นโยบายการควบคุมที่มีประสิทธิภาพช่วยให้บริษัทอุตสาหกรรมสามารถเพิ่มผลกำไรโดยการเพิ่มผลผลิตสูงสุด ในขณะเดียวกันก็ลดการหยุดทำงานและการใช้พลังงานที่ไม่ได้กำหนดไว้ การค้นหานโยบายการควบคุมที่เหมาะสมที่สุดนั้นเป็นงานที่ซับซ้อน เนื่องจากระบบทางกายภาพ เช่น เครื่องปฏิกรณ์เคมีและกังหันลม มักจะสร้างแบบจำลองได้ยาก และเนื่องจากการเคลื่อนตัวของกระบวนการที่เบี่ยงเบนไปอาจทำให้ประสิทธิภาพการทำงานลดลงเมื่อเวลาผ่านไป การเรียนรู้การเสริมกำลังแบบออฟไลน์เป็นกลยุทธ์การควบคุมที่ช่วยให้บริษัทอุตสาหกรรมสามารถสร้างนโยบายการควบคุมทั้งหมดจากข้อมูลในอดีตโดยไม่จำเป็นต้องมีแบบจำลองกระบวนการที่ชัดเจน แนวทางนี้ไม่ต้องการปฏิสัมพันธ์กับกระบวนการโดยตรงในขั้นตอนการสำรวจ ซึ่งจะขจัดอุปสรรคประการหนึ่งสำหรับการนำการเรียนรู้แบบเสริมแรงมาใช้ในการใช้งานที่มีความสำคัญด้านความปลอดภัย ในโพสต์นี้ เราจะสร้างโซลูชันแบบครบวงจรเพื่อค้นหานโยบายการควบคุมที่เหมาะสมที่สุดโดยใช้เฉพาะข้อมูลประวัติเท่านั้น อเมซอน SageMaker โดยใช้ของเรย์ RLlib ห้องสมุด. หากต้องการเรียนรู้เพิ่มเติมเกี่ยวกับการเรียนรู้แบบเสริมกำลัง โปรดดู ใช้การเรียนรู้แบบเสริมกำลังกับ Amazon SageMaker
ใช้กรณี
การควบคุมทางอุตสาหกรรมเกี่ยวข้องกับการจัดการระบบที่ซับซ้อน เช่น สายการผลิต โครงข่ายพลังงาน และโรงงานเคมี เพื่อให้มั่นใจถึงการดำเนินงานที่มีประสิทธิภาพและเชื่อถือได้ กลยุทธ์การควบคุมแบบดั้งเดิมจำนวนมากเป็นไปตามกฎและแบบจำลองที่กำหนดไว้ล่วงหน้า ซึ่งมักต้องมีการปรับให้เหมาะสมด้วยตนเอง ถือเป็นแนวปฏิบัติมาตรฐานในบางอุตสาหกรรมในการติดตามประสิทธิภาพและปรับนโยบายการควบคุม เมื่ออุปกรณ์เริ่มเสื่อมคุณภาพหรือสภาพแวดล้อมเปลี่ยนแปลง เป็นต้น การปรับแต่งใหม่อาจใช้เวลาหลายสัปดาห์และอาจต้องมีการกระตุ้นจากภายนอกเข้าสู่ระบบเพื่อบันทึกการตอบสนองด้วยวิธีลองผิดลองถูก
การเรียนรู้แบบเสริมกำลังกลายเป็นกระบวนทัศน์ใหม่ในการควบคุมกระบวนการเพื่อเรียนรู้นโยบายการควบคุมที่เหมาะสมที่สุดผ่านการโต้ตอบกับสิ่งแวดล้อม กระบวนการนี้จำเป็นต้องแบ่งข้อมูลออกเป็นสามประเภท: 1) การวัดที่มีจากระบบทางกายภาพ 2) ชุดการดำเนินการที่สามารถทำได้กับระบบ และ 3) ตัวชี้วัดเชิงตัวเลข (รางวัล) ของประสิทธิภาพของอุปกรณ์ นโยบายได้รับการฝึกอบรมเพื่อค้นหาการดำเนินการตามการสังเกตที่กำหนด ซึ่งมีแนวโน้มที่จะสร้างผลตอบแทนสูงสุดในอนาคต
ในการเรียนรู้การเสริมกำลังแบบออฟไลน์ เราสามารถฝึกอบรมนโยบายเกี่ยวกับข้อมูลในอดีตก่อนที่จะนำไปใช้จริง อัลกอริทึมที่ได้รับการฝึกในโพสต์บล็อกนี้เรียกว่า “การเรียนรู้ Q แบบอนุรักษ์นิยม” (ซีคิวแอล) CQL มีโมเดล "นักแสดง" และโมเดล "นักวิจารณ์" และได้รับการออกแบบมาเพื่อคาดการณ์ประสิทธิภาพของตนเองอย่างอนุรักษ์นิยมหลังจากดำเนินการตามที่แนะนำแล้ว ในโพสต์นี้ กระบวนการนี้แสดงให้เห็นด้วยปัญหาการควบคุมเสารถเข็นที่มีภาพประกอบ เป้าหมายคือการฝึกอบรมตัวแทนให้ทรงตัวบนรถเข็นในขณะเดียวกันก็เคลื่อนย้ายรถเข็นไปยังตำแหน่งเป้าหมายที่กำหนด ขั้นตอนการฝึกอบรมใช้ข้อมูลออฟไลน์ ช่วยให้ตัวแทนเรียนรู้จากข้อมูลที่มีอยู่แล้ว กรณีศึกษาแบบรถเข็นนี้แสดงให้เห็นถึงกระบวนการฝึกอบรมและประสิทธิผลในการใช้งานจริง
ภาพรวมโซลูชัน
โซลูชันที่นำเสนอในโพสต์นี้ทำให้การปรับใช้เวิร์กโฟลว์แบบ end-to-end เป็นแบบอัตโนมัติสำหรับการเรียนรู้แบบเสริมออฟไลน์ด้วยข้อมูลประวัติ ไดอะแกรมต่อไปนี้อธิบายสถาปัตยกรรมที่ใช้ในเวิร์กโฟลว์นี้ ข้อมูลการวัดถูกสร้างขึ้นที่ขอบโดยอุปกรณ์อุตสาหกรรมชิ้นหนึ่ง (ในที่นี้จำลองโดย AWS แลมบ์ดา การทำงาน). ข้อมูลจะถูกใส่ลงใน อเมซอน Kinesis Data Firehose ซึ่งจัดเก็บไว้ บริการจัดเก็บข้อมูลอย่างง่ายของ Amazon (อเมซอน S3). Amazon S3 เป็นโซลูชันพื้นที่จัดเก็บข้อมูลที่ทนทาน มีประสิทธิภาพ และต้นทุนต่ำ ซึ่งช่วยให้คุณสามารถให้บริการข้อมูลจำนวนมากแก่กระบวนการฝึกอบรม Machine Learning ได้
AWS กาว แคตตาล็อกข้อมูลและทำให้สามารถสืบค้นได้โดยใช้ อเมซอน อาเธน่า. Athena แปลงข้อมูลการวัดให้อยู่ในรูปแบบที่อัลกอริธึมการเรียนรู้แบบเสริมสามารถนำเข้าแล้วยกเลิกการโหลดกลับเข้าไปใน Amazon S3 Amazon SageMaker โหลดข้อมูลนี้ในงานการฝึกและสร้างโมเดลที่ได้รับการฝึก จากนั้น SageMaker จะให้บริการโมเดลนั้นในจุดสิ้นสุด SageMaker อุปกรณ์ทางอุตสาหกรรมสามารถสอบถามตำแหน่งข้อมูลนั้นเพื่อรับคำแนะนำการดำเนินการได้
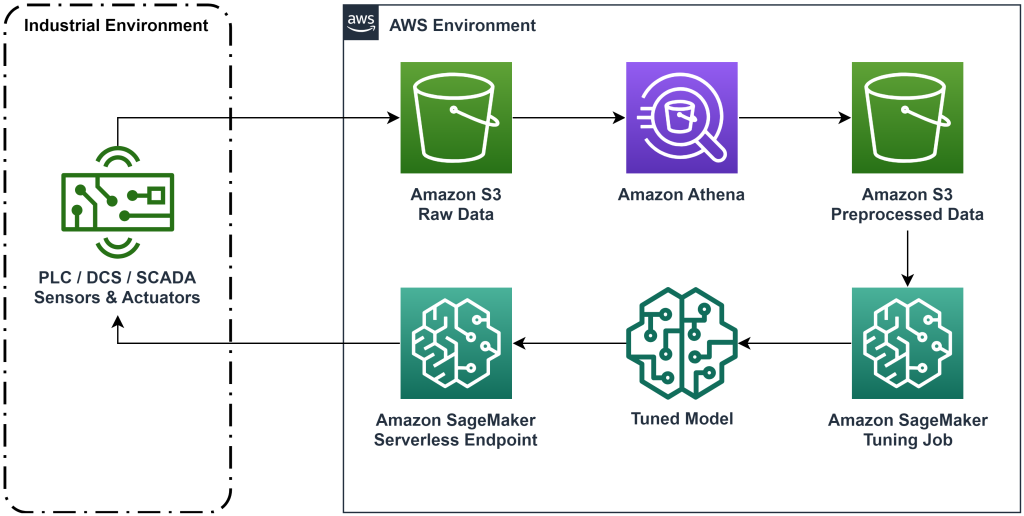
รูปที่ 1: แผนภาพสถาปัตยกรรมแสดงขั้นตอนการเรียนรู้การเสริมกำลังแบบ end-to-end
ในโพสต์นี้ เราจะแจกแจงขั้นตอนการทำงานตามขั้นตอนต่อไปนี้:
- กำหนดปัญหา ตัดสินใจว่าการดำเนินการใดที่สามารถทำได้ การวัดใดเพื่อให้คำแนะนำตาม และกำหนดตัวเลขว่าแต่ละการกระทำทำงานได้ดีเพียงใด
- เตรียมข้อมูล แปลงตารางการวัดให้เป็นรูปแบบที่อัลกอริธึมแมชชีนเลิร์นนิงสามารถใช้ได้
- ฝึกอัลกอริทึมกับข้อมูลนั้น
- เลือกการฝึกซ้อมที่ดีที่สุดตามเกณฑ์ชี้วัดการฝึกซ้อม
- ปรับใช้โมเดลกับตำแหน่งข้อมูล SageMaker
- ประเมินประสิทธิภาพของแบบจำลองในการผลิต
เบื้องต้น
เพื่อให้คำแนะนำนี้เสร็จสมบูรณ์ คุณต้องมี บัญชี AWS และอินเตอร์เฟสบรรทัดคำสั่งด้วย ติดตั้ง AWS SAM แล้ว. ทำตามขั้นตอนเหล่านี้เพื่อปรับใช้เทมเพลต AWS SAM เพื่อรันเวิร์กโฟลว์นี้และสร้างข้อมูลการฝึก:
- ดาวน์โหลดที่เก็บโค้ดด้วยคำสั่ง
- เปลี่ยนไดเร็กทอรีเป็น repo:
- สร้าง repo:
- ปรับใช้ repo
- ใช้คำสั่งต่อไปนี้เพื่อเรียกใช้สคริปต์ทุบตี ซึ่งสร้างข้อมูลจำลองโดยใช้ฟังก์ชัน AWS Lambda
sudo yum install jqcd utilssh generate_mock_data.sh
แนวทางการแก้ปัญหา
กำหนดปัญหา
ระบบของเราในบล็อกโพสต์นี้คือรถเข็นที่มีเสาสมดุลอยู่ด้านบน ระบบทำงานได้ดีเมื่อตั้งเสาตั้งตรงและตำแหน่งรถเข็นอยู่ใกล้กับตำแหน่งประตู ในขั้นตอนข้อกำหนดเบื้องต้น เราสร้างข้อมูลประวัติจากระบบนี้
ตารางต่อไปนี้แสดงข้อมูลประวัติที่รวบรวมจากระบบ
| ตำแหน่งรถเข็น | ความเร็วรถเข็น | มุมเสา | ความเร็วเชิงมุมของขั้วโลก | ตำแหน่งเป้าหมาย | แรงภายนอก | รางวัล | เวลา |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5: 37: 54 PM |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5: 37: 55 PM |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5: 37: 56 PM |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5: 37: 57 PM |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5: 37: 58 PM |
คุณสามารถสืบค้นข้อมูลระบบในอดีตได้โดยใช้ Amazon Athena ด้วยการสืบค้นต่อไปนี้:
สถานะของระบบนี้ถูกกำหนดโดยตำแหน่งรถเข็น ความเร็วของรถเข็น มุมเสา ความเร็วเชิงมุมของเสา และตำแหน่งเป้าหมาย การดำเนินการในแต่ละขั้นตอนคือแรงภายนอกที่จ่ายให้กับรถเข็น สภาพแวดล้อมจำลองจะให้มูลค่ารางวัลที่สูงขึ้นเมื่อรถเข็นเข้าใกล้ตำแหน่งเป้าหมายมากขึ้น และเสาตั้งตรงมากขึ้น
เตรียมข้อมูล
หากต้องการนำเสนอข้อมูลระบบให้กับโมเดลการเรียนรู้แบบเสริมกำลัง ให้แปลงเป็นออบเจ็กต์ JSON ด้วยคีย์ที่จัดหมวดหมู่ค่าเป็นสถานะ (หรือเรียกว่าการสังเกต) การดำเนินการ และหมวดหมู่รางวัล จัดเก็บอ็อบเจ็กต์เหล่านี้ใน Amazon S3 นี่คือตัวอย่างของออบเจ็กต์ JSON ที่สร้างจากขั้นตอนเวลาในตารางก่อนหน้า
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
สแต็ก AWS CloudFormation มีเอาต์พุตที่เรียกว่า AthenaQueryToCreateJsonFormatedData. เรียกใช้การสืบค้นนี้ใน Amazon Athena เพื่อทำการเปลี่ยนแปลงและจัดเก็บอ็อบเจ็กต์ JSON ใน Amazon S3 อัลกอริธึมการเรียนรู้แบบเสริมกำลังใช้โครงสร้างของออบเจ็กต์ JSON เหล่านี้เพื่อทำความเข้าใจว่าค่าใดที่จะอ้างอิงตามคำแนะนำและผลลัพธ์ของการดำเนินการในข้อมูลประวัติ
ตัวแทนรถไฟ
ตอนนี้เราสามารถเริ่มงานการฝึกอบรมเพื่อสร้างแบบจำลองคำแนะนำการดำเนินการที่ได้รับการฝึกอบรมแล้ว Amazon SageMaker ช่วยให้คุณเริ่มงานการฝึกหลายๆ งานได้อย่างรวดเร็วเพื่อดูว่าการกำหนดค่าต่างๆ ส่งผลต่อโมเดลที่ได้รับการฝึกอย่างไร เรียกใช้ฟังก์ชัน Lambda ที่มีชื่อ TuningJobLauncherFunction เพื่อเริ่มงานการปรับแต่งไฮเปอร์พารามิเตอร์ที่ทดลองกับชุดไฮเปอร์พารามิเตอร์ที่แตกต่างกันสี่ชุดเมื่อฝึกอัลกอริทึม
เลือกการฝึกซ้อมที่ดีที่สุด
หากต้องการค้นหาว่างานฝึกอบรมใดที่สร้างแบบจำลองได้ดีที่สุด ให้ตรวจสอบกราฟการสูญเสียที่เกิดขึ้นระหว่างการฝึก โมเดลการวิพากษ์วิจารณ์ของ CQL จะประเมินประสิทธิภาพของนักแสดง (เรียกว่าค่า Q) หลังจากดำเนินการตามที่แนะนำ ส่วนหนึ่งของฟังก์ชันการสูญเสียของนักวิจารณ์รวมถึงข้อผิดพลาดผลต่างชั่วคราว ตัวชี้วัดนี้จะวัดความแม่นยำของค่า Q ของนักวิจารณ์ มองหาการฝึกซ้อมที่มีค่า Q เฉลี่ยสูง และมีข้อผิดพลาดของผลต่างเวลาต่ำ กระดาษแผ่นนี้, ขั้นตอนการทำงานสำหรับการเรียนรู้การเสริมกำลังด้วยหุ่นยนต์แบบไม่มีโมเดลออฟไลน์, รายละเอียดวิธีการเลือกการวิ่งฝึกซ้อมที่ดีที่สุด ที่เก็บโค้ดมีไฟล์ /utils/investigate_training.pyที่สร้างรูป html แบบพล็อตที่อธิบายงานการฝึกอบรมล่าสุด เรียกใช้ไฟล์นี้และใช้เอาต์พุตเพื่อเลือกการฝึกซ้อมที่ดีที่สุด
เราสามารถใช้ค่า Q เฉลี่ยเพื่อทำนายประสิทธิภาพของแบบจำลองที่ได้รับการฝึก ค่า Q ได้รับการฝึกให้คาดการณ์ผลรวมของมูลค่ารางวัลในอนาคตที่มีส่วนลดอย่างระมัดระวัง สำหรับกระบวนการที่ใช้เวลานาน เราสามารถแปลงตัวเลขนี้เป็นค่าเฉลี่ยถ่วงน้ำหนักแบบเอ็กซ์โปเนนเชียลได้โดยการคูณค่า Q ด้วย (1- “อัตราคิดลด”) การวิ่งฝึกซ้อมที่ดีที่สุดในชุดนี้ได้รับค่า Q เฉลี่ย 539 อัตราคิดลดของเราคือ 0.99 ดังนั้นแบบจำลองจึงคาดการณ์รางวัลเฉลี่ยอย่างน้อย 5.39 ต่อก้าวของเวลา คุณสามารถเปรียบเทียบค่านี้กับประสิทธิภาพของระบบในอดีตเพื่อบ่งชี้ว่าโมเดลใหม่จะมีประสิทธิภาพเหนือกว่านโยบายการควบคุมในอดีตหรือไม่ ในการทดลองนี้ รางวัลเฉลี่ยต่อขั้นตอนของข้อมูลในอดีตคือ 4.3 ดังนั้นโมเดล CQL จึงคาดการณ์ประสิทธิภาพที่ดีกว่าระบบที่ทำได้ในอดีตถึง 25 เปอร์เซ็นต์
ปรับใช้โมเดล
ตำแหน่งข้อมูล Amazon SageMaker ช่วยให้คุณสามารถให้บริการโมเดล Machine Learning ได้หลายวิธีเพื่อตอบสนองกรณีการใช้งานที่หลากหลาย ในโพสต์นี้ เราจะใช้ประเภทตำแหน่งข้อมูลแบบ Serverless เพื่อให้ตำแหน่งข้อมูลของเราปรับขนาดตามความต้องการโดยอัตโนมัติ และเราจ่ายเฉพาะการใช้งานการประมวลผลเมื่อตำแหน่งข้อมูลสร้างการอนุมานเท่านั้น หากต้องการปรับใช้ตำแหน่งข้อมูลแบบไร้เซิร์ฟเวอร์ ให้รวมก ProductionVariantServerlessConfig ใน ตัวแปรการผลิต ของ SageMaker การกำหนดค่าปลายทาง. ข้อมูลโค้ดต่อไปนี้แสดงวิธีการปรับใช้ตำแหน่งข้อมูลแบบไร้เซิร์ฟเวอร์ในตัวอย่างนี้โดยใช้ชุดพัฒนาซอฟต์แวร์ Amazon SageMaker สำหรับ Python ค้นหาโค้ดตัวอย่างที่ใช้ในการปรับใช้โมเดลได้ที่ sagemaker-ออฟไลน์-การเสริมแรง-การเรียนรู้-ray-cql.
ไฟล์โมเดลที่ได้รับการฝึกจะอยู่ที่อาร์ติแฟกต์ของโมเดล S3 สำหรับการรันการฝึกแต่ละครั้ง หากต้องการปรับใช้โมเดลการเรียนรู้ของเครื่อง ให้ค้นหาไฟล์โมเดลของการรันการฝึกที่ดีที่สุด และเรียกใช้ฟังก์ชัน Lambda ชื่อ “ModelDeployerFunction” โดยมีเหตุการณ์ที่มีข้อมูลโมเดลนี้ ฟังก์ชัน Lambda จะเปิดตัวตำแหน่งข้อมูลแบบไร้เซิร์ฟเวอร์ของ SageMaker เพื่อรองรับโมเดลที่ได้รับการฝึก ตัวอย่างเหตุการณ์ที่จะใช้เมื่อเรียก “ModelDeployerFunction"
ประเมินประสิทธิภาพของโมเดลที่ผ่านการฝึกอบรม
ถึงเวลาดูว่าโมเดลที่ผ่านการฝึกอบรมของเรากำลังดำเนินการอย่างไรในการใช้งานจริง! หากต้องการตรวจสอบประสิทธิภาพของรุ่นใหม่ ให้เรียกใช้ฟังก์ชัน Lambda ชื่อ “RunPhysicsSimulationFunction” พร้อมด้วยชื่อตำแหน่งข้อมูล SageMaker ในกิจกรรม สิ่งนี้จะรันการจำลองโดยใช้การดำเนินการที่แนะนำโดยจุดสิ้นสุด ตัวอย่างเหตุการณ์ที่จะใช้เมื่อโทรไปที่ RunPhysicsSimulatorFunction:
ใช้แบบสอบถาม Athena ต่อไปนี้เพื่อเปรียบเทียบประสิทธิภาพของโมเดลที่ผ่านการฝึกอบรมกับประสิทธิภาพของระบบในอดีต
| แหล่งที่มาของการดำเนินการ | รางวัลเฉลี่ยต่อก้าวเวลา |
trained_model |
10.8 |
historic_data |
4.3 |
ภาพเคลื่อนไหวต่อไปนี้แสดงความแตกต่างระหว่างตอนตัวอย่างจากข้อมูลการฝึกและตอนที่มีการใช้โมเดลที่ได้รับการฝึกเพื่อเลือกการกระทำที่จะดำเนินการ ในภาพเคลื่อนไหว กล่องสีน้ำเงินคือรถเข็น เส้นสีน้ำเงินคือเสา และสี่เหลี่ยมสีเขียวคือตำแหน่งเป้าหมาย ลูกศรสีแดงแสดงแรงที่ใช้กับรถเข็นในแต่ละขั้นตอน ลูกศรสีแดงในข้อมูลการฝึกอบรมจะกระโดดไปมาเล็กน้อย เนื่องจากข้อมูลถูกสร้างขึ้นโดยใช้การดำเนินการของผู้เชี่ยวชาญ 50 เปอร์เซ็นต์ และการดำเนินการแบบสุ่ม 50 เปอร์เซ็นต์ แบบจำลองที่ได้รับการฝึกอบรมได้เรียนรู้นโยบายการควบคุมที่จะเคลื่อนรถเข็นอย่างรวดเร็วไปยังตำแหน่งเป้าหมาย ในขณะที่ยังคงรักษาเสถียรภาพ ทั้งหมดจากการสังเกตการสาธิตที่ไม่มีผู้เชี่ยวชาญ
 |
 |
ทำความสะอาด
หากต้องการลบทรัพยากรที่ใช้ในเวิร์กโฟลว์นี้ ให้ไปที่ส่วนทรัพยากรของสแต็ก Amazon CloudFormation และลบบัคเก็ต S3 และบทบาท IAM จากนั้นลบสแต็ก CloudFormation ออกไป
สรุป
การเรียนรู้การเสริมกำลังแบบออฟไลน์สามารถช่วยให้บริษัทอุตสาหกรรมค้นหานโยบายที่เหมาะสมได้โดยอัตโนมัติ โดยไม่กระทบต่อความปลอดภัยโดยใช้ข้อมูลในอดีต หากต้องการนำแนวทางนี้ไปใช้ในการดำเนินงานของคุณ ให้เริ่มต้นด้วยการระบุการวัดที่ประกอบกันเป็นระบบที่รัฐกำหนด การดำเนินการที่คุณสามารถควบคุมได้ และหน่วยเมตริกที่บ่งบอกถึงประสิทธิภาพที่ต้องการ จากนั้นให้เข้าถึง ที่เก็บ GitHub นี้ สำหรับการปรับใช้โซลูชันแบบครบวงจรอัตโนมัติโดยใช้ Ray และ Amazon SageMaker
โพสต์นี้เป็นเพียงแค่ภาพรวมของสิ่งที่คุณสามารถทำได้ด้วย Amazon SageMaker RL ทดลองใช้งาน และโปรดส่งข้อเสนอแนะถึงเรา ทั้งใน ฟอรัมสนทนาของ Amazon SageMaker หรือผ่านผู้ติดต่อ AWS ปกติของคุณ
เกี่ยวกับผู้เขียน
 วอลท์ เมย์ฟิลด์ เป็นสถาปนิกโซลูชันที่ AWS และช่วยให้บริษัทพลังงานดำเนินงานได้อย่างปลอดภัยและมีประสิทธิภาพมากขึ้น ก่อนที่จะมาร่วมงานกับ AWS Walt เคยทำงานเป็นวิศวกรฝ่ายปฏิบัติการให้กับ Hilcorp Energy Company เขาชอบทำสวนและบินปลาในเวลาว่าง
วอลท์ เมย์ฟิลด์ เป็นสถาปนิกโซลูชันที่ AWS และช่วยให้บริษัทพลังงานดำเนินงานได้อย่างปลอดภัยและมีประสิทธิภาพมากขึ้น ก่อนที่จะมาร่วมงานกับ AWS Walt เคยทำงานเป็นวิศวกรฝ่ายปฏิบัติการให้กับ Hilcorp Energy Company เขาชอบทำสวนและบินปลาในเวลาว่าง
 เฟลิเป้ โลเปซ เป็นสถาปนิกโซลูชันอาวุโสที่ AWS โดยเน้นการดำเนินงานด้านการผลิตน้ำมันและก๊าซ ก่อนที่จะมาร่วมงานกับ AWS นั้น Felipe ทำงานร่วมกับ GE Digital และ Schlumberger ซึ่งเขามุ่งเน้นที่การสร้างแบบจำลองและการเพิ่มประสิทธิภาพผลิตภัณฑ์สำหรับการใช้งานทางอุตสาหกรรม
เฟลิเป้ โลเปซ เป็นสถาปนิกโซลูชันอาวุโสที่ AWS โดยเน้นการดำเนินงานด้านการผลิตน้ำมันและก๊าซ ก่อนที่จะมาร่วมงานกับ AWS นั้น Felipe ทำงานร่วมกับ GE Digital และ Schlumberger ซึ่งเขามุ่งเน้นที่การสร้างแบบจำลองและการเพิ่มประสิทธิภาพผลิตภัณฑ์สำหรับการใช้งานทางอุตสาหกรรม
 หยิงเว่ย หยู เป็นนักวิทยาศาสตร์ประยุกต์ที่ Generative AI Incubator, AWS เขามีประสบการณ์ทำงานร่วมกับองค์กรต่างๆ ในอุตสาหกรรมต่างๆ เพื่อพิสูจน์แนวคิดต่างๆ ในการเรียนรู้ของเครื่อง รวมถึงการประมวลผลภาษาธรรมชาติ การวิเคราะห์อนุกรมเวลา และการบำรุงรักษาเชิงคาดการณ์ ในเวลาว่าง เขาชอบว่ายน้ำ วาดภาพ เดินป่า และใช้เวลากับครอบครัวและเพื่อนฝูง
หยิงเว่ย หยู เป็นนักวิทยาศาสตร์ประยุกต์ที่ Generative AI Incubator, AWS เขามีประสบการณ์ทำงานร่วมกับองค์กรต่างๆ ในอุตสาหกรรมต่างๆ เพื่อพิสูจน์แนวคิดต่างๆ ในการเรียนรู้ของเครื่อง รวมถึงการประมวลผลภาษาธรรมชาติ การวิเคราะห์อนุกรมเวลา และการบำรุงรักษาเชิงคาดการณ์ ในเวลาว่าง เขาชอบว่ายน้ำ วาดภาพ เดินป่า และใช้เวลากับครอบครัวและเพื่อนฝูง
 ห่าวจู หวาง เป็นนักวิทยาศาสตร์การวิจัยใน Amazon Bedrock ที่มุ่งเน้นการสร้างแบบจำลองรากฐาน Titan ของ Amazon ก่อนหน้านี้เขาทำงานใน Amazon ML Solutions Lab ในตำแหน่งหัวหน้าร่วมของ Reinforcement Learning Vertical และช่วยลูกค้าสร้างโซลูชัน ML ขั้นสูงด้วยการวิจัยล่าสุดเกี่ยวกับการเรียนรู้แบบเสริมกำลัง การประมวลผลภาษาธรรมชาติ และการเรียนรู้กราฟ Haozhu สำเร็จการศึกษาระดับปริญญาเอกสาขาวิศวกรรมไฟฟ้าและคอมพิวเตอร์จากมหาวิทยาลัยมิชิแกน
ห่าวจู หวาง เป็นนักวิทยาศาสตร์การวิจัยใน Amazon Bedrock ที่มุ่งเน้นการสร้างแบบจำลองรากฐาน Titan ของ Amazon ก่อนหน้านี้เขาทำงานใน Amazon ML Solutions Lab ในตำแหน่งหัวหน้าร่วมของ Reinforcement Learning Vertical และช่วยลูกค้าสร้างโซลูชัน ML ขั้นสูงด้วยการวิจัยล่าสุดเกี่ยวกับการเรียนรู้แบบเสริมกำลัง การประมวลผลภาษาธรรมชาติ และการเรียนรู้กราฟ Haozhu สำเร็จการศึกษาระดับปริญญาเอกสาขาวิศวกรรมไฟฟ้าและคอมพิวเตอร์จากมหาวิทยาลัยมิชิแกน
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- PlatoData.Network Vertical Generative Ai เพิ่มพลังให้กับตัวเอง เข้าถึงได้ที่นี่.
- เพลโตไอสตรีม. Web3 อัจฉริยะ ขยายความรู้ เข้าถึงได้ที่นี่.
- เพลโตESG. ยานยนต์ / EVs, คาร์บอน, คลีนเทค, พลังงาน, สิ่งแวดล้อม แสงอาทิตย์, การจัดการของเสีย. เข้าถึงได้ที่นี่.
- เพลโตสุขภาพ เทคโนโลยีชีวภาพและข่าวกรองการทดลองทางคลินิก เข้าถึงได้ที่นี่.
- ChartPrime. ยกระดับเกมการซื้อขายของคุณด้วย ChartPrime เข้าถึงได้ที่นี่.
- BlockOffsets การปรับปรุงการเป็นเจ้าของออฟเซ็ตด้านสิ่งแวดล้อมให้ทันสมัย เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

