههای کاربردی هوش مصنوعی برای امور مالی تمرکز دارد.
یونگ زی یک دانشمند کاربردی در آمازون فین تک است. او بر توسعه مدلهای زبان بزرگ و برنامههای کاربردی هوش مصنوعی برای امور مالی تمرکز دارد.
 کاران آگاروال یک دانشمند کاربردی ارشد در آمازون فینتک با تمرکز بر هوش مصنوعی مولد برای موارد استفاده مالی است. کاران تجربه گسترده ای در تجزیه و تحلیل سری های زمانی و NLP دارد و علاقه خاصی به یادگیری از داده های برچسب گذاری شده محدود دارد.
کاران آگاروال یک دانشمند کاربردی ارشد در آمازون فینتک با تمرکز بر هوش مصنوعی مولد برای موارد استفاده مالی است. کاران تجربه گسترده ای در تجزیه و تحلیل سری های زمانی و NLP دارد و علاقه خاصی به یادگیری از داده های برچسب گذاری شده محدود دارد.
 اعتزاز احمد یک مدیر علوم کاربردی در آمازون است که در آنجا تیمی از دانشمندان را رهبری می کند که برنامه های مختلف یادگیری ماشین و هوش مصنوعی تولیدی در امور مالی ایجاد می کنند. علایق تحقیقاتی او در NLP، Generative AI و LLM Agents است. او دکترای خود را در رشته مهندسی برق از دانشگاه A&M تگزاس دریافت کرد.
اعتزاز احمد یک مدیر علوم کاربردی در آمازون است که در آنجا تیمی از دانشمندان را رهبری می کند که برنامه های مختلف یادگیری ماشین و هوش مصنوعی تولیدی در امور مالی ایجاد می کنند. علایق تحقیقاتی او در NLP، Generative AI و LLM Agents است. او دکترای خود را در رشته مهندسی برق از دانشگاه A&M تگزاس دریافت کرد.
 کینگوی لی یک متخصص یادگیری ماشین در خدمات وب آمازون است. او دکترای خود را دریافت کرد. در تحقیقات عملیات پس از اینکه حساب کمک هزینه تحقیقاتی مشاورش را شکست و نتوانست جایزه نوبل را که وعده داده بود تحویل دهد. در حال حاضر او به مشتریان در خدمات مالی کمک می کند تا راه حل های یادگیری ماشینی را در AWS بسازند.
کینگوی لی یک متخصص یادگیری ماشین در خدمات وب آمازون است. او دکترای خود را دریافت کرد. در تحقیقات عملیات پس از اینکه حساب کمک هزینه تحقیقاتی مشاورش را شکست و نتوانست جایزه نوبل را که وعده داده بود تحویل دهد. در حال حاضر او به مشتریان در خدمات مالی کمک می کند تا راه حل های یادگیری ماشینی را در AWS بسازند.
 راغوندر آرنی تیم شتاب مشتری (CAT) را در صنایع AWS رهبری می کند. CAT یک تیم متقابل جهانی متشکل از معماران ابری، مهندسین نرمافزار، دانشمندان داده و کارشناسان و طراحان AI/ML است که نوآوری را از طریق نمونهسازی پیشرفته، و تعالی عملیاتی ابر را از طریق تخصص فنی تخصصی هدایت میکند.
راغوندر آرنی تیم شتاب مشتری (CAT) را در صنایع AWS رهبری می کند. CAT یک تیم متقابل جهانی متشکل از معماران ابری، مهندسین نرمافزار، دانشمندان داده و کارشناسان و طراحان AI/ML است که نوآوری را از طریق نمونهسازی پیشرفته، و تعالی عملیاتی ابر را از طریق تخصص فنی تخصصی هدایت میکند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/efficient-continual-pre-training-llms-for-financial-domains/

