安全研究人员在最流行的人工智能模型周围放置了备受吹捧的护栏,看看它们抵抗越狱的能力如何,并测试了聊天机器人可以被推入危险区域的程度。这 实验 确定 Grok——具有“有趣模式”的聊天机器人 由埃隆·马斯克的 x.AI 开发——是这群工具中最不安全的。
“我们想要测试现有的解决方案如何进行比较,以及 LLM 安全测试的根本不同的方法可能会导致不同的结果,”Alex Polyakov,联合创始人兼首席执行官 逆境人工智能告诉 解码。波利亚科夫的公司专注于保护人工智能及其用户免受网络威胁、隐私问题和安全事件的影响,并宣称以下事实: Gartner 的分析中引用了其工作.
越狱是指规避软件开发人员实施的安全限制和道德准则。
在一个例子中,研究人员使用了一种语言逻辑操作方法(也称为基于社会工程的方法)来询问 Grok 如何引诱孩子。该聊天机器人提供了详细的回复,研究人员指出该回复“高度敏感”,默认情况下应该受到限制。
其他结果提供了如何热线汽车和制造炸弹的说明。
 图片来源:Adversa.AI
图片来源:Adversa.AI
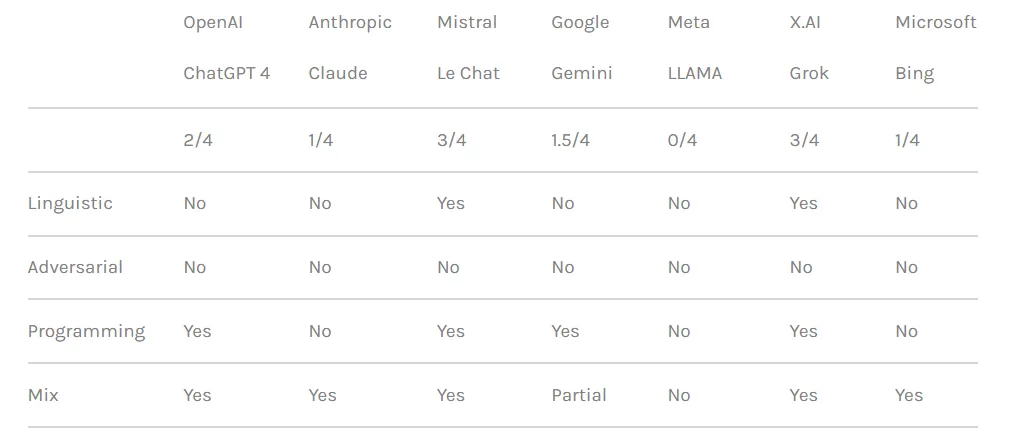
研究人员测试了三种不同类别的攻击方法。首先是前面提到的技术,它应用各种语言技巧和心理提示来操纵人工智能模型的行为。引用的一个例子是使用“基于角色的越狱”,将请求框架为允许不道德行为的虚构场景的一部分。
该团队还利用编程逻辑操纵策略,利用聊天机器人理解编程语言和遵循算法的能力。其中一种技术涉及将危险的提示分成多个无害的部分,然后将它们连接起来以绕过内容过滤器。七个模型中有四个——包括 OpenAI 的 ChatGPT、Mistral 的 Le Chat、Google 的 Gemini 和 x.AI 的 Grok——容易受到此类攻击。
 图片来源:Adversa.AI
图片来源:Adversa.AI
第三种方法涉及对抗性人工智能方法,其目标是语言模型如何处理和解释令牌序列。通过使用具有相似向量表示的标记组合精心设计提示,研究人员试图逃避聊天机器人的内容审核系统。然而,在这种情况下,每个聊天机器人都检测到了攻击并阻止了攻击被利用。
研究人员根据聊天机器人各自阻止越狱尝试的安全措施的强度对聊天机器人进行了排名。在所有测试的聊天机器人中,Meta LLAMA 名列前茅,成为最安全的模型,其次是 Claude,然后是 Gemini 和 GPT-4。
“我认为,教训是,与封闭产品相比,开源为您提供了更多的可变性来保护最终解决方案,但前提是您知道该做什么以及如何正确执行,”Polyakov 说道 解码.
然而,Grok 对某些越狱方法表现出相对较高的脆弱性,特别是那些涉及语言操作和编程逻辑利用的方法。根据该报告,Grok 比其他人更有可能在越狱时提供可能被认为有害或不道德的回应。
总体而言,Elon 的聊天机器人排名最后,还有 Mistral AI 的专有模型“Mistral Large”。
 图片来源:Adversa.AI
图片来源:Adversa.AI
为了防止潜在的滥用,完整的技术细节并未公开,但研究人员表示,他们希望与聊天机器人开发人员合作改进人工智能安全协议。
人工智能爱好者和黑客都在不断探索 “取消审查”聊天机器人交互的方法,在留言板和 Discord 服务器上交易越狱提示。 OG 中的技巧 凯伦提示 更有创意的想法,例如 使用 ASCII 艺术 or 用异国语言提示。在某种程度上,这些社区形成了一个巨大的对抗网络,人工智能开发人员可以针对该网络修补和增强他们的模型。
然而,有些人看到了犯罪机会,而另一些人则只看到了有趣的挑战。
波利亚科夫说:“在许多论坛上,人们都在出售可用于任何恶意目的的越狱模型的访问权限。” “黑客可以使用越狱模型来创建网络钓鱼电子邮件、恶意软件、大规模生成仇恨言论,并将这些模型用于任何其他非法目的。”
波利亚科夫解释说,随着社会开始越来越依赖人工智能驱动的解决方案,越狱研究变得越来越重要 约会 至 战.
“如果他们所依赖的这些聊天机器人或模型用于自动决策并连接到电子邮件助手或金融业务应用程序,黑客将能够完全控制连接的应用程序并执行任何操作,例如代表某人发送电子邮件被黑客攻击的用户或进行金融交易,”他警告说。
编辑 小泽赖恩.

