В управлении активами управляющие портфелями должны внимательно следить за компаниями в их инвестиционной сфере, чтобы выявлять риски и возможности и принимать инвестиционные решения. Отслеживать прямые события, такие как отчеты о доходах или понижение кредитного рейтинга, очень просто: вы можете настроить оповещения, чтобы уведомлять менеджеров о новостях, содержащих названия компаний. Однако выявление воздействий второго и третьего порядка, возникающих в результате событий у поставщиков, клиентов, партнеров или других субъектов экосистемы компании, является сложной задачей.
Например, сбой в цепочке поставок у ключевого поставщика, скорее всего, негативно повлияет на производителей последующей переработки. Или потеря главного клиента для крупного клиента создает риск спроса для поставщика. Очень часто такие события не попадают в заголовки газет, в которых напрямую освещается затронутая компания, но на них все равно важно обращать внимание. В этом посте мы демонстрируем автоматизированное решение, сочетающее в себе графы знаний и генеративный искусственный интеллект (ИИ) чтобы выявить такие риски, сопоставив карты взаимосвязей с новостями в реальном времени.
В общих чертах это влечет за собой два шага: во-первых, построение сложных отношений между компаниями (клиентами, поставщиками, директорами) в граф знаний. Во-вторых, использование этой графовой базы данных вместе с генеративным искусственным интеллектом для обнаружения воздействий второго и третьего порядка от новостных событий. Например, это решение может подчеркнуть, что задержки у поставщика запчастей могут нарушить производство последующих автопроизводителей в портфеле, хотя ни один из них не упоминается напрямую.
С помощью AWS вы можете развернуть это решение в бессерверной, масштабируемой и полностью управляемой событиями архитектуре. В этом посте демонстрируется доказательство концепции, основанной на двух ключевых сервисах AWS, хорошо подходящих для представления знаний в виде графов и обработки естественного языка: Амазонка Нептун и Коренная порода Амазонки. Neptune — это быстрая, надежная, полностью управляемая служба графовых баз данных, которая упрощает создание и запуск приложений, работающих с тесно связанными наборами данных. Amazon Bedrock — это полностью управляемый сервис, который предлагает выбор высокопроизводительных базовых моделей (FM) от ведущих компаний в области искусственного интеллекта, таких как AI21 Labs, Anthropic, Cohere, Meta, Stability AI и Amazon, через единый API, а также широкий набор возможности для создания генеративных приложений ИИ с безопасностью, конфиденциальностью и ответственным ИИ.
В целом, этот прототип демонстрирует искусство возможного с помощью графов знаний и генеративного искусственного интеллекта — получения сигналов путем соединения разрозненных точек. Вывод для профессионалов в области инвестиций — это возможность оставаться в курсе событий ближе к сигналу, избегая при этом шума.
Постройте граф знаний

Первым шагом в этом решении является построение графика знаний, а ценным, но часто упускаемым из виду источником данных для графиков знаний являются годовые отчеты компании. Поскольку официальные корпоративные публикации перед выпуском проходят тщательную проверку, содержащаяся в них информация, скорее всего, будет точной и достоверной. Однако годовые отчеты пишутся в неструктурированном формате, предназначенном для чтения человеком, а не для машинного использования. Чтобы раскрыть их потенциал, вам нужен способ систематически извлекать и структурировать богатство фактов и отношений, которые они содержат.
Благодаря генеративным сервисам искусственного интеллекта, таким как Amazon Bedrock, у вас теперь есть возможность автоматизировать этот процесс. Вы можете взять годовой отчет и запустить конвейер обработки, чтобы принять отчет, разбить его на более мелкие фрагменты и применить понимание естественного языка для выявления существенных объектов и связей.
Например, предложение, в котором говорится, что «[Компания А] расширила свой европейский автопарк по доставке электромобилей заказом на 1,800 электрофургонов у [Компании Б]», позволит Amazon Bedrock идентифицировать следующее:
- [Компания А] в качестве клиента
- [Компания Б] в качестве поставщика
- Отношения с поставщиками между [Компанией А] и [Компанией Б]
- Подробности взаимоотношений с «поставщиком электрофургонов»
Извлечение таких структурированных данных из неструктурированных документов требует предоставления тщательно продуманных подсказок для больших языковых моделей (LLM), чтобы они могли анализировать текст и извлекать такие сущности, как компании и люди, а также отношения, такие как клиенты, поставщики и многое другое. Подсказки содержат четкие инструкции о том, на что следует обращать внимание, и структуру возврата данных. Повторяя этот процесс для всего годового отчета, вы можете извлечь соответствующие сущности и связи и построить богатый граф знаний.
Однако прежде чем зафиксировать извлеченную информацию в графе знаний, вам необходимо сначала устранить неоднозначность сущностей. Например, в графе знаний уже может быть другая сущность «[Компания А]», но она может представлять другую организацию с тем же именем. Amazon Bedrock может анализировать и сравнивать такие атрибуты, как сфера деятельности бизнеса, отрасль и отрасли, приносящие доход, а также отношения с другими объектами, чтобы определить, действительно ли эти два объекта различны. Это предотвращает ошибочное слияние несвязанных компаний в единое целое.
После завершения устранения неоднозначности вы можете надежно добавлять новые сущности и отношения в свой график знаний Нептуна, обогащая его фактами, извлеченными из годовых отчетов. Со временем прием надежных данных и интеграция более надежных источников данных помогут построить комплексный граф знаний, который поможет выявить ценные сведения с помощью запросов к графу и аналитики.
Эта автоматизация, обеспечиваемая генеративным искусственным интеллектом, позволяет обрабатывать тысячи годовых отчетов и открывает бесценный ресурс для создания графов знаний, который в противном случае остался бы неиспользованным из-за непомерно больших затрат ручного труда.
На следующем снимке экрана показан пример визуального исследования, которое возможно в графовой базе данных Neptune с использованием Графический обозреватель инструмент.

Обрабатывать новостные статьи

Следующим шагом решения является автоматическое обогащение новостных лент портфельных менеджеров и выделение статей, соответствующих их интересам и инвестициям. Что касается ленты новостей, портфельные менеджеры могут подписаться на любого стороннего поставщика новостей через Обмен данными AWS или другой новостной API по своему выбору.
Когда новостная статья поступает в систему, для обработки содержимого запускается конвейер приема. Используя методы, аналогичные обработке годовых отчетов, Amazon Bedrock используется для извлечения сущностей, атрибутов и связей из новостной статьи, которые затем используются для устранения неоднозначности в графе знаний и идентификации соответствующей сущности в графе знаний.
Граф знаний содержит связи между компаниями и людьми, и, связывая сущности статей с существующими узлами, вы можете определить, находятся ли какие-либо субъекты в пределах двух шагов от компаний, в которые менеджер портфеля инвестировал или в которых заинтересован. статья может иметь отношение к портфельному менеджеру, и поскольку основные данные представлены в виде графика знаний, их можно визуализировать, чтобы помочь портфельному менеджеру понять, почему и как этот контекст важен. Помимо выявления связей с портфелем, вы также можете использовать Amazon Bedrock для анализа настроений упомянутых объектов.
Конечным результатом является расширенная новостная лента, в которой появляются статьи, которые могут повлиять на области интересов и инвестиций портфельного менеджера.
Обзор решения
Общая архитектура решения выглядит следующим образом.
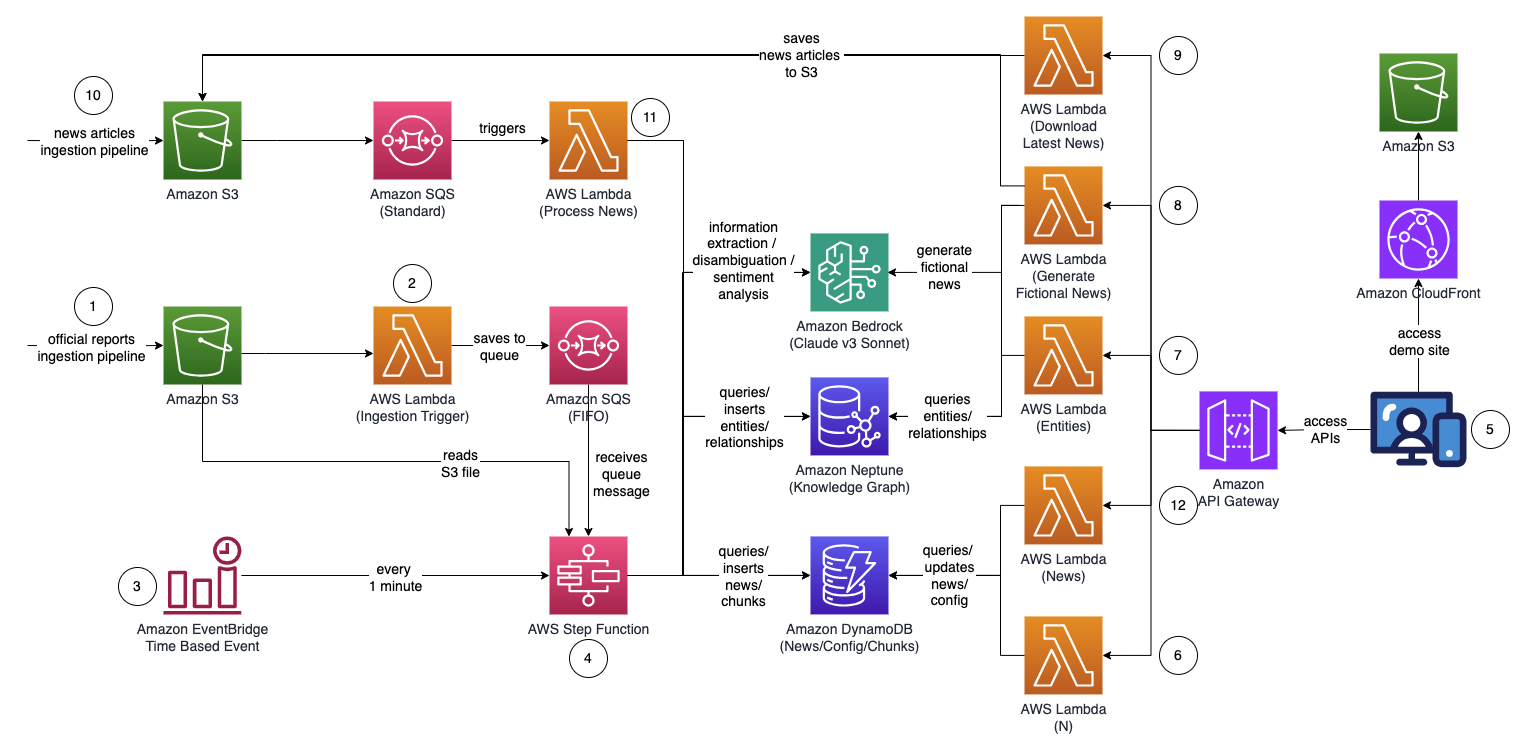
Рабочий процесс состоит из следующих шагов:
- Пользователь загружает официальные отчеты (в формате PDF) на Простой сервис хранения Amazon (Amazon S3) ведро. Отчеты должны быть официально опубликованными, чтобы свести к минимуму включение неточных данных в ваш график знаний (в отличие от новостей и таблоидов).
- Уведомление о событии S3 вызывает AWS Lambda функция, которая отправляет корзину S3 и имя файла в Простой сервис очередей Amazon (Amazon SQS) очередь. Очередь «первым пришел — первым обслужен» (FIFO) гарантирует, что процесс приема отчетов выполняется последовательно, чтобы снизить вероятность внесения дублирующихся данных в ваш граф знаний.
- An Amazon EventBridge событие, основанное на времени, запускается каждую минуту, чтобы начать выполнение Шаговые функции AWS конечный автомат асинхронно.
- Конечный автомат Step Functions выполняет ряд задач для обработки загруженного документа, извлекая ключевую информацию и вставляя ее в ваш граф знаний:
- Получите сообщение очереди от Amazon SQS.
- Загрузите файл отчета в формате PDF с Amazon S3, разделите его на несколько небольших текстовых фрагментов (около 1,000 слов) для обработки и сохраните текстовые фрагменты в Amazon DynamoDB.
- Используйте Anthropic Claude v3 Sonnet на Amazon Bedrock для обработки первых нескольких фрагментов текста и определения основного объекта, на который ссылается отчет, а также соответствующих атрибутов (например, отрасли).
- Получите фрагменты текста из DynamoDB и для каждого фрагмента текста вызовите функцию Lambda для извлечения объектов (например, компании или человека) и их отношений (клиент, поставщик, партнер, конкурент или директор) с основным объектом с помощью Amazon Bedrock. .
- Объедините всю полученную информацию.
- Отфильтровывайте шум и ненужные объекты (например, общие термины, такие как «потребители») с помощью Amazon Bedrock.
- Используйте Amazon Bedrock для устранения неоднозначности, сравнивая извлеченную информацию со списком аналогичных объектов из графа знаний. Если сущность не существует, вставьте ее. В противном случае используйте сущность, которая уже существует в графе знаний. Вставьте все извлеченные связи.
- Выполните очистку, удалив сообщение очереди SQS и файл S3.
- Пользователь обращается к веб-приложению на основе React для просмотра новостных статей, дополненных информацией об сущности, настроении и пути подключения.
- Используя веб-приложение, пользователь указывает количество прыжков (по умолчанию N=2) на пути подключения для мониторинга.
- С помощью веб-приложения пользователь указывает список объектов для отслеживания.
- Для создания вымышленных новостей пользователь выбирает Создать образец новостей создать 10 образцов статей о финансовых новостях со случайным содержанием, которые будут использоваться в процессе приема новостей. Контент создается с помощью Amazon Bedrock и является чисто вымышленным.
- Чтобы загрузить актуальные новости, пользователь выбирает Скачать последние новости чтобы загрузить главные новости сегодняшнего дня (на базе NewsAPI.org).
- Файл новостей (формат TXT) загружается в корзину S3. Шаги 8 и 9 автоматически загружают новости в корзину S3, но вы также можете интегрировать ее с предпочитаемым вами поставщиком новостей, например AWS Data Exchange, или любым сторонним поставщиком новостей, чтобы помещать новостные статьи в виде файлов в корзину S3. Содержимое файла данных новостей должно быть отформатировано как
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - Уведомление о событии S3 отправляет корзину S3 или имя файла в Amazon SQS (стандартно), который вызывает несколько функций Lambda для параллельной обработки данных новостей:
- Используйте Amazon Bedrock для извлечения объектов, упомянутых в новостях, вместе со всей связанной информацией, связями и настроениями упомянутых объектов.
- Сравните график знаний и используйте Amazon Bedrock для устранения неоднозначности, рассуждая, используя доступную информацию из новостей и из графика знаний, чтобы идентифицировать соответствующий объект.
- После обнаружения объекта найдите и верните все пути подключения, соединяющие объекты, отмеченные значком
INTERESTED=YESв графе знаний, которые находятся в пределах N=2 прыжков.
- Веб-приложение автоматически обновляется каждую 1 секунду, чтобы получить последний набор обработанных новостей для отображения в веб-приложении.
Развертывание прототипа
Вы можете развернуть прототип решения и начать экспериментировать самостоятельно. Прототип доступен по адресу GitHub и включает подробную информацию о следующем:
- Предварительные условия развертывания
- Шаги развертывания
- Этапы очистки
Обзор
В этом посте продемонстрировано концептуальное решение, помогающее портфельным менеджерам выявлять риски второго и третьего порядка, связанные с новостными событиями, без прямых ссылок на компании, которые они отслеживают. Объединив график знаний о сложных взаимоотношениях компаний с анализом новостей в реальном времени с использованием генеративного искусственного интеллекта, можно выявить последствия последующих процессов, такие как задержки производства из-за сбоев в работе поставщиков.
Хотя это всего лишь прототип, это решение демонстрирует перспективность графов знаний и языковых моделей для соединения точек и извлечения сигналов из шума. Эти технологии могут помочь профессионалам в области инвестиций, поскольку они быстрее выявляют риски с помощью карт взаимоотношений и рассуждений. В целом, это многообещающее применение графовых баз данных и искусственного интеллекта, которое требует изучения для улучшения инвестиционного анализа и принятия решений.
Если этот пример генеративного искусственного интеллекта в финансовых услугах представляет интерес для вашего бизнеса или у вас есть аналогичная идея, обратитесь к своему менеджеру по работе с клиентами AWS, и мы будем рады продолжить с вами изучение.
Об авторе
 Ксан Хуанг — старший архитектор решений в AWS, живет в Сингапуре. Он сотрудничает с крупными финансовыми учреждениями над проектированием и созданием безопасных, масштабируемых и высокодоступных облачных решений. Вне работы Ксан проводит большую часть своего свободного времени со своей семьей и находится под руководством своей трехлетней дочери. Вы можете найти Ксана на LinkedIn.
Ксан Хуанг — старший архитектор решений в AWS, живет в Сингапуре. Он сотрудничает с крупными финансовыми учреждениями над проектированием и созданием безопасных, масштабируемых и высокодоступных облачных решений. Вне работы Ксан проводит большую часть своего свободного времени со своей семьей и находится под руководством своей трехлетней дочери. Вы можете найти Ксана на LinkedIn.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

