Har du någonsin behövt extrahera data från en PDF eller ett skannat dokument till ett kalkylblad? OCR kan vara en riktig tidsbesparare. Skanna helt enkelt dina dokument och konvertera bilderna till redigerbar, sökbar text. OCR gör det enkelt att extrahera data, oavsett om du arbetar med PDF-filer, foton eller skannade sidor.
Optimera din dokumenthantering process med denna OCR till kalkylbladsguide. Vi guidar dig genom arbetsflödet och ger dig kraftfulla effektivitetshöjande tips.
Varför omorganisera data till kalkylblad med OCR?
OCR är en total gamechanger. Det tar data som är inlåst i dina skannade papper, PDF-filer och foton och förvandlar dem till strukturerad data. Vi pratar färdiga kalkylblad. Detta öppnar upp en helt ny värld av möjligheter.
Här är några anledningar till varför du bör överväga att använda OCR för att organisera dina data i kalkylblad:
1. Enklare dataanalys
När din data har extraherats och organiserats snyggt i rader och kolumner i ett kalkylblad, blir det mycket lättare att analysera och arbeta med. Du kan snabbt upptäcka trender, sortera, filtrera, använda formler och skapa pivottabeller och diagram. Denna nivå av datamanipulering är inte möjlig i skannade dokument eller PDF-filer.
2. Bättre datakvalitet
OCR-konvertering till kalkylblad ger dig ren, strukturerad data. Data kan valideras och standardiseras under OCR-processen. Detta förbättrar den övergripande datakvaliteten och noggrannheten jämfört med ostrukturerade skannade dokument.
3. Förbättrad sökbarhet
Skannade dokument och bilder är komplicerade att söka efter — OCR fixar detta genom att konvertera bilderna till verklig text. Väl i ett kalkylblad blir informationen helt sökbar. Du kan omedelbart hitta det du behöver.
4. Förbättrad datadelning
Kalkylblad som innehåller extraherade data kan enkelt delas med andra för samarbete. Data är nu i ett standardiserat återanvändbart format istället för att fångas i enskilda dokumentbilder.
5. Automationsmöjligheter
Kalkylbladsdata kan automatiseras och strömlinjeformas över affärssystem. Med möjligheten att mata ut CSV-filer kan de extraherade OCR-data automatiskt flöda in i databaser och andra branschapplikationer.
6. Hoppa över manuell bearbetning
Ditt team kommer inte längre att behöva transkribera data manuellt från skannade dokument eller utstå det tråkiga och ineffektiva arbetsflödet för kopiera och klistra in för PDF-filer. Du kan minska antalet fel och spara tid på att rensa och validera data genom att eliminera monotona datainmatningsuppgifter. Som ett resultat kan din personal ägna sina ansträngningar åt ett mer produktivt och tillfredsställande arbete.
7. skalbarhet
OCR-konvertering skalar och datavolymer växer. Oavsett om du behöver bearbeta hundratals eller till och med tusentals dokumentsidor, hanterar OCR-automatisering det smidigt. Manuell datainmatning skalas inte lika snabbt för stora volymer.
Arbetsflödet för OCR till kalkylblad
Att konvertera dokument till kalkylblad med OCR är enkelt när du följer dessa viktiga steg. Genom att sätta upp ett effektivt arbetsflöde kan du spara timmar av manuell datainmatning och få snabbt tillgång till information som är inlåst i PDF-filer eller skannade filer.

Låt oss dyka in.
1. Samla dokument för OCR
Samla först in dokumentbilderna, PDF-filerna eller skannade papper som innehåller de data du behöver extrahera. Nanonets låter dig enkelt importera filer från flera källor, inklusive e-post, molnlagring, Dropbox, Google Drive, OneDrive och mer.

Du kan också ställa in mappar eller e-postkonton för att bearbeta nya filer eller inkommande bilagor automatiskt. API-samtal och integrationer med annan affärsprogramvara kan också ställas in för sömlös datauttag.
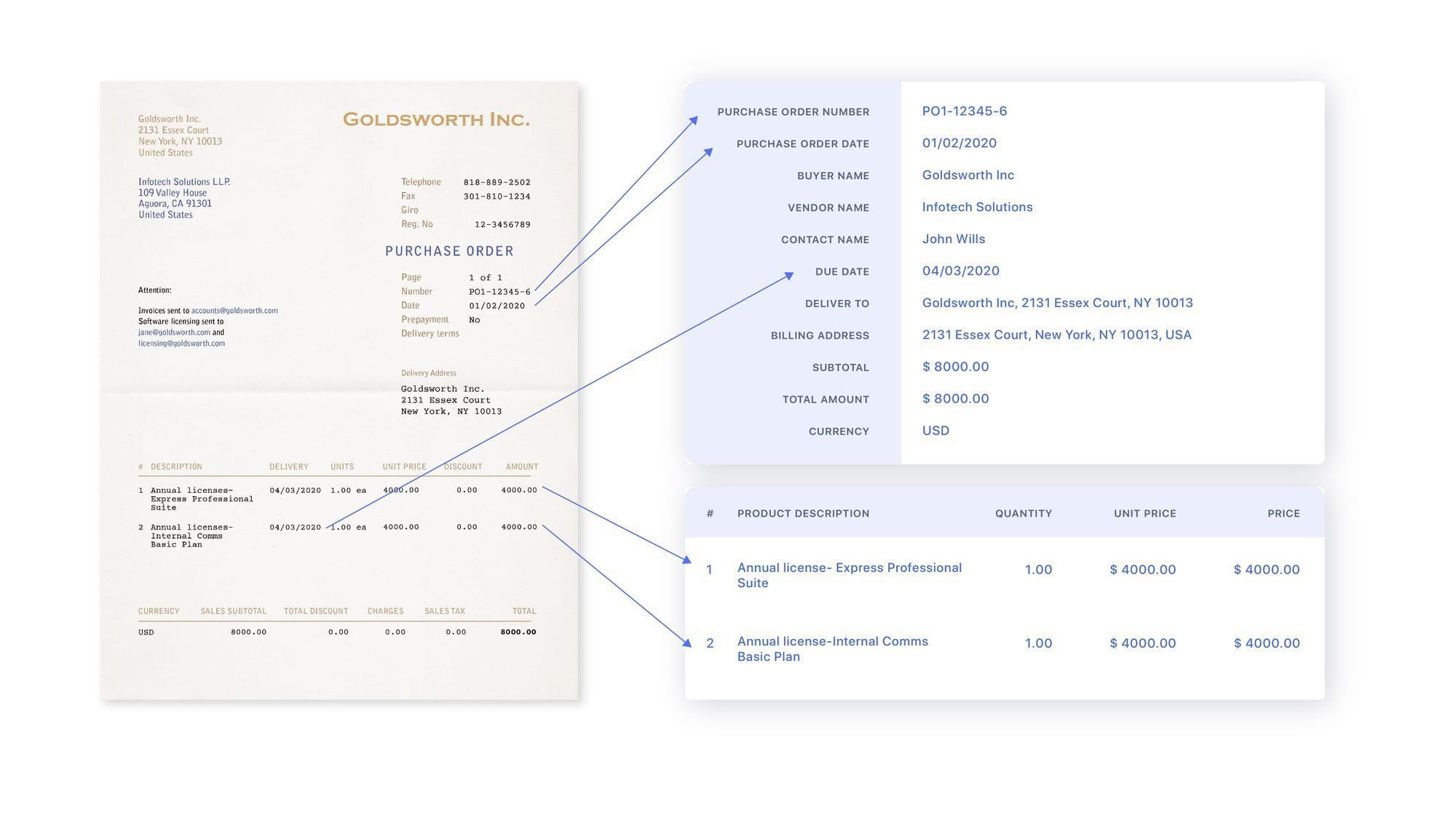
2. Definiera datafält
Ange sedan de datafält eller kolumner du vill extrahera, såsom fakturanummer, datum, kundnamn, förfallna belopp, etc. Nanonets erbjuder olika AI-modeller för dokumenttyper som t.ex. fakturor, kvitton, visitkortOch mycket mer.
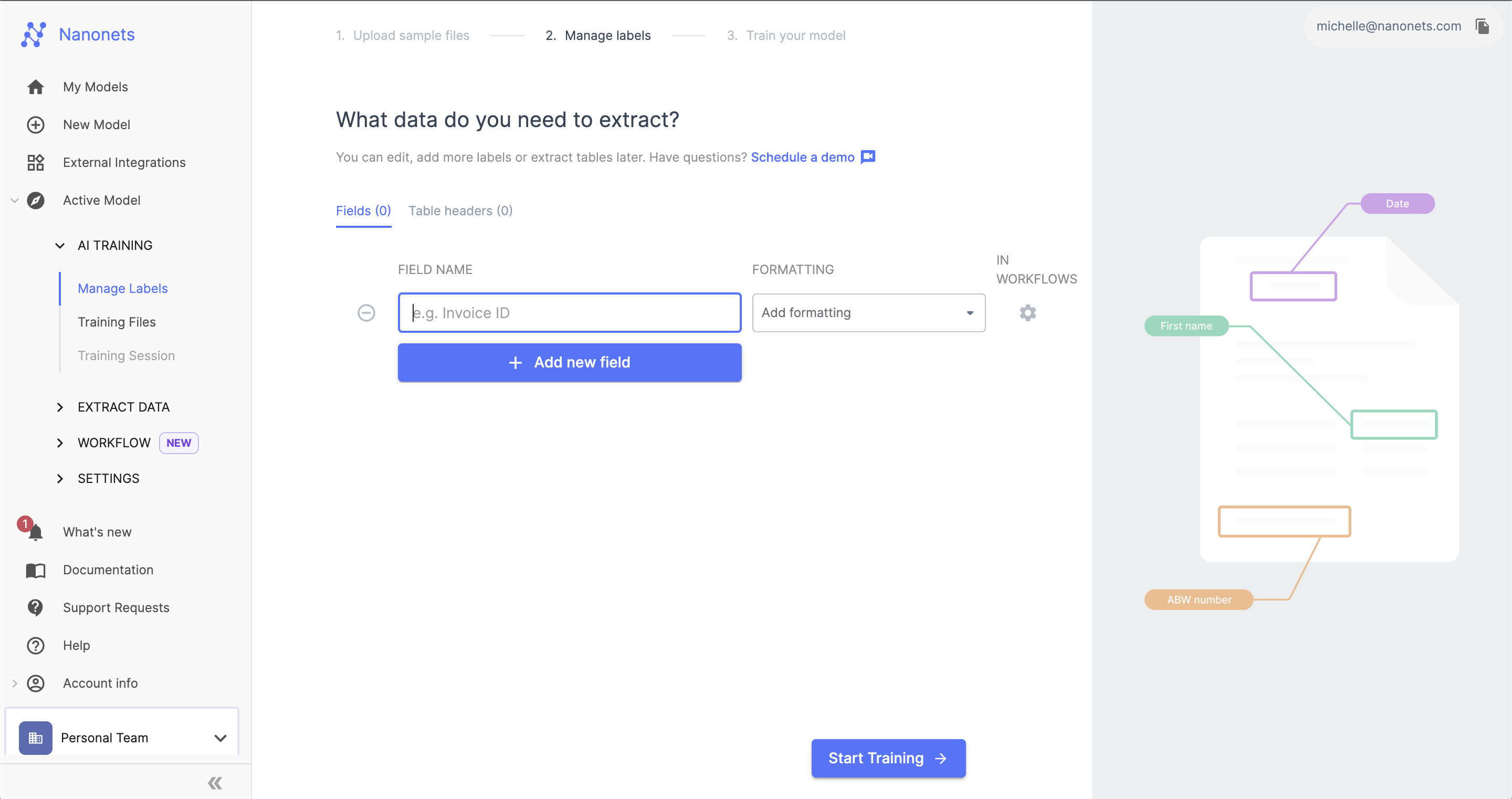
Smakämnen färdigbyggda modeller vet redan hur man på ett intelligent sätt extraherar standardfält från varje dokumenttyp. Du kan också konfigurera dina anpassade fält och träna AI-modellen. Du kan sedan förbereda modellen med några prover. Rita bara zoner på exempeldokument för att kartlägga var den kritiska informationen finns.
Nu är du redo att köra OCR och extrahera data från dina dokument. Nanonets utnyttjar avancerade AI- och ML-algoritmer för att automatiskt identifiera och fånga text från komplexa dokumentlayouter med hög noggrannhet. AI:n "läser" var och en dokumentera, extraherar de definierade fälten och matar ut strukturerad data redo för export.

Det här steget är helt automatiserat för dig när datafälten och AI-modellen är korrekt konfigurerade. Bakom kulisserna konverterar OCR-tekniken skannade bilder till text. Intelligent zondetektering plockar sedan ut relevanta datafält.
4. Validera och korrigera data
Granska de extraherade uppgifterna för noggrannhet. Nanonets gör detta enkelt eftersom det låter dig göra korrigeringar direkt i dokumentvisningen. För mer avancerade användare kan du också redigera den strukturerade JSON-utgång.

Du kan också använda automatiserad validering möjligheter att sätta upp regler för att validera insamlad data. Du kan till exempel kontrollera om ett datum faller inom ett giltigt intervall eller ett numeriskt värde under en tröskel. Eventuella valideringsproblem flaggas för granskning.
5. Exportera och integrera kalkylbladsdata
Den slutliga utdata som innehåller de strukturerade data som extraherats från dina skannade dokument eller PDF-filer kan laddas ner och användas för nedströmsändamål. Nanonets låter dig exportera den som en CSV, Excel- eller JSON-fil, vilket gör att du enkelt kan importera data till din föredragna kalkylprogram eller annan affärsprogramvara.

Du kan också direkt integrera med populära appar som Google Sheets, Quickbooks, Salesforce, etc. The Zapier integration låter dig ansluta till över 5000+ appar för sömlöst dataflöde. Denna integration säkerställer att din data uppdateras automatiskt på alla dina plattformar i realtid.
Hur man förbättrar OCR till kalkylbladsprocessen
OCR-teknik är inte perfekt. Det kan ibland kämpa med skanningar av låg kvalitet, komplexa layouter eller ovanliga teckensnitt. Men även mindre marginella förbättringar i OCR-processen kan leda till betydande tids- och kostnadsbesparingar.
Anta att du kör en försäkringsföretag som behandlar tusentals dokument per dag. Även en 2% förbättring av OCR-noggrannheten kan spara hundratals arbetstimmar per vecka.
Här är några sätt att förbättra OCR till kalkylarksprocessen:
1. Förbättra kvaliteten på dina skanningar
Se till att dokumenten du skannar är tydliga och läsbara. Skanningar av dålig kvalitet kan leda till fel i OCR-processen. Så, förbehandla skanningar för att förbättra bildkvaliteten innan du matar in dem i ditt OCR-system.

Tips för att förbättra skanningskvaliteten:
- Använd en högupplöst skanner (minst 300 dpi). Detta fångar upp finare detaljer som kan hjälpa OCR-motorn att korrekt känna igen tecken.
- Se till att sidorna är korrekt justerade och inte skeva. Snedvändning fixar lutade skanningar.
- Kontrollera skanningens ljusstyrka och kontrast. Justera nivåerna så att texten är tydligt synlig och inte för ljus eller mörk.
- Rengör skannerglaset för att undvika damm, fläckar eller artefakter på skannade bilder.
- Använd Adobe Scan eller liknande appar för att fånga högkvalitativa skanningar med din smartphone.
- Använd bildförbättringstekniker som skärpa, brusreducering och binarisering.
2. Standardisera dina dokument
Konsekvens i dokumentlayout och design kan förbättra OCR-noggrannheten avsevärt. Om möjligt, standardisera formatet för dokument du behandlar. Detta innebär att datafälten ska hållas på den exakta platsen i varje dokument, använda konsekventa teckensnitt och storlekar och bibehålla en ren, stilren layout.

Här är några tips för att standardisera dokument:
- Använd en konsekvent mall för alla dokument av samma typ.
- Håll viktiga datafält på samma plats i varje dokument.
- Använd tydliga, läsbara typsnitt och undvik konstnärliga eller ovanliga typsnitt.
- Undvik röran och håll layouten ren och enkel.
- Begränsa användningen av bilder, logotyper och grafik nära viktiga textfält.
- Använd färger med hög kontrast för text och bakgrund för att förbättra läsbarheten.
3. Investera i ett AI-drivet OCR-system
Dessa system använder maskininlärningsalgoritmer för att lära av varje dokument som bearbetas, vilket ständigt förbättrar deras förmåga att känna igen och extrahera relevant data.

Nanoneter är ett utmärkt exempel på en AI-driven OCR systemet. Den erbjuder förutbildade modeller för olika dokumenttyper och låter dig anpassa modellen efter dina behov. Ju mer data den bearbetar, desto bättre känner den igen mönster och extraherar data exakt.
Dessutom tillåter AI-drivna OCR-systems språkigenkänning och kontextförståelse för dem att hantera dokument på olika språk, valutor, skatteformat och mer. Detta gör dem mycket mångsidiga och anpassningsbara till olika affärsbehov.
4. Ställ in automatiserade arbetsflöden
Att automatisera repetitiva manuella steg i ditt OCR-arbetsflöde kan förbättra effektiviteten och minimera fel. Du kan till exempel ställa in regler för automatisk import som säkerställer att OCR-systemet automatiskt behandlar varje faktura som skickas till [e-postskyddad].
Integrationer med affärsprogramvara som ERP tillåta sömlöst dataflöde. De extraherade kalkylbladsdata kan automatiskt synkroniseras till nedströmsdatabaser. Automatiska valideringsregler hjälper till att fånga upp eventuella extraheringsfel tidigt. Arbetsflöden kan dirigera dokument som behöver granskas till lämplig personal. Automatiska meddelanden och påminnelser säkerställer att ingen deadline missas.
Avslutande tankar
OCR-teknik har revolutionerat hur vi extraherar och arbetar med data från skannade dokument och PDF-filer. Genom att konvertera bilder till strukturerade kalkylbladsdata eliminerar OCR tråkig manuell inmatning samtidigt som analysmöjligheterna förbättras.
Som den här guiden beskrev kan det spara enorma mängder tid att skapa ett effektivt OCR-arbetsflöde med rätt verktyg, som Nanonets. Mindre förbättringar av noggrannheten leder också snabbt till betydande besparingar.
Vill du se hur OCR kan påskynda ditt företags arbetsflöden? Nanonets erbjuder en gratisversion för att testa AI-driven dataextraktion från dina dokument. Att konvertera PDF-tabeller eller skannade fakturor till redigerbara Excel-ark har aldrig varit enklare. Registrera dig nu för att komma igång!
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://nanonets.com/blog/ocr-to-spreadsheet/

