赞助功能 训练人工智能模型需要大量的计算能力和高带宽内存。 由于模型训练可以并行化,数据被分割成相对较小的部分,并由大量相当适中的浮点数学单元进行处理,因此 GPU 可以说是人工智能革命可以在其上开始的自然设备。
虽然有一些定制的 ASIC 可以执行大量所需的矩阵数学运算,并带有各种 SRAM 或 DRAM 内存,但 GPU 仍然是首选的 AI 训练设备。 部分原因是 GPU 无处不在,其计算框架开发完善且易于访问,因此没有理由相信对于大多数公司(大部分时间)而言,GPU 仍将是 AI 训练的首选计算引擎。
GPU 加速在 HPC 模拟和建模工作负载中变得普遍并没有什么坏处。 或者数据中心的其他工作负载——例如虚拟桌面基础设施、数据分析和数据库管理系统——也可以在用于执行 AI 训练的同一台机器上加速。
但是人工智能推理,将相对复杂的人工智能模型归结为一组权重,以对不属于原始训练集的新数据进行预测计算,则完全是另一回事。 出于非常合理的技术和经济原因,在很多情况下,AI 推理应该保留——并将保留——在今天运行应用程序的相同服务器 CPU 上,并通过 AI 算法进行增强。
很难击败免费的 AI 推理
为什么推理应该留在 CPU 上,而不是转移到服务器机箱内的加速器,或者通过网络进入 GPU 库或作为推理加速器运行的定制 ASIC,存在很多争论。
首先,外部推理引擎增加了复杂性(需要购买更多可能会损坏的东西)并可能增加安全风险,因为应用程序与其推理引擎之间存在更多的攻击面。 无论如何,外部推理引擎会增加延迟,尤其是对于跨网络运行的那些工作负载,许多超大规模人员和云构建者都会这样做。
不可否认,对于前几代服务器 CPU,推理吞吐量使用混合精度整数或浮点数据。 通过集成矢量数学单元推动它们不需要太多带宽,尽管它可能非常适合许多应用程序所需的推理率。 因此, 这仍然是数据中心 70% 的推理的原因,包括超大规模企业和云建设者以及其他类型的企业,仍然在英特尔® 至强® CPU 上运行。 但对于繁重的推理工作,服务器级 CPU 的吞吐量无法与 GPU 或定制 ASIC 竞争。
到现在。
像我们一样 以前讨论过,借助“Sapphire Rapids”第 4 代英特尔® 至强® 处理器,每个“Golden Cove”内核中的英特尔高级矩阵扩展 (AMX) 矩阵数学加速器显着提高了支撑 AI 推理的低精度数学运算的性能(阅读更多关于内置于英特尔最新 Xeon CPU 中的加速器 相关信息).
图 1:Sapphire Rapids 向量矩阵吞吐量
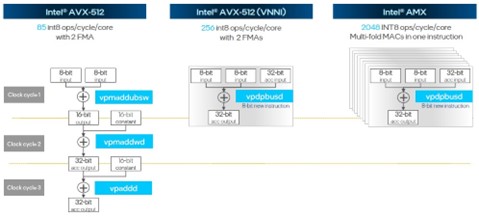
AMX 单元每个内核每个周期可以处理 2,048 个 8 位整数 (INT8) 运算。 这比“Skylake”CPU 中使用的普通香草 AVX-24 矢量单元的吞吐量高 512 倍,在 INT8 操作上比“Cascade Lake”和“Ice Lake”AVX-8 单元高 512 倍,后者增加了更高效的矢量神经网络网络指令 (VNNI)。 Golden Cove 内核支持同时使用具有 VNNI 和 AMX 单元的 AVX-512,因此推理工作负载的吞吐量是 INT32 的 8 倍。
AMX 单元的诀窍在于它包含在 SKU 堆栈中 Sapphire Rapids CPU 的 52 种变体中每一种的 Golden Cove 核心中。 基于这些内核的整数性能(不包括 AVX-512 和 AMX 性能),Sapphire Rapids Xeon 的性价比与上一代 Xeon SP 处理器相同或略好。 这是另一种说法,AMX 单元基本上是免费的,因为它们包含在所有 CPU 中,并且与 Ice Lake 相比,无需增加成本即可提供额外的性能。 获得比免费更便宜的推理更难,特别是如果 CPU 是运行应用程序所必需的。
堆叠人字拖
理论性能是一回事,但重要的是实际的 AI 推理应用程序如何利用 Golden Cove 内核中的新 AMX 单元。
让我们放眼长远,看看推理性能自 “Broadwell”Xeon E7s 于 2016 年 XNUMX 月推出 通过以下四代 Xeon SP 处理器。 此特定图表显示了处理器吞吐量与每秒处理 1,000 张图像的瓦特之间的相互作用:
图 2:Sapphire Rapids Xeon 随着时间的推移 RESNET 推理

请参阅 [A17, A33],网址为 https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. 结果可能会有所不同。
在这种情况下,在五代服务器上运行的测试正在使用 TensorFlow 框架之上的 ResNet-50 模型进行图像识别。 在过去九年中,图像处理吞吐量从每秒约 300 张图像增加到每秒 12,000 多张图像,提高了 40 多倍。
每秒处理 1,000 张图像所产生的热量比这张图表显示的还要多。 需要三个和第三个 FP24 精度的 7 核 Broadwell E32 处理器才能达到每秒 1,000 张图像的速度,并且每个芯片的功率为 165 瓦,因此分配给此负载的总功率为 550 瓦。 Sapphire Rapids 芯片和 AMX 单元混合使用 BF16 和 INT8 处理,功耗低于 75 瓦。 因此,与前五代 Broadwell CPU 相比,Sapphire Rapids 的每瓦性能提高了 7.3 倍以上。
其他工作负载呢? 让我们来看看。 这就是运行频率为 56GHz 的 8480 核 Sapphire Rapids Xeon SP-2+ CPU 在图像分类、自然语言处理、图像分割、变压器等方面与运行频率为 40GHz 的上一代 8380 核 Ice Lake Xeon SP-2.3 CPU 的对比,以及在 PyTorch 框架上运行的对象检测模型:
图 3:Sapphire Rapids vs Ice Lake 各种推理
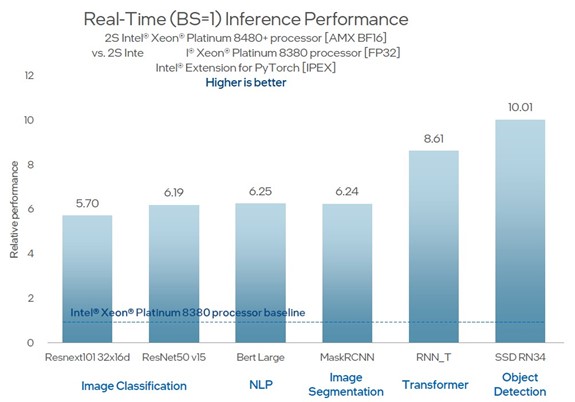
请参阅 [A17, A33],网址为 https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. 结果可能会有所不同。
正如图表所示,这是在 Ice Lake 芯片中的 AVX-32 单元上进行 FP512 处理与在 AMX 单元上进行 BF16 处理的比较。 仅仅两个平台之间的精度减半就使这两代之间的吞吐量翻了一番。 这两款芯片的相对性能(核心数量和时钟速度的综合)产生了另外 21.7% 的性能。 其余的性能提升——在上面显示的 3.5 倍到 7.8 倍中达到 5.7 倍到 10 倍——来自使用 AMX 单元。
当然,真正的测试是与使用舷外加速器相比,Sapphire Rapids 中固有的 AMX 单元的推理能力如何。 因此,与 Nvidia“Ampere”A8480 GPU 加速器相比,使用 Xeon SP-10+ 处理器的双路服务器的性能对比如下:
图4:Sapphire Raipds vs NVIDIA A10 各种推理

见 [A218] https://edc.intel.com/content/www/us/en/products/performance/benchmarks/4th-generation-intel-xeon-scalable-processors/. 结果可能会有所不同。
两个 Sapphire Rapids 处理器在 BERT-Large 模型上的自然语言推理性能达到 A90 的 10%,并且在其他工作负载上比 A10 高出 1.5 到 3.5 倍。
A10 GPU 加速器目前的成本可能在 3,000 美元到 6,000 美元之间,并且可以通过 PCI-Express 4.0 总线或更远的以太网或 InfiniBand 网络在通过网络访问的专用推理服务器中使用通过应用程序服务器的往返。 即使来自 Nvidia 的新“Lovelace”L40 GPU 加速器可以完成更多工作,AMX 单元默认内置于 Sapphire Rapids CPU 中,不需要附加组件。
由英特尔赞助。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图区块链。 Web3 元宇宙智能。 知识放大。 访问这里。
- Sumber: https://go.theregister.com/feed/www.theregister.com/2023/04/10/why_ai_inference_will_remain/

