آمازون SageMaker چندین راه برای اجرای کارهای پردازش داده های توزیع شده با Apache Spark، یک چارچوب محاسباتی توزیع شده محبوب برای پردازش داده های بزرگ ارائه می دهد.
میتوانید برنامههای Spark را به صورت تعاملی اجرا کنید Amazon SageMaker Studio با اتصال نوت بوک های SageMaker Studio و AWS Glue Interactive Sessions برای اجرای کارهای Spark با یک خوشه بدون سرور. با جلسات تعاملی، می توانید Apache Spark یا Ray را انتخاب کنید تا به راحتی مجموعه داده های بزرگ را پردازش کنید، بدون اینکه نگران مدیریت خوشه باشید.
متناوباً، اگر به کنترل بیشتری بر روی محیط نیاز دارید، میتوانید از یک کانتینر SageMaker Spark از پیش ساخته شده برای اجرای برنامههای Spark به عنوان کارهای دستهای در یک خوشه توزیعشده کاملاً مدیریت شده استفاده کنید. پردازش آمازون SageMaker. این گزینه به شما امکان می دهد چندین نوع نمونه (محاسبه بهینه، حافظه بهینه شده و موارد دیگر)، تعداد گره ها در خوشه و پیکربندی خوشه را انتخاب کنید، در نتیجه انعطاف پذیری بیشتری را برای پردازش داده ها و آموزش مدل فراهم می کند.
در نهایت، میتوانید با اتصال نوتبوکهای استودیو، برنامههای Spark را اجرا کنید آمازون EMR خوشه، یا با اجرای کلاستر Spark خود در ابر محاسبه الاستیک آمازون (آمازون EC2).
همه این گزینهها به شما امکان میدهند گزارشهای رویداد Spark را تولید و ذخیره کنید تا آنها را از طریق رابط کاربری مبتنی بر وب که معمولاً به نام Spark UI، که یک سرور Spark History را برای نظارت بر پیشرفت برنامه های Spark، پیگیری استفاده از منابع و خطاهای اشکال زدایی اجرا می کند.
در این پست یک را به اشتراک می گذاریم راه حل برای نصب و اجرای Spark History Server در SageMaker Studio و دسترسی مستقیم به Spark UI از SageMaker Studio IDE، برای تجزیه و تحلیل Spark log های تولید شده توسط سرویس های مختلف AWS (AWS Glue Interactive Sessions، SageMaker Processing jobs و Amazon EMR) و ذخیره شده در سرویس ذخیره سازی ساده آمازون سطل (Amazon S3).
بررسی اجمالی راه حل
راه حل Spark History Server را در برنامه Jupyter Server در SageMaker Studio ادغام می کند. این به کاربران اجازه می دهد تا مستقیماً از SageMaker Studio IDE به گزارش های Spark دسترسی داشته باشند. سرور Spark History یکپارچه موارد زیر را پشتیبانی می کند:
- دسترسی به سیاهههای مربوط به کارهای SageMaker Processing Spark
- دسترسی به گزارش های تولید شده توسط برنامه های کاربردی AWS Glue Spark
- دسترسی به گزارشهای تولید شده توسط خوشههای Spark خود مدیریت و آمازون EMR
یک رابط خط فرمان ابزار (CLI) فراخوانی شده است sm-spark-cli همچنین برای تعامل با Spark UI از ترمینال سیستم SageMaker Studio ارائه شده است. را sm-spark-cli مدیریت Spark History Server را بدون خروج از SageMaker Studio فعال می کند.

راه حل شامل اسکریپت های پوسته است که اقدامات زیر را انجام می دهد:
- Spark را روی سرور Jupyter برای پروفایل های کاربر SageMaker Studio یا برای فضای مشترک SageMaker Studio نصب کنید.
- نصب
sm-spark-cliبرای نمایه کاربری یا فضای مشترک
Spark UI را به صورت دستی در دامنه SageMaker Studio نصب کنید
برای میزبانی Spark UI در SageMaker Studio، مراحل زیر را انجام دهید:
- را انتخاب کنید ترمینال سیستم از لانچر SageMaker Studio.
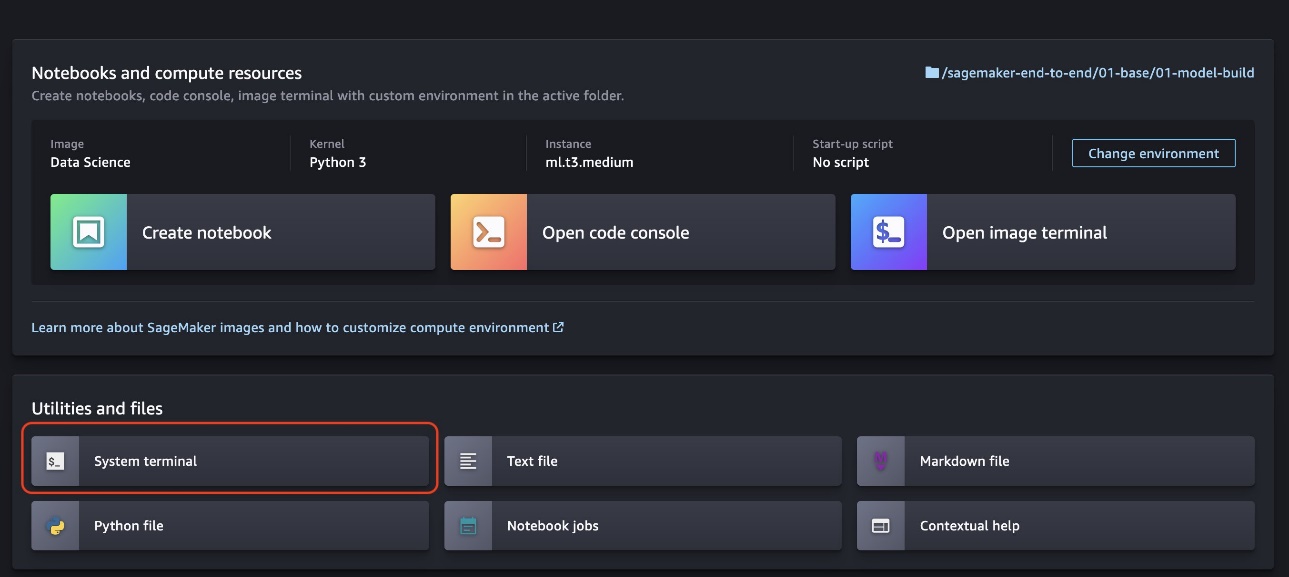
- دستورات زیر را در ترمینال سیستم اجرا کنید:
دستورات چند ثانیه طول می کشد تا کامل شوند.
- هنگامی که نصب کامل شد، می توانید با استفاده از ارائه شده، Spark UI را راه اندازی کنید
sm-spark-cliو با اجرای کد زیر از مرورگر وب به آن دسترسی پیدا کنید:
sm-spark-cli start s3://DOC-EXAMPLE-BUCKET/<SPARK_EVENT_LOGS_LOCATION>
مکان S3 که در آن گزارشهای رویداد تولید شده توسط SageMaker Processing، AWS Glue یا Amazon EMR ذخیره میشوند، هنگام اجرای برنامههای Spark قابل پیکربندی هستند.
برای نوت بوک های SageMaker Studio و AWS Glue Interactive Sessions، می توانید مکان گزارش رویداد Spark را مستقیماً از نوت بوک با استفاده از sparkmagic هسته
La sparkmagic هسته شامل مجموعه ای از ابزارها برای تعامل با خوشه های Spark راه دور از طریق نوت بوک است. جادو ارائه می کند (%spark, %sql) دستوراتی برای اجرای کد Spark، انجام پرس و جوهای SQL و پیکربندی تنظیمات Spark مانند حافظه اجرایی و هستهها.

برای کار پردازش SageMaker، میتوانید مکان گزارش رویداد Spark را مستقیماً از SageMaker Python SDK پیکربندی کنید.

برای اطلاعات بیشتر به مستندات AWS مراجعه کنید:

می توانید URL تولید شده را برای دسترسی به رابط کاربری Spark انتخاب کنید.
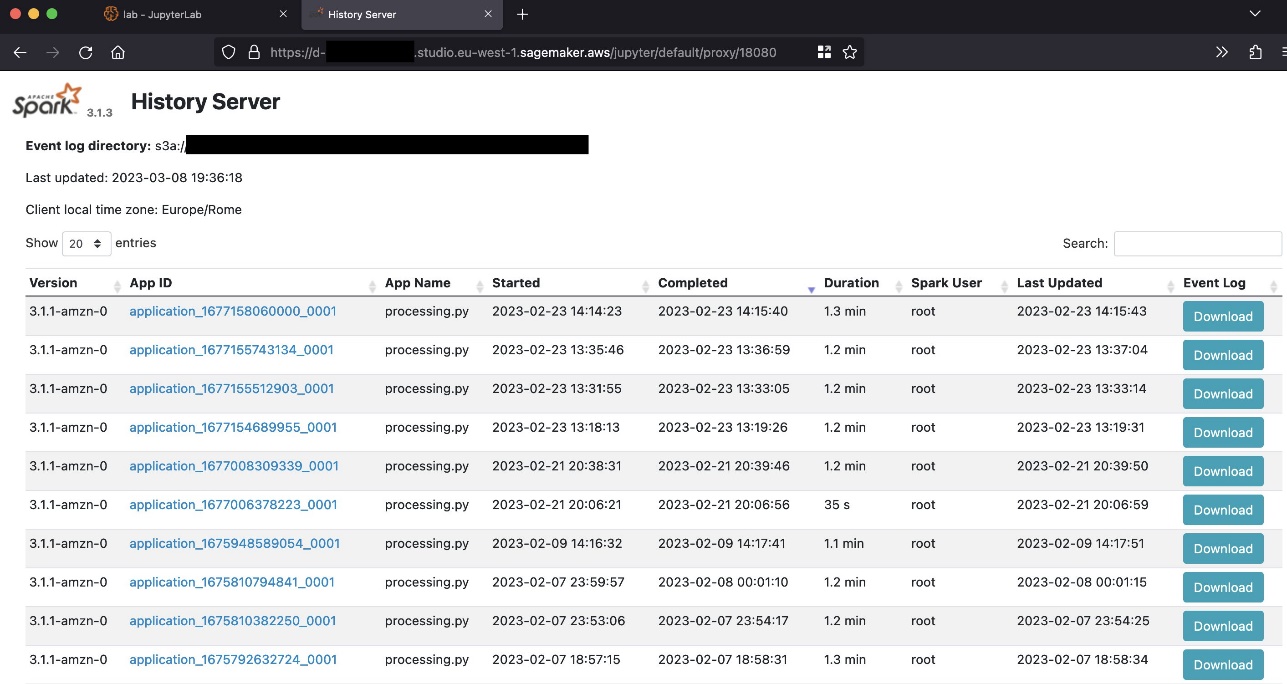
تصویر زیر نمونه ای از Spark UI را نشان می دهد.
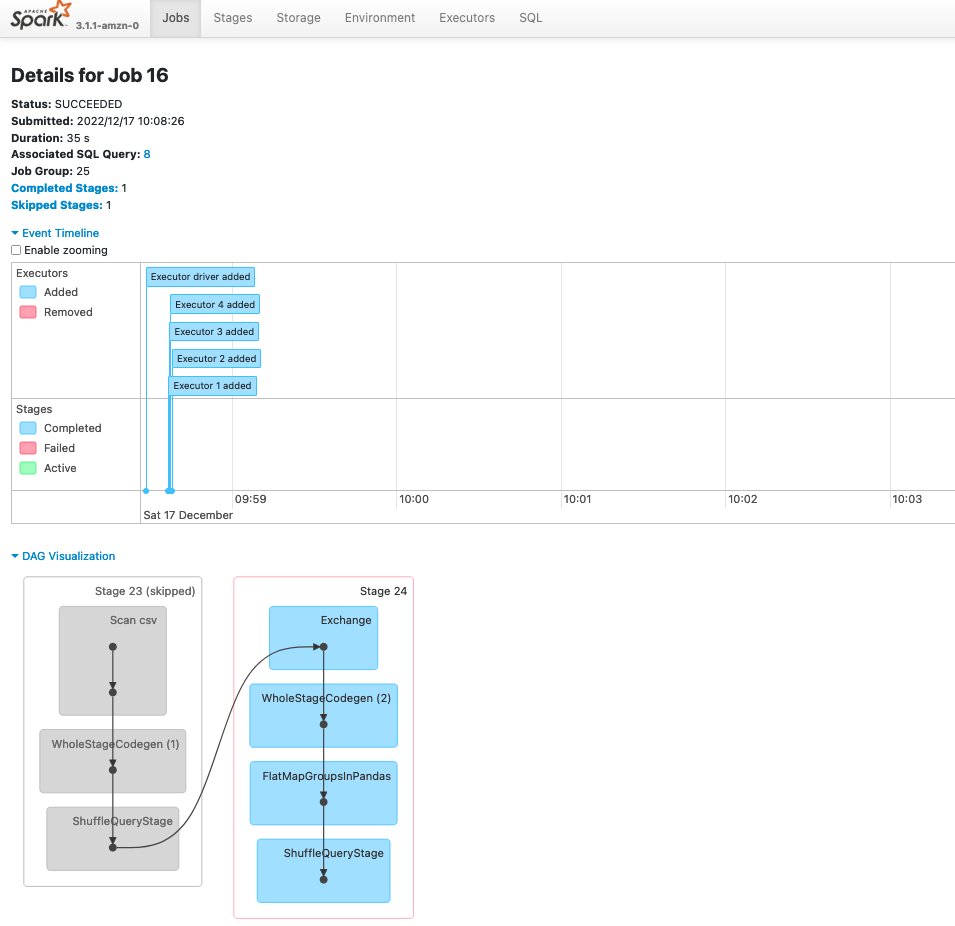
می توانید وضعیت سرور Spark History را با استفاده از sm-spark-cli status دستور در ترمینال Studio System.

همچنین می توانید سرور Spark History را در صورت نیاز متوقف کنید.

نصب Spark UI را برای کاربران در دامنه SageMaker Studio به صورت خودکار انجام دهید
به عنوان یک سرپرست فناوری اطلاعات، میتوانید نصب را برای کاربران SageMaker Studio با استفاده از یک خودکار انجام دهید پیکربندی چرخه حیات. این را می توان برای تمام پروفایل های کاربر تحت دامنه SageMaker Studio یا برای پروفایل های خاص انجام داد. دیدن Amazon SageMaker Studio را با استفاده از تنظیمات چرخه زندگی سفارشی کنید برای جزئیات بیشتر.
شما می توانید یک پیکربندی چرخه حیات از آن ایجاد کنید install-history-server.sh اسکریپت و آن را به دامنه SageMaker Studio موجود وصل کنید. نصب برای تمام پروفایل های کاربر در دامنه اجرا می شود.
از ترمینال پیکربندی شده با رابط خط فرمان AWS (AWS CLI) و مجوزهای مناسب، دستورات زیر را اجرا کنید:
پس از راه اندازی مجدد سرور Jupyter، Spark UI و sm-spark-cli در محیط SageMaker Studio شما در دسترس خواهد بود.
پاک کردن
در این بخش، نحوه پاکسازی Spark UI در دامنه SageMaker Studio را به صورت دستی یا خودکار به شما نشان می دهیم.
Spark UI را به صورت دستی حذف نصب کنید
برای حذف دستی Spark UI در SageMaker Studio، مراحل زیر را انجام دهید:
- را انتخاب کنید ترمینال سیستم در لانچر SageMaker Studio.

- دستورات زیر را در ترمینال سیستم اجرا کنید:
Spark UI را به طور خودکار برای تمام پروفایل های کاربر SageMaker Studio حذف نصب کنید
برای حذف خودکار Spark UI در SageMaker Studio برای همه پروفایل های کاربر، مراحل زیر را انجام دهید:
- در کنسول SageMaker، را انتخاب کنید دامنه در صفحه پیمایش، سپس دامنه SageMaker Studio را انتخاب کنید.

- در صفحه جزئیات دامنه، به مسیر بروید محیط تب.
- پیکربندی چرخه حیات را برای Spark UI در SageMaker Studio انتخاب کنید.
- را انتخاب کنید جدا شدن.

- برنامه های سرور Jupyter را برای پروفایل های کاربر SageMaker Studio حذف و راه اندازی مجدد کنید.

نتیجه
در این پست راه حلی را به اشتراک گذاشتیم که می توانید از آن برای نصب سریع Spark UI در SageMaker Studio استفاده کنید. با استفاده از Spark UI که در SageMaker میزبانی میشود، تیمهای یادگیری ماشین (ML) و مهندسی داده میتوانند از محاسبات ابری مقیاسپذیر برای دسترسی و تجزیه و تحلیل گزارشهای Spark از هر نقطه استفاده کنند و تحویل پروژه خود را سرعت بخشند. مدیران فناوری اطلاعات می توانند ارائه راه حل را در فضای ابری استاندارد و تسریع کنند و از گسترش محیط های توسعه سفارشی برای پروژه های ML اجتناب کنند.
تمام کدهایی که به عنوان بخشی از این پست نشان داده شده است در موجود است مخزن GitHub.
درباره نویسنده
 جوزپه آنجلو پورچلی یک معمار اصلی راه حل های متخصص یادگیری ماشین برای خدمات وب آمازون است. او با چندین سال مهندسی نرم افزار و پیشینه ML، با مشتریان در هر اندازه ای کار می کند تا نیازهای تجاری و فنی آنها را درک کند و راه حل های هوش مصنوعی و ML را طراحی کند که بهترین استفاده را از AWS Cloud و پشته یادگیری ماشین آمازون می کند. او روی پروژههایی در حوزههای مختلف، از جمله MLOps، بینایی کامپیوتر، و NLP، که شامل مجموعه گستردهای از خدمات AWS است، کار کرده است. جوزپه در اوقات فراغت خود از بازی فوتبال لذت می برد.
جوزپه آنجلو پورچلی یک معمار اصلی راه حل های متخصص یادگیری ماشین برای خدمات وب آمازون است. او با چندین سال مهندسی نرم افزار و پیشینه ML، با مشتریان در هر اندازه ای کار می کند تا نیازهای تجاری و فنی آنها را درک کند و راه حل های هوش مصنوعی و ML را طراحی کند که بهترین استفاده را از AWS Cloud و پشته یادگیری ماشین آمازون می کند. او روی پروژههایی در حوزههای مختلف، از جمله MLOps، بینایی کامپیوتر، و NLP، که شامل مجموعه گستردهای از خدمات AWS است، کار کرده است. جوزپه در اوقات فراغت خود از بازی فوتبال لذت می برد.
 برونو پیستون یک معمار راه حل های تخصصی AI/ML برای AWS مستقر در میلان است. او با مشتریان در هر اندازه ای کار می کند و به آنها کمک می کند تا نیازهای فنی آنها را درک کنند و راه حل های هوش مصنوعی و ML را طراحی کنند که بهترین استفاده را از AWS Cloud و پشته یادگیری ماشین آمازون می کند. زمینه تخصص او شامل یادگیری ماشینی از پایان به انتها، یادگیری ماشینی پیشرفته، و هوش مصنوعی مولد است. او از گذراندن وقت با دوستانش و کشف مکان های جدید و همچنین سفر به مقاصد جدید لذت می برد.
برونو پیستون یک معمار راه حل های تخصصی AI/ML برای AWS مستقر در میلان است. او با مشتریان در هر اندازه ای کار می کند و به آنها کمک می کند تا نیازهای فنی آنها را درک کنند و راه حل های هوش مصنوعی و ML را طراحی کنند که بهترین استفاده را از AWS Cloud و پشته یادگیری ماشین آمازون می کند. زمینه تخصص او شامل یادگیری ماشینی از پایان به انتها، یادگیری ماشینی پیشرفته، و هوش مصنوعی مولد است. او از گذراندن وقت با دوستانش و کشف مکان های جدید و همچنین سفر به مقاصد جدید لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. خودرو / خودروهای الکتریکی، کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- BlockOffsets. نوسازی مالکیت افست زیست محیطی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/host-the-spark-ui-on-amazon-sagemaker-studio/

