En primera parte En esta serie de tres partes, presentamos una solución que demuestra cómo se puede automatizar la detección de manipulación y fraude de documentos a escala utilizando servicios de IA y aprendizaje automático (ML) de AWS para un caso de uso de suscripción de hipotecas.
En esta publicación, presentamos un enfoque para desarrollar un modelo de visión por computadora basado en aprendizaje profundo para detectar y resaltar imágenes falsificadas en la suscripción de hipotecas. Brindamos orientación sobre la construcción, capacitación e implementación de redes de aprendizaje profundo en Amazon SageMaker.
En la Parte 3, demostramos cómo implementar la solución en Detector de fraudes de Amazon.
Resumen de la solución
Para cumplir con el objetivo de detectar la manipulación de documentos en la suscripción de hipotecas, empleamos un modelo de visión por computadora alojado en SageMaker para nuestra solución de detección de falsificación de imágenes. Este modelo recibe una imagen de prueba como entrada y genera una predicción de probabilidad de falsificación como salida. La arquitectura de la red es como se muestra en el siguiente diagrama.
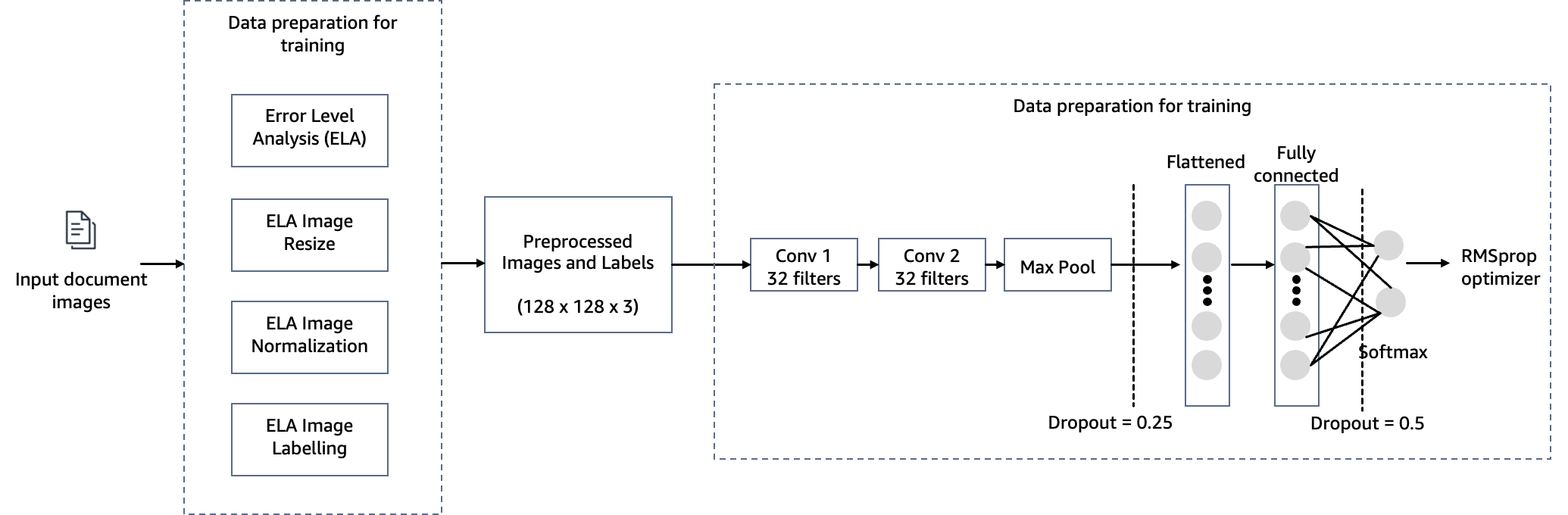
La falsificación de imágenes implica principalmente cuatro técnicas: empalmar, copiar y mover, eliminar y mejorar. Dependiendo de las características de la falsificación, se pueden utilizar diferentes pistas como base para la detección y localización. Estas pistas incluyen artefactos de compresión JPEG, inconsistencias en los bordes, patrones de ruido, consistencia del color, similitud visual, consistencia EXIF y modelo de cámara.
Dado el amplio ámbito de la detección de falsificaciones de imágenes, utilizamos el algoritmo de análisis de nivel de error (ELA) como método ilustrativo para detectar falsificaciones. Seleccionamos la técnica ELA para esta publicación por las siguientes razones:
- Es más rápido de implementar y puede detectar fácilmente la manipulación de imágenes.
- Funciona analizando los niveles de compresión de diferentes partes de una imagen. Esto le permite detectar inconsistencias que pueden indicar manipulación (por ejemplo, si un área se copió y pegó de otra imagen que se había guardado con un nivel de compresión diferente).
- Es bueno para detectar manipulaciones más sutiles o perfectas que pueden ser difíciles de detectar a simple vista. Incluso pequeños cambios en una imagen pueden introducir anomalías de compresión detectables.
- No depende de tener la imagen original sin modificar para comparar. ELA puede identificar signos de manipulación sólo dentro de la propia imagen cuestionada. Otras técnicas a menudo requieren comparar el original sin modificar.
- Es una técnica ligera que sólo se basa en analizar artefactos de compresión en los datos de la imagen digital. No depende de hardware especializado ni de conocimientos forenses. Esto hace que ELA sea accesible como una herramienta de análisis de primer paso.
- La imagen ELA de salida puede resaltar claramente las diferencias en los niveles de compresión, haciendo que las áreas manipuladas sean visiblemente obvias. Esto permite que incluso un no experto reconozca signos de posible manipulación.
- Funciona con muchos tipos de imágenes (como JPEG, PNG y GIF) y solo requiere la propia imagen para analizarla. Otras técnicas forenses pueden estar más restringidas en formatos o requisitos de imagen original.
Sin embargo, en escenarios del mundo real donde puede tener una combinación de documentos de entrada (JPEG, PNG, GIF, TIFF, PDF), recomendamos emplear ELA junto con varios otros métodos, como detectar inconsistencias en los bordes, patrones de ruido, uniformidad de color, Consistencia de datos EXIF, identificación del modelo de cámaray uniformidad de fuente. Nuestro objetivo es actualizar el código de esta publicación con técnicas adicionales de detección de falsificaciones.
La premisa subyacente de ELA supone que las imágenes de entrada están en formato JPEG, conocido por su compresión con pérdida. Sin embargo, el método aún puede ser efectivo incluso si las imágenes de entrada estaban originalmente en un formato sin pérdidas (como PNG, GIF o BMP) y luego se convirtieron a JPEG durante el proceso de manipulación. Cuando se aplica ELA a formatos originales sin pérdidas, normalmente indica una calidad de imagen consistente sin ningún deterioro, lo que dificulta identificar áreas alteradas. En imágenes JPEG, la norma esperada es que toda la imagen presente niveles de compresión similares. Sin embargo, si una sección particular dentro de la imagen muestra un nivel de error marcadamente diferente, a menudo sugiere que se ha realizado una alteración digital.
ELA destaca las diferencias en la tasa de compresión JPEG. Las regiones con coloración uniforme probablemente tendrán un resultado de ELA más bajo (por ejemplo, un color más oscuro en comparación con los bordes de alto contraste). Los elementos que debe buscar para identificar manipulación o modificación incluyen lo siguiente:
- Los bordes similares deberían tener un brillo similar en el resultado de ELA. Todos los bordes de alto contraste deben verse similares entre sí y todos los bordes de bajo contraste deben verse similares. En una fotografía original, los bordes de bajo contraste deben ser casi tan brillantes como los de alto contraste.
- Texturas similares deberían tener colores similares bajo ELA. Las áreas con más detalles en la superficie, como un primer plano de una pelota de baloncesto, probablemente tendrán un resultado de ELA más alto que una superficie lisa.
- Independientemente del color real de la superficie, todas las superficies planas deben tener aproximadamente el mismo color según ELA.
Las imágenes JPEG utilizan un sistema de compresión con pérdida. Cada nueva codificación (volver a guardar) de la imagen añade más pérdida de calidad a la imagen. Específicamente, el algoritmo JPEG opera en una cuadrícula de 8×8 píxeles. Cada cuadrado de 8×8 se comprime de forma independiente. Si la imagen no se modifica en absoluto, entonces todos los cuadrados de 8 × 8 deberían tener potenciales de error similares. Si la imagen no se modifica y se vuelve a guardar, entonces cada cuadrado debería degradarse aproximadamente al mismo ritmo.
ELA guarda la imagen con un nivel de calidad JPEG específico. Este volver a guardar introduce una cantidad conocida de errores en toda la imagen. Luego, la imagen guardada nuevamente se compara con la imagen original. Si se modifica una imagen, entonces cada cuadrado de 8 × 8 que fue tocado por la modificación debe tener un potencial de error mayor que el resto de la imagen.
Los resultados de ELA dependen directamente de la calidad de la imagen. Es posible que desee saber si se agregó algo, pero si la imagen se copia varias veces, es posible que ELA solo permita detectar los guardados nuevamente. Intente encontrar la versión de mejor calidad de la imagen.
Con capacitación y práctica, ELA también puede aprender a identificar transformaciones de escalado, calidad, recorte y guardado de imágenes. Por ejemplo, si una imagen que no es JPEG contiene líneas de cuadrícula visibles (1 píxel de ancho en cuadrados de 8 × 8), significa que la imagen comenzó como JPEG y se convirtió a un formato que no es JPEG (como PNG). Si algunas áreas de la imagen carecen de líneas de cuadrícula o las líneas de cuadrícula se desplazan, entonces indica un empalme o una parte dibujada en la imagen que no es JPEG.
En las siguientes secciones, demostramos los pasos para configurar, entrenar e implementar el modelo de visión por computadora.
Requisitos previos
Para seguir con esta publicación, complete los siguientes requisitos previos:
- Tener una cuenta de AWS.
- Preparar Estudio Amazon SageMaker. Puede iniciar rápidamente SageMaker Studio utilizando ajustes preestablecidos predeterminados, lo que facilita un inicio rápido. Para obtener más información, consulte Amazon SageMaker simplifica la configuración de Amazon SageMaker Studio para usuarios individuales.
- Abra SageMaker Studio e inicie una terminal del sistema.
- Ejecute el siguiente comando en la terminal:
git clone https://github.com/aws-samples/document-tampering-detection.git - El costo total de ejecutar SageMaker Studio para un usuario y las configuraciones del entorno del portátil es de $7.314 USD por hora.
Configurar el cuaderno de entrenamiento modelo
Complete los siguientes pasos para configurar su cuaderno de entrenamiento:
- Abra la
tampering_detection_training.ipynbarchivo del directorio de detección de manipulación de documentos. - Configure el entorno del portátil con la imagen TensorFlow 2.6 Python 3.8 CPU o GPU optimizada.
Es posible que tenga problemas de disponibilidad insuficiente o alcance el límite de cuota para instancias de GPU dentro de su cuenta de AWS al seleccionar instancias optimizadas para GPU. Para aumentar la cuota, visite la consola de Cuotas de servicio y aumente el límite de servicio para el tipo de instancia específico que necesita. En tales casos, también puede utilizar un entorno de portátil optimizado para la CPU. - Núcleo, escoger Python3.
- Tipo de instancia, escoger ml.m5d.24xgrande o cualquier otra instancia grande.
Seleccionamos un tipo de instancia más grande para reducir el tiempo de entrenamiento del modelo. Con un entorno de notebook ml.m5d.24xlarge, el costo por hora es de $7.258 USD por hora.
Ejecute el cuaderno de entrenamiento
Ejecute cada celda en el cuaderno. tampering_detection_training.ipynb en orden. Analizamos algunas celdas con más detalle en las siguientes secciones.
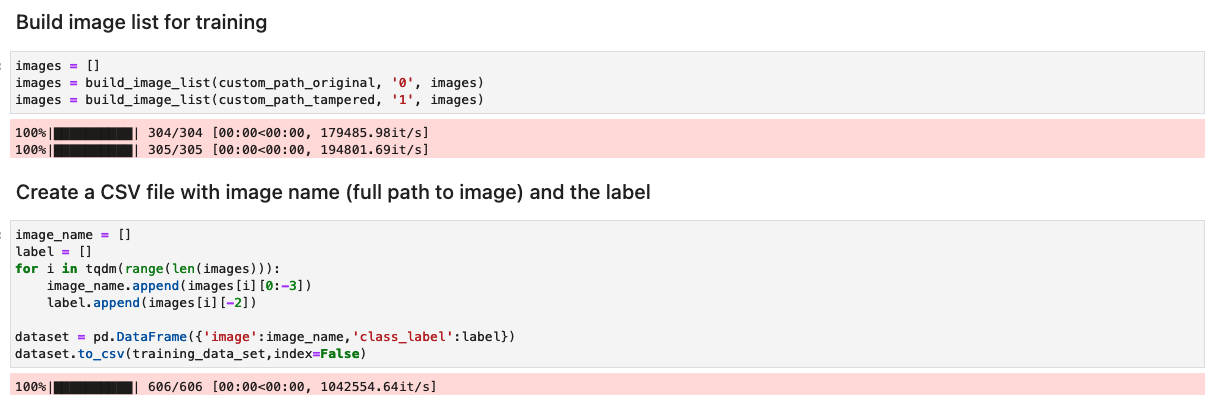
Prepare el conjunto de datos con una lista de imágenes originales y manipuladas.
Antes de ejecutar la siguiente celda en el cuaderno, prepare un conjunto de datos de documentos originales y manipulados según sus requisitos comerciales específicos. Para esta publicación, utilizamos un conjunto de datos de muestra de recibos de pago y extractos bancarios manipulados. El conjunto de datos está disponible en el directorio de imágenes del Repositorio GitHub.

El cuaderno lee las imágenes originales y manipuladas del images/training directorio.
El conjunto de datos para el entrenamiento se crea utilizando un archivo CSV con dos columnas: la ruta al archivo de imagen y la etiqueta de la imagen (0 para la imagen original y 1 para la imagen manipulada).
Procese el conjunto de datos generando los resultados de ELA de cada imagen de entrenamiento.
En este paso, generamos el resultado ELA (con una calidad del 90%) de la imagen de entrenamiento de entrada. La función convert_to_ela_image toma dos parámetros: ruta, que es la ruta a un archivo de imagen, y calidad, que representa el parámetro de calidad para la compresión JPEG. La función realiza los siguientes pasos:
- Convierta la imagen al formato RGB y vuelva a guardarla como un archivo JPEG con la calidad especificada con el nombre tempresaved.jpg.
- Calcule la diferencia entre la imagen original y la imagen JPEG (ELA) guardada nuevamente para determinar la diferencia máxima en valores de píxeles entre las imágenes original y guardada nuevamente.
- Calcule un factor de escala basado en la diferencia máxima para ajustar el brillo de la imagen ELA.
- Mejore el brillo de la imagen ELA utilizando el factor de escala calculado.
- Cambie el tamaño del resultado de ELA a 128x128x3, donde 3 representa la cantidad de canales para reducir el tamaño de entrada para el entrenamiento.
- Devuelve la imagen de ELA.
En formatos de imagen con pérdida como JPEG, el proceso de guardado inicial provoca una pérdida de color considerable. Sin embargo, cuando la imagen se carga y posteriormente se vuelve a codificar en el mismo formato con pérdida, generalmente se agrega menos degradación del color. Los resultados de ELA enfatizan las áreas de la imagen más susceptibles a la degradación del color al volver a guardarla. Generalmente, las alteraciones aparecen de manera prominente en regiones que exhiben un mayor potencial de degradación en comparación con el resto de la imagen.
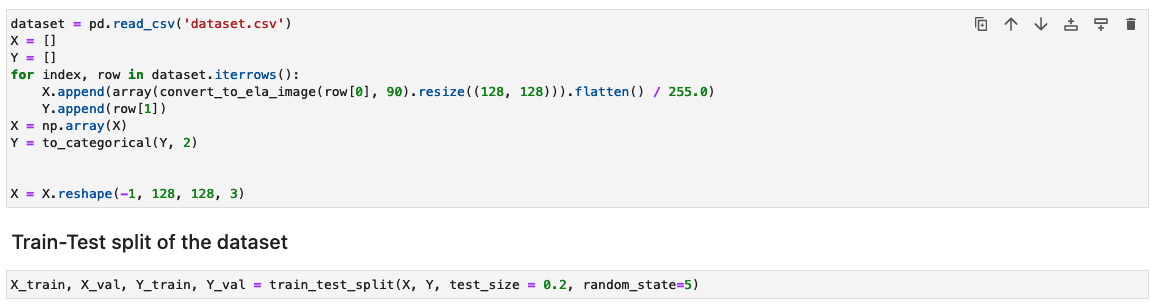
A continuación, las imágenes se procesan en una matriz NumPy para su entrenamiento. Luego dividimos el conjunto de datos de entrada aleatoriamente en datos de entrenamiento y de prueba o validación (80/20). Puede ignorar cualquier advertencia al ejecutar estas celdas.
Dependiendo del tamaño del conjunto de datos, la ejecución de estas celdas puede tardar en completarse. Para el conjunto de datos de muestra que proporcionamos en este repositorio, podría tardar entre 5 y 10 minutos.
Configurar el modelo CNN
En este paso, construimos una versión mínima de la red VGG con pequeños filtros convolucionales. El VGG-16 consta de 13 capas convolucionales y tres capas completamente conectadas. La siguiente captura de pantalla ilustra la arquitectura de nuestro modelo de red neuronal convolucional (CNN).
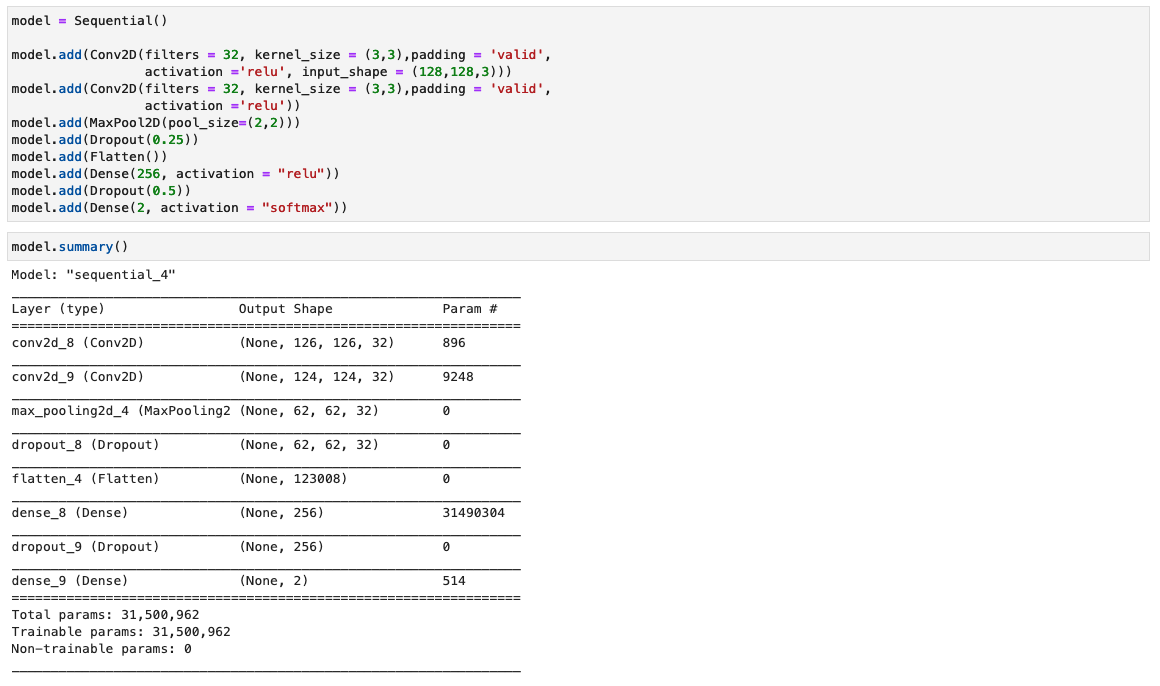
Tenga en cuenta las siguientes configuraciones:
- Entrada – El modelo admite un tamaño de entrada de imagen de 128x128x3.
- Capas convolucionales – Las capas convolucionales utilizan un campo receptivo mínimo (3×3), el tamaño más pequeño posible que aún captura arriba/abajo e izquierda/derecha. A esto le sigue una función de activación de unidad lineal rectificada (ReLU) que reduce el tiempo de entrenamiento. Esta es una función lineal que generará la entrada si es positiva; de lo contrario, la salida es cero. El paso de convolución se fija en el valor predeterminado (1 píxel) para mantener la resolución espacial preservada después de la convolución (el paso es el número de desplazamientos de píxeles sobre la matriz de entrada).
- Capas totalmente conectadas – La red tiene dos capas completamente conectadas. La primera capa densa usa activación ReLU y la segunda usa softmax para clasificar la imagen como original o manipulada.
Puede ignorar cualquier advertencia al ejecutar estas celdas.
Guarde los artefactos del modelo.
Guarde el modelo entrenado con un nombre de archivo único (por ejemplo, basado en la fecha y hora actuales) en un directorio llamado modelo.

El modelo se guarda en formato Keras con la extensión .keras. También guardamos los artefactos del modelo como un directorio llamado 1 que contiene firmas serializadas y el estado necesario para ejecutarlas, incluidos valores de variables y vocabularios para implementar en un tiempo de ejecución de SageMaker (que discutiremos más adelante en esta publicación).
Medir el rendimiento del modelo
La siguiente curva de pérdida muestra la progresión de la pérdida del modelo a lo largo de las épocas de entrenamiento (iteraciones).
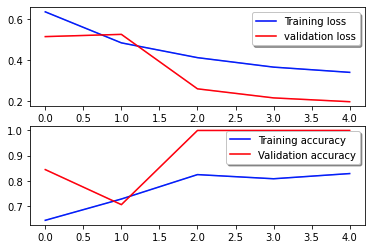
La función de pérdida mide qué tan bien las predicciones del modelo coinciden con los objetivos reales. Los valores más bajos indican una mejor alineación entre las predicciones y los valores verdaderos. La disminución de la pérdida a lo largo de las épocas significa que el modelo está mejorando. La curva de precisión ilustra la precisión del modelo durante las épocas de entrenamiento. La precisión es la relación entre las predicciones correctas y el número total de predicciones. Una mayor precisión indica un modelo de mejor rendimiento. Normalmente, la precisión aumenta durante el entrenamiento a medida que el modelo aprende patrones y mejora su capacidad predictiva. Esto le ayudará a determinar si el modelo está sobreajustado (funciona bien con los datos de entrenamiento pero mal con datos invisibles) o está insuficientemente ajustado (no está aprendiendo lo suficiente de los datos de entrenamiento).
La siguiente matriz de confusión representa visualmente qué tan bien el modelo distingue con precisión entre las clases positiva (imagen falsificada, representada como valor 1) y negativa (imagen no manipulada, representada como valor 0).
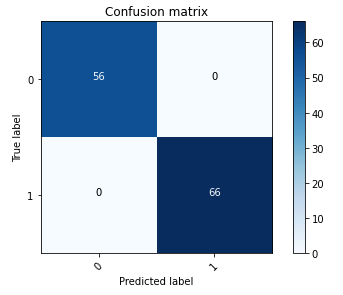
Después de la capacitación del modelo, nuestro siguiente paso implica implementar el modelo de visión por computadora como una API. Esta API se integrará en las aplicaciones comerciales como componente del flujo de trabajo de suscripción. Para lograrlo, utilizamos Amazon SageMaker Inference, un servicio totalmente administrado. Este servicio se integra perfectamente con las herramientas MLOps, lo que permite la implementación de modelos escalables, inferencia rentable, gestión mejorada de modelos en producción y complejidad operativa reducida. En esta publicación, implementamos el modelo como un punto final de inferencia en tiempo real. Sin embargo, es importante tener en cuenta que, según el flujo de trabajo de sus aplicaciones empresariales, la implementación del modelo también se puede adaptar como procesamiento por lotes, manejo asincrónico o mediante una arquitectura de implementación sin servidor.
Configurar el cuaderno de implementación del modelo
Complete los siguientes pasos para configurar su cuaderno de implementación de modelo:
- Abra la
tampering_detection_model_deploy.ipynbarchivo del directorio de detección de manipulación de documentos. - Configure el entorno del portátil con la imagen Data Science 3.0.
- Núcleo, escoger Python3.
- Tipo de instancia, escoger ml.t3.medio.
Con un entorno de notebook ml.t3.medium, el costo por hora es de $0.056 USD.
Cree una política en línea personalizada para el rol de SageMaker para permitir todas las acciones de Amazon S3
El Gestión de identidades y accesos de AWS (IAM) para SageMaker tendrá el formato AmazonSageMaker- ExecutionRole-<random numbers>. Asegúrate de estar utilizando el rol correcto. El nombre de la función se puede encontrar en los detalles del usuario dentro de las configuraciones del dominio de SageMaker.

Actualice la función de IAM para incluir una política en línea que permita a todos Servicio de almacenamiento simple de Amazon (Amazon S3) acciones. Esto será necesario para automatizar la creación y eliminación de depósitos de S3 que almacenarán los artefactos del modelo. Puede limitar el acceso a depósitos S3 específicos. Tenga en cuenta que utilizamos un comodín para el nombre del depósito S3 en la política de IAM (tamperingdetection*).

Ejecute el cuaderno de implementación
Ejecute cada celda en el cuaderno. tampering_detection_model_deploy.ipynb en orden. Analizamos algunas celdas con más detalle en las siguientes secciones.
Crea un cubo S3
Ejecute la celda para crear un depósito S3. El cubo se llamará tamperingdetection<current date time> y en la misma región de AWS que su entorno de SageMaker Studio.

Cree el archivo de artefactos del modelo y cárguelo en Amazon S3.
Cree un archivo tar.gz a partir de los artefactos del modelo. Hemos guardado los artefactos del modelo como un directorio llamado 1, que contiene firmas serializadas y el estado necesario para ejecutarlas, incluidos valores de variables y vocabularios para implementar en el tiempo de ejecución de SageMaker. También puede incluir un archivo de inferencia personalizado llamado inference.py dentro de la carpeta de código en el artefacto del modelo. La inferencia personalizada se puede utilizar para el preprocesamiento y posprocesamiento de la imagen de entrada.
![]()
Crear un punto final de inferencia de SageMaker
La celda para crear un punto final de inferencia de SageMaker puede tardar unos minutos en completarse.
Probar el punto final de inferencia
La función check_image preprocesa una imagen como una imagen ELA, la envía a un punto final de SageMaker para su inferencia, recupera y procesa las predicciones del modelo e imprime los resultados. El modelo toma una matriz NumPy de la imagen de entrada como una imagen ELA para proporcionar predicciones. Las predicciones se generan como 0, que representa una imagen no manipulada, y 1, que representa una imagen falsificada.

Invoquemos el modelo con una imagen no alterada de un recibo de sueldo y verifiquemos el resultado.

El modelo genera la clasificación como 0, lo que representa una imagen no alterada.
Ahora invoquemos el modelo con una imagen manipulada de un talón de pago y verifiquemos el resultado.

El modelo genera la clasificación como 1, lo que representa una imagen falsificada.
Limitaciones
Aunque ELA es una excelente herramienta para ayudar a detectar modificaciones, existen una serie de limitaciones, como las siguientes:
- Es posible que un solo cambio de píxel o un ajuste de color menor no genere un cambio notable en el ELA porque JPEG opera en una cuadrícula.
- ELA solo identifica qué regiones tienen diferentes niveles de compresión. Si una imagen de menor calidad se fusiona con una imagen de mayor calidad, entonces la imagen de menor calidad puede aparecer como una región más oscura.
- Escalar, cambiar el color o agregar ruido a una imagen modificará toda la imagen, creando un potencial de nivel de error más alto.
- Si una imagen se vuelve a guardar varias veces, es posible que se encuentre completamente en un nivel de error mínimo, donde más guardados no alteran la imagen. En este caso, ELA devolverá una imagen negra y no se podrán identificar modificaciones utilizando este algoritmo.
- Con Photoshop, el simple hecho de guardar la imagen puede afinar automáticamente las texturas y los bordes, creando un mayor potencial de nivel de error. Este artefacto no identifica modificación intencional; identifica que se utilizó un producto de Adobe. Técnicamente, ELA aparece como una modificación porque Adobe realizó una modificación automáticamente, pero la modificación no fue necesariamente intencionada por parte del usuario.
Recomendamos utilizar ELA junto con otras técnicas discutidas previamente en el blog para detectar una mayor variedad de casos de manipulación de imágenes. ELA también puede servir como una herramienta independiente para examinar visualmente las disparidades de imágenes, especialmente cuando entrenar un modelo basado en CNN se vuelve desafiante.
Limpiar
Para eliminar los recursos que creó como parte de esta solución, complete los siguientes pasos:
- Ejecute las celdas del cuaderno debajo del Limpiar sección. Esto eliminará lo siguiente:
- Punto final de inferencia de SageMaker – El nombre del punto final de inferencia será
tamperingdetection-<datetime>. - Objetos dentro del depósito S3 y el propio depósito S3 – El nombre del depósito será
tamperingdetection<datetime>.
- Punto final de inferencia de SageMaker – El nombre del punto final de inferencia será
- cerrar los recursos del cuaderno de SageMaker Studio.
Conclusión
En esta publicación, presentamos una solución de un extremo a otro para detectar fraude y manipulación de documentos mediante el aprendizaje profundo y SageMaker. Utilizamos ELA para preprocesar imágenes e identificar discrepancias en los niveles de compresión que pueden indicar manipulación. Luego entrenamos un modelo CNN en este conjunto de datos procesados para clasificar las imágenes como originales o manipuladas.
El modelo puede lograr un rendimiento sólido, con una precisión superior al 95 % con un conjunto de datos (falsificado y original) adecuado a los requisitos de su negocio. Esto indica que puede detectar de manera confiable documentos falsificados como recibos de pago y extractos bancarios. El modelo entrenado se implementa en un punto final de SageMaker para permitir la inferencia de baja latencia a escala. Al integrar esta solución en los flujos de trabajo hipotecarios, las instituciones pueden marcar automáticamente documentos sospechosos para una mayor investigación de fraude.
Aunque potente, ELA tiene algunas limitaciones a la hora de identificar ciertos tipos de manipulación más sutil. Como próximos pasos, el modelo podría mejorarse incorporando técnicas forenses adicionales en el entrenamiento y utilizando conjuntos de datos más grandes y diversos. En general, esta solución demuestra cómo se pueden utilizar el aprendizaje profundo y los servicios de AWS para crear soluciones impactantes que aumenten la eficiencia, reduzcan el riesgo y prevengan el fraude.
En la Parte 3, demostramos cómo implementar la solución en Amazon Fraud Detector.
Sobre los autores
 anup ravindranath es arquitecto de soluciones sénior en Amazon Web Services (AWS) con sede en Toronto, Canadá, y trabaja con organizaciones de servicios financieros. Ayuda a los clientes a transformar sus negocios e innovar en la nube.
anup ravindranath es arquitecto de soluciones sénior en Amazon Web Services (AWS) con sede en Toronto, Canadá, y trabaja con organizaciones de servicios financieros. Ayuda a los clientes a transformar sus negocios e innovar en la nube.
 vinnie saini es Arquitecto de Soluciones Sénior en Amazon Web Services (AWS) con sede en Toronto, Canadá. Ha estado ayudando a los clientes de Servicios Financieros a transformarse en la nube, con soluciones impulsadas por IA y ML asentadas sobre sólidos pilares fundamentales de Excelencia Arquitectónica.
vinnie saini es Arquitecto de Soluciones Sénior en Amazon Web Services (AWS) con sede en Toronto, Canadá. Ha estado ayudando a los clientes de Servicios Financieros a transformarse en la nube, con soluciones impulsadas por IA y ML asentadas sobre sólidos pilares fundamentales de Excelencia Arquitectónica.
- Distribución de relaciones públicas y contenido potenciado por SEO. Consiga amplificado hoy.
- PlatoData.Network Vertical Generativo Ai. Empodérate. Accede Aquí.
- PlatoAiStream. Inteligencia Web3. Conocimiento amplificado. Accede Aquí.
- PlatoESG. Carbón, tecnología limpia, Energía, Ambiente, Solar, Gestión de residuos. Accede Aquí.
- PlatoSalud. Inteligencia en Biotecnología y Ensayos Clínicos. Accede Aquí.
- Fuente: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/

