V današnjem poslovnem okolju organizacije nenehno iščejo načine za optimizacijo svojih finančnih procesov, povečanje učinkovitosti in zmanjšanje stroškov. Eno področje, ki ima velik potencial za izboljšave, so obveznosti do dobaviteljev. Na visoki ravni proces obračunavanja obveznosti vključuje prejemanje in skeniranje računov, pridobivanje ustreznih podatkov iz skeniranih računov, validacijo, odobritev in arhiviranje. Drugi korak (ekstrakcija) je lahko zapleten. Vsak račun in potrdilo izgleda drugače. Oznake so nepopolne in nedosledne. Najpomembnejši deli informacij, kot so cena, ime prodajalca, naslov prodajalca in plačilni pogoji, pogosto niso izrecno označeni in jih je treba razlagati glede na kontekst. Tradicionalni pristop uporabe človeških pregledovalcev za ekstrahiranje podatkov je dolgotrajen, nagnjen k napakam in ni razširljiv.
V tej objavi prikazujemo, kako avtomatizirati postopek obračunavanja obveznosti z uporabo Amazonovo besedilo za pridobivanje podatkov. Ponujamo tudi referenčno arhitekturo za izgradnjo cevovoda za avtomatizacijo računov, ki omogoča ekstrakcijo, preverjanje, arhiviranje in inteligentno iskanje.
Pregled rešitev
Naslednji diagram arhitekture prikazuje stopnje delovnega toka obdelave potrdila in računa. Začne se s stopnjo zajemanja dokumentov za varno zbiranje in shranjevanje skeniranih računov in potrdil. Naslednja faza je faza ekstrakcije, kjer zbrane račune in potrdila posredujete v Amazon Texttract. AnalyzeExpense API za pridobivanje finančno povezanih odnosov med besedilom, kot je ime prodajalca, datum prejema računa, datum naročila, zapadli znesek, plačani znesek itd. V naslednji fazi uporabite vnaprej določena pravila stroškov, da ugotovite, ali morate samodejno odobriti ali zavrniti potrdilo. Odobreni in zavrnjeni dokumenti gredo v ustrezne mape znotraj Preprosta storitev shranjevanja Amazon (Amazon S3) vedro. Za odobrene dokumente lahko iščete vsa izvlečena polja in vrednosti z uporabo Storitev Amazon OpenSearch. Indeksirane metapodatke lahko vizualizirate z nadzornimi ploščami OpenSearch. Odobreni dokumenti so prav tako nastavljeni za premik Amazon S3 Intelligent-Tiering za dolgoročno hrambo in arhiviranje z uporabo pravilnikov življenjskega cikla S3.
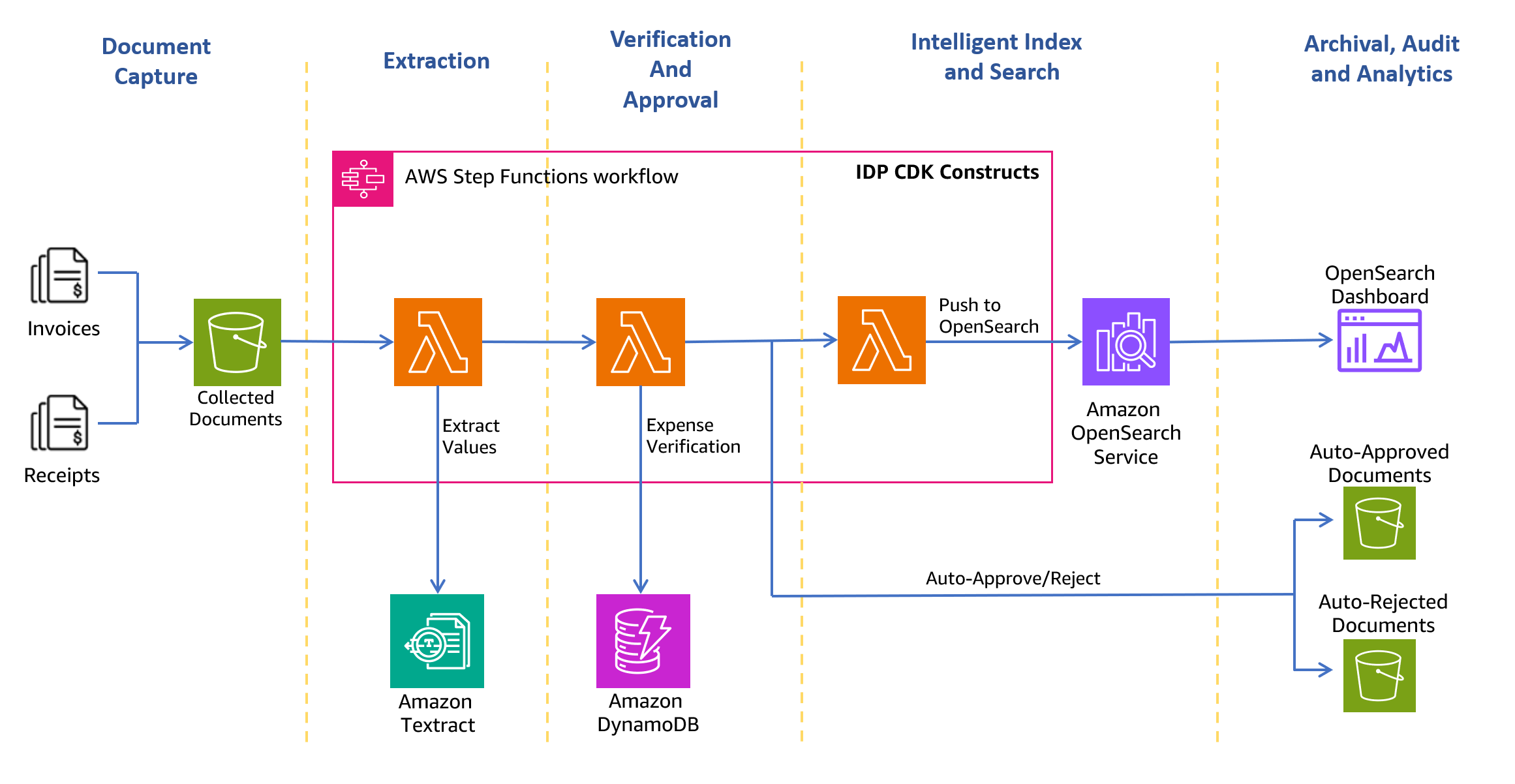
Naslednji razdelki vas popeljejo skozi postopek ustvarjanja rešitve.
Predpogoji
Za uvedbo te rešitve morate imeti naslednje:
- AWS račun.
- An AWS Cloud9 okolju. AWS Cloud9 je v oblaku temelječe integrirano razvojno okolje (IDE), ki vam omogoča pisanje, izvajanje in odpravljanje napak v kodi samo z brskalnikom. Vključuje urejevalnik kode, razhroščevalnik in terminal.
Če želite ustvariti okolje AWS Cloud9, navedite ime in opis. Vse ostalo naj bo privzeto. Izberite povezavo IDE na konzoli AWS Cloud9, da se pomaknete do IDE. Zdaj ste pripravljeni za uporabo okolja AWS Cloud9.
Uvedite rešitev
Za nastavitev rešitve uporabite Komplet za razvoj oblaka AWS (AWS CDK) za uvedbo an Oblikovanje oblaka AWS kup.
- V terminalu AWS Cloud9 IDE klonirajte GitHub repozitorij in namestite odvisnosti. Zaženite naslednje ukaze za uvedbo
InvoiceProcessorsklad:
Uvajanje traja približno 25 minut s privzetimi konfiguracijskimi nastavitvami iz repoja GitHub. Dodatne informacije o izhodu so na voljo tudi na konzoli AWS CloudFormation.
- Ko je uvedba AWS CDK končana, ustvarite pravila za preverjanje stroškov v Amazon DynamoDB tabela. Isti terminal AWS Cloud9 lahko uporabite za izvajanje naslednjih ukazov:
- V vedru S3, ki se začne z
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, ustvarite mapo za nalaganje.
In Amazon Cognito, že morate imeti imenovano obstoječo skupino uporabnikov OpenSearchResourcesCognitoUserPool*. To skupino uporabnikov uporabljamo za ustvarjanje novega uporabnika.
- Na konzoli Amazon Cognito se pomaknite do skupine uporabnikov
OpenSearchResourcesCognitoUserPool*. - Ustvarite novega uporabnika Amazon Cognito.
- Vnesite uporabniško ime in geslo po svoji izbiri in ju zabeležite za poznejšo uporabo.
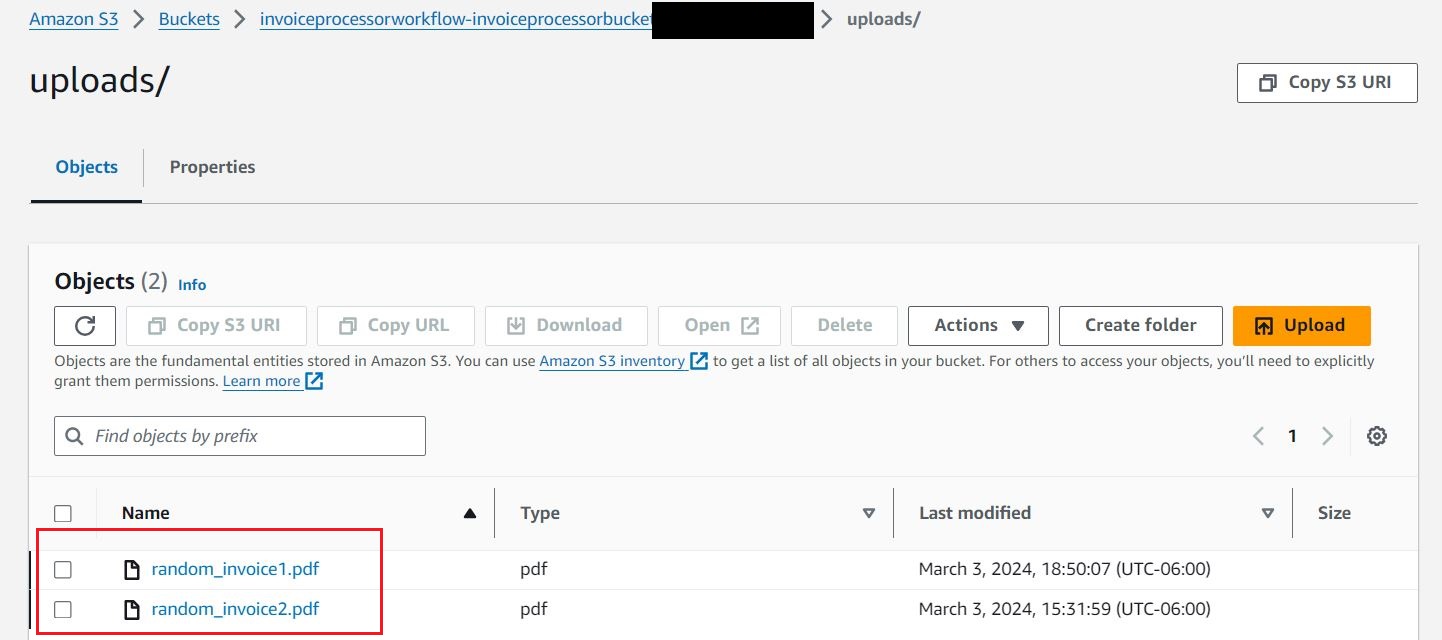
- Naložite dokumente naključni_račun1 in naključni_račun2 do S3
uploadsmapo za začetek delovnih tokov.
Zdaj pa se poglobimo v vsak korak obdelave dokumenta.
Zajem dokumenta
Stranke obravnavajo račune in potrdila v številnih oblikah različnih prodajalcev. Ti dokumenti so prejeti prek kanalov, kot so tiskane kopije, skenirane kopije, naložene v shrambo datotek, ali skupne pomnilniške naprave. V fazi zajema dokumentov shranite vse optično prebrane kopije potrdil in računov v zelo razširljivo shrambo, kot je vedro S3.
Pridobivanje
Naslednja faza je faza ekstrakcije, kjer zbrane račune in potrdila posredujete v Amazon Texttract. AnalyzeExpense API za pridobivanje finančno povezanih odnosov med besedilom, kot je ime prodajalca, datum prejema računa, datum naročila, dolgovani/plačani znesek itd.
AnalyzeExpense je API, namenjen obdelavi dokumentov o računih in potrdilih. Na voljo je kot sinhroni ali asinhroni API. Sinhroni API omogoča pošiljanje slik v formatu bajtov, asinhroni API pa omogoča pošiljanje datotek v formatih JPG, PNG, TIFF in PDF. The AnalyzeExpense Odgovor API je sestavljen iz treh različnih razdelkov:
- Polja povzetka – Ta razdelek vključuje normalizirane ključe in izrecno omenjene ključe skupaj z njihovimi vrednostmi.
AnalyzeExpensenormalizira ključe za informacije, povezane s kontaktom, kot sta ime prodajalca in naslov prodajalca, ključe, povezane z davčno številko, kot je ID davčnega zavezanca, ključe, povezane s plačilom, kot sta zapadli znesek in popust, in splošne ključe, kot so ID računa, datum dostave in številka računa. Ključi, ki niso normalizirani, so še vedno prikazani v poljih povzetka kot pari ključ-vrednost. Za celoten seznam podprtih stroškovnih polj glejte Analiza računov in potrdil. - Vrstične postavke – Ta razdelek vključuje normalizirane ključe vrstičnih postavk, kot so opis postavke, cena na enoto, količina in koda izdelka.
- OCR blok – Blok vsebuje izvleček neobdelanega besedila s strani računa. Izvleček neobdelanega besedila je mogoče uporabiti za naknadno obdelavo in identifikacijo informacij, ki niso zajete kot del polj povzetka in vrstične postavke.
Ta objava uporablja Konstrukti Amazon Texttract IDP CDK (Komponente AWS CDK za definiranje infrastrukture za delovne tokove inteligentne obdelave dokumentov (IDP), ki vam omogoča, da zgradite prilagojene delovne tokove IDP, specifične za primer uporabe. Konstrukti in vzorci so zbirka komponent, ki omogočajo definiranje procesov IDP na AWS in so objavljeni v GitHub. Glavni uporabljeni koncepti so konstrukti AWS CDK, dejanski Skladi AWS CDKin Korak funkcije AWS.
Naslednja slika prikazuje potek dela funkcij korakov.
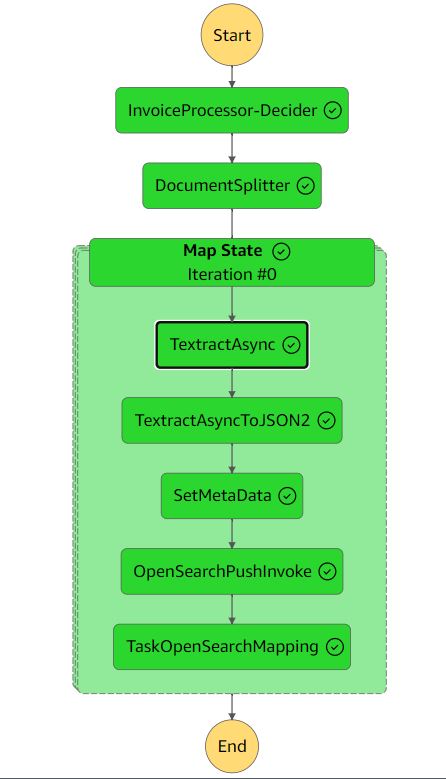
Potek dela ekstrakcije vključuje naslednje korake:
- InvoiceProcessor-Decider - An AWS Lambda funkcijo, ki preveri, ali format vhodnega dokumenta podpira Amazon Texttract. Za več podrobnosti o podprtih formatih glejte Vhodni dokumenti.
- DocumentSplitter – Funkcija Lambda, ki ustvari 2,500-stranske (največ) kose iz dokumentov in lahko obdela velike večstranske dokumente.
- Država zemljevida – Lambda funkcija, ki obdeluje vsak kos vzporedno.
- TextAsync – Ta naloga pokliče Amazon Texttract z naslednjim asinhronim API-jem najboljše prakse z Amazon Simple notification Service (Amazon SNS) obvestila in uporabe
OutputConfigza shranjevanje izhoda Amazon Texttract JSON v vedro S3, ki ste ga ustvarili prej. Sestavljen je iz dveh funkcij Lambda: ene za predložitev dokumenta v obdelavo in ene, ki se sproži ob obvestilu SNS. - TextAsyncToJSON2 - Zaradi
TextractAsyncopravilo lahko proizvede več ostranjenih izhodnih datotek,TextractAsyncToJSON2postopek jih združi v eno datoteko JSON.
O podrobnostih naslednjih treh korakov razpravljamo v naslednjih razdelkih.
Preverjanje in odobritev
Za stopnjo preverjanja, SetMetaData Funkcija Lambda preveri, ali je naložena datoteka veljaven strošek v skladu s pravili, predhodno konfiguriranimi v tabeli DynamoDB. Za to objavo uporabite naslednja vzorčna pravila:
- Preverjanje je uspešno, če
INVOICE_RECEIPT_IDje prisoten in se ujema z regularnim izrazom(?i)[0-9]{3}[a-z]{3}[0-9]{3}$in ifPO_NUMBERje prisoten in se ujema z regularnim izrazom(?i)[a-z0-9]+$ - Preverjanje je neuspešno, če
PO_NUMBERorINVOICE_RECEIPT_IDni pravilna ali manjka v dokumentu.
Ko so datoteke obdelane, funkcija preverjanja stroškov premakne vhodne datoteke v eno ali drugo approved or declined mape v istem vedru S3.
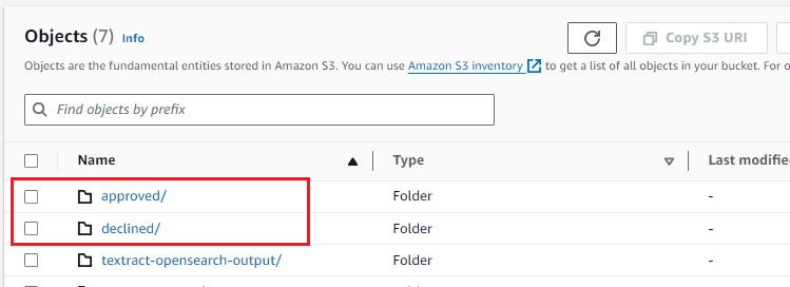
Za namene te rešitve uporabljamo DynamoDB za shranjevanje pravil za preverjanje stroškov. Vendar pa lahko to rešitev spremenite tako, da se integrira z lastnimi ali komercialnimi rešitvami za preverjanje ali upravljanje stroškov.
Inteligentni indeks in iskanje
Z OpenSearchPushInvoke Lambda funkcija, ekstrahirani metapodatki o stroških so potisnjeni v indeks OpenSearch Service in so na voljo za iskanje.
Konec TaskOpenSearchMapping korak počisti kontekst, ki bi sicer lahko presegel Kvota funkcij koraka največje vhodne ali izhodne velikosti za izvajanje opravila, stanja ali poteka dela.
Ko je indeks OpenSearch Service ustvarjen, lahko iščete ključne besede iz ekstrahiranega besedila prek nadzornih plošč OpenSearch.
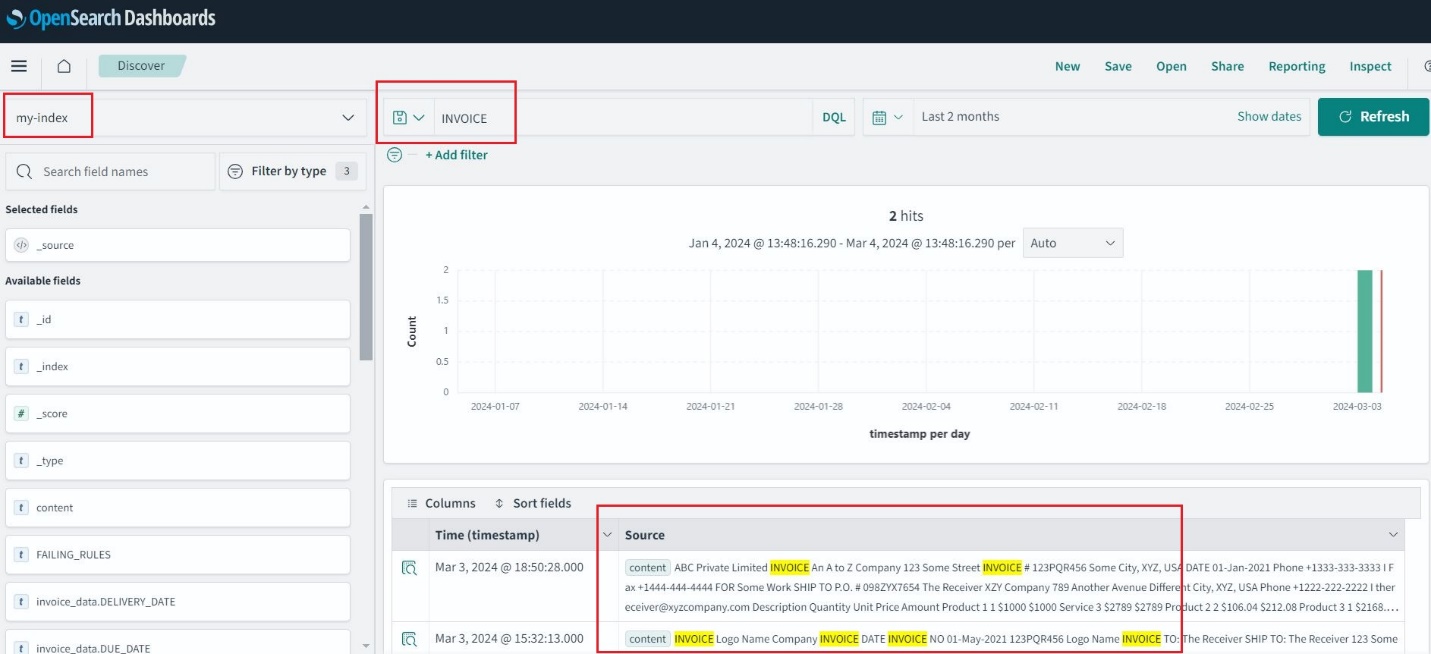
Arhiv, revizija in analitika
Za upravljanje življenjskega cikla in arhiviranja računov in potrdil lahko konfigurirate pravila življenjskega cikla S3 za prehod objektov S3 iz standardnih v razrede shranjevanja Intelligent-Tiering. S3 Intelligent-Tiering spremlja vzorce dostopa in samodejno premakne objekte na raven redkega dostopa, če do njih niste dostopali 30 zaporednih dni. Po 90 dneh brez dostopa se objekti premaknejo na raven arhivskega takojšnjega dostopa brez vpliva na zmogljivost ali operativnih stroškov.
Za revizijo in analitiko ta rešitev uporablja storitev OpenSearch za izvajanje analitike zahtevkov za račune. Storitev OpenSearch vam omogoča brez napora vnos, zaščito, iskanje, združevanje, ogled in analizo podatkov za številne primere uporabe, kot je analitika dnevnika, iskanje aplikacij, iskanje v podjetju in še več.
Prijavite se v nadzorne plošče OpenSearch in se pomaknite do Stack Management, Shranjeni predmeti, nato izberite uvoz. Izberite fakture.ndjson datoteko iz kloniranega repozitorija in izberite uvoz. To vnaprej poseli indekse in zgradi vizualizacijo.
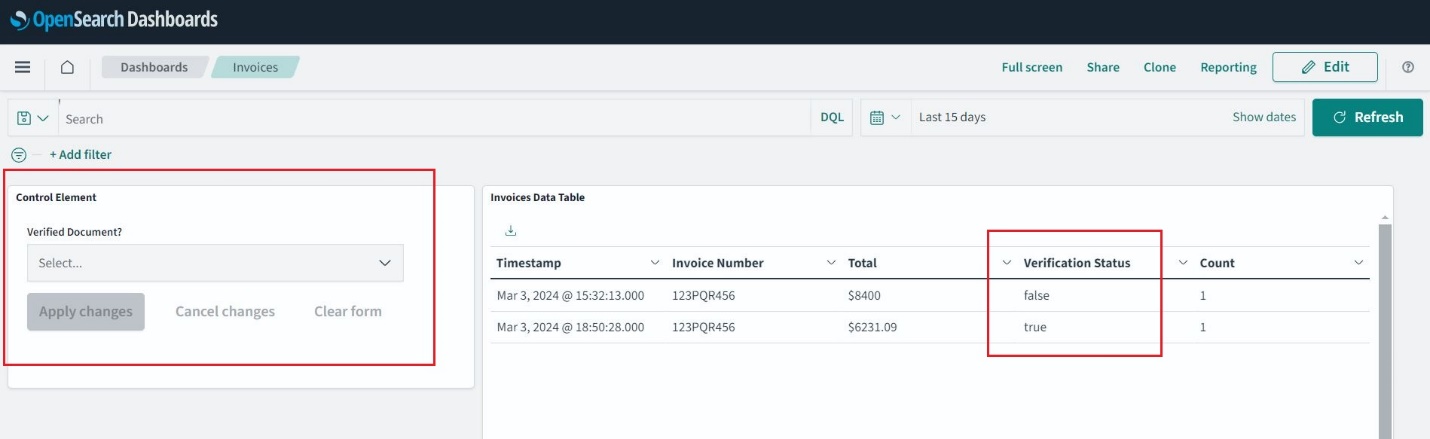
Osvežite stran in se pomaknite do Domov, Splošnoin odprite Računi. Zdaj lahko izberete in uporabite filtre ter razširite časovno okno za raziskovanje preteklih računov.
Čiščenje
Ko končate z ocenjevanjem Amazon Texttract za obdelavo potrdil in računov, priporočamo, da počistite vse vire, ki ste jih morda ustvarili. Izvedite naslednje korake:
- Izbrišite vso vsebino iz vedra S3
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - V AWS Cloud9 zaženite naslednje ukaze, da izbrišete vire Amazon Cognito in sklade CloudFormation:
- Izbrišite okolje AWS Cloud9, ki ste ga ustvarili s konzole AWS Cloud9.
zaključek
V tej objavi smo podali pregled, kako lahko zgradimo cevovod za avtomatizacijo računov z uporabo Amazon Texttract za pridobivanje podatkov in ustvarimo potek dela za preverjanje, arhiviranje in iskanje. Zagotovili smo vzorce kode za uporabo AnalyzeExpense API za ekstrakcijo kritičnih polj iz računa.
Za začetek se vpišite v konzolo Amazon Texttract in preizkusite to funkcijo. Če želite izvedeti več o zmogljivostih Amazon Texttract, glejte Vodič za razvijalce Amazon Textract or Viri besedila. Če želite izvedeti več o IDP, glejte IDP s storitvami AI AWS Del 1 in Del 2 objav.
O avtorjih
 Sushant Pradhan je starejši arhitekt rešitev pri Amazon Web Services, ki pomaga poslovnim strankam. Njegovi interesi in izkušnje vključujejo vsebnike, brezstrežniško tehnologijo in DevOps. Sushant v prostem času rad preživlja čas na prostem s svojo družino.
Sushant Pradhan je starejši arhitekt rešitev pri Amazon Web Services, ki pomaga poslovnim strankam. Njegovi interesi in izkušnje vključujejo vsebnike, brezstrežniško tehnologijo in DevOps. Sushant v prostem času rad preživlja čas na prostem s svojo družino.
 Šibin Michaelraj je višji produktni vodja pri ekipi AWS Texttract. Osredotočen je na izdelavo izdelkov, ki temeljijo na AI/ML, za stranke AWS.
Šibin Michaelraj je višji produktni vodja pri ekipi AWS Texttract. Osredotočen je na izdelavo izdelkov, ki temeljijo na AI/ML, za stranke AWS.
 Suprakash Dutta je starejši arhitekt rešitev pri Amazon Web Services. Osredotoča se na strategijo digitalne transformacije, posodobitev in migracijo aplikacij, podatkovno analitiko in strojno učenje. Je del skupnosti AI/ML pri AWS in oblikuje rešitve za inteligentno obdelavo dokumentov.
Suprakash Dutta je starejši arhitekt rešitev pri Amazon Web Services. Osredotoča se na strategijo digitalne transformacije, posodobitev in migracijo aplikacij, podatkovno analitiko in strojno učenje. Je del skupnosti AI/ML pri AWS in oblikuje rešitve za inteligentno obdelavo dokumentov.
 Maran Chandrasekaran je višji arhitekt rešitev pri Amazon Web Services, ki dela z našimi poslovnimi strankami. Zunaj službe rad potuje in se vozi z motorjem po Texas Hill Countryju.
Maran Chandrasekaran je višji arhitekt rešitev pri Amazon Web Services, ki dela z našimi poslovnimi strankami. Zunaj službe rad potuje in se vozi z motorjem po Texas Hill Countryju.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

