Pogovorna umetna inteligenca je v zadnjih letih močno napredovala po zaslugi hitrega razvoja generativne umetne inteligence, zlasti izboljšav zmogljivosti velikih jezikovnih modelov (LLM), uvedenih s tehnikami usposabljanja, kot sta natančno prilagajanje navodil in okrepljeno učenje iz človeških povratnih informacij. Ko so pravilno pozvani, lahko ti modeli izvajajo koherentne pogovore brez kakršnih koli podatkov o usposabljanju, specifičnih za nalogo. Vendar pa ne morejo dobro posplošiti vprašanj, specifičnih za podjetje, ker se za ustvarjanje odgovora zanašajo na javne podatke, ki so jim bili izpostavljeni med predhodnim usposabljanjem. Takšnim podatkom pogosto primanjkuje specializiranega znanja iz internih dokumentov, ki so na voljo v sodobnih podjetjih, kar je običajno potrebno za pridobitev natančnih odgovorov na področjih, kot so farmacevtske raziskave, finančne preiskave in podpora strankam.
Da bi ustvarili pomočnike AI, ki so sposobni voditi razprave, ki temeljijo na specializiranem podjetniškem znanju, moramo te močne, a generične LLM-je povezati z notranjimi bazami znanja dokumentov. Ta metoda obogatitve konteksta generiranja LLM z informacijami, pridobljenimi iz vaših notranjih virov podatkov, se imenuje Retrieval Augmented Generation (RAG) in proizvaja pomočnike, ki so specifični za domeno in so bolj vredni zaupanja, kot je prikazano v Generacija z razširjenim iskanjem za NLP naloge, ki zahtevajo veliko znanja. Drugo gonilo za priljubljenost RAG-a je njegova enostavnost implementacije in obstoj zrelih rešitev vektorskega iskanja, kot so tiste, ki jih ponuja Amazonska Kendra (Glej Amazon Kendra lansira Retrieval API) in Storitev Amazon OpenSearch (Glej Iskanje k-najbližjega soseda (k-NN) v storitvi Amazon OpenSearch), med ostalimi.
Vendar pa priljubljeni oblikovalski vzorec RAG s semantičnim iskanjem ne more odgovoriti na vse vrste vprašanj, ki so možna v dokumentih. To še posebej velja za vprašanja, ki zahtevajo analitično razmišljanje v več dokumentih. Na primer, predstavljajte si, da načrtujete strategijo investicijske družbe za naslednje leto. Eden od bistvenih korakov bi bila analiza in primerjava finančnih rezultatov in potencialnih tveganj podjetij kandidatov. Ta naloga vključuje odgovarjanje na vprašanja o analitičnem razmišljanju. Na primer, poizvedba »Navedite mi 5 najboljših podjetij z najvišjimi prihodki v zadnjih 2 letih in opredelite njihova glavna tveganja« zahteva več korakov sklepanja, od katerih lahko nekateri uporabljajo semantično iskanje, medtem ko drugi zahtevajo analitične sposobnosti.
V tem prispevku prikazujemo, kako oblikovati inteligentnega pomočnika za dokumente, ki je sposoben odgovarjati na analitična vprašanja in vprašanja sklepanja v več korakih v treh delih. V 1. delu pregledamo vzorec načrtovanja RAG in njegove omejitve glede analitičnih vprašanj. Nato vam predstavimo bolj vsestransko arhitekturo, ki premaga te omejitve. 2. del vam pomaga poglobiti se v cevovod ekstrakcije entitet, ki se uporablja za pripravo strukturiranih podatkov, kar je ključna sestavina za odgovarjanje na analitična vprašanja. 3. del vas vodi skozi uporabo Amazon Bedrock LLM-ji za poizvedovanje po teh podatkih in izdelavo agenta LLM-a, ki izboljša RAG z analitičnimi zmožnostmi, s čimer vam omogoči izdelavo inteligentnih dokumentnih pomočnikov, ki lahko odgovorijo na zapletena vprašanja, specifična za domeno, v več dokumentih.
1. del: Omejitve RAG in pregled rešitve
V tem razdelku pregledamo vzorec načrtovanja RAG in razpravljamo o njegovih omejitvah glede analitičnih vprašanj. Predstavljamo tudi bolj vsestransko arhitekturo, ki presega te omejitve.
Pregled RAG
Rešitve RAG se zgledujejo po predstavniško učenje in pomensko iskanje ideje, ki so bile od leta 2010 postopoma sprejete pri težavah z razvrščanjem (na primer priporočilo in iskanje) in nalogah obdelave naravnega jezika (NLP).
Danes priljubljeni pristop je sestavljen iz treh korakov:
- Opravilo paketne obdelave brez povezave zaužije dokumente iz vhodne baze znanja, jih razdeli na dele, ustvari vdelavo za vsak kos, ki predstavlja njegovo semantiko z uporabo vnaprej usposobljenega modela vdelave, kot je npr. Amazon Titan vdelane modele, nato te vdelave uporabi kot vhodne podatke za ustvarjanje semantičnega iskalnega indeksa.

- Pri odgovoru na novo vprašanje v realnem času se vhodno vprašanje pretvori v vdelavo, ki se uporablja za iskanje in ekstrahiranje najbolj podobnih delov dokumentov z uporabo metrike podobnosti, kot je kosinusna podobnost, in približnega algoritma najbližjih sosedov. Natančnost iskanja je mogoče izboljšati tudi s filtriranjem metapodatkov.

- Poziv je sestavljen iz veriženja sistemskega sporočila s kontekstom, ki je oblikovan iz ustreznih kosov dokumentov, ekstrahiranih v 2. koraku, in samega vhodnega vprašanja. Ta poziv je nato predstavljen modelu LLM, da ustvari končni odgovor na vprašanje iz konteksta.

S pravim osnovnim modelom vdelave, ki je zmožen izdelati natančne semantične predstavitve delov vhodnega dokumenta in vhodnih vprašanj, ter učinkovit modul semantičnega iskanja lahko ta rešitev odgovori na vprašanja, ki zahtevajo pridobivanje obstoječih informacij v bazi dokumentov. Na primer, če imate storitev ali izdelek, lahko začnete z indeksiranjem razdelka s pogostimi vprašanji ali dokumentacije in imate začetni pogovorni AI, prilagojen vaši specifični ponudbi.
Omejitve RAG na podlagi semantičnega iskanja
Čeprav je RAG bistvena komponenta v sodobnih pomočnikih umetne inteligence, specifičnih za domeno, in smiselno izhodišče za gradnjo pogovorne umetne inteligence okoli specializirane baze znanja, ne more odgovoriti na vprašanja, ki zahtevajo skeniranje, primerjavo in razmišljanje v vseh dokumentih v vaši bazi znanja hkrati, še posebej, če povečava temelji izključno na semantičnem iskanju.
Da bi razumeli te omejitve, si ponovno oglejmo primer odločanja, kam investirati na podlagi finančnih poročil. Če bi uporabili RAG za pogovor s temi poročili, bi lahko postavili vprašanja, kot sta "Kakšna so tveganja, s katerimi se je soočilo podjetje X leta 2022" ali "Kakšen je neto prihodek podjetja Y leta 2022?" Za vsako od teh vprašanj se ustrezen vdelani vektor, ki kodira semantični pomen vprašanja, uporabi za pridobitev zgornjih K pomensko podobnih kosov dokumentov, ki so na voljo v iskalnem indeksu. To se običajno doseže z uporabo približne rešitve najbližjih sosedov, kot je npr FAISS, NMSLIB, pgvector ali drugi, ki si prizadevajo najti ravnovesje med hitrostjo priklica in priklicem, da bi dosegli zmogljivost v realnem času in hkrati ohranili zadovoljivo natančnost.
Vendar pa prejšnji pristop ne more natančno odgovoriti na analitična vprašanja v vseh dokumentih, na primer »Katerih je 5 najboljših podjetij z najvišjimi neto prihodki v letu 2022?«
To je zato, ker iskanje s semantičnim iskanjem poskuša najti K najbolj podobnih delov dokumentov vhodnemu vprašanju. Ker pa nobeden od dokumentov ne vsebuje izčrpnih povzetkov prihodkov, bo vrnil dele dokumentov, ki vsebujejo le omembe »neto prihodkov« in morda »2022«, ne da bi izpolnili bistveni pogoj osredotočanja na podjetja z najvišjimi prihodki. Če študentu LLM predstavimo te rezultate iskanja kot kontekst za odgovor na vhodno vprašanje, lahko oblikuje zavajajoč odgovor ali zavrne odgovor, ker manjkajo zahtevane pravilne informacije.
Te omejitve izhajajo iz načrta, ker semantično iskanje ne izvede temeljitega pregleda vseh vdelanih vektorjev, da bi našli ustrezne dokumente. Namesto tega uporablja metode približnega najbližjega soseda, da ohrani razumno hitrost iskanja. Ključna strategija za učinkovitost teh metod je segmentiranje prostora za vdelavo v skupine med indeksiranjem. To omogoča hitro prepoznavanje, katere skupine lahko vsebujejo ustrezne vdelave med iskanjem, brez potrebe po parnih primerjavah. Poleg tega celo tradicionalne tehnike najbližjih sosedov, kot je KNN, ki skenirajo vse dokumente, izračunajo samo osnovne meritve razdalje in niso primerne za kompleksne primerjave, potrebne za analitično sklepanje. Zato RAG s semantičnim iskanjem ni prilagojen za odgovarjanje na vprašanja, ki vključujejo analitično sklepanje v vseh dokumentih.
Za premagovanje teh omejitev predlagamo rešitev, ki združuje RAG z metapodatki in ekstrakcijo entitet, poizvedovanjem SQL in agenti LLM, kot je opisano v naslednjih razdelkih.
Premagovanje omejitev RAG z metapodatki, SQL in agenti LLM
Poglejmo globlje vprašanje, pri katerem RAG ne uspe, da bomo lahko izsledili obrazložitev, ki je potrebna za učinkovit odgovor. Ta analiza bi nas morala usmeriti k pravemu pristopu, ki bi lahko dopolnil RAG v celotni rešitvi.
Razmislite o vprašanju: »Katerih je 5 najboljših podjetij z najvišjimi prihodki v letu 2022?«
Da bi lahko odgovorili na to vprašanje, bi morali:
- Ugotovite prihodke za vsako podjetje.
- Filtrirajte navzdol, da obdržite prihodke iz leta 2022 za vsakega od njih.
- Razvrstite prihodke po padajočem vrstnem redu.
- Izločite 5 največjih prihodkov poleg imen podjetij.
Običajno se te analitične operacije izvajajo na strukturiranih podatkih z uporabo orodij, kot so pandas ali motorji SQL. Če bi imeli dostop do tabele SQL, ki bi vsebovala stolpce company, revenuein year, bi lahko zlahka odgovorili na naše vprašanje z izvajanjem poizvedbe SQL, podobno kot v naslednjem primeru:
SELECT company, revenue FROM table_name WHERE year = 2022 ORDER BY revenue DESC LIMIT 5;Shranjevanje strukturiranih metapodatkov v tabeli SQL, ki vsebuje informacije o ustreznih entitetah, vam omogoča, da odgovorite na številne vrste analitičnih vprašanj tako, da napišete pravilno poizvedbo SQL. Zato dopolnjujemo RAG v naši rešitvi z modulom za poizvedovanje SQL v realnem času v tabeli SQL, ki je poseljena z metapodatki, ekstrahiranimi v procesu brez povezave.
Toda kako lahko implementiramo in integriramo ta pristop v pogovorno umetno inteligenco, ki temelji na LLM?
Obstajajo trije koraki, da lahko dodate analitično sklepanje SQL:
- Ekstrakcija metapodatkov – Ekstrahirajte metapodatke iz nestrukturiranih dokumentov v tabelo SQL
- Besedilo v SQL – Natančno oblikujte poizvedbe SQL iz vhodnih vprašanj z uporabo LLM
- Izbira orodja – Ugotovite, ali je treba na vprašanje odgovoriti s poizvedbo RAG ali SQL
Za izvedbo teh korakov se najprej zavedamo, da je pridobivanje informacij iz nestrukturiranih dokumentov tradicionalna naloga NLP, za katero LLM-ji obetajo doseganje visoke natančnosti z učenjem z ničelnim ali nekajkratnim učenjem. Drugič, sposobnost teh modelov za ustvarjanje poizvedb SQL iz naravnega jezika je bila dokazana že leta, kot je razvidno iz 2020 za javnost of Amazon QuickSight Q. Končno samodejna izbira pravega orodja za določeno vprašanje izboljša uporabniško izkušnjo in omogoča odgovarjanje na zapletena vprašanja z večstopenjskim razmišljanjem. Za implementacijo te funkcije se bomo v kasnejšem razdelku poglobili v agente LLM.
Če povzamemo, je rešitev, ki jo predlagamo, sestavljena iz naslednjih ključnih komponent:
- Pridobivanje semantičnega iskanja za razširitev konteksta generiranja
- Strukturirano pridobivanje metapodatkov in poizvedovanje s SQL
- Agent, ki je sposoben uporabiti prava orodja za odgovor na vprašanje
Pregled rešitev
Naslednji diagram prikazuje poenostavljeno arhitekturo rešitve. Pomaga vam prepoznati in razumeti vlogo osrednjih komponent in kako medsebojno delujejo pri izvajanju popolnega vedenja LLM-asistenta. Številčenje je usklajeno z vrstnim redom operacij pri izvajanju te rešitve.

V praksi smo implementirali to rešitev, kot je opisano v naslednji podrobni arhitekturi.

Za to arhitekturo predlagamo izvedbo na GitHub, z ohlapno povezanimi komponentami, kjer se lahko zaledje (5), podatkovni cevovodi (1, 2, 3) in sprednji del (4) razvijajo ločeno. To je namenjeno poenostavitvi sodelovanja med kompetencami pri prilagajanju in izboljšanju rešitve za proizvodnjo.
Uvedite rešitev
Če želite namestiti to rešitev v svoj račun AWS, izvedite naslednje korake:
- Kloniraj repozitorij na GitHubu.
- Namestite zaledje Komplet za razvoj oblaka AWS (AWS CDK) aplikacija:
- odprite
backendmapa. - Run
npm installza namestitev odvisnosti. - Če še nikoli niste uporabljali AWS CDK v trenutnem računu in regiji, zaženite bootstrapping z
npx cdk bootstrap. - Run
npx cdk deployza razporeditev sklada.
- odprite
- Po želji zaženite
streamlit-uikot sledi:- Priporočamo kloniranje tega repozitorija v Amazon SageMaker Studio okolju. Za več informacij glejte Vkrcajte se na domeno Amazon SageMaker z uporabo hitre nastavitve.
- Znotraj
frontend/streamlit-uifolder, runbash run-streamlit-ui.sh. - Izberite povezavo v naslednji obliki, da odprete predstavitev:
https://{domain_id}.studio.{region}.sagemaker.aws/jupyter/default/proxy/{port_number}/.
- Končno lahko zaženete Amazon SageMaker cevovod, opredeljen v
data-pipelines/04-sagemaker-pipeline-for-documents-processing.ipynbprenosni računalnik za obdelavo vhodnih dokumentov PDF in pripravo tabele SQL ter semantičnega iskalnega indeksa, ki ga uporablja asistent LLM.
V preostalem delu te objave se osredotočamo na razlago najpomembnejših komponent in oblikovalskih odločitev, da bi vas, upajmo, navdihnili pri oblikovanju lastnega pomočnika AI na podlagi interne baze znanja. Predvidevamo, da sta komponenti 1 in 4 enostavni za razumevanje, in se osredotočamo na ključne komponente 2, 3 in 5.
2. del: Cevovod za ekstrakcijo entitet
V tem razdelku se poglobimo v cevovod za pridobivanje entitet, ki se uporablja za pripravo strukturiranih podatkov, kar je ključna sestavina za odgovarjanje na analitična vprašanja.
Ekstrakcija besedila
Dokumenti so običajno shranjeni v formatu PDF ali kot skenirane slike. Lahko so sestavljeni iz preprostih postavitev odstavkov ali kompleksnih tabel in vsebujejo digitalno ali ročno napisano besedilo. Za pravilno pridobivanje informacij moramo te neobdelane dokumente pretvoriti v golo besedilo, pri tem pa ohraniti njihovo prvotno strukturo. Če želite to narediti, lahko uporabite Amazonovo besedilo, ki je storitev strojnega učenja (ML), ki ponuja zrele API-je za ekstrakcijo besedila, tabel in obrazcev iz digitalnih in ročno napisanih vnosov.
V komponenti 2 ekstrahiramo besedilo in tabele na naslednji način:
- Za vsak dokument pokličemo Amazon Texttract, da ekstrahiramo besedilo in tabele.
- Uporabljamo naslednje Python skript za ponovno ustvarjanje tabel kot pandas DataFrames.
- Rezultate združimo v en sam dokument in vstavimo tabele kot markdown.
Ta proces je orisan z naslednjim diagramom poteka in konkretno prikazan v notebooks/03-pdf-document-processing.ipynb.

Ekstrakcija entitet in poizvedovanje z uporabo LLM
Če želite učinkovito odgovoriti na analitična vprašanja, morate ustrezne metapodatke in entitete izvleči iz baze znanja vašega dokumenta v dostopen format strukturiranih podatkov. Predlagamo uporabo SQL za shranjevanje teh informacij in pridobivanje odgovorov zaradi njegove priljubljenosti, enostavne uporabe in razširljivosti. Ta izbira ima tudi koristi od zmožnosti dokazanih jezikovnih modelov za ustvarjanje poizvedb SQL iz naravnega jezika.
V tem razdelku se poglobimo v naslednje komponente, ki omogočajo analitična vprašanja:
- Paketni proces, ki ekstrahira strukturirane podatke iz nestrukturiranih podatkov z uporabo LLM
- Modul v realnem času, ki pretvori vprašanja v naravnem jeziku v poizvedbe SQL in pridobi rezultate iz baze podatkov SQL
Ustrezne metapodatke lahko izvlečete za podporo analitičnih vprašanj, kot sledi:
- Definirajte shemo JSON za informacije, ki jih morate izvleči, ki vsebuje opis vsakega polja in njegove vrste podatkov ter vključuje primere pričakovanih vrednosti.
- Za vsak dokument pozovite LLM s shemo JSON in ga prosite, naj natančno izvleče ustrezne podatke.
- Ko dolžina dokumenta presega dolžino konteksta in da zmanjšate stroške ekstrakcije z LLM-ji, lahko uporabite semantično iskanje za pridobitev in predstavitev ustreznih delov dokumentov LLM-ju med ekstrakcijo.
- Razčlenite izhod JSON in potrdite ekstrakcijo LLM.
- Po želji varnostno kopirajte rezultate na Amazon S3 kot datoteke CSV.
- Naložite v bazo podatkov SQL za poznejše poizvedovanje.
Ta proces upravlja naslednja arhitektura, kjer se dokumenti v besedilni obliki naložijo s skriptom Python, ki se izvaja v Obdelava Amazon SageMaker delo za izvedbo ekstrakcije.

Za vsako skupino entitet dinamično sestavimo poziv, ki vključuje jasen opis naloge pridobivanja informacij in vključuje shemo JSON, ki definira pričakovan izhod in vključuje ustrezne dele dokumenta kot kontekst. Dodamo tudi nekaj primerov vnosa in pravilnega izhoda za izboljšanje zmogljivosti ekstrakcije z nekajkratnim učenjem. To je prikazano v notebooks/05-entities-extraction-to-structured-metadata.ipynb.
3. del: Z Amazon Bedrock zgradite agentskega pomočnika za dokumente
V tem razdelku prikazujemo, kako uporabljati Amazon Bedrock LLM za poizvedovanje po podatkih in gradnjo agenta LLM, ki izboljša RAG z analitičnimi zmogljivostmi, s čimer vam omogoča izdelavo inteligentnih pomočnikov za dokumente, ki lahko odgovorijo na zapletena vprašanja, specifična za domeno, v več dokumentih. Lahko se sklicujete na Lambda funkcija na GitHubu za konkretno implementacijo agenta in orodij, opisanih v tem delu.
Oblikujte poizvedbe SQL in odgovarjajte na analitična vprašanja
Zdaj, ko imamo strukturirano shrambo metapodatkov z ustreznimi entitetami, ekstrahiranimi in naloženimi v bazo podatkov SQL, po kateri lahko izvajamo poizvedbe, ostaja vprašanje, kako ustvariti pravo poizvedbo SQL iz vhodnih vprašanj naravnega jezika?
Sodobni LLM-ji so dobri pri ustvarjanju SQL. Na primer, če zahtevate od Anthropic Claude LLM prek Amazon Bedrock za ustvarjanje poizvedbe SQL, boste videli verjetne odgovore. Vendar pa moramo pri pisanju poziva upoštevati nekaj pravil, da dosežemo natančnejše poizvedbe SQL. Ta pravila so še posebej pomembna za zapletene poizvedbe za zmanjšanje halucinacij in sintaktičnih napak:
- V pozivu natančno opišite nalogo
- V poziv vključite shemo tabel SQL, pri tem pa opišite vsak stolpec tabele in navedite njegov podatkovni tip
- LLM-ju izrecno povejte, naj uporablja samo obstoječa imena stolpcev in vrste podatkov
- Dodajte nekaj vrstic tabel SQL
Ustvarjeno poizvedbo SQL lahko tudi naknadno obdelate z uporabo a linter kot sqlfluff za popravljanje oblikovanja ali razčlenjevalnik, kot je npr sqlglot za odkrivanje sintaksnih napak in optimizacijo poizvedbe. Poleg tega, ko zmogljivost ne izpolnjuje zahteve, lahko navedete nekaj primerov v pozivu, da usmerite model z nekajkratnim učenjem k generiranju natančnejših poizvedb SQL.
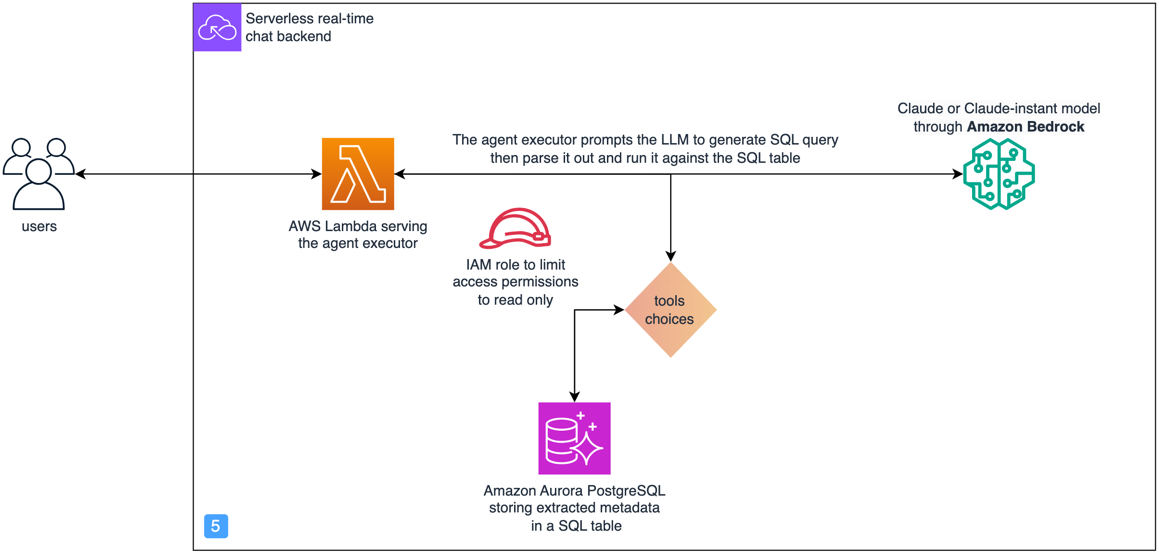
Z izvedbenega vidika uporabljamo an AWS Lambda funkcijo za orkestracijo naslednjega procesa:
- Pokličite model Anthropic Claude v Amazon Bedrock z vnosnim vprašanjem, da dobite ustrezno poizvedbo SQL. Tukaj uporabljamo SQLDatabase razreda iz LangChaina, da dodate opise shem ustreznih tabel SQL in uporabite poziv po meri.
- Razčlenite, potrdite in zaženite poizvedbo SQL proti Izdaja Amazon Aurora, združljiva s PostgreSQL baze podatkov.
Arhitektura tega dela rešitve je poudarjena v naslednjem diagramu.
Varnostni vidiki za preprečevanje napadov z vbrizgavanjem SQL
Ko pomočniku AI omogočimo, da poizveduje po bazi podatkov SQL, se moramo prepričati, da to ne povzroči varnostnih ranljivosti. Da bi to dosegli, predlagamo naslednje varnostne ukrepe za preprečevanje napadov z vbrizgavanjem SQL:
- Uporabi dovoljenja IAM z najmanjšimi pravicami – Omejite dovoljenje funkcije Lambda, ki izvaja poizvedbe SQL z uporabo AWS upravljanje identitete in dostopa (IAM) politiko in vlogo, ki sledi načelo najmanjših privilegijev. V tem primeru odobrimo dostop samo za branje.
- Omejite dostop do podatkov – Zagotovite dostop samo do najmanjšega števila tabel in stolpcev, da preprečite napade z razkritjem informacij.
- Dodajte moderacijsko plast – Uvedite moderacijsko plast, ki zgodaj zazna poskuse hitrega vstavljanja in prepreči njihovo širjenje na preostali sistem. Lahko je v obliki filtrov, ki temeljijo na pravilih, ujemanja podobnosti z bazo podatkov znanih primerov hitrega vbrizgavanja ali klasifikatorja ML.
Pridobivanje semantičnega iskanja za razširitev konteksta generiranja
Rešitev, ki jo predlagamo, uporablja RAG s semantičnim iskanjem v komponenti 3. Ta modul lahko implementirate z uporabo baze znanja za Amazon Bedrock. Poleg tega obstajajo številne druge možnosti za implementacijo RAG, kot je Amazon Kendra Retrieval API, Vektorska baza podatkov Amazon OpenSearchin Amazon Aurora PostgreSQL s pgvectorjem, med ostalimi. Odprtokodni paket aws-genai-llm-klepetalni robot prikazuje, kako uporabiti številne od teh možnosti vektorskega iskanja za implementacijo chatbota, ki ga poganja LLM.
Ker v tej rešitvi potrebujemo poizvedovanje SQL in vektorsko iskanje, smo se odločili uporabiti Amazon Aurora PostgreSQL z pgvector razširitev, ki podpira obe funkciji. Zato implementiramo komponento RAG semantičnega iskanja z naslednjo arhitekturo.

Postopek odgovarjanja na vprašanja z uporabo predhodne arhitekture poteka v dveh glavnih fazah.
Prvič, paketni postopek brez povezave, ki se izvaja kot opravilo SageMaker Processing, ustvari semantični iskalni indeks, kot sledi:
- Bodisi občasno ali ob prejemu novih dokumentov se zažene opravilo SageMaker.
- Naloži besedilne dokumente iz Amazon S3 in jih razdeli na prekrivajoče se dele.
- Za vsak kos uporablja model vdelave Amazon Titan za ustvarjanje vdelanega vektorja.
- Uporablja PGVector razreda iz LangChaina za vnos vdelav z njihovimi deli dokumentov in metapodatki v Amazon Aurora PostgreSQL in ustvarjanje semantičnega iskalnega indeksa na vseh vdelanih vektorjih.
Drugič, v realnem času in za vsako novo vprašanje sestavimo odgovor na naslednji način:
- Vprašanje prejme orkestrator, ki deluje na funkciji Lambda.
- Orkestrator vdela vprašanje z istim modelom vdelave.
- Iz indeksa semantičnega iskanja PostgreSQL pridobi najpomembnejših K najpomembnejših kosov dokumentov. Izbirno uporablja filtriranje metapodatkov za izboljšanje natančnosti.
- Ti kosi se dinamično vstavijo v poziv LLM poleg vhodnega vprašanja.
- Poziv je predstavljen Anthropic Claudu na Amazon Bedrock, da mu naroči, naj odgovori na vhodno vprašanje na podlagi razpoložljivega konteksta.
- Končno se ustvarjeni odgovor pošlje nazaj orkestratorju.
Agent, ki je sposoben uporabljati orodja za razmišljanje in ukrepanje
Doslej smo v tej objavi razpravljali o ločeni obravnavi vprašanj, ki zahtevajo RAG ali analitično razmišljanje. Vendar mnoga vprašanja iz resničnega sveta zahtevajo obe zmožnosti, včasih v več korakih razmišljanja, da bi dosegli končni odgovor. Da bi podprli ta bolj zapletena vprašanja, moramo uvesti pojem agenta.
LLM agenti, kot je zastopniki za Amazon Bedrock, so se pred kratkim pojavile kot obetavna rešitev, ki lahko uporablja LLM za razmišljanje in prilagajanje ob trenutnem kontekstu ter za izbiro ustreznih dejanj s seznama možnosti, ki predstavlja splošen okvir za reševanje problemov. Kot je razloženo v Avtonomni agenti, ki jih poganja LLM, obstaja več strategij spodbujanja in vzorcev oblikovanja za agente LLM, ki podpirajo zapleteno sklepanje.
Eden takšnih oblikovalskih vzorcev je Reason and Act (ReAct), predstavljen v ReAct: Sinergiziranje sklepanja in delovanja v jezikovnih modelih. V ReActu agent vzame kot vnos cilj, ki je lahko vprašanje, identificira dele informacij, ki manjkajo za odgovor nanj, in iterativno predlaga pravo orodje za zbiranje informacij na podlagi opisov razpoložljivih orodij. Po prejemu odgovora od danega orodja LLM ponovno oceni, ali ima vse informacije, ki jih potrebuje za popoln odgovor na vprašanje. Če ne, opravi še en korak sklepanja in uporabi isto ali drugo orodje za zbiranje več informacij, dokler ni pripravljen končni odgovor ali dokler ni dosežena meja.
Naslednji diagram zaporedja pojasnjuje, kako si agent ReAct prizadeva odgovoriti na vprašanje »Navedite mi 5 najboljših podjetij z največjim prihodkom v zadnjih 2 letih in opredelite tveganja, povezana z največjim.«

Podrobnosti o izvajanju tega pristopa v Pythonu so opisane v LLM agent po meri. V naši rešitvi so agent in orodja implementirani z naslednjo poudarjeno delno arhitekturo.

Za odgovor na vnosno vprašanje uporabljamo storitve AWS na naslednji način:
- Uporabnik vnese svoje vprašanje prek uporabniškega vmesnika, ki prikliče API Amazon API Gateway.
- Prehod API pošlje vprašanje funkciji Lambda, ki izvaja izvajalca agenta.
- Agent pokliče LLM s pozivom, ki vsebuje opis razpoložljivih orodij, obliko navodil ReAct in vhodno vprašanje, nato pa razčleni naslednje dejanje za dokončanje.
- Dejanje vsebuje, katero orodje poklicati in kaj je vnos dejanja.
- Če je orodje za uporabo SQL, izvajalec agenta pokliče SQLQA, da pretvori vprašanje v SQL in ga zažene. Nato doda rezultat k pozivu in ponovno pokliče LLM, da preveri, ali lahko odgovori na prvotno vprašanje ali so potrebna dodatna dejanja.
- Podobno, če je orodje za uporabo semantično iskanje, se vnos dejanja razčleni in uporabi za pridobivanje iz indeksa semantičnega iskanja PostgreSQL. Pozivu doda rezultate in preveri, ali LLM lahko odgovori ali potrebuje drugo dejanje.
- Ko so na voljo vse informacije za odgovor na vprašanje, LLM agent oblikuje končni odgovor in ga pošlje nazaj uporabniku.
Agenta lahko razširite z nadaljnjimi orodji. V izvedbi, ki je na voljo na GitHub, prikazujemo, kako lahko dodate iskalnik in kalkulator kot dodatni orodji zgoraj omenjenemu mehanizmu SQL in semantičnim iskalnim orodjem. Za shranjevanje zgodovine tekočih pogovorov uporabljamo an Amazon DynamoDB miza.
Iz naših dosedanjih izkušenj smo videli, da so naslednji ključi do uspešnega agenta:
- Temeljni LLM, ki je sposoben razmišljati s formatom ReAct
- Jasen opis razpoložljivih orodij, kdaj jih uporabiti, in opis njihovih vhodnih argumentov z morebitnim primerom vnosa in pričakovanega izhoda
- Jasen oris formata ReAct, ki mu mora slediti LLM
- Prava orodja za reševanje poslovnega vprašanja so na voljo LLM agentu za uporabo
- Pravilno razčlenjevanje izhodov iz odgovorov agenta LLM, kot jih utemeljuje
Za optimizacijo stroškov priporočamo, da predpomnite najpogostejša vprašanja z njihovimi odgovori in občasno posodabljate ta predpomnilnik, da zmanjšate klice osnovnemu LLM. Ustvarite lahko na primer semantični iskalni indeks z najpogostejšimi vprašanji, kot je bilo razloženo prej, in najprej primerjate vprašanje novega uporabnika z indeksom, preden pokličete LLM. Če želite raziskati druge možnosti predpomnjenja, glejte LLM Caching integracije.
Podpira druge formate, kot so video, slikovne, zvočne in 3D datoteke
Isto rešitev lahko uporabite za različne vrste informacij, kot so slike, videoposnetki, zvok in datoteke 3D-zasnove, kot so datoteke CAD ali mreže. To vključuje uporabo uveljavljenih tehnik ML za opis vsebine datoteke v besedilu, ki se nato lahko vnese v rešitev, ki smo jo raziskali prej. Ta pristop vam omogoča vodenje pogovorov o zagotavljanju kakovosti teh različnih tipov podatkov. Svojo zbirko podatkov o dokumentih lahko na primer razširite tako, da ustvarite besedilne opise slik, videoposnetkov ali zvočnih vsebin. Tabelo z metapodatki lahko izboljšate tudi z identifikacijo lastnosti s klasifikacijo ali zaznavanjem objektov na elementih znotraj teh formatov. Potem ko so ti ekstrahirani podatki indeksirani bodisi v shrambi metapodatkov bodisi v semantičnem iskalnem indeksu za dokumente, ostane splošna arhitektura predlaganega sistema v veliki meri dosledna.
zaključek
V tem prispevku smo pokazali, kako je uporaba LLM-jev z oblikovalskim vzorcem RAG potrebna za izgradnjo domensko specifičnega pomočnika umetne inteligence, vendar ne zadostuje za doseganje zahtevane ravni zanesljivosti za ustvarjanje poslovne vrednosti. Zaradi tega smo predlagali razširitev priljubljenega oblikovalskega vzorca RAG s koncepti agentov in orodij, kjer nam prilagodljivost orodij omogoča uporabo tradicionalnih tehnik NLP in sodobnih zmogljivosti LLM, da bi pomočniku AI omogočili več možnosti za iskanje informacij in pomoč. uporabnikom pri učinkovitem reševanju poslovnih problemov.
Rešitev prikazuje proces načrtovanja za asistenta LLM, ki je sposoben odgovoriti na različne vrste vprašanj o priklicu, analitičnem sklepanju in večstopenjskem sklepanju v vsej vaši bazi znanja. Poudarili smo tudi pomen razmišljanja za nazaj od vrst vprašanj in nalog, pri katerih naj bi vaš LLM asistent pomagal uporabnikom. V tem primeru nas je pot oblikovanja pripeljala do arhitekture s tremi komponentami: semantičnim iskanjem, ekstrakcijo metapodatkov in poizvedovanjem SQL ter agentom in orodji LLM, za katere menimo, da so generične in dovolj prilagodljive za več primerov uporabe. Verjamemo tudi, da boste z navdihom pri tej rešitvi in poglobljenim poglabljanjem v potrebe vaših uporabnikov to rešitev lahko še razširili v tisto, kar vam najbolj ustreza.
O avtorjih
 Mohamed Ali Jamaoui je višji arhitekt za izdelavo prototipov ML z 10-letnimi izkušnjami na področju proizvodnega strojnega učenja. Uživa v reševanju poslovnih problemov s strojnim učenjem in programskim inženiringom ter pomaga strankam pridobiti poslovno vrednost z ML. Kot del AWS EMEA Prototyping and Cloud Engineering strankam pomaga zgraditi poslovne rešitve, ki izkoriščajo inovacije v MLOP, NLP, CV in LLM.
Mohamed Ali Jamaoui je višji arhitekt za izdelavo prototipov ML z 10-letnimi izkušnjami na področju proizvodnega strojnega učenja. Uživa v reševanju poslovnih problemov s strojnim učenjem in programskim inženiringom ter pomaga strankam pridobiti poslovno vrednost z ML. Kot del AWS EMEA Prototyping and Cloud Engineering strankam pomaga zgraditi poslovne rešitve, ki izkoriščajo inovacije v MLOP, NLP, CV in LLM.
 Giuseppe Hannen je pridruženi svetovalec ProServe. Giuseppe uporablja svoje analitične sposobnosti v kombinaciji z AI&ML za razvoj jasnih in učinkovitih rešitev za svoje stranke. Rad najde preproste rešitve za zapletene probleme, še posebej tiste, ki vključujejo najnovejši tehnološki razvoj in raziskave.
Giuseppe Hannen je pridruženi svetovalec ProServe. Giuseppe uporablja svoje analitične sposobnosti v kombinaciji z AI&ML za razvoj jasnih in učinkovitih rešitev za svoje stranke. Rad najde preproste rešitve za zapletene probleme, še posebej tiste, ki vključujejo najnovejši tehnološki razvoj in raziskave.
 Laurens deset Cate je višji podatkovni znanstvenik. Laurens sodeluje s podjetniškimi strankami v EMEA in jim pomaga pospešiti njihove poslovne rezultate z uporabo tehnologij AWS AI/ML. Specializiran je za rešitve NLP in se osredotoča na industrijo dobavne verige in logistike. V prostem času uživa v branju in umetnosti.
Laurens deset Cate je višji podatkovni znanstvenik. Laurens sodeluje s podjetniškimi strankami v EMEA in jim pomaga pospešiti njihove poslovne rezultate z uporabo tehnologij AWS AI/ML. Specializiran je za rešitve NLP in se osredotoča na industrijo dobavne verige in logistike. V prostem času uživa v branju in umetnosti.
 Irina Radu je Prototyping Engagement Manager, del AWS EMEA Prototyping and Cloud Engineering. Strankam pomaga čim bolje izkoristiti najnovejšo tehnologijo, hitreje uvesti inovacije in razmišljati širše.
Irina Radu je Prototyping Engagement Manager, del AWS EMEA Prototyping and Cloud Engineering. Strankam pomaga čim bolje izkoristiti najnovejšo tehnologijo, hitreje uvesti inovacije in razmišljati širše.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/boosting-rag-based-intelligent-document-assistants-using-entity-extraction-sql-querying-and-agents-with-amazon-bedrock/

