Conversational AI has come a long way in recent years thanks to the rapid developments in generative AI, especially the performance improvements of large language models (LLMs) introduced by training techniques such as instruction fine-tuning and reinforcement learning from human feedback. When prompted correctly, these models can carry coherent conversations without any task-specific training data. However, they can’t generalize well to enterprise-specific questions because, to generate an answer, they rely on the public data they were exposed to during pre-training. Such data often lacks the specialized knowledge contained in internal documents available in modern businesses, which is typically needed to get accurate answers in domains such as pharmaceutical research, financial investigation, and customer support.
To create AI assistants that are capable of having discussions grounded in specialized enterprise knowledge, we need to connect these powerful but generic LLMs to internal knowledge bases of documents. This method of enriching the LLM generation context with information retrieved from your internal data sources is called Retrieval Augmented Generation (RAG), and produces assistants that are domain specific and more trustworthy, as shown by Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Another driver behind RAG’s popularity is its ease of implementation and the existence of mature vector search solutions, such as those offered by Amazon Kendra (see Amazon Kendra launches Retrieval API) and Amazon OpenSearch Service (see k-Nearest Neighbor (k-NN) search in Amazon OpenSearch Service), among others.
However, the popular RAG design pattern with semantic search can’t answer all types of questions that are possible on documents. This is especially true for questions that require analytical reasoning across multiple documents. For example, imagine that you are planning next year’s strategy of an investment company. One essential step would be to analyze and compare the financial results and potential risks of candidate companies. This task involves answering analytical reasoning questions. For instance, the query “Give me the top 5 companies with the highest revenue in the last 2 years and identify their main risks” requires multiple steps of reasoning, some of which can use semantic search retrieval, whereas others require analytical capabilities.
In this post, we show how to design an intelligent document assistant capable of answering analytical and multi-step reasoning questions in three parts. In Part 1, we review the RAG design pattern and its limitations on analytical questions. Then we introduce you to a more versatile architecture that overcomes these limitations. Part 2 helps you dive deeper into the entity extraction pipeline used to prepare structured data, which is a key ingredient for analytical question answering. Part 3 walks you through how to use Amazon Bedrock LLMs to query that data and build an LLM agent that enhances RAG with analytical capabilities, thereby enabling you to build intelligent document assistants that can answer complex domain-specific questions across multiple documents.
Part 1: RAG limitations and solution overview
In this section, we review the RAG design pattern and discuss its limitations on analytical questions. We also present a more versatile architecture that overcomes these limitations.
Overview of RAG
RAG solutions are inspired by representation learning and semantic search ideas that have been gradually adopted in ranking problems (for example, recommendation and search) and natural language processing (NLP) tasks since 2010.
The popular approach used today is formed of three steps:
- An offline batch processing job ingests documents from an input knowledge base, splits them into chunks, creates an embedding for each chunk to represent its semantics using a pre-trained embedding model, such as Amazon Titan embedding models, then uses these embeddings as input to create a semantic search index.

- When answering a new question in real time, the input question is converted to an embedding, which is used to search for and extract the most similar chunks of documents using a similarity metric, such as cosine similarity, and an approximate nearest neighbors algorithm. The search precision can also be improved with metadata filtering.

- A prompt is constructed from the concatenation of a system message with a context that is formed of the relevant chunks of documents extracted in step 2, and the input question itself. This prompt is then presented to an LLM model to generate the final answer to the question from the context.

With the right underlying embedding model, capable of producing accurate semantic representations of the input document chunks and the input questions, and an efficient semantic search module, this solution is able to answer questions that require retrieving existent information in a database of documents. For example, if you have a service or a product, you could start by indexing its FAQ section or documentation and have an initial conversational AI tailored to your specific offering.
Limitations of RAG based on semantic search
Although RAG is an essential component in modern domain-specific AI assistants and a sensible starting point for building a conversational AI around a specialized knowledge base, it can’t answer questions that require scanning, comparing, and reasoning across all documents in your knowledge base simultaneously, especially when the augmentation is based solely on semantic search.
To understand these limitations, let’s consider again the example of deciding where to invest based on financial reports. If we were to use RAG to converse with these reports, we could ask questions such as “What are the risks that faced company X in 2022,” or “What is the net revenue of company Y in 2022?” For each of these questions, the corresponding embedding vector, which encodes the semantic meaning of the question, is used to retrieve the top-K semantically similar chunks of documents available in the search index. This is typically accomplished by employing an approximate nearest neighbors solution such as FAISS, NMSLIB, pgvector, or others, which strive to strike a balance between retrieval speed and recall to achieve real-time performance while maintaining satisfactory accuracy.
However, the preceding approach can’t accurately answer analytical questions across all documents, such as “What are the top 5 companies with the highest net revenues in 2022?”
This is because semantic search retrieval attempts to find the K most similar chunks of documents to the input question. But because none of the documents contain comprehensive summaries of revenues, it will return chunks of documents that merely contain mentions of “net revenue” and possibly “2022,” without fulfilling the essential condition of focusing on companies with the highest revenue. If we present these retrieval results to an LLM as context to answer the input question, it may formulate a misleading answer or refuse to answer, because the required correct information is missing.
These limitations come by design because semantic search doesn’t conduct a thorough scan of all embedding vectors to find relevant documents. Instead, it uses approximate nearest neighbor methods to maintain reasonable retrieval speed. A key strategy for efficiency in these methods is segmenting the embedding space into groups during indexing. This allows for quickly identifying which groups may contain relevant embeddings during retrieval, without the need for pairwise comparisons. Additionally, even traditional nearest neighbors techniques like KNN, which scan all documents, only compute basic distance metrics and aren’t suitable for the complex comparisons needed for analytical reasoning. Therefore, RAG with semantic search is not tailored for answering questions that involve analytical reasoning across all documents.
To overcome these limitations, we propose a solution that combines RAG with metadata and entity extraction, SQL querying, and LLM agents, as described in the following sections.
Overcoming RAG limitations with metadata, SQL, and LLM agents
Let’s examine more deeply a question on which RAG fails, so that we can trace back the reasoning required to answer it effectively. This analysis should point us towards the right approach that could complement RAG in the overall solution.
Consider the question: “What are the top 5 companies with the highest revenue in 2022?”
To be able to answer this question, we would need to:
- Identify the revenue for each company.
- Filter down to keep the revenues of 2022 for each of them.
- Sort the revenues in descending order.
- Slice out the top 5 revenues alongside the company names.
Typically, these analytical operations are done on structured data, using tools such as pandas or SQL engines. If we had access to a SQL table containing the columns company, revenue, and year, we could easily answer our question by running a SQL query, similar to the following example:
SELECT company, revenue FROM table_name WHERE year = 2022 ORDER BY revenue DESC LIMIT 5;Storing structured metadata in a SQL table that contains information about relevant entities enables you to answer many types of analytical questions by writing the correct SQL query. This is why we complement RAG in our solution with a real-time SQL querying module against a SQL table, populated by metadata extracted in an offline process.
But how can we implement and integrate this approach to an LLM-based conversational AI?
There are three steps to be able to add SQL analytical reasoning:
- Metadata extraction – Extract metadata from unstructured documents into a SQL table
- Text to SQL – Formulate SQL queries from input questions accurately using an LLM
- Tool selection – Identify if a question must be answered using RAG or a SQL query
To implement these steps, first we recognize that information extraction from unstructured documents is a traditional NLP task for which LLMs show promise in achieving high accuracy through zero-shot or few-shot learning. Second, the ability of these models to generate SQL queries from natural language has been proven for years, as seen in the 2020 release of Amazon QuickSight Q. Finally, automatically selecting the right tool for a specific question enhances the user experience and enables answering complex questions through multi-step reasoning. To implement this feature, we delve into LLM agents in a later section.
To summarize, the solution we propose is composed of the following core components:
- Semantic search retrieval to augment generation context
- Structured metadata extraction and querying with SQL
- An agent capable of using the right tools to answer a question
Solution overview
The following diagram depicts a simplified architecture of the solution. It helps you identify and understand the role of the core components and how they interact to implement the full LLM-assistant behavior. The numbering aligns with the order of operations when implementing this solution.

In practice, we implemented this solution as outlined in the following detailed architecture.

For this architecture, we propose an implementation on GitHub, with loosely coupled components where the backend (5), data pipelines (1, 2, 3) and front end (4) can evolve separately. This is to simplify the collaboration across competencies when customizing and improving the solution for production.
Deploy the solution
To install this solution in your AWS account, complete the following steps:
- Clone the repository on GitHub.
- Install the backend AWS Cloud Development Kit (AWS CDK) app:
- Open the
backendfolder. - Run
npm installto install the dependencies. - If you have never used the AWS CDK in the current account and Region, run bootstrapping with
npx cdk bootstrap. - Run
npx cdk deployto deploy the stack.
- Open the
- Optionally, run the
streamlit-uias follows:- We recommend cloning this repository into an Amazon SageMaker Studio environment. For more information, refer to Onboard to Amazon SageMaker Domain using Quick setup.
- Inside the
frontend/streamlit-uifolder, runbash run-streamlit-ui.sh. - Choose the link with the following format to open the demo:
https://{domain_id}.studio.{region}.sagemaker.aws/jupyter/default/proxy/{port_number}/.
- Finally, you can run the Amazon SageMaker pipeline defined in the
data-pipelines/04-sagemaker-pipeline-for-documents-processing.ipynbnotebook to process the input PDF documents and prepare the SQL table and the semantic search index used by the LLM assistant.
In the rest of this post, we focus on explaining the most important components and design choices, to hopefully inspire you when designing your own AI assistant on an internal knowledge base. We assume that components 1 and 4 are straightforward to understand, and focus on the core components 2, 3, and 5.
Part 2: Entity extraction pipeline
In this section, we dive deeper into the entity extraction pipeline used to prepare structured data, which is a key ingredient for analytical question answering.
Text extraction
Documents are typically stored in PDF format or as scanned images. They may be formed of simple paragraph layouts or complex tables, and contain digital or handwritten text. To extract information correctly, we need to transform these raw documents into plain text, while preserving their original structure. To do this, you can use Amazon Textract, which is a machine learning (ML) service that provides mature APIs for text, tables, and forms extraction from digital and handwritten inputs.
In component 2, we extract text and tables as follows:
- For each document, we call Amazon Textract to extract the text and tables.
- We use the following Python script to recreate tables as pandas DataFrames.
- We consolidate the results into a single document and insert tables as markdown.
This process is outlined by the following flow diagram and concretely demonstrated in notebooks/03-pdf-document-processing.ipynb.

Entity extraction and querying using LLMs
To answer analytical questions effectively, you need to extract relevant metadata and entities from your document’s knowledge base to an accessible structured data format. We suggest using SQL to store this information and retrieve answers due to its popularity, ease of use, and scalability. This choice also benefits from the proven language models’ ability to generate SQL queries from natural language.
In this section, we dive deeper into the following components that enable analytical questions:
- A batch process that extracts structured data out of unstructured data using LLMs
- A real-time module that converts natural language questions to SQL queries and retrieves results from a SQL database
You can extract the relevant metadata to support analytical questions as follows:
- Define a JSON schema for information you need to extract, which contains a description of each field and its data type, and includes examples of the expected values.
- For each document, prompt an LLM with the JSON schema and ask it to extract the relevant data accurately.
- When the document length is beyond the context length, and to reduce the extraction cost with LLMs, you can use semantic search to retrieve and present the relevant chunks of documents to the LLM during extraction.
- Parse the JSON output and validate the LLM extraction.
- Optionally, back up the results on Amazon S3 as CSV files.
- Load into the SQL database for later querying.
This process is managed by the following architecture, where the documents in text format are loaded with a Python script that runs in an Amazon SageMaker Processing job to perform the extraction.

For each group of entities, we dynamically construct a prompt that includes a clear description of the information extraction task, and includes a JSON schema that defines the expected output and includes the relevant document chunks as context. We also add a few examples of input and correct output to improve the extraction performance with few-shot learning. This is demonstrated in notebooks/05-entities-extraction-to-structured-metadata.ipynb.
Part 3: Build an agentic document assistant with Amazon Bedrock
In this section, we demonstrate how to use Amazon Bedrock LLMs to query data and build an LLM agent that enhances RAG with analytical capabilities, thereby enabling you to build intelligent document assistants that can answer complex domain-specific questions across multiple documents. You can refer to the Lambda function on GitHub for the concrete implementation of the agent and tools described in this part.
Formulate SQL queries and answer analytical questions
Now that we have a structured metadata store with the relevant entities extracted and loaded into a SQL database that we can query, the question that remains is how to generate the right SQL query from the input natural language questions?
Modern LLMs are good at generating SQL. For instance, if you request from the Anthropic Claude LLM through Amazon Bedrock to generate a SQL query, you will see plausible answers. However, we need to abide by a few rules when writing the prompt to reach more accurate SQL queries. These rules are especially important for complex queries to reduce hallucination and syntax errors:
- Describe the task accurately within the prompt
- Include the schema of the SQL tables within the prompt, while describing each column of the table and specifying its data type
- Explicitly tell the LLM to only use existing column names and data types
- Add a few rows of the SQL tables
You could also postprocess the generated SQL query using a linter such as sqlfluff to correct formatting, or a parser such as sqlglot to detect syntax errors and optimize the query. Moreover, when the performance doesn’t meet the requirement, you could provide a few examples within the prompt to steer the model with few-shot learning towards generating more accurate SQL queries.
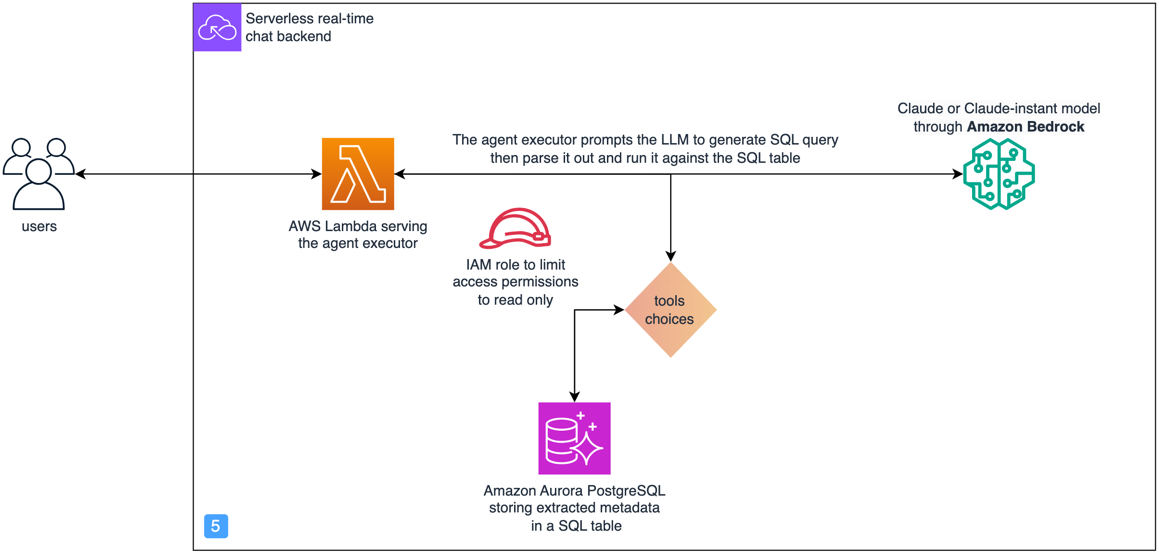
From an implementation perspective, we use an AWS Lambda function to orchestrate the following process:
- Call an Anthropic Claude model in Amazon Bedrock with the input question to get the corresponding SQL query. Here, we use the SQLDatabase class from LangChain to add schema descriptions of relevant SQL tables, and use a custom prompt.
- Parse, validate, and run the SQL query against the Amazon Aurora PostgreSQL-Compatible Edition database.
The architecture for this part of the solution is highlighted in the following diagram.
Security considerations to prevent SQL injection attacks
As we enable the AI assistant to query a SQL database, we have to make sure this doesn’t introduce security vulnerabilities. To achieve this, we propose the following security measures to prevent SQL injection attacks:
- Apply least privilege IAM permissions – Limit the permission of the Lambda function that runs the SQL queries using an AWS Identity and Access Management (IAM) policy and role that follows the least privilege principle. In this case, we grant read-only access.
- Limit data access – Only provide access to the bare minimum of tables and columns to prevent information disclosure attacks.
- Add a moderation layer – Introduce a moderation layer that detects prompt injection attempts early on and prevents them from propagating to the rest of the system. It can take the form of rule-based filters, similarity matching against a database of known prompt injection examples, or an ML classifier.
Semantic search retrieval to augment generation context
The solution we propose uses RAG with semantic search in component 3. You can implement this module using knowledge bases for Amazon Bedrock. Additionally, there are a variety of others options to implement RAG, such as the Amazon Kendra Retrieval API, Amazon OpenSearch vector database, and Amazon Aurora PostgreSQL with pgvector, among others. The open source package aws-genai-llm-chatbot demonstrates how to use many of these vector search options to implement an LLM-powered chatbot.
In this solution, because we need both SQL querying and vector search, we decided to use Amazon Aurora PostgreSQL with the pgvector extension, which supports both features. Therefore, we implement the semantic-search RAG component with the following architecture.

The process of answering questions using the preceding architecture is done in two main stages.
First, an offline-batch process, run as a SageMaker Processing job, creates the semantic search index as follows:
- Either periodically, or upon receiving new documents, a SageMaker job is run.
- It loads the text documents from Amazon S3 and splits them into overlapping chunks.
- For each chunk, it uses an Amazon Titan embedding model to generate an embedding vector.
- It uses the PGVector class from LangChain to ingest the embeddings, with their document chunks and metadata, into Amazon Aurora PostgreSQL and create a semantic search index on all the embedding vectors.
Second, in real time and for each new question, we construct an answer as follows:
- The question is received by the orchestrator that runs on a Lambda function.
- The orchestrator embeds the question with the same embedding model.
- It retrieves the top-K most relevant documents chunks from the PostgreSQL semantic search index. It optionally uses metadata filtering to improve precision.
- These chunks are inserted dynamically in an LLM prompt alongside the input question.
- The prompt is presented to Anthropic Claude on Amazon Bedrock, to instruct it to answer the input question based on the available context.
- Finally, the generated answer is sent back to the orchestrator.
An agent capable of using tools to reason and act
So far in this post, we have discussed treating questions that require either RAG or analytical reasoning separately. However, many real-world questions demand both capabilities, sometimes over multiple steps of reasoning, in order to reach a final answer. To support these more complex questions, we need to introduce the notion of an agent.
LLM agents, such as the agents for Amazon Bedrock, have emerged recently as a promising solution capable of using LLMs to reason and adapt using the current context and to choose appropriate actions from a list of options, which presents a general problem-solving framework. As discussed in LLM Powered Autonomous Agents, there are multiple prompting strategies and design patterns for LLM agents that support complex reasoning.
One such design pattern is Reason and Act (ReAct), introduced in ReAct: Synergizing Reasoning and Acting in Language Models. In ReAct, the agent takes as input a goal that can be a question, identifies the pieces of information missing to answer it, and proposes iteratively the right tool to gather information based on the available tools’ descriptions. After receiving the answer from a given tool, the LLM reassesses whether it has all the information it needs to fully answer the question. If not, it does another step of reasoning and uses the same or another tool to gather more information, until a final response is ready or a limit is reached.
The following sequence diagram explains how a ReAct agent works toward answering the question “Give me the top 5 companies with the highest revenue in the last 2 years and identify the risks associated with the top one.”

The details of implementing this approach in Python are described in Custom LLM Agent. In our solution, the agent and tools are implemented with the following highlighted partial architecture.

To answer an input question, we use AWS services as follows:
- A user inputs their question through a UI, which calls an API on Amazon API Gateway.
- API Gateway sends the question to a Lambda function implementing the agent executor.
- The agent calls the LLM with a prompt that contains a description of the tools available, the ReAct instruction format, and the input question, and then parses the next action to complete.
- The action contains which tool to call and what the action input is.
- If the tool to use is SQL, the agent executor calls SQLQA to convert the question to SQL and run it. Then it adds the result to the prompt and calls the LLM again to see if it can answer the original question or if more actions are needed.
- Similarly, if the tool to use is semantic search, then the action input is parsed out and used to retrieve from the PostgreSQL semantic search index. It adds the results to the prompt and checks if the LLM is able to answer or needs another action.
- After all the information to answer a question is available, the LLM agent formulates a final answer and sends it back to the user.
You can extend the agent with further tools. In the implementation available on GitHub, we demonstrate how you can add a search engine and a calculator as extra tools to the aforementioned SQL engine and semantic search tools. To store the ongoing conversation history, we use an Amazon DynamoDB table.
From our experience so far, we have seen that the following are keys to a successful agent:
- An underlying LLM capable of reasoning with the ReAct format
- A clear description of the available tools, when to use them, and a description of their input arguments with, potentially, an example of the input and expected output
- A clear outline of the ReAct format that the LLM must follow
- The right tools for solving the business question made available to the LLM agent to use
- Correctly parsing out the outputs from the LLM agent responses as it reasons
To optimize costs, we recommend caching the most common questions with their answers and updating this cache periodically to reduce calls to the underlying LLM. For instance, you can create a semantic search index with the most common questions as explained previously, and match the new user question against the index first before calling the LLM. To explore other caching options, refer to LLM Caching integrations.
Supporting other formats such as video, image, audio, and 3D files
You can apply the same solution to various types of information, such as images, videos, audio, and 3D design files like CAD or mesh files. This involves using established ML techniques to describe the file content in text, which can then be ingested into the solution that we explored earlier. This approach enables you to conduct QA conversations on these diverse data types. For instance, you can expand your document database by creating textual descriptions of images, videos, or audio content. You can also enhance the metadata table by identifying properties through classification or object detection on elements within these formats. After this extracted data is indexed in either the metadata store or the semantic search index for documents, the overall architecture of the proposed system remains largely consistent.
Conclusion
In this post, we showed how using LLMs with the RAG design pattern is necessary for building a domain-specific AI assistant, but is insufficient to reach the required level of reliability to generate business value. Because of this, we proposed extending the popular RAG design pattern with the concepts of agents and tools, where the flexibility of tools allows us to use both traditional NLP techniques and modern LLM capabilities to enable an AI assistant with more options to seek information and assist users in solving business problems efficiently.
The solution demonstrates the design process towards an LLM assistant able to answer various types of retrieval, analytical reasoning, and multi-step reasoning questions across all of your knowledge base. We also highlighted the importance of thinking backward from the types of questions and tasks that your LLM assistant is expected to help users with. In this case, the design journey led us to an architecture with the three components: semantic search, metadata extraction and SQL querying, and LLM agent and tools, which we think is generic and flexible enough for multiple use cases. We also believe that by getting inspiration from this solution and diving deep into your users’ needs, you will be able to extend this solution further toward what works best for you.
About the authors
 Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
Mohamed Ali Jamaoui is a Senior ML Prototyping Architect with 10 years of experience in production machine learning. He enjoys solving business problems with machine learning and software engineering, and helping customers extract business value with ML. As part of AWS EMEA Prototyping and Cloud Engineering, he helps customers build business solutions that leverage innovations in MLOPs, NLP, CV and LLMs.
 Giuseppe Hannen is a ProServe Associate Consultant. Giuseppe applies his analytical skills in combination with AI&ML to develop clear and effective solutions for his customers. He loves to come up with simple solutions to complicated problems, especially those that involve the latest technological developments and research.
Giuseppe Hannen is a ProServe Associate Consultant. Giuseppe applies his analytical skills in combination with AI&ML to develop clear and effective solutions for his customers. He loves to come up with simple solutions to complicated problems, especially those that involve the latest technological developments and research.
 Laurens ten Cate is a Senior Data Scientist. Laurens works with enterprise customers in EMEA helping them accelerate their business outcomes using AWS AI/ML technologies. He specializes in NLP solutions and focusses on the Supply Chain & Logistics industry. In his free time he enjoys reading and art.
Laurens ten Cate is a Senior Data Scientist. Laurens works with enterprise customers in EMEA helping them accelerate their business outcomes using AWS AI/ML technologies. He specializes in NLP solutions and focusses on the Supply Chain & Logistics industry. In his free time he enjoys reading and art.
 Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She is helping customers get the best out of the latest tech, innovate faster and think bigger.
Irina Radu is a Prototyping Engagement Manager, part of AWS EMEA Prototyping and Cloud Engineering. She is helping customers get the best out of the latest tech, innovate faster and think bigger.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/boosting-rag-based-intelligent-document-assistants-using-entity-extraction-sql-querying-and-agents-with-amazon-bedrock/

