В первой части В этой серии из трех частей мы представили решение, которое демонстрирует, как можно автоматизировать обнаружение фальсификации документов и мошенничества в больших масштабах с помощью сервисов искусственного интеллекта AWS и машинного обучения (ML) для сценария использования ипотечного андеррайтинга.
В этом посте мы представляем подход к разработке модели компьютерного зрения на основе глубокого обучения для обнаружения и выделения поддельных изображений при выдаче ипотечных кредитов. Мы предоставляем рекомендации по созданию, обучению и развертыванию сетей глубокого обучения на Создатель мудреца Амазонки.
В части 3 мы покажем, как реализовать решение на Амазон детектор мошенничества.
Обзор решения
Чтобы достичь цели обнаружения подделки документов при выдаче ипотечного кредита, мы используем модель компьютерного зрения, размещенную на SageMaker, для нашего решения по обнаружению подделки изображений. Эта модель получает тестовое изображение в качестве входных данных и генерирует прогноз вероятности подделки в качестве выходных данных. Архитектура сети показана на следующей схеме.
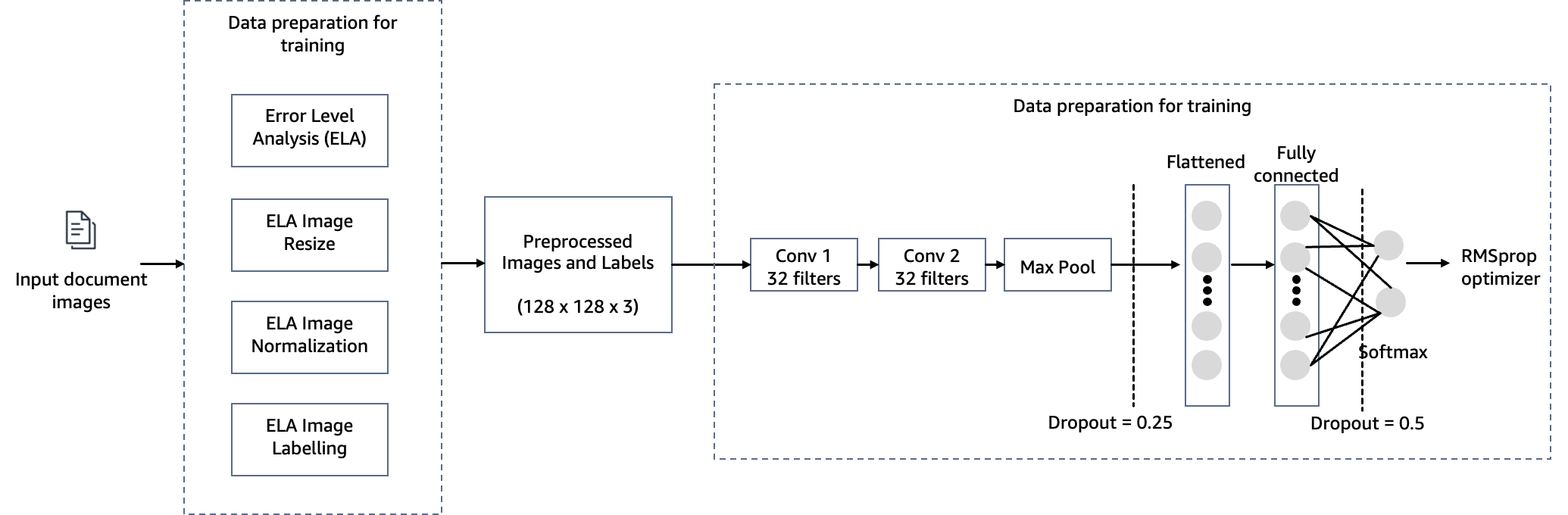
Подделка изображений в основном включает в себя четыре метода: сращивание, копирование-перемещение, удаление и улучшение. В зависимости от характеристик подделки в качестве основы для обнаружения и локализации могут использоваться различные улики. Эти подсказки включают в себя артефакты сжатия JPEG, несоответствия краев, образцы шума, согласованность цвета, визуальное сходство, согласованность EXIF и модель камеры.
Учитывая обширную область обнаружения подделок изображений, мы используем алгоритм анализа уровня ошибок (ELA) в качестве наглядного метода обнаружения подделок. Мы выбрали метод ELA для этой статьи по следующим причинам:
- Это быстрее реализовать и позволяет легко обнаружить подделку изображений.
- Он работает путем анализа уровней сжатия различных частей изображения. Это позволяет обнаруживать несоответствия, которые могут указывать на несанкционированное вмешательство — например, если одна область была скопирована и вставлена из другого изображения, сохраненного с другим уровнем сжатия.
- Он хорош для обнаружения более тонких или незаметных вмешательств, которые трудно обнаружить невооруженным глазом. Даже небольшие изменения в изображении могут привести к заметным аномалиям сжатия.
- Он не полагается на наличие исходного немодифицированного изображения для сравнения. ELA может идентифицировать признаки фальсификации только внутри самого сомнительного изображения. Другие методы часто требуют для сравнения немодифицированный оригинал.
- Это упрощенный метод, который основан только на анализе артефактов сжатия в данных цифрового изображения. Это не зависит от специализированного оборудования или криминалистической экспертизы. Это делает ELA доступным в качестве инструмента первичного анализа.
- Выходное изображение ELA может четко выделять различия в уровнях сжатия, делая видимыми подделанные области. Это позволяет даже неспециалисту распознать признаки возможных манипуляций.
- Он работает со многими типами изображений (такими как JPEG, PNG и GIF) и требует анализа только самого изображения. Другие судебно-медицинские методы могут быть более ограничены в отношении форматов или требований к исходному изображению.
Однако в реальных сценариях, когда у вас может быть комбинация входных документов (JPEG, PNG, GIF, TIFF, PDF), мы рекомендуем использовать ELA в сочетании с различными другими методами, такими как обнаружение несоответствий в краях, структура шума, однородность цвета, Согласованность данных EXIF, идентификация модели камерыи единообразие шрифта. Мы стремимся обновить код для этого поста, добавив дополнительные методы обнаружения подделок.
Основная предпосылка ELA предполагает, что входные изображения имеют формат JPEG, известный своим сжатием с потерями. Тем не менее, этот метод по-прежнему может быть эффективным, даже если входные изображения изначально были в формате без потерь (например, PNG, GIF или BMP), а затем были преобразованы в JPEG в процессе изменения. Когда ELA применяется к исходным форматам без потерь, это обычно указывает на стабильное качество изображения без каких-либо ухудшений, что затрудняет определение измененных областей. В изображениях JPEG ожидаемой нормой является то, что все изображение имеет одинаковый уровень сжатия. Однако если в определенном участке изображения отображается заметно другой уровень ошибок, это часто указывает на то, что было внесено цифровое изменение.
ELA подчеркивает различия в степени сжатия JPEG. Области с однородной окраской, скорее всего, будут иметь более низкий результат ELA (например, более темный цвет по сравнению с высококонтрастными краями). Для выявления взлома или модификации необходимо обратить внимание на следующее:
- Похожие края должны иметь одинаковую яркость в результате ELA. Все высококонтрастные края должны быть похожи друг на друга, а все низкоконтрастные края должны выглядеть одинаково. На исходной фотографии низкоконтрастные края должны быть почти такими же яркими, как и высококонтрастные.
- Подобные текстуры должны иметь схожую окраску под ELA. Области с большей детализацией поверхности, например баскетбольный мяч крупным планом, скорее всего, будут иметь более высокий результат ELA, чем гладкая поверхность.
- Независимо от фактического цвета поверхности, все плоские поверхности должны иметь примерно одинаковую окраску под ELA.
Изображения JPEG используют систему сжатия с потерями. Каждое перекодирование (пересохранение) изображения увеличивает потерю качества изображения. В частности, алгоритм JPEG работает с сеткой пикселей 8×8. Каждый квадрат 8×8 сжимается независимо. Если изображение полностью не изменено, то все квадраты 8×8 должны иметь одинаковый потенциал ошибки. Если изображение не изменено и пересохранено, то каждый квадрат должен деградировать примерно с одинаковой скоростью.
ELA сохраняет изображение с указанным уровнем качества JPEG. Это повторное сохранение приводит к известному количеству ошибок во всем изображении. Затем повторно сохраненное изображение сравнивается с исходным изображением. Если изображение изменено, то каждый квадрат 8×8, которого затронула модификация, должен иметь более высокий потенциал ошибки, чем остальная часть изображения.
Результаты ELA напрямую зависят от качества изображения. Возможно, вам захочется узнать, было ли что-то добавлено, но если изображение копируется несколько раз, ELA может разрешить только обнаружение повторных сохранений. Постарайтесь найти версию изображения в наилучшем качестве.
Благодаря обучению и практике ELA также может научиться определять масштабирование, качество, обрезку и повторные преобразования изображений. Например, если изображение, отличное от JPEG, содержит видимые линии сетки (шириной 1 пиксель в квадратах 8×8), это означает, что изображение изначально было в формате JPEG и было преобразовано в формат, отличный от JPEG (например, PNG). Если в некоторых областях изображения отсутствуют линии сетки или линии сетки смещаются, это означает склейку или нарисованную часть изображения, отличного от JPEG.
В следующих разделах мы демонстрируем шаги по настройке, обучению и развертыванию модели компьютерного зрения.
Предпосылки
Чтобы следовать этому сообщению, выполните следующие предварительные условия:
- У вас есть учетная запись AWS.
- Создавать Студия Amazon SageMaker. Вы можете быстро запустить SageMaker Studio, используя настройки по умолчанию, что облегчает быстрый запуск. Для получения дополнительной информации см. Amazon SageMaker упрощает настройку Amazon SageMaker Studio для отдельных пользователей..
- Откройте SageMaker Studio и запустите системный терминал.
- Запустите следующую команду в терминале:
git clone https://github.com/aws-samples/document-tampering-detection.git - Общая стоимость запуска SageMaker Studio для одного пользователя и конфигурации среды ноутбука составляет 7.314 долларов США в час.
Настройте блокнот для обучения модели
Выполните следующие шаги, чтобы настроить тренировочный блокнот:
- Откройте приложение
tampering_detection_training.ipynbфайл из каталога обнаружения подделки документов. - Настройте среду ноутбука с изображением TensorFlow 2.6 Python 3.8, оптимизированным для ЦП или графического процессора.
Вы можете столкнуться с проблемой недостаточной доступности или достичь предела квоты для экземпляров графического процессора в вашей учетной записи AWS при выборе экземпляров, оптимизированных для графического процессора. Чтобы увеличить квоту, посетите консоль «Квоты служб» и увеличьте лимит службы для конкретного типа экземпляра, который вам нужен. В таких случаях вы также можете использовать среду ноутбука, оптимизированную для ЦП. - Что касается ядро, выберите Python3.
- Что касается Тип экземпляра, выберите ml.m5d.24xlarge или любой другой крупный экземпляр.
Мы выбрали более крупный тип экземпляра, чтобы сократить время обучения модели. В среде ноутбуков ml.m5d.24xlarge стоимость часа составляет 7.258 долларов США в час.
Запустите тренировочный блокнот
Пробегите каждую ячейку в блокноте tampering_detection_training.ipynb чтобы. Мы обсудим некоторые ячейки более подробно в следующих разделах.
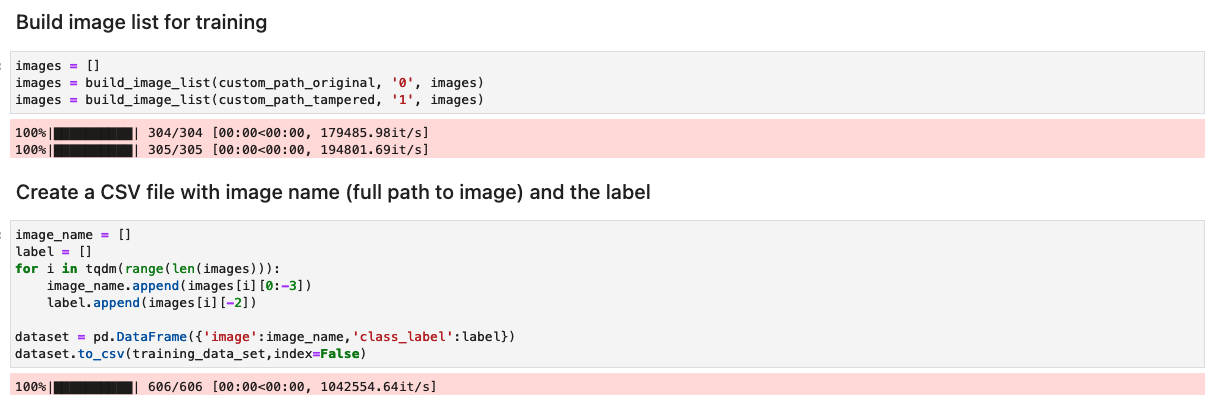
Подготовьте набор данных со списком оригинальных и подделанных изображений.
Прежде чем запускать следующую ячейку в записной книжке, подготовьте набор данных оригинальных и поддельных документов в соответствии с конкретными бизнес-требованиями. Для этой статьи мы используем образец набора данных о поддельных платежных квитанциях и банковских выписках. Набор данных доступен в каталоге изображений на Репозиторий GitHub.

Ноутбук считывает оригинальные и подделанные изображения с images/training каталог.
Набор данных для обучения создается с использованием файла CSV с двумя столбцами: путь к файлу изображения и метка изображения (0 для исходного изображения и 1 для подделанного изображения).
Обработайте набор данных, генерируя результаты ELA для каждого обучающего изображения.
На этом этапе мы генерируем результат ELA (с качеством 90%) входного обучающего изображения. Функция convert_to_ela_image принимает два параметра: путь, который представляет собой путь к файлу изображения, и качество, представляющее параметр качества для сжатия JPEG. Функция выполняет следующие шаги:
- Преобразуйте изображение в формат RGB и пересохраните его в файл JPEG с указанным качеством под именем tempresaved.jpg.
- Вычислите разницу между исходным изображением и повторно сохраненным изображением JPEG (ELA), чтобы определить максимальную разницу в значениях пикселей между исходным и повторно сохраненным изображениями.
- Рассчитайте масштабный коэффициент на основе максимальной разницы, чтобы отрегулировать яркость изображения ELA.
- Увеличьте яркость изображения ELA, используя рассчитанный масштабный коэффициент.
- Измените размер результата ELA на 128x128x3, где 3 представляет количество каналов для уменьшения размера входных данных для обучения.
- Верните изображение ELA.
В форматах изображений с потерями, таких как JPEG, первоначальный процесс сохранения приводит к значительной потере цвета. Однако когда изображение загружается и впоследствии перекодируется в тот же формат с потерями, ухудшение цвета обычно происходит меньше. Результаты ELA подчеркивают области изображения, наиболее подверженные ухудшению цвета при повторном сохранении. Как правило, изменения заметны в областях с более высоким потенциалом деградации по сравнению с остальной частью изображения.
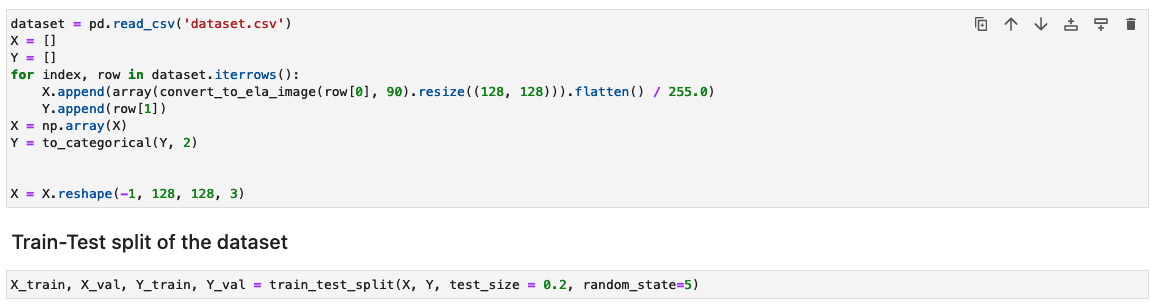
Далее изображения обрабатываются в массив NumPy для обучения. Затем мы случайным образом разделяем входной набор данных на данные обучения, тестирования или проверки (80/20). Вы можете игнорировать любые предупреждения при запуске этих ячеек.
В зависимости от размера набора данных запуск этих ячеек может занять некоторое время. Для примера набора данных, который мы предоставили в этом репозитории, это может занять 5–10 минут.
Настройте модель CNN
На этом этапе мы создаем минимальную версию сети VGG с небольшими сверточными фильтрами. VGG-16 состоит из 13 сверточных слоев и трех полносвязных слоев. На следующем снимке экрана показана архитектура нашей модели сверточной нейронной сети (CNN).
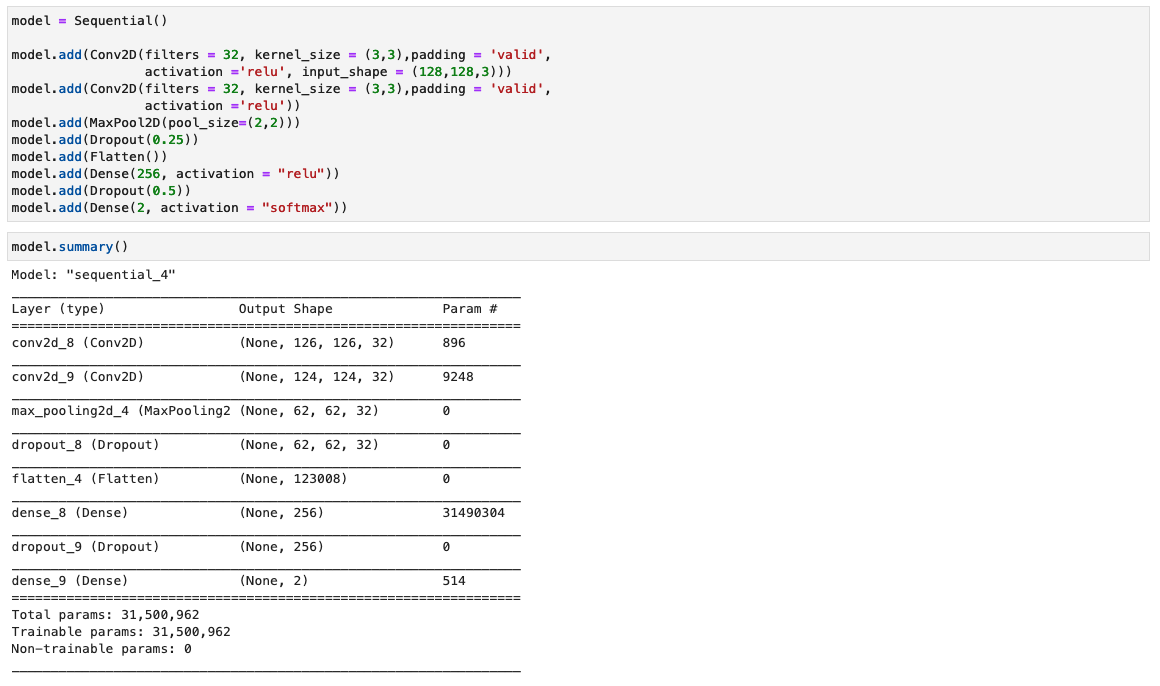
Обратите внимание на следующие конфигурации:
- вход – Модель принимает входное изображение размером 128x128x3.
- Сверточные слои – Сверточные слои используют минимальное рецептивное поле (3×3), наименьшего возможного размера, которое по-прежнему захватывает верх/низ и лево/право. За этим следует функция активации выпрямленного линейного блока (ReLU), которая сокращает время обучения. Это линейная функция, которая выводит входные данные, если они положительные; в противном случае выход равен нулю. Шаг свертки фиксирован по умолчанию (1 пиксель), чтобы сохранить пространственное разрешение после свертки (шаг — это количество сдвигов пикселей по входной матрице).
- Полностью связанные слои – Сеть имеет два полностью связанных уровня. Первый плотный слой использует активацию ReLU, а второй использует softmax для классификации изображения как оригинального или подделанного.
Вы можете игнорировать любые предупреждения при запуске этих ячеек.
Сохраните артефакты модели
Сохраните обученную модель под уникальным именем файла (например, на основе текущей даты и времени) в каталоге с именем model.

Модель сохраняется в формате Keras с расширением .keras. Мы также сохраняем артефакты модели как каталог с именем 1, содержащий сериализованные подписи и состояние, необходимое для их запуска, включая значения переменных и словари для развертывания в среде выполнения SageMaker (о чем мы поговорим позже в этом посте).
Измерьте производительность модели
Следующая кривая потерь показывает прогресс потерь модели в течение эпох обучения (итераций).
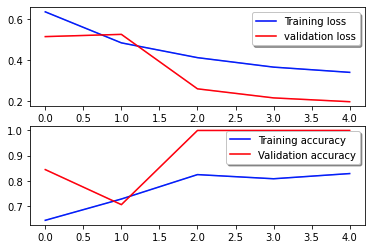
Функция потерь измеряет, насколько хорошо прогнозы модели соответствуют фактическим целям. Более низкие значения указывают на лучшее соответствие между прогнозами и истинными значениями. Уменьшение потерь с течением эпох означает, что модель улучшается. Кривая точности иллюстрирует точность модели в течение эпох обучения. Точность — это отношение правильных предсказаний к общему количеству предсказаний. Более высокая точность указывает на более эффективную модель. Обычно точность увеличивается во время обучения, поскольку модель изучает закономерности и улучшает свои прогнозирующие способности. Это поможет вам определить, является ли модель переоснащенной (хорошо работает на обучающих данных, но плохо на невидимых данных) или недостаточно обученной (недостаточно обучается на обучающих данных).
Следующая матрица путаницы визуально показывает, насколько хорошо модель точно различает положительные (поддельное изображение, представленное как значение 1) и отрицательное (неподделанное изображение, представленное как значение 0) классы.
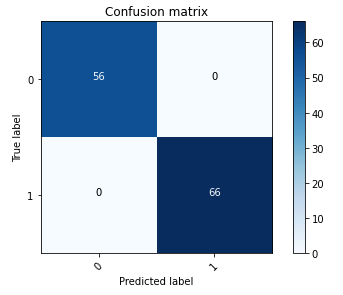
После обучения модели наш следующий шаг — развертывание модели компьютерного зрения в качестве API. Этот API будет интегрирован в бизнес-приложения как компонент рабочего процесса андеррайтинга. Для этого мы используем Amazon SageMaker Inference — полностью управляемый сервис. Этот сервис легко интегрируется с инструментами MLOps, обеспечивая масштабируемое развертывание моделей, экономичный вывод, улучшенное управление моделями в производстве и снижение сложности эксплуатации. В этом посте мы развертываем модель как конечную точку вывода в реальном времени. Однако важно отметить, что в зависимости от рабочего процесса ваших бизнес-приложений развертывание модели также может быть адаптировано для пакетной обработки, асинхронной обработки или с помощью бессерверной архитектуры развертывания.
Настройка записной книжки для развертывания модели
Выполните следующие шаги, чтобы настроить блокнот для развертывания модели:
- Откройте приложение
tampering_detection_model_deploy.ipynbфайл из каталога обнаружения подделки документов. - Настройте среду блокнота с помощью изображения Data Science 3.0.
- Что касается ядро, выберите Python3.
- Что касается Тип экземпляра, выберите мл.т3.средняя.
В среде ноутбуков ml.t3.medium стоимость часа составляет 0.056 доллара США.
Создайте собственную встроенную политику для роли SageMaker, чтобы разрешить все действия Amazon S3.
Ассоциация Управление идентификацией и доступом AWS (IAM) роль для SageMaker будет в формате AmazonSageMaker- ExecutionRole-<random numbers>. Убедитесь, что вы используете правильную роль. Имя роли можно найти под сведениями о пользователе в конфигурациях домена SageMaker.

Обновите роль IAM, включив в нее встроенную политику, разрешающую все Простой сервис хранения Amazon (Amazon S3) действия. Это потребуется для автоматизации создания и удаления корзин S3, в которых будут храниться артефакты модели. Вы можете ограничить доступ к определенным корзинам S3. Обратите внимание, что мы использовали подстановочный знак для имени корзины S3 в политике IAM (tamperingdetection*).

Запустите блокнот развертывания
Пробегите каждую ячейку в блокноте tampering_detection_model_deploy.ipynb чтобы. Мы обсудим некоторые ячейки более подробно в следующих разделах.
Создайте ведро S3
Запустите ячейку, чтобы создать корзину S3. Ведро будет называться tamperingdetection<current date time> и в том же регионе AWS, что и ваша среда SageMaker Studio.

Создайте архив артефактов модели и загрузите их на Amazon S3.
Создайте файл tar.gz из артефактов модели. Мы сохранили артефакты модели в каталоге с именем 1, содержащем сериализованные сигнатуры и состояние, необходимое для их запуска, включая значения переменных и словари для развертывания в среде выполнения SageMaker. Вы также можете включить собственный файл вывода под названием inference.py в папке кода в артефакте модели. Пользовательский вывод можно использовать для предварительной и постобработки входного изображения.
![]()
Создайте конечную точку вывода SageMaker
Создание ячейки для создания конечной точки вывода SageMaker может занять несколько минут.
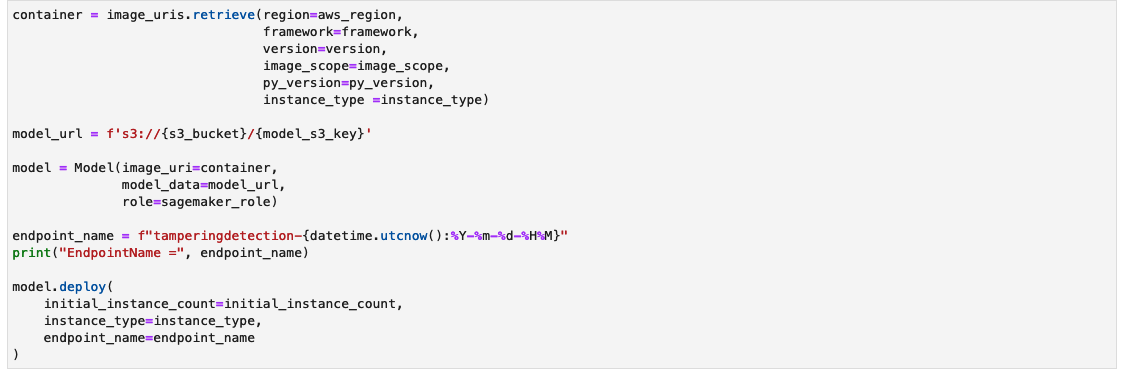
Проверьте конечную точку вывода
Функция check_image предварительно обрабатывает изображение как изображение ELA, отправляет его в конечную точку SageMaker для вывода, извлекает и обрабатывает прогнозы модели и печатает результаты. Модель принимает массив NumPy входного изображения в качестве изображения ELA для предоставления прогнозов. Прогнозы выводятся как 0, обозначающий незатронутое изображение, и 1, обозначающий поддельное изображение.

Давайте вызовем модель с незатронутым изображением платежной квитанции и проверим результат.

Модель выводит классификацию как 0, что представляет собой незатронутое изображение.
Теперь давайте вызовем модель с измененным изображением платежной квитанции и проверим результат.

Модель выводит классификацию как 1, что представляет собой поддельное изображение.
ограничения
Хотя ELA — отличный инструмент для обнаружения изменений, существует ряд ограничений, например следующие:
- Изменение одного пикселя или незначительная настройка цвета могут не привести к заметному изменению ELA, поскольку JPEG работает с сеткой.
- ELA только определяет, какие регионы имеют разные уровни сжатия. Если изображение более низкого качества соединяется с изображением более высокого качества, то изображение более низкого качества может выглядеть как более темная область.
- Масштабирование, перекрашивание или добавление шума к изображению изменят все изображение, создавая более высокий уровень ошибок.
- Если изображение пересохраняется несколько раз, то оно может полностью находиться на минимальном уровне ошибок, при котором дополнительные повторные сохранения не изменяют изображение. В этом случае ELA вернет черное изображение, и с помощью этого алгоритма невозможно выявить никакие изменения.
- В Photoshop простое сохранение изображения может автоматически повысить резкость текстур и краев, создавая более высокий уровень ошибок. Этот артефакт не указывает на преднамеренное изменение; он указывает на то, что использовался продукт Adobe. Технически ELA выглядит как модификация, поскольку Adobe автоматически выполнила модификацию, но эта модификация не обязательно была преднамеренной пользователем.
Мы рекомендуем использовать ELA наряду с другими методами, ранее обсуждавшимися в блоге, чтобы обнаружить более широкий спектр случаев манипулирования изображениями. ELA также может служить независимым инструментом для визуального изучения различий в изображениях, особенно когда обучение модели на основе CNN становится сложной задачей.
Убирать
Чтобы удалить ресурсы, созданные вами в рамках этого решения, выполните следующие действия:
- Запустите ячейки блокнота под уборка раздел. Это приведет к удалению следующего:
- Конечная точка вывода SageMaker – Имя конечной точки вывода будет
tamperingdetection-<datetime>. - Объекты внутри корзины S3 и сама корзина S3 – Имя сегмента будет
tamperingdetection<datetime>.
- Конечная точка вывода SageMaker – Имя конечной точки вывода будет
- выключать ресурсы блокнота SageMaker Studio.
Заключение
В этом посте мы представили комплексное решение для обнаружения подделки документов и мошенничества с использованием глубокого обучения и SageMaker. Мы использовали ELA для предварительной обработки изображений и выявления несоответствий в уровнях сжатия, которые могут указывать на манипуляции. Затем мы обучили модель CNN на этом обработанном наборе данных классифицировать изображения как оригинальные или подделанные.
Модель может обеспечить высокую производительность с точностью более 95 % при использовании набора данных (поддельного и оригинального), соответствующего требованиям вашего бизнеса. Это указывает на то, что он может надежно обнаруживать поддельные документы, такие как платежные квитанции и банковские выписки. Обученная модель развертывается на конечной точке SageMaker, чтобы обеспечить возможность вывода с малой задержкой в любом масштабе. Интегрируя это решение в рабочие процессы по ипотеке, учреждения могут автоматически отмечать подозрительные документы для дальнейшего расследования случаев мошенничества.
Несмотря на свою эффективность, ELA имеет некоторые ограничения в выявлении определенных типов более тонких манипуляций. В качестве следующих шагов модель может быть улучшена за счет включения в обучение дополнительных методов судебной экспертизы и использования более крупных и разнообразных наборов данных. В целом, это решение демонстрирует, как можно использовать глубокое обучение и сервисы AWS для создания эффективных решений, которые повышают эффективность, снижают риски и предотвращают мошенничество.
В части 3 мы демонстрируем, как реализовать решение на Amazon Fraud Detector.
Об авторах
 Ануп Равиндранат — старший архитектор решений в Amazon Web Services (AWS) в Торонто, Канада, работающий с организациями финансовых услуг. Он помогает клиентам трансформировать свой бизнес и внедрять инновации в облаке.
Ануп Равиндранат — старший архитектор решений в Amazon Web Services (AWS) в Торонто, Канада, работающий с организациями финансовых услуг. Он помогает клиентам трансформировать свой бизнес и внедрять инновации в облаке.
 Винни Сайни — старший архитектор решений в Amazon Web Services (AWS) в Торонто, Канада. Она помогает клиентам финансовых услуг трансформироваться в облако, используя решения на основе искусственного интеллекта и машинного обучения, заложенные на прочной основе архитектурного совершенства.
Винни Сайни — старший архитектор решений в Amazon Web Services (AWS) в Торонто, Канада. Она помогает клиентам финансовых услуг трансформироваться в облако, используя решения на основе искусственного интеллекта и машинного обучения, заложенные на прочной основе архитектурного совершенства.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/train-and-host-a-computer-vision-model-for-tampering-detection-on-amazon-sagemaker-part-2/

