این پست با سوهیونگ کیم، مدیر کل آزمایشگاه تجزیه و تحلیل داده KakaoGames نوشته شده است.
بازی های کاکائو یک ناشر و توسعه دهنده برتر بازی های ویدیویی است که دفتر مرکزی آن در کره جنوبی قرار دارد. این شرکت در توسعه و انتشار بازیها بر روی رایانه شخصی، موبایل، و واقعیت مجازی (VR) در سطح جهانی تخصص دارد. به منظور به حداکثر رساندن تجربه بازیکنان خود و بهبود کارایی عملیات و بازاریابی، آنها به طور مداوم آیتم های جدید درون بازی را اضافه می کنند و برای بازیکنان خود تبلیغات ارائه می دهند. نتیجه این اتفاقات را می توان بعدا ارزیابی کرد تا در آینده تصمیمات بهتری بگیرند.
با این حال، این رویکرد واکنشی است. اگر بتوانیم ارزش طول عمر (LTV) را پیشبینی کنیم، میتوانیم رویکردی فعالانه داشته باشیم. به عبارت دیگر، این فعالیتها را میتوان بر اساس LTV پیشبینیشده برنامهریزی و اجرا کرد، که ارزشهای بازیکنان را در طول عمرشان در بازی تعیین میکند. با این رویکرد پیشگیرانه، Kakao Games می تواند رویدادهای مناسب را در زمان مناسب راه اندازی کند. اگر LTV پیشبینیشده برای برخی از بازیکنان در حال کاهش باشد، به این معنی است که بازیکنان به زودی ترک خواهند کرد. سپس Kakao Games می تواند یک رویداد تبلیغاتی برای ترک بازی ایجاد کند. این امر باعث می شود که پیش بینی دقیق LTV بازیکنان آنها مهم باشد. LTV اندازه گیری است که نه تنها توسط شرکت های بازی، بلکه هر نوع خدماتی با درگیری طولانی مدت مشتری اتخاذ می شود. روشهای آماری و روشهای یادگیری ماشین (ML) به طور فعال برای به حداکثر رساندن LTV توسعه یافته و اتخاذ شدهاند.
در این پست نحوه بازی های Kakao و بازی ها را به اشتراک می گذاریم آزمایشگاه راه حل های یادگیری ماشین آمازون برای ایجاد یک راه حل مقیاس پذیر و قابل اعتماد برای پیش بینی LTV با استفاده از داده های AWS و خدمات ML مانند چسب AWS و آمازون SageMaker.
ما یکی از محبوب ترین بازی های Kakao Games را انتخاب کردیم، اودین، به عنوان بازی هدف پروژه. ODIN یک بازی پرطرفدار نقش آفرینی آنلاین چند نفره (MMORPG) برای رایانه شخصی و دستگاه های تلفن همراه است که توسط Kakao Games منتشر و اجرا می شود. در ژوئن 2021 راه اندازی شد و در بین سه رتبه برتر درآمد در کره قرار گرفته است.

چالش ها
در این بخش، چالشهای پیرامون منابع مختلف داده، جابجایی دادهها ناشی از رویدادهای داخلی یا خارجی و قابلیت استفاده مجدد راهحلها را مورد بحث قرار میدهیم. این چالشها معمولاً زمانی که ما راهحلهای ML را پیادهسازی میکنیم و آنها را در یک محیط تولید مستقر میکنیم، با آن مواجه میشویم.
رفتار بازیکن تحت تأثیر رویدادهای داخلی و خارجی
پیشبینی دقیق LTV چالش برانگیز است، زیرا عوامل پویا زیادی بر رفتار بازیکن تأثیر میگذارند. این موارد شامل تبلیغات بازی، موارد جدید اضافه شده، تعطیلات، ممنوع کردن حسابها به دلیل سوء استفاده یا بازی غیرقانونی، یا رویدادهای خارجی غیرمنتظره مانند رویدادهای ورزشی یا شرایط آب و هوایی شدید است. این بدان معنی است که مدلی که در این ماه کار می کند ممکن است ماه آینده به خوبی کار نکند.
میتوانیم از رویدادهای خارجی بهعنوان ویژگیهای ML همراه با گزارشها و دادههای مربوط به بازی استفاده کنیم. مثلا، پیش بینی آمازون از داده های سری زمانی مرتبط مانند آب و هوا، قیمت ها، شاخص های اقتصادی یا تبلیغات برای منعکس کردن رویدادهای مرتبط داخلی و خارجی پشتیبانی می کند. رویکرد دیگر این است که مدلهای ML را بهطور منظم بهروزرسانی کنیم، زمانی که جابجایی دادهها مشاهده میشود. برای راهحل خود، روش دوم را انتخاب کردیم زیرا دادههای رویداد مرتبط در دسترس نبود و مطمئن نبودیم که دادههای موجود چقدر قابل اعتماد هستند.
بازآموزی مداوم مدل ML یکی از روشهای غلبه بر این چالش با یادگیری مجدد از جدیدترین دادهها است. این نه تنها به ویژگی های خوب طراحی شده و معماری ML نیاز دارد، بلکه به آماده سازی داده ها و خطوط لوله ML نیز نیاز دارد که می تواند فرآیند بازآموزی را خودکار کند. در غیر این صورت، راه حل ML به دلیل پیچیدگی و تکرارپذیری ضعیف، نمی تواند به طور موثر در محیط تولید کار کند.
آموزش مجدد مدل با استفاده از آخرین مجموعه داده آموزشی کافی نیست. مدل بازآموزی شده ممکن است نتیجه پیشبینی دقیقتری نسبت به مدل موجود ارائه نکند، بنابراین ما نمیتوانیم به سادگی مدل را با مدل جدید جایگزین کنیم بدون هیچ ارزیابی. اگر مدل جدید به دلایلی شروع به عملکرد ضعیف کرد، باید بتوانیم به مدل قبلی برگردیم.
برای حل این مشکل، ما مجبور شدیم یک خط لوله داده قوی برای ایجاد ویژگی های ML از داده های خام و MLOs طراحی کنیم.
منابع داده چندگانه
ODIN یک MMORPG است که در آن بازیکنان بازی با یکدیگر تعامل دارند و رویدادهای مختلفی مانند ارتقا سطح، خرید آیتم و شکار طلا (پول بازی) وجود دارد. هر روز حدود 300 گیگابایت گزارش از بیش از 10 میلیون بازیکن خود در سراسر جهان تولید می کند. گزارش های بازی انواع مختلفی دارند، مانند ورود به سیستم بازیکن، فعالیت بازیکن، خرید بازیکن و ارتقاء سطح بازیکن. این نوع داده ها، داده های خام تاریخی از دیدگاه ML هستند. به عنوان مثال، هر گزارش در قالب مهر زمانی، شناسه کاربری و اطلاعات رویداد نوشته شده است. فاصله سیاههها یکنواخت نیست. همچنین، دادههای ثابتی برای توصیف بازیکنان مانند سن و تاریخ ثبت نام وجود دارد که دادههای غیر تاریخی است. مدلسازی پیشبینی LTV به این دو نوع داده به عنوان ورودی نیاز دارد، زیرا آنها مکمل یکدیگر هستند تا ویژگیها و رفتار بازیکن را نشان دهند.
برای این راهحل، ما تصمیم گرفتیم مجموعه داده جدولی را با ترکیب ویژگیهای تاریخی با تعداد ثابت مراحل جمعآوری شده همراه با ویژگیهای پخشکننده استاتیک تعریف کنیم. ویژگیهای تاریخی جمعآوری شده از طریق چندین مرحله از تعداد گزارشهای بازی که در آن ذخیره میشوند، ایجاد میشوند آمازون آتنا جداول علاوه بر چالش تعریف ویژگیها برای مدل ML، خودکار کردن فرآیند تولید ویژگی بسیار مهم است تا بتوانیم ویژگیهای ML را از دادههای خام برای استنتاج ML و بازآموزی مدل دریافت کنیم.
برای حل این مشکل، ما یک خط لوله استخراج، تبدیل و بارگذاری (ETL) می سازیم که می تواند به طور خودکار و مکرر برای ایجاد مجموعه داده های آموزشی و استنتاج اجرا شود.
مقیاس پذیری برای بازی های دیگر
Kakao Games بازیهای دیگری مانند ODIN با درگیری طولانی مدت بازیکن دارد. به طور طبیعی، پیشبینی LTV به آن بازیها نیز سود میرساند. از آنجایی که اکثر بازیها انواع گزارش مشابه دارند، میخواهند از این راهحل ML برای بازیهای دیگر استفاده کنند. وقتی مدل ML را طراحی میکنیم، میتوانیم این نیاز را با استفاده از گزارش و ویژگیهای مشترک در بین بازیهای مختلف برآورده کنیم. اما هنوز یک چالش مهندسی وجود دارد. خط لوله ETL، خط لوله MLOps و استنتاج ML باید در یک حساب AWS متفاوت بازسازی شوند. استقرار دستی این راه حل پیچیده مقیاس پذیر نیست و راه حل مستقر شده به سختی نگهداری می شود.
برای حل این مشکل، راه حل ML را با چند تغییر پیکربندی به طور خودکار قابل استقرار می کنیم.
بررسی اجمالی راه حل
راهحل ML برای پیشبینی LTV از چهار جزء تشکیل شده است: خط لوله مجموعه داده آموزشی ETL، خط لوله MLOps، خط لوله دادههای استنتاج ETL، و استنتاج دستهای ML.
خط لوله آموزش و استنتاج ETL ویژگیهای ML را از گزارشهای بازی و ابردادههای بازیکن ذخیره شده در جداول Athena ایجاد میکند و دادههای ویژگی حاصل را در یک ذخیره میکند. سرویس ذخیره سازی ساده آمازون سطل (Amazon S3). ETL به چندین مرحله تبدیل نیاز دارد و گردش کار با استفاده از چسب AWS پیاده سازی می شود. MLOps مدل های ML را آموزش می دهد، مدل آموزش دیده را با مدل موجود ارزیابی می کند و سپس مدل آموزش دیده را در صورت عملکرد بهتر از مدل موجود در رجیستری مدل ثبت می کند. اینها همه به عنوان یک خط لوله ML با استفاده از پیاده سازی می شوند خطوط لوله آمازون SageMaker، و تمام آموزش های ML از طریق مدیریت می شوند آزمایشات آمازون SageMaker. با SageMaker Experiments، مهندسان ML میتوانند بیابند که کدام مجموعه دادههای آموزشی و ارزیابی، فراپارامترها و پیکربندیها برای هر مدل ML در طول آموزش یا بعد از آن مورد استفاده قرار گرفتهاند. مهندسین ML دیگر نیازی به مدیریت جداگانه این ابرداده آموزشی ندارند.
آخرین مؤلفه استنتاج دسته ای ML است که به طور منظم برای پیش بینی LTV برای چند هفته آینده اجرا می شود.
شکل زیر نشان می دهد که چگونه این اجزا به عنوان یک راه حل واحد ML با هم کار می کنند.

معماری راه حل با استفاده از کیت توسعه ابری AWS (AWS CDK) برای ارتقای زیرساخت به عنوان کد (IaC)، که کنترل نسخه و استقرار راه حل را در حساب های مختلف AWS و مناطق آسان می کند.
در بخشهای بعدی، هر یک از اجزاء را با جزئیات بیشتری مورد بحث قرار میدهیم.
خط لوله داده برای تولید ویژگی ML
لاگ های بازی ذخیره شده در Athena با پشتیبانی آمازون S3 از طریق خطوط لوله ETL ایجاد شده به عنوان مشاغل پوسته Python در AWS Glue می گذرد. اجرای اسکریپتهای پایتون با چسب AWS را برای بررسی ویژگیها برای تولید مجموعه داده آماده برای آموزش فعال میکند. جداول مربوطه در هر فاز در آتنا ایجاد می شود. ما از چسب AWS برای اجرای خط لوله ETL به دلیل معماری بدون سرور و انعطاف پذیری آن در تولید نسخه های مختلف مجموعه داده با عبور در تاریخ های مختلف شروع و پایان استفاده می کنیم. رجوع شود به دسترسی به پارامترها با استفاده از getResolvedOptions برای کسب اطلاعات بیشتر در مورد نحوه انتقال پارامترها به یک کار چسب AWS. با استفاده از این روش، مجموعه دادهها را میتوان برای مدت کوتاهی به مدت 4 هفته ایجاد کرد و از بازی در مراحل اولیه پشتیبانی کرد. برای مثال، تاریخ شروع ورودی و تاریخ شروع پیشبینی برای هر نسخه از مجموعه دادهها از طریق کد زیر تجزیه میشوند:
کارهای چسب AWS طراحی و به مراحل مختلف تقسیم می شوند و به صورت متوالی فعال می شوند. هر کار به گونهای پیکربندی شده است که آرگومانهای جفت موقعیتی و کلید-مقدار را برای اجرای خطوط لوله ETL سفارشیسازی کند. یکی از پارامترهای کلیدی تاریخ شروع و پایان داده هایی است که در آموزش استفاده می شود. این به این دلیل است که تاریخ شروع و پایان داده ها احتمالاً تعطیلات مختلف را در بر می گیرد و به عنوان یک عامل مستقیم در تعیین طول مجموعه داده عمل می کند. برای مشاهده تأثیر این پارامتر بر عملکرد مدل، ما نه نسخه مجموعه داده مختلف (با تاریخ شروع و طول دوره آموزشی متفاوت) ایجاد کردیم.
به طور خاص، ما نسخههای مجموعه دادههایی را با تاریخهای شروع متفاوت (تغییر ۴ هفته) و دورههای آموزشی متفاوت (۱۲ هفته، ۱۶ هفته، ۲۰ هفته، ۲۴ هفته و ۲۸ هفته) در نه پایگاه داده Athena ایجاد کردیم که توسط آمازون S4 پشتیبانی میشوند. هر نسخه از مجموعه داده شامل ویژگی هایی است که ویژگی های بازیکن و داده های سری زمانی فعالیت خرید درون بازی را توصیف می کند.
مدل ML
انتخاب کردیم AutoGluon برای آموزش مدل اجرا شده با خطوط لوله SageMaker. AutoGluon یک جعبه ابزار برای یادگیری ماشین خودکار (AutoML) است. این نرم افزار AutoML با استفاده آسان و گسترش آسان را با تمرکز بر مجموعه خودکار پشته، یادگیری عمیق و برنامه های کاربردی دنیای واقعی که شامل تصویر، متن و داده های جدولی هستند، فعال می کند.
میتوانید از AutoGluon مستقل برای آموزش مدلهای ML یا همراه با آن استفاده کنید Amazon SageMaker Autopilot، یکی از ویژگی های SageMaker است که یک محیط کاملاً مدیریت شده برای آموزش و استقرار مدل های ML فراهم می کند.
به طور کلی، اگر میخواهید از محیط کاملاً مدیریتشده ارائهشده توسط SageMaker، از جمله ویژگیهایی مانند مقیاسگذاری خودکار و مدیریت منابع، و همچنین استقرار آسان مدلهای آموزشدیده، استفاده کنید، باید از AutoGluon با Autopilot استفاده کنید. این می تواند به ویژه مفید باشد اگر در ML تازه کار هستید و می خواهید روی آموزش و ارزیابی مدل ها تمرکز کنید بدون اینکه نگران زیرساخت های اساسی باشید.
هنگامی که می خواهید مدل های ML را به روشی سفارشی آموزش دهید، می توانید از AutoGluon مستقل نیز استفاده کنید. در مورد ما، ما از AutoGluon با SageMaker برای تحقق یک پیشبینی دو مرحلهای، از جمله طبقهبندی انحراف و رگرسیون ارزش طول عمر استفاده کردیم. در این صورت، بازیکنانی که از خرید آیتم های بازی منصرف شده اند، به عنوان خراشیده در نظر گرفته می شوند.
بیایید در مورد رویکرد مدلسازی برای پیشبینی LTV و اثربخشی بازآموزی مدل در برابر علامت رانش داده صحبت کنیم، که به معنای رویدادهای داخلی یا خارجی است که الگوی خرید بازیکن را تغییر میدهد.
ابتدا، فرآیندهای مدلسازی به دو مرحله، شامل یک طبقهبندی باینری (طبقهبندی یک بازیکن بهعنوان خرد شده یا نه) و یک مدل رگرسیونی که برای پیشبینی مقدار LTV برای بازیکنانی که چروک نشدهاند، آموزش داده شد، تقسیم شدند:
- مرحله 1 - مقادیر هدف برای LTV به یک برچسب باینری تبدیل می شود،
LTV = 0وLTV > 0. AutoGluon TabularPredictor برای به حداکثر رساندن امتیاز F1 آموزش دیده است. - مرحله 2 - یک مدل رگرسیون با استفاده از AutoGluon TabularPredictor برای آموزش مدل به کاربران استفاده می شود
LTV > 0برای رگرسیون LTV واقعی
در مرحله آزمایش مدل، دادههای آزمایشی بهطور متوالی از دو مدل عبور میکنند:
- مرحله 1 – مدل طبقهبندی باینری روی دادههای آزمایشی اجرا میشود تا پیشبینی باینری 0 را بدست آورد (کاربر دارای
LTV = 0, churned) یا 1 (کاربر داردLTV > 0، خرد نشده است). - مرحله 2 – بازیکنان پیش بینی شده با
LTV > 0برای بدست آوردن مقدار واقعی LTV پیش بینی شده از مدل رگرسیون استفاده کنید. همراه با کاربر پیش بینی شده به عنوان داشتنLTV = 0، نتیجه نهایی پیش بینی LTV تولید می شود.
مصنوعات مدل مرتبط با پیکربندیهای آموزشی برای هر آزمایش و برای هر نسخه از مجموعه دادهها پس از آموزش در یک سطل S3 ذخیره میشوند و همچنین در SageMaker Model Registry در اجرای SageMaker Pipelines ثبت میشوند.
برای آزمایش اینکه آیا به دلیل استفاده از مدل مشابه آموزش داده شده در مجموعه داده v1 (12 هفته از اکتبر) هرگونه جابجایی داده وجود دارد یا خیر، استنتاج را روی مجموعه داده v1، v2 (زمان شروع 4 هفته به جلو منتقل شد)، v3 (انتقال به جلو توسط 8 هفته) و به همین ترتیب برای نسخه 4 و 5. جدول زیر عملکرد مدل را خلاصه می کند. معیاری که برای مقایسه مورد استفاده قرار می گیرد، حداقل امتیاز است که محدوده آن 0-1 است. زمانی که پیشبینی LTV به مقدار LTV واقعی نزدیکتر باشد، عدد بالاتری به دست میدهد.
| نسخه مجموعه داده | حداقل امتیاز | تفاوت با v1 |
| v1 | 0.68756 | - |
| v2 | 0.65283 | -0.03473 |
| v3 | 0.66173 | -0.02584 |
| v4 | 0.69633 | 0.00877 |
| v5 | 0.71533 | 0.02777 |
یک افت عملکرد در مجموعه داده v2 و v3 مشاهده میشود، که با تحلیل انجام شده در رویکردهای مدلسازی مختلف که عملکرد کاهشی روی مجموعه دادههای v2 و v3 دارند، مطابقت دارد. برای نسخه 4 و 5، مدل عملکردی معادل را نشان میدهد و حتی در نسخه 5 بدون آموزش مجدد مدل، بهبود جزئی را نشان میدهد. با این حال، هنگام مقایسه عملکرد مدل v1 در مجموعه داده v5 (0.71533) در مقابل عملکرد مدل v5 در مجموعه داده v5 (0.7599)، بازآموزی مدل عملکرد را به طور قابل توجهی بهبود می بخشد.
خط لوله آموزشی
SageMaker Pipelines راههای آسانی برای نوشتن، مدیریت و استفاده مجدد از گردشهای کاری ML ارائه میکند. بهترین مدل ها را برای استقرار در تولید انتخاب کنید. ردیابی مدل ها به صورت خودکار. و CI/CD را در خطوط لوله ML ادغام کنید.
در مرحله آموزش یک SageMaker Estimator با کد زیر ساخته می شود. برخلاف SageMaker Estimator معمولی برای ایجاد یک کار آموزشی، ما یک جلسه خط لوله SageMaker را به SageMaker_session به جای یک جلسه SageMaker:
تصویر پایه با کد زیر بازیابی می شود:
مدل آموزش دیده فرآیند ارزیابی را طی می کند، جایی که متریک هدف حداقل حداکثر است. امتیاز بزرگتر از بهترین امتیاز حداقل LTV فعلی منجر به مرحله ثبت مدل می شود، در حالی که امتیاز حداقل LTV کمتر منجر به به روز رسانی نسخه مدل ثبت شده فعلی نمی شود. ارزیابی مدل بر روی مجموعه داده آزمون holdout به عنوان یک کار پردازش SageMaker اجرا می شود.
مرحله ارزیابی با کد زیر تعریف می شود:
وقتی ارزیابی مدل کامل شد، باید نتیجه ارزیابی (minmax) را با عملکرد مدل موجود مقایسه کنیم. ما یک مرحله خط لوله دیگر را تعریف می کنیم، step_cond.
با تمام مراحل لازم تعریف شده، خط لوله ML را می توان با کد زیر ساخته و اجرا کرد:
کل گردش کار قابل پیگیری و تجسم است Amazon SageMaker Studio، همانطور که در نمودار زیر نشان داده شده است. کارهای آموزش ML توسط SageMaker Experiment به طور خودکار ردیابی می شوند تا بتوانید پیکربندی آموزش ML، فراپارامترها، مجموعه داده ها و مدل آموزش دیده هر کار آموزشی را بیابید. هر یک از ماژول ها، لاگ ها، پارامترها، خروجی ها و غیره را انتخاب کنید تا آنها را با جزئیات بررسی کنید.
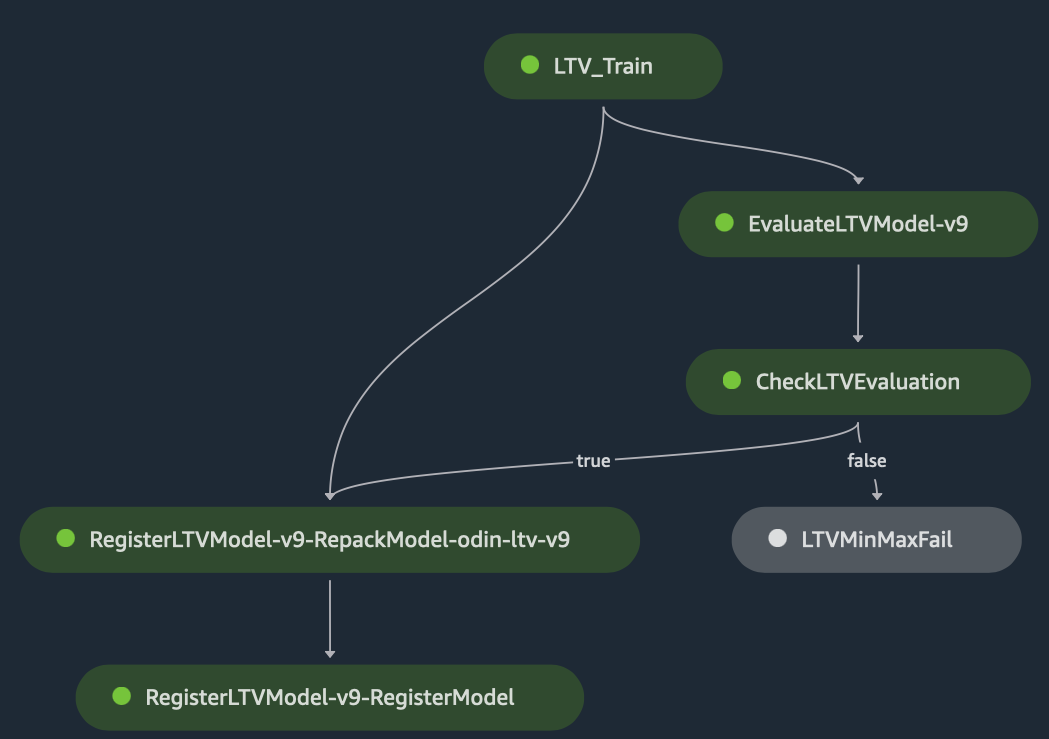
استنتاج دسته ای خودکار
در مورد پیشبینی LTV، استنتاج دستهای به استنتاج بلادرنگ ترجیح داده میشود زیرا LTV پیشبینیشده برای کارهای پاییندستی آفلاین بهطور معمول استفاده میشود. درست مانند ایجاد ویژگی های ML از مجموعه داده آموزشی از طریق ETL چند مرحله ای، ما باید ویژگی های ML را به عنوان ورودی مدل پیش بینی LTV ایجاد کنیم. ما از همان گردش کار چسب AWS برای تبدیل داده های پخش کننده به ویژگی های ML استفاده می کنیم، اما تقسیم داده ها و تولید برچسب انجام نمی شود. ویژگی ML حاصل در سطل S3 تعیین شده ذخیره می شود که توسط یک مانیتور می شود AWS لامبدا ماشه. هنگامی که فایل ویژگی ML در سطل S3 انداخته میشود، تابع Lambda بهطور خودکار اجرا میشود، که کار تبدیل دستهای SageMaker را با استفاده از آخرین مدل LTV تأیید شده موجود در SageMaker Model Registry شروع میکند. هنگامی که تبدیل دسته ای کامل شد، خروجی یا مقادیر LTV پیش بینی شده برای هر بازیکن در سطل S3 ذخیره می شود تا هر کار پایین دستی بتواند نتیجه را بگیرد. این معماری در نمودار زیر توضیح داده شده است.

با این خط لوله که وظیفه ETL و استنتاج دسته ای را ترکیب می کند، پیش بینی LTV به سادگی با اجرای منظم گردش کار AWS Glue ETL انجام می شود، مانند یک بار در هفته یا یک بار در ماه. AWS Glue و SageMaker منابع زیربنایی خود را مدیریت می کنند، به این معنی که این خط لوله نیازی ندارد که شما هیچ منبعی را همیشه در حال اجرا نگه دارید. بنابراین، این معماری با استفاده از خدمات مدیریت شده برای کارهای دسته ای مقرون به صرفه است.
راه حل قابل استقرار با استفاده از AWS CDK
خط لوله ML خود با استفاده از Pipelines تعریف و اجرا می شود، اما خط لوله داده و کد استنتاج مدل ML از جمله تابع Lambda خارج از محدوده Pipelines هستند. برای اینکه این راه حل قابل استقرار باشد تا بتوانیم آن را در بازی های دیگر اعمال کنیم، خط لوله داده و استنتاج مدل ML را با استفاده از AWS CDK تعریف کردیم. به این ترتیب، تیم مهندسی و تیم علم داده انعطاف پذیری برای مدیریت، به روز رسانی و کنترل کل راه حل ML را بدون نیاز به مدیریت زیرساخت به صورت دستی با استفاده از کنسول مدیریت AWS.
نتیجه
در این پست، ما بحث کردیم که چگونه میتوانیم جابجایی دادهها و چالشهای پیچیده ETL را با ایجاد یک خط لوله داده خودکار و خط لوله ML با استفاده از خدمات مدیریتشده مانند AWS Glue و SageMaker حل کنیم، و چگونه میتوان آن را به یک راهحل ML مقیاسپذیر و تکرارپذیر تبدیل کرد. بازی های دیگر با استفاده از AWS CDK.
«در این دوران، بازیها چیزی بیش از محتوا هستند. آنها مردم را دور هم جمع می کنند و وقتی صحبت از لذت بردن از زندگی ما می شود، پتانسیل و ارزش بی حد و حصری دارند. در Kakao Games، ما رویای دنیایی پر از بازیهایی را داریم که هر کسی به راحتی میتواند از آن لذت ببرد. ما در تلاش هستیم تا تجربیاتی ایجاد کنیم که بازیکنان بخواهند در بازی باقی بمانند و از طریق جامعه پیوند ایجاد کنند. تیم MLSL به ما کمک کرد تا با استفاده از AutoGluon برای AutoML، Amazon SageMaker برای MLOps و AWS Glue برای خط لوله داده، یک راهحل ML پیشبینی LTV مقیاسپذیر بسازیم. این راه حل آموزش مجدد مدل را برای تغییرات داده یا بازی به طور خودکار انجام می دهد و به راحتی می تواند از طریق AWS CDK در بازی های دیگر مستقر شود. این راه حل به ما کمک می کند تا فرآیندهای تجاری خود را بهینه کنیم، که به نوبه خود به ما کمک می کند تا در بازی جلوتر بمانیم."
- سو هیونگ کیم، رئیس آزمایشگاه تجزیه و تحلیل داده، کاکائو گیمز.
برای کسب اطلاعات بیشتر در مورد ویژگی های مرتبط SageMaker و AWS CDK، موارد زیر را بررسی کنید:
آزمایشگاه راه حل های آمازون ام ال
La آزمایشگاه راه حل های آمازون ام ال تیم خود را با کارشناسان ML جفت می کند تا به شما کمک کند فرصت های با ارزش ML سازمان خود را شناسایی و اجرا کنید. اگر می خواهید استفاده از ML را در محصولات و فرآیندهای خود تسریع کنید، لطفاً با آزمایشگاه راه حل های آمازون ML تماس بگیرید.
درباره نویسنده
 سوهیونگ کیم مدیر کل آزمایشگاه تجزیه و تحلیل داده KakaoGames است. او مسئول جمع آوری و تجزیه و تحلیل داده ها، و به ویژه نگرانی برای اقتصاد بازی های آنلاین است.
سوهیونگ کیم مدیر کل آزمایشگاه تجزیه و تحلیل داده KakaoGames است. او مسئول جمع آوری و تجزیه و تحلیل داده ها، و به ویژه نگرانی برای اقتصاد بازی های آنلاین است.
 موهیون کیم دانشمند داده در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او مشکلات مختلف تجاری مشتریان را با استفاده از یادگیری ماشینی و یادگیری عمیق حل می کند و همچنین به آنها کمک می کند تا مهارت پیدا کنند.
موهیون کیم دانشمند داده در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او مشکلات مختلف تجاری مشتریان را با استفاده از یادگیری ماشینی و یادگیری عمیق حل می کند و همچنین به آنها کمک می کند تا مهارت پیدا کنند.
 شلدون لیو دانشمند داده در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او بهعنوان یک متخصص باتجربه یادگیری ماشینی که در معماری راهحلهای مقیاسپذیر و قابل اعتماد مهارت دارد، با مشتریان سازمانی برای رسیدگی به مشکلات تجاری آنها و ارائه راهحلهای موثر ML کار میکند.
شلدون لیو دانشمند داده در آزمایشگاه راه حل های یادگیری ماشین آمازون است. او بهعنوان یک متخصص باتجربه یادگیری ماشینی که در معماری راهحلهای مقیاسپذیر و قابل اعتماد مهارت دارد، با مشتریان سازمانی برای رسیدگی به مشکلات تجاری آنها و ارائه راهحلهای موثر ML کار میکند.
 الکس چیرایت یک مهندس ارشد یادگیری ماشین در آزمایشگاه راه حل های آمازون ML است. او تیم هایی از دانشمندان و مهندسان داده را برای ایجاد برنامه های کاربردی هوش مصنوعی برای رفع نیازهای کسب و کار رهبری می کند.
الکس چیرایت یک مهندس ارشد یادگیری ماشین در آزمایشگاه راه حل های آمازون ML است. او تیم هایی از دانشمندان و مهندسان داده را برای ایجاد برنامه های کاربردی هوش مصنوعی برای رفع نیازهای کسب و کار رهبری می کند.
 گونسو مون، معمار راه حل های تخصصی AI/ML در AWS، با مشتریان برای حل مشکلات ML خود با استفاده از خدمات AWS AI/ML همکاری کرده است. او در گذشته تجربه توسعه خدمات یادگیری ماشینی در صنعت تولید و همچنین در مقیاس بزرگ توسعه خدمات، تجزیه و تحلیل داده ها و توسعه سیستم در صنعت پورتال و بازی را داشت. گونسو در اوقات فراغتش قدم می زند و با بچه ها بازی می کند.
گونسو مون، معمار راه حل های تخصصی AI/ML در AWS، با مشتریان برای حل مشکلات ML خود با استفاده از خدمات AWS AI/ML همکاری کرده است. او در گذشته تجربه توسعه خدمات یادگیری ماشینی در صنعت تولید و همچنین در مقیاس بزرگ توسعه خدمات، تجزیه و تحلیل داده ها و توسعه سیستم در صنعت پورتال و بازی را داشت. گونسو در اوقات فراغتش قدم می زند و با بچه ها بازی می کند.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- پلاتوبلاک چین. Web3 Metaverse Intelligence. دانش تقویت شده دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/how-kakao-games-automates-lifetime-value-prediction-from-game-data-using-amazon-sagemaker-and-aws-glue/

