در این پست، ما نشان میدهیم که چگونه میتوان یک مدل زبان پروتئینی پیشرفته (pLM) را برای پیشبینی محلیسازی درون سلولی پروتئین بهطور مؤثر تنظیم کرد. آمازون SageMaker.
پروتئین ها ماشین های مولکولی بدن هستند که مسئول همه چیز از حرکت عضلات گرفته تا پاسخ به عفونت ها هستند. با وجود این تنوع، همه پروتئین ها از زنجیره های تکرار شونده مولکول هایی به نام اسیدهای آمینه ساخته شده اند. ژنوم انسان 20 اسید آمینه استاندارد را رمزگذاری می کند که هر کدام ساختار شیمیایی کمی متفاوت دارند. این ها را می توان با حروف الفبا نشان داد، که سپس به ما امکان می دهد پروتئین ها را به عنوان یک رشته متن تجزیه و تحلیل و کشف کنیم. تعداد زیادی از توالی ها و ساختارهای پروتئینی همان چیزی است که به پروتئین ها کاربردهای گسترده ای می دهد.
پروتئین ها همچنین نقش کلیدی در توسعه دارو، به عنوان اهداف بالقوه و همچنین به عنوان درمان دارند. همانطور که در جدول زیر نشان داده شده است، بسیاری از داروهای پرفروش در سال 2022 یا پروتئین ها (به ویژه آنتی بادی ها) یا مولکول های دیگر مانند mRNA بودند که به پروتئین در بدن تبدیل شده بودند. به همین دلیل، بسیاری از محققان علوم زیستی باید به سؤالات مربوط به پروتئین ها سریع تر، ارزان تر و دقیق تر پاسخ دهند.
| نام | سازنده | فروش جهانی 2022 (میلیارد دلار آمریکا) | موارد مصرف |
| مجلسی | Pfizer / BioNTech | $40.8 | Covid-19 |
| اسپیکواکس | مدرن | $21.8 | Covid-19 |
| هومیرا | AbbVie | $21.6 | آرتریت، بیماری کرون و غیره |
| Keytruda | مرک | $21.0 | سرطانهای مختلف |
منبع داده: Urquhart, L. برترین شرکت ها و داروها بر اساس فروش در سال 2022. Nature Reviews Drug Discovery 22، 260-260 (2023).
از آنجایی که میتوانیم پروتئینها را بهعنوان دنبالهای از کاراکترها نشان دهیم، میتوانیم آنها را با استفاده از تکنیکهایی که در ابتدا برای زبان نوشتاری توسعه داده شدهاند، تجزیه و تحلیل کنیم. این شامل مدلهای زبان بزرگ (LLM) میشود که روی مجموعه دادههای عظیم از قبل آموزش داده شدهاند، که سپس میتوانند برای کارهای خاص، مانند خلاصهسازی متن یا رباتهای گفتگو، تطبیق داده شوند. به طور مشابه، plm ها در پایگاه داده های توالی پروتئین بزرگ با استفاده از یادگیری بدون برچسب و خود نظارت از قبل آموزش داده شده اند. ما میتوانیم آنها را برای پیشبینی چیزهایی مانند ساختار سهبعدی یک پروتئین یا نحوه تعامل آن با مولکولهای دیگر تطبیق دهیم. محققان حتی از plm ها برای طراحی پروتئین های جدید از ابتدا استفاده کرده اند. این ابزارها جایگزین تخصص علمی انسان نمی شوند، اما پتانسیل آن را دارند که توسعه پیش بالینی و طراحی آزمایشی را سرعت بخشند.
یکی از چالش های این مدل ها اندازه آنهاست. همانطور که در شکل زیر نشان داده شده است، هر دو LLM و plM در چند سال گذشته به ترتیب بزرگی رشد کرده اند. این بدان معناست که آموزش آنها با دقت کافی می تواند زمان زیادی طول بکشد. همچنین به این معنی است که برای ذخیره پارامترهای مدل باید از سخت افزار، به ویژه پردازنده های گرافیکی، با مقدار زیادی حافظه استفاده کنید.

زمان های طولانی آموزش، به علاوه نمونه های بزرگ، برابر است با هزینه های بالا، که می تواند این کار را برای بسیاری از محققان دور از دسترس قرار دهد. به عنوان مثال، در سال 2023، الف گروه تحقیق آموزش یک plm 100 میلیارد پارامتری را بر روی 768 پردازنده گرافیکی A100 به مدت 164 روز توضیح داد! خوشبختانه، در بسیاری از موارد، میتوانیم با تطبیق یک plm موجود برای کار خاص خود، در زمان و منابع صرفهجویی کنیم. این تکنیک نامیده می شود تنظیم دقیقو همچنین به ما اجازه می دهد تا ابزارهای پیشرفته را از انواع دیگر مدل سازی زبان قرض بگیریم.
بررسی اجمالی راه حل
مشکل خاصی که در این پست به آن می پردازیم این است محلی سازی درون سلولی: با توجه به یک توالی پروتئین، آیا میتوانیم مدلی بسازیم که بتواند پیشبینی کند که در بیرون (غشاء سلولی) یا داخل سلول زندگی میکند؟ این بخش مهمی از اطلاعات است که می تواند به ما در درک عملکرد و اینکه آیا می تواند یک هدف دارویی خوب باشد یا خیر کمک کند.
ما با دانلود یک مجموعه داده عمومی با استفاده از Amazon SageMaker Studio. سپس از SageMaker برای تنظیم دقیق مدل زبان پروتئین ESM-2 با استفاده از یک روش آموزشی کارآمد استفاده می کنیم. در نهایت، ما مدل را به عنوان یک نقطه پایانی استنتاج بلادرنگ مستقر می کنیم و از آن برای آزمایش برخی از پروتئین های شناخته شده استفاده می کنیم. نمودار زیر این گردش کار را نشان می دهد.
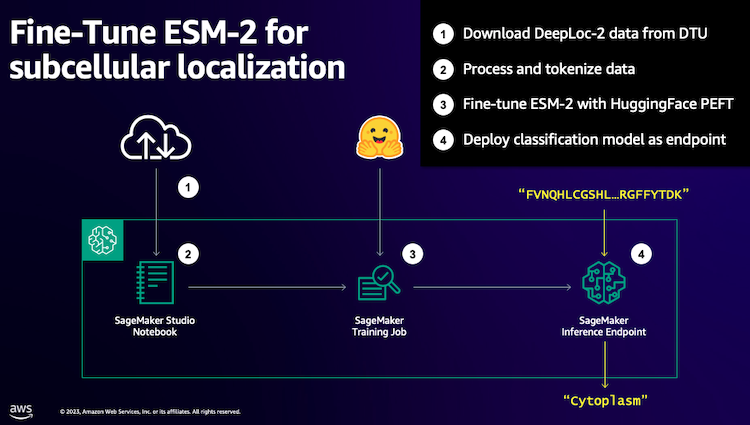
در قسمت های بعدی مراحل آماده سازی داده های آموزشی شما، ایجاد یک اسکریپت آموزشی و اجرای کار آموزشی SageMaker را طی می کنیم. همه کدهای ارائه شده در این پست در دسترس هستند GitHub.
داده های آموزشی را آماده کنید
ما از بخشی از مجموعه داده DeepLoc-2، که حاوی چندین هزار پروتئین SwissProt با مکان های آزمایشی تعیین شده است. ما برای دنباله های با کیفیت بالا بین 100-512 اسید آمینه فیلتر می کنیم:
df = pd.read_csv(
"https://services.healthtech.dtu.dk/services/DeepLoc-2.0/data/Swissprot_Train_Validation_dataset.csv"
).drop(["Unnamed: 0", "Partition"], axis=1)
df["Membrane"] = df["Membrane"].astype("int32")
# filter for sequences between 100 and 512 amino acides
df = df[df["Sequence"].apply(lambda x: len(x)).between(100, 512)]
# Remove unnecessary features
df = df[["Sequence", "Kingdom", "Membrane"]]
سپس، توالی ها را توکن می کنیم و آنها را به مجموعه های آموزشی و ارزیابی تقسیم می کنیم:
dataset = Dataset.from_pandas(df).train_test_split(test_size=0.2, shuffle=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/esm2_t33_650M_UR50D")
def preprocess_data(examples, max_length=512):
text = examples["Sequence"]
encoding = tokenizer(text, truncation=True, max_length=max_length)
encoding["labels"] = examples["Membrane"]
return encoding
encoded_dataset = dataset.map(
preprocess_data,
batched=True,
num_proc=os.cpu_count(),
remove_columns=dataset["train"].column_names,
)
encoded_dataset.set_format("torch")
در نهایت، داده های آموزش و ارزیابی پردازش شده را در آن آپلود می کنیم سرویس ذخیره سازی ساده آمازون (Amazon S3):
train_s3_uri = S3_PATH + "/data/train"
test_s3_uri = S3_PATH + "/data/test"
encoded_dataset["train"].save_to_disk(train_s3_uri)
encoded_dataset["test"].save_to_disk(test_s3_uri)یک اسکریپت آموزشی ایجاد کنید
حالت اسکریپت SageMaker به شما امکان می دهد کد آموزشی سفارشی خود را در کانتینرهای چارچوب یادگیری ماشینی بهینه شده (ML) که توسط AWS مدیریت می شود اجرا کنید. برای این مثال، ما یک را تطبیق می دهیم اسکریپت موجود برای طبقه بندی متن از در آغوش گرفتن صورت. این به ما امکان می دهد چندین روش را برای بهبود کارایی شغل آموزشی خود امتحان کنیم.
روش 1: کلاس تمرین وزنه
مانند بسیاری از مجموعه دادههای بیولوژیکی، دادههای DeepLoc بهطور نابرابر توزیع میشوند، به این معنی که تعداد پروتئینهای غشایی و غیر غشایی برابر نیست. میتوانیم دادههایمان را دوباره نمونهبرداری کنیم و رکوردهای کلاس اکثریت را کنار بگذاریم. با این حال، این کل داده های آموزشی را کاهش می دهد و به طور بالقوه به دقت ما آسیب می رساند. در عوض، وزنهای کلاس را در طول کار تمرینی محاسبه میکنیم و از آنها برای تنظیم ضرر استفاده میکنیم.
در اسکریپت آموزشی خود، ما به زیر کلاس می دهیم Trainer کلاس از transformers با یک WeightedTrainer کلاسی که وزن کلاس ها را هنگام محاسبه تلفات آنتروپی متقابل در نظر می گیرد. این به جلوگیری از تعصب در مدل ما کمک می کند:
class WeightedTrainer(Trainer):
def __init__(self, class_weights, *args, **kwargs):
self.class_weights = class_weights
super().__init__(*args, **kwargs)
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
outputs = model(**inputs)
logits = outputs.get("logits")
loss_fct = torch.nn.CrossEntropyLoss(
weight=torch.tensor(self.class_weights, device=model.device)
)
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else lossروش 2: تجمع گرادیان
انباشت گرادیان یک تکنیک آموزشی است که به مدلها اجازه میدهد آموزش را در اندازههای دستهای بزرگتر شبیهسازی کنند. به طور معمول، اندازه دسته (تعداد نمونه های مورد استفاده برای محاسبه گرادیان در یک مرحله آموزشی) توسط ظرفیت حافظه GPU محدود می شود. با انباشت گرادیان، مدل ابتدا گرادیان ها را در دسته های کوچکتر محاسبه می کند. سپس، به جای بهروزرسانی وزنهای مدل فوراً، گرادیانها در چندین دسته کوچک جمع میشوند. هنگامی که گرادیان های انباشته شده با اندازه دسته بزرگتر هدف برابری می کند، مرحله بهینه سازی برای به روز رسانی مدل انجام می شود. این به مدلها اجازه میدهد با دستههای بزرگتر بدون تجاوز از محدودیت حافظه GPU تمرین کنند.
با این حال، محاسبات اضافی برای عبور دسته ای کوچکتر به جلو و عقب مورد نیاز است. افزایش اندازه دسته از طریق انباشت گرادیان می تواند تمرین را کند کند، به خصوص اگر از مراحل انباشت بیش از حد استفاده شود. هدف این است که استفاده از پردازنده گرافیکی را به حداکثر برسانیم اما از کاهش سرعت بیش از حد ناشی از بسیاری از مراحل محاسبه گرادیان اضافی جلوگیری کنیم.
روش 3: ایست بازرسی گرادیان
چک پوینت گرادیان تکنیکی است که حافظه مورد نیاز در طول تمرین را کاهش می دهد و در عین حال زمان محاسباتی را معقول نگه می دارد. شبکههای عصبی بزرگ حافظه زیادی را اشغال میکنند، زیرا باید تمام مقادیر میانی را از گذر به جلو ذخیره کنند تا شیبها را در طول گذر به عقب محاسبه کنند. این می تواند باعث مشکلات حافظه شود. یک راه حل این است که این مقادیر میانی را ذخیره نکنید، اما پس از آن باید آنها را در طول گذر به عقب محاسبه کرد که زمان زیادی می برد.
ایست بازرسی گرادیان یک رویکرد متعادل را ارائه می دهد. فقط برخی از مقادیر میانی را که نامیده می شوند ذخیره می کند پست های بازرسی، و بقیه را در صورت نیاز دوباره محاسبه می کند. بنابراین، از حافظه کمتری نسبت به ذخیره کردن همه چیز استفاده می کند، اما از محاسبات کمتری نسبت به محاسبه مجدد همه چیز استفاده می کند. با انتخاب استراتژیک فعالسازیهایی که برای بازرسی انتخاب شوند، نقطهی کنترل گرادیان شبکههای عصبی بزرگ را قادر میسازد تا با استفاده از حافظه قابل مدیریت و زمان محاسبه آموزش ببینند. این تکنیک مهم آموزش مدل های بسیار بزرگ را که در غیر این صورت با محدودیت های حافظه مواجه می شوند، امکان پذیر می کند.
در اسکریپت آموزشی ما، فعال سازی گرادیان و چک پوینت را با افزودن پارامترهای لازم به TrainingArguments هدف - شی:
from transformers import TrainingArguments
training_args = TrainingArguments(
gradient_accumulation_steps=4,
gradient_checkpointing=True
)روش 4: انطباق با رتبه پایین LLMs
مدلهای زبان بزرگ مانند ESM-2 میتوانند حاوی میلیاردها پارامتر باشند که آموزش و اجرای آنها پرهزینه است. محققان یک روش آموزشی به نام انطباق با رتبه پایین (LoRA) توسعه داد تا تنظیم دقیق این مدلهای عظیم را کارآمدتر کند.
ایده کلیدی پشت LoRA این است که هنگام تنظیم دقیق یک مدل برای یک کار خاص، نیازی به به روز رسانی تمام پارامترهای اصلی ندارید. در عوض، LoRA ماتریس های کوچکتر جدیدی را به مدل اضافه می کند که ورودی ها و خروجی ها را تغییر می دهد. فقط این ماتریس های کوچکتر در هنگام تنظیم دقیق به روز می شوند که بسیار سریعتر است و از حافظه کمتری استفاده می کند. پارامترهای مدل اصلی ثابت می مانند.
پس از تنظیم دقیق با LoRA، می توانید ماتریس های کوچک تطبیق داده شده را در مدل اصلی ادغام کنید. یا اگر میخواهید به سرعت مدل را برای کارهای دیگر بدون فراموش کردن کارهای قبلی تنظیم کنید، میتوانید آنها را جدا نگه دارید. به طور کلی، LoRA به LLM ها اجازه می دهد تا با کسری از هزینه معمول به طور موثر با وظایف جدید سازگار شوند.
در اسکریپت آموزشی خود، LoRA را با استفاده از پیکربندی می کنیم PEFT کتابخانه از چهره در آغوش گرفته:
from peft import get_peft_model, LoraConfig, TaskType
import torch
from transformers import EsmForSequenceClassification
model = EsmForSequenceClassification.from_pretrained(
“facebook/esm2_t33_650M_UR50D”,
Torch_dtype=torch.bfloat16,
Num_labels=2,
)
peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS,
inference_mode=False,
bias="none",
r=8,
lora_alpha=16,
lora_dropout=0.05,
target_modules=[
"query",
"key",
"value",
"EsmSelfOutput.dense",
"EsmIntermediate.dense",
"EsmOutput.dense",
"EsmContactPredictionHead.regression",
"EsmClassificationHead.dense",
"EsmClassificationHead.out_proj",
]
)
model = get_peft_model(model, peft_config)یک شغل آموزشی SageMaker ارسال کنید
بعد از اینکه اسکریپت آموزشی خود را تعریف کردید، می توانید یک کار آموزشی SageMaker را پیکربندی و ارسال کنید. ابتدا هایپرپارامترها را مشخص کنید:
hyperparameters = {
"model_id": "facebook/esm2_t33_650M_UR50D",
"epochs": 1,
"per_device_train_batch_size": 8,
"gradient_accumulation_steps": 4,
"use_gradient_checkpointing": True,
"lora": True,
}در مرحله بعد، معیارهایی را که باید از لاگ های آموزشی گرفته شود، تعریف کنید:
metric_definitions = [
{"Name": "epoch", "Regex": "'epoch': ([0-9.]*)"},
{
"Name": "max_gpu_mem",
"Regex": "Max GPU memory use during training: ([0-9.e-]*) MB",
},
{"Name": "train_loss", "Regex": "'loss': ([0-9.e-]*)"},
{
"Name": "train_samples_per_second",
"Regex": "'train_samples_per_second': ([0-9.e-]*)",
},
{"Name": "eval_loss", "Regex": "'eval_loss': ([0-9.e-]*)"},
{"Name": "eval_accuracy", "Regex": "'eval_accuracy': ([0-9.e-]*)"},
]در نهایت، تخمینگر Hugging Face را تعریف کنید و آن را برای آموزش در نوع نمونه ml.g5.2xlarge ارسال کنید. این یک نوع نمونه مقرون به صرفه است که به طور گسترده در بسیاری از مناطق AWS در دسترس است:
from sagemaker.experiments.run import Run
from sagemaker.huggingface import HuggingFace
from sagemaker.inputs import TrainingInput
hf_estimator = HuggingFace(
base_job_name="esm-2-membrane-ft",
entry_point="lora-train.py",
source_dir="scripts",
instance_type="ml.g5.2xlarge",
instance_count=1,
transformers_version="4.28",
pytorch_version="2.0",
py_version="py310",
output_path=f"{S3_PATH}/output",
role=sagemaker_execution_role,
hyperparameters=hyperparameters,
metric_definitions=metric_definitions,
checkpoint_local_path="/opt/ml/checkpoints",
sagemaker_session=sagemaker_session,
keep_alive_period_in_seconds=3600,
tags=[{"Key": "project", "Value": "esm-fine-tuning"}],
)
with Run(
experiment_name=EXPERIMENT_NAME,
sagemaker_session=sagemaker_session,
) as run:
hf_estimator.fit(
{
"train": TrainingInput(s3_data=train_s3_uri),
"test": TrainingInput(s3_data=test_s3_uri),
}
)جدول زیر روش های آموزشی مختلفی را که مورد بحث قرار دادیم و تأثیر آنها بر زمان اجرا، دقت و نیازهای حافظه GPU کار ما مقایسه می کند.
| پیکر بندی | زمان قابل پرداخت (دقیقه) | دقت ارزیابی | حداکثر استفاده از حافظه GPU (گیگابایت) |
| مدل پایه | 28 | 0.91 | 22.6 |
| پایه + GA | 21 | 0.90 | 17.8 |
| پایه + GC | 29 | 0.91 | 10.2 |
| پایه + LoRA | 23 | 0.90 | 18.6 |
تمامی روش ها مدل هایی را با دقت ارزیابی بالا تولید کردند. استفاده از LoRA و فعالسازی گرادیان، زمان اجرا (و هزینه) را به ترتیب 18 و 25 درصد کاهش داد. استفاده از نقطه کنترل گرادیان، حداکثر استفاده از حافظه GPU را تا 55 درصد کاهش داد. بسته به محدودیت های شما (هزینه، زمان، سخت افزار)، یکی از این رویکردها ممکن است منطقی تر از دیگری باشد.
هر یک از این روش ها به تنهایی عملکرد خوبی دارند، اما چه اتفاقی می افتد که از آنها به صورت ترکیبی استفاده کنیم؟ جدول زیر نتایج را به طور خلاصه نشان می دهد.
| پیکر بندی | زمان قابل پرداخت (دقیقه) | دقت ارزیابی | حداکثر استفاده از حافظه GPU (گیگابایت) |
| همه روش ها | 12 | 0.80 | 3.3 |
در این حالت شاهد کاهش 12 درصدی دقت هستیم. با این حال، ما زمان اجرا را تا 57 درصد و استفاده از حافظه GPU را تا 85 درصد کاهش داده ایم! این کاهش گسترده ای است که به ما امکان می دهد در طیف گسترده ای از انواع نمونه های مقرون به صرفه آموزش ببینیم.
پاک کردن
اگر در حساب AWS خود دنبال میکنید، برای جلوگیری از هزینههای بیشتر، نقاط پایانی و دادههای استنتاج بلادرنگ را که ایجاد کردهاید حذف کنید.
predictor.delete_endpoint()
bucket = boto_session.resource("s3").Bucket(S3_BUCKET)
bucket.objects.filter(Prefix=S3_PREFIX).delete()نتیجه
در این پست، نحوه تنظیم دقیق مدلهای زبان پروتئینی مانند ESM-2 را برای یک کار علمی مرتبط نشان دادیم. برای اطلاعات بیشتر در مورد استفاده از کتابخانههای Transformers و PEFT برای آموزش plms، پستها را بررسی کنید یادگیری عمیق با پروتئین و ESMBind (ESMB): سازگاری با رتبه پایین ESM-2 برای پیشبینی محل اتصال پروتئین در وبلاگ صورت در آغوش گرفتن. همچنین میتوانید نمونههای بیشتری از استفاده از یادگیری ماشینی برای پیشبینی ویژگیهای پروتئین را پیدا کنید آنالیز عالی پروتئین در AWS مخزن GitHub.
درباره نویسنده
 برایان وفادار یک معمار ارشد راه حل های AI/ML در تیم بهداشت جهانی و علوم زندگی در خدمات وب آمازون است. او بیش از 17 سال تجربه در بیوتکنولوژی و یادگیری ماشین دارد و مشتاق کمک به مشتریان در حل چالش های ژنومی و پروتئومی است. او در اوقات فراغت خود از آشپزی و غذا خوردن با دوستان و خانواده اش لذت می برد.
برایان وفادار یک معمار ارشد راه حل های AI/ML در تیم بهداشت جهانی و علوم زندگی در خدمات وب آمازون است. او بیش از 17 سال تجربه در بیوتکنولوژی و یادگیری ماشین دارد و مشتاق کمک به مشتریان در حل چالش های ژنومی و پروتئومی است. او در اوقات فراغت خود از آشپزی و غذا خوردن با دوستان و خانواده اش لذت می برد.
- محتوای مبتنی بر SEO و توزیع روابط عمومی. امروز تقویت شوید.
- PlatoData.Network Vertical Generative Ai. به خودت قدرت بده دسترسی به اینجا.
- PlatoAiStream. هوش وب 3 دانش تقویت شده دسترسی به اینجا.
- PlatoESG. کربن ، CleanTech، انرژی، محیط، خورشیدی، مدیریت پسماند دسترسی به اینجا.
- PlatoHealth. هوش بیوتکنولوژی و آزمایشات بالینی. دسترسی به اینجا.
- منبع: https://aws.amazon.com/blogs/machine-learning/efficiently-fine-tune-the-esm-2-protein-language-model-with-amazon-sagemaker/

