บทนำ
คุณกำลังทำงานในบริษัทที่ปรึกษาในฐานะนักวิทยาศาสตร์ข้อมูล โครงการที่คุณได้รับมอบหมายให้มีข้อมูลจากนักศึกษาที่เพิ่งจบหลักสูตรการเงิน บริษัทการเงินที่จัดหลักสูตรต้องการทราบว่ามีปัจจัยทั่วไปที่มีอิทธิพลต่อนักเรียนในการซื้อหลักสูตรเดียวกันหรือซื้อหลักสูตรที่แตกต่างกันหรือไม่ ด้วยการทำความเข้าใจปัจจัยเหล่านี้ บริษัทสามารถสร้างโปรไฟล์นักเรียน จำแนกนักเรียนแต่ละคนตามโปรไฟล์ และแนะนำรายชื่อหลักสูตร
เมื่อตรวจสอบข้อมูลจากกลุ่มนักเรียนต่างๆ คุณพบการจัดการสามจุด ดังใน 1, 2 และ 3 ด้านล่าง:
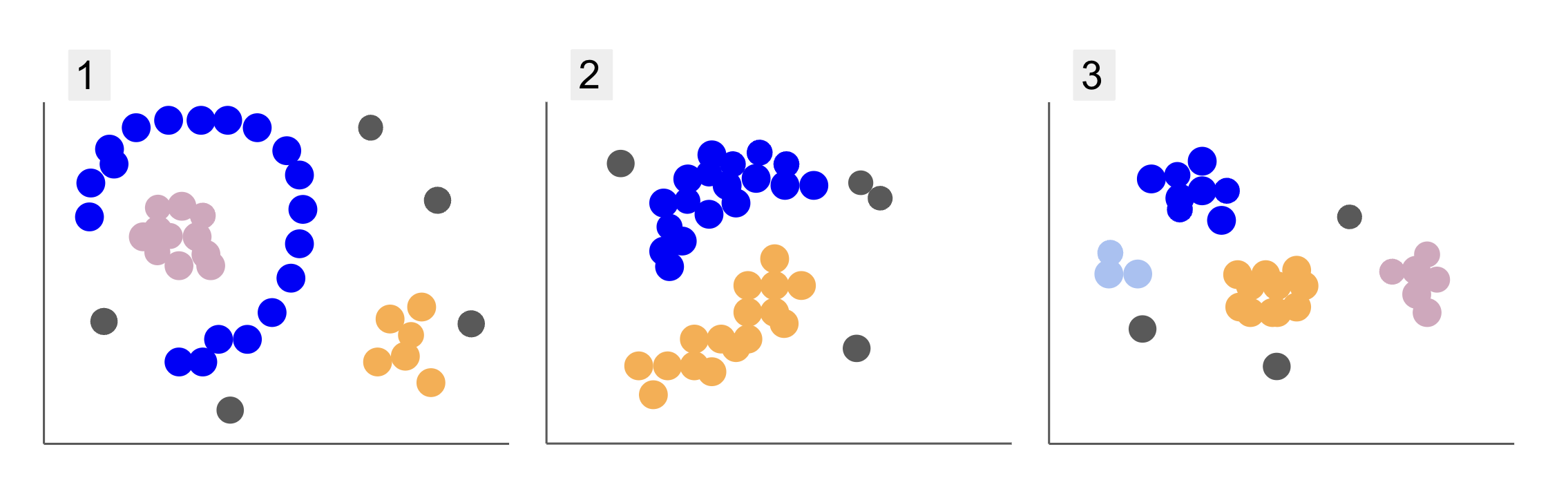
สังเกตว่าในพล็อตที่ 1 มีจุดสีม่วงที่จัดอยู่ในครึ่งวงกลมโดยมีมวลของจุดสีชมพูอยู่ภายในวงกลมนั้น จุดสีส้มที่มีความเข้มข้นเล็กน้อยอยู่นอกครึ่งวงกลมนั้น และจุดสีเทาอีก XNUMX จุดซึ่งอยู่ห่างจากจุดอื่นๆ ทั้งหมด
ในพล็อต 2 มีจุดสีม่วงมวลกลม จุดสีส้มอีกจุดหนึ่ง และยังมีจุดสีเทาอีกสี่จุดซึ่งอยู่ห่างจากจุดอื่นๆ ทั้งหมด
และในพล็อตที่ 3 เราสามารถเห็นความเข้มข้นของจุดสี่จุด สีม่วง สีฟ้า สีส้ม สีชมพู และจุดสีเทาอีกสามจุดที่อยู่ไกลออกไป
ทีนี้ ถ้าคุณต้องเลือกโมเดลที่สามารถเข้าใจข้อมูลของนักเรียนใหม่และกำหนดกลุ่มที่คล้ายกัน มีอัลกอริทึมการจัดกลุ่มที่สามารถให้ผลลัพธ์ที่น่าสนใจกับข้อมูลประเภทนั้นหรือไม่
เมื่ออธิบายโครงเรื่อง เราได้กล่าวถึงคำเช่น มวลของจุด และ ความเข้มข้นของคะแนนซึ่งแสดงว่ามีพื้นที่ในกราฟทั้งหมดที่มีความหนาแน่นมากกว่า เรายังอ้างถึง กลม และ ครึ่งวงกลม รูปร่างซึ่งยากต่อการระบุโดยการวาดเส้นตรงหรือเพียงแค่ตรวจสอบจุดที่ใกล้เคียงที่สุด นอกจากนี้ยังมีจุดที่ห่างไกลซึ่งน่าจะเบี่ยงเบนไปจากการกระจายข้อมูลหลัก ทำให้เกิดความท้าทายมากขึ้นหรือ สัญญาณรบกวน เมื่อกำหนดกลุ่ม
อัลกอริทึมตามความหนาแน่นที่สามารถกรองสัญญาณรบกวน เช่น ดีบีเอสแคน (Dความหนาแน่น-Based Sลาน Cความแวววาวของ Aใบสมัครด้วย Noise) เป็นตัวเลือกที่ดีสำหรับสถานการณ์ที่มีพื้นที่หนาแน่น รูปทรงโค้งมน และเสียงรบกวน
เกี่ยวกับ DBSCAN
DBSCAN เป็นหนึ่งในอัลกอริธึมที่มีการอ้างถึงมากที่สุดในงานวิจัย มีการตีพิมพ์ครั้งแรกในปี 1996 นี่คือ กระดาษ DBSCAN ต้นฉบับ. ในบทความนี้ นักวิจัยได้แสดงให้เห็นว่าอัลกอริทึมสามารถระบุคลัสเตอร์เชิงพื้นที่ที่ไม่ใช่เชิงเส้นและจัดการข้อมูลในมิติที่สูงขึ้นได้อย่างมีประสิทธิภาพได้อย่างไร
แนวคิดหลักที่อยู่เบื้องหลัง DBSCAN คือมีจำนวนจุดขั้นต่ำที่จะอยู่ในระยะทางที่กำหนดหรือ รัศมี จากจุดคลัสเตอร์ "ศูนย์กลาง" ที่สุดเรียกว่า จุดสำคัญ. จุดที่อยู่ในรัศมีนั้นคือจุดย่าน และจุดบนขอบของย่านนั้นคือจุด จุดชายแดน or จุดขอบเขต. รัศมี หรือ ระยะใกล้ ก็เรียก ย่านเอปไซลอน, ε-พื้นที่ใกล้เคียง หรือเพียงแค่ ε (สัญลักษณ์ของอักษรกรีกเอปไซลอน)
นอกจากนี้ เมื่อมีจุดที่ไม่ใช่จุดหลักหรือจุดชายแดนเนื่องจากเกินรัศมีของคลัสเตอร์ที่กำหนดและไม่มีจำนวนจุดขั้นต่ำที่จะเป็นจุดหลัก จะถือว่าจุดเหล่านั้น จุดรบกวน.
หมายความว่าเรามีคะแนนอยู่ XNUMX ประเภท ได้แก่ แกน, ชายแดน และ สัญญาณรบกวน. นอกจากนี้ สิ่งสำคัญคือต้องสังเกตว่าแนวคิดหลักนั้นขึ้นอยู่กับรัศมีหรือระยะทางเป็นพื้นฐาน ซึ่งทำให้ DBSCAN เหมือนกับโมเดลการจัดกลุ่มส่วนใหญ่ ขึ้นอยู่กับเมตริกระยะทางนั้น เมตริกนี้อาจเป็น Euclidean, Manhattan, Mahalanobis และอื่นๆ อีกมากมาย ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องเลือกมาตรวัดระยะทางที่เหมาะสมโดยคำนึงถึงบริบทของข้อมูล ตัวอย่างเช่น หากคุณกำลังใช้ข้อมูลระยะทางการขับขี่จาก GPS อาจเป็นเรื่องที่น่าสนใจหากใช้เมตริกที่คำนึงถึงรูปแบบถนน เช่น ระยะทางแมนฮัตตัน

หมายเหตุ เนื่องจาก DBSCAN จับคู่จุดที่ก่อให้เกิดสัญญาณรบกวน จึงสามารถใช้เป็นอัลกอริธึมการตรวจจับค่าผิดปกติได้ ตัวอย่างเช่น หากคุณกำลังพยายามระบุว่าธุรกรรมธนาคารใดที่อาจเป็นการฉ้อโกงและมีอัตราการทำธุรกรรมฉ้อโกงเพียงเล็กน้อย DBSCAN อาจเป็นวิธีแก้ปัญหาในการระบุจุดเหล่านั้น
ในการค้นหาจุดหลัก ก่อนอื่น DBSCAN จะเลือกจุดหนึ่งโดยการสุ่ม แมปจุดทั้งหมดภายในย่าน ε และเปรียบเทียบจำนวนเพื่อนบ้านของจุดที่เลือกกับจำนวนจุดต่ำสุด หากจุดที่เลือกมีจำนวนเพื่อนบ้านเท่ากันหรือมากกว่าจำนวนจุดต่ำสุด จุดนั้นจะถูกทำเครื่องหมายเป็นจุดหลัก จุดหลักนี้และจุดใกล้เคียงจะประกอบเป็นคลัสเตอร์แรก
อัลกอริทึมจะตรวจสอบแต่ละจุดของคลัสเตอร์แรกและดูว่ามีจุดข้างเคียงจำนวนเท่ากันหรือมากกว่าจำนวนจุดขั้นต่ำภายใน ε หรือไม่ หากเป็นเช่นนั้น คะแนนข้างเคียงเหล่านั้นจะถูกเพิ่มไปยังคลัสเตอร์แรกด้วย กระบวนการนี้จะดำเนินต่อไปจนกว่าคะแนนของกลุ่มแรกจะมีเพื่อนบ้านน้อยกว่าจำนวนคะแนนขั้นต่ำภายใน ε เมื่อสิ่งนั้นเกิดขึ้น อัลกอริทึมจะหยุดเพิ่มจุดให้กับคลัสเตอร์นั้น ระบุจุดหลักอื่นนอกคลัสเตอร์นั้น และสร้างคลัสเตอร์ใหม่สำหรับจุดหลักใหม่นั้น
จากนั้น DBSCAN จะทำกระบวนการคลัสเตอร์แรกซ้ำเพื่อค้นหาจุดทั้งหมดที่เชื่อมต่อกับจุดหลักใหม่ของคลัสเตอร์ที่สองจนกว่าจะไม่มีจุดเพิ่มในคลัสเตอร์นั้น จากนั้นจะพบกับจุดหลักอื่นและสร้างคลัสเตอร์ที่สาม หรือวนซ้ำผ่านจุดทั้งหมดที่ยังไม่เคยดูมาก่อน ถ้าจุดเหล่านี้อยู่ห่างจากคลัสเตอร์ ε จุดเหล่านี้จะถูกเพิ่มเข้าไปในคลัสเตอร์นั้น และกลายเป็นจุดชายแดน หากไม่เป็นเช่นนั้น จะถือว่าเป็นจุดรบกวน
คำแนะนำ: มีกฎและการสาธิตทางคณิตศาสตร์มากมายที่เกี่ยวข้องกับแนวคิดเบื้องหลัง DBSCAN หากคุณต้องการเจาะลึกยิ่งขึ้น คุณอาจต้องการดูเอกสารต้นฉบับซึ่งมีลิงก์ด้านบน
เป็นเรื่องน่าสนใจที่จะทราบว่าอัลกอริทึม DBSCAN ทำงานอย่างไร โชคดีที่ไม่จำเป็นต้องเขียนโค้ดอัลกอริทึม เมื่อไลบรารี Scikit-Learn ของ Python ถูกนำไปใช้งานแล้ว
มาดูกันว่ามันใช้งานจริงได้อย่างไร!
การนำเข้าข้อมูลเพื่อทำคลัสเตอร์
เพื่อดูว่า DBSCAN ทำงานอย่างไรในทางปฏิบัติ เราจะเปลี่ยนโครงการเล็กน้อยและใช้ชุดข้อมูลลูกค้าขนาดเล็กที่มีประเภท อายุ รายได้ต่อปี และคะแนนการใช้จ่ายของลูกค้า 200 ราย
คะแนนการใช้จ่ายอยู่ในช่วงตั้งแต่ 0 ถึง 100 และแสดงถึงความถี่ที่บุคคลใช้จ่ายเงินในห้างสรรพสินค้าในระดับตั้งแต่ 1 ถึง 100 กล่าวอีกนัยหนึ่ง หากลูกค้ามีคะแนนเป็น 0 พวกเขาไม่เคยใช้เงิน และถ้าคะแนนเท่ากับ 100 พวกเขาเป็นผู้ใช้จ่ายสูงสุด
หมายเหตุ คุณสามารถดาวน์โหลดชุดข้อมูล โปรดคลิกที่นี่เพื่ออ่านรายละเอียดเพิ่มเติม.
หลังจากดาวน์โหลดชุดข้อมูลแล้ว คุณจะเห็นว่าเป็นไฟล์ CSV (ค่าที่คั่นด้วยเครื่องหมายจุลภาค) ที่เรียกว่า ช้อปปิ้ง data.csvเราจะโหลดลงใน DataFrame โดยใช้ Pandas และจัดเก็บไว้ใน customer_data ตัวแปร:
import pandas as pd path_to_file = '../../datasets/dbscan/dbscan-with-python-and-scikit-learn-shopping-data.csv'
customer_data = pd.read_csv(path_to_file)
หากต้องการดูข้อมูลห้าแถวแรกของเรา คุณสามารถดำเนินการได้ customer_data.head():
ผลลัพธ์นี้ใน:
CustomerID Genre Age Annual Income (k$) Spending Score (1-100)
0 1 Male 19 15 39
1 2 Male 21 15 81
2 3 Female 20 16 6
3 4 Female 23 16 77
4 5 Female 31 17 40
จากการตรวจสอบข้อมูล เราสามารถเห็นหมายเลขรหัสลูกค้า ประเภท อายุ รายได้เป็น k$ และคะแนนการใช้จ่าย โปรดทราบว่าตัวแปรเหล่านี้บางส่วนหรือทั้งหมดจะถูกใช้ในโมเดล เช่น ถ้าเราจะใช้ Age และ Spending Score (1-100) ในฐานะตัวแปรสำหรับ DBSCAN ซึ่งใช้มาตรวัดระยะทาง สิ่งสำคัญคือต้องนำมาเป็นมาตราส่วนทั่วไปเพื่อหลีกเลี่ยงการบิดเบือนเนื่องจาก Age มีหน่วยวัดเป็นปีและ Spending Score (1-100) มีช่วงจำกัดตั้งแต่ 0 ถึง 100 ซึ่งหมายความว่าเราจะดำเนินการปรับขนาดข้อมูลบางประเภท
นอกจากนี้ เรายังสามารถตรวจสอบได้ว่าข้อมูลต้องการการประมวลผลล่วงหน้าเพิ่มเติมนอกเหนือจากการปรับขนาดหรือไม่ โดยดูว่าประเภทของข้อมูลสอดคล้องกันหรือไม่ และตรวจสอบว่ามีค่าใดๆ ที่ขาดหายไปซึ่งจำเป็นต้องได้รับการปฏิบัติโดยการดำเนินการของ Panda info() วิธี:
customer_data.info()
สิ่งนี้แสดง:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 200 entries, 0 to 199
Data columns (total 5 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 CustomerID 200 non-null int64 1 Genre 200 non-null object 2 Age 200 non-null int64 3 Annual Income (k$) 200 non-null int64 4 Spending Score (1-100) 200 non-null int64 dtypes: int64(4), object(1)
memory usage: 7.9+ KB
เราสามารถสังเกตได้ว่าไม่มีค่าใดขาดหายไปเนื่องจากมีรายการที่ไม่เป็นค่าว่าง 200 รายการสำหรับคุณลักษณะลูกค้าแต่ละรายการ นอกจากนี้ เรายังเห็นได้ว่าเฉพาะคอลัมน์ประเภทเท่านั้นที่มีเนื้อหาข้อความ เนื่องจากเป็นตัวแปรหมวดหมู่ ซึ่งแสดงเป็น objectและคุณสมบัติอื่นๆ ทั้งหมดเป็นตัวเลขของประเภท int64. ดังนั้น ในแง่ของความสอดคล้องของประเภทข้อมูลและการไม่มีค่า Null ข้อมูลของเราพร้อมสำหรับการวิเคราะห์เพิ่มเติม
เราสามารถดำเนินการแสดงภาพข้อมูลและพิจารณาว่าคุณสมบัติใดที่น่าสนใจที่จะใช้ใน DBSCAN หลังจากเลือกคุณสมบัติเหล่านั้นแล้ว เราสามารถปรับขนาดได้
ชุดข้อมูลลูกค้านี้เหมือนกับชุดที่ใช้ในคู่มือขั้นสุดท้ายเกี่ยวกับการจัดกลุ่มแบบลำดับชั้น หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับข้อมูลนี้ วิธีการสำรวจ และการวัดระยะทาง คุณสามารถดูได้ที่ คู่มือขั้นสุดท้ายสำหรับการจัดคลัสเตอร์แบบลำดับชั้นด้วย Python และ Scikit-Learn!
การแสดงข้อมูล
โดยใช้ของซีบอร์น pairplot()เราสามารถลงจุดกราฟกระจายสำหรับคุณลักษณะแต่ละอย่างรวมกันได้ เนื่องจาก CustomerID เป็นเพียงการระบุตัวตนและไม่ใช่คุณลักษณะ เราจะลบออกด้วย drop() ก่อนวางแผน:
import seaborn as sns customer_data = customer_data.drop('CustomerID', axis=1) sns.pairplot(customer_data);
ผลลัพธ์นี้:
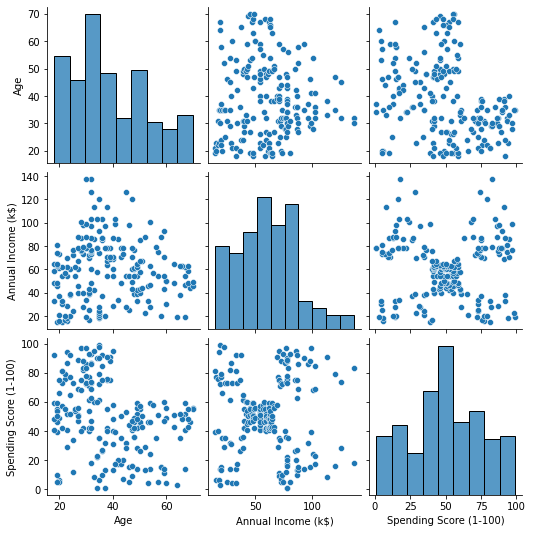
เมื่อดูที่การผสมผสานของคุณสมบัติที่ผลิตโดย pairplotกราฟของ Annual Income (k$) กับ Spending Score (1-100) ดูเหมือนว่าจะแสดงประมาณ 5 กลุ่มของจุด นี่ดูเหมือนจะเป็นการผสมผสานคุณสมบัติที่มีแนวโน้มมากที่สุด เราสามารถสร้างรายชื่อโดยเลือกจาก customer_data DataFrame และจัดเก็บการเลือกไว้ในไฟล์ customer_data ตัวแปรอีกครั้งเพื่อใช้ในโมเดลในอนาคตของเรา
selected_cols = ['Annual Income (k$)', 'Spending Score (1-100)']
customer_data = customer_data[selected_cols]
หลังจากเลือกคอลัมน์แล้ว เราสามารถดำเนินการปรับขนาดที่กล่าวถึงในส่วนก่อนหน้าได้ เพื่อนำคุณสมบัติมาชั่งเท่ากันหรือ วางมาตรฐาน เราสามารถนำเข้า Scikit-Learn ได้ StandardScaler, สร้างมัน, พอดีกับข้อมูลของเราเพื่อคำนวณค่าเฉลี่ยและส่วนเบี่ยงเบนมาตรฐาน และแปลงข้อมูลโดยการลบค่าเฉลี่ยและหารด้วยส่วนเบี่ยงเบนมาตรฐาน สามารถทำได้ในขั้นตอนเดียวด้วยการ fit_transform() วิธี:
from sklearn.preprocessing import StandardScaler ss = StandardScaler() scaled_data = ss.fit_transform(customer_data)
ตอนนี้ตัวแปรได้รับการปรับขนาดแล้ว และเราสามารถตรวจสอบได้โดยเพียงแค่พิมพ์เนื้อหาของ scaled_data ตัวแปร. นอกจากนี้ เรายังสามารถเพิ่มเข้าไปใหม่ได้อีกด้วย scaled_customer_data DataFrame พร้อมกับชื่อคอลัมน์และใช้ไฟล์ head() วิธีการอีกครั้ง:
scaled_customer_data = pd.DataFrame(columns=selected_cols, data=scaled_data)
scaled_customer_data.head()
ผลลัพธ์นี้:
Annual Income (k$) Spending Score (1-100)
0 -1.738999 -0.434801
1 -1.738999 1.195704
2 -1.700830 -1.715913
3 -1.700830 1.040418
4 -1.662660 -0.395980 ข้อมูลนี้พร้อมสำหรับการจัดกลุ่มแล้ว! เมื่อแนะนำ DBSCAN เราได้กล่าวถึงจำนวนคะแนนขั้นต่ำและเอปไซลอน ต้องเลือกค่าทั้งสองนี้ก่อนที่จะสร้างแบบจำลอง มาดูกันว่าทำอย่างไร
การเลือกขั้นต่ำ ตัวอย่างและเอปไซลอน
ในการเลือกจำนวนจุดต่ำสุดสำหรับการทำคลัสเตอร์ DBSCAN มีกฎง่ายๆ ซึ่งระบุว่าต้องเท่ากับหรือสูงกว่าจำนวนมิติในข้อมูลบวกหนึ่ง ดังใน:
$$
ข้อความ{นาที จุด} >= ข้อความ{ขนาดข้อมูล} + 1
$$
มิติข้อมูลคือจำนวนคอลัมน์ในดาต้าเฟรม เราใช้ 2 คอลัมน์ ดังนั้นค่าต่ำสุด คะแนนควรเป็น 2+1 ซึ่งก็คือ 3 หรือสูงกว่า สำหรับตัวอย่างนี้ ลองใช้ 5 นาที คะแนน.
$$
ข้อความ{5 (จุดต่ำสุด)} >= ข้อความ{2 (มิติข้อมูล)} + 1
$$
ดูคู่มือเชิงปฏิบัติสำหรับการเรียนรู้ Git ที่มีแนวทางปฏิบัติที่ดีที่สุด มาตรฐานที่ยอมรับในอุตสาหกรรม และเอกสารสรุปรวม หยุดคำสั่ง Googling Git และจริงๆ แล้ว เรียน มัน!
ตอนนี้ ในการเลือกค่าสำหรับ ε มีวิธีการที่ เพื่อนบ้านที่ใกล้ที่สุด อัลกอริทึมถูกใช้เพื่อค้นหาระยะทางของจำนวนจุดที่ใกล้ที่สุดที่กำหนดไว้ล่วงหน้าสำหรับแต่ละจุด จำนวนเพื่อนบ้านที่กำหนดไว้ล่วงหน้าคือขั้นต่ำ คะแนนที่เราเพิ่งเลือกลบ 1 ในกรณีของเรา อัลกอริทึมจะหา 5-1 หรือ 4 คะแนนที่ใกล้ที่สุดสำหรับแต่ละจุดของข้อมูลของเรา นั่นคือ k-เพื่อนบ้าน และเรา k เท่ากับ 4
$$
ข้อความ{k-neighbors} = ข้อความ{นาที คะแนน} – 1
$$
หลังจากหาเพื่อนบ้านได้แล้ว เราจะเรียงลำดับระยะทางจากมากไปน้อย และวางแผนระยะห่างของแกน y และจุดบนแกน x เมื่อดูที่โครงเรื่อง เราจะพบตำแหน่งที่คล้ายกับการงอข้อศอก และจุดแกน y ที่อธิบายว่าการงอข้อศอกคือค่า ε ที่แนะนำ
หมายเหตุ: เป็นไปได้ว่ากราฟสำหรับหาค่า ε จะมี "การงอข้อศอก" อย่างใดอย่างหนึ่งหรือมากกว่า ไม่ว่าจะใหญ่หรือเล็ก เมื่อเป็นเช่นนั้น คุณสามารถหาค่า ทดสอบ และเลือกค่าที่มีผลลัพธ์ที่อธิบายคลัสเตอร์ได้ดีที่สุด โดยดูที่เมตริกของแปลง
ในการดำเนินการตามขั้นตอนเหล่านี้ เราสามารถนำเข้าอัลกอริทึม พอดีกับข้อมูล จากนั้นเราสามารถแยกระยะทางและดัชนีของแต่ละจุดด้วย kneighbors() วิธี:
from sklearn.neighbors import NearestNeighbors
import numpy as np nn = NearestNeighbors(n_neighbors=4) nbrs = nn.fit(scaled_customer_data)
distances, indices = nbrs.kneighbors(scaled_customer_data)
หลังจากหาระยะทางได้แล้ว เราก็สามารถเรียงลำดับจากมากไปน้อยได้ เนื่องจากคอลัมน์แรกของอาร์เรย์ Distances เป็นจุดของตัวเอง (หมายถึงทั้งหมดเป็น 0) และคอลัมน์ที่สองประกอบด้วยระยะทางที่น้อยที่สุด ตามด้วยคอลัมน์ที่สามซึ่งมีระยะทางมากกว่าคอลัมน์ที่สอง เป็นต้น เราสามารถเลือกเฉพาะ ค่าของคอลัมน์ที่สองและเก็บไว้ใน distances ตัวแปร:
distances = np.sort(distances, axis=0)
distances = distances[:,1] ตอนนี้เรามีระยะทางที่เล็กที่สุดที่เรียงลำดับแล้ว เราสามารถนำเข้าได้ matplotlibวางแผนระยะทางและวาดเส้นสีแดงตรงที่ "ข้อศอกงอ" คือ:
import matplotlib.pyplot as plt plt.figure(figsize=(6,3))
plt.plot(distances)
plt.axhline(y=0.24, color='r', linestyle='--', alpha=0.4) plt.title('Kneighbors distance graph')
plt.xlabel('Data points')
plt.ylabel('Epsilon value')
plt.show();
นี่คือผลลัพธ์:
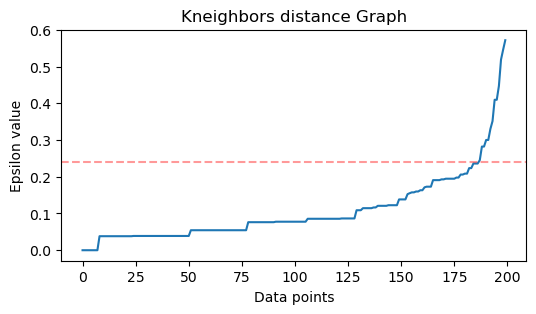
สังเกตว่าเมื่อวาดเส้นเราจะพบค่า ε ในกรณีนี้คือ 0.24.
ในที่สุดเราก็มีคะแนนขั้นต่ำและ ε ด้วยตัวแปรทั้งสอง เราสามารถสร้างและรันโมเดล DBSCAN ได้
การสร้างแบบจำลอง DBSCAN
ในการสร้างโมเดล เราสามารถนำเข้าจาก Scikit-Learn สร้างด้วย ε ซึ่งเหมือนกับ eps อาร์กิวเมนต์และจุดต่ำสุดที่เป็น mean_samples การโต้แย้ง. เราก็สามารถเก็บมันไว้ในตัวแปรได้ เรียกมันว่า dbs และพอดีกับข้อมูลที่ปรับขนาด:
from sklearn.cluster import DBSCAN dbs = DBSCAN(eps=0.24, min_samples=5)
dbs.fit(scaled_customer_data)
เช่นเดียวกับที่โมเดล DBSCAN ของเราได้รับการสร้างและฝึกอบรมเกี่ยวกับข้อมูล! ในการแยกผลลัพธ์ เราเข้าถึง labels_ คุณสมบัติ. เรายังสามารถสร้างใหม่ได้ labels คอลัมน์ใน scaled_customer_data dataframe และเติมด้วยป้ายกำกับที่คาดการณ์ไว้:
labels = dbs.labels_ scaled_customer_data['labels'] = labels
scaled_customer_data.head()
นี่คือผลลัพธ์สุดท้าย:
Annual Income (k$) Spending Score (1-100) labels
0 -1.738999 -0.434801 -1
1 -1.738999 1.195704 0
2 -1.700830 -1.715913 -1
3 -1.700830 1.040418 0
4 -1.662660 -0.395980 -1
สังเกตว่าเรามีฉลากด้วย -1 ค่า; เหล่านี้เป็น จุดรบกวนที่ไม่ได้อยู่ในคลัสเตอร์ใดๆ หากต้องการทราบจำนวนจุดรบกวนที่อัลกอริทึมพบ เราสามารถนับจำนวนครั้งที่ค่า -1 ปรากฏในรายการป้ายกำกับของเรา:
labels_list = list(scaled_customer_data['labels'])
n_noise = labels_list.count(-1)
print("Number of noise points:", n_noise)
ผลลัพธ์นี้:
Number of noise points: 62
เรารู้แล้วว่า 62 คะแนนจากข้อมูลเดิมของเรา 200 คะแนนถือเป็นสัญญาณรบกวน นี่เป็นสัญญาณรบกวนจำนวนมาก ซึ่งบ่งชี้ว่าบางทีการจัดกลุ่ม DBSCAN ไม่ได้ถือว่าหลายจุดเป็นส่วนหนึ่งของคลัสเตอร์ เราจะเข้าใจว่าเกิดอะไรขึ้นในไม่ช้าเมื่อเราวางแผนข้อมูล
ในตอนแรกเมื่อเราสังเกตข้อมูล ดูเหมือนว่าจะมีกลุ่มของจุด 5 กลุ่ม หากต้องการทราบจำนวนคลัสเตอร์ที่ DBSCAN ก่อตัวขึ้น เราสามารถนับจำนวนป้ายกำกับที่ไม่ใช่ -1 มีหลายวิธีในการเขียนโค้ดนั้น ที่นี่ เราได้เขียน for loop ซึ่งจะทำงานกับข้อมูลที่ DBSCAN พบคลัสเตอร์จำนวนมากด้วย:
total_labels = np.unique(labels) n_labels = 0
for n in total_labels: if n != -1: n_labels += 1
print("Number of clusters:", n_labels)
ผลลัพธ์นี้:
Number of clusters: 6
เราจะเห็นว่าอัลกอริทึมคาดการณ์ว่าข้อมูลจะมี 6 กลุ่ม โดยมีจุดรบกวนหลายจุด ลองจินตนาการว่าด้วยการพล็อตด้วยซีบอร์น scatterplot:
sns.scatterplot(data=scaled_customer_data, x='Annual Income (k$)', y='Spending Score (1-100)', hue='labels', palette='muted').set_title('DBSCAN found clusters');
ผลลัพธ์นี้ใน:

เมื่อดูที่โครงเรื่อง เราจะเห็นว่า DBSCAN จับจุดที่มีการเชื่อมต่อหนาแน่นกว่า และจุดที่อาจถือได้ว่าเป็นส่วนหนึ่งของคลัสเตอร์เดียวกันคือสัญญาณรบกวนหรือพิจารณาว่าเป็นคลัสเตอร์ขนาดเล็กอีกอันหนึ่ง
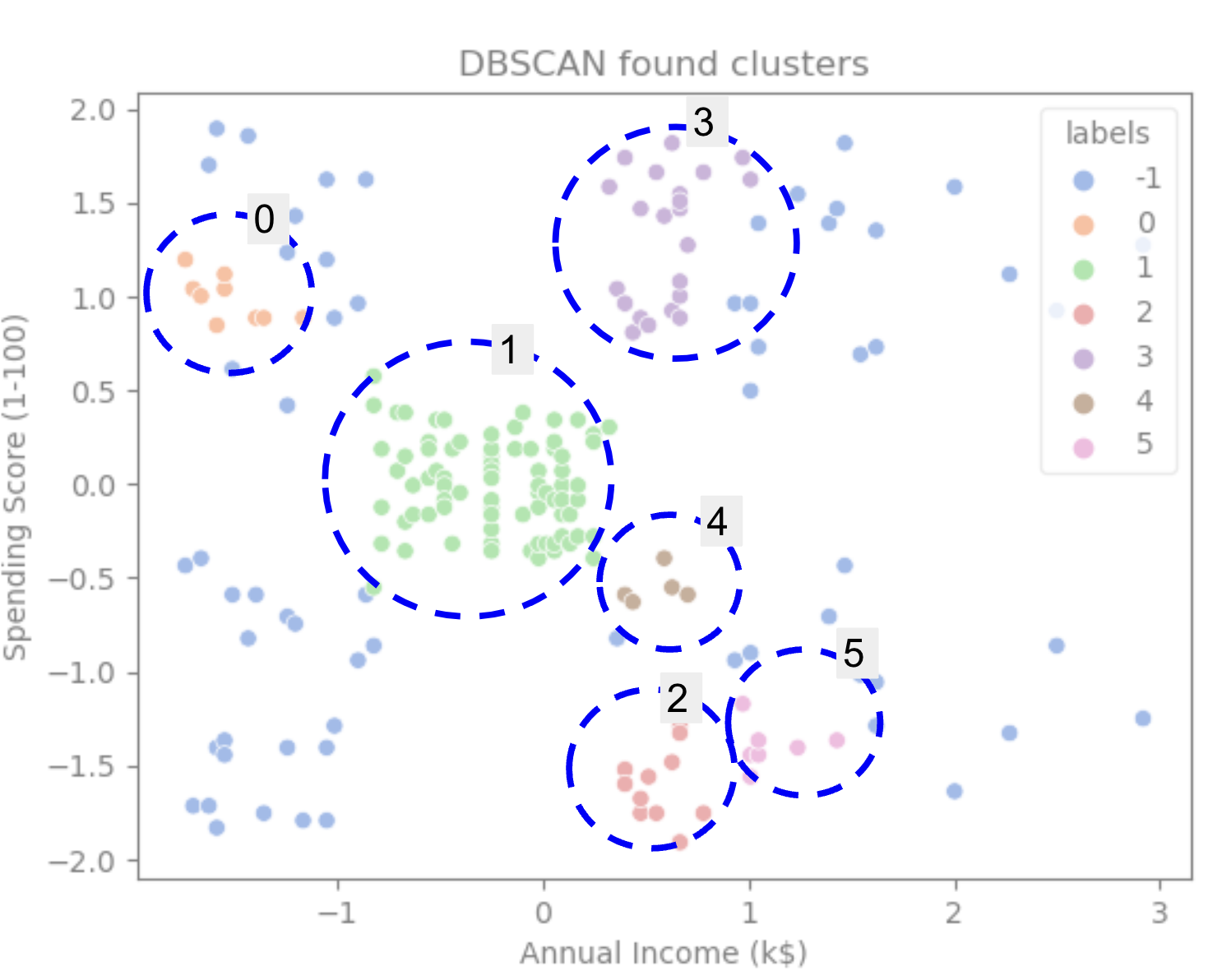
หากเราเน้นคลัสเตอร์ ให้สังเกตว่า DBSCAN รับคลัสเตอร์ 1 อย่างสมบูรณ์ได้อย่างไร ซึ่งเป็นคลัสเตอร์ที่มีช่องว่างระหว่างจุดน้อยกว่า จากนั้นจะได้ส่วนของกลุ่ม 0 และ 3 ที่จุดต่างๆ อยู่ใกล้กัน โดยพิจารณาจากจุดที่มีระยะห่างมากขึ้นเป็นสัญญาณรบกวน นอกจากนี้ยังถือว่าจุดในครึ่งล่างซ้ายเป็นสัญญาณรบกวน และแบ่งจุดที่ด้านขวาล่างออกเป็น 3 กลุ่ม อีกครั้งเพื่อจับกลุ่ม 4, 2 และ 5 โดยที่จุดต่างๆ อยู่ใกล้กันมากขึ้น
เราสามารถเริ่มสรุปได้ว่า DBSCAN นั้นยอดเยี่ยมสำหรับการจับภาพพื้นที่หนาแน่นของคลัสเตอร์ แต่ไม่มากนักสำหรับการระบุโครงร่างข้อมูลที่ใหญ่กว่า ซึ่งเป็นการคั่นด้วย 5 คลัสเตอร์ มันน่าสนใจที่จะทดสอบอัลกอริทึมการจัดกลุ่มเพิ่มเติมกับข้อมูลของเรา มาดูกันว่าตัวชี้วัดจะยืนยันสมมติฐานนี้หรือไม่
การประเมินอัลกอริทึม
ในการประเมิน DBSCAN เราจะใช้ คะแนนเงา โดยจะคำนึงถึงระยะห่างระหว่างจุดในกลุ่มเดียวกันและระยะห่างระหว่างกลุ่ม
หมายเหตุ ปัจจุบัน เมตริกการจัดกลุ่มส่วนใหญ่ไม่เหมาะที่จะใช้ในการประเมิน DBSCAN เนื่องจากไม่ได้ขึ้นอยู่กับความหนาแน่น ในที่นี้ เราใช้คะแนนภาพเงาเนื่องจากได้มีการนำไปใช้แล้วใน Scikit-learn และเนื่องจากพยายามดูรูปร่างคลัสเตอร์
เพื่อให้มีการประเมินที่เหมาะสมยิ่งขึ้น คุณสามารถใช้หรือรวมกับ การตรวจสอบการทำคลัสเตอร์ตามความหนาแน่น เมตริก (DBCV) ซึ่งออกแบบมาโดยเฉพาะสำหรับการจัดกลุ่มตามความหนาแน่น มีการใช้งานสำหรับ DBCV ในสิ่งนี้ GitHub.
ขั้นแรก เราสามารถนำเข้า silhouette_score จาก Scikit-Learn จากนั้นส่งต่อคอลัมน์และป้ายกำกับของเรา:
from sklearn.metrics import silhouette_score s_score = silhouette_score(scaled_customer_data, labels)
print(f"Silhouette coefficient: {s_score:.3f}")
ผลลัพธ์นี้:
Silhouette coefficient: 0.506
จากคะแนนนี้ ดูเหมือนว่า DBSCAN สามารถเก็บข้อมูลได้ประมาณ 50%
สรุป
ข้อดีและข้อเสียของ DBSCAN
DBSCAN เป็นอัลกอริทึมหรือแบบจำลองการทำคลัสเตอร์ที่ไม่เหมือนใคร
ถ้าเราดูที่ข้อดีของมัน มันดีมากในการเก็บพื้นที่หนาแน่นในข้อมูลและจุดที่ห่างไกลจากที่อื่น ซึ่งหมายความว่าข้อมูลไม่จำเป็นต้องมีรูปร่างเฉพาะ และสามารถล้อมรอบด้วยจุดอื่นๆ ได้ ตราบใดที่เชื่อมต่อกันอย่างหนาแน่น
กำหนดให้เราต้องระบุจุดต่ำสุดและ ε แต่ไม่จำเป็นต้องระบุจำนวนของคลัสเตอร์ล่วงหน้า เช่นใน K-Means เป็นต้น นอกจากนี้ยังสามารถใช้กับฐานข้อมูลขนาดใหญ่มากได้เนื่องจากได้รับการออกแบบมาสำหรับข้อมูลที่มีมิติสูง
สำหรับข้อเสียของมัน เราพบว่ามันไม่สามารถจับความหนาแน่นที่แตกต่างกันในคลัสเตอร์เดียวกันได้ ดังนั้นมันจึงมีช่วงเวลาที่ยากลำบากกับความหนาแน่นที่แตกต่างกันมาก นอกจากนี้ยังขึ้นอยู่กับเมตริกระยะทางและมาตราส่วนของจุด ซึ่งหมายความว่าหากข้อมูลไม่เข้าใจดี ด้วยความแตกต่างของมาตราส่วนและการวัดระยะทางที่ไม่สมเหตุสมผล ก็อาจไม่เข้าใจข้อมูลนั้น
ส่วนขยาย DBSCAN
มีอัลกอริทึมอื่น ๆ เช่น DBSCAN ลำดับชั้น (HDBSCAN) และ จุดสั่งซื้อเพื่อระบุโครงสร้างการจัดกลุ่ม (OPTICS)ซึ่งถือเป็นส่วนขยายของ DBSCAN
โดยปกติแล้ว ทั้ง HDBSCAN และ OPTICS จะทำงานได้ดีขึ้นเมื่อมีกลุ่มข้อมูลที่มีความหนาแน่นต่างกัน และยังมีความไวต่อตัวเลือกหรือค่าต่ำสุดเริ่มต้นน้อยกว่าด้วย จุดและพารามิเตอร์ ε
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://stackabuse.com/dbscan-with-scikit-learn-in-python/

