Pogovorni pomočniki umetne inteligence (AI) so zasnovani tako, da zagotavljajo natančne odzive v realnem času prek inteligentnega usmerjanja poizvedb do najprimernejših funkcij AI. Z generativnimi storitvami umetne inteligence AWS, kot je Amazon Bedrock, lahko razvijalci ustvarijo sisteme, ki strokovno upravljajo in se odzivajo na zahteve uporabnikov. Amazon Bedrock je popolnoma upravljana storitev, ki ponuja izbiro visoko zmogljivih temeljnih modelov (FM) vodilnih podjetij z umetno inteligenco, kot so AI21 Labs, Anthropic, Cohere, Meta, Stability AI in Amazon, z uporabo enega samega API-ja, skupaj s širokim naborom zmožnosti, ki jih potrebujete za izdelavo generativnih aplikacij AI z varnostjo, zasebnostjo in odgovornim AI.
Ta objava ocenjuje dva primarna pristopa za razvoj pomočnikov AI: uporabo upravljanih storitev, kot je npr Zastopniki za Amazon Bedrock, in uporabo odprtokodnih tehnologij, kot je LangChain. Raziščemo prednosti in izzive vsakega, tako da lahko izberete najprimernejšo pot za svoje potrebe.
Kaj je pomočnik AI?
Pomočnik AI je inteligenten sistem, ki razume poizvedbe v naravnem jeziku in sodeluje z različnimi orodji, viri podatkov in API-ji za izvajanje nalog ali pridobivanje informacij v imenu uporabnika. Učinkoviti pomočniki AI imajo naslednje ključne zmogljivosti:
- Procesiranje naravnega jezika (NLP) in pogovorni tok
- Integracija baze znanja in semantična iskanja za razumevanje in pridobivanje ustreznih informacij na podlagi nians konteksta pogovora
- Izvajanje nalog, kot so poizvedbe po bazi podatkov in po meri AWS Lambda funkcije
- Obravnava specializiranih pogovorov in zahtev uporabnikov
Na primeru upravljanja naprav interneta stvari (IoT) prikazujemo prednosti pomočnikov AI. V tem primeru uporabe lahko umetna inteligenca pomaga tehnikom pri učinkovitem upravljanju strojev z ukazi, ki pridobivajo podatke ali avtomatizirajo naloge, s čimer racionalizirajo operacije v proizvodnji.
Pristop agentov za Amazon Bedrock
Zastopniki za Amazon Bedrock vam omogoča izdelavo generativnih aplikacij AI, ki lahko izvajajo naloge v več korakih v sistemih in virih podatkov podjetja. Ponuja naslednje ključne zmogljivosti:
- Samodejno hitro ustvarjanje iz navodil, podrobnosti API-ja in informacij o izvoru podatkov, kar prihrani tedne hitrega inženiringa
- Retrieval Augmented Generation (RAG) za varno povezovanje agentov z viri podatkov podjetja in zagotavljanje ustreznih odgovorov
- Orkestracija in izvajanje večstopenjskih opravil z razčlenitvijo zahtev v logična zaporedja in klicanjem potrebnih API-jev
- Vpogled v sklepanje agenta prek sledi verige misli (CoT), kar omogoča odpravljanje težav in usmerjanje vedenja modela
- Inženirske zmožnosti hitrega poziva za spreminjanje samodejno ustvarjene predloge poziva za izboljšan nadzor nad agenti
Uporabite lahko agente za Amazon Bedrock in Baze znanja za Amazon Bedrock za izdelavo in uvajanje pomočnikov AI za zapletene primere uporabe usmerjanja. Zagotavljajo strateško prednost za razvijalce in organizacije s poenostavitvijo upravljanja infrastrukture, izboljšanjem razširljivosti, izboljšanjem varnosti in zmanjšanjem nediferenciranega dvigovanja težkega. Omogočajo tudi enostavnejšo kodo aplikacijskega sloja, ker se logika usmerjanja, vektorizacija in pomnilnik v celoti upravljajo.
Pregled rešitev
Ta rešitev uvaja pogovornega pomočnika AI, prilagojenega za upravljanje in delovanje naprav interneta stvari pri uporabi Anthropic's Claude v2.1 na Amazon Bedrock. Osnovno funkcionalnost pomočnika AI ureja obsežen nabor navodil, znan kot a sistemski poziv, ki opisuje njegove sposobnosti in strokovna področja. Ta navodila zagotavljajo, da lahko pomočnik za umetno inteligenco opravi širok nabor nalog, od upravljanja informacij o napravi do izvajanja operativnih ukazov.
Opremljen s temi zmogljivostmi, kot je podrobno opisano v sistemskem pozivu, pomočnik AI sledi strukturiranemu delovnemu toku za odgovarjanje na vprašanja uporabnikov. Naslednja slika ponuja vizualno predstavitev tega poteka dela, ki ponazarja vsak korak od začetne interakcije uporabnika do končnega odgovora.

Potek dela je sestavljen iz naslednjih korakov:
- Postopek se začne, ko uporabnik od pomočnika zahteva izvedbo naloge; na primer zahtevati največje število podatkovnih točk za določeno napravo IoT
device_xxx. Ta vnos besedila se zajame in pošlje pomočniku AI. - Pomočnik AI razlaga uporabnikov vnos besedila. Za razumevanje konteksta in določanje potrebnih nalog uporablja ponujeno zgodovino pogovorov, akcijske skupine in baze znanja.
- Ko je uporabnikov namen razčlenjen in razumljen, pomočnik AI definira naloge. To temelji na navodilih, ki jih razlaga pomočnik glede na sistemski poziv in uporabnikov vnos.
- Naloge se nato izvajajo skozi vrsto klicev API-ja. To se naredi z uporabo React poziv, ki nalogo razdeli na niz korakov, ki se obdelajo zaporedno:
- Za preverjanje meritev naprave uporabljamo
check-device-metricsakcijska skupina, ki vključuje klic API-ja funkcijam Lambda, ki nato poizvedujejo Amazonska Atena za zahtevane podatke. - Za neposredna dejanja naprave, kot so zagon, zaustavitev ali ponovni zagon, uporabljamo
action-on-deviceakcijska skupina, ki prikliče funkcijo Lambda. Ta funkcija sproži proces, ki pošilja ukaze napravi IoT. Za to objavo funkcija Lambda pošilja obvestila z uporabo Enostavna e -poštna storitev Amazon (Amazon SES). - Uporabljamo baze znanja za Amazon Bedrock za pridobivanje iz zgodovinskih podatkov, shranjenih kot vdelave v Storitev Amazon OpenSearch vektorska baza podatkov.
- Za preverjanje meritev naprave uporabljamo
- Ko so naloge končane, Amazon Bedrock FM ustvari končni odgovor in ga pošlje nazaj uporabniku.
- Agenti za Amazon Bedrock samodejno shranjujejo informacije z uporabo seje s stanjem za vzdrževanje istega pogovora. Stanje se izbriše po preteku nastavljive časovne omejitve nedejavnosti.
Tehnični pregled
Naslednji diagram ponazarja arhitekturo za uvedbo pomočnika AI z agenti za Amazon Bedrock.

Sestavljen je iz naslednjih ključnih komponent:
- Pogovorni vmesnik – Pogovorni vmesnik uporablja Streamlit, odprtokodno knjižnico Python, ki poenostavlja ustvarjanje prilagojenih, vizualno privlačnih spletnih aplikacij za strojno učenje (ML) in podatkovno znanost. Gostuje na Amazonska storitev za kontejnerje z elastiko (Amazon ECS) z AWS Fargate, do njega pa se dostopa z izravnalnikom obremenitve aplikacij. Za zagon lahko uporabite Fargate z Amazon ECS posode ne da bi morali upravljati strežnike, gruče ali virtualne stroje.
- Zastopniki za Amazon Bedrock – Agenti za Amazon Bedrock dokonča uporabniške poizvedbe z nizom korakov razmišljanja in ustreznih dejanj, ki temeljijo na ReAct poziv:
- Baze znanja za Amazon Bedrock – Baze znanja za Amazon Bedrock zagotavljajo popolno upravljanje krpa da pomočniku AI omogoči dostop do vaših podatkov. V našem primeru uporabe smo naložili specifikacije naprave v Preprosta storitev shranjevanja Amazon (Amazon S3) vedro. Služi kot vir podatkov za bazo znanja.
- Akcijske skupine – To so definirane sheme API-jev, ki kličejo specifične funkcije Lambda za interakcijo z napravami IoT in drugimi storitvami AWS.
- Anthropic Claude v2.1 na Amazon Bedrock – Ta model interpretira uporabniške poizvedbe in orkestrira tok nalog.
- Amazon Titan Embeddings – Ta model služi kot model vdelave besedila, ki pretvori besedilo v naravnem jeziku – od posameznih besed do kompleksnih dokumentov – v numerične vektorje. To omogoča zmožnosti vektorskega iskanja, kar omogoča sistemu, da semantično poveže uporabniške poizvedbe z najbolj ustreznimi vnosi v bazo znanja za učinkovito iskanje.
Rešitev je integrirana s storitvami AWS, kot je Lambda za izvajanje kode kot odgovor na klice API-ja, Athena za poizvedovanje po nizih podatkov, OpenSearch Service za iskanje po bazah znanja in Amazon S3 za shranjevanje. Te storitve delujejo skupaj in zagotavljajo brezhibno izkušnjo za upravljanje operacij naprav IoT prek ukazov v naravnem jeziku.
prednosti
Ta rešitev nudi naslednje prednosti:
- Kompleksnost izvedbe:
- Potrebnih je manj vrstic kode, ker Agenti za Amazon Bedrock abstrahirajo velik del osnovne zapletenosti in zmanjšajo trud pri razvoju
- Upravljanje vektorskih zbirk podatkov, kot je OpenSearch Service, je poenostavljeno, saj baze znanja za Amazon Bedrock obravnavajo vektorizacijo in shranjevanje
- Integracija z različnimi storitvami AWS je bolj poenostavljena prek vnaprej določenih akcijskih skupin
- Izkušnje razvijalca:
- Konzola Amazon Bedrock ponuja uporabniku prijazen vmesnik za hiter razvoj, testiranje in analizo vzroka (RCA), kar izboljša celotno izkušnjo razvijalcev
- Gibljivost in fleksibilnost:
- Agenti za Amazon Bedrock omogočajo brezhibne nadgradnje na novejše FM (kot je Claude 3.0), ko bodo na voljo, tako da vaša rešitev ostane na tekočem z najnovejšimi dosežki.
- Storitvene kvote in omejitve upravlja AWS, kar zmanjšuje režijske stroške infrastrukture za spremljanje in skaliranje
- Varnost:
- Amazon Bedrock je popolnoma upravljana storitev, ki upošteva stroge standarde varnosti in skladnosti AWS, kar lahko poenostavi organizacijske varnostne preglede
Čeprav Agenti za Amazon Bedrock ponujajo poenostavljeno in upravljano rešitev za izdelavo pogovornih aplikacij AI, bodo nekatere organizacije morda raje uporabile odprtokodni pristop. V takšnih primerih lahko uporabite ogrodja, kot je LangChain, o katerem razpravljamo v naslednjem razdelku.
Pristop dinamičnega usmerjanja LangChain
LangChain je odprtokodno ogrodje, ki poenostavlja gradnjo pogovorne umetne inteligence, tako da omogoča integracijo velikih jezikovnih modelov (LLM) in zmožnosti dinamičnega usmerjanja. Z jezikom izražanja LangChain (LCEL) lahko razvijalci definirajo usmerjanje, ki vam omogoča ustvarjanje nedeterminističnih verig, kjer rezultat prejšnjega koraka definira naslednji korak. Usmerjanje pomaga zagotoviti strukturo in doslednost v interakcijah z LLM.
Za to objavo uporabljamo isti primer kot pomočnik AI za upravljanje naprav IoT. Vendar je glavna razlika ta, da moramo sistemske pozive obravnavati ločeno in vsako verigo obravnavati kot ločeno entiteto. Usmerjevalna veriga določi ciljno verigo na podlagi uporabnikovega vnosa. Odločitev je sprejeta s podporo LLM s posredovanjem sistemskega poziva, zgodovine klepetov in vprašanja uporabnika.
Pregled rešitev
Naslednji diagram prikazuje potek dela rešitve dinamičnega usmerjanja.
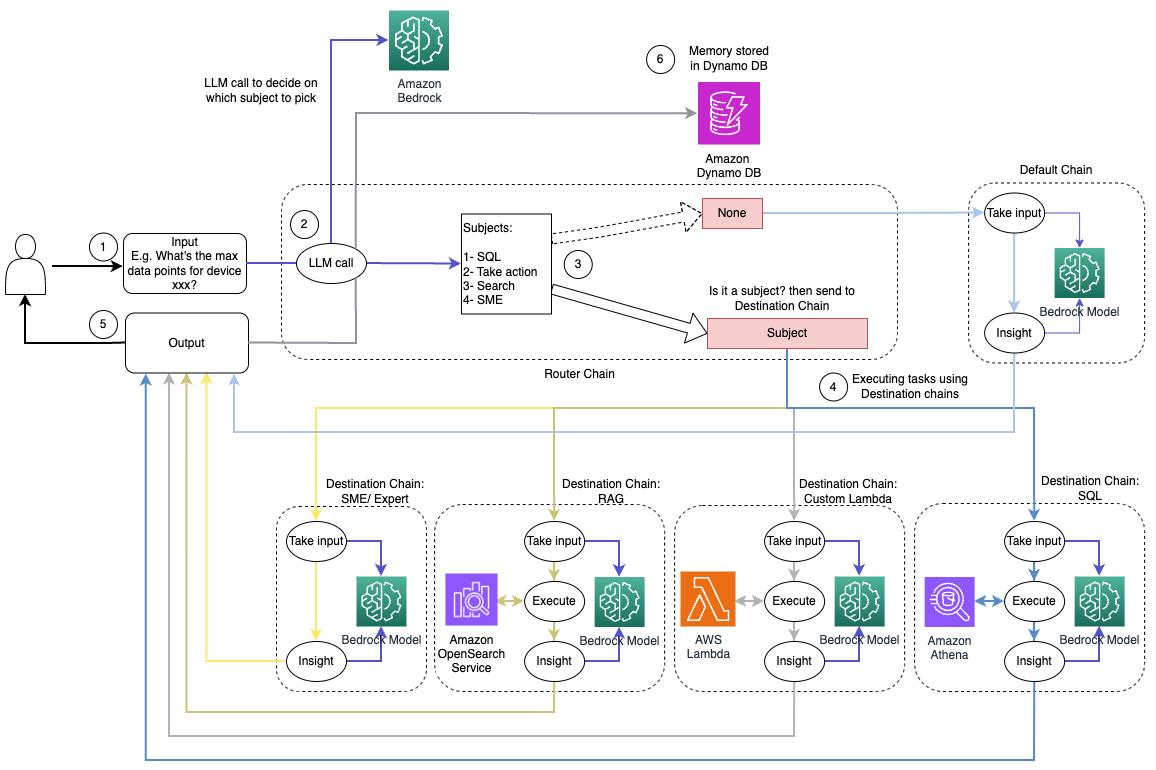
Potek dela je sestavljen iz naslednjih korakov:
- Uporabnik pomočniku AI postavi vprašanje. Na primer, "Kakšne so največje meritve za napravo 1009?"
- LLM oceni vsako vprašanje skupaj z zgodovino klepeta iz iste seje, da ugotovi njegovo naravo in pod katero področje spada (na primer SQL, dejanje, iskanje ali MSP). LLM razvrsti vhod in usmerjevalna veriga LCEL prevzame ta vnos.
- Veriga usmerjevalnika izbere ciljno verigo na podlagi vnosa, LLM pa prejme naslednji sistemski poziv:
LLM ovrednoti uporabnikovo vprašanje skupaj z zgodovino klepetov, da ugotovi naravo poizvedbe in pod katero področje spada. LLM nato razvrsti vhod in izda odgovor JSON v naslednji obliki:
Veriga usmerjevalnika uporablja ta odziv JSON za priklic ustrezne ciljne verige. Obstajajo štiri predmetno specifične ciljne verige, vsaka s svojim sistemskim pozivom:
- Poizvedbe, povezane s SQL, so poslane v ciljno verigo SQL za interakcije z bazo podatkov. Za izdelavo lahko uporabite LCEL Veriga SQL.
- K dejanjem usmerjena vprašanja prikličejo ciljno verigo Lambda po meri za izvajanje operacij. Z LCEL lahko določite svoje funkcija po meri; v našem primeru je to funkcija za zagon vnaprej določene funkcije Lambda za pošiljanje e-pošte z razčlenjenim ID-jem naprave. Primer uporabniškega vnosa je lahko »Izklopi napravo 1009«.
- Poizvedbe, osredotočene na iskanje, se nadaljujejo do krpa ciljna veriga za iskanje informacij.
- Vprašanja, povezana z malimi in srednje velikimi podjetji, se za posebne vpoglede obrnite na ciljno verigo malih in srednje velikih podjetij/strokovnjakov.
- Vsaka ciljna veriga sprejme vhodne podatke in zažene potrebne modele ali funkcije:
- Veriga SQL uporablja Atheno za izvajanje poizvedb.
- Veriga RAG uporablja storitev OpenSearch za semantično iskanje.
- Veriga Lambda po meri izvaja funkcije Lambda za dejanja.
- Veriga MSP/strokovnjakov zagotavlja vpoglede z uporabo modela Amazon Bedrock.
- LLM oblikuje odzive vsake ciljne verige v koherentne vpoglede. Ti vpogledi so nato dostavljeni uporabniku, s čimer se zaključi cikel poizvedbe.
- Uporabniški vnos in odgovori so shranjeni v Amazon DynamoDB zagotoviti kontekst za LLM za trenutno sejo in iz preteklih interakcij. Trajanje trajnih informacij v DynamoDB nadzira aplikacija.
Tehnični pregled
Naslednji diagram ponazarja arhitekturo rešitve za dinamično usmerjanje LangChain.
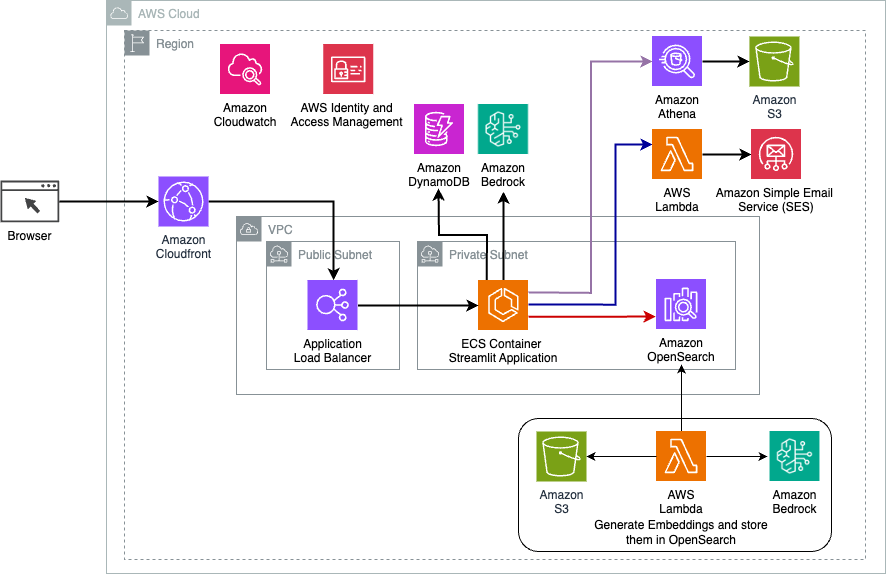
Spletna aplikacija je zgrajena na Streamlitu, ki gostuje na Amazon ECS s Fargate, do nje pa se dostopa s pomočjo Application Load Balancer. Kot LLM uporabljamo Anthropic's Claude v2.1 na Amazon Bedrock. Spletna aplikacija komunicira z modelom s pomočjo knjižnic LangChain. Prav tako sodeluje z različnimi drugimi storitvami AWS, kot so OpenSearch Service, Athena in DynamoDB, da izpolni potrebe končnih uporabnikov.
prednosti
Ta rešitev nudi naslednje prednosti:
- Kompleksnost izvedbe:
- Čeprav zahteva več kode in razvoj po meri, LangChain zagotavlja večjo prilagodljivost in nadzor nad logiko usmerjanja ter integracijo z različnimi komponentami.
- Upravljanje vektorskih zbirk podatkov, kot je OpenSearch Service, zahteva dodatno nastavitev in konfiguracijo. Postopek vektorizacije je implementiran v kodi.
- Integracija s storitvami AWS lahko vključuje več kode in konfiguracije po meri.
- Izkušnje razvijalca:
- LangChainov pristop, ki temelji na Pythonu, in obsežna dokumentacija sta lahko privlačna za razvijalce, ki že poznajo Python in odprtokodna orodja.
- Hiter razvoj in odpravljanje napak lahko zahtevata več ročnega truda v primerjavi z uporabo konzole Amazon Bedrock.
- Gibljivost in fleksibilnost:
- LangChain podpira široko paleto LLM-jev, kar vam omogoča preklapljanje med različnimi modeli ali ponudniki, kar spodbuja prilagodljivost.
- Odprtokodna narava LangChaina omogoča izboljšave in prilagoditve, ki jih vodi skupnost.
- Varnost:
- Kot odprtokodno ogrodje lahko LangChain zahteva strožje varnostne preglede in preverjanje znotraj organizacij, kar lahko povzroči dodatne stroške.
zaključek
Pogovorni pomočniki AI so transformativna orodja za racionalizacijo operacij in izboljšanje uporabniške izkušnje. Ta objava je raziskala dva močna pristopa z uporabo storitev AWS: upravljane agente za Amazon Bedrock in prilagodljivo odprtokodno dinamično usmerjanje LangChain. Izbira med temi pristopi je odvisna od zahtev vaše organizacije, razvojnih preferenc in želene ravni prilagajanja. Ne glede na izbrano pot vam AWS omogoča ustvarjanje inteligentnih pomočnikov AI, ki revolucionirajo poslovanje in interakcije s strankami
Poiščite kodo rešitve in sredstva za uvajanje v našem GitHub repozitorij, kjer lahko sledite podrobnim korakom za vsak pogovorni pristop AI.
O avtorjih
 Ameer Hakme je arhitekt rešitev AWS s sedežem v Pensilvaniji. Sodeluje z neodvisnimi ponudniki programske opreme (ISV) v severovzhodni regiji in jim pomaga pri oblikovanju in izgradnji razširljivih in sodobnih platform v oblaku AWS. Ameer, strokovnjak za AI/ML in generativno umetno inteligenco, strankam pomaga sprostiti potencial teh najsodobnejših tehnologij. V prostem času uživa v vožnji z motorjem in preživlja kakovosten čas s svojo družino.
Ameer Hakme je arhitekt rešitev AWS s sedežem v Pensilvaniji. Sodeluje z neodvisnimi ponudniki programske opreme (ISV) v severovzhodni regiji in jim pomaga pri oblikovanju in izgradnji razširljivih in sodobnih platform v oblaku AWS. Ameer, strokovnjak za AI/ML in generativno umetno inteligenco, strankam pomaga sprostiti potencial teh najsodobnejših tehnologij. V prostem času uživa v vožnji z motorjem in preživlja kakovosten čas s svojo družino.
 Sharon Li je arhitekt rešitev AI/ML pri Amazon Web Services s sedežem v Bostonu, s strastjo do oblikovanja in gradnje generativnih aplikacij AI na AWS. Sodeluje s strankami pri izkoriščanju storitev AWS AI/ML za inovativne rešitve.
Sharon Li je arhitekt rešitev AI/ML pri Amazon Web Services s sedežem v Bostonu, s strastjo do oblikovanja in gradnje generativnih aplikacij AI na AWS. Sodeluje s strankami pri izkoriščanju storitev AWS AI/ML za inovativne rešitve.
 Kawsar Kamal je višji arhitekt rešitev pri Amazon Web Services z več kot 15-letnimi izkušnjami na področju avtomatizacije infrastrukture in varnosti. Strankam pomaga oblikovati in zgraditi razširljive rešitve DevSecOps in AI/ML v oblaku.
Kawsar Kamal je višji arhitekt rešitev pri Amazon Web Services z več kot 15-letnimi izkušnjami na področju avtomatizacije infrastrukture in varnosti. Strankam pomaga oblikovati in zgraditi razširljive rešitve DevSecOps in AI/ML v oblaku.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

