นี่คือโพสต์บล็อกของแขกที่เขียนโดย Nitin Kumar นักวิทยาศาสตร์ข้อมูลชั้นนำของ T and T Consulting Services, Inc.
ในโพสต์นี้ เราจะหารือเกี่ยวกับคุณค่าและผลกระทบที่อาจเกิดขึ้นจากการเรียนรู้แบบสมาพันธ์ในสาขาการดูแลสุขภาพ แนวทางนี้สามารถช่วยให้ผู้ป่วยโรคหลอดเลือดหัวใจ แพทย์ และนักวิจัยได้รับการวินิจฉัยที่รวดเร็วขึ้น การตัดสินใจที่สมบูรณ์ขึ้น และงานวิจัยที่ครอบคลุมและครอบคลุมมากขึ้นเกี่ยวกับปัญหาสุขภาพที่เกี่ยวข้องกับโรคหลอดเลือดสมอง โดยใช้แนวทางแบบเนทีฟบนคลาวด์พร้อมบริการของ AWS เพื่อการยกแบบน้ำหนักเบาและการใช้งานที่ตรงไปตรงมา .
การวินิจฉัยความท้าทายด้วยภาวะหัวใจเต้นผิดจังหวะ
สถิติจาก ศูนย์ควบคุมและป้องกันโรค (CDC) แสดงให้เห็นว่าในแต่ละปีในสหรัฐอเมริกา ผู้คนมากกว่า 795,000 รายต้องทนทุกข์ทรมานจากโรคหลอดเลือดสมองครั้งแรก และประมาณ 25% ของพวกเขามีอาการกำเริบอีก เป็นสาเหตุการตายอันดับที่ XNUMX ตาม พ.ร.บ อเมริกันสมาคมโรคหลอดเลือดสมอง และเป็นสาเหตุสำคัญของความพิการในสหรัฐอเมริกา ดังนั้นจึงจำเป็นอย่างยิ่งที่จะต้องมีการวินิจฉัยและการรักษาที่รวดเร็วเพื่อลดความเสียหายของสมองและภาวะแทรกซ้อนอื่น ๆ ในผู้ป่วยโรคหลอดเลือดสมองเฉียบพลัน
CT และ MRI เป็นมาตรฐานทองคำในเทคโนโลยีการถ่ายภาพสำหรับการจำแนกประเภทย่อยของโรคหลอดเลือดสมอง และมีความสำคัญอย่างยิ่งในการประเมินเบื้องต้นของผู้ป่วย การระบุสาเหตุที่แท้จริง และการรักษา ความท้าทายที่สำคัญอย่างหนึ่งที่นี่ โดยเฉพาะอย่างยิ่งในกรณีของโรคหลอดเลือดสมองเฉียบพลัน คือระยะเวลาในการวินิจฉัยด้วยภาพ ซึ่งโดยเฉลี่ยจะอยู่ในช่วง 30 นาทีถึงหนึ่งชั่วโมง และอาจนานกว่านั้นมากขึ้นอยู่กับความหนาแน่นของแผนกฉุกเฉิน
แพทย์และบุคลากรทางการแพทย์ต้องการการวินิจฉัยด้วยภาพที่รวดเร็วและแม่นยำ เพื่อประเมินอาการของผู้ป่วยและเสนอทางเลือกในการรักษา ในคำพูดของดร.เวอร์เนอร์ โวเกลส์เองที่ AWS re:ประดิษฐ์ 2023, “ทุกวินาทีที่คนเป็นโรคหลอดเลือดสมองนับ” ผู้ที่เป็นโรคหลอดเลือดสมองอาจสูญเสียเซลล์ประสาทประมาณ 1.9 พันล้านเซลล์ทุกๆ วินาทีที่ไม่ได้รับการรักษา
ข้อจำกัดด้านข้อมูลทางการแพทย์
คุณสามารถใช้การเรียนรู้ของเครื่อง (ML) เพื่อช่วยแพทย์และนักวิจัยในงานวินิจฉัยได้ ซึ่งจะช่วยเร่งกระบวนการให้เร็วขึ้น อย่างไรก็ตาม ชุดข้อมูลที่จำเป็นในการสร้างโมเดล ML และให้ผลลัพธ์ที่เชื่อถือได้นั้นกำลังเก็บซ่อนอยู่ในระบบและองค์กรด้านการดูแลสุขภาพต่างๆ ข้อมูลเดิมที่แยกออกมานี้มีโอกาสที่จะสร้างผลกระทบมหาศาลหากสะสมไว้ แล้วทำไมถึงยังไม่ใช้ล่ะ?
มีความท้าทายหลายประการเมื่อทำงานกับชุดข้อมูลโดเมนทางการแพทย์และการสร้างโซลูชัน ML รวมถึงความเป็นส่วนตัวของผู้ป่วย ความปลอดภัยของข้อมูลส่วนบุคคล และข้อจำกัดของระบบราชการและนโยบายบางประการ นอกจากนี้ สถาบันวิจัยยังได้เพิ่มความเข้มงวดในการแบ่งปันข้อมูลอีกด้วย อุปสรรคเหล่านี้ยังขัดขวางไม่ให้ทีมวิจัยนานาชาติทำงานร่วมกันในชุดข้อมูลที่หลากหลายและสมบูรณ์ ซึ่งสามารถช่วยชีวิตคนและป้องกันความพิการที่อาจเป็นผลมาจากภาวะหัวใจล้มเหลว รวมถึงประโยชน์อื่นๆ
นโยบายและข้อบังคับเช่น ระเบียบว่าด้วยการคุ้มครองข้อมูลทั่วไป (จีดีพีอาร์) พระราชบัญญัติการประกันสุขภาพแบบพกพาและความรับผิดชอบ (ฮิปปา) และ พระราชบัญญัติความเป็นส่วนตัวของผู้บริโภคในแคลิฟอร์เนีย (CCPA) วางมาตรการป้องกันในการแชร์ข้อมูลจากโดเมนทางการแพทย์ โดยเฉพาะข้อมูลผู้ป่วย นอกจากนี้ ชุดข้อมูลของแต่ละสถาบัน องค์กร และโรงพยาบาลมักจะมีขนาดเล็กเกินไป ไม่สมดุล หรือมีการกระจายแบบเอนเอียง ซึ่งนำไปสู่ข้อจำกัดในการวางโมเดลทั่วไป
การเรียนรู้แบบสหพันธรัฐ: บทนำ
การเรียนรู้แบบสมาพันธ์ (FL) เป็นรูปแบบการกระจายอำนาจของ ML ซึ่งเป็นแนวทางทางวิศวกรรมแบบไดนามิก ในแนวทาง ML แบบกระจายอำนาจนี้ โมเดล ML จะถูกแชร์ระหว่างองค์กรสำหรับการฝึกอบรมเกี่ยวกับชุดย่อยข้อมูลที่เป็นกรรมสิทธิ์ ซึ่งแตกต่างจากการฝึกอบรม ML แบบรวมศูนย์แบบดั้งเดิม ซึ่งโดยทั่วไปแล้วโมเดลจะฝึกชุดข้อมูลที่รวบรวมไว้ ข้อมูลจะได้รับการปกป้องหลังไฟร์วอลล์ขององค์กรหรือ VPC ในขณะที่โมเดลที่มีข้อมูลเมตาจะถูกแชร์
ในขั้นตอนการฝึกอบรม โมเดล FL ทั่วโลกจะได้รับการเผยแพร่และซิงโครไนซ์ระหว่างหน่วยงานต่างๆ สำหรับการฝึกอบรมชุดข้อมูลแต่ละชุด และโมเดลที่ได้รับการฝึกอบรมในพื้นที่จะถูกส่งกลับ โมเดลระดับโลกขั้นสุดท้ายพร้อมใช้คาดการณ์สำหรับทุกคนในหมู่ผู้เข้าร่วม และยังสามารถใช้เป็นฐานสำหรับการฝึกอบรมเพิ่มเติมเพื่อสร้างโมเดลแบบกำหนดเองในท้องถิ่นสำหรับองค์กรที่เข้าร่วม สามารถขยายผลไปเป็นประโยชน์ต่อสถาบันอื่นๆ ได้อีก วิธีการนี้สามารถลดข้อกำหนดด้านความปลอดภัยทางไซเบอร์สำหรับข้อมูลระหว่างทางได้อย่างมาก โดยไม่จำเป็นต้องส่งข้อมูลออกนอกขอบเขตขององค์กรเลย
ไดอะแกรมต่อไปนี้แสดงตัวอย่างสถาปัตยกรรม
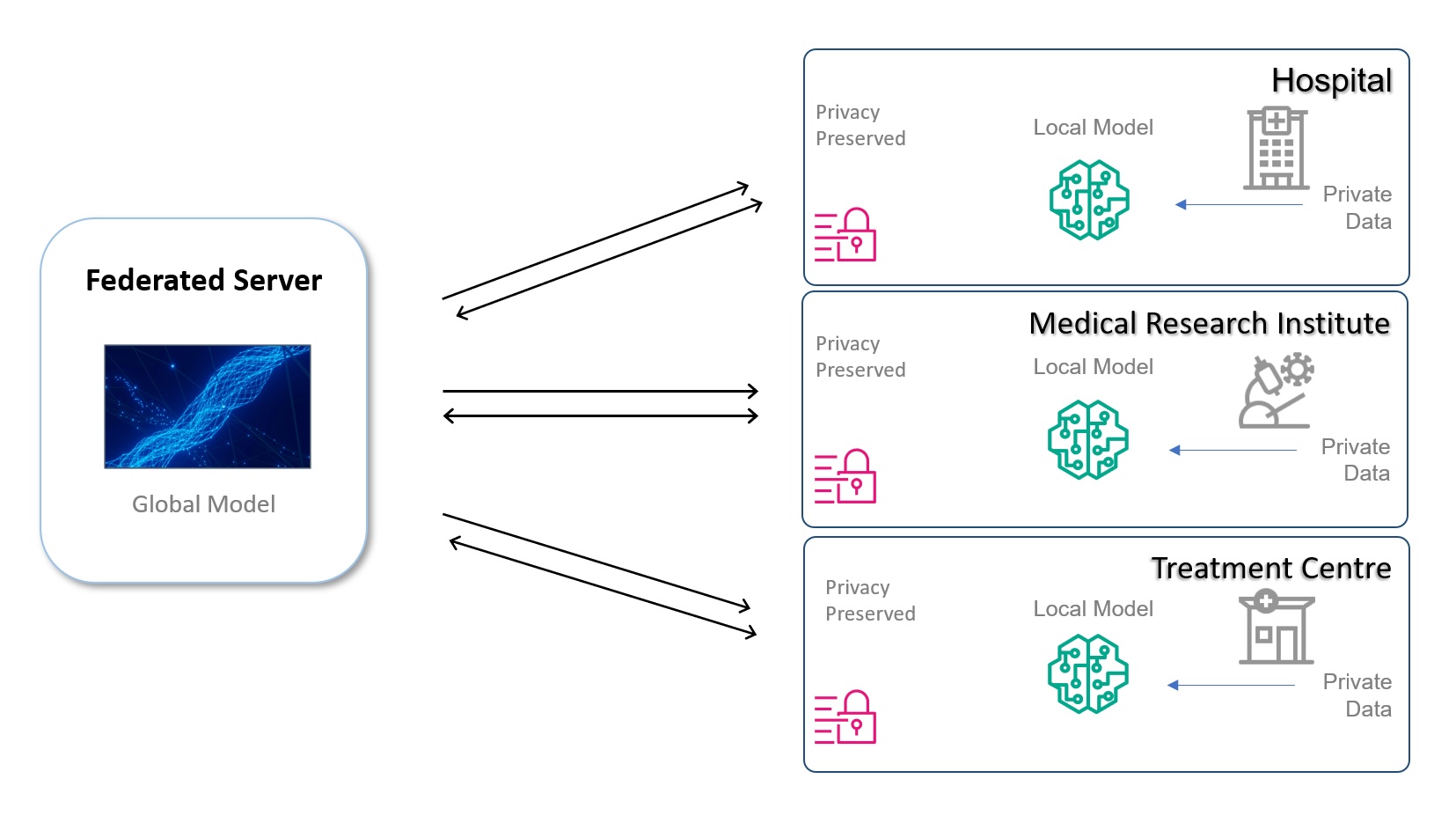
ในส่วนต่อไปนี้ เราจะหารือว่าการเรียนรู้แบบสหพันธรัฐสามารถช่วยได้อย่างไร
สหพันธ์เรียนรู้ที่จะกอบกู้โลก (และช่วยชีวิต)
สำหรับปัญญาประดิษฐ์ (AI) ที่ดี คุณต้องมีข้อมูลที่ดี
ระบบเดิมซึ่งมักพบในโดเมนของรัฐบาลกลาง ก่อให้เกิดความท้าทายในการประมวลผลข้อมูลที่สำคัญ ก่อนที่คุณจะสามารถรับข้อมูลข่าวกรองใดๆ หรือรวมเข้ากับชุดข้อมูลที่ใหม่กว่าได้ นี่เป็นอุปสรรคในการมอบความฉลาดอันมีคุณค่าแก่ผู้นำ อาจนำไปสู่การตัดสินใจที่ไม่ถูกต้อง เนื่องจากบางครั้งสัดส่วนของข้อมูลเดิมอาจมีค่ามากกว่ามากเมื่อเทียบกับชุดข้อมูลขนาดเล็กรุ่นใหม่ คุณต้องการแก้ไขคอขวดนี้อย่างมีประสิทธิภาพและไม่มีภาระงานในการรวมข้อมูลและการบูรณาการด้วยตนเอง (รวมถึงกระบวนการทำแผนที่ที่ยุ่งยาก) สำหรับชุดข้อมูลเดิมและใหม่กว่าที่อยู่ในโรงพยาบาลและสถาบันต่างๆ ซึ่งอาจใช้เวลาหลายเดือน ในหลายกรณี หรือหลายปีก็ได้ ข้อมูลเดิมนั้นค่อนข้างมีคุณค่าเนื่องจากเก็บข้อมูลเชิงบริบทที่สำคัญที่จำเป็นสำหรับการตัดสินใจที่แม่นยำและการฝึกอบรมโมเดลที่มีข้อมูลครบถ้วน ซึ่งนำไปสู่ AI ที่เชื่อถือได้ในโลกแห่งความเป็นจริง ระยะเวลาของข้อมูลแจ้งถึงความแปรผันและรูปแบบในระยะยาวในชุดข้อมูลที่อาจไม่ถูกตรวจพบและนำไปสู่การคาดการณ์ที่มีอคติและไม่มีข้อมูล
การทำลายไซโลข้อมูลเหล่านี้เพื่อรวมศักยภาพของข้อมูลที่กระจัดกระจายที่ยังไม่ได้ใช้สามารถช่วยและเปลี่ยนแปลงชีวิตผู้คนจำนวนมากได้ นอกจากนี้ยังสามารถเร่งการวิจัยที่เกี่ยวข้องกับปัญหาสุขภาพทุติยภูมิที่เกิดจากโรคหลอดเลือดสมองได้อีกด้วย โซลูชันนี้สามารถช่วยให้คุณแบ่งปันข้อมูลเชิงลึกจากข้อมูลที่แยกระหว่างสถาบันต่างๆ เนื่องจากนโยบายและเหตุผลอื่นๆ ไม่ว่าคุณจะเป็นโรงพยาบาล สถาบันวิจัย หรือองค์กรที่มุ่งเน้นข้อมูลด้านสุขภาพอื่นๆ ช่วยให้สามารถตัดสินใจได้อย่างชาญฉลาดเกี่ยวกับทิศทางการวิจัยและการวินิจฉัย นอกจากนี้ยังส่งผลให้มีที่เก็บข้อมูลอัจฉริยะแบบรวมศูนย์ผ่านฐานความรู้ที่ปลอดภัย เป็นส่วนตัว และทั่วโลก

การเรียนรู้แบบสมาพันธ์มีประโยชน์มากมายโดยทั่วไปและโดยเฉพาะอย่างยิ่งสำหรับการตั้งค่าข้อมูลทางการแพทย์
คุณสมบัติความปลอดภัยและความเป็นส่วนตัว:
- เก็บข้อมูลที่ละเอียดอ่อนให้ห่างจากอินเทอร์เน็ตและยังคงใช้สำหรับ ML และควบคุมความชาญฉลาดด้วยความเป็นส่วนตัวที่แตกต่างกัน
- ช่วยให้คุณสร้าง ฝึกอบรม และปรับใช้โมเดลที่เป็นกลางและแข็งแกร่ง ไม่ใช่แค่ในเครื่องเท่านั้น แต่ยังรวมไปถึงเครือข่าย โดยไม่มีอันตรายต่อความปลอดภัยของข้อมูล
- เอาชนะอุปสรรคด้วยผู้จำหน่ายหลายรายที่จัดการข้อมูล
- ขจัดความจำเป็นในการแบ่งปันข้อมูลข้ามไซต์และการกำกับดูแลระดับโลก
- รักษาความเป็นส่วนตัวด้วยความเป็นส่วนตัวที่แตกต่างกัน และนำเสนอการประมวลผลแบบหลายฝ่ายที่ปลอดภัยด้วยการฝึกอบรมในพื้นที่
การปรับปรุงประสิทธิภาพ:
- แก้ไขปัญหาขนาดตัวอย่างเล็กน้อยในพื้นที่การถ่ายภาพทางการแพทย์และกระบวนการติดฉลากที่มีค่าใช้จ่ายสูง
- ปรับสมดุลการกระจายข้อมูล
- ช่วยให้คุณสามารถรวม ML แบบดั้งเดิมและวิธีการเรียนรู้เชิงลึก (DL) ได้มากที่สุด
- ใช้ชุดรูปภาพที่รวบรวมไว้เพื่อช่วยปรับปรุงพลังทางสถิติ โดยเอาชนะข้อจำกัดขนาดตัวอย่างของแต่ละสถาบัน
ประโยชน์ของความยืดหยุ่น:
- หากฝ่ายใดฝ่ายหนึ่งตัดสินใจลาออกก็ไม่เป็นอุปสรรคต่อการฝึก
- โรงพยาบาลหรือสถาบันใหม่สามารถเข้าร่วมได้ตลอดเวลา มันไม่ได้ขึ้นอยู่กับชุดข้อมูลใด ๆ กับองค์กรโหนดใด ๆ
- ไม่จำเป็นต้องมีขั้นตอนทางวิศวกรรมข้อมูลที่กว้างขวางสำหรับข้อมูลเดิมที่กระจัดกระจายไปตามสถานที่ตั้งทางภูมิศาสตร์ที่กว้างขวาง
คุณสมบัติเหล่านี้สามารถช่วยลดกำแพงระหว่างสถาบันที่โฮสต์ชุดข้อมูลที่แยกออกมาบนโดเมนที่คล้ายกัน โซลูชันนี้สามารถเป็นตัวคูณกำลังโดยการควบคุมพลังแบบรวมศูนย์ของชุดข้อมูลแบบกระจาย และปรับปรุงประสิทธิภาพโดยการเปลี่ยนแปลงด้านความสามารถในการขยายอย่างรุนแรงโดยไม่ต้องยกระดับโครงสร้างพื้นฐานจำนวนมาก แนวทางนี้ช่วยให้ ML เข้าถึงศักยภาพสูงสุด โดยมีความเชี่ยวชาญในระดับคลินิก ไม่ใช่แค่การวิจัยเท่านั้น
การเรียนรู้แบบสมาพันธ์มีประสิทธิภาพเทียบเท่ากับ ML ทั่วไป ดังที่แสดงไว้ต่อไปนี้ การทดลอง โดย NVidia Clara (บน Medical Modal ARchive (MMAR) โดยใช้ชุดข้อมูล BRATS2018) ที่นี่ FL บรรลุประสิทธิภาพการแบ่งส่วนที่เทียบเคียงได้เมื่อเปรียบเทียบกับการฝึกอบรมด้วยข้อมูลแบบรวมศูนย์: มากกว่า 80% โดยมีประมาณ 600 epoch ในขณะที่ฝึกอบรมงานการแบ่งส่วนเนื้องอกในสมองแบบหลายรูปแบบและหลายระดับ
เมื่อเร็วๆ นี้ การเรียนรู้แบบสมาพันธ์ได้รับการทดสอบในสาขาย่อยทางการแพทย์บางสาขาสำหรับกรณีการใช้งาน รวมถึงการเรียนรู้ความคล้ายคลึงของผู้ป่วย การเรียนรู้การเป็นตัวแทนผู้ป่วย ฟีโนไทป์ และการสร้างแบบจำลองการทำนาย
พิมพ์เขียวแอปพลิเคชัน: การเรียนรู้แบบสมาพันธ์ทำให้เป็นไปได้และตรงไปตรงมา
ในการเริ่มต้นกับ FL คุณสามารถเลือกจากชุดข้อมูลคุณภาพสูงมากมาย เช่น ชุดข้อมูลที่มีภาพสมองได้แก่ อยู่ (ความคิดริเริ่มการแลกเปลี่ยนข้อมูลการถ่ายภาพสมองออทิสติก) แอดนิ (โครงการริเริ่มการสร้างภาพระบบประสาทสำหรับโรคอัลไซเมอร์), อาร์เอสเอ็นเอ (สมาคมรังสีวิทยาแห่งอเมริกาเหนือ) Brain CT, บราทีเอส (เกณฑ์มาตรฐานการแบ่งส่วนภาพเนื้องอกสมองหลายรูปแบบ) อัปเดตเป็นประจำสำหรับความท้าทายในการแบ่งส่วนภาพเนื้องอกสมองภายใต้ UPENN (มหาวิทยาลัยเพนซิลเวเนีย), UK BioBank (ครอบคลุมอยู่ใน NIH ต่อไปนี้ กระดาษ), และ ทรงเครื่อง. ในทำนองเดียวกันสำหรับภาพหัวใจ คุณสามารถเลือกจากตัวเลือกต่างๆ ที่เปิดเผยต่อสาธารณะ รวมถึง ACDC (Automatic Cardiac Diagnosis Challenge) ซึ่งเป็นชุดข้อมูลการประเมินการเต้นของหัวใจด้วย MRI พร้อมคำอธิบายประกอบแบบเต็มที่กล่าวถึงโดยหอสมุดแพทยศาสตร์แห่งชาติดังต่อไปนี้ กระดาษและ M&M (Multi-Center, Multi-Vendor และ Multi-Disease) Cardiac Segmentation Challenge ที่กล่าวถึงต่อไปนี้ อีอีอี กระดาษ
ภาพต่อไปนี้แสดงก แผนที่ความน่าจะเป็นของรอยโรคที่ทับซ้อนกันสำหรับรอยโรคหลักจากชุดข้อมูล ATLAS R1.1. (โรคหลอดเลือดสมองเป็นสาเหตุหนึ่งที่พบบ่อยที่สุดของรอยโรคในสมองตาม คลีฟแลนด์คลินิก.)

สำหรับข้อมูล Electronic Health Records (EHR) มีชุดข้อมูลบางส่วนที่เป็นไปตาม ทรัพยากรการทำงานร่วมกันอย่างรวดเร็วของ Healthcare (FHIR) มาตรฐาน มาตรฐานนี้ช่วยให้คุณสร้างโปรแกรมนำร่องที่ตรงไปตรงมาโดยการขจัดความท้าทายบางอย่างด้วยชุดข้อมูลที่ไม่เหมือนกันและต่างกัน ทำให้สามารถแลกเปลี่ยน แบ่งปัน และบูรณาการชุดข้อมูลได้อย่างราบรื่นและปลอดภัย FHIR ช่วยให้สามารถทำงานร่วมกันได้สูงสุด ตัวอย่างชุดข้อมูลได้แก่ มิมิก-IV (ตลาดข้อมูลทางการแพทย์สำหรับผู้ป่วยหนัก). ชุดข้อมูลคุณภาพดีอื่นๆ ที่ปัจจุบันไม่ใช่ FHIR แต่สามารถแปลงได้อย่างง่ายดาย ได้แก่ ศูนย์บริการ Medicare & Medicaid (CMS) ไฟล์การใช้งานสาธารณะ (PUF) และ ฐานข้อมูลการวิจัยความร่วมมือ eICU จาก MIT (สถาบันเทคโนโลยีแมสซาชูเซตส์) นอกจากนี้ยังมีแหล่งข้อมูลอื่นๆ ที่นำเสนอชุดข้อมูลแบบ FHIR
วงจรการใช้งานสำหรับการนำ FL ไปใช้อาจมีดังต่อไปนี้ ทำตามขั้นตอน: การเริ่มต้นงาน การเลือก การกำหนดค่า การฝึกโมเดล การสื่อสารระหว่างไคลเอ็นต์/เซิร์ฟเวอร์ การกำหนดเวลาและการเพิ่มประสิทธิภาพ การกำหนดเวอร์ชัน การทดสอบ การปรับใช้ และการสิ้นสุด มีขั้นตอนที่ต้องใช้เวลามากมายในการเตรียมข้อมูลภาพทางการแพทย์สำหรับ ML แบบดั้งเดิม ดังที่อธิบายไว้ต่อไปนี้ กระดาษ. ความรู้โดเมนอาจจำเป็นในบางสถานการณ์เพื่อประมวลผลข้อมูลดิบของผู้ป่วยล่วงหน้า โดยเฉพาะอย่างยิ่งเนื่องจากลักษณะที่ละเอียดอ่อนและเป็นส่วนตัว สิ่งเหล่านี้สามารถรวมเข้าด้วยกันและบางครั้งอาจตัดออกสำหรับ FL ซึ่งช่วยประหยัดเวลาที่สำคัญสำหรับการฝึกอบรมและให้ผลลัพธ์ที่รวดเร็วยิ่งขึ้น
การดำเนินงาน
เครื่องมือและไลบรารีของ FL เติบโตขึ้นด้วยการสนับสนุนอย่างกว้างขวาง ทำให้ใช้งาน FL ได้อย่างง่ายดายโดยไม่ต้องเพิ่มค่าใช้จ่ายจำนวนมาก มีทรัพยากรและตัวเลือกเฟรมเวิร์กที่ดีมากมายสำหรับการเริ่มต้น คุณสามารถดูสิ่งต่อไปนี้ รายการที่กว้างขวาง ของเฟรมเวิร์กและเครื่องมือยอดนิยมในโดเมน FL รวมถึง PySyft, FedML, ดอกไม้, โอเพ่นฟล, ชะตากรรม, TensorFlow สหพันธ์และ NVFlare. มีรายการโครงการสำหรับผู้เริ่มต้นเพื่อเริ่มต้นอย่างรวดเร็วและต่อยอด
คุณสามารถใช้แนวทางแบบคลาวด์เนทีฟได้ด้วย อเมซอน SageMaker ที่ทำงานได้อย่างราบรื่นด้วย การเพียร์ AWS VPCทำให้การฝึกอบรมของแต่ละโหนดอยู่ในซับเน็ตส่วนตัวใน VPC ที่เกี่ยวข้องและเปิดใช้งานการสื่อสารผ่านที่อยู่ IPv4 ส่วนตัว นอกจากนี้โมเดลโฮสติ้งยังเปิดอยู่ Amazon SageMaker JumpStart สามารถช่วยได้โดยการเปิดเผย API ปลายทางโดยไม่ต้องแชร์น้ำหนักโมเดล
นอกจากนี้ยังขจัดความท้าทายในการประมวลผลระดับสูงที่อาจเกิดขึ้นด้วยฮาร์ดแวร์ภายในองค์กรด้วย อเมซอน อีลาสติก คอมพิวท์ คลาวด์ ทรัพยากร (Amazon EC2) คุณสามารถใช้งานไคลเอนต์ FL และเซิร์ฟเวอร์บน AWS ได้ โน้ตบุ๊ค SageMaker และ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (Amazon S3) รักษาการเข้าถึงข้อมูลและโมเดลที่มีการควบคุมด้วย AWS Identity และการจัดการการเข้าถึง (IAM) บทบาทและการใช้งาน บริการโทเค็นความปลอดภัย AWS (AWS STS) สำหรับการรักษาความปลอดภัยฝั่งไคลเอ็นต์ คุณยังสามารถสร้างระบบที่คุณกำหนดเองสำหรับ FL โดยใช้ Amazon EC2 ได้อีกด้วย
สำหรับภาพรวมโดยละเอียดของการนำ FL ไปใช้ด้วย ดอกไม้ กรอบการทำงานบน SageMaker และการอภิปรายเกี่ยวกับความแตกต่างจากการฝึกอบรมแบบกระจาย โปรดดูที่ การเรียนรู้ของเครื่องพร้อมข้อมูลการฝึกอบรมแบบกระจายอำนาจโดยใช้การเรียนรู้แบบรวมศูนย์บน Amazon SageMaker.
รูปภาพต่อไปนี้แสดงให้เห็นสถาปัตยกรรมของการถ่ายโอนการเรียนรู้ในฟลอริดา

จัดการกับความท้าทายด้านข้อมูล FL
การเรียนรู้แบบสมาพันธ์มาพร้อมกับความท้าทายด้านข้อมูลในตัวเอง ซึ่งรวมถึงความเป็นส่วนตัวและความปลอดภัย แต่ก็สามารถจัดการได้อย่างตรงไปตรงมา ขั้นแรก คุณต้องแก้ไขปัญหาความหลากหลายของข้อมูลด้วยข้อมูลภาพทางการแพทย์ที่เกิดจากข้อมูลที่จัดเก็บไว้ในไซต์ต่างๆ และองค์กรที่เข้าร่วม ซึ่งเรียกว่า การย้ายโดเมน ปัญหา (หรือเรียกอีกอย่างว่า กะลูกค้า ในระบบ FL) ตามที่ Guan และ Liu เน้นไว้ดังต่อไปนี้ กระดาษ. สิ่งนี้สามารถนำไปสู่ความแตกต่างในการบรรจบกันของโมเดลระดับโลก
องค์ประกอบอื่นๆ ที่ต้องพิจารณา ได้แก่ การรับรองคุณภาพข้อมูลและความสม่ำเสมอที่แหล่งที่มา การผสมผสานความรู้ของผู้เชี่ยวชาญเข้ากับกระบวนการเรียนรู้เพื่อสร้างแรงบันดาลใจให้เกิดความมั่นใจในระบบในหมู่ผู้เชี่ยวชาญทางการแพทย์ และการบรรลุความแม่นยำของแบบจำลอง สำหรับข้อมูลเพิ่มเติมเกี่ยวกับความท้าทายที่อาจเกิดขึ้นที่คุณอาจเผชิญระหว่างการดำเนินการ โปรดดูที่ต่อไปนี้ กระดาษ.
AWS ช่วยคุณแก้ไขปัญหาท้าทายเหล่านี้ด้วยคุณสมบัติต่างๆ เช่น การประมวลผลที่ยืดหยุ่นของ Amazon EC2 และที่สร้างไว้ล่วงหน้า ภาพนักเทียบท่า ใน SageMaker เพื่อการปรับใช้ที่ตรงไปตรงมา คุณสามารถแก้ไขปัญหาฝั่งไคลเอ็นต์ได้ เช่น ข้อมูลไม่สมดุลและทรัพยากรการคำนวณสำหรับแต่ละองค์กรโหนด คุณสามารถแก้ไขปัญหาการเรียนรู้ฝั่งเซิร์ฟเวอร์ เช่น การโจมตีแบบวางยาพิษจากกลุ่มที่เป็นอันตรายได้ด้วย คลาวด์ส่วนตัวเสมือนของ Amazon (Amazon VPC) กลุ่มความปลอดภัยและมาตรฐานความปลอดภัยอื่นๆ การป้องกันความเสียหายของไคลเอ็นต์และการใช้บริการตรวจจับความผิดปกติของ AWS
AWS ยังช่วยจัดการกับความท้าทายในการใช้งานในโลกแห่งความเป็นจริง ซึ่งอาจรวมถึงความท้าทายในการบูรณาการ ปัญหาความเข้ากันได้กับระบบโรงพยาบาลปัจจุบันหรือระบบเดิม และอุปสรรคในการนำไปใช้ของผู้ใช้ โดยนำเสนอโซลูชันเทคโนโลยีลิฟต์ที่ยืดหยุ่น ใช้งานง่าย และง่ายดาย
ด้วยบริการของ AWS คุณสามารถเปิดใช้งานการวิจัยและการใช้งานทางคลินิกบน FL ขนาดใหญ่ ซึ่งอาจประกอบด้วยไซต์ต่างๆ ทั่วโลก
นโยบายล่าสุดเกี่ยวกับความสามารถในการทำงานร่วมกันเน้นย้ำถึงความจำเป็นในการเรียนรู้แบบรวมศูนย์
กฎหมายหลายฉบับที่เพิ่งผ่านโดยรัฐบาล รวมถึงการมุ่งเน้นไปที่การทำงานร่วมกันของข้อมูล ซึ่งสนับสนุนความจำเป็นในการทำงานร่วมกันข้ามองค์กรของข้อมูลสำหรับข่าวกรอง ซึ่งสามารถทำได้โดยใช้ FL รวมถึงกรอบงานเช่น ทีฟก้า (Trusted Exchange Framework และ Common Agreement) และขยายออกไป USCDI (ข้อมูลหลักสำหรับการทำงานร่วมกันของสหรัฐอเมริกา)
แนวคิดที่เสนอยังมีส่วนสนับสนุนความคิดริเริ่มในการดักจับและแจกจ่ายของ CDC CDC ก้าวไปข้างหน้า. คำพูดต่อไปนี้จากบทความ GovCIO การแบ่งปันข้อมูลและ AI ลำดับความสำคัญสูงสุดของหน่วยงานด้านสุขภาพของรัฐบาลกลางในปี 2024 ยังสะท้อนแนวคิดที่คล้ายกัน: “ความสามารถเหล่านี้ยังสามารถสนับสนุนสาธารณะได้อย่างเท่าเทียมกัน พบปะผู้ป่วยในที่ที่พวกเขาอยู่ และปลดล็อกการเข้าถึงบริการเหล่านี้ที่สำคัญ งานนี้ส่วนใหญ่มาจากข้อมูล”
สิ่งนี้สามารถช่วยเหลือสถาบันทางการแพทย์และหน่วยงานต่างๆ ทั่วประเทศ (และทั่วโลก) ในเรื่องไซโลข้อมูล พวกเขาจะได้รับประโยชน์จากการบูรณาการที่ราบรื่นและปลอดภัยและการทำงานร่วมกันของข้อมูล ทำให้ข้อมูลทางการแพทย์สามารถนำมาใช้สำหรับการคาดการณ์ตาม ML และการจดจำรูปแบบที่มีผลกระทบ คุณสามารถเริ่มต้นด้วยรูปภาพ แต่แนวทางนี้สามารถใช้ได้กับ EHR ทั้งหมดเช่นกัน เป้าหมายคือการค้นหาแนวทางที่ดีที่สุดสำหรับผู้มีส่วนได้ส่วนเสียด้านข้อมูล ด้วยไปป์ไลน์บนคลาวด์เพื่อทำให้ข้อมูลเป็นมาตรฐานและเป็นมาตรฐาน หรือใช้โดยตรงสำหรับ FL
เรามาสำรวจกรณีการใช้งานตัวอย่างกัน ข้อมูลและภาพสแกนการเต้นของหัวใจกระจัดกระจายไปทั่วประเทศและทั่วโลก โดยแยกอยู่ในสถาบัน มหาวิทยาลัย และโรงพยาบาล และถูกแยกออกจากกันด้วยขอบเขตของระบบราชการ ภูมิศาสตร์ และการเมือง ไม่มีแหล่งข้อมูลที่รวบรวมไว้เพียงแห่งเดียว และไม่มีวิธีที่ง่ายสำหรับผู้เชี่ยวชาญทางการแพทย์ (ไม่ใช่โปรแกรมเมอร์) ที่จะดึงข้อมูลเชิงลึกออกมา ในขณะเดียวกัน ก็เป็นไปไม่ได้ที่จะฝึกโมเดล ML และ DL กับข้อมูลนี้ ซึ่งอาจช่วยให้ผู้เชี่ยวชาญทางการแพทย์ตัดสินใจได้รวดเร็วและแม่นยำยิ่งขึ้นในช่วงเวลาวิกฤติ เมื่อการสแกนหัวใจอาจใช้เวลาหลายชั่วโมงกว่าจะเข้ามา ในขณะที่ชีวิตของผู้ป่วยอาจแขวนอยู่ในนั้น สมดุล.
กรณีการใช้งานอื่น ๆ ที่ทราบ ได้แก่ หม้อ (ระบบติดตามการจัดซื้อออนไลน์) ได้ที่ NIH (สถาบันสุขภาพแห่งชาติ) และความปลอดภัยทางไซเบอร์สำหรับความต้องการโซลูชันข่าวกรองที่กระจัดกระจายและเป็นชั้นที่สถานที่ตั้ง COMCOM/MAJCOM ทั่วโลก
สรุป
การเรียนรู้แบบสหพันธรัฐถือเป็นคำมั่นสัญญาที่ยอดเยี่ยมสำหรับการวิเคราะห์และข้อมูลด้านการดูแลสุขภาพแบบดั้งเดิม การใช้โซลูชันแบบเนทีฟบนคลาวด์กับบริการของ AWS นั้นตรงไปตรงมา และ FL มีประโยชน์อย่างยิ่งสำหรับองค์กรทางการแพทย์ที่มีข้อมูลเดิมและความท้าทายทางเทคนิค FL อาจมีผลกระทบที่อาจเกิดขึ้นต่อวงจรการรักษาทั้งหมด และตอนนี้ยิ่งมีผลกระทบมากขึ้นไปอีก ด้วยการมุ่งเน้นไปที่การทำงานร่วมกันของข้อมูลจากองค์กรรัฐบาลกลางขนาดใหญ่และผู้นำรัฐบาล
โซลูชันนี้สามารถช่วยให้คุณหลีกเลี่ยงการคิดค้นสิ่งใหม่ๆ และใช้เทคโนโลยีล่าสุดเพื่อก้าวกระโดดจากระบบเดิมและอยู่ในแถวหน้าในโลกของ AI ที่พัฒนาอยู่ตลอดเวลา คุณยังสามารถเป็นผู้นำด้านแนวทางปฏิบัติที่ดีที่สุดและแนวทางที่มีประสิทธิภาพในการทำงานร่วมกันของข้อมูลภายในและระหว่างหน่วยงานและสถาบันในขอบเขตด้านสุขภาพและนอกเหนือจากนั้น หากคุณเป็นสถาบันหรือเอเจนซี่ที่มีไซโลข้อมูลกระจายอยู่ทั่วประเทศ คุณจะได้รับประโยชน์จากการบูรณาการที่ราบรื่นและปลอดภัยนี้
เนื้อหาและความคิดเห็นในโพสต์นี้เป็นของผู้เขียนบุคคลที่สาม และ AWS จะไม่รับผิดชอบต่อเนื้อหาหรือความถูกต้องของโพสต์นี้ เป็นความรับผิดชอบของลูกค้าแต่ละรายในการพิจารณาว่าตนต้องอยู่ภายใต้ HIPAA หรือไม่ และหากเป็นเช่นนั้น จะต้องปฏิบัติตามวิธีที่ดีที่สุดในการปฏิบัติตาม HIPAA และกฎระเบียบที่บังคับใช้ ก่อนที่จะใช้ AWS ร่วมกับข้อมูลด้านสุขภาพที่ได้รับการคุ้มครอง ลูกค้าจะต้องป้อน AWS Business Associate Addendum (BAA) และปฏิบัติตามข้อกำหนดในการกำหนดค่า
เกี่ยวกับผู้เขียน

นิทินกุมาร (มธ., มช) เป็นหัวหน้านักวิทยาศาสตร์ด้านข้อมูลของ T and T Consulting Services, Inc. เขามีประสบการณ์กว้างขวางในการสร้างต้นแบบด้านการวิจัยและพัฒนา สารสนเทศด้านสุขภาพ ข้อมูลภาครัฐ และการทำงานร่วมกันของข้อมูล เขาใช้ความรู้เกี่ยวกับวิธีการวิจัยที่ล้ำสมัยกับภาครัฐบาลกลางเพื่อส่งมอบเอกสารทางเทคนิคที่เป็นนวัตกรรม, POC และ MVP เขาได้ทำงานร่วมกับหน่วยงานรัฐบาลกลางหลายแห่งเพื่อพัฒนาข้อมูลและเป้าหมาย AI ของพวกเขา พื้นที่มุ่งเน้นอื่นๆ ของ Nitin ได้แก่ การประมวลผลภาษาธรรมชาติ (NLP) ไปป์ไลน์ข้อมูล และ AI เชิงสร้างสรรค์
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/enable-data-sharing-through-federated-learning-a-policy-approach-for-chief-digital-officers/

