Вам коли-небудь потрібно було витягти дані з PDF-файлу або сканованого документа в електронну таблицю? OCR може реально заощадити час. Просто відскануйте документи та перетворите зображення на редагований текст із можливістю пошуку. OCR полегшує вилучення даних, незалежно від того, чи працюєте ви з PDF-файлами, фотографіями чи відскановані сторінки.
Оптимізуйте свій управління документами за допомогою цього посібника з розпізнавання тексту в електронну таблицю. Ми проведемо вас через робочий процес і надамо важливі поради щодо підвищення ефективності.
Навіщо реорганізовувати дані в електронні таблиці за допомогою OCR?
OCR повністю змінює правила гри. Він бере дані, заблоковані у ваших відсканованих документах, PDF-файлах і фотографіях, і перетворює їх на структуровані дані. Ми говоримо про готові до використання електронні таблиці. Це відкриває цілий новий світ можливостей.
Ось кілька причин, чому вам слід розглянути можливість використання оптичного розпізнавання символів для впорядкування даних у таблиці.
1. Простіший аналіз даних
Коли ваші дані витягнуті та акуратно організовані в рядки та стовпці в електронній таблиці, їх стане набагато легше аналізувати та працювати з ними. Ви можете швидко виявляти тенденції, сортувати, фільтрувати, використовувати формули та створювати зведені таблиці та діаграми. Цей рівень маніпулювання даними неможливий у відсканованих документах або PDF-файли.
2. Краща якість даних
Перетворення OCR в електронні таблиці дає чисті, структуровані дані. Дані можна перевірити та стандартизувати під час процесу OCR. Це покращує загальну якість і точність даних порівняно з неструктурованими сканованими документами.
3. Покращена можливість пошуку
Відскановані документи та зображення складні для пошуку — оптичне розпізнавання символів виправляє це, перетворюючи зображення на справжній текст. Потрапивши в електронну таблицю, дані стають доступними для пошуку. Ви можете миттєво знайти те, що вам потрібно.
4. Розширений обмін даними
Електронні таблиці, що містять витягнуті дані, можна легко надати іншим для співпраці. Дані тепер у стандартизованому форматі для багаторазового використання, а не в окремих зображеннях документів.
5. Можливості автоматизації
Дані електронних таблиць можна автоматизувати та оптимізувати між бізнес-системами. Завдяки можливості виводу файлів CSV витягнуті OCR дані можуть автоматично надходити в бази даних та інші бізнес-програми.
6. Пропустити ручну обробку
Вашій команді більше не потрібно буде вручну переписувати дані зі сканованих документів або виконувати виснажливий і неефективний процес копіювання та вставлення для PDF-файлів. Ви можете зменшити кількість помилок і заощадити час на очищення та перевірку даних, усунувши монотонні завдання введення даних. У результаті ваші співробітники можуть присвятити свої зусилля більш продуктивній та повноцінній роботі.
7. Масштабованість
Перетворення OCR добре масштабується, оскільки обсяги даних зростають. Незалежно від того, чи потрібно вам обробити сотні чи навіть тисячі сторінок документа, автоматизація OCR впорається з цим без проблем. Ручне введення даних не масштабується так швидко для великих обсягів.
Робочий процес OCR для електронних таблиць
Перетворення документів на електронні таблиці за допомогою оптичного розпізнавання символів стає простим, якщо виконати ці основні дії. Налаштувавши ефективний робочий процес, ви можете заощадити години ручної праці введення даних і швидко отримувати доступ до інформації, захищеної в PDF-файлах або відсканованих файлах.

Давай поринемо
1. Зберіть документи для OCR
Спочатку зберіть зображення документів, PDF-файли або відскановані документи, що містять дані, які потрібно витягти. Nanonets дозволяє легко імпортувати файли з багатьох джерел, включаючи електронну пошту, хмарне сховище, Dropbox, Google Drive, OneDrive тощо.

Ви також можете налаштувати папки або акаунти електронної пошти для автоматичної обробки будь-яких нових файлів або вхідних вкладень. Виклики API і інтеграція з іншим бізнес-програмним забезпеченням також може бути налаштована для бездоганної роботи вилучення даних.
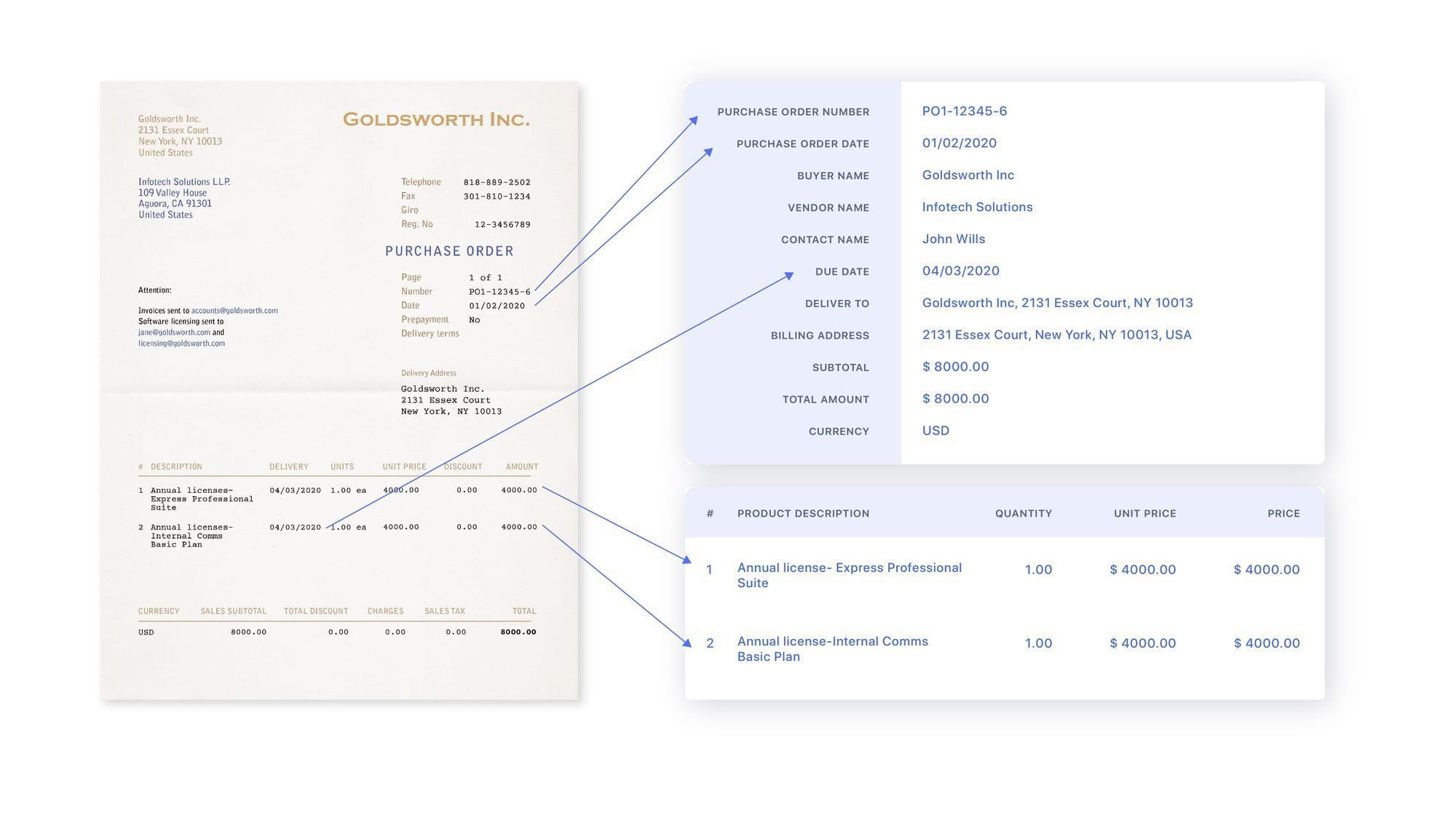
2. Визначте поля даних
Далі вкажіть поля або стовпці даних, які потрібно витягти, як-от номер рахунка-фактури, дата, ім’я клієнта, сума до сплати тощо. Nanonets пропонує різні моделі AI для таких типів документів, як рахунки, надходження, візитні карткиІ багато іншого.
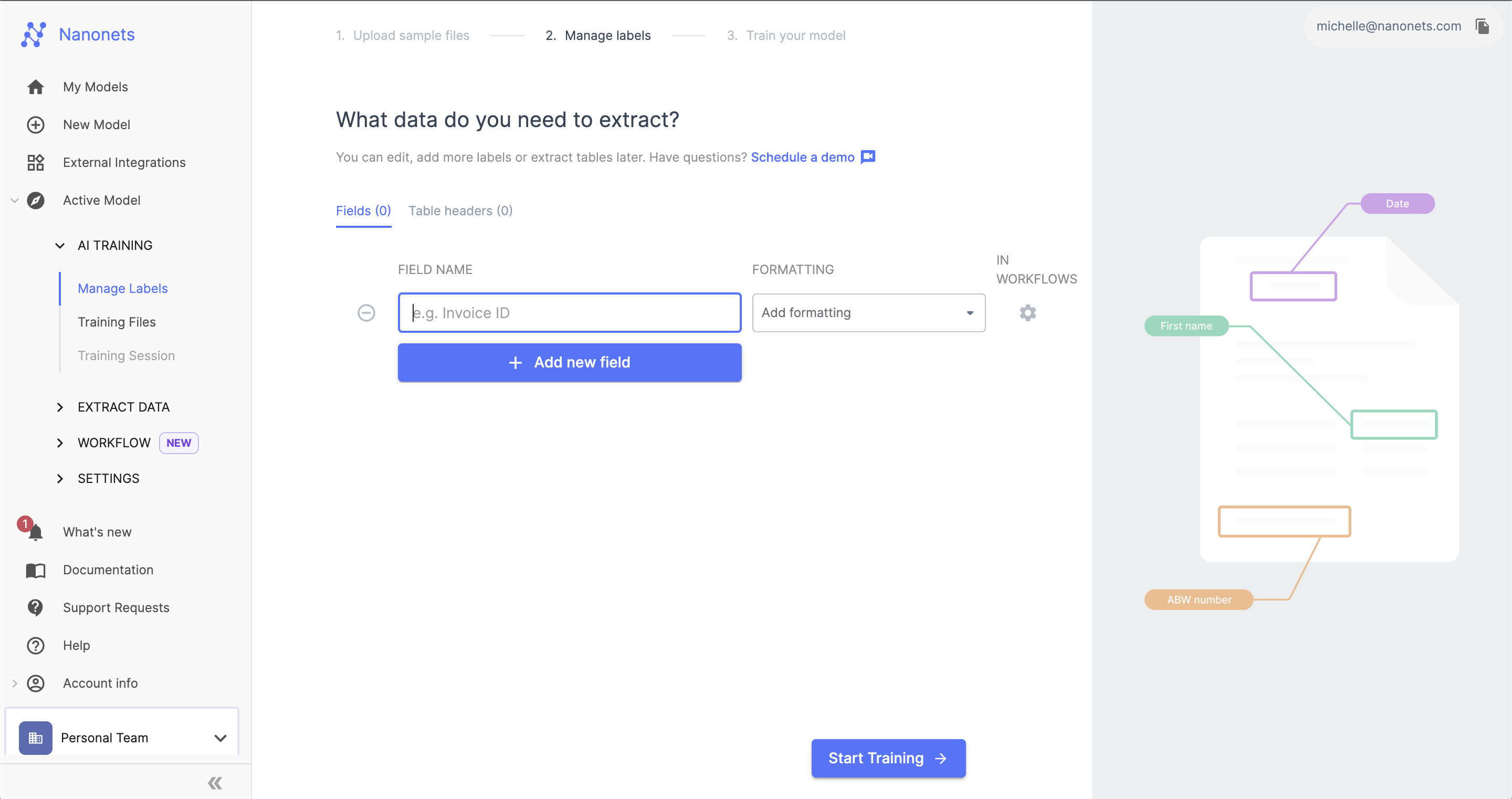
Команда готові моделі вже знають, як інтелектуально витягувати стандартні поля з кожного типу документа. Ви також можете налаштувати власні поля та навчити модель ШІ. Потім ви можете підготувати модель із кількома зразками. Просто намалюйте зони на зразках документів, щоб визначити, де знаходяться важливі дані.
Тепер ви готові запустити оптичне розпізнавання тексту та витягти дані з ваших документів. Nanonets використовує розширені алгоритми штучного інтелекту та машинного навчання для автоматичної ідентифікації та захоплення тексту зі складних макетів документів із високою точністю. ШІ «читає» кожен документ, витягує визначені поля та виводить структуровані дані, готові для експорту.

Після правильного налаштування полів даних і моделі AI цей крок буде повністю автоматизовано. За лаштунками технологія OCR перетворює відскановані зображення в текст. Потім інтелектуальне виявлення зон вибирає відповідні поля даних.
4. Перевірте та виправте дані
Перевірте точність отриманих даних. Nanonets полегшує це, оскільки дає змогу вносити виправлення безпосередньо в програмі перегляду документів. Для більш досвідчених користувачів ви також можете редагувати структуровані Вихід JSON.

Vous використання aussi можете оплатити автоматизована перевірка можливість налаштувати правила для перевірки отриманих даних. Наприклад, ви можете перевірити, чи входить дата в дійсний діапазон або числове значення нижче порогу. Будь-які проблеми перевірки позначаються для перевірки.
5. Експортуйте та інтегруйте дані електронної таблиці
Остаточний результат, що містить структуровані дані, витягнуті з ваших відсканованих документів або PDF-файлів, можна завантажити та використовувати для подальших цілей. Nanonets дозволяє експортувати його як a CSV, Файл Excel або JSON, який дає змогу легко імпортувати дані у бажану програму для роботи з електронними таблицями чи інше бізнес-програмне забезпечення.

Ви також можете напряму інтегрувати такі популярні програми, як Google Таблиці, QuickBooks, Salesforce тощо Інтеграція Zapier дозволяє підключатися до понад 5000 програм для безперебійного потоку даних. Ця інтеграція гарантує автоматичне оновлення ваших даних на всіх ваших платформах у режимі реального часу.
Як покращити процес OCR для електронної таблиці
Технологія OCR не ідеальна. Іноді може виникати проблема із скануванням низької якості, складними макетами або незвичними шрифтами. Але навіть незначні покращення процесу OCR можуть призвести до значної економії часу та коштів.
Припустімо, ви запускаєте страхова фірма який обробляє тисячі документів на день. Навіть підвищення точності OCR на 2% може заощадити сотні робочих годин на тиждень.
Нижче наведено кілька способів покращити процес розпізнавання тексту в електронну таблицю.
1. Покращте якість ваших сканувань
Переконайтеся, що документи, які ви скануєте, чіткі та розбірливі. Неякісні скани можуть призвести до помилок у процесі OCR. Отже, попередньо обробіть скановані зображення, щоб покращити якість зображення, перш ніж надсилати їх у систему OCR.

Поради щодо покращення якості сканування:
- Використовуйте сканер з високою роздільною здатністю (мінімум 300 dpi). Це фіксує дрібніші деталі, які можуть допомогти системі OCR точно розпізнавати символи.
- Переконайтеся, що сторінки правильно вирівняні та не перекошені. Усунення перекосів виправляє сканування під нахилом.
- Перевірте яскравість і контраст сканування. Відрегулюйте рівні, щоб текст був чітко видимим і не був занадто світлим або темним.
- Очистіть скло сканера, щоб уникнути пилу, плям або артефактів на сканованих зображеннях.
- Використовуйте Adobe Scan або подібні програми, щоб робити високоякісні скановані зображення за допомогою смартфона.
- Використовуйте такі методи покращення зображення, як збільшення різкості, зменшення шуму та бінаризація.
2. Стандартизуйте свої документи
Узгодженість компонування та дизайну документа може значно підвищити точність OCR. Якщо можливо, стандартизуйте формат документи, які ви обробляєте. Це означає збереження полів даних у точному місці в кожному документі, використання узгоджених шрифтів і розмірів, а також підтримку чистого, лаконічного макета.

Ось кілька порад щодо стандартизації документів:
- Використовуйте узгоджений шаблон для всіх документів одного типу.
- Зберігайте важливі поля даних в одному місці в кожному документі.
- Використовуйте чіткі, розбірливі шрифти та уникайте художніх або незвичних шрифтів.
- Уникайте безладу та зберігайте макет чистим і простим.
- Обмежте використання зображень, логотипів і графіки біля важливих текстових полів.
- Використовуйте висококонтрастні кольори для тексту та фону, щоб покращити розбірливість.
3. Інвестуйте в систему OCR на основі штучного інтелекту
Ці системи використовують алгоритми машинного навчання, щоб навчатися з кожного обробленого документа, постійно покращуючи свою здатність розпізнавати та витягувати відповідні дані.

Наномережі є яскравим прикладом OCR на основі AI система. Він пропонує попередньо підготовлені моделі для різних типів документів і дозволяє налаштувати модель відповідно до ваших потреб. Чим більше даних він обробляє, тим краще він розпізнає закономірності та точно витягує дані.
Крім того, можливості розпізнавання мови та розуміння контексту систем оптичного розпізнавання символів на основі штучного інтелекту дозволяють їм обробляти документи різними мовами, валютами, податковими форматами тощо. Це робить їх надзвичайно універсальними та адаптованими до різноманітних потреб бізнесу.
4. Налаштуйте автоматизовані робочі процеси
Автоматизація повторюваних ручних кроків у робочому процесі OCR може підвищити ефективність і мінімізувати помилки. Наприклад, ви можете налаштувати правила автоматичного імпорту, які гарантуватимуть, що система OCR автоматично оброблятиме кожен надісланий рахунок-фактуру [захищено електронною поштою].
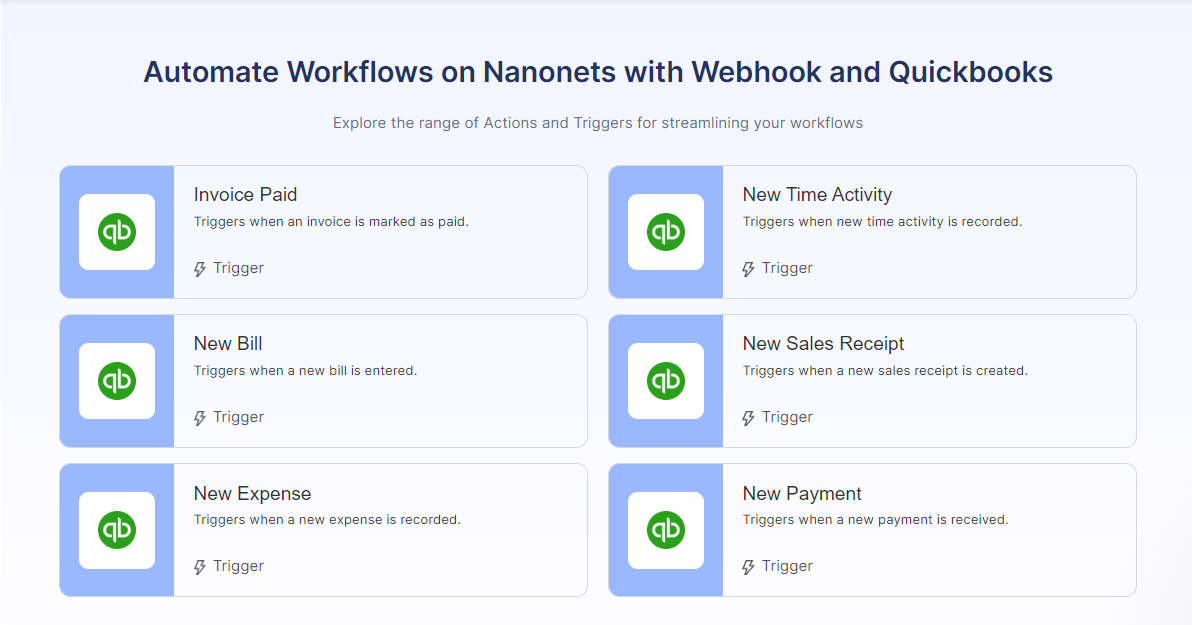
Інтеграція з програмним забезпеченням для бізнесу, наприклад ERP забезпечують безперебійний потік даних. Витягнуті дані електронної таблиці можуть автоматично синхронізуватися з подальшими базами даних. Автоматичні правила перевірки допомагають завчасно виявити будь-які помилки вилучення. Робочі процеси можуть направляти документи, які потребують перевірки, відповідному персоналу. Автоматичні сповіщення та нагадування гарантують, що кінцевий термін не буде пропущено.
Заключні думки
Технологія оптичного розпізнавання символів (OCR) кардинально змінила спосіб вилучення та роботи з даними зі сканованих документів і PDF-файлів. Завдяки перетворенню зображень у структуровані дані електронної таблиці OCR усуває виснажливий ручний ввід, одночасно розширюючи можливості аналізу.
Як зазначено в цьому посібнику, створення ефективного робочого процесу OCR за допомогою правильних інструментів, таких як Nanonets, може заощадити величезну кількість часу. Незначне підвищення точності також швидко перетворюється на значну економію.
Хочете побачити, як OCR може прискорити робочі процеси вашого бізнесу? Nanonets пропонує безкоштовну версію для тестування вилучення даних із ваших документів за допомогою штучного інтелекту. Перетворення PDF-таблиць або сканованих рахунків-фактур на редаговані аркуші Excel ще ніколи не було таким простим. Зареєструйтеся зараз, щоб почати!
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://nanonets.com/blog/ocr-to-spreadsheet/

