Generative KI Anwendungen, die auf Basismodellen (FMs) basieren, ermöglichen Unternehmen einen erheblichen Geschäftswert in Bezug auf Kundenerlebnis, Produktivität, Prozessoptimierung und Innovationen. Die Einführung dieser FMs erfordert jedoch die Bewältigung einiger wichtiger Herausforderungen, darunter Qualitätsausgabe, Datenschutz, Sicherheit, Integration mit Unternehmensdaten, Kosten und zu liefernde Fähigkeiten.
In diesem Beitrag untersuchen wir verschiedene Ansätze, die Sie beim Erstellen von Anwendungen mit generativer KI verfolgen können. Angesichts der rasanten Weiterentwicklung von FMs ist es eine aufregende Zeit, ihre Macht zu nutzen, aber es ist auch wichtig zu verstehen, wie man sie richtig nutzt, um Geschäftsergebnisse zu erzielen. Wir bieten einen Überblick über die wichtigsten generativen KI-Ansätze, einschließlich Prompt Engineering, Retrieval Augmented Generation (RAG) und Modellanpassung. Bei der Anwendung dieser Ansätze diskutieren wir wichtige Überlegungen zu potenzieller Halluzination, Integration mit Unternehmensdaten, Ausgabequalität und Kosten. Am Ende verfügen Sie über solide Richtlinien und ein hilfreiches Flussdiagramm zur Bestimmung der besten Methode zur Entwicklung Ihrer eigenen FM-gestützten Anwendungen, basierend auf Beispielen aus der Praxis. Unabhängig davon, ob Sie einen Chatbot oder ein Zusammenfassungstool erstellen, können Sie leistungsstarke FMs entsprechend Ihren Anforderungen gestalten.
Generative KI mit AWS
Das Aufkommen von FMs schafft sowohl Chancen als auch Herausforderungen für Unternehmen, die diese Technologien nutzen möchten. Eine zentrale Herausforderung besteht darin, qualitativ hochwertige, kohärente Ergebnisse sicherzustellen, die den Geschäftsanforderungen entsprechen, und nicht Halluzinationen oder falsche Informationen. Unternehmen müssen außerdem sorgfältig mit Datenschutz- und Sicherheitsrisiken umgehen, die sich aus der Verarbeitung proprietärer Daten mit FMs ergeben. Die erforderlichen Fähigkeiten zur ordnungsgemäßen Integration, Anpassung und Validierung von FMs in bestehende Systeme und Daten sind Mangelware. Der Aufbau großer Sprachmodelle (LLMs) von Grund auf oder die Anpassung vorab trainierter Modelle erfordert erhebliche Rechenressourcen, erfahrene Datenwissenschaftler und monatelange Entwicklungsarbeit. Allein der Rechenaufwand kann leicht in die Millionen gehen, um Modelle mit Hunderten von Milliarden Parametern auf riesigen Datensätzen mit Tausenden von GPUs oder TPUs zu trainieren. Über die Hardware hinaus erfordern die Datenbereinigung und -verarbeitung, das Design von Modellarchitekturen, die Optimierung von Hyperparametern und die Entwicklung von Trainingspipelines spezielle Fähigkeiten im Bereich maschinelles Lernen (ML). Der End-to-End-Prozess ist komplex, zeitaufwändig und für die meisten Unternehmen ohne die erforderliche Infrastruktur und Talentinvestition unerschwinglich. Unternehmen, die diesen Risiken nicht angemessen begegnen, können negative Auswirkungen auf den Ruf ihrer Marke, das Vertrauen ihrer Kunden, ihre Geschäftstätigkeit und ihre Umsätze haben.
Amazonas Grundgestein ist ein vollständig verwalteter Dienst, der über eine einzige API eine Auswahl leistungsstarker Basismodelle (FMs) von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Cohere, Meta, Mistral AI, Stability AI und Amazon bietet. Mit der serverlosen Erfahrung von Amazon Bedrock können Sie schnell loslegen, FMs privat mit Ihren eigenen Daten anpassen und sie mithilfe von AWS-Tools in Ihre Anwendungen integrieren und bereitstellen, ohne eine Infrastruktur verwalten zu müssen. Amazon Bedrock ist HIPAA-berechtigt und Sie können Amazon Bedrock in Übereinstimmung mit der DSGVO nutzen. Bei Amazon Bedrock werden Ihre Inhalte nicht zur Verbesserung der Basismodelle verwendet und nicht an Drittanbieter von Modellen weitergegeben. Ihre Daten in Amazon Bedrock werden während der Übertragung und im Ruhezustand immer verschlüsselt, und Sie können Ressourcen optional mit Ihren eigenen Schlüsseln verschlüsseln. Sie können verwenden AWS PrivateLink mit Amazon Bedrock, um private Konnektivität zwischen Ihren FMs und Ihrer VPC herzustellen, ohne Ihren Datenverkehr dem Internet auszusetzen. Mit Wissensdatenbanken für Amazon Bedrockkönnen Sie FMs und Agenten Kontextinformationen aus den privaten Datenquellen Ihres Unternehmens zur Verfügung stellen, damit RAG relevantere, genauere und individuellere Antworten liefern kann. Sie können FMs über eine visuelle Schnittstelle privat mit Ihren eigenen Daten anpassen, ohne Code schreiben zu müssen. Als vollständig verwalteter Service bietet Amazon Bedrock eine unkomplizierte Entwicklererfahrung für die Zusammenarbeit mit einer breiten Palette leistungsstarker FMs.
Gestartet in 2017, Amazon Sage Maker ist ein vollständig verwalteter Dienst, der das Erstellen, Trainieren und Bereitstellen von ML-Modellen unkompliziert macht. Immer mehr Kunden erstellen ihre eigenen FMs mit SageMaker, darunter Stability AI, AI21 Labs, Hugging Face, Perplexity AI, Hippocratic AI, LG AI Research und Technology Innovation Institute. Damit Sie schnell loslegen können, Amazon SageMaker-JumpStart bietet einen ML-Hub, in dem Sie eine große Auswahl öffentlicher FMs erkunden, trainieren und einsetzen können, wie z. B. Mistral-Modelle, LightOn-Modelle, RedPajama, Mosiac MPT-7B, FLAN-T5/UL2, GPT-J-6B/Neox-20B und Bloom/BloomZ unter Verwendung speziell entwickelter SageMaker-Tools wie Experimente und Pipelines.
Gängige generative KI-Ansätze
In diesem Abschnitt diskutieren wir gängige Ansätze zur Implementierung effektiver generativer KI-Lösungen. Wir erforschen beliebte Prompt-Engineering-Techniken, die es Ihnen ermöglichen, mit FMs komplexere und interessantere Aufgaben zu lösen. Wir diskutieren auch, wie Techniken wie RAG und Modellanpassung die Fähigkeiten von FMs weiter verbessern und Herausforderungen wie begrenzte Daten und Rechenbeschränkungen überwinden können. Mit der richtigen Technik können Sie leistungsstarke und wirkungsvolle generative KI-Lösungen entwickeln.
Schnelles Engineering
Unter Prompt Engineering versteht man die sorgfältige Gestaltung von Eingabeaufforderungen, um die Fähigkeiten von FMs effizient zu nutzen. Dabei werden Eingabeaufforderungen verwendet, bei denen es sich um kurze Textabschnitte handelt, die das Modell anleiten, genauere und relevantere Antworten zu generieren. Durch schnelles Engineering können Sie die Leistung von FMs verbessern und sie für eine Vielzahl von Anwendungen effektiver machen. In diesem Abschnitt untersuchen wir Techniken wie Zero-Shot- und Few-Shot-Prompting, das FMs mit nur wenigen Beispielen schnell an neue Aufgaben anpasst, und Chain-of-Thought-Prompting, das komplexe Überlegungen in Zwischenschritte zerlegt. Diese Methoden zeigen, wie schnelles Engineering FMs bei komplexen Aufgaben effektiver machen kann, ohne dass eine Neuschulung des Modells erforderlich ist.
Zero-Shot-Eingabeaufforderung
Bei einer Zero-Shot-Prompt-Technik müssen FMs eine Antwort generieren, ohne explizite Beispiele für das gewünschte Verhalten bereitzustellen, und sich ausschließlich auf das Vortraining verlassen. Der folgende Screenshot zeigt ein Beispiel einer Zero-Shot-Eingabeaufforderung mit dem Anthropic Claude 2.1-Modell auf der Amazon Bedrock-Konsole.
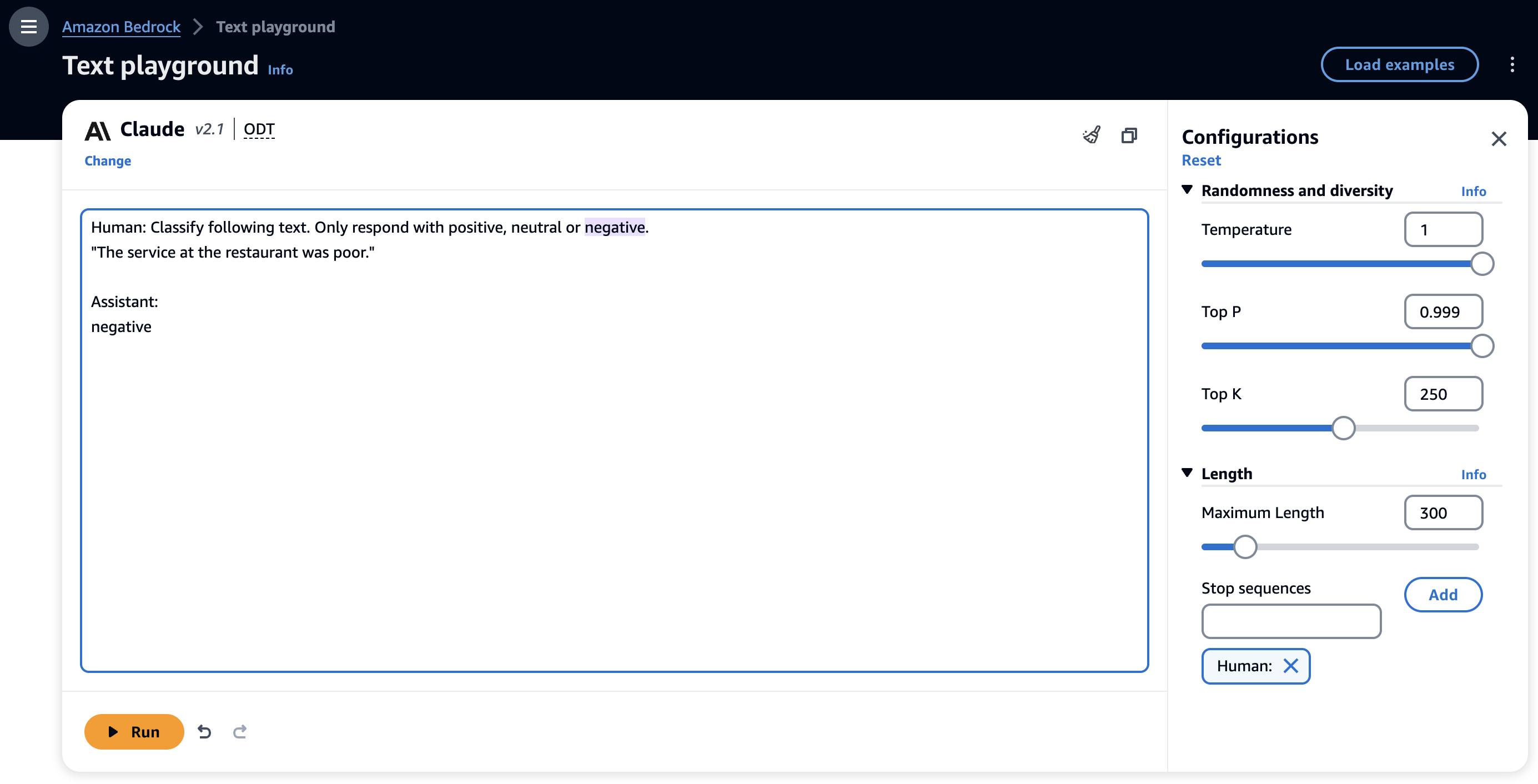
In dieser Anleitung haben wir keine Beispiele angegeben. Das Modell kann jedoch die Aufgabe verstehen und eine entsprechende Ausgabe generieren. Zero-Shot-Eingabeaufforderungen sind die einfachste Eingabeaufforderungstechnik für die Bewertung eines FM für Ihren Anwendungsfall. Obwohl FMs mit Zero-Shot-Eingabeaufforderungen bemerkenswert sind, liefern sie bei komplexeren Aufgaben möglicherweise nicht immer genaue oder gewünschte Ergebnisse. Wenn Zero-Shot-Eingabeaufforderungen nicht ausreichen, wird empfohlen, in der Eingabeaufforderung einige Beispiele anzugeben (Few-Shot-Eingabeaufforderungen).
Eingabeaufforderung für wenige Schüsse
Die Few-Shot-Prompt-Technik ermöglicht es FMs, im Kontext anhand der Beispiele in den Prompts zu lernen und die Aufgabe genauer auszuführen. Mit nur wenigen Beispielen können Sie FMs ohne großen Trainingsaufwand schnell an neue Aufgaben anpassen und sie zum gewünschten Verhalten führen. Im Folgenden finden Sie ein Beispiel für eine Eingabeaufforderung mit wenigen Schüssen mit dem Cohere Command-Modell auf der Amazon Bedrock-Konsole.
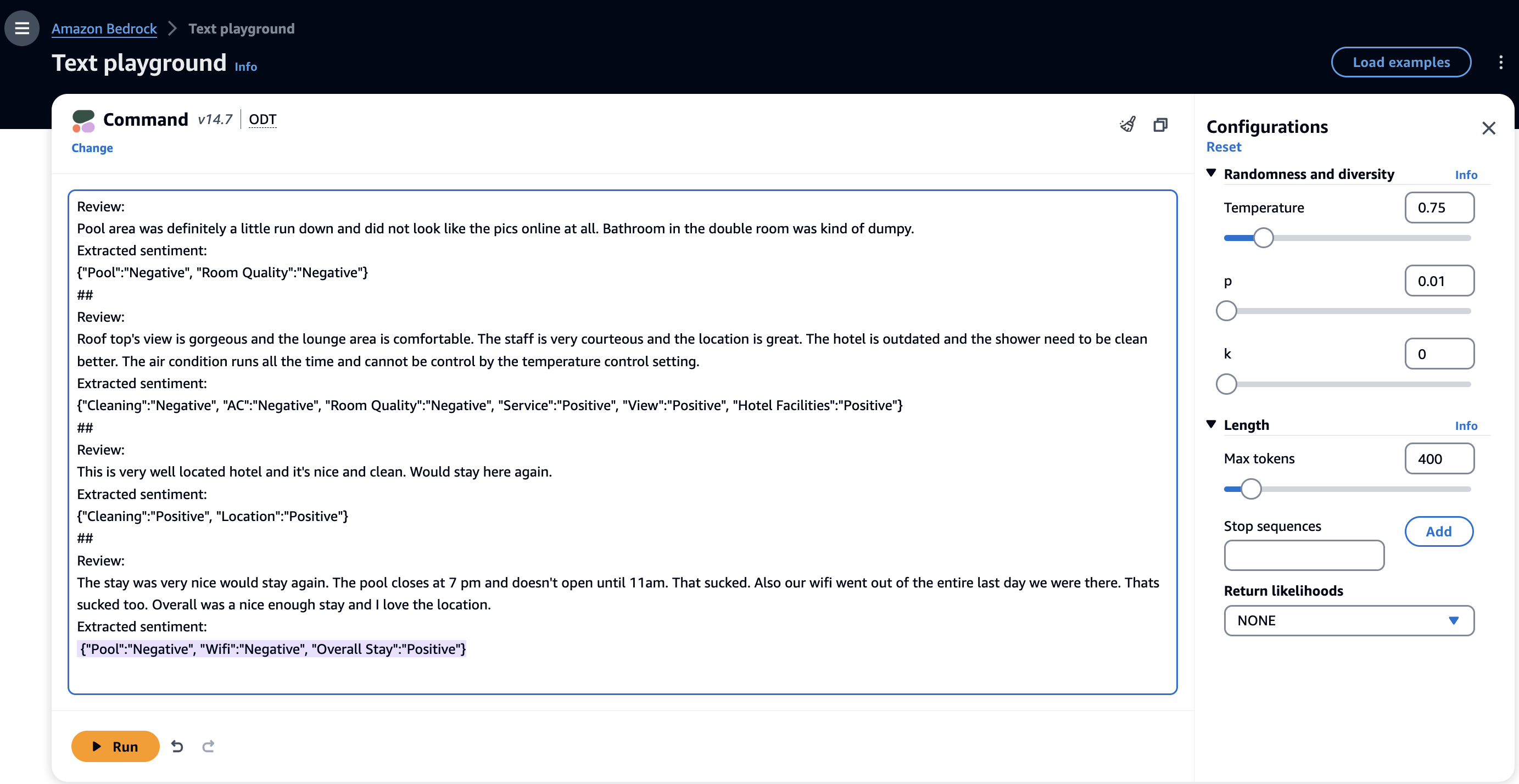
Im vorherigen Beispiel war der FM in der Lage, Entitäten aus dem Eingabetext (Rezensionen) zu identifizieren und die zugehörigen Stimmungen zu extrahieren. Wenige Eingabeaufforderungen sind eine effektive Möglichkeit, komplexe Aufgaben zu bewältigen, indem sie einige Beispiele für Eingabe-Ausgabe-Paare bereitstellen. Für einfache Aufgaben können Sie ein Beispiel (1-Schuss) angeben, während Sie für schwierigere Aufgaben drei (3-Schuss) bis fünf (5-Schuss) Beispiele angeben sollten. Min et al. (2022) veröffentlichte Erkenntnisse zum kontextbezogenen Lernen, die die Leistung der Few-Shot-Prompting-Technik verbessern können. Sie können Fow-Shot-Prompting für eine Vielzahl von Aufgaben verwenden, z. B. Stimmungsanalyse, Entitätserkennung, Beantwortung von Fragen, Übersetzung und Codegenerierung.
Aufforderung zur Gedankenkette
Trotz seines Potenzials weist die Eingabeaufforderung mit wenigen Schüssen Einschränkungen auf, insbesondere bei der Bearbeitung komplexer Denkaufgaben (z. B. arithmetischer oder logischer Aufgaben). Für diese Aufgaben ist es erforderlich, das Problem in Schritte zu zerlegen und dann zu lösen. Wei et al. (2022) führte die Chain-of-Thought (CoT)-Prompting-Technik ein, um komplexe Denkprobleme durch Zwischenschritte des Denkens zu lösen. Sie können CoT mit der Eingabeaufforderung mit wenigen Schüssen kombinieren, um die Ergebnisse bei komplexen Aufgaben zu verbessern. Im Folgenden finden Sie ein Beispiel für eine Argumentationsaufgabe, bei der CoT-Eingabeaufforderungen mit wenigen Schüssen mit dem Anthropic Claude 2-Modell auf der Amazon Bedrock-Konsole verwendet werden.

Kojima et al. (2022) führte eine Idee des Zero-Shot-CoT ein, indem es die ungenutzten Zero-Shot-Fähigkeiten von FMs nutzte. Ihre Untersuchungen deuten darauf hin, dass Zero-Shot-CoT unter Verwendung der gleichen Single-Prompt-Vorlage die Zero-Shot-FM-Leistungen bei verschiedenen Benchmark-Argumentationsaufgaben deutlich übertrifft. Sie können die Zero-Shot-CoT-Eingabeaufforderung für einfache Argumentationsaufgaben verwenden, indem Sie „Lass uns Schritt für Schritt denken“ zur ursprünglichen Eingabeaufforderung hinzufügen.
Reagieren
CoT-Eingabeaufforderungen können die Denkfähigkeiten von FMs verbessern, hängen jedoch immer noch vom internen Wissen des Modells ab und berücksichtigen keine externe Wissensbasis oder Umgebung, um weitere Informationen zu sammeln, was zu Problemen wie Halluzinationen führen kann. Der ReAct-Ansatz (Reasoning and Acting) schließt diese Lücke, indem er CoT erweitert und dynamisches Denken mithilfe einer externen Umgebung (wie Wikipedia) ermöglicht.
Integration
FMs sind in der Lage, Fragen zu verstehen und mithilfe ihres vorab trainierten Wissens Antworten zu geben. Ihnen fehlt jedoch die Fähigkeit, auf Anfragen zu reagieren, die Zugriff auf die privaten Daten einer Organisation erfordern, oder die Fähigkeit, Aufgaben autonom auszuführen. RAG und Agenten sind Methoden, um diese generativen KI-gestützten Anwendungen mit Unternehmensdatensätzen zu verbinden und sie in die Lage zu versetzen, Antworten zu geben, die organisatorische Informationen berücksichtigen und die Ausführung von Aktionen basierend auf Anfragen ermöglichen.
Augmented Generation abrufen
Mit Retrieval Augmented Generation (RAG) können Sie die Antworten eines Modells anpassen, wenn das Modell neues Wissen oder aktuelle Informationen berücksichtigen soll. Wenn sich Ihre Daten häufig ändern, z. B. Inventar oder Preise, ist es nicht praktikabel, das Modell zu optimieren und zu aktualisieren, während es Benutzeranfragen bedient. Um das FM mit aktuellen proprietären Informationen auszustatten, greifen Unternehmen auf RAG zurück, eine Technik, bei der Daten aus Unternehmensdatenquellen abgerufen und die Eingabeaufforderung mit diesen Daten angereichert werden, um relevantere und genauere Antworten zu liefern.
Es gibt mehrere Anwendungsfälle, in denen RAG zur Verbesserung der FM-Leistung beitragen kann:
- Frage beantworten – RAG-Modelle helfen Frage-Antwort-Anwendungen dabei, Informationen aus Dokumenten oder Wissensquellen zu finden und zu integrieren, um qualitativ hochwertige Antworten zu generieren. Beispielsweise könnte eine Anwendung zur Beantwortung von Fragen Passagen zu einem Thema abrufen, bevor eine zusammenfassende Antwort generiert wird.
- Chatbots und Konversationsagenten – RAG ermöglichen Chatbots den Zugriff auf relevante Informationen aus großen externen Wissensquellen. Dadurch werden die Antworten des Chatbots sachkundiger und natürlicher.
- Schreibhilfe – RAG kann relevante Inhalte, Fakten und Gesprächsthemen vorschlagen, um Ihnen beim effizienteren Verfassen von Dokumenten wie Artikeln, Berichten und E-Mails zu helfen. Die abgerufenen Informationen liefern nützliche Kontexte und Ideen.
- Zusammenfassung – RAG kann relevante Quelldokumente, Passagen oder Fakten finden, um das Verständnis eines Zusammenfassungsmodells für ein Thema zu erweitern und so bessere Zusammenfassungen zu erstellen.
- Kreatives Schreiben und Geschichtenerzählen – RAG kann Handlungsideen, Charaktere, Schauplätze und kreative Elemente aus vorhandenen Geschichten ziehen, um KI-Modelle zur Story-Generierung zu inspirieren. Dadurch wird die Ausgabe interessanter und fundierter.
- Übersetzungen – RAG kann Beispiele dafür finden, wie bestimmte Phrasen zwischen Sprachen übersetzt werden. Dies stellt Kontext für das Übersetzungsmodell bereit und verbessert die Übersetzung mehrdeutiger Phrasen.
- Personalisierung – In Chatbots und Empfehlungsanwendungen kann RAG persönlichen Kontext wie vergangene Gespräche, Profilinformationen und Präferenzen abrufen, um Antworten personalisierter und relevanter zu gestalten.
Die Verwendung eines RAG-Frameworks bietet mehrere Vorteile:
- Reduzierte Halluzinationen – Das Abrufen relevanter Informationen trägt dazu bei, den generierten Text auf Fakten und realem Wissen zu verankern, anstatt Text zu halluzinieren. Dies fördert genauere, sachlichere und vertrauenswürdigere Antworten.
- Abdeckung – Der Abruf ermöglicht es einem FM, über seine Trainingsdaten hinaus ein breiteres Spektrum an Themen und Szenarien abzudecken, indem er externe Informationen einbezieht. Dies hilft, Probleme mit der begrenzten Abdeckung zu lösen.
- Effizienz – Durch den Abruf kann das Modell seine Generierung auf die relevantesten Informationen konzentrieren, anstatt alles von Grund auf neu zu generieren. Dies verbessert die Effizienz und ermöglicht die Nutzung größerer Kontexte.
- Sicherheit – Das Abrufen der Informationen aus erforderlichen und zulässigen Datenquellen kann die Governance und Kontrolle über die Generierung schädlicher und ungenauer Inhalte verbessern. Dies unterstützt eine sicherere Einführung.
- Skalierbarkeit – Das Indizieren und Abrufen aus großen Korpora ermöglicht eine bessere Skalierung des Ansatzes im Vergleich zur Verwendung des gesamten Korpus während der Generierung. Dies ermöglicht Ihnen die Einführung von FMs in Umgebungen mit stärker eingeschränkten Ressourcen.
RAG liefert qualitativ hochwertige Ergebnisse, da der anwendungsfallspezifische Kontext direkt aus vektorisierten Datenspeichern erweitert wird. Verglichen mit Prompt Engineering führt es zu erheblich besseren Ergebnissen und einem deutlich geringeren Risiko für Halluzinationen. Mit können Sie RAG-basierte Anwendungen auf Ihren Unternehmensdaten erstellen Amazon Kendra. RAG weist eine höhere Komplexität auf als Prompt Engineering, da für die Implementierung dieser Lösung Programmier- und Architekturkenntnisse erforderlich sind. Allerdings bieten Knowledge Bases für Amazon Bedrock ein vollständig verwaltetes RAG-Erlebnis und die einfachste Möglichkeit, mit RAG in Amazon Bedrock zu beginnen. Knowledge Bases für Amazon Bedrock automatisiert den End-to-End-RAG-Workflow, einschließlich Aufnahme, Abruf und prompter Erweiterung, sodass Sie keinen benutzerdefinierten Code schreiben müssen, um Datenquellen zu integrieren und Abfragen zu verwalten. Die Sitzungskontextverwaltung ist integriert, sodass Ihre App Konversationen mit mehreren Runden unterstützen kann. Antworten in der Wissensdatenbank enthalten Quellenangaben, um die Transparenz zu verbessern und Halluzinationen zu minimieren. Der einfachste Weg, einen generativ-KI-gestützten Assistenten zu erstellen, ist die Verwendung von Amazon Q, das über ein integriertes RAG-System verfügt.
RAG verfügt über ein Höchstmaß an Flexibilität, wenn es um Änderungen in der Architektur geht. Sie können das Einbettungsmodell, den Vektorspeicher und FM unabhängig voneinander ändern, mit minimalen bis mäßigen Auswirkungen auf andere Komponenten. Erfahren Sie mehr über den RAG-Ansatz mit Amazon OpenSearch-Dienst und Amazon Bedrock, siehe Erstellen Sie skalierbare und serverlose RAG-Workflows mit einer Vektor-Engine für die Modelle Amazon OpenSearch Serverless und Amazon Bedrock Claude. Weitere Informationen zur Implementierung von RAG mit Amazon Kendra finden Sie unter Nutzen Sie die Leistungsfähigkeit von Unternehmensdaten mit generativer KI: Erkenntnisse von Amazon Kendra, LangChain und großen Sprachmodellen.
Mitarbeiter
FMs können Anfragen basierend auf ihrem vorab trainierten Wissen verstehen und beantworten. Allerdings sind sie nicht in der Lage, reale Aufgaben wie die Buchung eines Fluges oder die Bearbeitung einer Bestellung alleine zu erledigen. Dies liegt daran, dass für solche Aufgaben organisationsspezifische Daten und Arbeitsabläufe erforderlich sind, die normalerweise eine individuelle Programmierung erfordern. Frameworks wie LangChain und bestimmte FMs wie Claude-Modelle bieten Funktionsaufruffunktionen für die Interaktion mit APIs und Tools. Jedoch, Agenten für Amazon Bedrock, eine neue und vollständig verwaltete KI-Funktion von AWS, soll es Entwicklern einfacher machen, Anwendungen mit FMs der nächsten Generation zu erstellen. Mit nur wenigen Klicks können Aufgaben automatisch aufgeschlüsselt und die erforderliche Orchestrierungslogik generiert werden, ohne dass manuelle Codierung erforderlich ist. Agenten können über APIs eine sichere Verbindung zu Unternehmensdatenbanken herstellen, die Daten für die Maschinennutzung erfassen und strukturieren und sie mit kontextbezogenen Details ergänzen, um genauere Antworten zu generieren und Anfragen zu erfüllen. Da Agents for Amazon Bedrock die Integration und Infrastruktur übernimmt, können Sie generative KI vollständig für geschäftliche Anwendungsfälle nutzen. Entwickler können sich jetzt auf ihre Kernanwendungen konzentrieren und müssen sich nicht mehr um Routinearbeiten kümmern. Die automatisierte Datenverarbeitung und der API-Aufruf ermöglichen es FM außerdem, aktualisierte, maßgeschneiderte Antworten zu liefern und tatsächliche Aufgaben mithilfe proprietären Wissens auszuführen.
Modellanpassung
Foundation-Modelle sind äußerst leistungsfähig und ermöglichen einige großartige Anwendungen, aber was Ihnen dabei helfen wird, Ihr Geschäft voranzutreiben, ist generative KI, die weiß, was für Ihre Kunden, Ihre Produkte und Ihr Unternehmen wichtig ist. Und das ist nur möglich, wenn Sie Modelle mit Ihren Daten aufladen. Daten sind der Schlüssel zum Übergang von generischen Anwendungen zu maßgeschneiderten generativen KI-Anwendungen, die einen echten Mehrwert für Ihre Kunden und Ihr Unternehmen schaffen.
In diesem Abschnitt besprechen wir verschiedene Techniken und Vorteile der Anpassung Ihrer FMs. Wir behandeln, wie die Modellanpassung weiteres Training und die Änderung der Gewichte des Modells umfasst, um seine Leistung zu verbessern.
Feintuning
Unter Feinabstimmung versteht man den Prozess, bei dem ein vorab trainiertes FM, wie z. B. Llama 2, für eine nachgelagerte Aufgabe mit einem für diese Aufgabe spezifischen Datensatz weiter trainiert wird. Das vorab trainierte Modell stellt allgemeines Sprachwissen bereit und ermöglicht durch Feinabstimmung die Spezialisierung und Verbesserung der Leistung auf eine bestimmte Aufgabe wie Textklassifizierung, Beantwortung von Fragen oder Textgenerierung. Bei der Feinabstimmung stellen Sie beschriftete Datensätze bereit, die mit zusätzlichem Kontext versehen sind, um das Modell für bestimmte Aufgaben zu trainieren. Anschließend können Sie die Modellparameter für die spezifische Aufgabe basierend auf Ihrem Geschäftskontext anpassen.
Mit können Sie Feinabstimmungen an FMs vornehmen Amazon SageMaker-JumpStart und Amazonas-Grundgestein. Weitere Einzelheiten finden Sie unter Stellen Sie Basismodelle in Amazon SageMaker JumpStart mit zwei Codezeilen bereit und optimieren Sie sie und Passen Sie Modelle in Amazon Bedrock mit Ihren eigenen Daten durch Feinabstimmung und kontinuierliches Vortraining an.
Fortsetzung des Vortrainings
Durch fortgesetztes Vortraining in Amazon Bedrock können Sie einem zuvor trainierten Modell zusätzliche Daten beibringen, die seinen Originaldaten ähneln. Dadurch kann das Modell allgemeinere sprachliche Kenntnisse erlangen, anstatt sich auf eine einzelne Anwendung zu konzentrieren. Durch fortlaufendes Vortraining können Sie Ihre unbeschrifteten Datensätze oder Rohdaten verwenden, um die Genauigkeit des Basismodells für Ihre Domäne durch Optimierung der Modellparameter zu verbessern. Beispielsweise kann ein Gesundheitsunternehmen sein Modell weiterhin vorab mithilfe medizinischer Fachzeitschriften, Artikel und Forschungsarbeiten trainieren, um sich besser mit der Branchenterminologie vertraut zu machen. Weitere Einzelheiten finden Sie unter Amazon Bedrock-Entwicklererfahrung.
Vorteile der Modellanpassung
Die Modellanpassung bietet mehrere Vorteile und kann Organisationen bei Folgendem helfen:
- Domänenspezifische Anpassung – Sie können ein Allzweck-FM verwenden und es dann anhand von Daten aus einem bestimmten Bereich (z. B. Biomedizin, Recht oder Finanzen) weiter trainieren. Dadurch wird das Modell an das Vokabular, den Stil usw. dieser Domäne angepasst.
- Aufgabenspezifische Feinabstimmung – Sie können ein vorab trainiertes FM verwenden und es anhand von Daten für eine bestimmte Aufgabe (z. B. Stimmungsanalyse oder Beantwortung von Fragen) verfeinern. Dadurch wird das Modell auf die jeweilige Aufgabe spezialisiert.
- Personalisierung – Sie können ein FM anhand der Daten einer Person (E-Mails, Texte, von ihr verfasste Dokumente) anpassen, um das Modell an ihren einzigartigen Stil anzupassen. Dies kann personalisiertere Anwendungen ermöglichen.
- Ressourcenarme Sprachoptimierung – Sie können nur die obersten Schichten eines mehrsprachigen FM in einer ressourcenarmen Sprache neu trainieren, um es besser an diese Sprache anzupassen.
- Mängel beheben – Wenn bestimmte unbeabsichtigte Verhaltensweisen in einem Modell entdeckt werden, kann die Anpassung entsprechender Daten dabei helfen, das Modell zu aktualisieren, um diese Fehler zu reduzieren.
Die Modellanpassung hilft dabei, die folgenden Herausforderungen bei der FM-Einführung zu meistern:
- Anpassung an neue Domänen und Aufgaben – FMs, die vorab auf allgemeine Textkorpora trainiert wurden, müssen häufig auf aufgabenspezifische Daten abgestimmt werden, um für nachgelagerte Anwendungen gut zu funktionieren. Durch die Feinabstimmung wird das Modell an neue Domänen oder Aufgaben angepasst, für die es ursprünglich nicht trainiert wurde.
- Voreingenommenheit überwinden – FMs können Verzerrungen gegenüber ihren ursprünglichen Trainingsdaten aufweisen. Durch die Anpassung eines Modells an neue Daten können unerwünschte Verzerrungen in den Modellausgaben reduziert werden.
- Verbesserung der Recheneffizienz – Vorab trainierte FMs sind oft sehr groß und rechenintensiv. Die Modellanpassung kann eine Verkleinerung des Modells durch Beschneiden unwichtiger Parameter ermöglichen und so die Bereitstellung einfacher machen.
- Umgang mit begrenzten Zieldaten – In einigen Fällen sind für die Zielaufgabe nur begrenzte reale Daten verfügbar. Die Modellanpassung nutzt die vorab trainierten Gewichte, die in größeren Datensätzen gelernt wurden, um diese Datenknappheit zu überwinden.
- Verbesserung der Aufgabenleistung – Eine Feinabstimmung verbessert fast immer die Leistung bei Zielaufgaben im Vergleich zur Verwendung der ursprünglich vorab trainierten Gewichte. Durch diese Optimierung des Modells für den vorgesehenen Verwendungszweck können Sie FMs erfolgreich in realen Anwendungen einsetzen.
Die Modellanpassung ist komplexer als Prompt Engineering und RAG, da Gewicht und Parameter des Modells über Tuning-Skripte geändert werden, was Datenwissenschaft und ML-Kenntnisse erfordert. Amazon Bedrock macht es jedoch unkompliziert, indem es Ihnen eine verwaltete Erfahrung zum Anpassen von Modellen bietet Feintuning or Fortsetzung der Vorschulung. Die Modellanpassung liefert hochpräzise Ergebnisse mit vergleichbarer Qualitätsausgabe wie RAG. Da Sie Modellgewichtungen für domänenspezifische Daten aktualisieren, erzeugt das Modell kontextbezogenere Antworten. Im Vergleich zu RAG kann die Qualität je nach Anwendungsfall geringfügig besser sein. Daher ist es wichtig, eine Kompromissanalyse zwischen den beiden Techniken durchzuführen. Sie können RAG möglicherweise mit einem benutzerdefinierten Modell implementieren.
Umschulung oder Ausbildung von Grund auf
Der Aufbau Ihres eigenen grundlegenden KI-Modells, anstatt nur vorab trainierte öffentliche Modelle zu verwenden, ermöglicht eine bessere Kontrolle, verbesserte Leistung und Anpassung an die spezifischen Anwendungsfälle und Daten Ihres Unternehmens. Die Investition in die Erstellung eines maßgeschneiderten FM kann eine bessere Anpassungsfähigkeit, Upgrades und Kontrolle über die Funktionen ermöglichen. Verteiltes Training ermöglicht die erforderliche Skalierbarkeit, um sehr große FMs auf riesigen Datensätzen auf vielen Maschinen zu trainieren. Diese Parallelisierung macht Modelle mit Hunderten Milliarden Parametern möglich, die auf Billionen Token trainiert wurden. Größere Modelle verfügen über eine größere Lern- und Verallgemeinerungsfähigkeit.
Ein Training von Grund auf kann qualitativ hochwertige Ergebnisse liefern, da das Modell von Grund auf auf anwendungsfallspezifischen Daten trainiert, die Wahrscheinlichkeit einer Halluzination gering ist und die Genauigkeit der Ausgabe zu den höchsten gehören kann. Wenn sich Ihr Datensatz jedoch ständig weiterentwickelt, kann es immer noch zu Halluzinationsproblemen kommen. Eine Schulung von Grund auf ist mit der höchsten Implementierungskomplexität und den höchsten Kosten verbunden. Es erfordert den größten Aufwand, da es das Sammeln großer Datenmengen, deren Kuratierung und Verarbeitung sowie die Schulung eines ziemlich großen FM erfordert, was fundierte Datenwissenschafts- und ML-Kenntnisse erfordert. Dieser Ansatz ist zeitaufwändig (normalerweise kann er Wochen bis Monate dauern).
Sie sollten darüber nachdenken, ein FM von Grund auf zu trainieren, wenn keiner der anderen Ansätze für Sie funktioniert und Sie die Möglichkeit haben, ein FM mit einer großen Menge gut kuratierter tokenisierter Daten, einem anspruchsvollen Budget und einem Team hochqualifizierter ML-Experten aufzubauen . AWS bietet die fortschrittlichste Cloud-Infrastruktur zum Trainieren und Ausführen von LLMs und anderen FMs, die auf GPUs und dem speziell entwickelten ML-Trainingschip basieren. AWS-Trainingund ML-Inferenzbeschleuniger, AWS-Inferenz. Weitere Informationen zum Training von LLMs auf SageMaker finden Sie unter Training großer Sprachmodelle auf Amazon SageMaker: Best Practices und SageMaker HyperPod.
Auswahl des richtigen Ansatzes für die Entwicklung generativer KI-Anwendungen
Bei der Entwicklung generativer KI-Anwendungen müssen Unternehmen mehrere Schlüsselfaktoren sorgfältig abwägen, bevor sie das für ihre Anforderungen am besten geeignete Modell auswählen. Eine Vielzahl von Aspekten sollte berücksichtigt werden, wie z. B. Kosten (um sicherzustellen, dass das ausgewählte Modell den Budgetbeschränkungen entspricht), Qualität (um kohärente und sachlich korrekte Ergebnisse zu liefern), nahtlose Integration in aktuelle Unternehmensplattformen und Arbeitsabläufe sowie die Reduzierung von Halluzinationen oder der Erzeugung falscher Informationen . Da viele Optionen zur Verfügung stehen, können Unternehmen sich die Zeit nehmen, diese Aspekte gründlich zu bewerten. Dies wird Unternehmen dabei helfen, das generative KI-Modell auszuwählen, das ihren spezifischen Anforderungen und Prioritäten am besten entspricht. Folgende Faktoren sollten Sie genau prüfen:
- Integration mit Unternehmenssystemen – Damit FMs im Unternehmenskontext wirklich nützlich sind, müssen sie sich in bestehende Geschäftssysteme und Arbeitsabläufe integrieren und mit ihnen interagieren. Dies kann den Zugriff auf Daten aus Datenbanken, Enterprise Resource Planning (ERP) und Customer Relationship Management (CRM) sowie das Auslösen von Aktionen und Workflows umfassen. Ohne ordnungsgemäße Integration besteht die Gefahr, dass das FM ein isoliertes Tool ist. Unternehmenssysteme wie ERP enthalten wichtige Geschäftsdaten (Kunden, Produkte, Bestellungen). Das FM muss mit diesen Systemen verbunden sein, um Unternehmensdaten nutzen zu können, anstatt seinen eigenen Wissensgraphen abzuarbeiten, der möglicherweise ungenau oder veraltet ist. Dies gewährleistet Genauigkeit und eine einzige Quelle der Wahrheit.
- Halluzinationen – Von Halluzinationen spricht man, wenn eine KI-Anwendung falsche Informationen generiert, die sachlich erscheinen. Diese müssen sorgfältig angegangen werden, bevor FMs weit verbreitet werden. Beispielsweise könnte ein medizinischer Chatbot, der Diagnosevorschläge machen soll, Details über die Symptome oder die Krankengeschichte eines Patienten halluzinieren und ihn so dazu verleiten, eine ungenaue Diagnose vorzuschlagen. Die Verhinderung schädlicher Halluzinationen wie dieser durch technische Lösungen und die Pflege von Datensätzen wird von entscheidender Bedeutung sein, um sicherzustellen, dass diese FMs für sensible Anwendungen wie Gesundheitswesen, Finanzen und Recht vertrauenswürdig sind. Gründliche Tests und Transparenz über die Trainingsdaten eines FM und verbleibende Mängel müssen den Einsatz begleiten.
- Fähigkeiten und Ressourcen – Die erfolgreiche Einführung von FMs wird stark davon abhängen, dass man über die richtigen Fähigkeiten und Ressourcen verfügt, um die Technologie effektiv zu nutzen. Unternehmen benötigen Mitarbeiter mit ausgeprägten technischen Fähigkeiten, um FMs entsprechend ihren spezifischen Anforderungen ordnungsgemäß zu implementieren, anzupassen und zu warten. Sie benötigen außerdem umfangreiche Rechenressourcen wie fortschrittliche Hardware und Cloud-Computing-Funktionen, um komplexe FMs auszuführen. Beispielsweise benötigt ein Marketingteam, das ein FM zum Erstellen von Werbetexten und Social-Media-Beiträgen verwenden möchte, qualifizierte Ingenieure, um das System zu integrieren, Kreative, die Eingabeaufforderungen bereitstellen und die Ausgabequalität bewerten, sowie ausreichend Cloud-Computing-Leistung, um das Modell kosteneffizient bereitzustellen. Durch Investitionen in die Entwicklung von Fachwissen und technischer Infrastruktur können Unternehmen durch den Einsatz von FMs einen echten Geschäftswert erzielen.
- Ausgabequalität – Die Qualität der von FMs produzierten Ergebnisse wird entscheidend für deren Akzeptanz und Nutzung sein, insbesondere bei verbraucherorientierten Anwendungen wie Chatbots. Wenn von FMs betriebene Chatbots Antworten liefern, die ungenau, unsinnig oder unangemessen sind, werden Benutzer schnell frustriert und hören auf, sich mit ihnen zu beschäftigen. Daher müssen Unternehmen, die Chatbots einsetzen möchten, die FMs, die sie antreiben, gründlich testen, um sicherzustellen, dass sie konsistent qualitativ hochwertige Antworten generieren, die hilfreich, relevant und angemessen sind, um eine gute Benutzererfahrung zu bieten. Die Ausgabequalität umfasst Faktoren wie Relevanz, Genauigkeit, Kohärenz und Angemessenheit, die alle zur allgemeinen Benutzerzufriedenheit beitragen und über die Einführung von FMs, wie sie für Chatbots verwendet werden, entscheiden.
- Kosten – Die hohe Rechenleistung, die zum Trainieren und Ausführen großer KI-Modelle wie FMs erforderlich ist, kann erhebliche Kosten verursachen. Vielen Unternehmen fehlen möglicherweise die finanziellen Ressourcen oder die Cloud-Infrastruktur, die für die Nutzung solch umfangreicher Modelle erforderlich sind. Darüber hinaus erhöht die Integration und Anpassung von FMs für bestimmte Anwendungsfälle die Engineering-Kosten. Die erheblichen Kosten, die für den Einsatz von FMs erforderlich sind, könnten eine breite Akzeptanz verhindern, insbesondere bei kleineren Unternehmen und Start-ups mit begrenzten Budgets. Die Bewertung des potenziellen Return on Investment und die Abwägung von Kosten und Nutzen von FMs ist für Unternehmen, die deren Anwendung und Nutzen abwägen, von entscheidender Bedeutung. Kosteneffizienz wird wahrscheinlich ein entscheidender Faktor bei der Entscheidung sein, ob und wie diese leistungsstarken, aber ressourcenintensiven Modelle sinnvoll eingesetzt werden können.
Designentscheidung
Wie wir in diesem Beitrag besprochen haben, sind derzeit viele verschiedene KI-Techniken verfügbar, wie z. B. Prompt Engineering, RAG und Modellanpassung. Diese große Auswahl macht es für Unternehmen schwierig, den optimalen Ansatz für ihren speziellen Anwendungsfall zu finden. Die Auswahl der richtigen Techniken hängt von verschiedenen Faktoren ab, darunter dem Zugriff auf externe Datenquellen, Echtzeit-Datenfeeds und der Domänenspezifität der beabsichtigten Anwendung. Um die Ermittlung der am besten geeigneten Technik basierend auf dem Anwendungsfall und den damit verbundenen Überlegungen zu erleichtern, gehen wir das folgende Flussdiagramm durch, das Empfehlungen für die Anpassung spezifischer Anforderungen und Einschränkungen mit geeigneten Methoden enthält.

Um ein klares Verständnis zu erlangen, gehen wir das Flussdiagramm der Designentscheidung anhand einiger anschaulicher Beispiele durch:
- Unternehmenssuche – Ein Mitarbeiter möchte bei seiner Organisation Urlaub beantragen. Um eine Antwort zu geben, die mit den Personalrichtlinien der Organisation übereinstimmt, benötigt der FM mehr Kontext, der über seine eigenen Kenntnisse und Fähigkeiten hinausgeht. Insbesondere benötigt das FM Zugriff auf externe Datenquellen, die relevante HR-Richtlinien und -Richtlinien bereitstellen. Angesichts dieses Szenarios einer Mitarbeiteranfrage, die den Verweis auf externe domänenspezifische Daten erfordert, ist der empfohlene Ansatz gemäß dem Flussdiagramm ein promptes Engineering mit RAG. RAG wird dabei helfen, die relevanten Daten aus den externen Datenquellen als Kontext für das FM bereitzustellen.
- Unternehmenssuche mit organisationsspezifischer Ausgabe – Angenommen, Sie verfügen über technische Zeichnungen und möchten daraus die Stückliste extrahieren und die Ausgabe gemäß Industriestandards formatieren. Dazu können Sie eine Technik verwenden, die Prompt Engineering mit RAG und einem fein abgestimmten Sprachmodell kombiniert. Das fein abgestimmte Modell würde darauf trainiert, Stücklisten zu erstellen, wenn technische Zeichnungen als Eingabe vorliegen. RAG hilft dabei, die relevantesten technischen Zeichnungen aus den Datenquellen der Organisation zu finden, um sie in den Kontext für das FM einzuspeisen. Insgesamt extrahiert dieser Ansatz Stücklisten aus Konstruktionszeichnungen und strukturiert die Ausgabe entsprechend für den Konstruktionsbereich.
- Allgemeine Suche – Stellen Sie sich vor, Sie möchten die Identität des 30. Präsidenten der Vereinigten Staaten herausfinden. Sie könnten Prompt Engineering nutzen, um die Antwort von einem FM zu erhalten. Da diese Modelle auf vielen Datenquellen trainiert werden, können sie häufig genaue Antworten auf Sachfragen wie diese liefern.
- Allgemeine Suche mit aktuellen Ereignissen – Wenn Sie den aktuellen Aktienkurs für Amazon ermitteln möchten, können Sie den Ansatz des Prompt Engineering mit einem Agenten nutzen. Der Agent stellt dem FM den aktuellsten Aktienkurs zur Verfügung, damit dieser eine sachliche Antwort generieren kann.
Zusammenfassung
Generative KI bietet Unternehmen ein enormes Potenzial, Innovationen voranzutreiben und die Produktivität in einer Vielzahl von Anwendungen zu steigern. Die erfolgreiche Einführung dieser neuen KI-Technologien erfordert jedoch die Berücksichtigung wichtiger Überlegungen zu Integration, Ausgabequalität, Fähigkeiten, Kosten und potenziellen Risiken wie schädlichen Halluzinationen oder Sicherheitslücken. Organisationen müssen einen systematischen Ansatz zur Bewertung ihrer Anwendungsfallanforderungen und -beschränkungen verfolgen, um die am besten geeigneten Techniken für die Anpassung und Anwendung von FMs zu ermitteln. Wie in diesem Beitrag hervorgehoben, haben Prompt Engineering, RAG und effiziente Modellanpassungsmethoden jeweils ihre eigenen Stärken und Schwächen, die für unterschiedliche Szenarien geeignet sind. Durch die Zuordnung von Geschäftsanforderungen zu KI-Funktionen mithilfe eines strukturierten Rahmens können Unternehmen Hürden bei der Implementierung überwinden und beginnen, die Vorteile von FMs zu realisieren, während sie gleichzeitig Leitplanken für das Risikomanagement aufbauen. Mit einer durchdachten Planung, die auf Beispielen aus der Praxis basiert, können Unternehmen aller Branchen einen enormen Nutzen aus dieser neuen Welle generativer KI ziehen. Lernen generative KI auf AWS.
Über die Autoren
 Jay Rao ist Principal Solutions Architect bei AWS. Er konzentriert sich auf KI/ML-Technologien mit einem großen Interesse an generativer KI und Computer Vision. Bei AWS genießt er es, Kunden technisch und strategisch zu beraten und ihnen bei der Entwicklung und Implementierung von Lösungen zu helfen, die zu Geschäftsergebnissen führen. Er ist Buchautor (Computer Vision on AWS), veröffentlicht regelmäßig Blogs und Codebeispiele und hat Vorträge auf Technologiekonferenzen wie AWS re:Invent gehalten.
Jay Rao ist Principal Solutions Architect bei AWS. Er konzentriert sich auf KI/ML-Technologien mit einem großen Interesse an generativer KI und Computer Vision. Bei AWS genießt er es, Kunden technisch und strategisch zu beraten und ihnen bei der Entwicklung und Implementierung von Lösungen zu helfen, die zu Geschäftsergebnissen führen. Er ist Buchautor (Computer Vision on AWS), veröffentlicht regelmäßig Blogs und Codebeispiele und hat Vorträge auf Technologiekonferenzen wie AWS re:Invent gehalten.
 Babu Kariyaden Parambath ist Senior AI/ML-Spezialist bei AWS. Bei AWS arbeitet er gerne mit Kunden zusammen und hilft ihnen dabei, den richtigen Geschäftsanwendungsfall mit Geschäftswert zu identifizieren und ihn mithilfe von AWS AI/ML-Lösungen und -Services zu lösen. Bevor er zu AWS kam, war Babu ein KI-Evangelist mit 20 Jahren vielfältiger Branchenerfahrung, der KI-gesteuerten Geschäftswert für Kunden lieferte.
Babu Kariyaden Parambath ist Senior AI/ML-Spezialist bei AWS. Bei AWS arbeitet er gerne mit Kunden zusammen und hilft ihnen dabei, den richtigen Geschäftsanwendungsfall mit Geschäftswert zu identifizieren und ihn mithilfe von AWS AI/ML-Lösungen und -Services zu lösen. Bevor er zu AWS kam, war Babu ein KI-Evangelist mit 20 Jahren vielfältiger Branchenerfahrung, der KI-gesteuerten Geschäftswert für Kunden lieferte.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/best-practices-to-build-generative-ai-applications-on-aws/

