Att låsa upp korrekta och insiktsfulla svar från stora mängder text är en spännande möjlighet som möjliggörs av stora språkmodeller (LLM). När man bygger LLM-applikationer är det ofta nödvändigt att ansluta och fråga externa datakällor för att ge relevant kontext till modellen. Ett populärt tillvägagångssätt är att använda Retrieval Augmented Generation (RAG) för att skapa Q&A-system som förstår komplex information och ger naturliga svar på frågor. RAG tillåter modeller att utnyttja stora kunskapsbaser och leverera mänskliga dialoger för applikationer som chatbots och företagssökassistenter.
I det här inlägget utforskar vi hur man kan utnyttja kraften i LamaIndex, Lama 2-70B-chattoch Langkedja att bygga kraftfulla fråge- och svarsapplikationer. Med dessa toppmoderna teknologier kan du ta in textkorpus, indexera kritisk kunskap och generera text som svarar på användarnas frågor exakt och tydligt.
Lama 2-70B-chatt
Llama 2-70B-Chat är en kraftfull LLM som konkurrerar med ledande modeller. Den är förtränad på två biljoner texttokens och avsedd av Meta att användas för chatthjälp till användare. Förträningsdata hämtas från allmänt tillgängliga data och avslutas i september 2022, och finjusteringsdata avslutas i juli 2023. För mer information om modellens träningsprocess, säkerhetsöverväganden, lärdomar och avsedda användningsområden, se artikeln Llama 2: Open Foundation och finjusterade chattmodeller. Llama 2-modeller finns tillgängliga på Amazon SageMaker JumpStart för en snabb och enkel implementering.
LamaIndex
LamaIndex är ett dataramverk som gör det möjligt att bygga LLM-applikationer. Det tillhandahåller verktyg som erbjuder dataanslutningar för att mata in din befintliga data med olika källor och format (PDF, dokument, API:er, SQL och mer). Oavsett om du har data lagrad i databaser eller i PDF-filer, gör LlamaIndex det enkelt att använda dessa data för LLM:er. Som vi visar i det här inlägget gör LlamaIndex API:er dataåtkomst enkel och gör att du kan skapa kraftfulla anpassade LLM-applikationer och arbetsflöden.
Om du experimenterar och bygger med LLM:er är du förmodligen bekant med LangChain, som erbjuder ett robust ramverk som förenklar utvecklingen och driftsättningen av LLM-drivna applikationer. I likhet med LangChain erbjuder LlamaIndex ett antal verktyg, inklusive dataanslutningar, dataindex, motorer och dataagenter, såväl som applikationsintegrationer som verktyg och observerbarhet, spårning och utvärdering. LlamaIndex fokuserar på att överbrygga klyftan mellan data och kraftfulla LLM:er och effektivisera datauppgifter med användarvänliga funktioner. LlamaIndex är specifikt designad och optimerad för att bygga sök- och hämtningsprogram, såsom RAG, eftersom det ger ett enkelt gränssnitt för att söka efter LLM och hämta relevanta dokument.
Lösningsöversikt
I det här inlägget visar vi hur man skapar en RAG-baserad applikation med LlamaIndex och en LLM. Följande diagram visar steg-för-steg-arkitekturen för denna lösning som beskrivs i följande avsnitt.
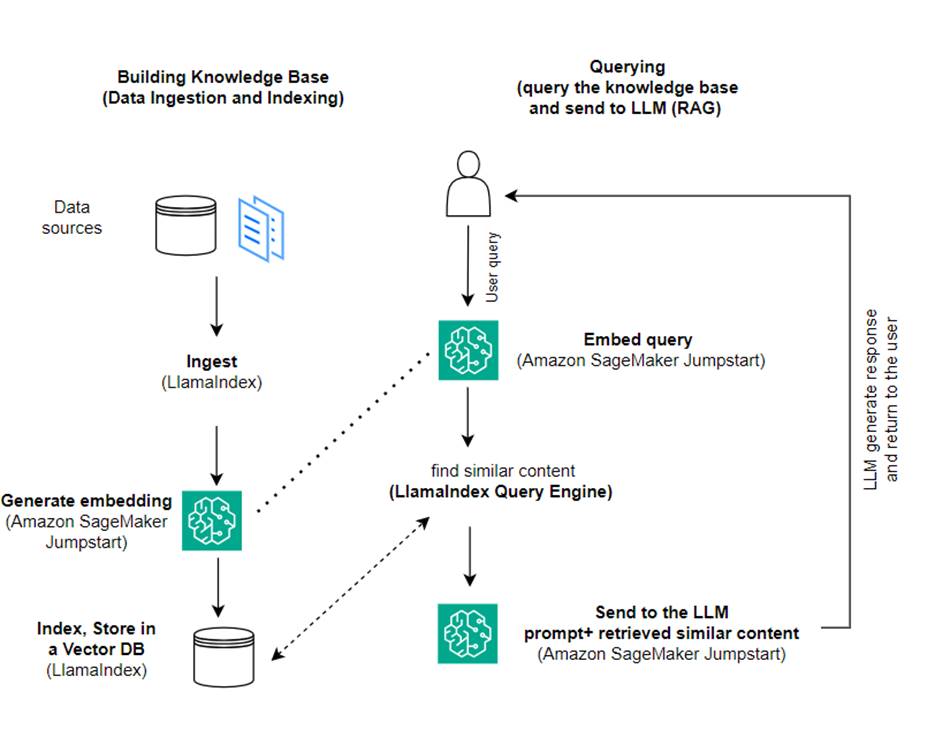
RAG kombinerar informationssökning med naturligt språkgenerering för att producera mer insiktsfulla svar. När du uppmanas, söker RAG först i textkorpus för att hämta de mest relevanta exemplen till ingången. Under svarsgenerering betraktar modellen dessa exempel för att öka dess kapacitet. Genom att inkludera relevanta hämtade passager tenderar RAG-svar att vara mer sakliga, sammanhängande och konsekventa med sammanhanget jämfört med grundläggande generativa modeller. Detta hämtningsgenererade ramverk drar fördel av styrkorna med både hämtning och generering, och hjälper till att hantera problem som upprepning och brist på sammanhang som kan uppstå från rena autoregressiva konversationsmodeller. RAG introducerar ett effektivt tillvägagångssätt för att bygga samtalsagenter och AI-assistenter med kontextualiserade svar av hög kvalitet.
Att bygga lösningen består av följande steg:
- Montera myggnät för luckor Amazon SageMaker Studio som utvecklingsmiljö och installera nödvändiga beroenden.
- Distribuera en inbäddningsmodell från Amazon SageMaker JumpStart-hubben.
- Ladda ner pressmeddelanden för att använda som vår externa kunskapsbas.
- Bygg ett index av pressmeddelandena för att kunna fråga och lägga till som ytterligare sammanhang till prompten.
- Fråga kunskapsbasen.
- Bygg en Q&A-applikation med hjälp av LlamaIndex och LangChain-agenter.
All kod i det här inlägget finns tillgänglig i GitHub repo.
Förutsättningar
För det här exemplet behöver du ett AWS-konto med en SageMaker-domän och lämplig AWS identitets- och åtkomsthantering (IAM) behörigheter. För instruktioner om kontoinställningar, se Skapa ett AWS-konto. Om du inte redan har en SageMaker-domän, se Amazon SageMaker-domän översikt för att skapa en. I det här inlägget använder vi AmazonSageMakerFullAccess roll. Det rekommenderas inte att du använder denna referens i en produktionsmiljö. Istället bör du skapa och använda en roll med minsta privilegier. Du kan också utforska hur du kan använda Amazon SageMaker Roll Manager att bygga och hantera personbaserade IAM-roller för vanliga maskininlärningsbehov direkt via SageMaker-konsolen.
Dessutom behöver du tillgång till ett minimum av följande instansstorlekar:
- ml.g5.2xlarge för slutpunktsanvändning när du distribuerar Kramande ansikte GPT-J textinbäddningsmodell
- ml.g5.48xlarge för slutpunktsanvändning när du använder Llama 2-Chat-modellens slutpunkt
För att öka din kvot, se Begär en kvothöjning.
Distribuera en GPT-J-inbäddningsmodell med SageMaker JumpStart
Det här avsnittet ger dig två alternativ när du distribuerar SageMaker JumpStart-modeller. Du kan använda en kodbaserad distribution med den kod som tillhandahålls, eller använda SageMaker JumpStart-användargränssnittet (UI).
Implementera med SageMaker Python SDK
Du kan använda SageMaker Python SDK för att distribuera LLM:erna, som visas i koda tillgänglig i förvaret. Slutför följande steg:
- Ställ in instansstorleken som ska användas för distribution av inbäddningsmodellen med hjälp av
instance_type = "ml.g5.2xlarge" - Leta reda på ID för modellen som ska användas för inbäddningar. I SageMaker JumpStart identifieras den som
model_id = "huggingface-textembedding-gpt-j-6b-fp16" - Hämta den förtränade modellbehållaren och distribuera den för slutledning.
SageMaker kommer att returnera namnet på modellens slutpunkt och följande meddelande när inbäddningsmodellen har implementerats framgångsrikt:
Implementera med SageMaker JumpStart i SageMaker Studio
Utför följande steg för att distribuera modellen med SageMaker JumpStart i Studio:
- På SageMaker Studio-konsolen väljer du JumpStart i navigeringsfönstret.

- Sök efter och välj GPT-J 6B Embedding FP16-modellen.
- Välj Distribuera och anpassa distributionskonfigurationen.

- För det här exemplet behöver vi en ml.g5.2xlarge-instans, vilket är standardinstansen som föreslås av SageMaker JumpStart.
- Välj Distribuera igen för att skapa slutpunkten.
Slutpunkten tar cirka 5–10 minuter att vara i drift.

Efter att du har distribuerat inbäddningsmodellen, för att kunna använda LangChain-integrationen med SageMaker API:er, måste du skapa en funktion för att hantera indata (råtext) och omvandla dem till inbäddningar med modellen. Du gör detta genom att skapa en klass som heter ContentHandler, som tar en JSON av indata och returnerar en JSON av textinbäddningar: class ContentHandler(EmbeddingsContentHandler).
Skicka modellens slutpunktsnamn till ContentHandler funktion för att konvertera texten och returnera inbäddningar:
Du kan hitta slutpunktsnamnet i antingen utdata från SDK:n eller i distributionsdetaljerna i SageMaker JumpStart UI.
Du kan testa att ContentHandler funktion och slutpunkt fungerar som förväntat genom att mata in lite råtext och köra embeddings.embed_query(text) fungera. Du kan använda exemplet som tillhandahålls text = "Hi! It's time for the beach" eller prova din egen text.
Distribuera och testa Llama 2-Chat med SageMaker JumpStart
Nu kan du distribuera modellen som kan ha interaktiva konversationer med dina användare. I det här fallet väljer vi en av Llama 2-chatt-modellerna, som identifieras via
Modellen måste distribueras till en realtidsslutpunkt med hjälp av predictor = my_model.deploy(). SageMaker kommer att returnera modellens slutpunktsnamn, som du kan använda för endpoint_name variabel att referera till senare.
Du definierar a print_dialogue funktion för att skicka input till chattmodellen och ta emot dess utdatasvar. Nyttolasten inkluderar hyperparametrar för modellen, inklusive följande:
- max_new_tokens – Avser det maximala antalet tokens som modellen kan generera i sina utgångar.
- top_p – Avser den kumulativa sannolikheten för de tokens som kan behållas av modellen när den genererar dess utdata
- temperatur – Avser slumpmässigheten hos de utgångar som genereras av modellen. En temperatur högre än 0 eller lika med 1 ökar nivån av slumpmässighet, medan en temperatur på 0 kommer att generera de mest sannolika tokens.
Du bör välja dina hyperparametrar baserat på ditt användningsfall och testa dem på lämpligt sätt. Modeller som Llama-familjen kräver att du inkluderar en ytterligare parameter som anger att du har läst och accepterat slutanvändarlicensavtalet (EULA):
För att testa modellen, byt ut innehållssektionen för den inmatade nyttolasten: "content": "what is the recipe of mayonnaise?". Du kan använda dina egna textvärden och uppdatera hyperparametrarna för att förstå dem bättre.
I likhet med implementeringen av inbäddningsmodellen kan du distribuera Llama-70B-Chat med SageMaker JumpStart UI:
- Välj på SageMaker Studio-konsolen Försprång i navigeringsfönstret
- Sök efter och välj
Llama-2-70b-Chat model - Acceptera EULA och välj Distribuera, använder standardinstansen igen
I likhet med inbäddningsmodellen kan du använda LangChain-integration genom att skapa en innehållshanterarmall för in- och utdata från din chattmodell. I det här fallet definierar du ingångarna som de som kommer från en användare och anger att de styrs av system prompt. De system prompt informerar modellen om dess roll i att hjälpa användaren för ett visst användningsfall.
Denna innehållshanterare skickas sedan när modellen anropas, förutom de tidigare nämnda hyperparametrarna och anpassade attribut (EULA-acceptans). Du analyserar alla dessa attribut med följande kod:
När slutpunkten är tillgänglig kan du testa att den fungerar som förväntat. Du kan uppdatera llm("what is amazon sagemaker?") med din egen text. Du måste också definiera det specifika ContentHandler för att anropa LLM med LangChain, som visas i koda och följande kodavsnitt:
Använd LlamaIndex för att bygga RAG
För att fortsätta, installera LlamaIndex för att skapa RAG-applikationen. Du kan installera LlamaIndex med hjälp av pip: pip install llama_index
Du måste först ladda din data (kunskapsbas) till LlamaIndex för indexering. Detta innebär några steg:
- Välj en dataladdare:
LlamaIndex tillhandahåller ett antal dataanslutningar tillgängliga på LamaHub för vanliga datatyper som JSON, CSV och textfiler, såväl som andra datakällor, så att du kan mata in en mängd olika datauppsättningar. I det här inlägget använder vi SimpleDirectoryReader för att mata in några PDF-filer som visas i koden. Vårt dataexempel är två Amazon-pressmeddelanden i PDF-version i pressmeddelanden mapp i vårt kodlager. När du har laddat in PDF-filerna kan du se att de har konverterats till en lista med 11 element.
Istället för att ladda dokumenten direkt kan du också dölja Document objekt in i Node objekt innan de skickas till indexet. Valet mellan att skicka hela Document invända mot indexet eller konvertera dokumentet till Node objekt innan indexering beror på ditt specifika användningsfall och strukturen på dina data. Nodmetoden är generellt sett ett bra val för långa dokument, där du vill bryta och hämta specifika delar av ett dokument snarare än hela dokumentet. För mer information, se Dokument / Noder.
- Instantiera laddaren och ladda dokumenten:
Det här steget initierar loader-klassen och alla nödvändiga konfigurationer, till exempel om dolda filer ska ignoreras. För mer information, se SimpleDirectoryReader.
- Ring lastarens
load_datametod för att analysera dina källfiler och data och konvertera dem till LlamaIndex Document-objekt, redo för indexering och sökning. Du kan använda följande kod för att slutföra datainmatningen och förberedelserna för fulltextsökning med hjälp av LlamaIndex indexerings- och hämtningsfunktioner:
- Bygg indexet:
Nyckelfunktionen hos LlamaIndex är dess förmåga att konstruera organiserade index över data, som representeras som dokument eller noder. Indexeringen underlättar effektiv sökning av data. Vi skapar vårt index med standardin-memory vektorlager och med vår definierade inställningskonfiguration. Lamaindexet Inställningar är ett konfigurationsobjekt som tillhandahåller vanliga resurser och inställningar för indexering och frågeoperationer i en LlamaIndex-applikation. Det fungerar som ett singleton-objekt, så att du kan ställa in globala konfigurationer, samtidigt som du kan åsidosätta specifika komponenter lokalt genom att skicka dem direkt till gränssnitten (som LLMs, inbäddningsmodeller) som använder dem. När en viss komponent inte uttryckligen tillhandahålls, faller LlamaIndex-ramverket tillbaka till inställningarna som definieras i Settings objekt som en global standard. För att använda våra inbäddnings- och LLM-modeller med LangChain och konfigurera Settings vi behöver installera llama_index.embeddings.langchain och llama_index.llms.langchain. Vi kan konfigurera Settings objekt som i följande kod:
Som standard VectorStoreIndex använder ett in-memory SimpleVectorStore som initieras som en del av standardlagringskontexten. I verkliga användningsfall behöver du ofta ansluta till externa vektorbutiker som t.ex Amazon OpenSearch Service. För mer information, se Vector Engine för Amazon OpenSearch Serverless.
Nu kan du köra frågor och svar över dina dokument genom att använda query_engine från LlamaIndex. För att göra det, skicka indexet du skapade tidigare för frågor och ställ din fråga. Frågemotorn är ett generiskt gränssnitt för sökning av data. Det tar en fråga på naturligt språk som input och returnerar ett rikt svar. Frågemotorn byggs vanligtvis ovanpå en eller flera index med hjälp av retriever.
Du kan se att RAG-lösningen kan hämta rätt svar från de medföljande dokumenten:
Använd LangChain verktyg och agenter
Loader klass. Laddaren är utformad för att ladda data till LlamaIndex eller därefter som ett verktyg i en LangChain agent. Detta ger dig mer kraft och flexibilitet att använda detta som en del av din applikation. Du börjar med att definiera ditt verktyg från agentklassen LangChain. Funktionen som du skickar vidare till ditt verktyg frågar efter indexet du byggt över dina dokument med hjälp av LlamaIndex.
Sedan väljer du rätt typ av agent som du vill använda för din RAG-implementering. I det här fallet använder du chat-zero-shot-react-description ombud. Med denna agent kommer LLM att använda det tillgängliga verktyget (i detta scenario, RAG över kunskapsbasen) för att ge svaret. Du initierar sedan agenten genom att skicka ditt verktyg, LLM och agenttyp:
Du kan se agenten gå igenom thoughts, actionsoch observation , använd verktyget (i detta scenario, fråga efter dina indexerade dokument); och returnera ett resultat:
Du kan hitta end-to-end-implementeringskoden i den medföljande GitHub repo.
Städa upp
För att undvika onödiga kostnader kan du rensa upp dina resurser, antingen via följande kodsnuttar eller Amazon JumpStart UI.
För att använda Boto3 SDK, använd följande kod för att ta bort textinbäddningsmodellens slutpunkt och textgenereringsmodellens slutpunkt, såväl som slutpunktskonfigurationerna:
Utför följande steg för att använda SageMaker-konsolen:
- På SageMaker-konsolen, under Inferens i navigeringsfönstret, välj Endpoints
- Sök efter slutpunkter för inbäddning och textgenerering.
- På sidan med slutpunktsdetaljer väljer du Ta bort.
- Välj Ta bort igen för att bekräfta.
Slutsats
För användningsfall fokuserade på sökning och hämtning erbjuder LlamaIndex flexibla funktioner. Det utmärker sig vid indexering och hämtning för LLM, vilket gör det till ett kraftfullt verktyg för djupgående utforskning av data. Med LlamaIndex kan du skapa organiserade dataindex, använda olika LLM, utöka data för bättre LLM-prestanda och fråga efter data med naturligt språk.
Det här inlägget demonstrerade några viktiga LlamaIndex-koncept och möjligheter. Vi använde GPT-J för inbäddning och Llama 2-Chat som LLM för att bygga en RAG-applikation, men du kunde använda vilken modell som helst istället. Du kan utforska det omfattande utbudet av modeller som finns på SageMaker JumpStart.
Vi visade också hur LlamaIndex kan tillhandahålla kraftfulla, flexibla verktyg för att ansluta, indexera, hämta och integrera data med andra ramverk som LangChain. Med LlamaIndex-integrationer och LangChain kan du bygga mer kraftfulla, mångsidiga och insiktsfulla LLM-applikationer.
Om författarna
 Dr Romina Sharifpour är senior maskininlärnings- och artificiell intelligenslösningsarkitekt på Amazon Web Services (AWS). Hon har tillbringat över 10 år med att leda designen och implementeringen av innovativa helhetslösningar som möjliggörs av framsteg inom ML och AI. Rominas intresseområden är naturlig språkbehandling, stora språkmodeller och MLOps.
Dr Romina Sharifpour är senior maskininlärnings- och artificiell intelligenslösningsarkitekt på Amazon Web Services (AWS). Hon har tillbringat över 10 år med att leda designen och implementeringen av innovativa helhetslösningar som möjliggörs av framsteg inom ML och AI. Rominas intresseområden är naturlig språkbehandling, stora språkmodeller och MLOps.
 Nicole Pinto är en AI/ML Specialist Solutions Architect baserad i Sydney, Australien. Hennes bakgrund inom sjukvård och finansiella tjänster ger henne ett unikt perspektiv på att lösa kundproblem. Hon brinner för att möjliggöra kunder genom maskininlärning och stärka nästa generations kvinnor inom STEM.
Nicole Pinto är en AI/ML Specialist Solutions Architect baserad i Sydney, Australien. Hennes bakgrund inom sjukvård och finansiella tjänster ger henne ett unikt perspektiv på att lösa kundproblem. Hon brinner för att möjliggöra kunder genom maskininlärning och stärka nästa generations kvinnor inom STEM.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-knowledge-powered-conversational-applications-using-llamaindex-and-llama-2-chat/

