Bei der Vermögensverwaltung müssen Portfoliomanager die Unternehmen in ihrem Anlageuniversum genau überwachen, um Risiken und Chancen zu erkennen und Anlageentscheidungen zu treffen. Das Verfolgen direkter Ereignisse wie Gewinnberichte oder Bonitätsherabstufungen ist unkompliziert – Sie können Benachrichtigungen einrichten, um Manager über Nachrichten zu informieren, die Firmennamen enthalten. Die Erkennung von Auswirkungen zweiter und dritter Ordnung, die sich aus Ereignissen bei Lieferanten, Kunden, Partnern oder anderen Einheiten im Ökosystem eines Unternehmens ergeben, ist jedoch eine Herausforderung.
Beispielsweise würde sich eine Unterbrechung der Lieferkette bei einem wichtigen Lieferanten wahrscheinlich negativ auf die nachgelagerten Hersteller auswirken. Oder der Verlust eines Topkunden für einen Großkunden stellt ein Nachfragerisiko für den Lieferanten dar. Sehr oft machen solche Ereignisse keine Schlagzeilen, bei denen das betroffene Unternehmen direkt in den Fokus gerückt wird, es ist aber dennoch wichtig, darauf zu achten. In diesem Beitrag demonstrieren wir eine automatisierte Lösung, die Wissensgraphen und kombiniert generative künstliche Intelligenz (KI) um solche Risiken aufzudecken, indem Beziehungskarten mit Echtzeitnachrichten abgeglichen werden.
Im Großen und Ganzen umfasst dies zwei Schritte: Erstens den Aufbau der komplexen Beziehungen zwischen Unternehmen (Kunden, Lieferanten, Direktoren) in einem Wissensgraphen. Zweitens: Verwendung dieser Diagrammdatenbank zusammen mit generativer KI, um Auswirkungen zweiter und dritter Ordnung von Nachrichtenereignissen zu erkennen. Diese Lösung kann beispielsweise verdeutlichen, dass Verzögerungen bei einem Teilelieferanten die Produktion nachgelagerter Automobilhersteller in einem Portfolio beeinträchtigen können, auch wenn dies nicht direkt erwähnt wird.
Mit AWS können Sie diese Lösung in einer serverlosen, skalierbaren und vollständig ereignisgesteuerten Architektur bereitstellen. Dieser Beitrag zeigt einen Proof of Concept, der auf zwei wichtigen AWS-Services basiert, die sich gut für die Darstellung von Graphwissen und die Verarbeitung natürlicher Sprache eignen: Amazon Neptun und Amazonas Grundgestein. Neptune ist ein schneller, zuverlässiger und vollständig verwalteter Graphdatenbankdienst, der die Erstellung und Ausführung von Anwendungen erleichtert, die mit stark vernetzten Datensätzen arbeiten. Amazon Bedrock ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl leistungsstarker Foundation-Modelle (FMs) von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Cohere, Meta, Stability AI und Amazon sowie eine breite Palette von bietet Fähigkeiten zum Erstellen generativer KI-Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI.
Insgesamt demonstriert dieser Prototyp die Kunst des Möglichen mit Wissensgraphen und generativer KI – der Ableitung von Signalen durch die Verbindung unterschiedlicher Punkte. Der Vorteil für Anlageprofis besteht darin, dass sie die Entwicklungen näher am Signal verfolgen und gleichzeitig Störungen vermeiden können.
Erstellen Sie den Wissensgraphen

Der erste Schritt dieser Lösung ist die Erstellung eines Wissensgraphen. Eine wertvolle, aber oft übersehene Datenquelle für Wissensgraphen sind Jahresberichte des Unternehmens. Da offizielle Unternehmenspublikationen vor ihrer Veröffentlichung einer genauen Prüfung unterzogen werden, ist es wahrscheinlich, dass die darin enthaltenen Informationen korrekt und zuverlässig sind. Jahresberichte werden jedoch in einem unstrukturierten Format verfasst, das für die menschliche Lektüre und nicht für den maschinellen Gebrauch gedacht ist. Um ihr Potenzial auszuschöpfen, benötigen Sie eine Möglichkeit, die darin enthaltene Fülle an Fakten und Beziehungen systematisch zu extrahieren und zu strukturieren.
Mit generativen KI-Diensten wie Amazon Bedrock haben Sie jetzt die Möglichkeit, diesen Prozess zu automatisieren. Sie können einen Jahresbericht nehmen und eine Verarbeitungspipeline auslösen, um den Bericht aufzunehmen, ihn in kleinere Teile aufzuteilen und das Verständnis natürlicher Sprache anzuwenden, um wichtige Entitäten und Beziehungen herauszufiltern.
Beispielsweise würde ein Satz, der besagt, dass „[Unternehmen A] seine europäische Elektrolieferflotte mit einer Bestellung von 1,800 Elektrotransportern von [Unternehmen B] erweitert hat“, es Amazon Bedrock ermöglichen, Folgendes zu identifizieren:
- [Unternehmen A] als Kunde
- [Unternehmen B] als Lieferant
- Eine Lieferantenbeziehung zwischen [Unternehmen A] und [Unternehmen B]
- Beziehungsdetails von „Lieferant für Elektro-Lieferwagen“
Das Extrahieren solcher strukturierter Daten aus unstrukturierten Dokumenten erfordert die Bereitstellung sorgfältig gestalteter Eingabeaufforderungen für große Sprachmodelle (LLMs), damit diese Texte analysieren können, um Entitäten wie Unternehmen und Personen sowie Beziehungen wie Kunden, Lieferanten usw. herauszuarbeiten. Die Eingabeaufforderungen enthalten klare Anweisungen dazu, worauf Sie achten müssen und in welcher Struktur die Daten zurückgegeben werden sollen. Indem Sie diesen Vorgang im gesamten Jahresbericht wiederholen, können Sie die relevanten Entitäten und Beziehungen extrahieren, um ein umfassendes Wissensdiagramm zu erstellen.
Bevor Sie jedoch die extrahierten Informationen in den Wissensgraphen übernehmen, müssen Sie zunächst die Entitäten eindeutig machen. Beispielsweise gibt es möglicherweise bereits eine andere Entität „[Unternehmen A]“ im Wissensgraphen, diese könnte jedoch eine andere Organisation mit demselben Namen darstellen. Amazon Bedrock kann die Attribute wie Geschäftsschwerpunkt, Branche und umsatzgenerierende Branchen und Beziehungen mit anderen Einheiten begründen und vergleichen, um festzustellen, ob die beiden Einheiten tatsächlich verschieden sind. Dadurch wird verhindert, dass unabhängige Unternehmen fälschlicherweise zu einer einzigen Einheit zusammengeführt werden.
Nachdem die Begriffsklärung abgeschlossen ist, können Sie Ihrem Neptune-Wissensdiagramm zuverlässig neue Entitäten und Beziehungen hinzufügen und es mit den aus Jahresberichten extrahierten Fakten anreichern. Im Laufe der Zeit wird die Aufnahme zuverlässiger Daten und die Integration zuverlässigerer Datenquellen dazu beitragen, ein umfassendes Wissensdiagramm zu erstellen, das die Gewinnung von Erkenntnissen durch Diagrammabfragen und Analysen unterstützen kann.
Diese durch generative KI ermöglichte Automatisierung ermöglicht die Verarbeitung Tausender Jahresberichte und erschließt einen unschätzbaren Vorteil für die Kuratierung von Wissensgraphen, der sonst aufgrund des unerschwinglich hohen manuellen Aufwands ungenutzt bleiben würde.
Der folgende Screenshot zeigt ein Beispiel für die visuelle Erkundung, die in einer Neptune-Diagrammdatenbank mithilfe von möglich ist Diagramm-Explorer Werkzeug.

Nachrichtenartikel verarbeiten

Der nächste Schritt der Lösung besteht darin, die Newsfeeds der Portfoliomanager automatisch anzureichern und Artikel hervorzuheben, die für ihre Interessen und Investitionen relevant sind. Für den Newsfeed können Portfoliomanager einen beliebigen Drittanbieter für Nachrichten über abonnieren AWS-Datenaustausch oder eine andere Nachrichten-API ihrer Wahl.
Wenn ein Nachrichtenartikel in das System gelangt, wird eine Aufnahmepipeline aufgerufen, um den Inhalt zu verarbeiten. Unter Verwendung von Techniken, die der Verarbeitung von Jahresberichten ähneln, wird Amazon Bedrock verwendet, um Entitäten, Attribute und Beziehungen aus dem Nachrichtenartikel zu extrahieren, die dann zur Disambiguierung mit dem Wissensgraphen verwendet werden, um die entsprechende Entität im Wissensgraphen zu identifizieren.
Der Wissensgraph enthält Verbindungen zwischen Unternehmen und Personen. Durch die Verknüpfung von Artikelentitäten mit vorhandenen Knoten können Sie feststellen, ob sich Themen innerhalb von zwei Hops von den Unternehmen befinden, in die der Portfoliomanager investiert hat oder an denen er interessiert ist. Das Finden einer solchen Verbindung zeigt an, dass Der Artikel kann für den Portfoliomanager relevant sein, und da die zugrunde liegenden Daten in einem Wissensgraphen dargestellt werden, können sie visualisiert werden, um dem Portfoliomanager zu helfen, zu verstehen, warum und wie dieser Kontext relevant ist. Neben der Identifizierung von Verbindungen zum Portfolio können Sie mit Amazon Bedrock auch eine Stimmungsanalyse für die referenzierten Entitäten durchführen.
Das Endergebnis ist ein angereicherter Newsfeed mit Artikeln, die sich wahrscheinlich auf die Interessengebiete und Investitionen des Portfoliomanagers auswirken.
Lösungsüberblick
Die Gesamtarchitektur der Lösung sieht wie im folgenden Diagramm aus.
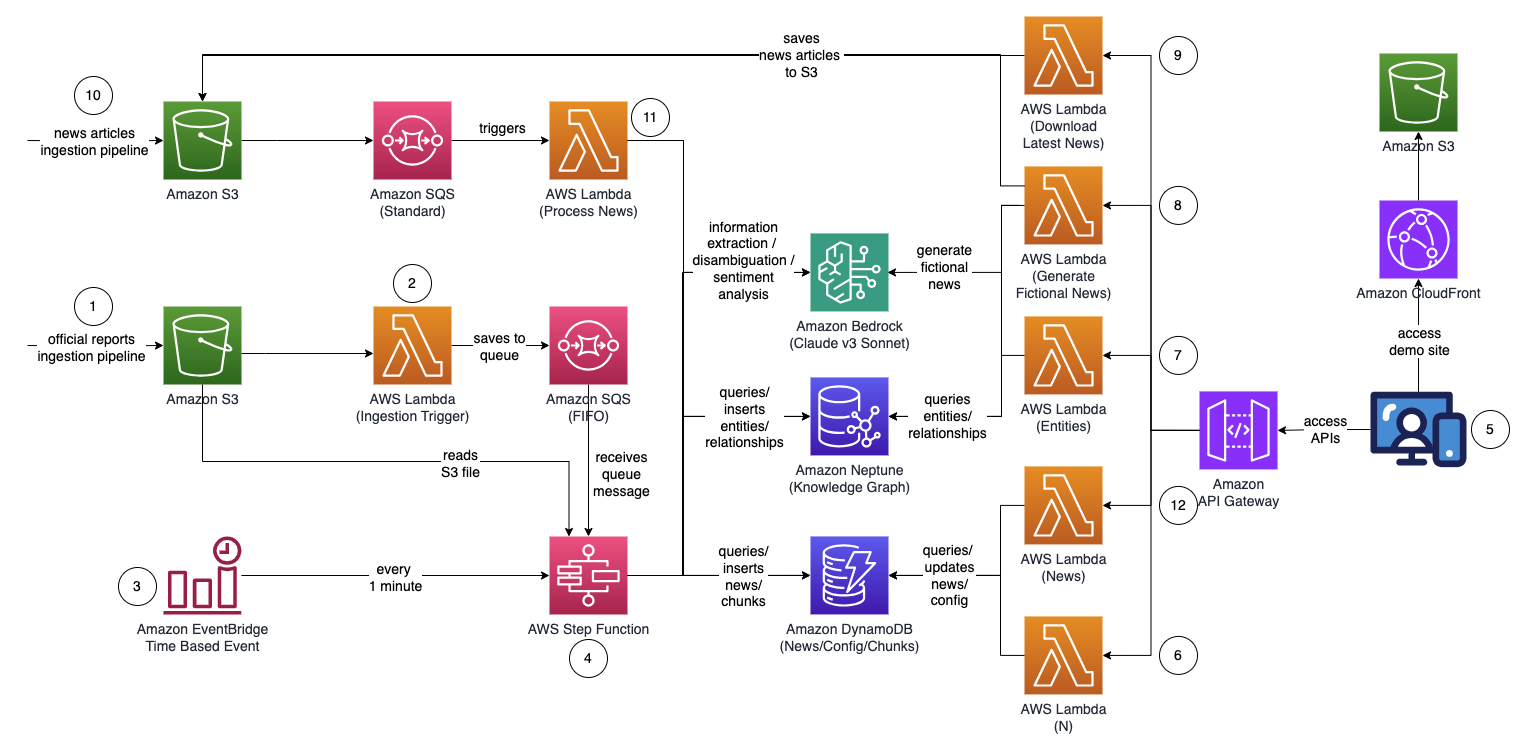
Der Arbeitsablauf besteht aus den folgenden Schritten:
- Ein Benutzer lädt offizielle Berichte (im PDF-Format) auf eine hoch Amazon Simple Storage-Service (Amazon S3) Eimer. Bei den Berichten sollte es sich um offiziell veröffentlichte Berichte handeln, um die Aufnahme ungenauer Daten in Ihren Wissensgraphen (im Gegensatz zu Nachrichten und Boulevardzeitungen) zu minimieren.
- Die S3-Ereignisbenachrichtigung ruft eine auf AWS Lambda Funktion, die den S3-Bucket und den Dateinamen an eine sendet Amazon Simple Queue-Dienst (Amazon SQS)-Warteschlange. Die First-In-First-Out (FIFO)-Warteschlange stellt sicher, dass der Berichtsaufnahmeprozess nacheinander durchgeführt wird, um die Wahrscheinlichkeit zu verringern, dass doppelte Daten in Ihren Wissensgraphen eingefügt werden.
- An Amazon EventBridge Das zeitbasierte Ereignis wird jede Minute ausgeführt, um die Ausführung eines zu starten AWS Step-Funktionen Zustandsmaschine asynchron.
- Die Step Functions-Zustandsmaschine durchläuft eine Reihe von Aufgaben, um das hochgeladene Dokument zu verarbeiten, indem sie wichtige Informationen extrahiert und in Ihren Wissensgraphen einfügt:
- Empfangen Sie die Warteschlangennachricht von Amazon SQS.
- Laden Sie die PDF-Berichtsdatei von Amazon S3 herunter, teilen Sie sie zur Verarbeitung in mehrere kleinere Textblöcke (ca. 1,000 Wörter) auf und speichern Sie die Textblöcke in Amazon DynamoDB.
- Verwenden Sie Claude v3 Sonnet von Anthropic auf Amazon Bedrock, um die ersten paar Textabschnitte zu verarbeiten, um die Hauptentität zu bestimmen, auf die sich der Bericht bezieht, zusammen mit relevanten Attributen (z. B. Branche).
- Rufen Sie die Textblöcke aus DynamoDB ab und rufen Sie für jeden Textblock eine Lambda-Funktion auf, um mithilfe von Amazon Bedrock Entitäten (z. B. Unternehmen oder Personen) und deren Beziehung (Kunde, Lieferant, Partner, Wettbewerber oder Direktor) zur Hauptentität zu extrahieren .
- Konsolidieren Sie alle extrahierten Informationen.
- Filtern Sie Störgeräusche und irrelevante Entitäten (z. B. generische Begriffe wie „Verbraucher“) mit Amazon Bedrock heraus.
- Verwenden Sie Amazon Bedrock, um eine Begriffsklärung durchzuführen, indem Sie die extrahierten Informationen mit der Liste ähnlicher Entitäten aus dem Wissensgraphen vergleichen. Wenn die Entität nicht existiert, fügen Sie sie ein. Andernfalls verwenden Sie die Entität, die bereits im Wissensgraphen vorhanden ist. Fügen Sie alle extrahierten Beziehungen ein.
- Bereinigen Sie, indem Sie die SQS-Warteschlangennachricht und die S3-Datei löschen.
- Ein Benutzer greift auf eine React-basierte Webanwendung zu, um die Nachrichtenartikel anzuzeigen, die durch Informationen zu Entität, Stimmung und Verbindungspfad ergänzt werden.
- Mithilfe der Webanwendung gibt der Benutzer die Anzahl der Hops (Standard: N=2) auf dem zu überwachenden Verbindungspfad an.
- Mithilfe der Webanwendung gibt der Benutzer die Liste der zu verfolgenden Entitäten an.
- Um fiktive Nachrichten zu generieren, wählt der Benutzer Generieren Sie Beispielnachrichten um 10 Beispiel-Finanznachrichtenartikel mit zufälligem Inhalt zu generieren, die in den Nachrichtenaufnahmeprozess eingespeist werden. Der Inhalt wird mit Amazon Bedrock generiert und ist rein fiktiv.
- Um aktuelle Nachrichten herunterzuladen, wählt der Benutzer Laden Sie die neuesten Nachrichten herunter um die Top-Nachrichten des heutigen Tages herunterzuladen (unterstützt von NewsAPI.org).
- Die Nachrichtendatei (TXT-Format) wird in einen S3-Bucket hochgeladen. Mit den Schritten 8 und 9 werden Nachrichten automatisch in den S3-Bucket hochgeladen. Sie können jedoch auch Integrationen zu Ihrem bevorzugten Nachrichtenanbieter wie AWS Data Exchange oder einem anderen Nachrichtenanbieter von Drittanbietern erstellen, um Nachrichtenartikel als Dateien im S3-Bucket abzulegen. Der Inhalt der Nachrichtendatendatei sollte wie folgt formatiert sein:
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - Die S3-Ereignisbenachrichtigung sendet den S3-Bucket- oder Dateinamen an Amazon SQS (Standard), das mehrere Lambda-Funktionen aufruft, um die Nachrichtendaten parallel zu verarbeiten:
- Verwenden Sie Amazon Bedrock, um in den Nachrichten erwähnte Entitäten zusammen mit allen zugehörigen Informationen, Beziehungen und Stimmungen der erwähnten Entität zu extrahieren.
- Vergleichen Sie den Wissensgraphen und verwenden Sie Amazon Bedrock, um eine Begriffsklärung durchzuführen, indem Sie die verfügbaren Informationen aus den Nachrichten und aus dem Wissensgraphen nutzen, um die entsprechende Entität zu identifizieren.
- Nachdem die Entität gefunden wurde, suchen Sie nach allen Verbindungspfaden, die mit mit gekennzeichneten Entitäten verbunden sind, und geben Sie diese zurück
INTERESTED=YESim Wissensgraphen, die innerhalb von N=2 Sprüngen entfernt sind.
- Die Webanwendung wird alle 1 Sekunde automatisch aktualisiert, um die neuesten verarbeiteten Nachrichten abzurufen und in der Webanwendung anzuzeigen.
Stellen Sie den Prototyp bereit
Sie können die Prototyplösung bereitstellen und selbst mit dem Experimentieren beginnen. Der Prototyp ist erhältlich bei GitHub und enthält Einzelheiten zu Folgendem:
- Bereitstellungsvoraussetzungen
- Bereitstellungsschritte
- Bereinigungsschritte
Zusammenfassung
In diesem Beitrag wurde eine Proof-of-Concept-Lösung vorgestellt, die Portfoliomanagern hilft, Risiken zweiter und dritter Ordnung aus Nachrichtenereignissen zu erkennen, ohne direkte Hinweise auf die von ihnen beobachteten Unternehmen. Durch die Kombination eines Wissensgraphen komplexer Unternehmensbeziehungen mit einer Echtzeit-Nachrichtenanalyse mithilfe generativer KI können nachgelagerte Auswirkungen hervorgehoben werden, beispielsweise Produktionsverzögerungen aufgrund von Lieferengpässen.
Obwohl es sich nur um einen Prototyp handelt, zeigt diese Lösung, dass Wissensgraphen und Sprachmodelle vielversprechend sind, um Punkte zu verbinden und Signale aus Rauschen abzuleiten. Diese Technologien können Anlageexperten helfen, indem sie Risiken durch Beziehungsabbildungen und Überlegungen schneller aufdecken. Insgesamt handelt es sich um eine vielversprechende Anwendung von Graphdatenbanken und KI, die eine Erkundung erfordert, um die Investitionsanalyse und Entscheidungsfindung zu verbessern.
Wenn dieses Beispiel generativer KI in Finanzdienstleistungen für Ihr Unternehmen von Interesse ist oder Sie eine ähnliche Idee haben, wenden Sie sich an Ihren AWS-Kundenbetreuer, und wir werden uns freuen, die Sache mit Ihnen weiter zu erkunden.
Über den Autor
 Xan Huang ist Senior Solutions Architect bei AWS und hat seinen Sitz in Singapur. Er arbeitet mit großen Finanzinstituten zusammen, um sichere, skalierbare und hochverfügbare Lösungen in der Cloud zu entwerfen und aufzubauen. Außerhalb der Arbeit verbringt Xan den Großteil seiner Freizeit mit seiner Familie und lässt sich von seiner dreijährigen Tochter herumkommandieren. Sie finden Xan auf LinkedIn.
Xan Huang ist Senior Solutions Architect bei AWS und hat seinen Sitz in Singapur. Er arbeitet mit großen Finanzinstituten zusammen, um sichere, skalierbare und hochverfügbare Lösungen in der Cloud zu entwerfen und aufzubauen. Außerhalb der Arbeit verbringt Xan den Großteil seiner Freizeit mit seiner Familie und lässt sich von seiner dreijährigen Tochter herumkommandieren. Sie finden Xan auf LinkedIn.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

