I dagens affärslandskap letar organisationer ständigt efter sätt att optimera sina finansiella processer, förbättra effektiviteten och driva kostnadsbesparingar. Ett område som har betydande förbättringspotential är leverantörsskulder. På en hög nivå inkluderar leverantörsreskontraprocessen att ta emot och skanna fakturor, extrahera relevant data från skannade fakturor, validering, godkännande och arkivering. Det andra steget (extraktion) kan vara komplext. Varje faktura och kvitto ser olika ut. Etiketterna är ofullkomliga och inkonsekventa. De viktigaste delarna av information som pris, säljarens namn, säljarens adress och betalningsvillkor är ofta inte explicit märkta och måste tolkas utifrån sammanhang. Den traditionella metoden att använda mänskliga granskare för att extrahera data är tidskrävande, felbenägen och inte skalbar.
I det här inlägget visar vi hur man automatiserar leverantörsreskontraprocessen med hjälp av amazontext för datautvinning. Vi tillhandahåller också en referensarkitektur för att bygga en pipeline för fakturaautomatisering som möjliggör extrahering, verifiering, arkivering och intelligent sökning.
Lösningsöversikt
Följande arkitekturdiagram visar stegen i ett arbetsflöde för kvitton och fakturahantering. Det börjar med ett dokumentfångststeg för att säkert samla in och lagra skannade fakturor och kvitton. Nästa steg är utvinningsfasen, där du skickar de insamlade fakturorna och kvittonen till Amazon Textract AnalyzeExpense API för att extrahera ekonomiskt relaterade relationer mellan text som leverantörsnamn, fakturamottagningsdatum, orderdatum, förfallna belopp, betalat belopp och så vidare. I nästa steg använder du fördefinierade utgiftsregler för att avgöra om du automatiskt ska godkänna eller avvisa kvittot. Godkända och avvisade dokument hamnar i sina respektive mappar inom Amazon enkel lagringstjänst (Amazon S3) hink. För godkända dokument kan du söka i alla extraherade fält och värden med hjälp av Amazon OpenSearch Service. Du kan visualisera den indexerade metadatan med hjälp av OpenSearch Dashboards. Godkända dokument är också inställda för att flyttas till Amazon S3 Intelligent Tiering för långsiktig lagring och arkivering med hjälp av S3 livscykelpolicyer.
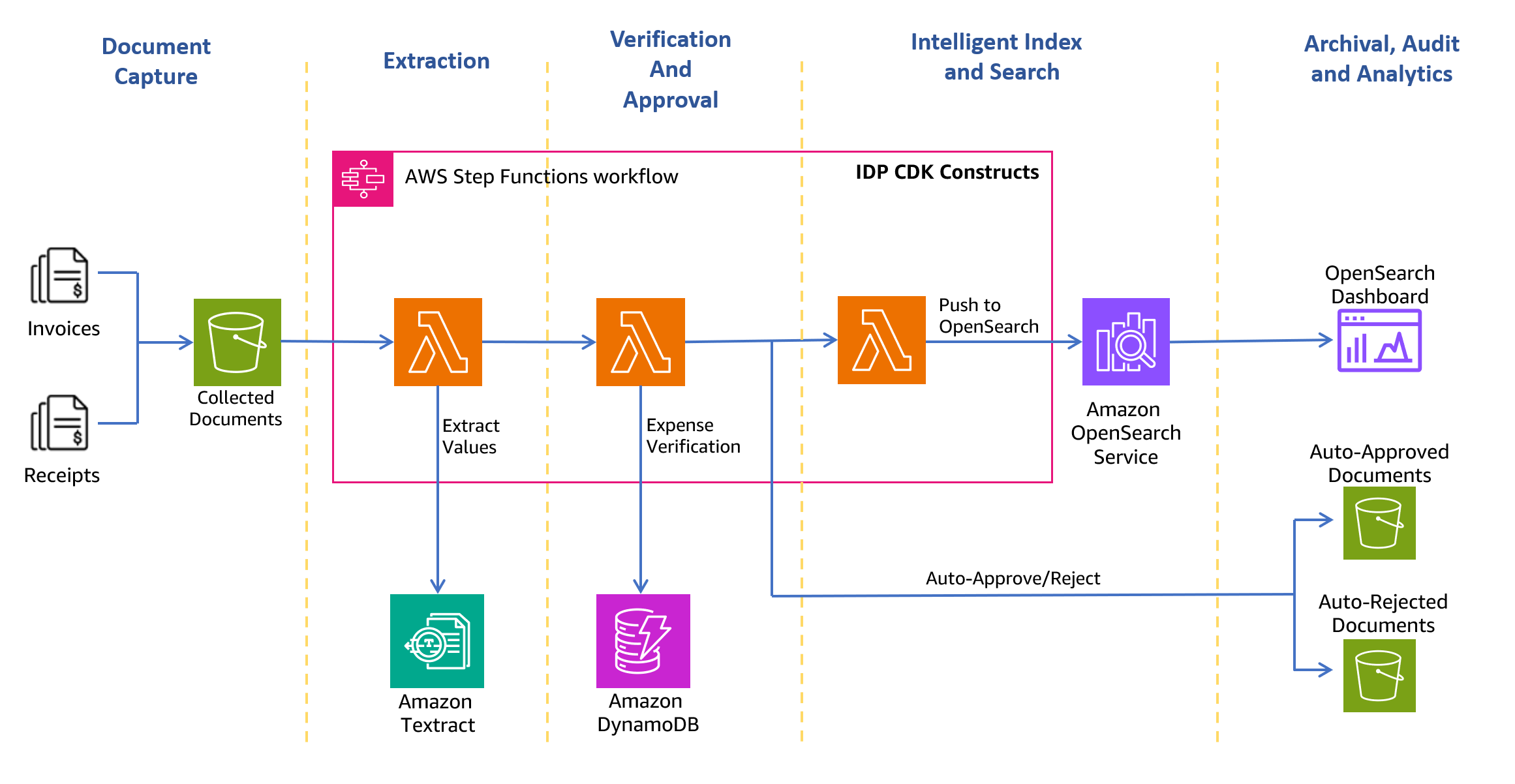
Följande avsnitt tar dig genom processen för att skapa lösningen.
Förutsättningar
För att distribuera den här lösningen måste du ha följande:
- Ett AWS-konto.
- An AWS Cloud9 miljö. AWS Cloud9 är en molnbaserad integrerad utvecklingsmiljö (IDE) som låter dig skriva, köra och felsöka din kod med bara en webbläsare. Den innehåller en kodredigerare, debugger och terminal.
För att skapa AWS Cloud9-miljön, ange ett namn och en beskrivning. Behåll allt annat som standard. Välj IDE-länken på AWS Cloud9-konsolen för att navigera till IDE. Du är nu redo att använda AWS Cloud9-miljön.
Distribuera lösningen
För att ställa in lösningen använder du AWS Cloud Development Kit (AWS CDK) för att distribuera en AWS molnformation stack.
- I din AWS Cloud9 IDE-terminal, klona GitHub repository och installera beroenden. Kör följande kommandon för att distribuera
InvoiceProcessorstack:
Implementeringen tar cirka 25 minuter med standardkonfigurationsinställningarna från GitHub-repo. Ytterligare utdatainformation är också tillgänglig på AWS CloudFormation-konsolen.
- När AWS CDK-distributionen är klar skapar du regler för utgiftsvalidering i en Amazon DynamoDB tabell. Du kan använda samma AWS Cloud9-terminal för att köra följande kommandon:
- I S3-skopan som börjar med
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, skapa en uppladdningsmapp.
In Amazon Cognito, bör du redan ha en befintlig användarpool som heter OpenSearchResourcesCognitoUserPool*. Vi använder denna användarpool för att skapa en ny användare.
- På Amazon Cognito-konsolen, navigera till användarpoolen
OpenSearchResourcesCognitoUserPool*. - Skapa en ny Amazon Cognito-användare.
- Ange ett användarnamn och lösenord som du väljer och notera dem för senare användning.
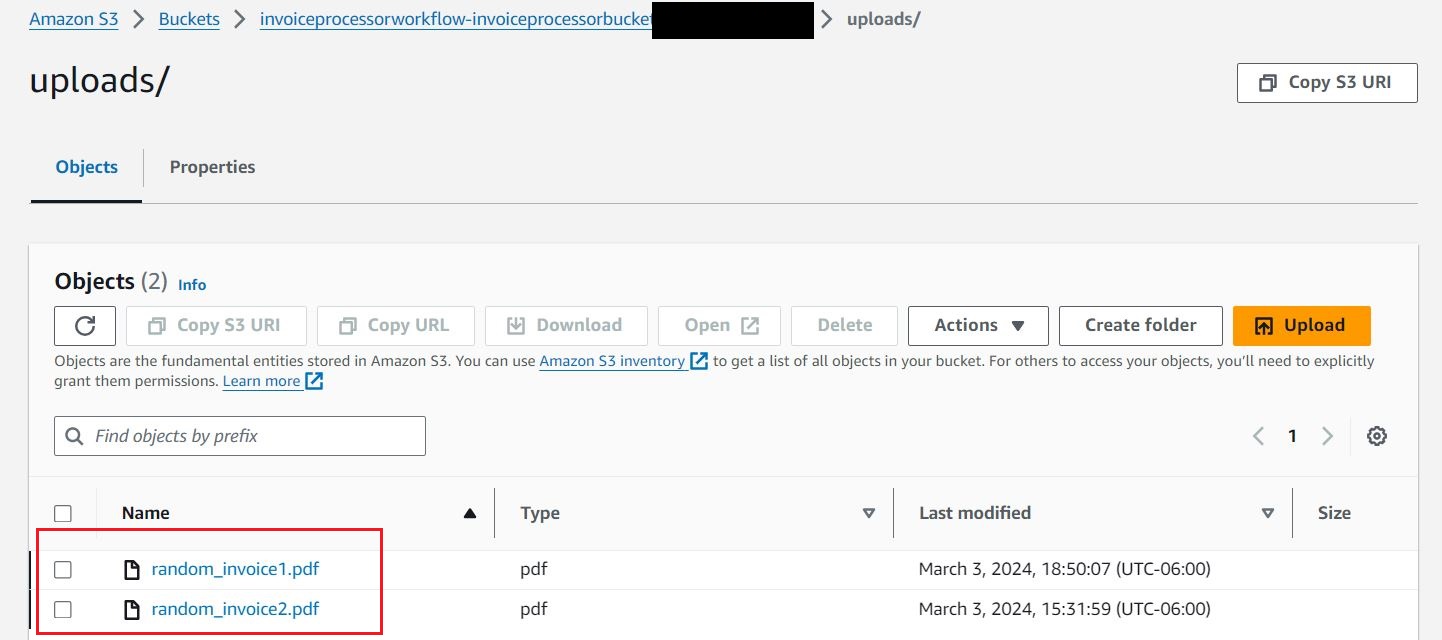
- Ladda upp dokumenten slumpmässig_faktura1 och slumpmässig_faktura2 till S3
uploadsmapp för att starta arbetsflödena.
Låt oss nu dyka in i vart och ett av dokumentbearbetningsstegen.
Dokumentfångst
Kunder hanterar fakturor och kvitton i en mängd olika format från olika leverantörer. Dessa dokument tas emot via kanaler som papperskopior, skannade kopior som laddas upp till fillagring eller delade lagringsenheter. I dokumentinsamlingsstadiet lagrar du alla skannade kopior av kvitton och fakturor i ett mycket skalbart lager som i en S3-hink.
Extraktion
Nästa steg är utvinningsfasen, där du skickar de insamlade fakturorna och kvittonen till Amazon Textract AnalyzeExpense API för att extrahera ekonomiskt relaterade relationer mellan text som leverantörsnamn, fakturamottagningsdatum, orderdatum, belopp som förfaller/betalt, etc.
AnalyseraExpense är ett API dedikerat till att behandla faktura- och kvittondokument. Det finns både som synkront eller asynkront API. Synchronous API låter dig skicka bilder i byte-format, och asynkron API låter dig skicka filer i JPG-, PNG-, TIFF- och PDF-format. De AnalyzeExpense API-svar består av tre distinkta sektioner:
- Sammanfattningsfält – Det här avsnittet innehåller både normaliserade nycklar och de uttryckligen nämnda nycklarna tillsammans med deras värden.
AnalyzeExpensenormaliserar nycklarna för kontaktrelaterad information såsom leverantörens namn och leverantörsadress, skatte-ID-relaterade nycklar såsom skattebetalar-ID, betalningsrelaterade nycklar såsom belopp och rabatt, och allmänna nycklar såsom faktura-ID, leveransdatum och kontonummer. Nycklar som inte är normaliserade visas fortfarande i sammanfattningsfälten som nyckel-värdepar. För en fullständig lista över utgiftsfält som stöds, se Analysera fakturor och kvitton. - Rader – Det här avsnittet innehåller normaliserade radnycklar som artikelbeskrivning, enhetspris, kvantitet och produktkod.
- OCR-block – Blocket innehåller råtextutdraget från fakturasidan. Råtextextraktet kan användas för efterbearbetning och identifiering av information som inte täcks som en del av sammanfattnings- och radfälten.
Detta inlägg använder Amazon Textract IDP CDK konstruerar (AWS CDK-komponenter för att definiera infrastruktur för intelligent dokumentbearbetning (IDP) arbetsflöden), vilket låter dig bygga användningsfallsspecifika, anpassningsbara IDP-arbetsflöden. Konstruktionerna och proverna är en samling komponenter för att möjliggöra definition av IDP-processer på AWS och publicerade till GitHub. De huvudsakliga begreppen som används är AWS CDK-konstruktionerna, den faktiska AWS CDK stackaroch AWS stegfunktioner.
Följande bild visar arbetsflödet för stegfunktioner.
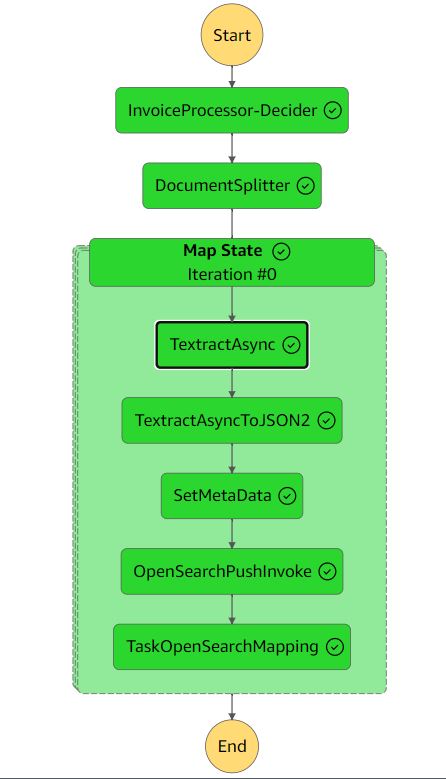
Extraktionsarbetsflödet inkluderar följande steg:
- InvoiceProcessor-Decider - En AWS Lambda funktion som verifierar om inmatningsdokumentformatet stöds av Amazon Textract. För mer information om format som stöds, se Mata in dokument.
- DocumentSplitter – En lambdafunktion som genererar 2,500 XNUMX sidor (max) bitar från dokument och kan bearbeta stora flersidiga dokument.
- Karta tillstånd – En lambdafunktion som bearbetar varje bit parallellt.
- TextractAsync – Den här uppgiften anropar Amazon Textract med hjälp av följande asynkrona API bästa praxis med Amazon enkel meddelandetjänst (Amazon SNS) aviseringar och användningar
OutputConfigför att lagra Amazon Textract JSON-utgången i S3-hinken som du skapade tidigare. Den består av två lambdafunktioner: en för att lämna in dokumentet för behandling och en som utlöses på SNS-aviseringen. - TextractAsyncToJSON2 - Eftersom den
TextractAsyncuppgift kan producera flera sidnumrerade utdatafiler, denTextractAsyncToJSON2process kombinerar dem till en JSON-fil.
Vi diskuterar detaljerna i de kommande tre stegen i följande avsnitt.
Verifiering och godkännande
För verifieringsstadiet, SetMetaData Lambdafunktionen verifierar om den uppladdade filen är en giltig kostnad enligt reglerna som tidigare konfigurerats i DynamoDB-tabellen. För det här inlägget använder du följande exempelregler:
- Verifieringen är framgångsrik om
INVOICE_RECEIPT_IDär närvarande och matchar det regex(?i)[0-9]{3}[a-z]{3}[0-9]{3}$och ifPO_NUMBERär närvarande och matchar det regex(?i)[a-z0-9]+$ - Verifieringen misslyckas om någon av dem
PO_NUMBERorINVOICE_RECEIPT_IDär felaktig eller saknas i dokumentet.
Efter att filerna har bearbetats flyttar kostnadsverifieringsfunktionen indatafilerna till någondera approved or declined mappar i samma S3-hink.
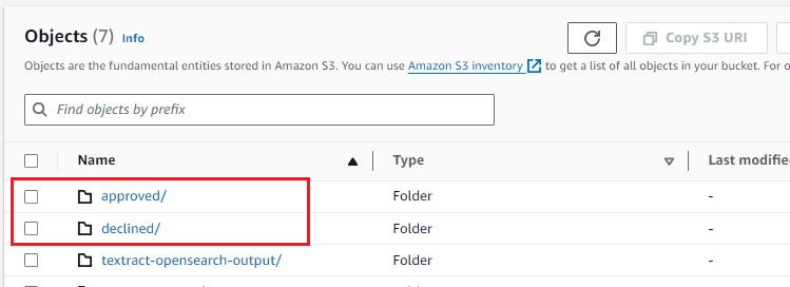
För denna lösning använder vi DynamoDB för att lagra reglerna för utgiftsvalidering. Du kan dock modifiera denna lösning så att den integreras med dina egna eller kommersiella kostnadsvaliderings- eller hanteringslösningar.
Intelligent index och sökning
Med OpenSearchPushInvoke Lambdafunktion, den extraherade kostnadsmetadatan skickas till ett OpenSearch Service-index och är tillgänglig för sökning.
Den slutliga TaskOpenSearchMapping steg rensar sammanhanget, som annars skulle kunna överskrida Steg Funktioner kvot maximal in- eller utdatastorlek för en uppgift, tillstånd eller arbetsflödeskörning.
Efter att OpenSearch Service-indexet har skapats kan du söka efter nyckelord från den extraherade texten via OpenSearch Dashboards.
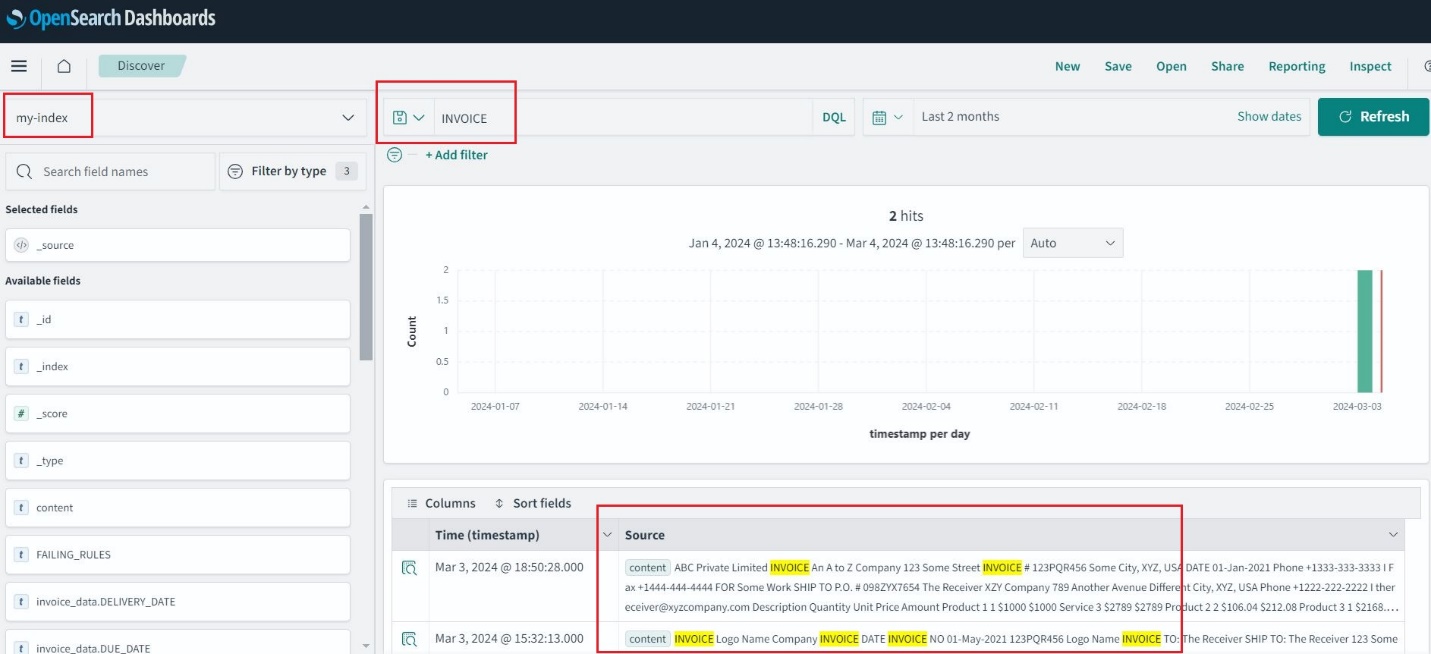
Arkivering, revision och analys
För att hantera livscykeln och arkiveringen av fakturor och kvitton kan du konfigurera S3-livscykelregler för att överföra S3-objekt från standard- till Intelligent-Tiering-lagringsklasser. S3 Intelligent-Tiering övervakar åtkomstmönster och flyttar automatiskt objekt till nivån Infrequent Access när de inte har nåtts på 30 dagar i följd. Efter 90 dagar utan åtkomst flyttas objekten till Archive Instant Access-nivån utan prestandapåverkan eller driftskostnader.
För revision och analys använder den här lösningen OpenSearch Service för att köra analyser på fakturaförfrågningar. OpenSearch-tjänsten gör att du enkelt kan ta in, säkra, söka, samla, visa och analysera data för ett antal användningsfall, som logganalys, applikationssökning, företagssökning och mer.
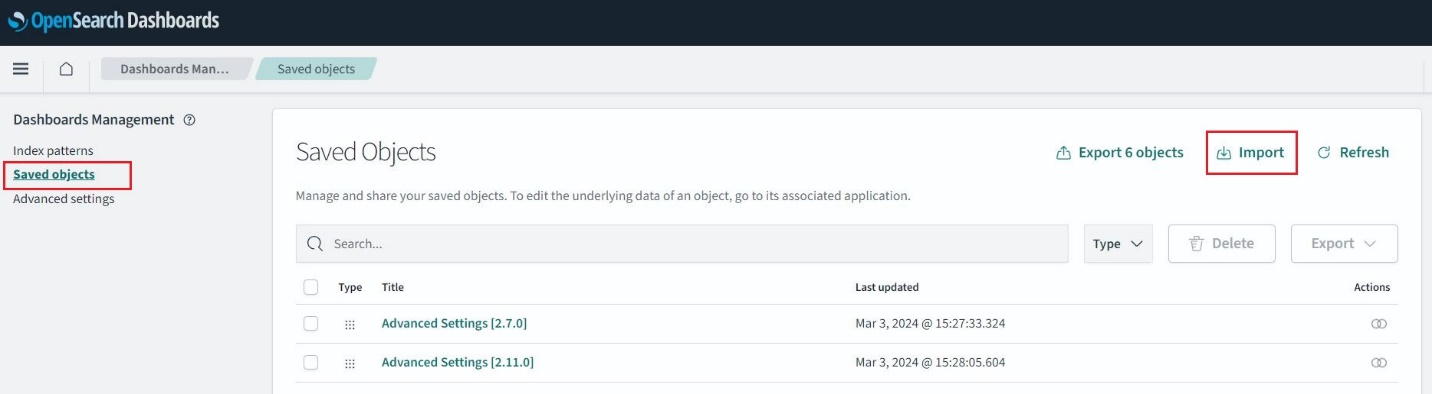
Logga in på OpenSearch Dashboards och navigera till Stackhantering, Sparade objektOch välj sedan Importera. Välj den invoices.ndjson fil från det klonade förvaret och välj Importera. Detta förbefolkar index och bygger visualiseringen.
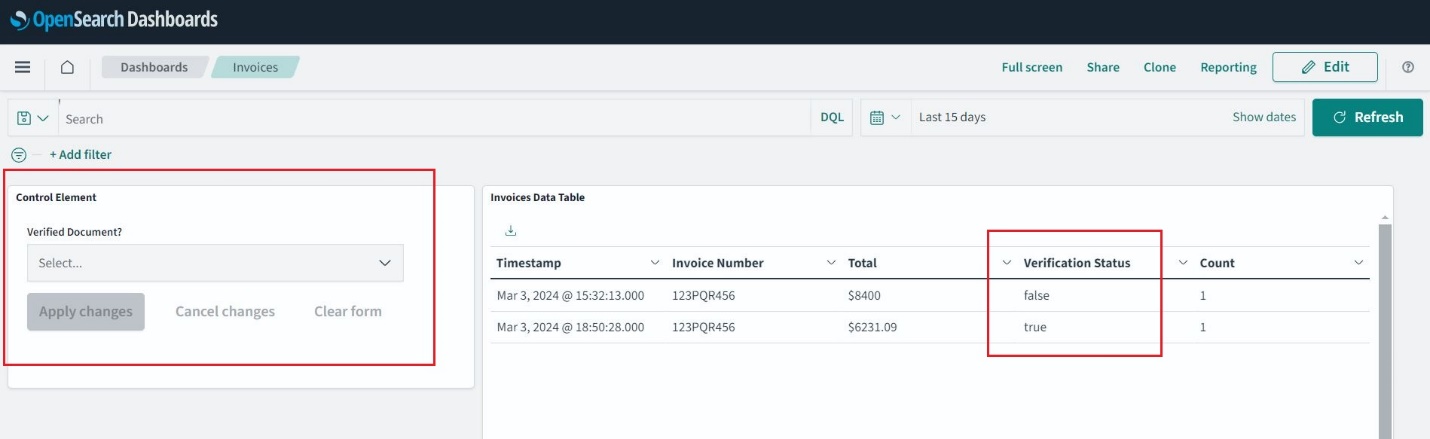
Uppdatera sidan och navigera till Hem, Dashboard, och öppna Fakturor. Du kan nu välja och använda filter och utöka tidsfönstret för att utforska tidigare fakturor.
Städa upp
När du är klar med att utvärdera Amazon Textract för att bearbeta kvitton och fakturor, rekommenderar vi att du rengör alla resurser som du kan ha skapat. Slutför följande steg:
- Ta bort allt innehåll från S3-hinken
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - I AWS Cloud9, kör följande kommandon för att ta bort Amazon Cognito-resurser och CloudFormation-stackar:
- Ta bort AWS Cloud9-miljön som du skapade från AWS Cloud9-konsolen.
Slutsats
I det här inlägget gav vi en översikt över hur vi kan bygga en pipeline för fakturaautomatisering med Amazon Textract för dataextraktion och skapa ett arbetsflöde för validering, arkivering och sökning. Vi gav kodexempel på hur man använder AnalyzeExpense API för utvinning av kritiska fält från en faktura.
För att komma igång, logga in på Amazon Textract-konsolen för att prova den här funktionen. För att lära dig mer om Amazon Textracts funktioner, se Amazon Textract utvecklarguide or Textract-resurser. För att lära dig mer om IDP, se IDP med AWS AI-tjänster del 1 och del 2 inlägg.
Om författarna
 Sushant Pradhan är Sr. Solutions Architect på Amazon Web Services och hjälper företagskunder. Hans intressen och erfarenhet inkluderar containrar, serverlös teknologi och DevOps. På sin fritid gillar Sushant att vara utomhus med sin familj.
Sushant Pradhan är Sr. Solutions Architect på Amazon Web Services och hjälper företagskunder. Hans intressen och erfarenhet inkluderar containrar, serverlös teknologi och DevOps. På sin fritid gillar Sushant att vara utomhus med sin familj.
 Shibin Michaelraj är Sr. Product Manager med AWS Textract-teamet. Han är fokuserad på att bygga AI/ML-baserade produkter för AWS-kunder.
Shibin Michaelraj är Sr. Product Manager med AWS Textract-teamet. Han är fokuserad på att bygga AI/ML-baserade produkter för AWS-kunder.
 Suprakash Dutta är Sr. Solutions Architect på Amazon Web Services. Han fokuserar på digital transformationsstrategi, applikationsmodernisering och migrering, dataanalys och maskininlärning. Han är en del av AI/ML-communityt på AWS och designar intelligenta dokumentbehandlingslösningar.
Suprakash Dutta är Sr. Solutions Architect på Amazon Web Services. Han fokuserar på digital transformationsstrategi, applikationsmodernisering och migrering, dataanalys och maskininlärning. Han är en del av AI/ML-communityt på AWS och designar intelligenta dokumentbehandlingslösningar.
 Maran Chandrasekaran är Senior Solutions Architect på Amazon Web Services och arbetar med våra företagskunder. Utanför jobbet älskar han att resa och åka motorcykel i Texas Hill Country.
Maran Chandrasekaran är Senior Solutions Architect på Amazon Web Services och arbetar med våra företagskunder. Utanför jobbet älskar han att resa och åka motorcykel i Texas Hill Country.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

