As Artificial Intelligence (AI) and Machine Learning (ML) technologies have become mainstream, many enterprises have been successful in building critical business applications powered by ML models at scale in production. However, since these ML models are making critical business decisions for the business, it’s important for enterprises to add proper guardrails throughout their ML lifecycle. Guardrails ensure that security, privacy, and quality of the code, configuration, and data and model configuration used in model lifecycle are versioned and preserved.
Implementing these guardrails is getting harder for enterprises because the ML processes and activities within enterprises are becoming more complex due to the inclusion of deeply involved processes that require contributions from multiple stakeholders and personas. In addition to data engineers and data scientists, there have been inclusions of operational processes to automate & streamline the ML lifecycle. Additionally, the surge of business stakeholders and in some cases legal and compliance reviews need capabilities to add transparency for managing access control, activity tracking, and reporting across the ML lifecycle.
The framework that gives systematic visibility into ML model development, validation, and usage is called ML governance. During AWS re:Invent 2022, AWS introduced new ML governance tools for Amazon SageMaker which simplifies access control and enhances transparency over your ML projects. One of the tools available as part of the ML governance is Amazon SageMaker Model Cards, which has the capability to create a single source of truth for model information by centralizing and standardizing documentation throughout the model lifecycle.
SageMaker model cards enable you to standardize how models are documented, thereby achieving visibility into the lifecycle of a model, from designing, building, training, and evaluation. Model cards are intended to be a single source of truth for business and technical metadata about the model that can reliably be used for auditing and documentation purposes. They provide a fact sheet of the model that is important for model governance.
As you scale your models, projects, and teams, as a best practice we recommend that you adopt a multi-account strategy that provides project and team isolation for ML model development and deployment. For more information about improving governance of your ML models, refer to Improve governance of your machine learning models with Amazon SageMaker.
Architecture overview
The architecture is implemented as follows:
- Data Science Account – Data Scientists conduct their experiments in SageMaker Studio and build an MLOps setup to deploy models to staging/production environments using SageMaker Projects.
- ML Shared Services Account – The MLOps set up from the Data Science account will trigger continuous integration and continuous delivery (CI/CD) pipelines using AWS CodeCommit and AWS CodePipeline.
- Dev Account – The CI/CD pipelines will further trigger ML pipelines in this account covering data pre-processing, model training and post processing like model evaluation and registration. Output of these pipelines will deploy the model in SageMaker endpoints to be consumed for inference purposes. Depending on your governance requirements, Data Science & Dev accounts can be merged into a single AWS account.
- Data Account – The ML pipelines running in the Dev Account will pull the data from this account.
- Test and Prod Accounts – The CI/CD pipelines will continue the deployment after the Dev Account to set up SageMaker endpoint configuration in these accounts.
- Security and Governance – Services like AWS Identity and Access Management (IAM), AWS IAM Identity Center, AWS CloudTrail, AWS Key Management Service (AWS KMS), Amazon CloudWatch, and AWS Security Hub will be used across these accounts as part of security and governance.
The following diagram illustrates this architecture.

For more information about setting scalable multi account ML architecture, refer to MLOps foundation for enterprises with Amazon SageMaker.
Our customers need the capability to share model cards across accounts to improve visibility and governance of their models through information shared in the model card. Now, with cross-account model cards sharing, customers can enjoy the benefits of multi-account strategy while having accessibility into the available model cards in their organization, so they can accelerate collaboration and ensure governance.
In this post, we show how to set up and access model cards across Model Development Lifecycle (MDLC) accounts using the new cross-account sharing feature of the model card. First, we will describe a scenario and architecture for setting up the cross-account sharing feature of the model card, and then dive deep into each component of how to set up and access shared model cards across accounts to improve visibility and model governance.
Solution overview
When building ML models, we recommend setting up a multi-account architecture to provide workload isolation improving security, reliability, and scalability. For this post, we will assume building and deploying a model for Customer Churn use case. The architecture diagram that follows shows one of the recommended approaches – centralized model card – for managing a model card in a multi-account Machine Learning Model-Development Lifecycle (MDLC) architecture. However, you can also adopt another approach, a hub-and-spoke model card. In this post, we will focus only on a centralized model card approach, but the same principles can be extended to a hub-and-spoke approach. The main difference is that each spoke account will maintain their own version of model card and it will have processes to aggregate and copy to a centralized account.
The following diagram illustrates this architecture.

The architecture is implemented as follows:
- Lead Data Scientist is notified to solve the Customer Churn use case using ML, and they start the ML project through creation of a model card for Customer Churn V1 model in Draft status in the ML Shared Services Account
- Through automation, that model card is shared with ML Dev Account
- Data Scientist builds the model and starts to populate information via APIs into the model card based on their experimentation results and the model card status is set to Pending Review
- Through automation, that model card is shared with the ML test account
- ML Engineer (MLE) runs integration and validation tests in ML Test account and the model in the central registry is marked Pending Approval
- Model Approver reviews the model results with the supporting documentation provided in the central model card and approves the model card for production deployment.
- Through automation, that model card is shared with ML Prod account in read-only mode.
Prerequisites
Before you get started, make sure you have the following prerequisites:
- Two AWS accounts.
- In both AWS accounts, an IAM federation role with administrator access to do the following:
- Create, edit, view, and delete model cards within Amazon SageMaker.
- Create, edit, view, and delete resource share within AWS RAM.
For more information, refer to Example IAM policies for AWS RAM.
Setting up model card sharing
The account where the model cards are created is the model card account. Users in the model card account share them with the shared accounts where they can be updated. Users in the model card account can share their model cards through AWS Resource Access Manager (AWS RAM). AWS RAM helps you share resources across AWS accounts.
In the following section, we show how to share model cards.
First, create a model card for a Customer Churn use case as previously described. On the Amazon SageMaker console, expand the Governance section and choose Model cards.

We create the model card in Draft status with the name Customer-Churn-Model-Card. For more information, refer to Create a model card. In this demonstration, you can leave the remainder of the fields blank and create the model card.
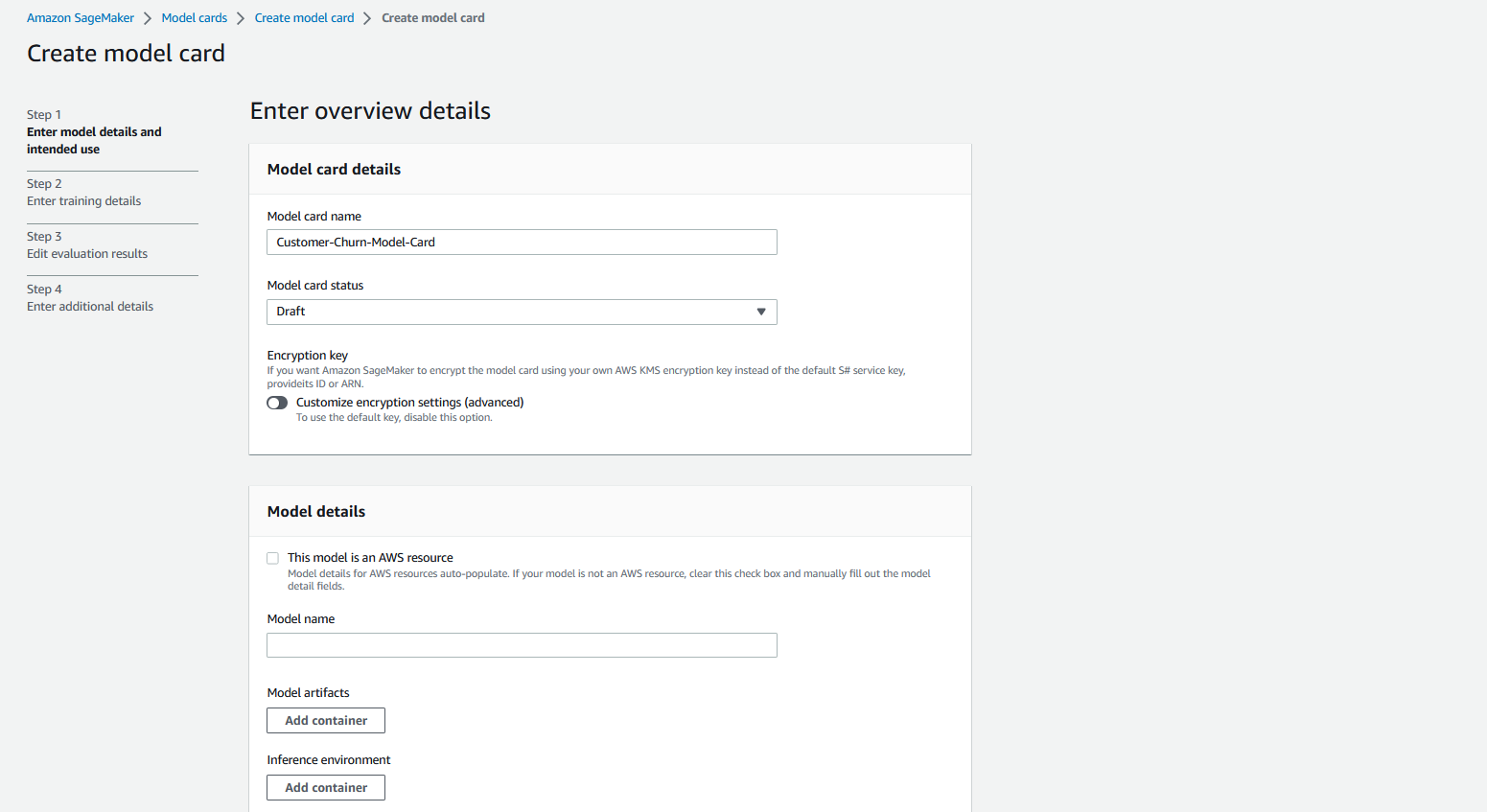
Alternatively, you can use the following AWS CLI command to create the model card:
Now, create the cross-account share using AWS RAM. In the AWS RAM console, select Create a resource share.

Enter a name for the resource share, for example “Customer-Churn-Model-Card-Share”. In the Resources – optional section, select the resource type as SageMaker Model Cards. The model card we created in the previous step will appear in the listing.
Select that model and it will appear in the Selected resources section. Select that resource again as shown in the following steps and choose Next.

On the next page, you can select the Managed permissions. You can create custom permissions or use the default option “AWSRAMPermissionSageMakerModelCards” and select Next. For more information, refer to Managing permissions in AWS RAM.

On the next page, you can select Principals. Under Select principal type, choose AWS Account and enter the ID of the account of the share the model card. Select Add and continue to the next page.

On the last page, review the information and select “Create resource share”. Alternatively, you can use the following AWS CLI command to create a resource share:
On the AWS RAM console, you see the attributes of the resource share. Make sure that Shared resources, Managed permissions, and Shared principals are in the “Associated” status.
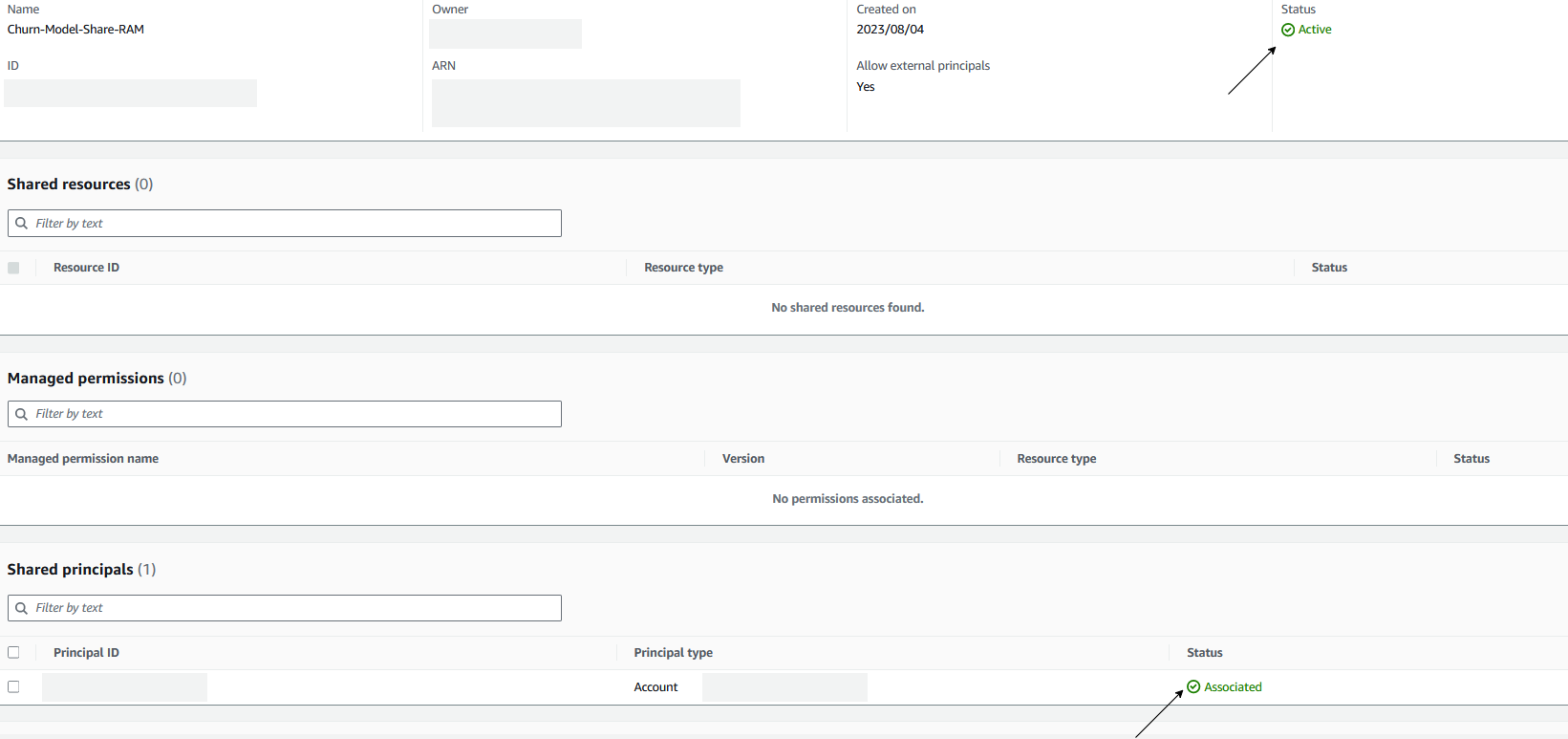
After you use AWS RAM to create a resource share, the principals specified in the resource share can be granted access to the share’s resources.
- If you turn on AWS RAM sharing with AWS Organizations, and your principals that you share with are in the same organization as the sharing account, those principals can receive access as soon as their account administrator grants them permissions.
- If you don’t turn on AWS RAM sharing with Organizations, you can still share resources with individual AWS accounts that are in your organization. The administrator in the consuming account receives an invitation to join the resource share, and they must accept the invitation before the principals specified in the resource share can access the shared resources.
- You can also share with accounts outside of your organization if the resource type supports it. The administrator in the consuming account receives an invitation to join the resource share, and they must accept the invitation before the principals specified in the resource share can access the shared resources.
For more information about AWS RAM, refer to Terms and concepts for AWS RAM.
Accessing shared model cards
Now we can log in to the shared AWS account to access the model card. Make sure that you are accessing the AWS console using IAM permissions (IAM role) which allow access to AWS RAM.
With AWS RAM, you can view the resource shares to which you have been added, the shared resources that you can access, and the AWS accounts that have shared resources with you. You can also leave a resource share when you no longer require access to its shared resources.
To view the model card in the shared AWS account:
- Navigate to the Shared with me: Shared resources page in the AWS RAM console.
- Make sure that you are operating in the same AWS region where the share was created.
- The model shared from the model account will be available in the listing. If there is a long list of resources, then you can apply a filter to find specific shared resources. You can apply multiple filters to narrow your search.
- The following information is available:
- Resource ID – The ID of the resource. This is the name of the model card that we created earlier in the model card account.
- Resource type – The type of resource.
- Last share date – The date on which the resource was shared with you.
- Resource shares – The number of resource shares in which the resource is included. Choose the value to view the resource shares.
- Owner ID – The ID of the principal who owns the resource.

You can also access the model card using the AWS CLI option. For the AWS IAM policy configured with the correct credentials, make sure that you have permissions to create, edit, and delete model cards within Amazon SageMaker. For more information, refer to Configure the AWS CLI.
You can use the following AWS IAM permissions policy as template:
You can run the following AWS CLI command to access the details of the shared model card.
Now you can make changes to this model card from this account.
After you make changes, go back to the model card account to see the changes that we made in this shared account.

The problem type has been updated to “Customer Churn Model” which we had provided as part of the AWS CLI command input.
Clean up
You can now delete the model card you created. Make sure that you delete the AWS RAM resource share that you created to share the model card.
Conclusion
In this post, we provided an overview of multi-account architecture for scaling and governing your ML workloads securely and reliably. We discussed the architecture patterns for setting up model card sharing and illustrated how centralized model card sharing patterns work. Finally, we set up model card sharing across multiple accounts for improving visibility and governance in your model development lifecycle. We encourage you try out the new model card sharing feature and let us know your feedback.
About the authors
 Vishal Naik is a Sr. Solutions Architect at Amazon Web Services (AWS). He is a builder who enjoys helping customers accomplish their business needs and solve complex challenges with AWS solutions and best practices. His core area of focus includes Machine Learning, DevOps, and Containers. In his spare time, Vishal loves making short films on time travel and alternate universe themes.
Vishal Naik is a Sr. Solutions Architect at Amazon Web Services (AWS). He is a builder who enjoys helping customers accomplish their business needs and solve complex challenges with AWS solutions and best practices. His core area of focus includes Machine Learning, DevOps, and Containers. In his spare time, Vishal loves making short films on time travel and alternate universe themes.
 Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 2-year-old sheep-a-doodle!
Ram Vittal is a Principal ML Solutions Architect at AWS. He has over 20 years of experience architecting and building distributed, hybrid, and cloud applications. He is passionate about building secure and scalable AI/ML and big data solutions to help enterprise customers with their cloud adoption and optimization journey to improve their business outcomes. In his spare time, he rides his motorcycle and walks with his 2-year-old sheep-a-doodle!
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Automotive / EVs, Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- ChartPrime. Elevate your Trading Game with ChartPrime. Access Here.
- BlockOffsets. Modernizing Environmental Offset Ownership. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/use-amazon-sagemaker-model-cards-sharing-to-improve-model-governance/

